CARTOとDatabricksによるフリート最適化
CPGを効率的に移動・配送するための空間解析の活用
によって Javier de la Torre, Miguel Ángel Carvajal, Cayetano Benavent, Eduardo Fernández León 、 ミロシュ・コリック による投稿
Original : Fleet optimization with CARTO & Databricks
翻訳: junichi.maruyama
近年、効率的な配送は企業にとってますます重要になってきており、特に物流企業や独自の流通網を持つ消費財(CPG)業界の企業にとって重要な課題となっています。
これらの企業にとって大きな課題は、輸送ルートを最適化し、コストを最小化しながらタイムリーな配送を実現することです。そのためには、距離、交通量、道路状況、使用する輸送手段の種類(トラック、鉄道、航空など)などの要素を考慮する必要があります。さらに、CPGやロジスティクス企業は、輸送手段の選択による環境への影響を考慮し、カーボンフットプリントの削減を目指さなければなりません。燃料価格の上昇と競争の激化により、これらの企業にとって、より持続可能性を高め、輸送の問題に対処し、全体的な配送コストを削減するための明確な計画を策定することが極めて重要となっています。
ルーティングソフトは、企業がこれらの課題に取り組む上で、以下のような重要なツールとなっています:
- より良いルートを計画し、全体的な燃料消費量とメンテナンス費用を削減する。
- お客様への配送時間を最適化
- 地理的な背景を考慮したルートのグラフ表示など、配送ネットワークに関する明��確で最新の洞察を得ることができます。
- 主要業績評価指標を用いたルートの定量分析
- 制約に基づく最適化手法の一環として、道路交通や気象データなどの追加データソースを活用する。
DatabricksとパートナーであるCARTOが、お客様の物流戦略を最適化し、配送プロセスやルートをより効率的かつ費用対効果の高いものにするために、どのようなサポートを提供できるのか、ご覧ください。
車両経路問題
車両経路問題(VRP)は、最適化問題の一種であり、車両がある場所に行くための最適な経路を、様々な制約条件を満たしながら見つけようとするものである。分析的な観点から、VRPを扱う場合、以下の表に示すような様々な制約を考慮する必要がある:
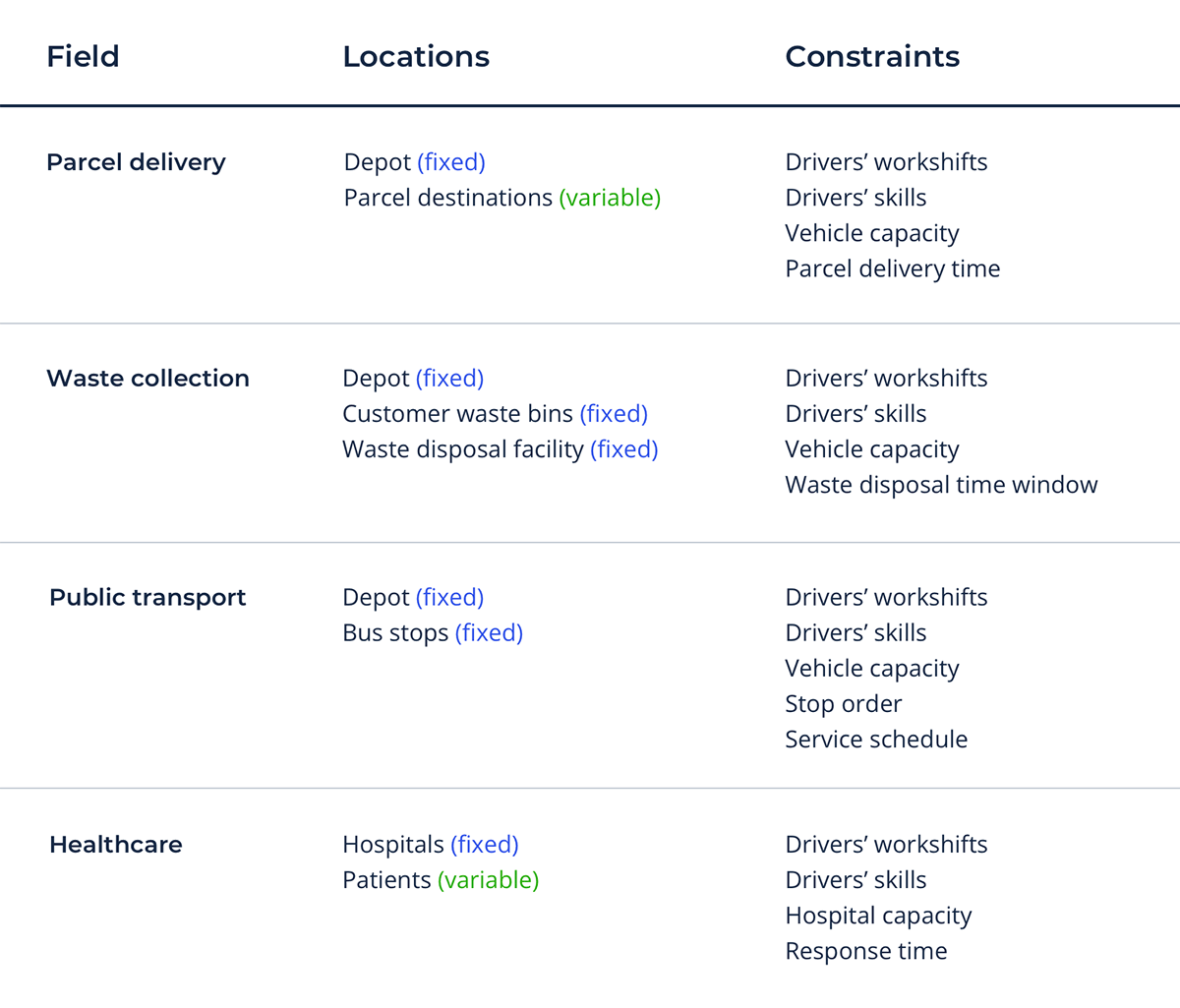
VRPは、よりシンプルなユースケースである巡回販売員問題(TSP)を一般化したものです:
訪問する都市がいくつもある場合、各都市をちょうど1回ずつ通過して元の都市に戻ってくる最短ルートはど�のようになるのだろうか?
TSPでは、1台の車両が最短ルートですべての都市を訪問する必要があり、唯一の制約は同じ都市を2回訪問しないことである。TSPとVRPの主な違いは、VRPでは1台の車両ではなく、車両群を考慮し、一連の追加制約を考慮しなければならないことです。
VRP = ロケーション + 車両群 + 制約 + 最適化する大きさ
VRPの問題は多岐に渡り、複雑であるため、以下のような多くのシナリオがあります:
- 車両は複数のルートを通ることができる -> VRP with Multiple Trips (VRPMT)
- 車両が元の場所に戻る必要はない -> Open VRP (OVRP)
- 車両は異なるデポで出発・終了することができる -> Multi Depot VRP (MDVRP)
- 車両は一定の容量まで荷物を運ぶことができる -> Capacitated VRP (CVRP)
- 特定の時間帯にしか訪問できない場所 -> VRP with Time Windows (VRPTW)
これは、利用可能なオプションのほんの一例に過ぎません。さらに複雑なことに、上記のすべてを組み合わせて新しいVRPを定義することも可能です。
一般に、VRP問題は難解である!NP困難問題と呼ばれるカテゴリーに属します。この問題を解くのに必要な時間は、入力データの大きさに応じて急速に増加する。
VRPを解くための素朴なアプローチは、次のようなものです:
1- 車両と訪問場所の組み合わせとして、すべての可能な解を計算する。
2- 制約を満たさない解を破棄する。
3- 各解の良し悪しを測るために、ある種のスコアを計算する。
4- 最良のスコアを持つ解を選択する
車両と訪問先の数が増えると、経路の組み合わせの数が桁違いに増える。例えば、1秒間に1,000,000,000回の演算ができるコンピュータがあるとします。異なるサイズのVRPを解くのにどれくらいの時間がかかるか見てみましょう:
| Locations to visit | Operations required | Time required |
|---|---|---|
| 5 | 5! = 120 | 0.00000012 seconds |
| 10 | 10! = 3628800 | 0.004 seconds |
| 15 | 15! = 1307674368000 | 22 minutes |
| 20 | 20! = 2.4329E+18 | 4628 years |
| 25 | 25! = 1.55112E+25 | 295 million years |
実際の事例では、訪問する場所の数が数千に及ぶことも稀ではありません。つまり、VRPの解を求めるには、必ずしも最善とは言えないが、より短時間で計算できる解を提供する手法を用いる必要があることは明らかだ。問題を単純化/分割する技術を適用したとしても、処理のスケールアップの必要性があるのです。Databricks Lakehouseプラットフォームは、VRPのような複雑な問題がもたらす様々なニーズに自然にフィッ�トします。
いくつかのライブラリはVRPアルゴリズムを実装しており、車両群のルートを最適化するソフトウェアを開発することが可能です。しかし、これらのソリューションをゼロから構築するのは簡単なことではありません。これらの利用可能なライブラリを利用するにも、以下のような考慮が必要です:
- ルーティング・ライブラリを完全に理解するには、急な学習曲線が必要です。当社のソリューションは、抽象化レイヤーを提供し、問題提起からVRPソリューションまでのエンド・ツー・エンドの旅を簡素化するものです。
- VRPはリソースを大量に消費するため、企業規模のアプリケーションを展開するには、計算リソースを慎重に管理する必要があります:
- スケーリングとロードバランシング: Databricks Lakehouseプラットフォームは、特定の時間帯にのみ高い計算能力が求められるVRPにおいて、強力な味方となり得るのです。
- 耐障害性: DatabricksはPaaS型のクラウドサービスであるため、エンドユーザーが手動で回復力を処理する必要がなく、プラットフォームがリソースを確保し、オンデマンドでVRPを実行できるよう配慮しています。
- また、VRPとは別の側面も考慮する必要があります:
- 地理的なコンテキストでデータをグラフィカルに表現します。CARTOとDatabricksの統合により、スケーラブルなコンピュートとインタラクティブな地理空間UIが見事に融合しています。
- ソリューションのパフォーマンスに関する主要なパフォーマンス指標を提供するチャートやメトリクスなどの追加のインサイト。MLFlowは、VRPソリューションのさまざまな側��面を照合し、包括的な監査証跡を作成する一連の機能を提供します。
Databricksを活用したCARTOのフリート最適化ソリューションの紹介
この複雑な空間問題に対処するため、CARTOはフリート最適化ツールキットを提供し、開発者はDatabricksの強力で弾力的なコンピューティングリソースを最大限に活用して、企業がより効率的で競争力があり環境に優しいルーティングアプリケーションを設計できるようにします。
CARTOのルーティング・ソリューションは、いくつかのレディメイドのコンポーネントを提供します。このフレームワークのさまざまな要素を定義することができ、ユーザーはルーティング問題の具体的な詳細を設定することができます。
以下の図は、Databricks上でCARTOルーティング・モジュールを使用してルーティング問題を解決するプロセスを示しています。
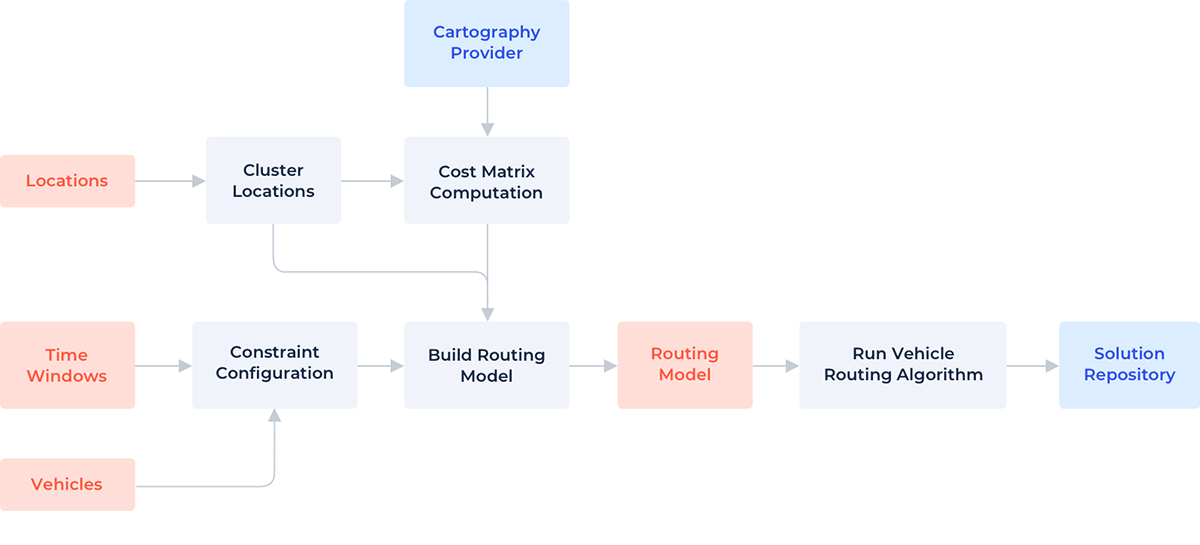
これらが、ソリューションの主な構成要素です:
- ビークルルーティングアルゴリズム。入力されたVRPに対して有効な解を計算する。
- ルーティング・モデル。停車駅、制約条件、経路コスト行列など、ルーティング・アルゴリズムが入力として必要とするすべてのものを含む問題設定が含まれている。
- カートグラフィープロバイダー。問題の各停留所間の移動経路を決定するために使用される交通地図を提供します。
- ロケーション・クラスタリング。問題のサイズを小さくするために、十分に近いロケーションを「ストップ」と呼ばれるグループに分類する。異なるクラスタリングアルゴリズムを定義することができる。
- 制約の構成。Time Windowsとドライバーから制約を作成し、ルーティングモデルに追加します。
- ソリューションリポジトリ。ルーティングアルゴリズムが正常に終了し、ソリューションが計算された後、Delta Lakeのようなソリューションリポジトリに保存することができます。
これらのコンポーネントを使用したアプリケーションの設計に使用できるサンプルコードを示します:
最初のコード例です。ネットワークデータを用意する.
2つ目のコード例:フリートの最適化問題を解く:
上記の例では、CARTOのルーティング・ソリューションを使ってVRPソリューションのコードを構築することがいかに簡単であるかを示しました。Databricks Lakehouseプラットフォームとのシームレスな統合により、これらのソリューションは簡単にスケールアップすることができ、Databricksのスケーラブルな計算機を使って多くのVRP問題を並行して実行することができます。同時に、MLFlowを使って異なるサブ問題を簡単に追跡し、異なる実行に関するメタデータを照合することができます。
ユースケース例:様々な小売店に配送するCPG会社
CPG企業にとって効果的な配送とロジスティクスの重要性を説明するために、独自の流通網を持つCPG企業の実際の使用例を考えてみましょう。このCPG企業は、指定された期��日に各小売店に配送する製品を多数配置し、これらの製品のほとんどは配送に特定の時間枠が設けられています。
物流ネットワークを最適化するために、同社はすべての製品を配送するために必要な車両の数を見積もり、輸送ルートを最適化してコストを最小化しつつ、タイムリーな配送を目指します。
VRPの解は、以下のような多くの追加的な側面を考慮する必要がある:
| Vehicles |
|
| Products |
|
| Depots |
|
当社の車両は、多数の車両とそのドライバーで構成されています。デポから小売店まで、さまざまなルートがあります。できるだけ多くの商品を、できるだけ短い時間で、できるだけ少ない車両で届けたい。また、配送時間帯、ドライバーの勤務シフト、車両のキャパシティなど、いくつかの制約もあります。
毎日、早朝にフリート最適化プロセスを実行し、日次VRPを解きます。その結果、ドライバーが通るべきルートと、それを視覚化するための地図が得られます。また、停車駅のリストと�、それぞれの停車駅で配送する商品のリストも得られます。各ルートは特定の車両に割り当てられ、いくつかのKPIを追跡することで状況を確認することができます。例えば、合計で何回停車したのか、各ルートの平均走行距離を確認することができます。さらに、ルートの所要時間をヒストグラムグラフで表示することもできます。
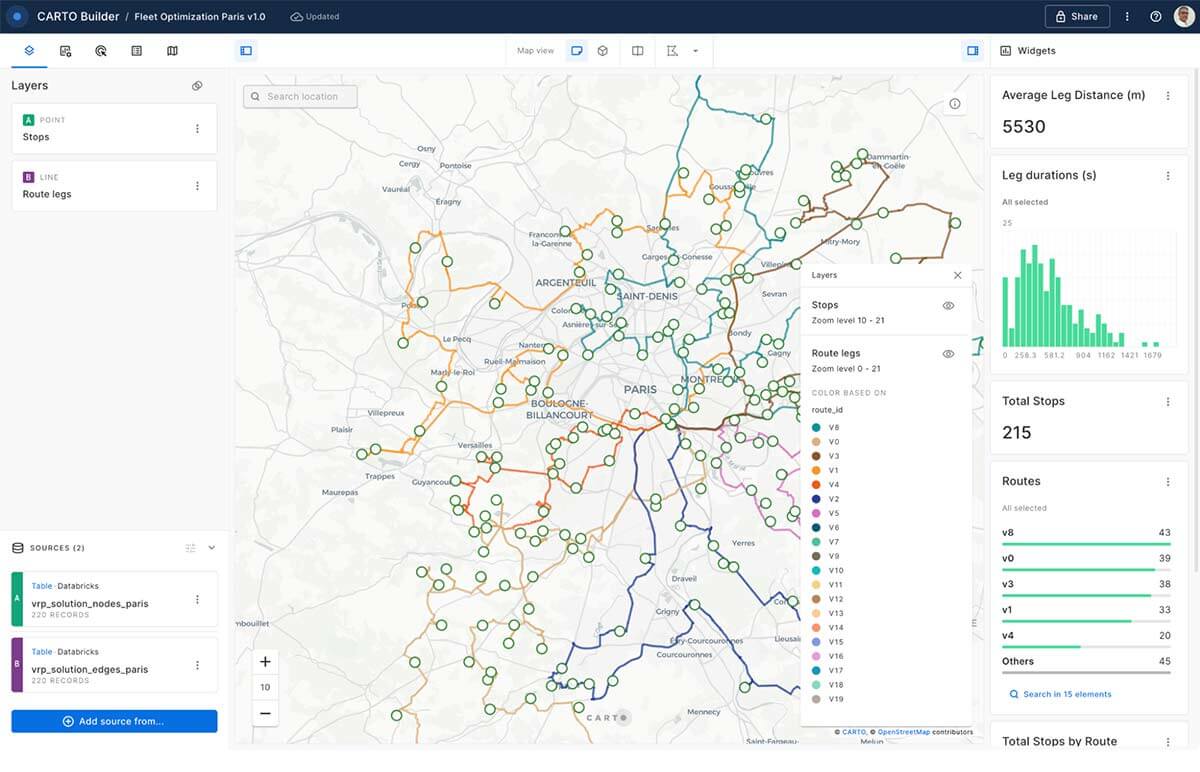
優れたルート最適化は、企業に競争優位性をもたらすことができます。物流網を最適化することで、競合他社よりも早く、費用対効果が高く、信頼性の高い配送を提供することができ、市場シェアを拡大することができるのです。
CARTOとDatabricksのフリート最適化ソリューションがお客様のユースケースにどのように適用できるかを確認したい場合は、遠慮なくご連絡をください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。