全体像を把握: Databricksとクラウドインフラストラクチャのコストを統合
FinOpsチームとプラットフォームチームが実際に使いたくなるような、統合されたコストダッシュボードを自動化する方法を学びましょう。
によって Steven Muschler, ダニエル・マルティネス・アレバロ 、 Sadhana Bala による投稿
- 新しい Cloud Infra Cost Field Solution(AWS および Azure で利用可能)は、Databricks および関連するクラウドコストデータを取り込み、エンリッチ、結合、可視化して、アカウント、クラスター、さらにはタグレベルで総コストを表示する方法を示します。* この Field Solution を導入することで、FinOps チームとプラットフォームチームは、信頼できる単一の TCO ビューを得られます。これにより、ワークスペース、ワークロード、ビジネスユニット別に全コストをドリルダウンして使用状況を予算と整合させることが可能になり、手動での照合が不要になり、コスト報告が常時稼働の運用ケイパビリティに変わります。* General Motors のような企業は、このアプローチを採用して Databricks のコストを包括的に理解し、コストが可視化され、十分に理解されるようにしています。
Databricksにおける総所有コスト (TCO) の理解
AI とデータへの投資価値を理解することは極めて重要ですが、52% 以上の企業が投資収益率 (ROI) を厳密に測定できていません [Futurum]。ROI を完全に可視化するには、プラットフォームの使用状況とクラウドインフラストラクチャを結びつけて、明確な財務状況を把握する必要があります。今日のデータプラットフォームは、ますます多様化するストレージおよびコンピュートアーキテクチャをサポートする必要があるため、データは利用可能であっても断片化されていることがよくあります。
Databricksでは、顧客はマルチクラウド、マルチワークロード、マルチチームの環境を管理しています。このような環境では、十分な情報に基づいて意思決定を行うために、一貫性のある包括的なコストのビューを持つことが不可欠です。
Databricksのようなプラットフォームにおけるコストの可視性の中核には、総所有コスト (TCO) という概念があります。
Databricks のようなマルチクラウドデータプラットフォームでは、TCO は 2 つの主要なコンポーネントで構成されます。
- プラットフォーム費用(コンピューティングやマネージドストレージなど)は、Databricks 製品の直接使用によって発生する費用です。
- クラウドインフラストラクチャコスト (仮想マシン、ストレージ、ネットワーク料金など) は、Databricksをサポートするために必要な基盤となるクラウドサービスの利用によって発生するコストです。
サーバーレス製品を使用すると、TCO の把握が簡単になります。コンピュートは Databricks によって管理されるため、クラウドインフラストラクチャのコストは Databricks のコストにバンドルされ、Databricks のシステムテーブルで直接コストを一元的に可視化できます(ただし、ストレージコストは引き続きクラウドプロバイダーで発生します)。
しかし、従来のコンピュート製品の TCO を理解することはより複雑です。ここでは、顧客はクラウド プロバイダーでコンピュートを直接管理します。つまり、Databricks プラットフォームのコストとクラウド インフラスト�ラクチャのコストの両方を調整する必要があります。これらのケースでは、解決すべき 2 つの異なるデータソースがあります。
- Databricksのシステムテーブル(AWS | AZURE | GCP)は、運用ワークロードレベルのメタデータとDatabricksの使用状況を提供します。
- クラウドプロバイダーからのコストレポートには、割引を含め、クラウドインフラストラクチャのコストが詳述されます。
これらのソースを合わせることで、TCOの全体像が形成されます。環境が多くのクラスター、ジョブ、クラウドアカウントにまたがって成長するにつれて、これらのデータセットを理解することは、コストの可観測性と財務ガバナンスの重要な部分になります。
TCOの複雑性
DatabricksのTCO測定の複雑さは、クラウドプロバイダーがコストデータを公開および報告する方法がばらばらであることによって、さらに増大します。これらのデータセットをシステムテーブルと結合して正確なコストKPIを作成する方法を理解するには、クラウド課金の仕組みに関する深い知識が必要です。これは、Databricksを中心とする多くのプラットフォーム管理者が持っていない可能性のある知識です。ここでは、Azure DatabricksとDatabricks on AWSのTCO測定��について詳しく説明します。
Azure Databricks: ファーストパーティ請求データの活用
Azure DatabricksはMicrosoft Azureエコシステム内のファーストパーティサービスであるため、Databricks関連の料金は、Databricks固有のタグも含め、他のAzureサービスと並んでAzure Cost Managementに直接表示されます。Databricksのコストは、Azure Cost analysis UIおよびコスト管理データとして表示されます。
しかし、Azure Cost Managementのデータには、Databricksのシステムテーブルにあるような、より詳細なワークロードレベルのメタデータやパフォーマンスメトリクスは含まれません。このため、多くの組織がAzureの課金エクスポートをDatabricksに取り込もうとしています。
しかし、これら 2 つのデータソースを完全に結合するには時間がかかり、深いドメイン知識も必要です。これは、ほとんどの顧客が定義、維持、複製する時間がないほどの労力を要します。これには、いくつかの課題があります。
- Databricksで直接参照してクエリーを実行できるように、ADLSへのコストの自動エクスポート用にインフラストラクチャを設定する必要があります。
- 数時間単位で更新されるシステムテーブルとは異なり、Azureのコストデータは毎日集計・更新されます。データは慎重に重複排除し、Timestampを一致させる必要があります。
- 2つのソースを結合するには、カーディナリティの高いAzureタグデータを解析し、適切な結合キー (例: ClusterId) を特定する必要があります。
Databricks on AWS: マーケット�プレイスとインフラストラクチャのコストの整合
AWS では、Databricks のコストは コストと使用状況レポート (CUR) と AWS Cost Explorer に表示されますが、Azure とは異なり、コストはより集約された SKU レベルで表示されます。さらに、Databricks が AWS Marketplace を通じて購入された場合、Databricks のコストは CUR にのみ表示されます。それ以外の場合、CUR には AWS インフラストラクチャのコストのみが反映されます。
この場合、AWS 環境をご利用のお客様にとって、システムテーブルと合わせて AWS CUR を共同分析する方法を理解することは、さらに重要になります。これにより、チームはインフラストラクチャの支出、DBU の使用状況、割引をクラスターおよびワークロードレベルのコンテキストと合わせて分析し、AWS アカウントやリージョンを横断する、より完全な TCO ビューを作成できるようになります。
しかし、AWS CUR とシステム テーブルを結合することも困難な場合があります。一般的な問題点には、次のようなものがあります。
- AWS は当月および変更があった過去の請求期間のコストデータを(プライマリーキーなしで)1日に複数回更新・置換するため、インフラストラクチャは定期的な CUR の再処理をサポートする必要があります。
- AWSのコストデータは複数の明細項目タイプとコストフィールドにまたがっているため、集計する前に使用タイプ (オンデマンド、Savings Plan、リザーブドインスタンス) ごとの正しい実効コストを選択する際に注意が必要です。
- カーディナリティが異なる可能性があるため、CUR と Databricks メタデータを結合するには慎重な関連付けが必要です。例えば、共有の汎用クラスターは単一の AWS 使用状況の行として表されますが、システムテーブル内の複数のジョブにマッピングされることがあります。
Databricks TCO計算の簡素化
本番運用規模のDatabricks環境では、コストに関する問題はすぐに総支出額だけの問題ではなくなります。チームはコンテキストの中でコストを理解したい、つまり、インフラストラクチャとプラットフォームの使用状況が実際のワークロードや意思決定にどのように関連しているかを把握したいと考えています。一般的な質問は次のとおりです。
- サーバーレスジョブの総コストは、従来のジョブと比較してどのようになりますか?
- どのクラスター、ジョブ、ウェアハウスが、クラウド管理の VM を最も多く使用していますか?
- ワークロードがスケール、シフト、または統合されるにつれて、コストの傾向はどのように変化しますか?
これらの質問に答えるには、クラウドプロバイダーの財務データと Databricks の運用メタデータをまとめる必要があります。しかし、上記のように、これを実現するために、チームは独自のパイプラインと、クラウドおよび Databricks の請求に関する詳細なナレッジベースを維持する必要があります。
このニーズに対応するため、DatabricksはCloud Infra Cost Field Solutionを導入しています。これは、Databricksプラットフォーム内でクラウドインフラストラクチャとDatabricksの使用状況データの取り込みと統合分析を自動化するオープンソースソリューションです。
Databricksのサーバーレスおよび従来のコンピューティング環境全体にわたるTCO分析のための統一された基盤を提供することで、フィールドソリューションは、組織がコストの可視性をより明確にし、アーキテクチャ上のトレードオフを理解するのに役立ちます。エンジニアリングチームはクラウド支出と割引を追跡できる一方、財務チームはコスト増の主なコストドライバーを特定できます。
次のセクションでは、ソリューションの仕組みと始め方について解説します。
技術ソリューションの内訳
コンポーネント名は異なる場合がありますが、Azure と AWS 両方の顧客向けの Cloud Infra Cost Field Solution は同じ原則を共有しており、次のコンポーネントに分類できます。
- コストと使用状況のデータをクラウドストレージにエクスポートする
- Lakeflow Spark Declarative Pipelinesを使用して、Databricksでデータを取り込み、モデル化します
- AI/BI ダッシュボードを使用して、TCO 全体 (Databricks および関連するクラウドプロバイダーのコスト) を可視化します。
AWSとAzureの両方のフィールドソリューションは、単一クラウド内で事業を展開する組織にとって優れたものですが、Delta Sharingを使用することで、マルチクラウドのDatabricksをご利用のお客様向けに組み合わせることもできます。
Azure Databricks フィールドソリューション
Azure Databricks 向けクラウド インフラ コスト フィールド ソリューションは、以下のアーキテクチャ コンポーネントで構成されています。
Azure Databricks ソリューション アーキテクチャ
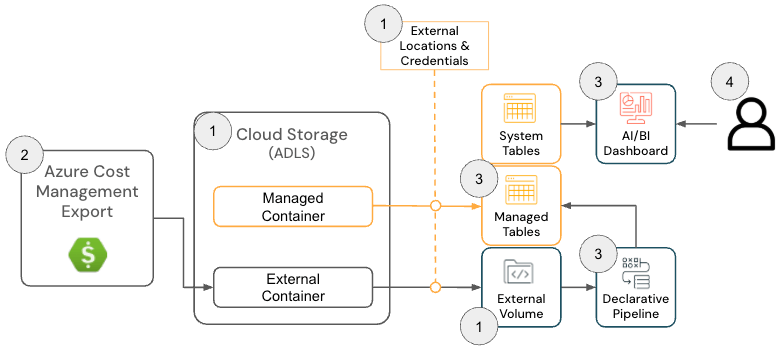
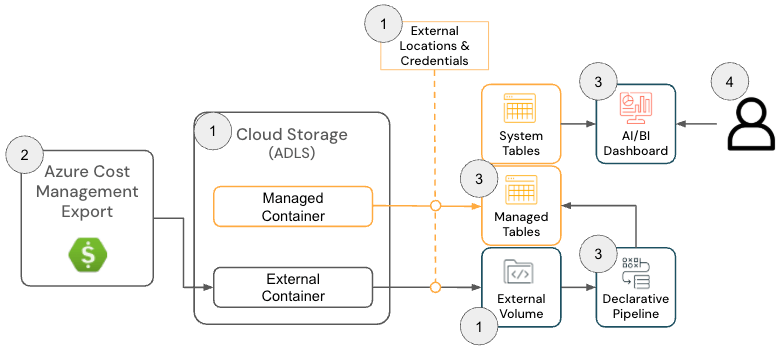{kind=link}
このソリューションをデプロイするには、管理者には Azure と Databricks にわたって以下の権限が必要です。
- Azure
- Azure Cost Export (Azure コストのエクスポート) を作成するためのアクセス許可
- リソースグループ内に次のリソースを作成するためのアクセス許可:
- Databricks
- 次のリソースを作成する権限:
- ストレージ資格情報
- 外部ロケーション
- 次のリソースを作成する権限:
GitHubリポジトリには、より詳細なセットアップ手順が記載されています。しかし、大まかに言うと、Azure Databricks向けのソリューションには次の手順があります。
- [Terraform] Terraform をデプロイして、ストレージ アカウント、外部ロケーション、ボリュームなどの依存コンポーネントを設定します。
- このステップの目的は、Databricks が読み取れるように Azure 請求データがエクスポートされる場所を設定することです。次のステップでAzure Cost Managementのエクスポート場所を設定できるため、既存のボリュームがある場合、このステップは任意です。
[Azure] Azure Cost Management Export を構成して Azure Billing データをストレージアカウントにエクスポートし、データが正常にエクスポートされていることを確認してください。
- このステップの目的は、Azure Cost Management のエクスポート機能を使用して、Azure Billing データを使いやすい形式 (例: Parquet) で利用できるようにすることです。
Azure Cost Management のエクスポートが構成されたストレージ アカウント
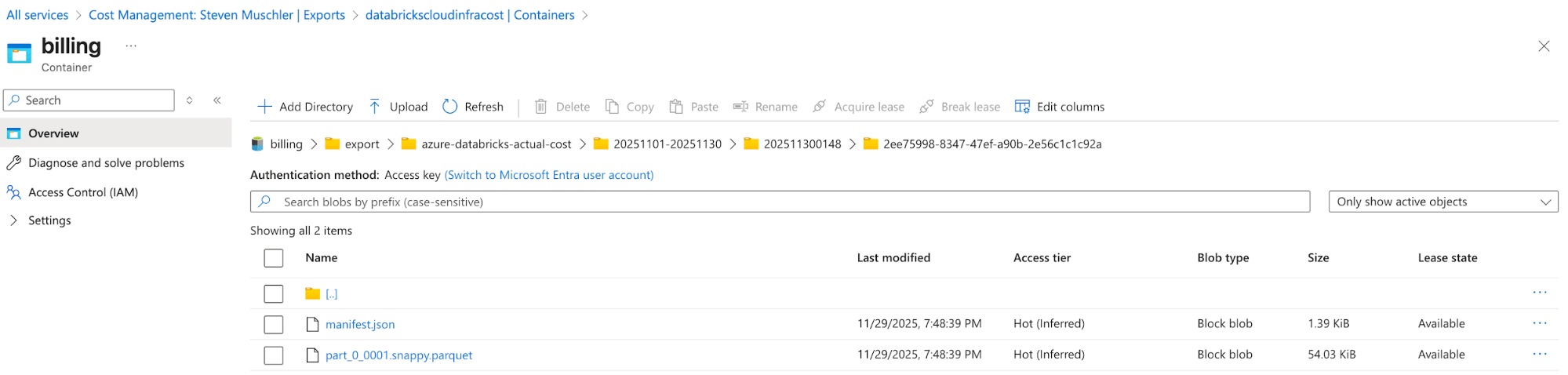
Azure Cost Management Export automatically delivers cost files to this location - [Databricks] Lakeflow Job、Spark宣言型パイプライン、AI/BI ダッシュボードをデプロイするた�めのDatabricks Asset Bundle (DAB) 設定
- このステップの目的は、Azureの請求データを取り込んでモデル化し、AI/BI dashboardを使用して視覚化することです。
- [Databricks] AI/BIダッシュボードのデータを検証し、Lakeflowジョブを検証
- この最後のステップで価値が実現します。これにより、顧客はLakehouseアーキテクチャのTCOを表示できる自動化されたプロセスを利用できるようになります。
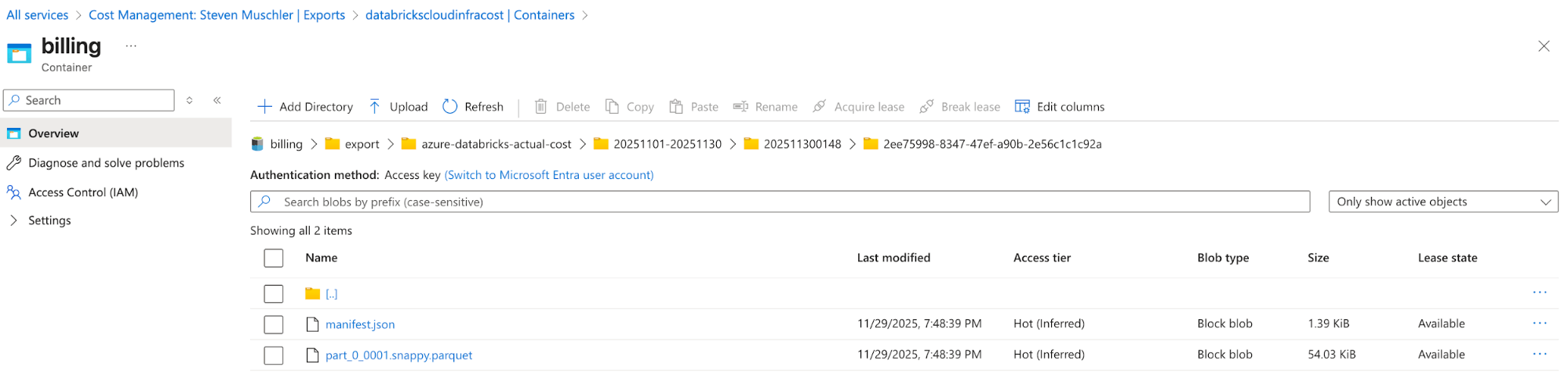{kind=link}
Azure Databricks の TCO を表示する AI/BI ダッシュボード
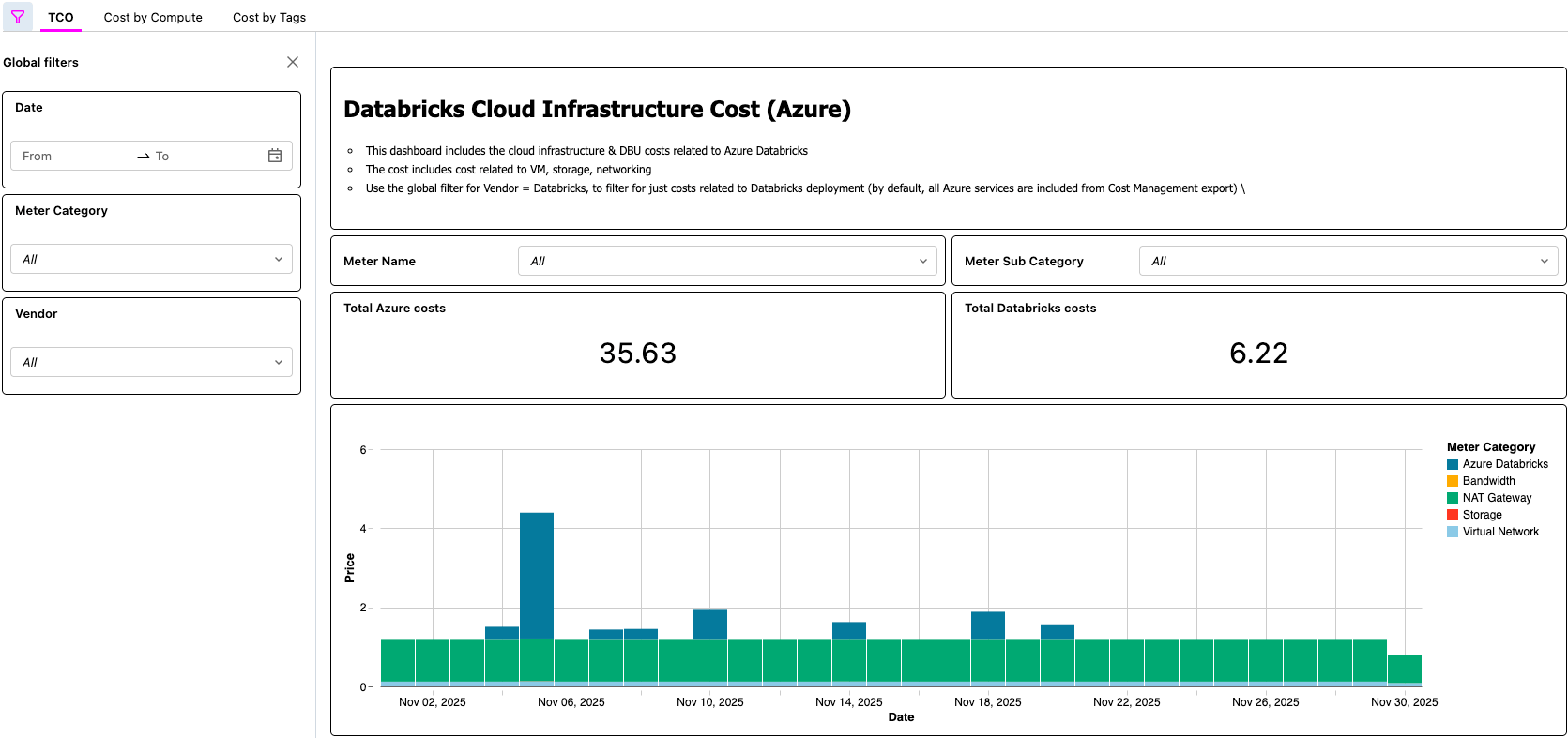
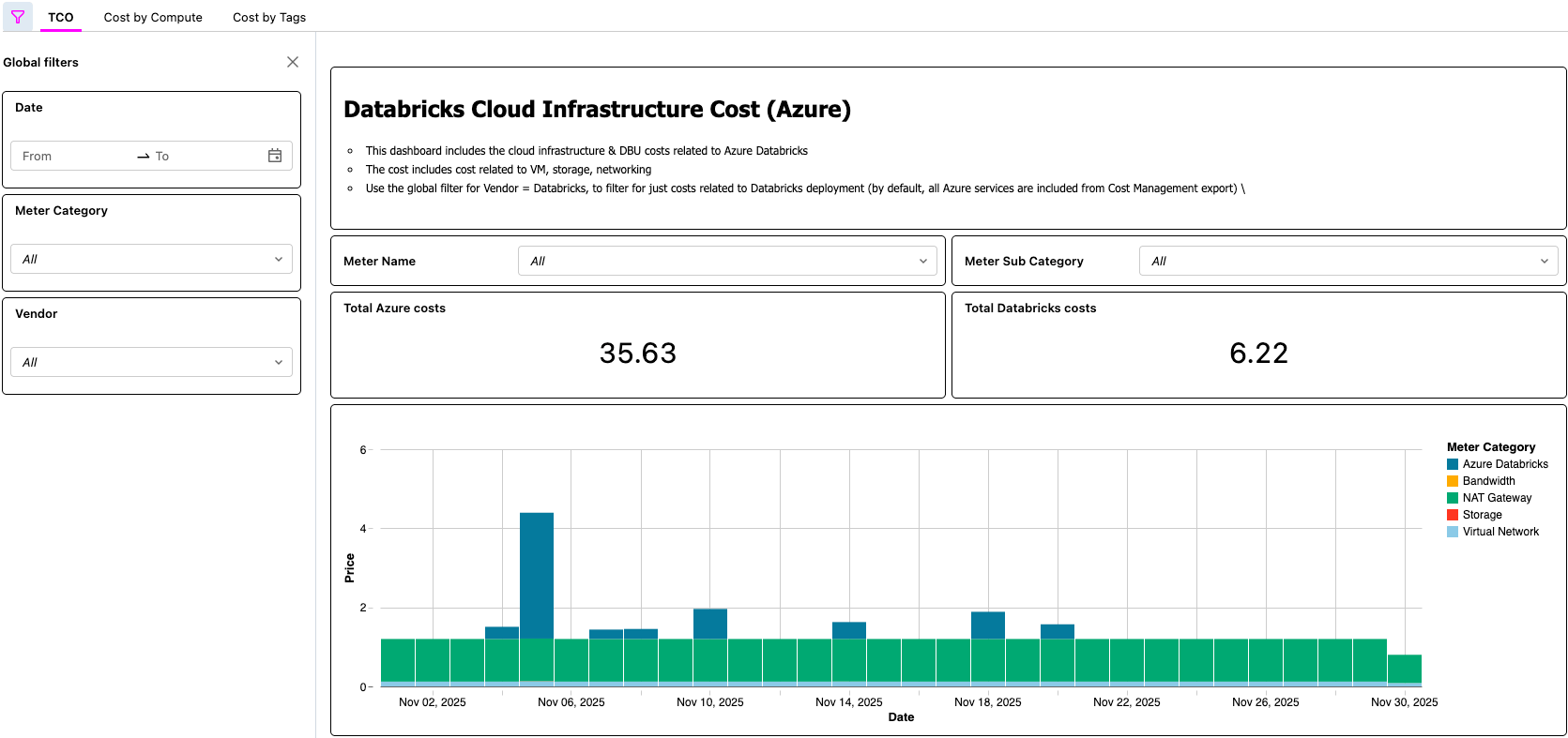{kind=link}
Databricks on AWSソリューション
Databricks on AWS向けのソリューションは、連携してAWS コストと使用状況レポート (CUR) 2.0データを取り込み、メダリオンアーキテクチャを使用してDatabricksに永続化する、いくつかのアーキテクチャコンポーネントで構成されています。
このソリ��ューションをデプロイするには、AWS と Databricks にわたって以下の権限と構成が設定されている必要があります。
- AWS
- CUR を作成する権限
- Amazon S3 バケットを作成するための権限 (または現在のバケットにCURをデプロイするための権限)
- 注: このソリューションには AWS CUR 2.0 が必要です。まだ CUR 1.0 のエクスポートを使用している場合は、AWS ドキュメントにアップグレードに必要なステップが記載されています。
- Databricks
- 次のリソースを作成する権限:
- ストレージ資格情報
- 外部ロケーション
- 次のリソースを作成する権限:
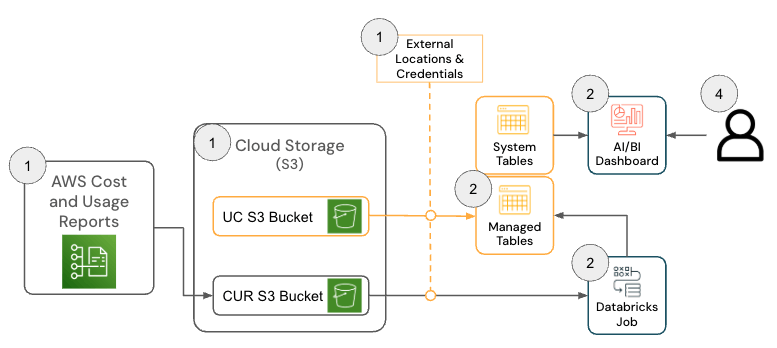
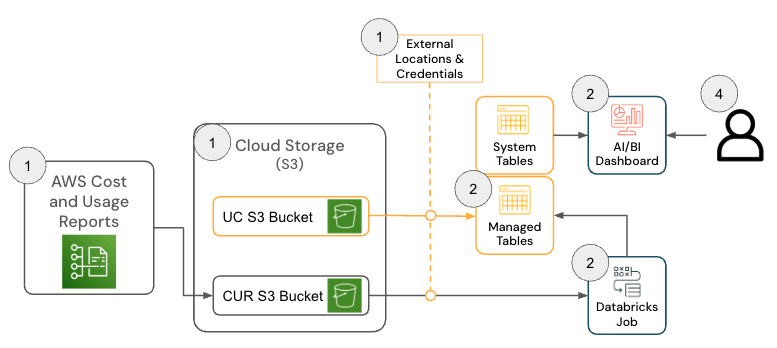{kind=link}
GitHub リポジトリには、より詳細なセットアップ手順が記載されています。しかし、概要として、AWS Databricks のソリューションには次のステップが含まれます。
- [AWS] AWS Cost & Usage Report (CUR) 2.0 セットアップ
- このステップの目的は、AWS CUR の機能を活用して、AWS の請求データを利用しやすい形式で利用できるようにすることです。
- [Databricks] Databricks アセットバンドル (DAB) 設定
- このステップの目的は、AWS の請求データを取り込んでモデル化し、AI/BI ダッシュボードで視覚化できるようにすることです。
- [Databricks] ダッシュボードの確認と Lakeflow ジョブの検証
- この最後のステップで、価値が実現されます。顧客は、レイクハウスアーキテクチャのTCOを把握できる自動化されたプロセスを利用できるようになりました!
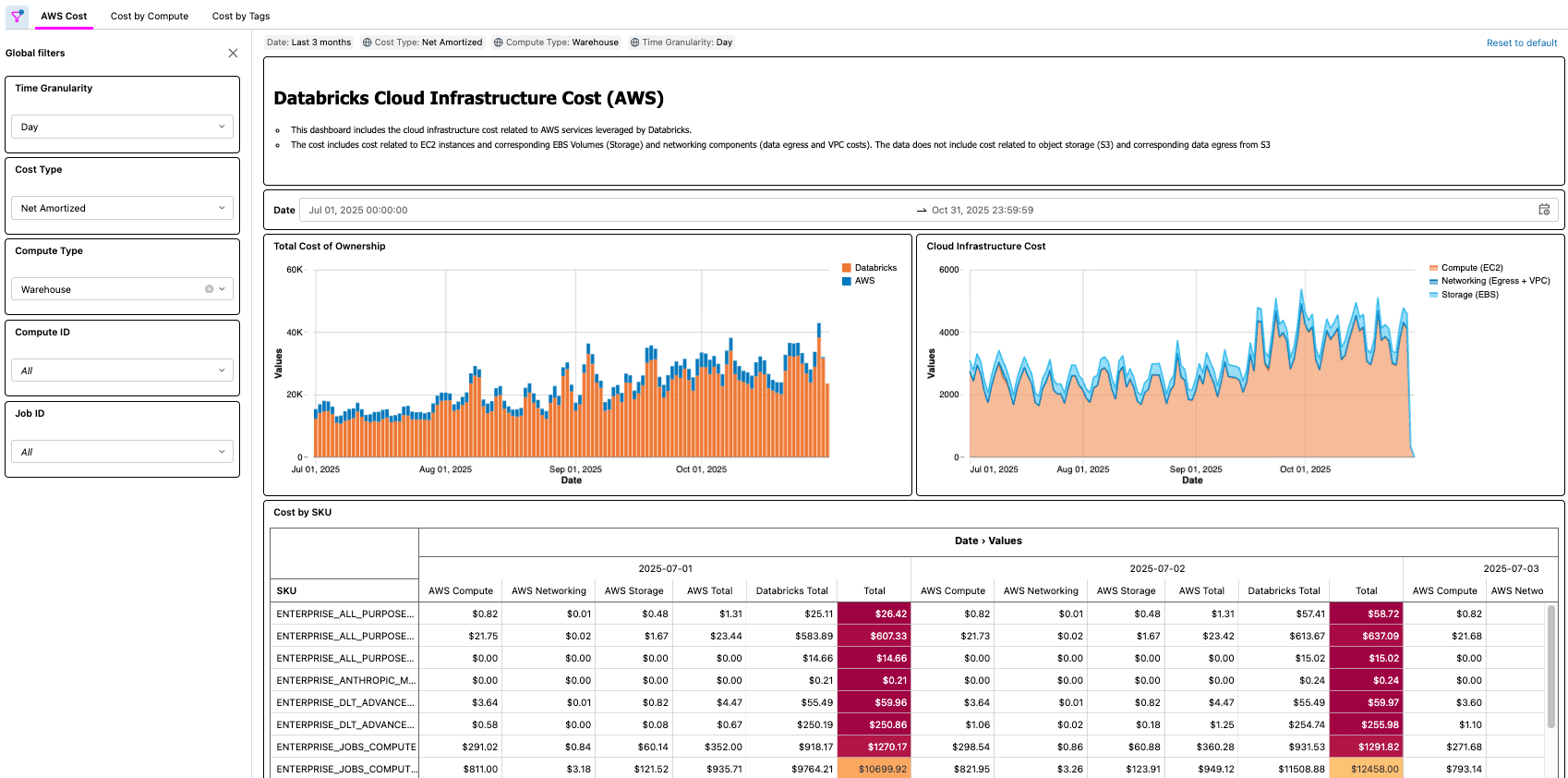
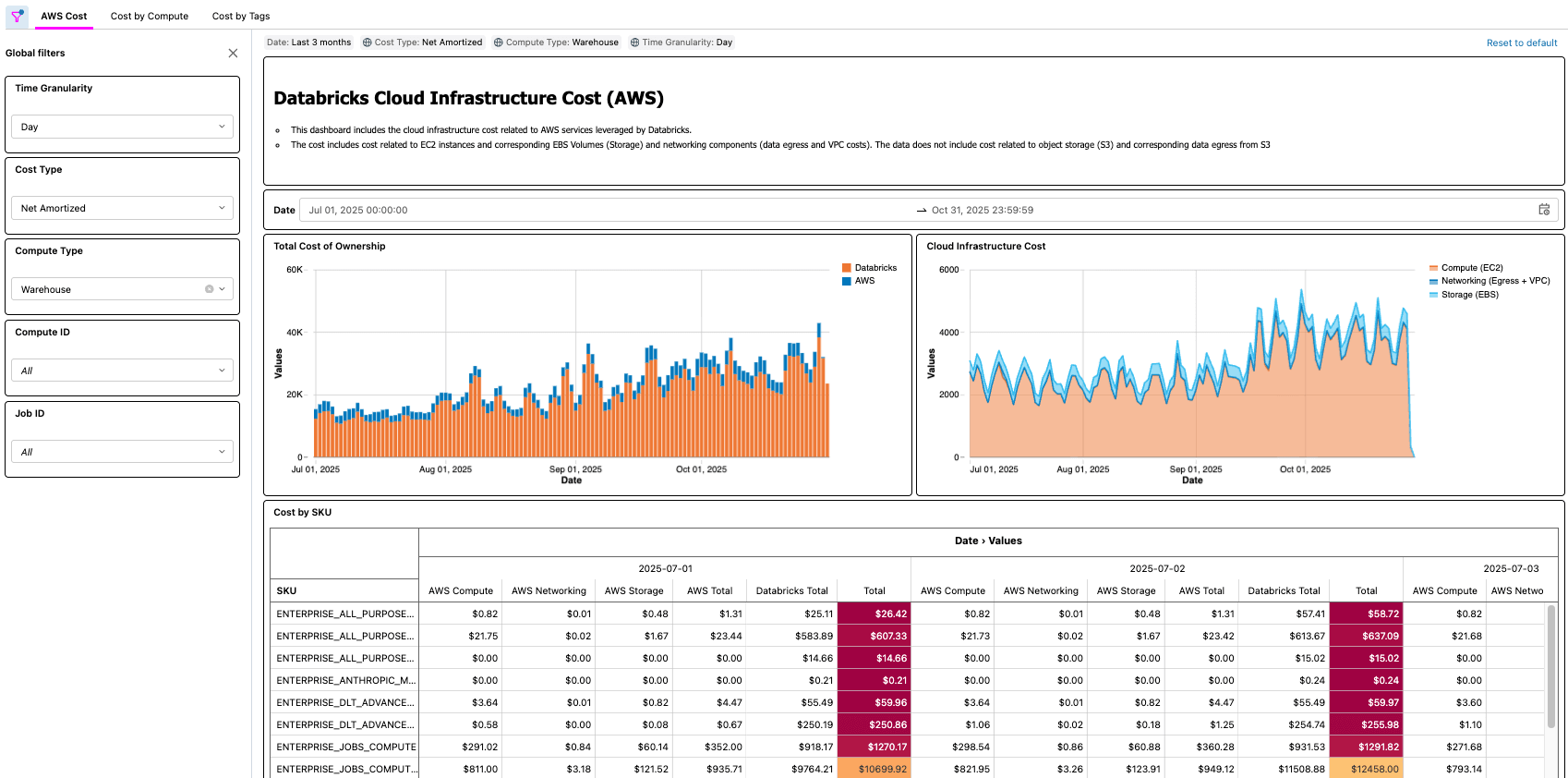{kind=link}
実際のシナリオ
AzureとAWS両方のソリューションで示されているように、このようなソリューションによって、以下のような多くの実世界の例が実現可能になります。
- CPUやメモリの使用率が低いジョブの最適化による総コスト削減額の特定と算出
- 予約がないVMタイプで実行されているワークロードを特定する
- ネットワークやローカルストレージのコストが異常に高いワークロードを特定する
実践的な例として、数千のワークロードを抱える大規模な組織のFinOps担当者は、一定のコストがかかるものの、CPUやメモリの使用率が低いワークロードを探すことで、最適化のために手軽に達成できる改善点を見つけるというタスクを課されるかもしれません。組織のTCO情報がCloud Infra Cost Field Solutionを介して表示されるようになったため、担当者はそのデータをNode Timelineシステムテーブル (AWS、AZURE、GCP) と結合してこの情報を表示し、最適化が完了した時点でコスト削減額を正確に定量化できます。最も重要となる質問は、顧客それぞれのビジネスニーズによって異なります。例えば、General Motors社は、この種のソ�リューションを使用して上記の多くの質問やその他の質問に答え、レイクハウスアーキテクチャから最大限の価値を得られるようにしています。
主要なポイント
Cloud Infra Cost Field Solution を導入すると、組織は Databricks と関連クラウドインフラの支出を組み合わせた、信頼できる単一の TCO ビューを取得でき、プラットフォーム間での手動によるコスト調整の必要がなくなります。このソリューションを使用して回答できる質問の例は次のとおりです。
- クラウドプロバイダーとDatabricksにまたがる、私のDatabricks使用量のコスト内訳はどうなっていますか?
- VM、ローカルストレージ、ネットワークのコストを含め、ワークロードを実行するための総コストはいくらですか?
- ワークロードをサーバーレスで実行する場合と、従来のコンピューティングで実行する場合とでは、総コストにどのような違いがありますか
プラットフォームおよび FinOps チームは、Databricks 内で直接、ワークスペース、ワークロード、ビジネスユニットごとの全コストをドリルダウンできます。これにより、使用状況を予算、アカウンタビリティモデル、FinOps の実践に合わせることがはるかに簡単になります。基盤となるすべてのデータは管理されたテーブルとして利用できるため、チームはダッシュボードや社内アプリといった独自のコストアプリケーションを構築したり、Databricks Genie のような組み込み AI アシスタントを使用したりできます。これにより、知見生成が加速し、FinOps は定期的なレポーティング作業から常時稼働の運用機能へと変わります。
次のステップとリソース
今すぐ GitHub (linkは こちら) から Cloud Infra Cost Field Solution をデプロイし (AWS と Azure で利用可能)、Databricks の総支出に対する完全な可視性を獲得してください。完全な可視性を確保することで、インフラストラクチャ管理を自動化するserverlessの導入検討など、Databricks のコストを最適化できます。
このソリューションの一部として作成されるダッシュボードとパイプラインは、Databricks の支出を他のインフラストラクチャコストと合わせて分析し始めるための、迅速かつ効果的な方法を提供します。ただし、料金の割り当てと解釈は組織ごとに異なるため、ニーズに合わせてモデルと変換をさらに調整することができます。一般的な拡張には、アトリビューションの精度を向上させるためのインフラストラクチャ コスト データと追加の Databricks システム テーブル (AWS | AZURE | GCP) の結合、インスタンス プールを使用する際の共有 VM コストを分離または再割り当てするためのロジックの構築、VM 予約の異なる方法でのモデリング、長期的なコストの傾向をサポートするための履歴バックフィルの組み込みなどがあります。あらゆるハイパースケーラーのコストモデルと同様に、社内のレポーティング、タグ付け戦略、FinOps の要件に合わせて、デフォルトの実装を超えてパイプラインをカスタマイズする大きな余地があります。
Databricksのデリバリーソリューションアーキテクト(DSA)は、組織全体のデータとAIのイニシアチブを加速させます。彼らはアーキテクチャのリーダーシップを提供し、コストとパフォーマンスのためにプラットフォームを最適化し、開発者エクスペリエンスを向上させ、プロジェクトの実行を成功に導きます。DSAは、初期導入と本番レベルのソリューションとの間のギャップを埋め、データエンジニアリング、テクニカルリード、経営幹部、その他の利害関係者を含むさまざまなチームと緊密に連携して、カスタマイズされたソリューションと価値実現までの時間の短縮を保証します。DSAによるデータとAIのジャーニー全体にわたるカスタム実行計画、戦略的ガイダンス、サポートをご希望の場合は、Databricksアカウントチームにお問い合わせください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。