[ゲスト投稿:Tecton]レイクハウスにおけるリアルタイムの不正検知
本記事はパートナーであるTectonのゲスト投稿です。
不正行為の代償は計り知れない。 2022年には、不正行為の1つであるカード非携帯型不正行為が、米国だけで約60億ドルの損失をもたらした。 連邦取引委員会によると、米国における詐欺のトップ5は以下の通りである1:
- 偽者
- オンラインショッピング
- 賞品、懸賞、宝くじ
- 投資
- ビジネスと仕事の機会
すでに多くの企業が、リアルタイムの不正防止と検知を大規模に自動化するためにAIを活用し始めている。 しかし、これは詐欺師が絶えず新しい方法を考え出��し、発見をすり抜ける、猫とネズミのゲームなのだ。 AIモデルは常に進化し、最も新鮮なデータを入力として取り込む必要があるため、機能の鮮度とモデル開発のスピードが成功に不可欠となる。
このブログでは、Tecton on Databricksを活用してリアルタイム不正検知システムを構築するための主な方法をご紹介する。 最後に実際の例をいくつか挙げているので、読んでみてほしい!
MLフィーチャーパイプラインの拡張
不正は、膨大で大量のネットワーク(1秒間に何千ものトランザクションがあると考える)内で特に蔓延している。 このようなネットワークで不正を摘発するためには、企業は信頼性が高くスケーラブルなストレージとコンピュートを必要としている。 Databricks Data Intelligence Platformは優れたオプションであり、特にDelta Lakeは1万社以上の企業で使用され、1日あたりエクサバイトのデータを処理している。 MLモデル側では、MLflowのような機能がMLOpsを大規模に提供する。 Databricks Model Serving は、MLflow の機械学習モデルをスケーラブルな REST API エンドポイントとして公開し、モデルをデプロイするための高可用性かつ低レイテンシのサービスを提供します。 このサービスは、需要の変化に合わせて自動的にスケールアップまたはスケールダウンするため、レイテンシー・パフォーマンスを最適化しながらインフラコストを節約できる。 Databricksは、信頼性の高いストレージ、コンピュート、モデルデプロイメント、およびモニタリングのためのセキュアな環境を提供する。
2019年の設立以来、TectonはDatabricksと提携し、リアルタイムフィーチャーデータパイプラインという中核的な課題を解決することで、プロダクションスケールでのリアルタイム機械学習の機能を強化してきた。Tectonはフィーチャーアズコードを管理し、バッチ、ストリーミング、リアルタイムのデータソースにわたる変換とオンラインサービングからモニタリングまで、エンドツーエンドのMLフィーチャーパイプラインを自動化する。パイプライン全体は、DatabricksのコンピュートとDelta Lake上に構築される。
TectonとDatabricksを利用することで、データチームはMLモデルのTime-to-Valueを最大化し、本番環境でモデルの正確性と信頼性を確保し、コストを管理し、MLスタックの将来性を証明することができる。
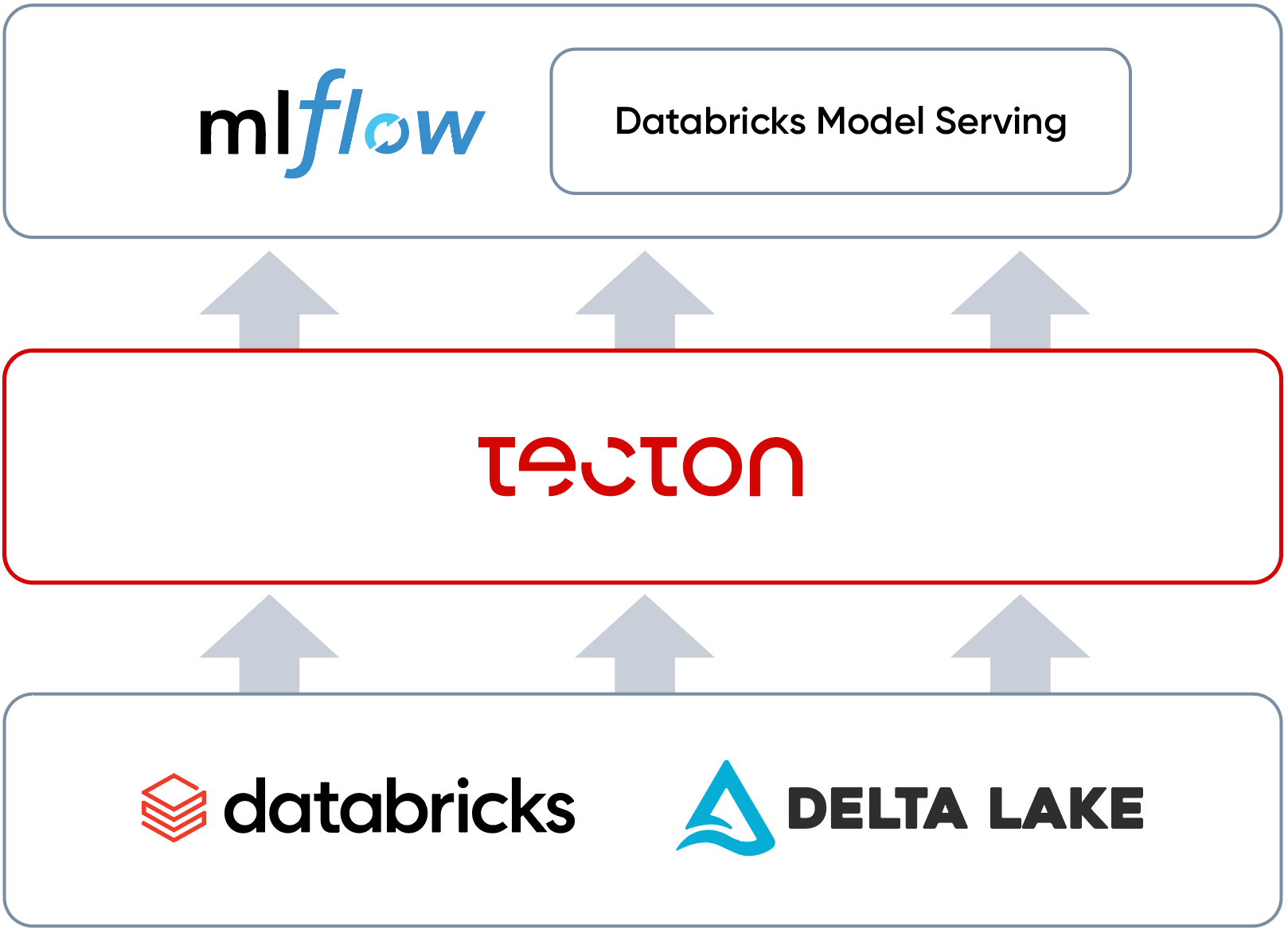
TectonをDatabricks上で使用し、リアルタイムの不正検知を実現
バッチ、ストリーミング、リアルタイムズMLの機能のアンロック
データインプットの鮮度が高ければ高いほど、不正行為を検出できる可能性が高まる。Databricksは、オープンソースのデータ標準を採用した大規模でスケーラブルなクラウドオブジェクトストレージにデータを保管し、Databricks Unity Catalogによって機密性の高い不正データへのアクセスを管理する。
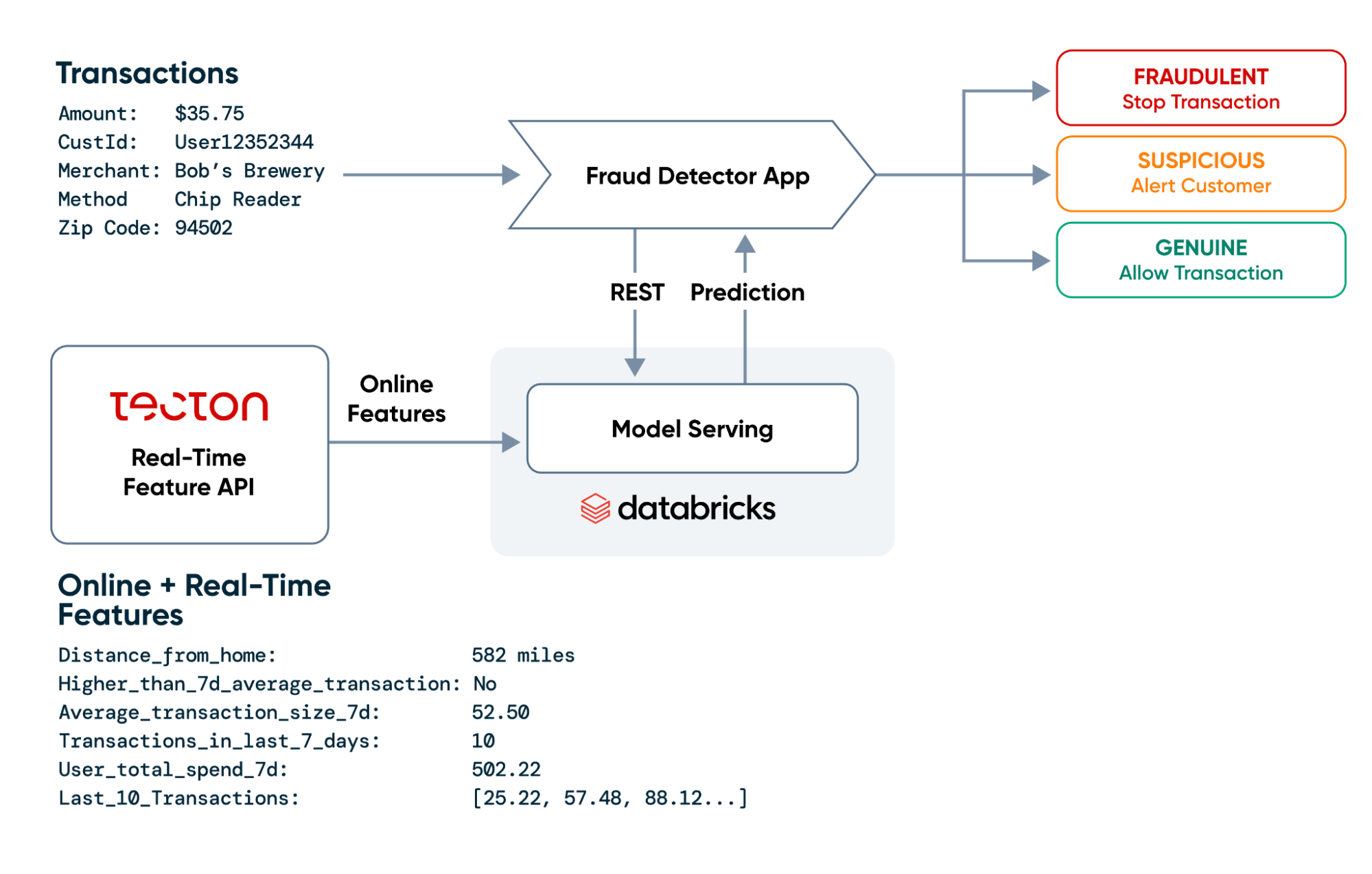
TectonはLakehouseの柔軟性を活用し、膨大な不正データセットの��特徴を計算する。クレジットカード詐欺を例にとると、Databricks上のTectonを使えば、最新のデータシグナルをML機能に注入するのが非常に簡単になる。ある顧客が過去1時間、1日、1週間に何件の取引を行ったかを知りたいかもしれない。このようなウィンドウ集約は、数行のコードで簡単に作成できる。さらに、オンデマンド機能は、推論時に提供されるデータを使って、機能をジャストインタイムで計算することができる。例えば、現在のトランザクションが、ある時間ウィンドウの平均しきい値より大きいか小さいかを判断するようなことができる。
MLフィーチャーを本番環境にデプロイする
データサイエンティストが不正検知モデルの新しいフィーチャーをいくつか開発し、本番環境で使用したいとする。Tectonで機能を定義すれば、ワンクリックでこれらの機能を本番稼動させることができる。Tectonは、最新の生データの取り込みを処理し、あなたが決定したスケジュールでフィーチャーに変換し、これらのフィーチャーをトレーニングやサービスに簡単に利用できるようにし、本番環境でのフィーチャーのパフォーマンスを監視する。テクトンはまた、コスト効率の高いパフォーマンスを最大化するために、特徴の計算と保存を最適化する。Tectonは、Delta LakeやDatabricksコンピュートなどのデータソースを活用している。
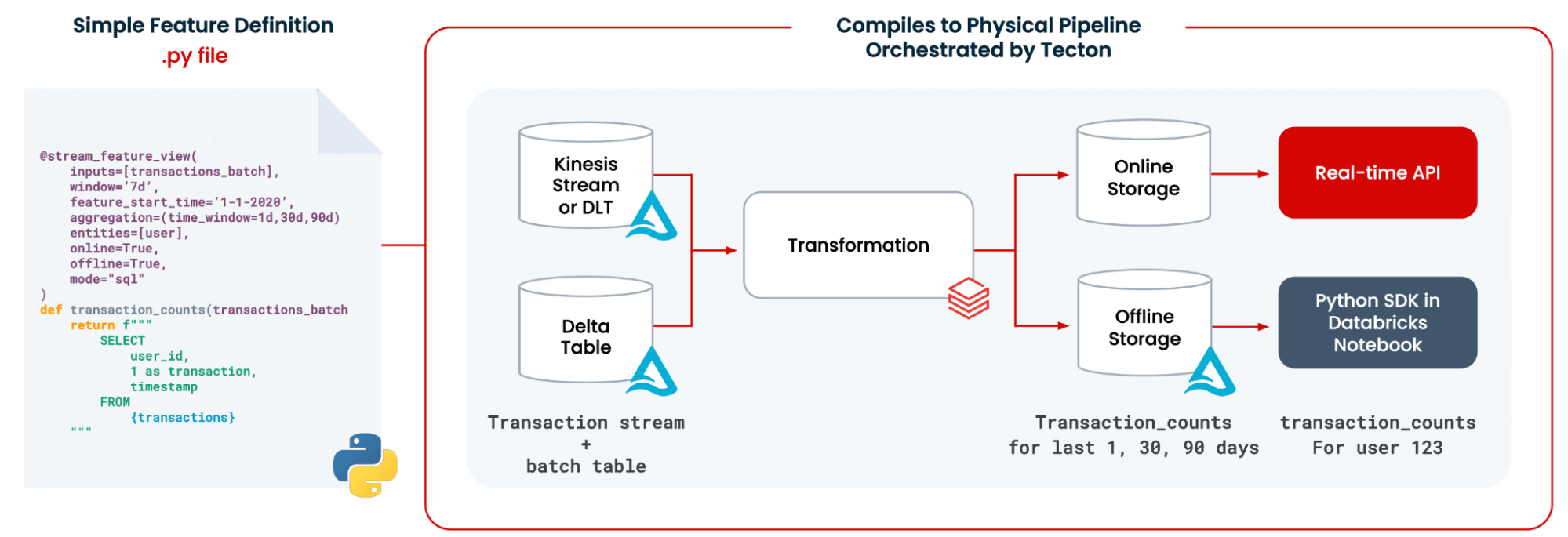
大規模なリアルタイム推論
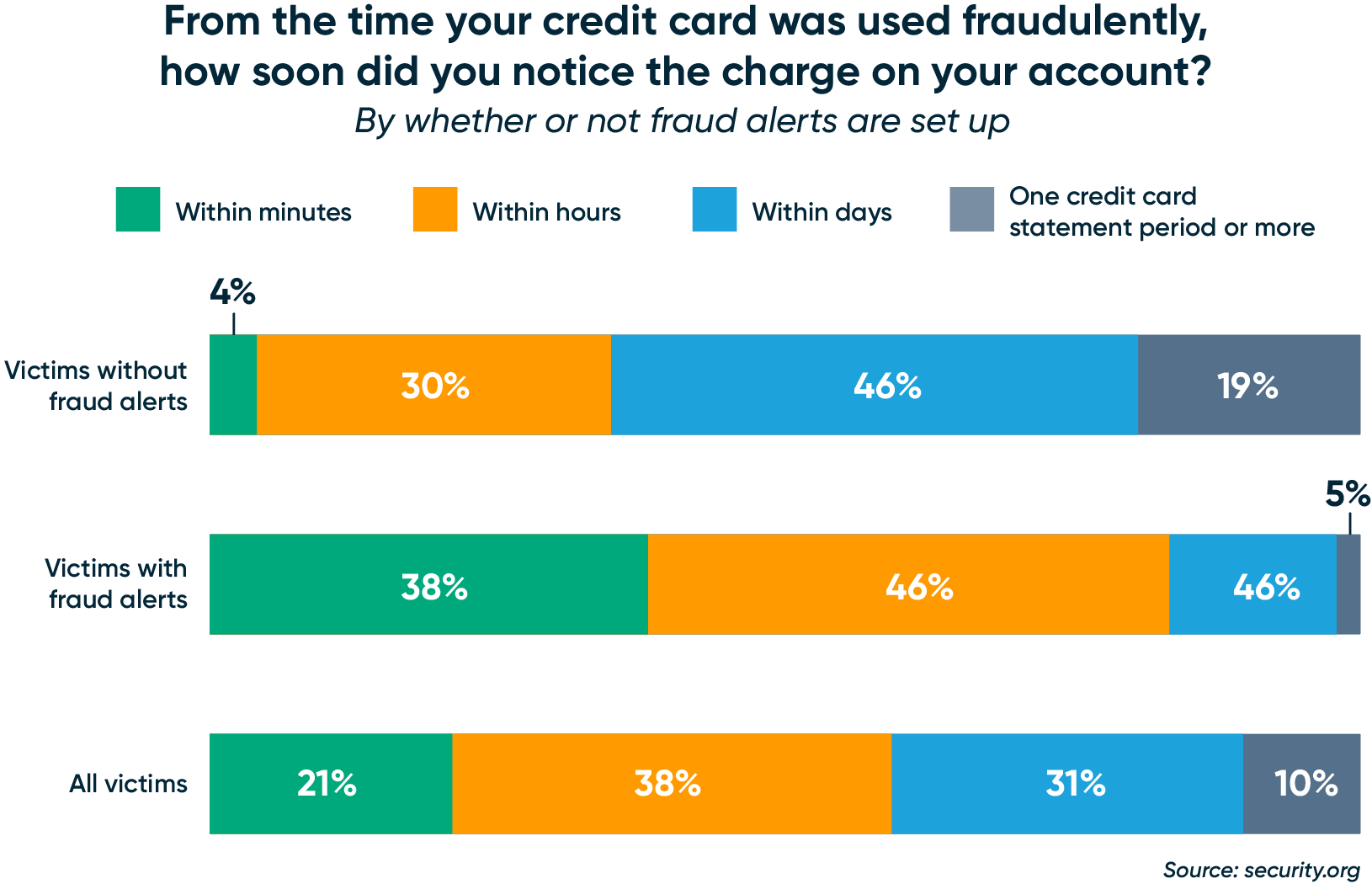
リアルタイム推論は、より多くの取引が発生する前に不正をキャッチするために不可欠である。米国では、クレジットカード詐欺だけで毎年110億ドル以上の損失が発生していることを考えると、詐欺が実際に発生した瞬間に捕捉することが極めて重要である。security.orgによると、タイムリーな詐欺アラートを提供するという単純な行為でさえ、顧客は(数日や数週間ではなく)数分や数時間以内に自分の口座の詐欺を発見することができた。
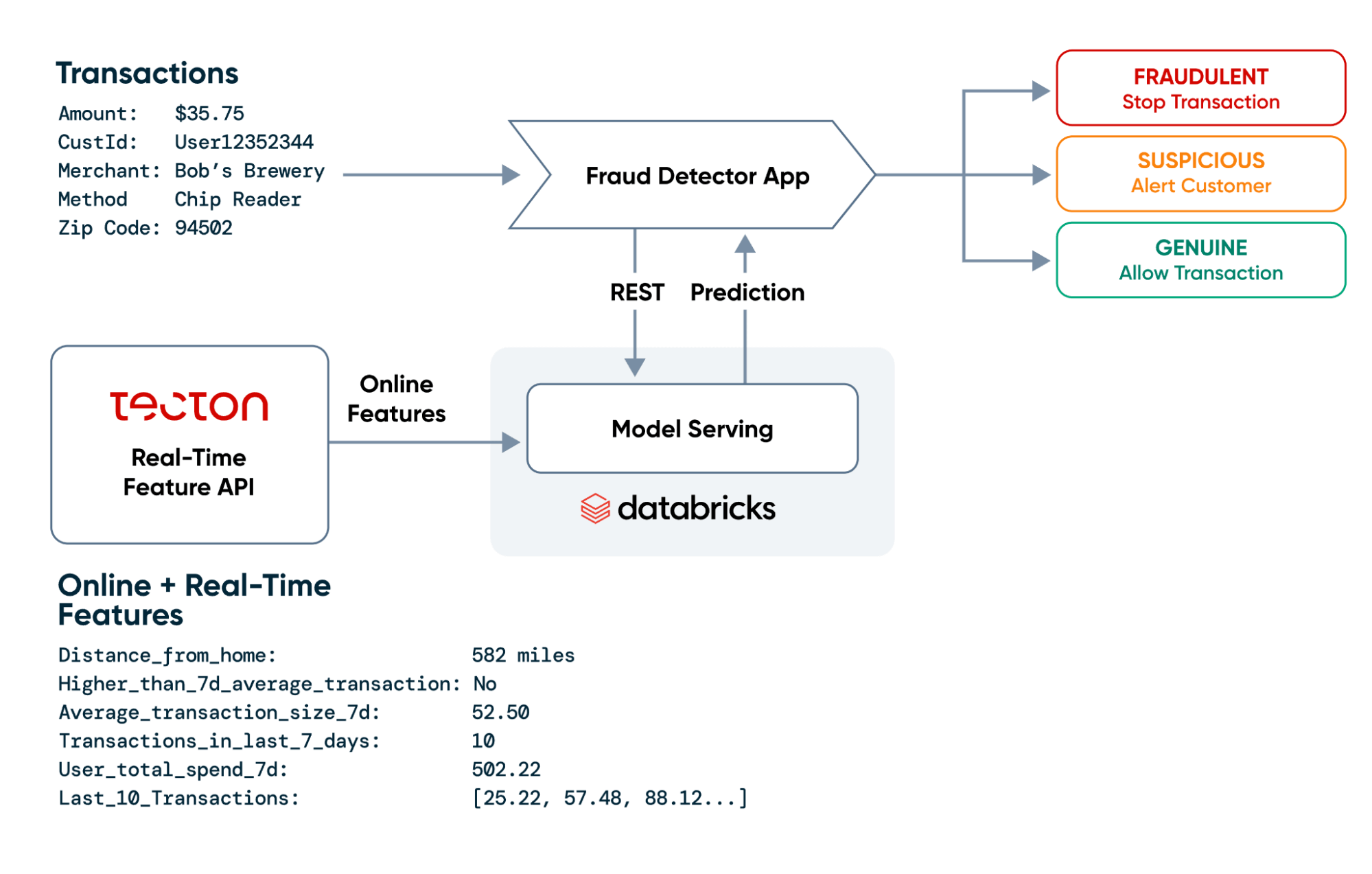
詐欺師の先を行くためには、不正検知モデルが、取引量の多い時期(休日など)でも、電光石火のスピードで意思決定できることを確認したい。Databricksのリアルタイムモデルサービングは、REST APIとしてMLモデルをデプロイするため、サービングインフラの管理に煩わされることなく、リアルタイムのMLアプリケーションを構築することができる。
TectonはDatabricksのリアルタイムモデルサービングとシームレスに統合し、Databricksのオンラインストアからリアルタイム機能を取得するためのセキュアなREST APIを提供する。Tecton自体は、エンタープライズ・セキュリティのベスト・プラクティスを採用しており、SOC 2 Type 2に準拠している。
{kind=link}
本番環境で複数のMLモデルを拡張する
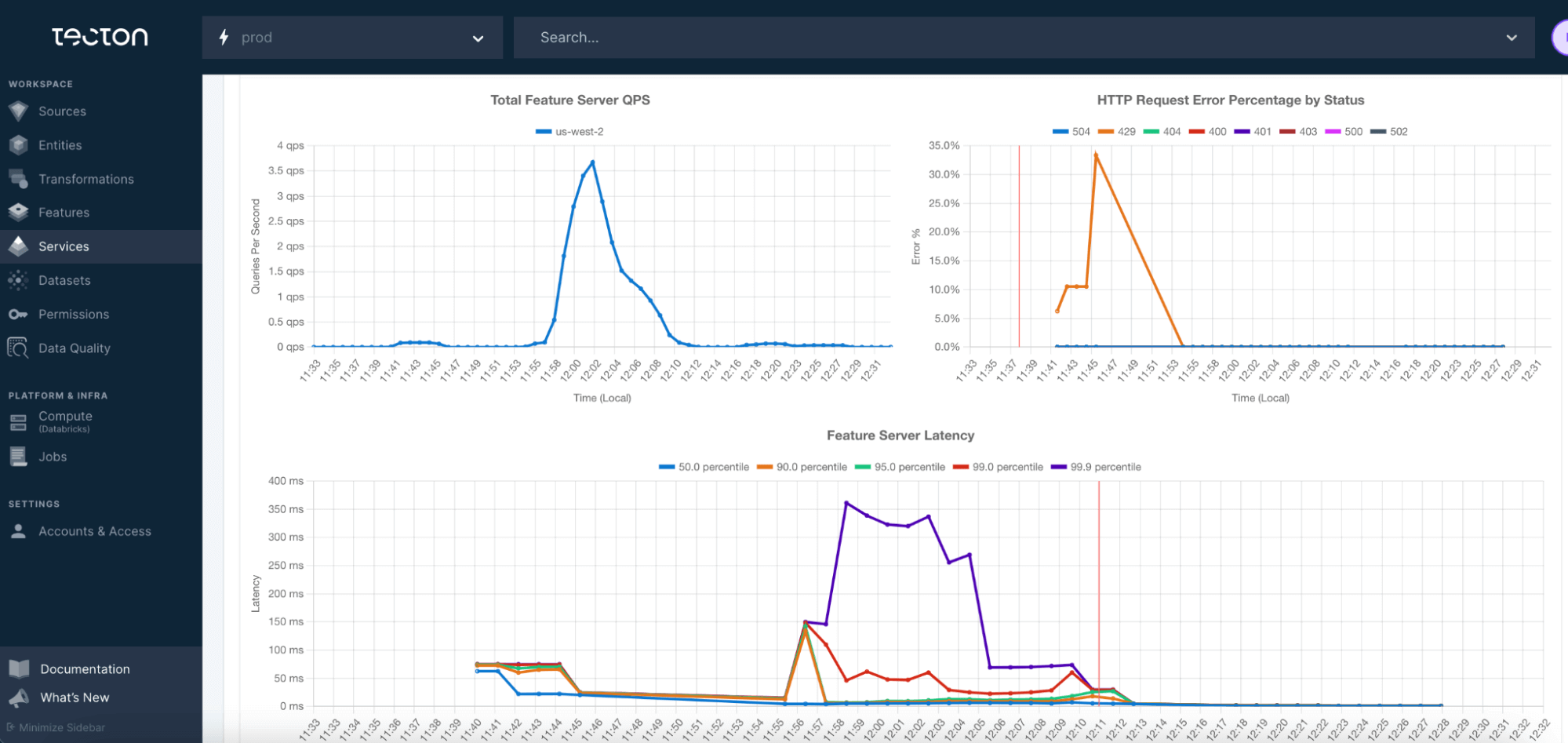
MLflow Model Registry と Databricks 上の Model Serving により、チームは複数のモデルを容易に反復し、最良の候補を本番環境に導入することができる。Tecton を使用することで、これらのモデルのいずれかに配信されたフィーチャーを簡単に管理し、オンライン ストアでの稼働時間やクエリ パフォーマンスを監視することができる。Tectonは、機能生成に宣言的な "Features-as-Code "アプローチを採用しているため、ユーザーは、次のモデル反復のニーズを満たすために、既存の機能を簡単に修正・拡張することができる。
{kind=link}
Databricks上でのTectonの使用方法についてご興味がおありですか?
Tectonのドキュメントをチェッ��クするか、hello@tecton.aiにメールを送ってください。
Databricksでリアルタイムの不正検出のためのフィーチャ開発とモデルのトレーニングを行う方法を示すサンプルNotebook については、このgithubリンクにアクセスするか、サンプルNotebook をご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。