Delta Lakeとの統合でデータエコシステムを統一する
Databricks以外のプラットフォームからDelta Lakeへの読み書きを行う
によって Itai Yaffe 、 リラン・バレケット による投稿
Original : Unifying Your Data Ecosystem with Delta Lake Integration
翻訳: junichi.maruyama
組織がデータインフラを成熟させ、データレイクにこれまで以上に多くのデータを蓄積していく中で、Delta Lakeのようなオープンで信頼性の高いテーブルフォーマットは非常に必要になってきます。
すでに何千もの企業が本番でDelta Lakeを使用しており、(2022年6月に発表された)Delta Lakeのすべてをオープンソース化したことで、さまざまなドメインや垂直方向での採用がさらに進んでいます。
それらの企業の多くは、Databricksとその他のデータおよびAIフレームワーク(Power BI、Trino、Flink、Spark on Kubernetesなど)の両方を技術スタックの一部として使用しているため、それらすべてのフレームワークを使用してDelta Lakeから/への読み取りと書き込みができることが極めて重要です。
このブログ記事の目標は、これらのユーザーができるだけシームレスにそうできるようにすることです。
統合オプション
Databricksは、Lakehouseからデータを読み込み、Lakehouseにデータを書き込むための複数のオプションを提供します。これらのオプションは、様々なパラメータで互いに異なります。これらのオプションは、それぞれ異なるユースケースにマッチしています。
これらのオプションを評価するために使用するパラメータは次のとおりです:
- Read Only/Read Write - このオプションは、読み取り/書き込みアクセスを提供するか、読み取りのみを提供するか。
- 先行投資 - この統合オプションは、カスタム開発または別のコンポーネントのセットアップを必要とするか。
- 実行オーバーヘッド - このオプションでは、データとクライアントアプリケーションの間にコンピュートエンジン(クラスタまたはSQLウェアハウス)が必要か。
- コスト - このオプションは、(ストレージとクライアントの運用コスト以外の)追加コストを伴うか。
- カタログ - このオプシ�ョンは、クライアントがデータ資産を参照し、メタデータを取得するために使用できるカタログ(Hive Metastoreなど)を提供するか。
- ストレージへのアクセス - クライアントがクラウドストレージに直接ネットワークでアクセスする必要があるかどうか。
- スケーラビリティ - このオプションは、クライアントでスケーラブルなコンピューティングに依存するか、クライアントのためにコンピューティングを提供するか。
- 同時書き込みサポート - このオプションは、複数のクライアントからの書き込み、またはクライアントとDatabricksからの同時書き込みを可能にする、同時書き込みを処理しますか。(Docs)
クラウドストレージへの直接アクセス
クラウドストレージのファイルに直接アクセスする Databricks Unity Catalog(UC)の外部テーブル(AWS/Azure/GCP)には、テーブルのパスを使用して直接アクセスすることができます。そのためには、クライアントがパスを保存し、ストレージへのネットワークパスを持ち、ストレージに直接アクセスする権限を持っていることが必要です。
a. Pros
- 先行投資が不要(スクリプトやツールは不要)
- 実行オーバーヘッドがない
- 追加費用なし
b. Cons
- カタログなし - 開発者がロケーションを登録・管理する必要がある
- ディスカバリー機能なし
- メタデータの制限(デルタテーブル以外はメタデータなし)
- ストレージへのアクセスが必要
- ガバナンス機能がない
- テーブルACLはありません: ファイル/フォルダレベルでパーミッションを管理する
- 監査なし
- 同時書き込み対応に制限あり
- スケーラビリティを内蔵していない - 大規模なデータセットの場合、読み取りアプリケーションでスケーラビリティを処理する必要がある
c. Flow:
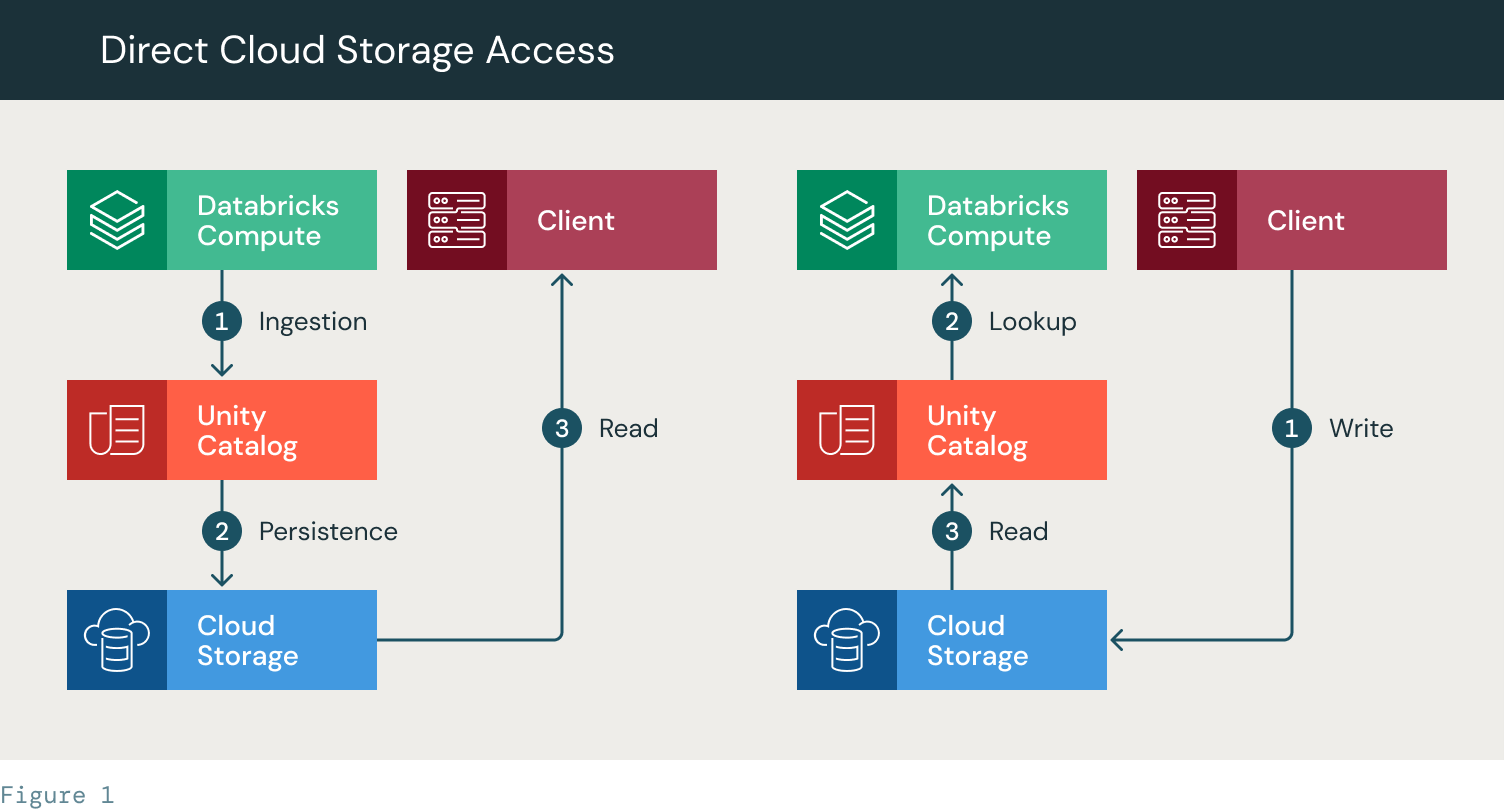
- Read:
- データブリックがインジェストを行う(1)
- Unity Catalogで定義されたテーブルにファイルを永続化します。クラウドストレージに永続化される(2)
- クライアントには、テーブルへのパスが提供されます。クライアントは、自身のストレージ認証情報(SPN/インスタンスプロファイル)を使用してクラウドストレージに直接アクセスし、テーブル/ファイルを読み取ります。
- Write:
- クライアントはパスを用いてクラウドストレージに直接書き込む。その後、パスはUCでテーブルを作成するために使用されます。このテーブルはDatabricksで読み取り操作に利用できます。
外部Hiveメタストア(双方向同期)
このシナリオでは、Unity CatalogのメタデータをGlueなどの外部のHive Metastore(HMS)と定期的に同期しています。1つまたは複数のデータベースを外部のディレクトリと同期させておきます。これにより、Hiveをサポートするリーダーを使用するクライアントがテーブルにアクセスできるようになります。前のソリューションと同様に、クライアントがストレージに直接アクセスできることが必要です。
a. Pros
- カタログは、テーブルのリストを提供し、場所を管理します。
- テーブルの閲覧や検索が可能なディスカバリー性
b. Cons
- 初期設定が必要
- ガバナンスのオーバーヘッド - このソリューションでは、アクセスに関する冗長な管理が必要です。UCはテーブルACLに依存し、Hive Metastoreはストレージアクセス許可に依存します。
- Hive MetastoreのメタデータをUnity Catalogのメタデータと最新の状態に保つためのカスタムスクリプトが必要です。
- 同時書き込み対応に制限あり
- スケーラビリティを内蔵していない - 大規模なデータセットの場合、読み取りアプリケーションでスケーラビリティを処理する必要がある
c. Flow:
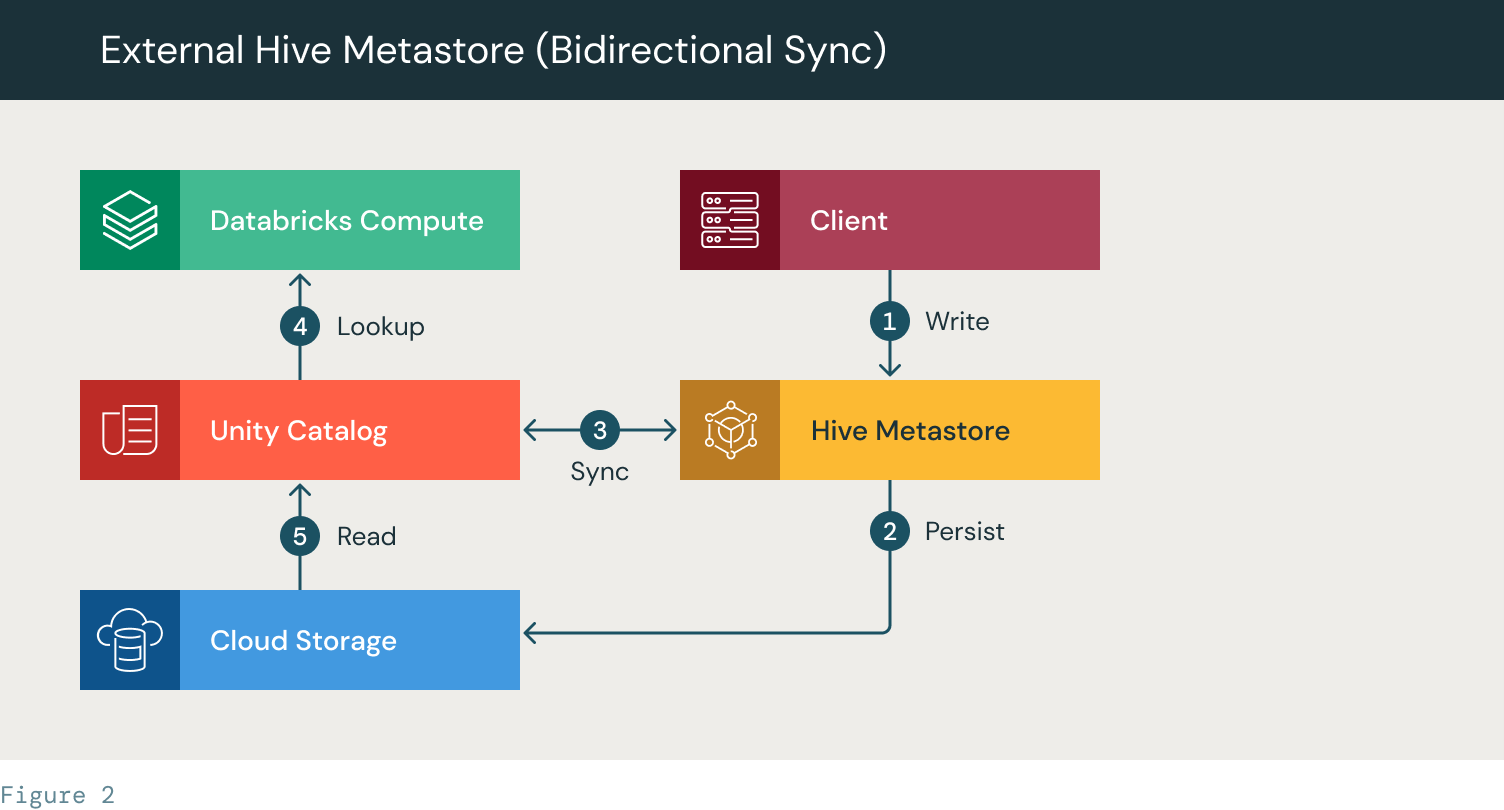
- クライアントがHMSにテーブルを作成する
- テーブルをクラウドストレージに永続化する
- HMSとUnity Catalogの間でテーブルのメタデータを同期するSyncスクリプト(カスタムスクリプト)。
- Databricksクラスタ/SQLウェアハウスが、UCでテーブルを検索する。
- 表ファイルは、クラウドストレージからUCを使ってアクセスします
Delta Sharing
デルタ共有を通じてデルタテーブルにアクセスします(デルタ共有の詳細についてはこちらをご覧ください)。
データプロバイダーは既存のデルタテーブルの共有を作成し、データ受信者は共有構成内で定義されたデータにアクセスすることができます。共有されたデータは常に最新の状態に保たれ、ストリーミングを含むリアルタイム/ニアリアルタイムのユースケースをサポートします。
一般的に、データ受信者は、デルタ共有クライアント(様々なツールでサポートされています)を介して、デルタ共有サーバーに接続します。デルタ共有クライアントとは、デルタ共有ソースからの直接読み込みをサポートするあらゆるツールのことです。署名されたURLがデルタ共有クライアントに提供され、クライアントはそれを使ってデルタテーブルのストレージに直接アクセスし、アクセスを許可されたデータのみを読みます。
データ提供側では、このアプローチにより、ストレージレベルでの権限管理の必要性がなくなり、(共有レベルでの)特定の監査機能が提供されます。
データ受信者側では、前述のツールのいずれかを使用してデータを消費するため、受信者側で計算��のスケーラビリティを処理する必要があります(例:Sparkクラスタを使用する)。
a. Pros
- カタログ+ディスカバビリティ
- ストレージへのアクセス権を必要としない(共有レベルで行われる)
- 監査機能を提供する(限定的ではあるが、シェアレベルであるため)
b. Cons
- 読み取り専用
- スケーラビリティを自前で処理する必要がある(Sparkを使うなど)
i. Flow:
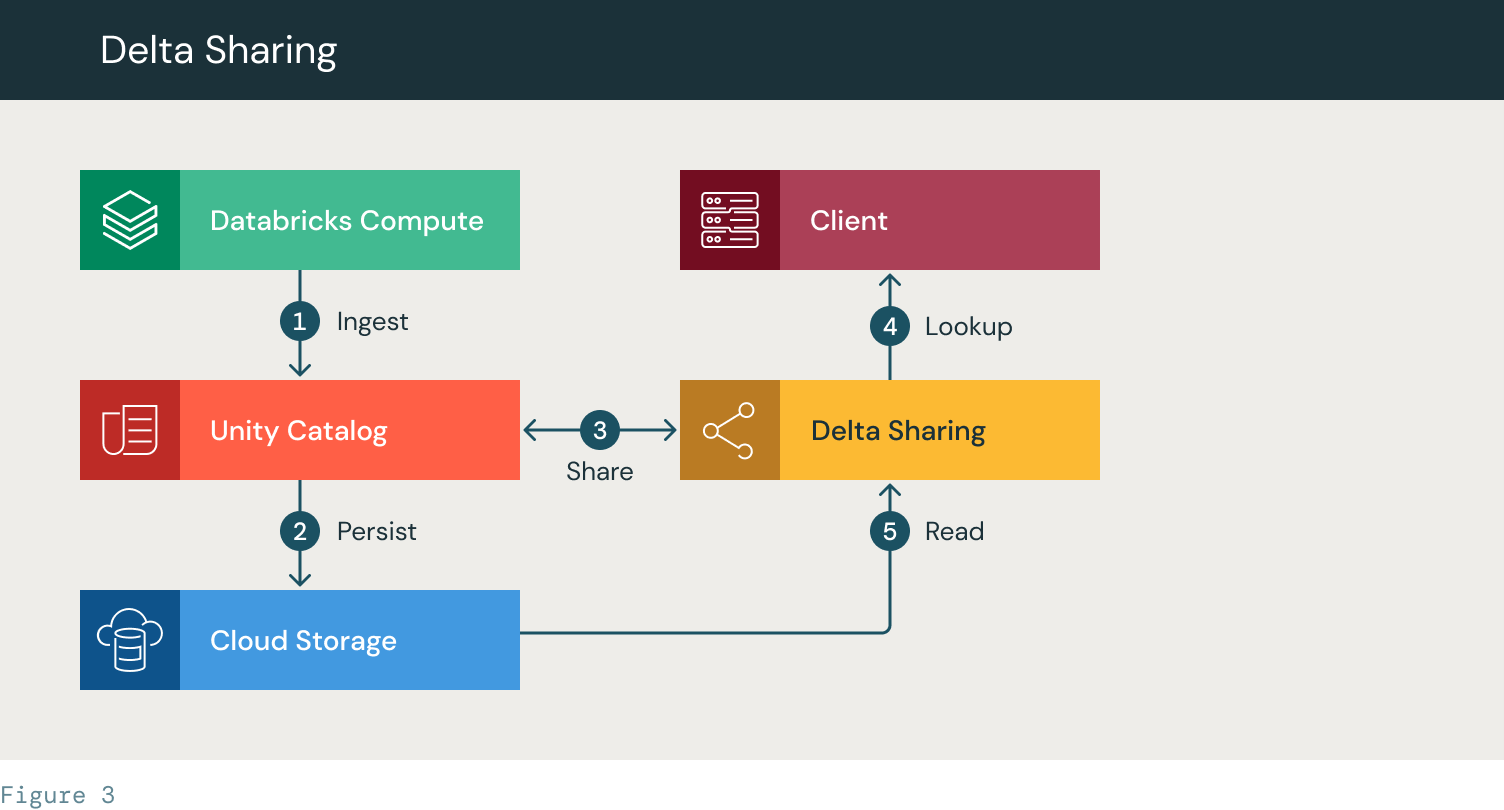
- Databricksがデータを取り込み、UCテーブルを作成する。
- データはクラウドストレージに保存されます
- Delta Sharingプロバイダが作成され、テーブル/データベースが共有されます。アクセストークンがクライアントに提供される
- クライアントは、Delta Sharingサーバーにアクセスし、テーブルを検索します。
- クライアントは、クラウドストレージからテーブルファイルを読み取るためのアクセス権を提供されます。
JDBC/ODBCコネクタ(Databricks SQLを使用してどこからでも書き込み/読み取りが可能)
JDBC/ODBC コネクタを使用すると、JDBC/ODBC を使用してバックエンドアプリケーションを Databricks SQL warehouse に接続することができます(ここで説明します)。
これは基本的に、バックエンドアプリケーションをデータベースに接続する際に通常行うことと変わりません。
Databricks といくつかのサードパーティ開発者は、JDBC/ODBC コネクタのラッパーを提供しており、以下のような様々な環境から直接アクセスできるようになっています:
このソリューションは、計算能力が Databricks SQL ウェアハウスであるため、スタンドアローンクライアントに適しています(したがって、計算のスケーラビリティは Databricks によって処理されます)。
Delta Sharingアプローチとは対照的に、JDBC/ODBCコネクタアプローチでは、Deltaテーブルへのデータ書き込みが可能です(同時書き込みもサポート)。
a. Pros
- スケーラビリティはDatabricksが担当します。
- 完全なガバナンスと監査
- 簡単なセットアップ
- 同時書き込み対応(Docs)
b. Cons
- コスト
- スタンドアローンクライアントに適している(Sparkのような��分散実行エンジンにはあまり向いていない)
l. Workflow:
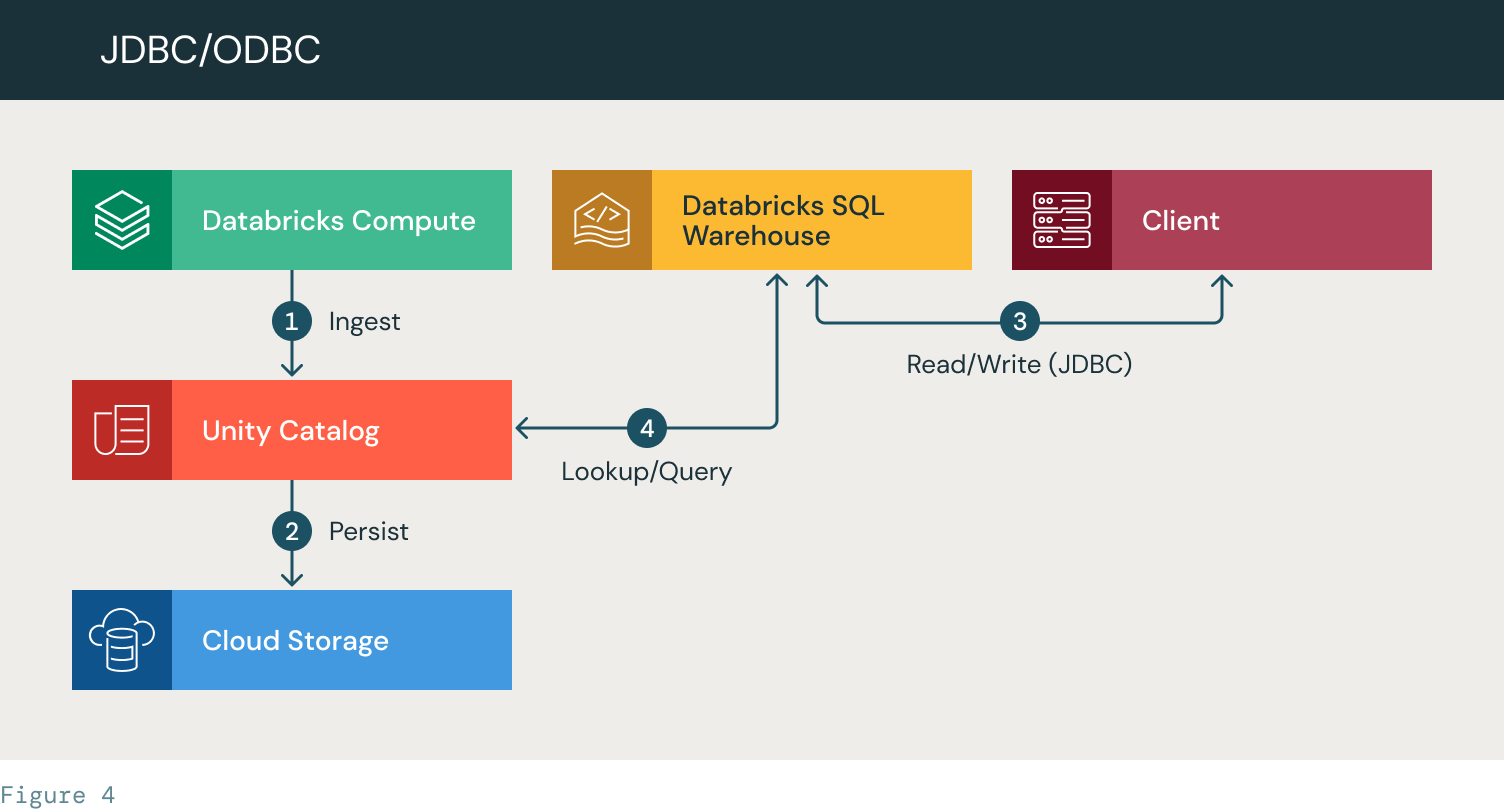
- Databricksがデータを取り込み、UCテーブルを作成する。
- データはクラウドストレージに保存されます
- クライアントは、JDBC接続を使用して認証し、SQLウェアハウスに問い合わせます。
- SQLウェアハウスは、Unity Catalogでデータを検索します。ACLを適用し、データにアクセスし、クエリを実行し、結果セットをクライアントに返します。
c. ワークスペース上でUnity Catalogを有効にしている場合、操作の完全なガバナンスと監査も得られることに注意してください。Unity Catalogを使用しない場合でも、上記のアプローチを使用することはできますが、ガバナンスと監査は制限されます。
d. 行レベルのフィルタリングと列のフィルタリングをサポートする唯一のオプションです。
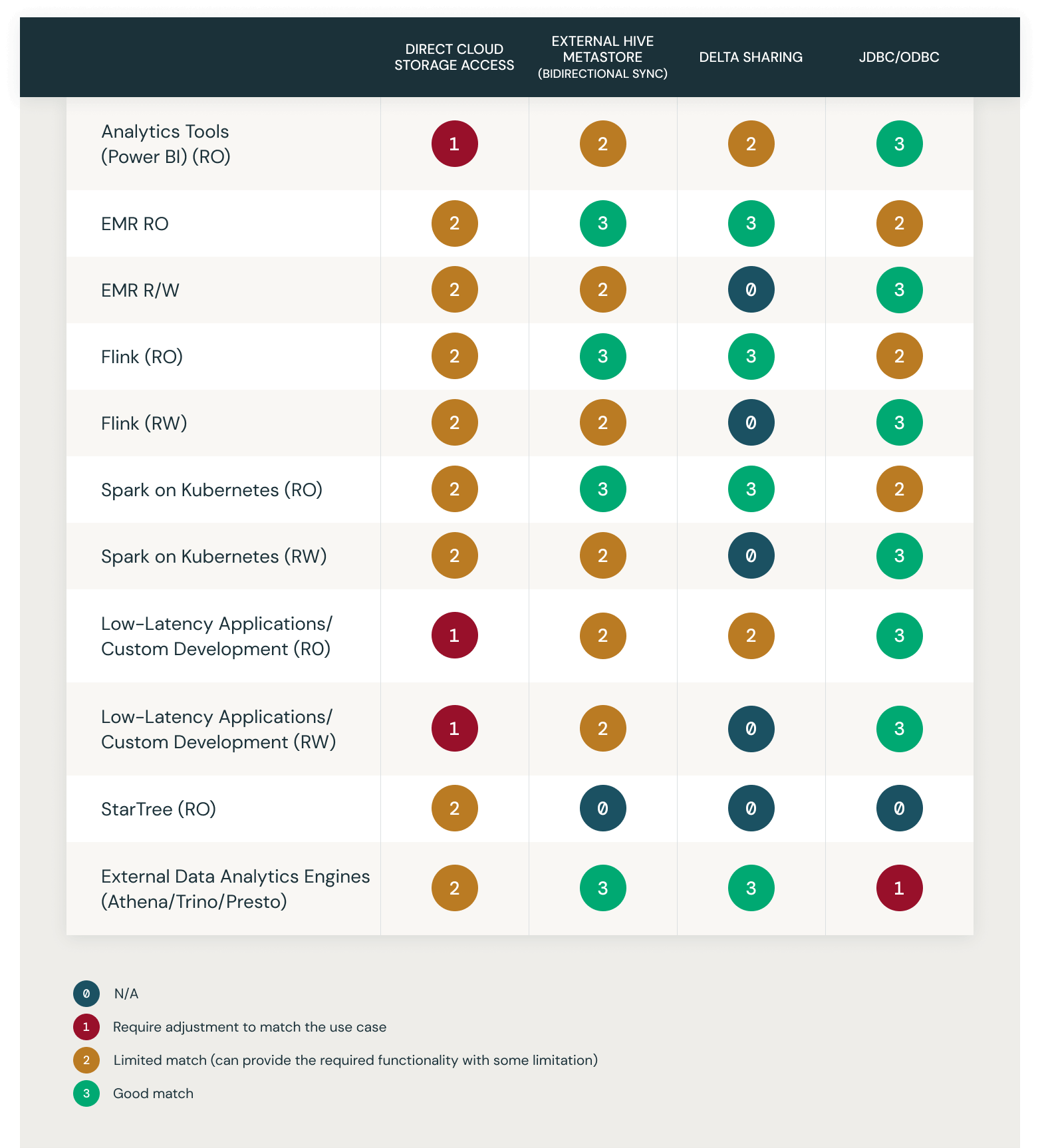
統合オプションとユースケースのマトリックス
この表は、一般的なユースケースを抜粋して、上記のソリューションの選択肢の適合性を示したものです。0~4で評価されています:
- 0 - N/A
- 1 - ユースケースに合わせた調整を要求する
- 2 - リミテッドマッチ(必要な機能をある程度制限して提供することができる)
- 3 - グッドマッチ
Review Documentation
https://docs.databricks.com/integrations/jdbc-odbc-bi.html
https://www.databricks.com/product/delta-sharing
https://docs.databricks.com/sql/language-manual/sql-ref-syntax-aux-sync.html
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。