Delta LakeとApache SparkにおけるVariantデータ型の導入
半構造化データ処理の高速化と柔軟性の向上
によって Kent Marten, ジーン・パン, 李 晨浩 、 ハン・シャオ による投稿
半構造化データ用の新しいデータ型であるVariantを発表できることを嬉しく思います。Variantは、JSON文字列として保存する場合と比較して、オーダーマグニチュードのパフォーマンス向上を実現しつつ、高度にネストされたスキーマや進化するスキーマをサポートする柔軟性を維持します。
半構造化データとの連携は、これまでもLakehouseの基本的な機能でした。Endpoint Detection & Response (EDR)、広告クリック分析、IoTテレメトリなどは、半構造化データに依存する一般的なユースケースの一部です。プロプライエタリなデータウェアハウスから移行するお客様が増えるにつれて、お客様はそれらのプロプライエタリなウェアハウスが提供するVariantデータ型に依存しており、ロックインを避けるためにオープンソースの標準を求めているという声を耳にしてきました。
オープンVariant型は、Apache SparkオープンソースコミュニティとLinux Foundation Delta Lakeコミュニティとの協力の成果です。
- Variantデータ型、Variantバイナリ式、およびVariantバイナリエンコーディング形式は、すでにオープンソースSparkにマージされています。バイナリエンコーディングの詳細については、こちらで確認できます。
- バイナリエンコーディング形式により、文字列と比較してデータのアクセスとナビゲーションが高速になります。Variantバイナリエンコーディング形式の実装は、オープンソースライブラリにパッケージ化されているため、他のプロジェクトでも使用できます。
- Variantデータ型へのサポートもDeltaにオープンソース化されており、プロトコルRFCはこちらで見つけることができます。VariantサポートはSpark 4.0およびDelta 4.0に含まれる予定です。
「私たちは、オープンソースのデータプラットフォームであるLegendを通じて、データに焦点を当てたオープンソースコミュニティを支援しています」と、Goldman SachsのCDO兼Data Engineering責任者であるNeema Raphael氏は述べています。「SparkにおけるオープンソースVariantのリリースは、オープンなデータエコシステムにとって、また一歩前進する素晴らしい機会です。」
そして、DBR 15.3から、上記のすべての機能がお客様にご利用いただけるようになります。
Variantとは?
Variantは、半構造化データを保存するための新しいデータ型です。Databricks Runtime 15.3のパブリックプレビューでは、JSONを介した階層データの入出力がサポートされます。Variantがない場合、お客様は柔軟性とパフォーマンスのどちらかを選択する必要がありました。柔軟性を維持するために、お客様はJSONを文字列として単一の列に保存していました。パフォーマンスを向上させるために、お客様はstructを使用した厳密なスキーマ化アプローチを適用していましたが、これはスキーマ変更の維持と更新のために別途プロセスが必要でした。Variantを使用すると、お客様は柔軟性(明示的なスキーマを定義する必要がない)を維持し、JSONを文字列としてクエリする場合と比較して大幅にパフォーマンスが向上します。
Variantは、JSONソースのスキーマが不明、変更される、または頻繁に進化する場合に特に役立ちます。たとえば、お客様はEndpoint Detection & Response (EDR) のユースケースを共有しており、異なるJSONスキーマを含むログを読み取って結合する必要がありました。同様に、スキーマが不明で常に変更される広告クリックやアプリケーションテレメトリに関連するユースケースでは、Variantが適しています。どちらの場合も、Variantデータ型の柔軟性により、明示的なスキーマを必要とせずにデータを効率的に取り込むことができます。
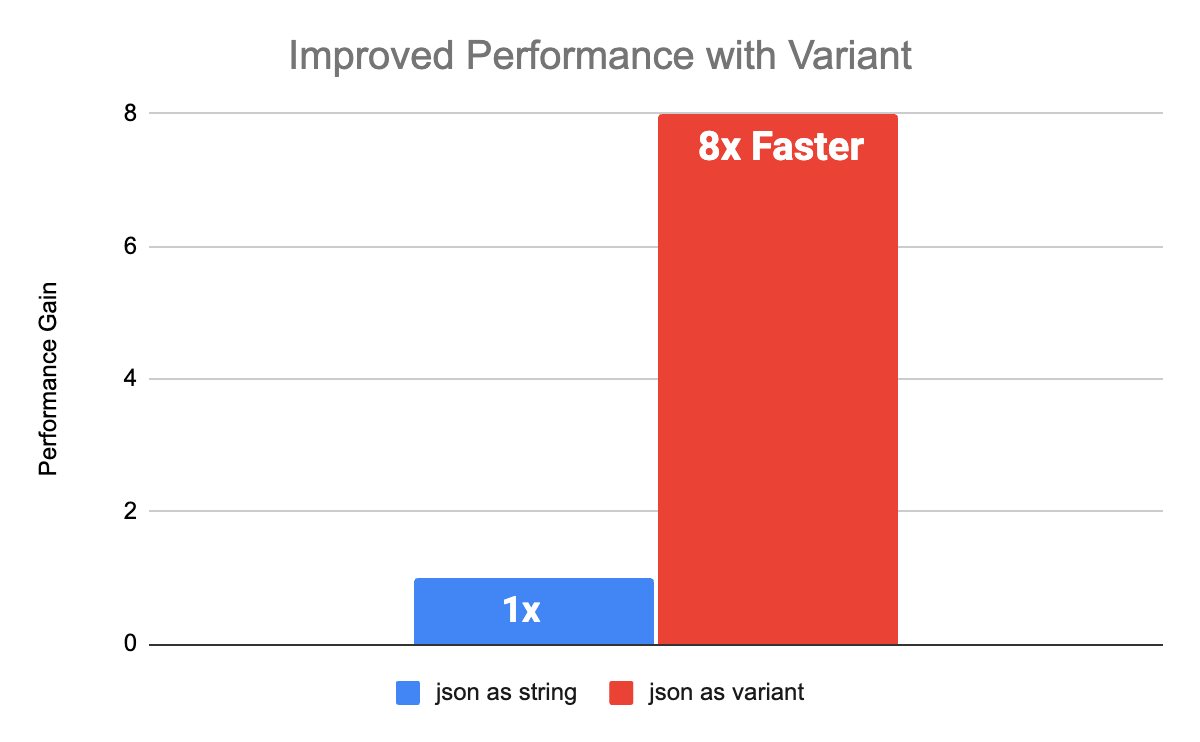
パフォーマンスベンチマーク
Variantは、JSONを文字列として維持する既存のワークロードよりもパフォーマンスが向上します。お客様のデータにインスパイアされたスキーマを使用して、文字列とVariantのパフォーマンスを比較する複数のベンチマークを実行しました。ネストされたスキーマとフラットなスキーマの両方で、Variantを使用したパフォーマンスは文字列列よりも8倍向上しました。ベンチマークは、Photonが有効化されたDatabricks Runtime 15.0で実施されました。
Variantの使用方法
Variant型をサポートするための新しい関数がいくつかあり、これらを使用すると、Variantのスキーマを検査したり、Variant列を展開したり、JSONに変換したりできます。PARSE_JSON()関数は、JSON文��字列入力を表すVariant値を返すためによく使用されます。
Variantデータをロードするには、Variant型のテーブル列を作成できます。PARSE_JSON()関数を使用して、JSON形式の文字列をVariantに変換し、Variant列に挿入できます。
CTASを使用して、Variant列を持つテーブルを作成できます。作成されるテーブルのスキーマは、クエリ結果から派生します。したがって、Variant列を持つテーブルを作成するには、クエリ結果にVariant列が出力スキーマに含まれている必要があります。
COPY INTOを使用して、Variant列を1つ以上持つテーブルにJSONデータをコピーすることもできます。
パスナビゲーションは、直感的なドット表記構文に従います。
完全にオープンソース化され、プロプライエタリなデータロックインなし
まとめましょう:
- Variantデータ型、バイナリ式、およびバイナリエンコーディング形式は、すでにApache Sparkにマージされています。バイナリエンコーディング形式は、こちらで詳細を確認できます。
- バイナリエンコーディング形式は、文字列と比較してデータのアクセスとナビゲーションを高速化するものです。バイナリエンコーディング形式の実装は、オープンソースライブラリにパッケージ化されているため、他のプロジェクトでも使用できます。
- Variantデータ型へのサポートもDeltaにオープンソース化されており、プロトコルRFCはこちらで見つけることができます。VariantサポートはSpark 4.0およびDelta 4.0に含まれる予定です。
さらに、Variant型のシュレッディング/サブカラム化を実装する計画があります。シュレッディングは、Variantデータ内の特定のパスのクエリパフォーマンスを向上させるための技術です。シュレッディングにより、パスを独自の列に格納でき、そのパスをクエリするために必要なIOと計算を削減できます。シュレッディングは、不要な追加作業を回避するためのデータプルーニングも可能にします。シュレッディングはApache SparkとDelta Lakeでも利用可能になります。
今年のDATA + AI Summit(6月10~13日、サンフランシスコ)に参加されますか?
「Variant Data Type - Making Semi-Structured Data Fast and Simple」にご参加ください。
VariantはDatabricks Runtime 15.3のパブリックプレビューでデフォルトで有効になり、DBSQLプレビューチャネルでも間もなく利用可能になります。半構造化データユースケースをテストし、考えや質問があればDatabricks Communityフォーラムで議論を開始してください。コミュニティの皆様のご意見をお待ちしております!
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。