Lakeflow Connect:SQL Server コネクタによる効率的で簡単なデータ取り込み
Databricks Lakeflow Connect のフルマネージドな SQL Server コネクタを活用し、データの取り込みと統合をシンプルに。Databricks のデータ処理・分析ツールとシームレスに連携できます。
によって Andrea Tardif, Prasanna Selvaraj, エクトル・ブスタマンテ 、 Phanitha Kommareddi による投稿
- 先進的なテクノロジー企業の多くは、SQL Server のデータを AI や分析に活用するうえで、複雑な課題に直面しています。
- Lakeflow Connect for SQL Server は、オンプレミスとクラウドの両方のデータベースに対応し、効率的な増分データ取り込みを実現します。
- 本ブログでは、SQL Server のデータをレイクハウスに取り込むためのアーキテクチャの検討ポイント、前提条件、具体的な設定手順について解説します。
SQL Serverデータの抽出の複雑さ
デジタルネイティブ企業は、イノベーションを推進するうえで AI が極めて重要であることを理解していますが、機械学習開発や高度分析などの下流用途にデータをすぐ活用できる状態にするには、いまだに多くの課題があります。こうした企業で SQL Server を利用するビジネス部門を支えるには、データエンジニアリングのリソース確保やカスタムコネクタの保守、分析用データの整備、さらにはモデル開発チームへのデータ提供が欠かせません。多くの場合、この�データは他ソースの情報でリッチ化・変換したうえで、意思決定に役立てられます。
しかし、こうしたプロセスはすぐに複雑化・脆弱化し、イノベーションの速度を鈍らせてしまいます。そこで Databricks は、主要なデータベース、エンタープライズアプリケーション、ファイルソース向けに組み込みコネクタを備えた Lakeflow Connect を開発しました。これらのコネクタはエンドツーエンドで効率的な増分取り込みを実現し、柔軟で簡単にセットアップできるうえ、ガバナンス・可観測性・オーケストレーションを統合した Databricks Data Intelligence Platform に完全に組み込まれています。新しい Lakeflow SQL Server コネクタ は、オンプレミスとクラウドの両方のデータベースを強力にサポートする初のデータベースコネクタで、Databricks 内でのデータ活用を加速します。
本ブログでは、SQL Server で Lakeflow Connect を利用すべきシーンの主な検討ポイントを整理し、Azure SQL Server インスタンスからデータを複製するためのコネクタ設定手順を解説します。さらに、具体的なユースケースやベストプラクティス、導入の進め方もご紹介します。
主要なアーキテクチャ上の考慮事項
以下は、SQL Serverコネクタを使用するタイミングを決定するための主要な考慮事項です。
リージョンと機能の互換性
Lakeflow Connect は Microsoft Azure SQL Database、Amazon RDS for SQL Server、Azure VM や Amazon EC2 上で稼働する Microsoft SQL Server、さらに Azure ExpressRoute や AWS Direct Connect を経由してアクセスするオンプレミス版 SQL Server など、幅広い SQL Server 系データベースに対応しています。
Lakeflow Connect は内部的に サーバーレス・パイプライン 上で動作するため、パイプラインの可観測性、イベントログのアラート、レイクハウスのモニタリングといった組み込み機能をそのまま活用できます。お使いのリージョンでサーバーレスが未対応の場合は、Databricks アカウントチームと連携して開発・展開を優先してもらえるようリクエストを提出してく��ださい。
Lakeflow Connect は Databricks Data Intelligence Platform 上に構築されており、Unity Catalog (UC) とシームレスに統合されます。既存の権限設定やアクセス制御を新しい SQL Server ソースにもそのまま再利用できるため、一元的なガバナンスが実現します。Databricks のテーブル/ビューを Hive メタストアで運用している場合は、これらの機能を最大限に活かすため UC への移行(AWS | Azure | GCP)を推奨します。
データ要件の変更
Lakeflow Connect は、Microsoft Change Tracking(CT) または Change Data Capture(CDC) を有効にした SQL Server と連携することで、効率的な増分データ取り込みに対応します。
CDC は、テーブル内で実行された挿入・更新・削除といった操作の履歴や、それらがいつ発生したかといった詳細な変更情報を記録します。
一方、Change Tracking は、どの行が変更されたかを特定しますが、実際のデータの変更内容までは記録しません。
CDC の仕組みや SQL Server における CDC 利用のメリットについて詳しく知りたい方は、こちらをご参照ください。
Databricks では、主キーを持つテーブルには Change Tracking の利用を推奨しています。これは、ソースデータベースへの負荷を最小限に抑えるためです。
主キーがないテーブルの場合には、CDC の利用を推奨しています。用途に応じた使い分けの詳細については、こちらをご覧ください。
SQL Server コネクタは、取り込みパイプラインの初回実行時に履歴データを一括で読み込みます。以降は、SQL Server の CT または CDC 機能を活用し、前回実行以降の変更分のみを検出・取り込みすることで、運用の効率化とパフォーマンスの最適化を実現します。
ガバナンスとプライベートネットワークのセキュリティ
Lakeflow Connect を使って SQL Server に接続する際には、以下のようなセキュリティ対策とガバナンスが適用されます:
クライアントインターフェースとコントロールプレーン間の通信は、TLS 1.2 以降で暗号化され、転送中のデータを保護します。
取り込み中に生データが一時的に保存される ステージングボリューム は、クラウドストレージプロバイダーによって暗号化されます。
保存データ(データアットレスト)は、業界標準の ベストプラクティスとコンプライアンス基準に従って保護されます。
プライベートエンドポイントを構成した場合、すべてのデータ通信はクラウドプロバイダーの プライベートネットワーク内で完結し、パブリックインターネットを経由しません。
取り込まれたデータは、Databricks 内の他のデータセットと同様に 暗号化されて保管されます。
また、スナップショットや変更ログ、メタデータを抽出する Ingestion Gateway により、データは UC Volume に格納されます。UC Volume は JSON などの非構造データを登録・管理するのに最適なストレージ抽象であり、お客様自身のクラウドストレージアカウント(VNet/VPC 内)に属しています。
さらに、Unity Catalog(UC)では以下のようなセキュリティ・ガバナンス機能が提供されます:
きめ細かなアクセス制御(Fine-Grained Access Control)
アクセスログや監査証跡の記録によるトレーサビリティ確保
UCサービス認証情報やストレージ認証情報は UC 内のセキュアなオブジェクトとして管理され、SQL パイプラインにハードコードされたりログに出力されたりすることはありません
これら��により、セキュアかつ統合された認証管理と強力なアクセスコントロールが実現されます。上記の条件を満たす企業であれば、Lakeflow Connect for SQL Server の導入をぜひご検討ください。Databricks へのデータ取り込みをよりシンプルかつ安全に実現できます。
技術ソリューションの分解
ここからは、Lakeflow Connect を使って SQL Server(今回は Azure SQL Server)からデータを複製する際の設定手順を順を追ってご紹介します。
Unity Catalog の権限設定
まず Databricks 上で、ノートブック・ワークフロー・パイプライン向けのサーバーレスコンピュートが有効化されていることを確認してください(AWS | Azure | GCP)。
そのうえで、取り込みパイプラインを作成するユーザーまたはサービスプリンシパルが、以下の Unity Catalog(UC)権限を持っているかどうかを確認します:
| 権限タイプ | 理由: | ドキュメント |
| メタストア上でのCONNECTIONの作成 | Lakeflow Connectは、SQL Serverにセキュアな接続を確立する必要があります。 | CONNECTIONの作成 |
| USE CATALOG on the target catalog | これは、Lakeflow ConnectがUC内のSQL Serverデータテーブルを配置するカタログへのアクセスを提供するために必要です。 | カタログを使用する |
| SCHEMAの使用、既存のスキーマまたはターゲットカタログ上でのTABLEの作成とVOLUMEの作成、またはSCHEMAの作成 | 取り込まれたデータテーブルのストレージ場所を作成し、スキーマにアクセスするための必要な権限を提供します。 | 権限の付与 |
| クラスターの作成に対する無制限の権限、またはカスタムクラスターポリシー | ゲートウェイ取り込みプロセスに必要な計算リソースを立ち上げるために必要 | COMPUTE POLICIESの管理 |
Azure SQL Serverの設定
SQL Serverコネクタを使用するには、以下の要件が満たされていることを確認してください:
- SQLバージョンの確認
- 変更追跡を使用するには、SQL Server 2012またはそれ以降のバージョンを有効にする必要があります。ただし、2016年以降が推奨されます*。SQLバ��ージョンの要件をこちらで確認してください。
- Databricks取り込み専用のデータベースサービスアカウントを設定します。
- 変更追跡または組み込みCDCの有効化
- CDCを使用するには、SQL Server 2012以降のバージョンが必要です。SQL Server 2016より前のバージョンでは、さらにエンタープライズエディションが必要です。
* 2025年5月時点の要件。変更の可能性あり。
例:Azure SQL ServerからDatabricksへの取り込み
次に、Lakeflow Connectを使用してAzure SQL ServerデータベースからテーブルをDatabricksに取り込みます。この例では、CDCとCTが利用可能なすべてのオプションの概要を提供します。この例のテーブルには主キーがあるため、CTが主な選択肢になる可能性がありました。しかし、この例では小さなテーブルが1つしかないため、ロードオーバーヘッドについては心配ありませんので、CDCも含まれていました。CDC、CT、または両方をいつ使用するべきかを確認することが推奨されます。これにより、データと更新要件に最適なものを決定できます。
1. [Azure SQL Server] CDCとCTのためのAzure SQL Serverの確認と設定
Azureポータルにアクセスし、Azureアカウントの資格情報を使用してサインインすることから始めます。左側にあるすべてのサービスをクリックし、SQL Serversを検索します。サーバーを見つけてクリックし、'Query Editor'をクリックします。この例では、sqlserver01が選択されました。
下のスクリーンショットは、SQL Serverデータベースに'drivers'という名前のテーブルが1つあることを示しています。
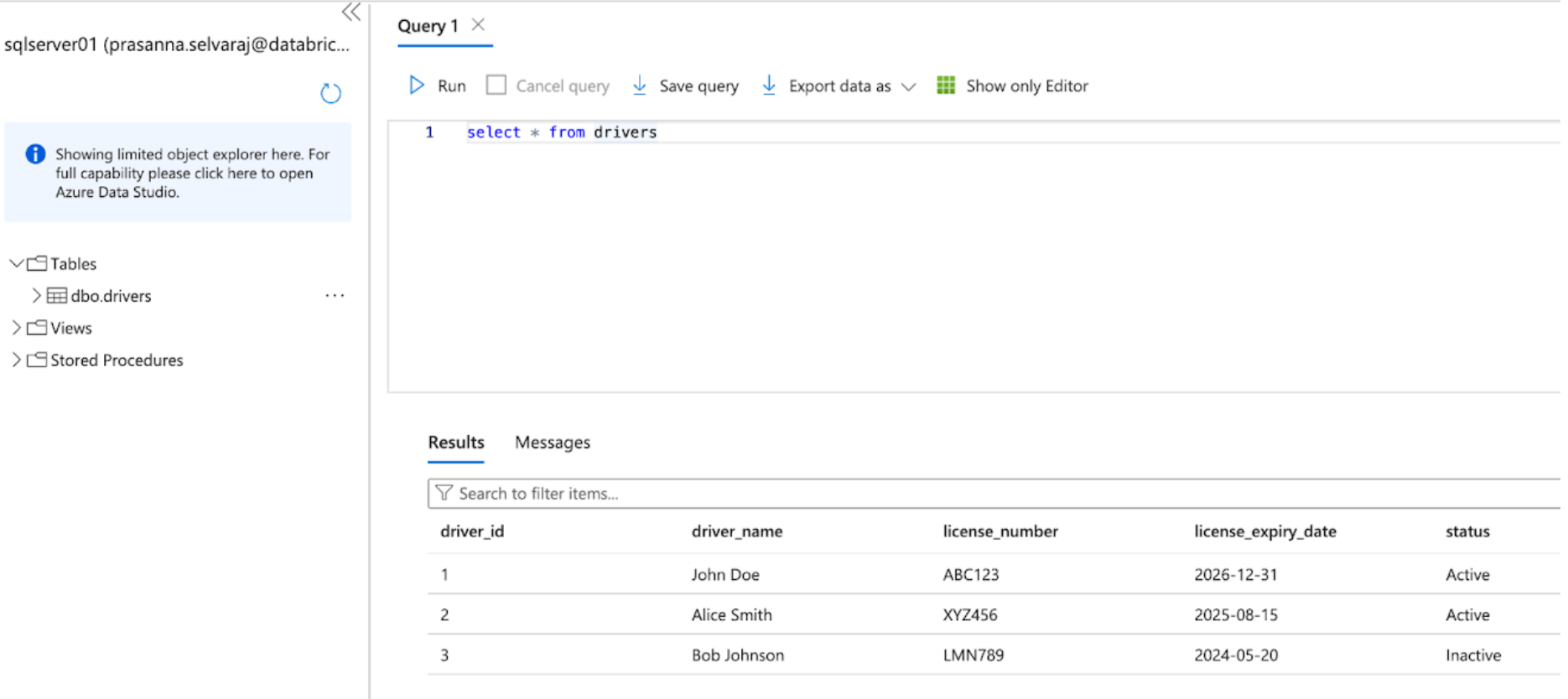
データをDatabricksにレプリケートする前に、変更データキャプチャ、変更トラッキング、または両方を有効にする必要があります。
この例では、以下のスクリプトがデータベースで実行されてCTを有効にします:
このコマンドは、以下のパラメーターでデータベースの変更追跡を有効にします:
- CHANGE_RETENTION = 3 DAYS:この値は3日間(72時間)の変更を追跡します。ゲートウェイが設定時間以上オフラインの場合、完全なリフレッシュが必要になります。より長い停電が予想される場合は、この値を増やすことを推奨します。
- AUTO_CLEANUP = ON:これはデフォルトの設定です。パフォーマンスを維持するために、自動的に保持期間を超えた変更トラッキングデータを削除します。
次に、以下のスクリプトをデータベースで実行してCDCを有効にします:
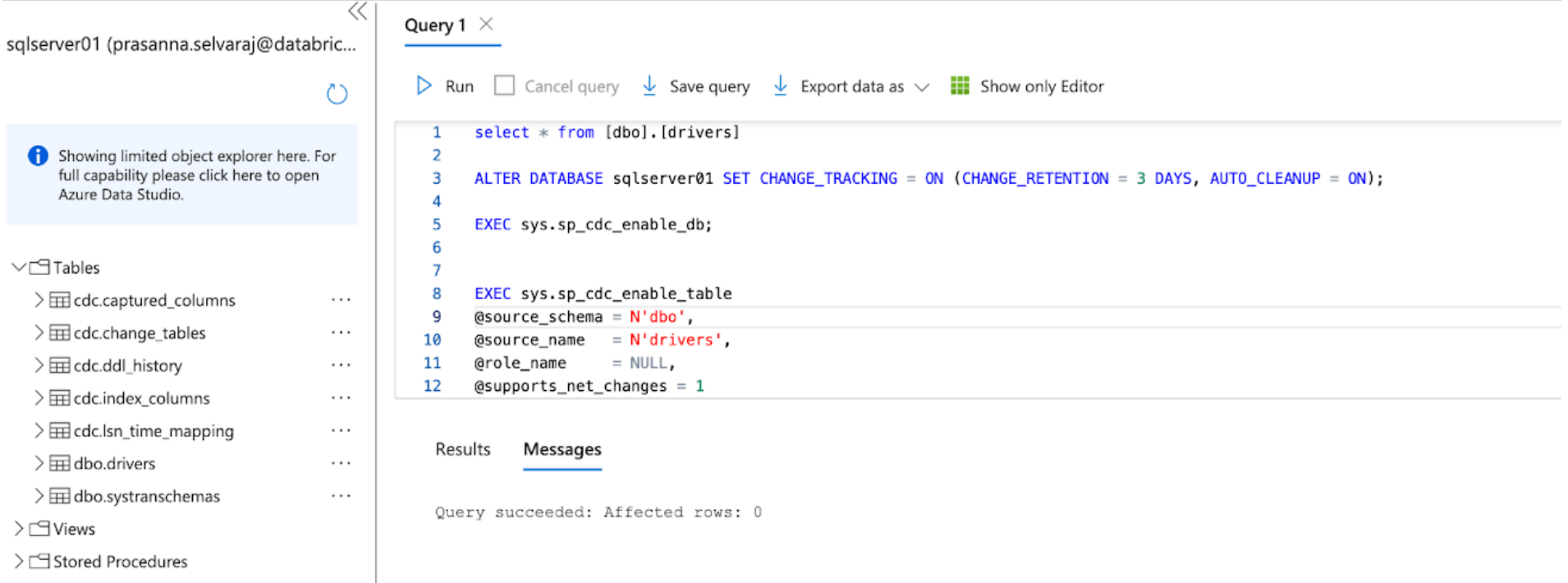
両方のスクリプトが実行された後、AzureのSQL Serverインスタンスのテーブルセクションを確認し、すべてのCDCとCTテーブルが作成されていることを確認します。
2. [Databricks] Lakeflow ConnectでSQL Serverコネクタを設定します
次のステップでは、SQL Serverコネクタを設定するためのDatabricksの画面(UI)が表示されます。または、Databricks Asset Bundles (DABs)、Lakeflow Connectパイプラインをコードとして管理するプログラム的な方法も活用できます。完全なDABsスクリプトの例は以下の付録にあります。
すべての権限が設定されると、権限前提条件セクションで説明されているように、データの取り込みを開始する準備が整います。左上の+ 新規ボタンをクリックし、次にデータを追加またはアップロードを選択します。
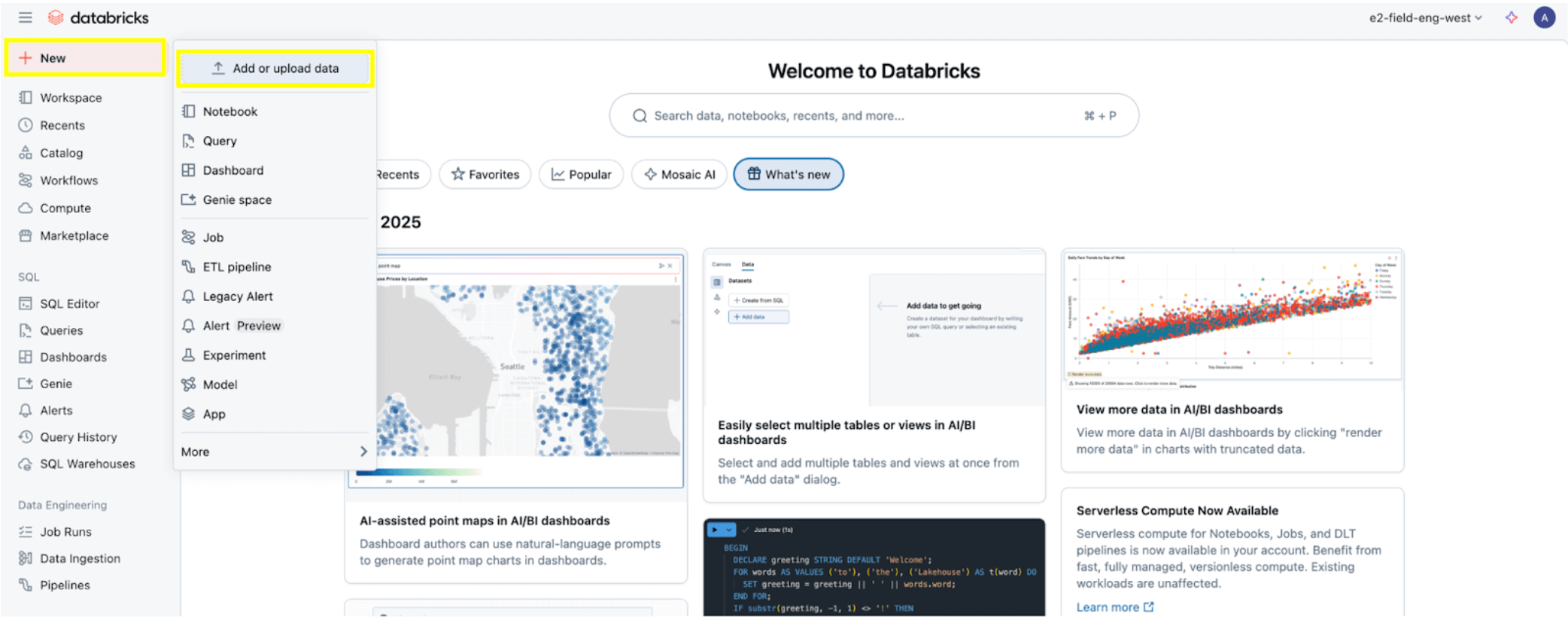
次に、SQL Serverオプションを選択します。
SQL Serverコネクタはいくつかのステップで設定されます。
1. 取り込みゲートウェイの設定(AWS | Azure | GCP)。このステップでは、ingestion gateway pipelineに名前を付け、UCボリュームの場所のカタログとスキーマを提供して、ソースデータベースからスナップショットを抽出し、データの変更を継続的に取り込みます。
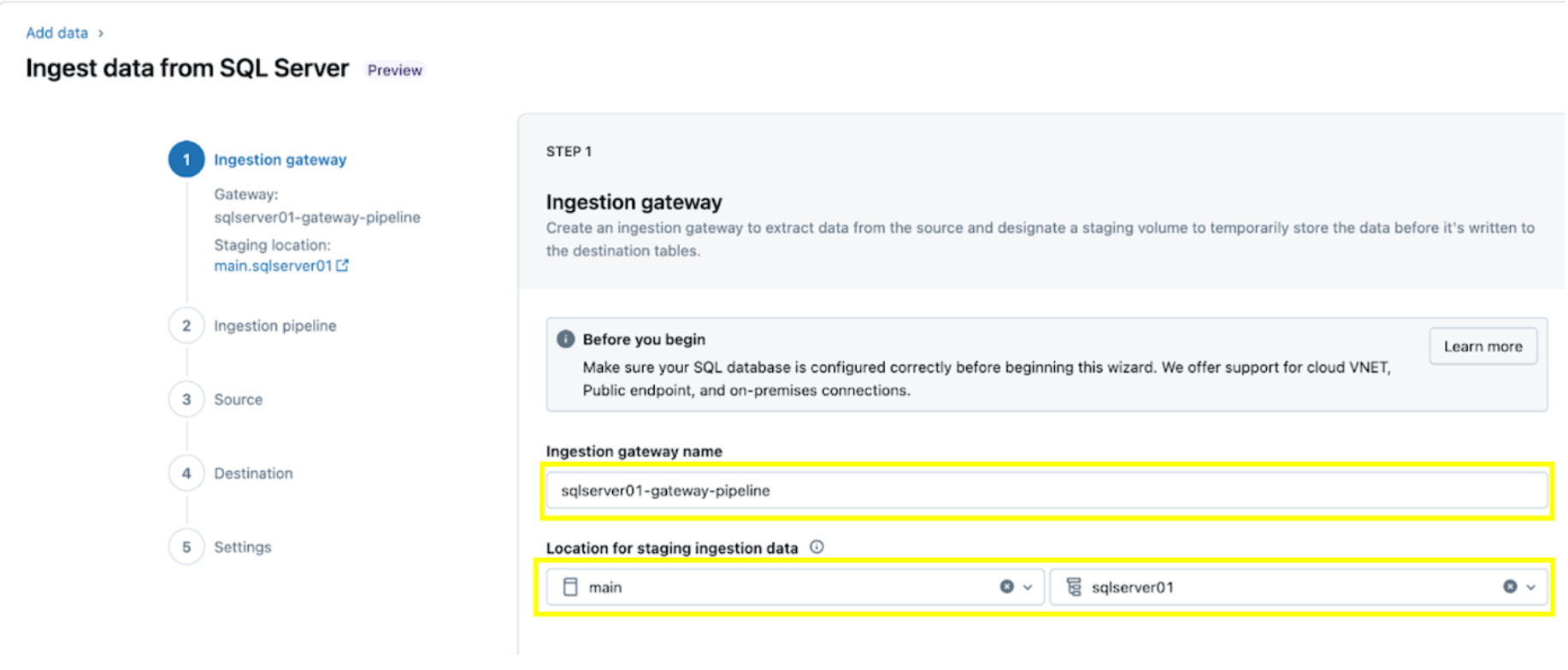
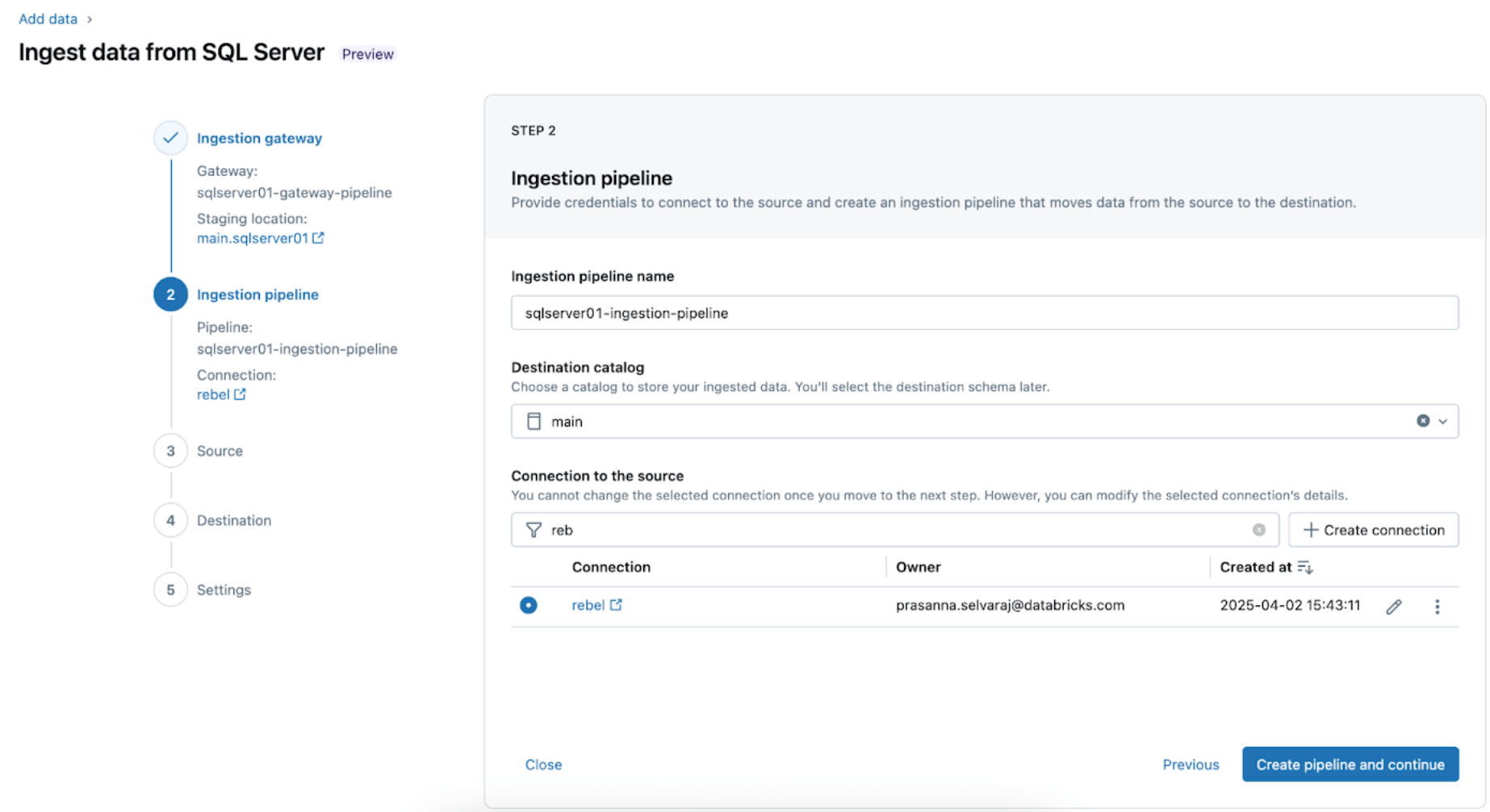
2. 取り込みパイプラインの設定。これにより、CDC/CTデータソースとスキーマ進化イベントが複製されます。SQL Serverへの接続が必要であり、これは以下の手順または以下のSQLコードに従ってUIを通じて作成されます:
この例では、SQLサーバー接続の名前を rebel としてください。
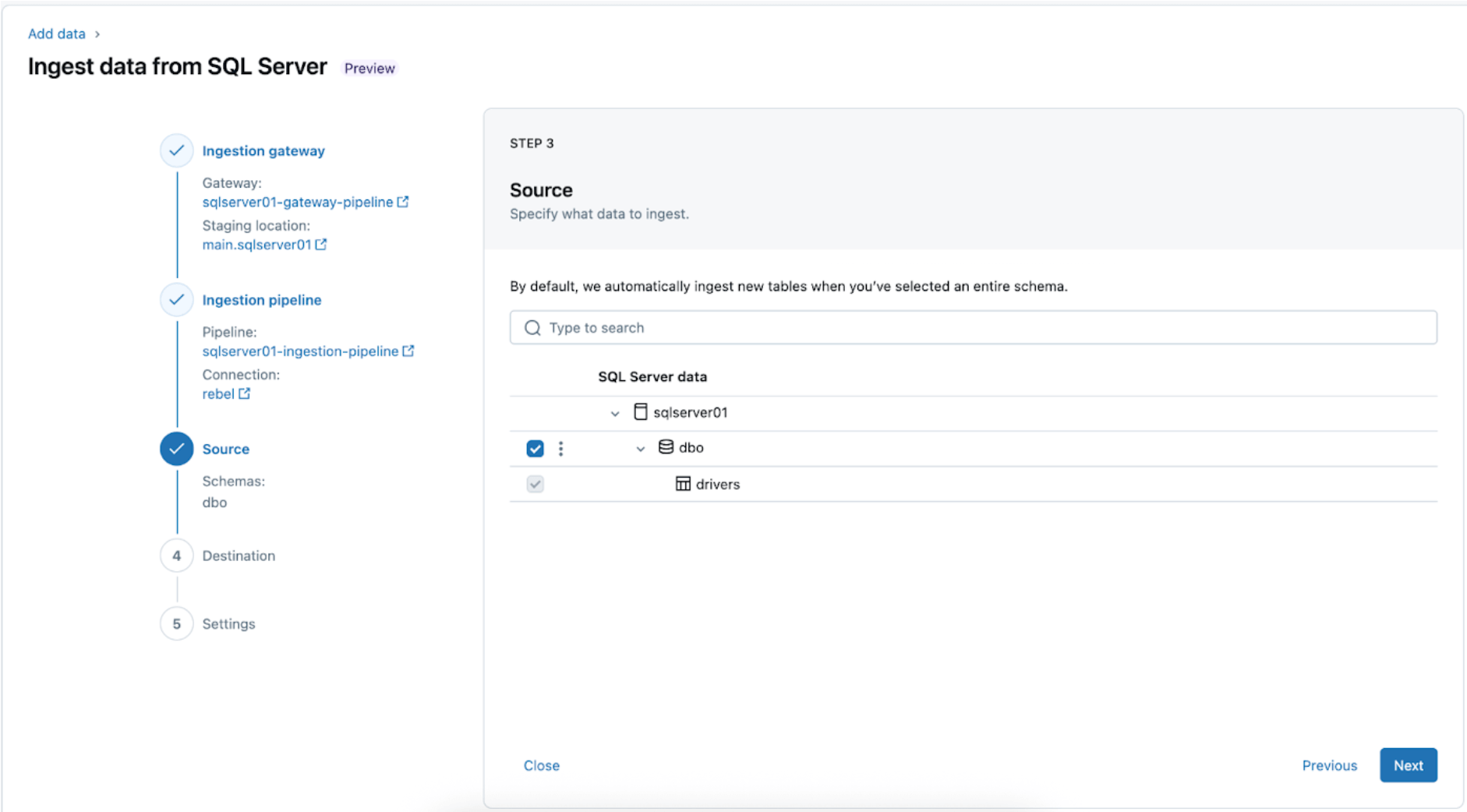
3. レプリケーションのためのSQL Serverテーブルの選択。個々のテーブルを取り込むのではなく、スキーマ全体をDatabricksに取り込むことを選択します。
全スキーマは、初期の探索または移行時にDatabricksに取り込むことができます。スキーマが大きいか、パイプラインごとの許容テーブル数を超える場合(コネクタの制限を参照)、Databricksは、最適なパフォーマンスを維持するために、取り込みを複数のパイプラインに分割することを推奨します。単一のMLモデル、ダッシュボード、レポートなどのユースケース固有のワークフローについては、全スキーマよりもその特定のニーズに合わせた個々のテーブルを取り込む方が一般的に効率的です。
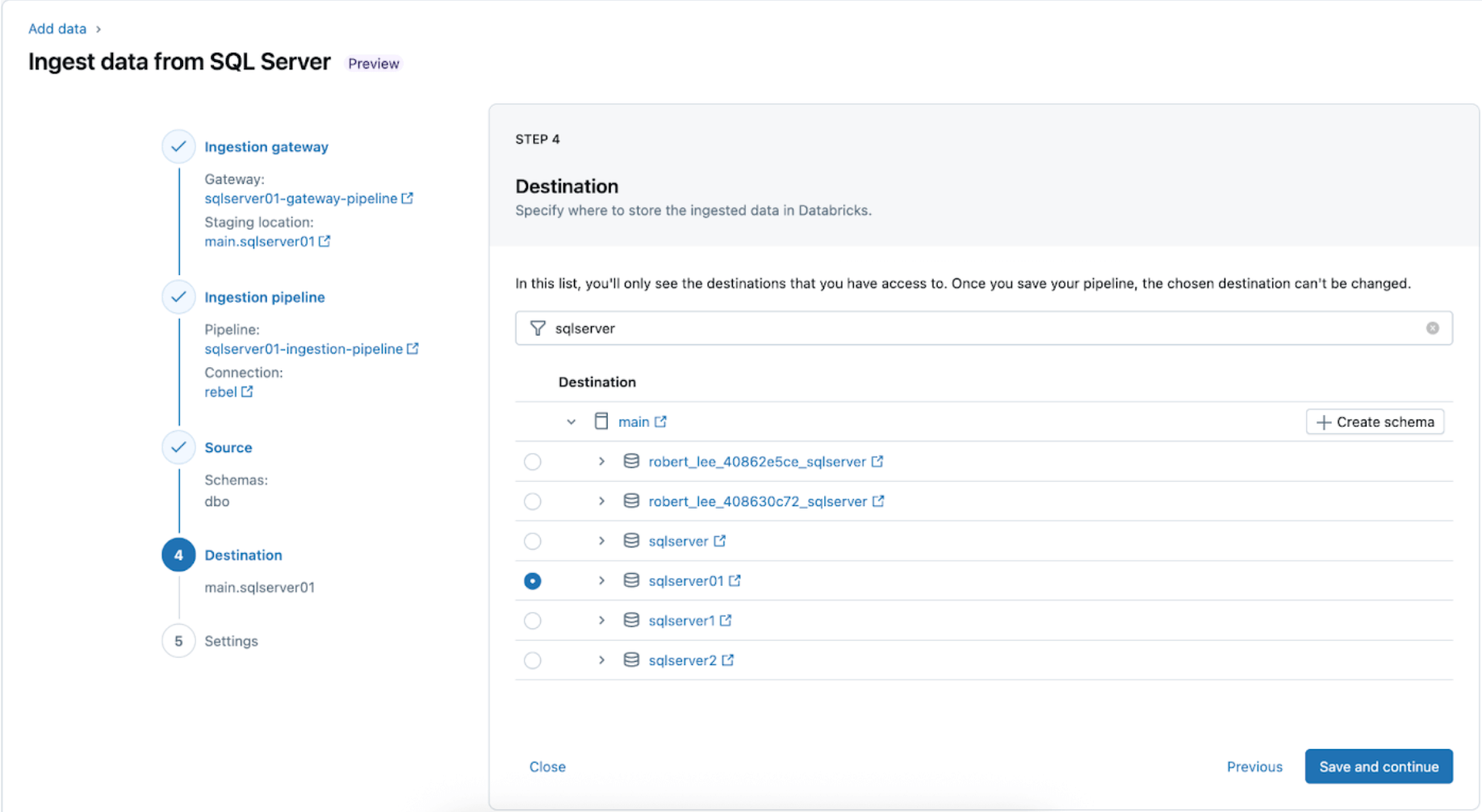
4. SQL ServerのテーブルがUC内でレプリケートされる先を設定します。main カタログとsqlserver01スキーマを選択して、データをUCに配置します。
5. スケジュールと通知の設定 (AWS | Azure | GCP)。この最終ステップでは、パイプラインをどのくら��いの頻度で実行し、成功または失敗のメッセージをどこに送るべきかを決定するのに役立ちます。パイプラインを6時間ごとに実行し、パイプラインの失敗のみをユーザーに通知します。この間隔は、ワークロードのニーズに合わせて設定できます。
取り込みパイプラインは、カスタムスケジュールでトリガーできます。Lakeflow Connectは、各スケジュールされたパイプライントリガーに対して専用のジョブを自動的に作成します。取り込みパイプラインは、ジョブ内のタスクです。必要に応じて、取り込みタスクの前後にさらにタスクを追加して、ダウンストリームの処理を行うことができます。
このステップの後、摂取パイプラインが保存され、トリガーされ、SQL ServerからDatabricksへの全データのロードが開始されます。
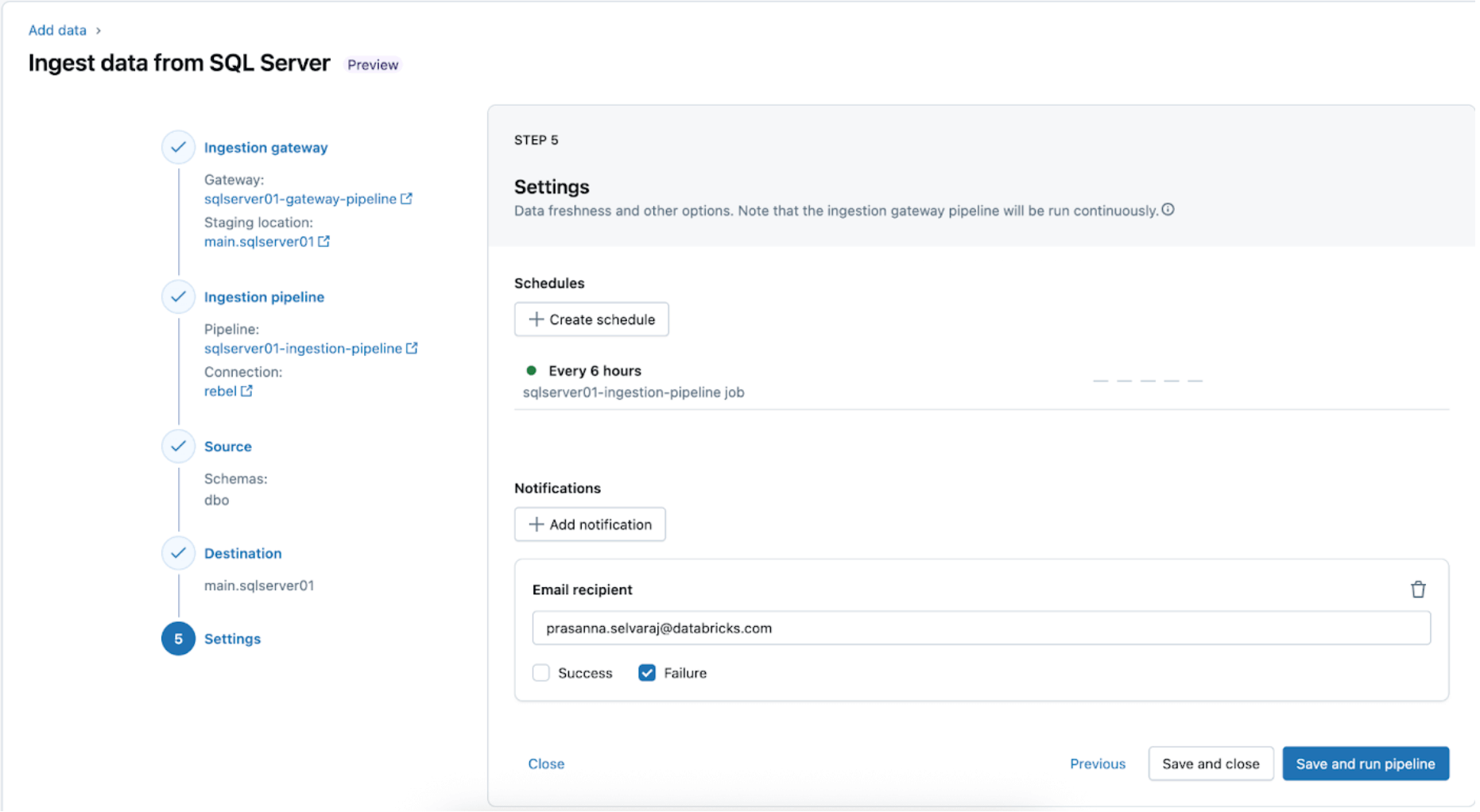
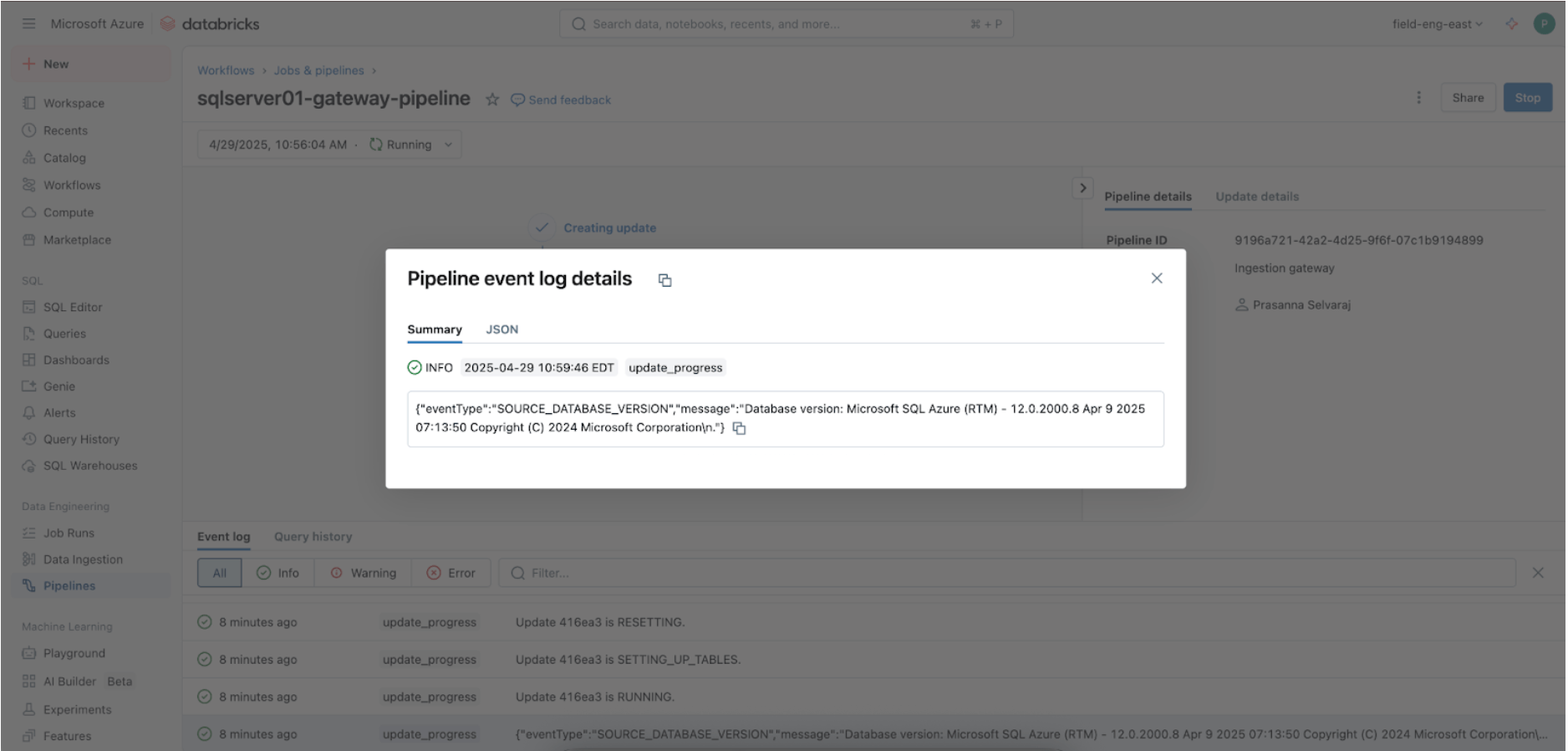
3. [Databricks] ゲートウェイと取り込みパイプラインの成功した実行を検証する
ゲートウェイ取り込みパイプラインが実行中かどうかを確認するために、パイプラインメニューに移動します。完了したら、ゲートウェイがソースデータを正常に取り込んだことを確認するために、下部のパネルにあるパイプラインイベントログインターフェース内で'update_progress'を検索します。
同期状態を確認するには、パイプラインメニューに移動します。下のスクリーンショットは、取り込みパイプラインが3つの挿入と更新(UPSERT)操作を実行したことを示しています。
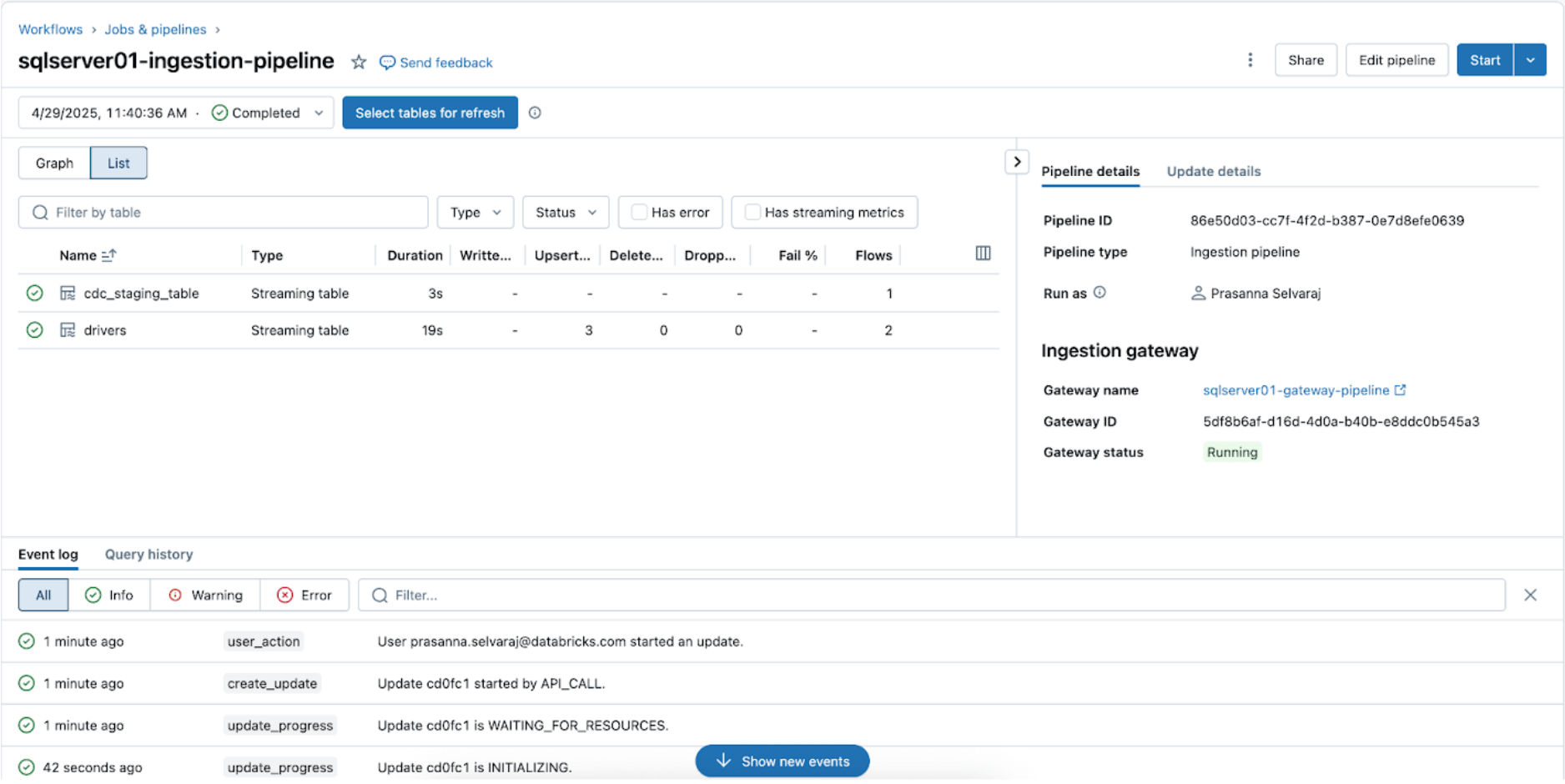
ターゲットカタログに移動し、mainスキーマに移動し、sqlserver01以下に示すように、レプリケートされたテーブルを表示します。

4. [Databricks] CDCとスキーマ進化のテスト
次に、ソーステーブルで挿入、更新、削除操作を実行してCDCイベントを確認します。下のAzure SQL Serverのスクリーンショットは、3つのイベントを示しています。
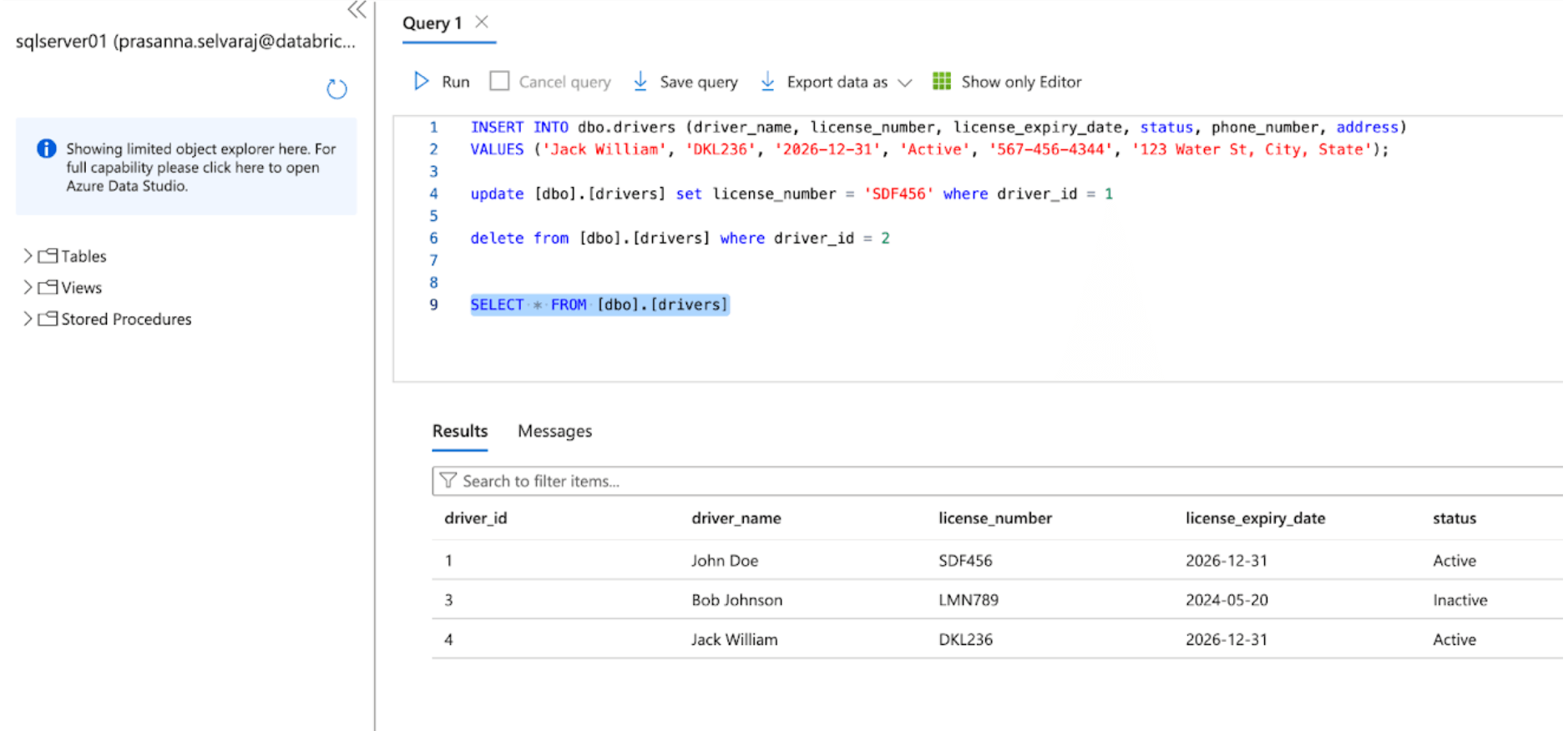
パイプラインがトリガーされて完了したら、ターゲットスキーマの下のデルタテーブルをクエリして変更を確認します。
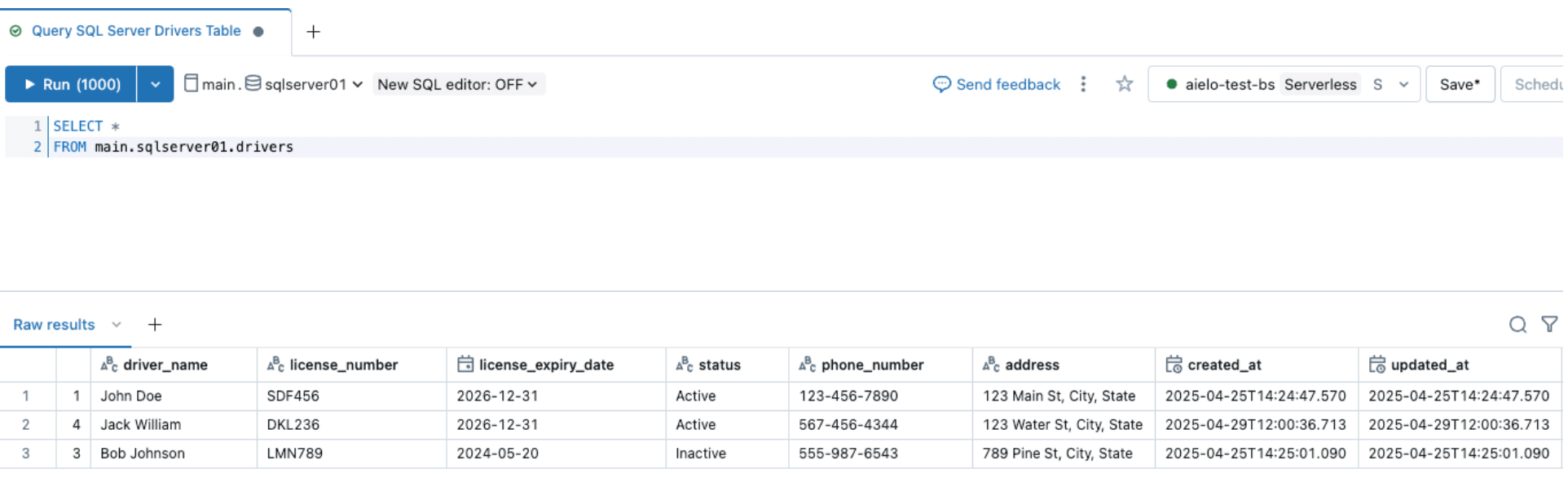
同様に、スキーマ進化イベントを実行し、以下に示すようにSQL Serverソーステーブルに列を追加しましょう

ソースを変更した後、Databricks DLT UI内のスタートボタンをクリックして取り込みパイプラインをトリガーします。パイプラインが完了したら、以下に示すように、ターゲットテーブルをブラウジングして変更を確認します。新しい列emailがdriversテーブルの最後に追加されます。
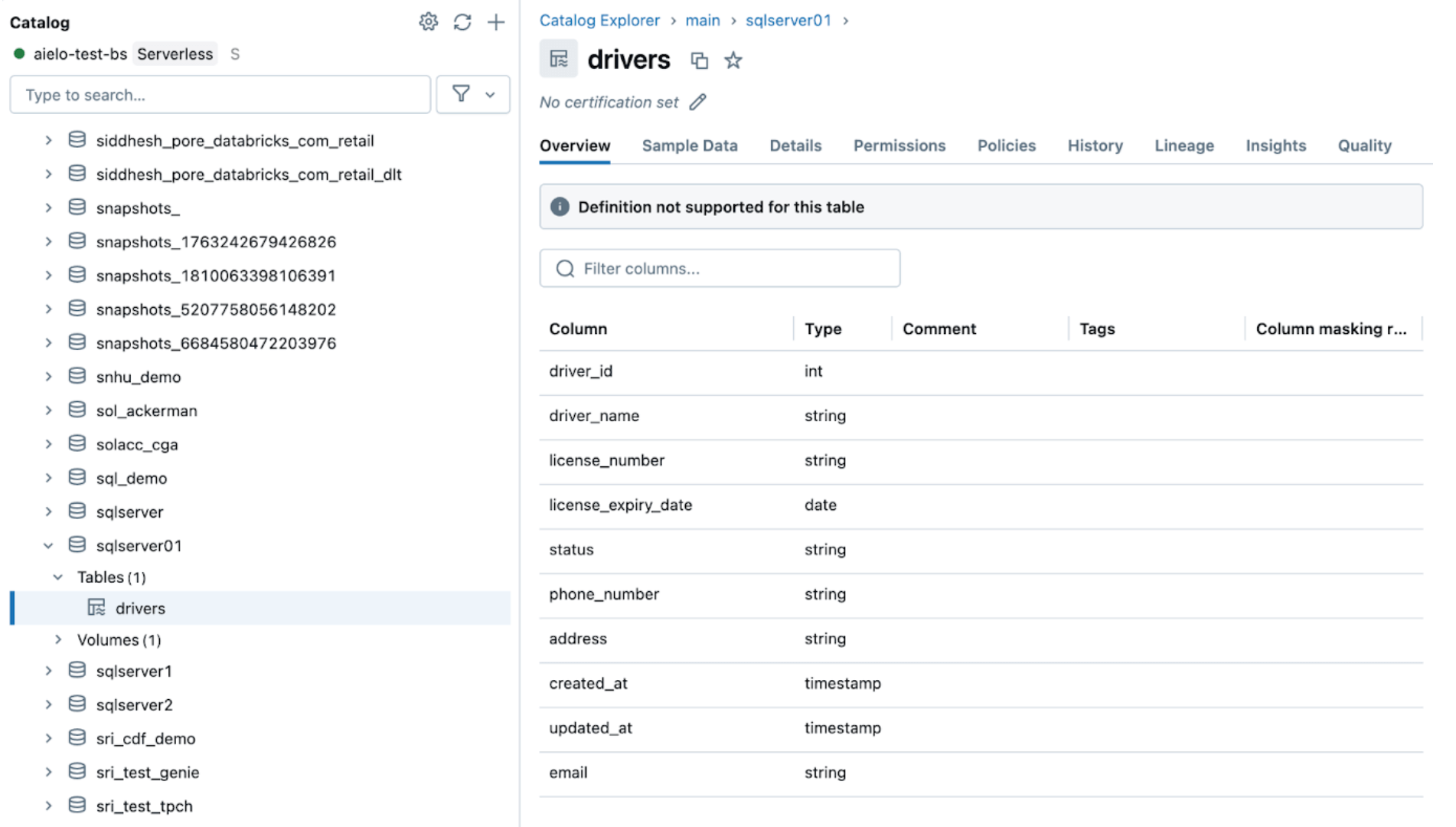
5. [Databricks] 連続的なパイプライン監視
インジェストとゲートウェイのパイプラインが正常に動作している場合、その健康状態と動作を監視することが重要です。パイプラインUIは、デ��ータ品質チェック、パイプラインの進行状況、データ系統情報を提供します。パイプラインUIのイベントログエントリを表示するには、以下に示すように、パイプラインDAGの下部のペインを探します。

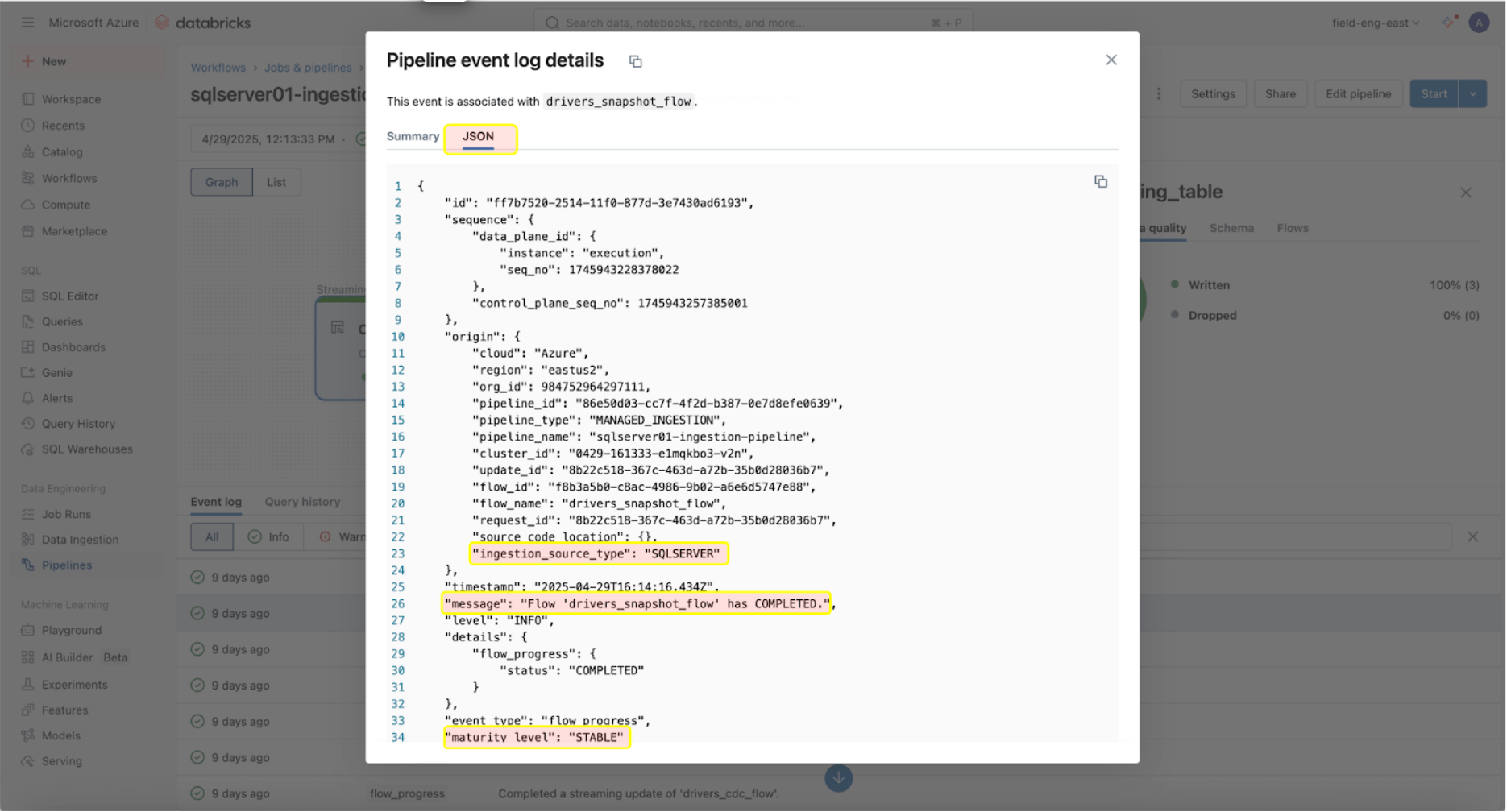
上記のイベントログエントリは、「drives_snapshot_flow」がSQL Serverから取り込まれ、完了したことを示しています。STABLEの成熟度レベルは、スキーマが安定しており、変更されていないことを示しています。イベントログスキーマの詳細情報はここで見つけることができます。
リアルワールドの例
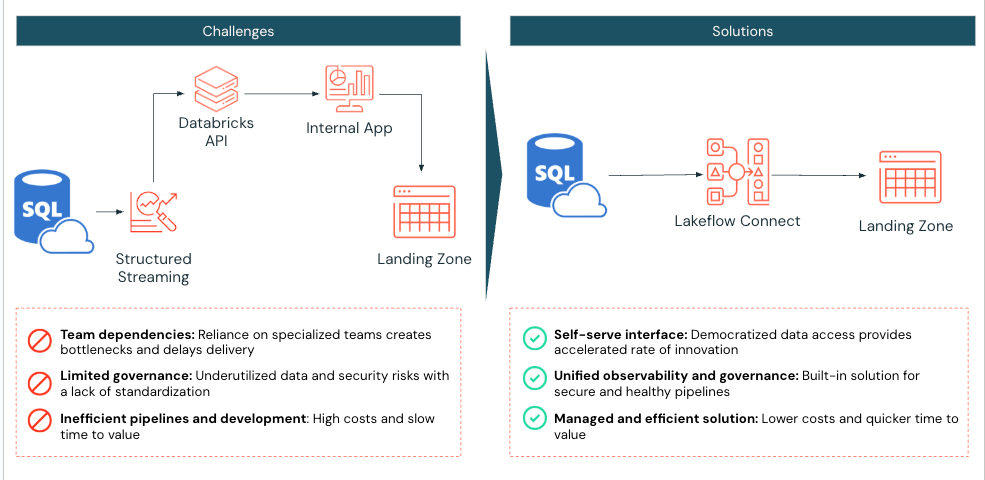
大規模な医療診断ラボがDatabricksを使用してSQL Serverデータを効率的に取り込むことに苦労していました。Lakeflow Connectを実装する前に、ラボはDatabricks Sparkノートブックを使用して、Azure SQL Serverから2つのテーブルをDatabricksに引き出しました。そのアプリケーションは、Databricks APIと対話して計算とジョブの実行を管理します。
医療診断ラボは、このプロセスを簡素化できると認識し、SQL Server用のLakeflow Connectを実装しました。有効化されると、実装はわずか1日で完了し、医療診断ラボはDatabricksの組み込みツールを使用して、日次の増分取り込みリフレッシュの観察可能性を活用できるようになりました。
運用上の考慮事項
SQL ServerコネクタがAzure SQLデータベースへの接続を正常に確立したら、次のステップは、パフォーマンスとリソース利用の最適化のために、データパイプラインを効率的にスケジュールすることです。さらに、環境間でのスケーラビリティと一貫性を確保するために、プログラム的なパイプライン設定のベストプラクティスを遵守することが重要です。
パイプラインオーケストレーション
インジェストパイプラインを実行する頻度に制限はありません。ただし、コストを最小限に抑え、パイプラインの実行が重複しないように一貫性を保つために、Databricksは取り込み実行間の最低5分間隔を推奨します。これにより、計算リソースと起動時間を考慮しながら、ソースで新しいデータを導入することが可能になります。
取り込みパイプラインは、ジョブ内のタスクとして設定できます。ダウンストリームのワークロードが新鮮なデータの到着に依存している場合、タスクの依存関係を設定して、取り込みパイプラインの実行がダウンストリームのタスクの実行前に完了することを確認できます。
さらに、次のリフレッシュがスケジュールされているときにパイプラインがまだ実行中の場合、取り込みパイプラインはジョブと同様に動作し、現在実行中の更新が時間内に完了すると仮定して、次のスケジュールされた更新まで更新をスキップします。
観察可能性&コスト追跡
Lakeflow Connectは、さまざまなデータ統合ニーズに対して効率とスケーラビリティを確保する料金モデルに基づいて動作します。取り込みパイプラインはサーバーレスコンピューティング上で動作し、需要に基づいてスケーリングの柔軟性を提供し、ユーザーが基盤となるインフラストラクチャを設定および管理する必要性を排除することで管理を簡素化します。
ただし、取り込みパイプラインはサーバーレスコンピュートで実行できる一方で、データベースコネクタの取り込みゲートウェイは現在、データベースソースへの接続を簡素化するためにクラシックコンピュートで動作していることに注意が必要です。その結��果、ユーザーはクラシックとサーバーレスのDLT DBU料金が組み合わさったものが請求に反映されることがあります。
Lakeflow Connectの使用状況を追跡し、監視する最も簡単な方法は、システムテーブルを通じてです。以下は、特定のLakeflow Connectパイプラインの使用状況を表示するためのクエリの例です:

Lakeflow Connectの公式価格設定文書(AWS | Azure | GCP)では、詳細な料金情報が提供されています。追加の費用、たとえばサーバーレスのエグレス料金(価格)が適用される場合があります。クラシックコンピューティングのクラウドプロバイダからのエグレスコストはここで見つけることができます (AWS | Azure | GCP)。
ベストプラクティスと主な教訓
2025年5月現在、このSQL Serverコネクタを実装する際には以下のベストプラクティスと考慮事項を参照してください:
- 各取り込みゲートウェイを、レプリケーションされたソースデータベースのみにアクセスできるユーザーまたはエンティティで認証するように設定します。
- ユーザーがUCで接続を作成し、データを取り込むための必要な権限を与えられていることを確認します。
- DABsを利用することで、Lakeflow Connectの取り込みパイプラインを信頼性高く設定し、インフラストラクチャ管理の再現性と一貫性を確保します。
- 主キーを持つテーブルのソースでは、変更追跡を有効にしてオーバーヘッドを減らし、パフォーマンスを向上させます。
- プライマリキーがないソーステーブルの場合、ユニークな行識別子がなくても列レベルでの変更をキャプチャできるCDCを有効にします。
Lakeflow Connect for SQL Serverは、オンプレミスとクラウドの両方のデータベースに対して完全に管理された組み込みの統合を提供し、効率的な増分取り込みをDatabricksに可能にします。
次のステップ&追加リソース
今日からSQL Serverコネクタを試して、データ取り込みの課題を解決しましょう。このブ��ログで説明されている手順をフォローするか、ドキュメンテーションをご覧ください。Lakeflow Connectについては、製品ページをご覧いただくか、製品ツアーをご覧いただくか、Salesforceコネクタのデモをご覧いただき、顧客の離脱を予測する方法を学んでください。
DatabricksのDelivery Solutions Architects(DSAs)は、組織全体のデータとAIのイニシアチブを加速します。彼らは、アーキテクチャリーダーシップを提供し、プラットフォームをコストとパフォーマンスの観点から最適化し、開発者体験を向上させ、プロジェクトの成功を推進します。DSAsは、初期のデプロイメントと本番環境のソリューションの間のギャップを埋め、データエンジニアリング、技術リーダー、エグゼクティブ、その他のステークホルダーを含むさまざまなチームと密接に連携して、カスタムソリューションとより早い価値提供を確実にします。カスタム実行計画、戦略的なガイダンス、およびDSAからのデータとAIの旅を通じたサポートを受けるためには、Databricksアカウントチームにお問い合わせください。
付��録
このオプションのステップでは、DABsを使用してLakeflow Connectパイプラインをコードとして管理するために、既存のバンドルに2つのファイルを追加するだけです:
- データ取り込みの頻度を制御するワークフローファイル(resources/sqlserver.yml)。
- パイプライン定義ファイル(resources/sqlserver_pipeline.yml)。
resources/sqlserver.yml:
resources/sqlserver_job.yml:
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。