Intel Gaudi 2 AIアクセラレーターによるLLMトレーニングと推論
Databricksでは、お客様がデータのプライバシーやコントロールを犠牲にすることなく、ご自身のデータでジェネレーティブAIアプリケーションを構築し、展開できるようにしたいと考えています。 カスタムAIモデルのトレーニングをご希望のお客様には、簡単かつ効率的に、低コストでトレーニングできるようお手伝いします。 この課題�に対処するための1つの手段は、MLハードウェアの最適化です。この目的のために、私たちはLLMスタックが様々なMLハードウェアプラットフォーム(例えば、NVIDIA [1][2]、AMD [3][4])をシームレスにサポートできるよう、たゆまぬ努力を続けてきました。
本日は、AIトレーニングおよび推論市場におけるもう1つの主役、Intel® Gaudi® AIアクセラレーター・ファミリーについてご紹介します! これらのアクセラレータは、AWS(第一世代のGaudi)、Intel Developer Cloud(Gaudi 2)、およびオンプレミス実装の場合はSupermicroとWiWynn(GaudiおよびGaudi 2アクセラレータ)から入手できます。
このブログでは、オープンソースの LLM Foundry を使用した LLM トレーニングと、オープンソースの Optimum Habana ライブラリーを 使用した推論について、 IntelR GaudiR 2 を紹介します。全体として、 IntelR GaudiR 2アクセラレータは、8 x Gaudi 2でMPT-7Bをトレーニングした場合、260 TFLOP/s/デバイス以上を達成し、我々がテストした中で 2番目に優れたトレーニング性能を持っていることがわかりました(NVIDIA H100のみがベスト)。LLM推論については、LLaMa2-70Bをプロファイリングしたところ、8 x Gaudi 2システムは、デコードレイテンシ(LLM推論の最もコストのかかるフェーズ)において、8 x H100システムに匹敵することがわかりました。
Gaudi 2アクセラレーターはインテル・デベロッパー・クラウド(IDC)を通じて一般に公開されているため、ドルあたりのパフォーマンスも見積もることができます。 AWSとIDCで公開されているオンデマンドの価格設定に基づくと、IntelR GaudiR 2は、NVIDIA A100-40GB、A100-80GB、さらにはH100をしのぎ、ドルあたりのトレーニングおよび推論のパフォーマンスが最も優れていることがわかります!
このブログで紹介する結果はすべて、SynapseAI 1.12とBF16混合精度トレーニングを使用して測定したものです。 将来的には、Gaudi 2のFP8トレーニングのサポートを解除するSynapseAI 1.13の開発に期待しています。SynapseAI 1.13は、256xGaudi 2のクラスタ上で379 TFLOP/s/デバイス、384xGaudi 2のクラスタ上で368 TFLOP/s/デバイスを達成し、MLPerf Training 3.1 GPT3に提出されました。 SynapseAI 1.13では、LLM推論のパフォーマンスも向上する見込みです。
Intel Gaudiプラットフォームの詳細、LLMのトレーニングと推論の結果、LLMの収束の結果などについては、こちらをお読みください。 もちろん、クラウド・サービス・プロバイダーに、Intel® Gaudi® 2(現在提供中)とGaudi 3(2024年提供予定)がいつ提供されるかを必ず尋ねてください。
IntelR GaudiR 2 ハードウェア
IntelR GaudiR 2アクセラレーターは、LLMのようなAIモデルのディープラーニングのトレーニングと推論の両方をサポートします。 IntelR GaudiR 2アクセラレーターは、7nmプロセス技術で構築されています。 デュアル行列乗算エンジン(MME)と24個のプログラマブル・テンソル・プロセッサ・コア(TPC)を含むヘテロジニアス・コンピュート・アーキテクチャを備えています。 NVIDIA A100-40GBやA100-80GBなど、同世代の一般的なクラウドアクセラレータと比較すると、Gaudi 2はより多くのメモリ(96GBのHBM2E)、より高いメモリ帯域幅、より高いピークFLOP/sを備えています。 なお、AMD MI250はチップあたりのスペックは高いものの、システム構成は4xMI250と小型です。 表1aでは、IntelR GaudiR 2をNVIDIA A100およびAMD MI250と比較し、表1bでは、近日発売予定のIntel Gaudi 3をNVIDIA H100/H200およびAMD MI300Xと比較しています。
IntelR GaudiR 2アクセラレーターは、8x Gaudi 2 アクセラレーターのシステムで出荷され、RDMA over Converged Ethernet (RoCEv2) 上に構築された独自のスケールアウト・ネットワーキング設計を備えています。 各Gaudi 2アクセラレータは、24 x 100 Gbpsイーサネットポートを統合しており、21ポートはシステム内の全対全接続専用(他の7つのデバイスにそれぞれ3リンク)、残りの3リンクはシステム間のスケールアウト専用となっています。 全体として、これは各8倍のGaudi 2システムが3 [スケールアウト・リンク] * 8 [アクセラレータ] * 100 [Gbps] = 2400 Gbpsの外部帯域幅を持つことを意味します��。 この設計により、標準イーサネット・ハードウェアを使用した高速で効率的なスケールアウトが可能になります。
Databricksでは、Intel Developer Cloud (IDC)を介して大規模なマルチノードのIntelR GaudiR 2クラスターにアクセスすることができました。
| IntelR GaudiR 2 | AMD MI250 | NVIDIA A100-40GB | NVIDIA A100-80GB | |||||
|---|---|---|---|---|---|---|---|---|
| シングルカード | 8x Gaudi2 | シングルカード | 4x MI250 | シングルカード | 8x A100-40GB | シングルカード | 8x A100-80GB | |
| FP16またはBF16 TFLOP/s | ~400TFLOP/秒 | ~3200TFLOP/秒 | 362 TFLOP/s | 1448TFLOP/秒 | 312 TFLOP/s | 2496TFLOP/秒 | 312 TFLOP/s | 2496TFLOP/秒 |
| HBMメモリ(GB) | 96 GB | 768 GB | 128 GB | 512 GB | 40GB | 320 GB | 80GB | 640 GB |
| メモリ帯域幅 | 2450GB/秒 | 19.6TB/秒 | 3277GB/秒 | 13.1TB/秒 | 1555 GB/秒 | 12.4TB/秒 | 2039GB/秒 | 16.3TB/秒 |
| ピーク消費電力 | 600W | 7500 W | 560W | 3000 W | 400W | 6500 W | 400W | 6500 W |
| ラックユニット(RU) | N/A | 8U | N/A | 2U | N/A | 4U | N/A | 4U |
| Intel Gaudi 3 | AMD MI300X | NVIDIA H100 | NVIDIA H200 | |||||
|---|---|---|---|---|---|---|---|---|
| シングルカード | 8x Gaudi3 | シングルカード | 8x MI300X | シングルカード | 8x H100 | シングルカード | 8x H200 | |
| FP16またはBF16 TFLOP/s | ~1600TFLOP/秒 | ~12800TFLOP/秒 | 1307 TFLOP/s | 10456TFLOP/秒 | 989.5TFLOP/秒 | 7916 TFLOP/s | 989.5TFLOP/秒 | 7916 TFLOP/s |
| HBMメモリ(GB) | N/A | N/A | 192 GB | 1536 GB | 80GB | 640 GB | 141GB | 1128 GB |
| メモリ帯域幅 | ~3675GB/秒 | ~29.4TB/秒 | 5300GB/秒 | 42.4TB/秒 | 3350GB/秒 | 26.8TB/秒 | 4800 GB/秒 | 38.4TB/秒 |
| ピーク消費電力 | N/A | N/A | 750 W | N/A | 700 W | 10200 W | 700 W | 10200 W |
| ラックユニット(RU) | N/A | N/A | N/A | 8U | N/A | 8U | N/A | 8U |
表1a(上)と表1b(下):NVIDIA、AMD、Intelアクセラレータのハードウェアスペック。 2023年12月現在、公表されているのは仕様の一部のみです。 Gaudi 2のTFLOP/sの数値はDatabricksが実行したマイクロベンチマークを使用して推定したもので、Gaudi 3のTFLOP/sとメモリバンド幅はIntelの公開情報を使用して予測したものです。
Intel SynapseAIソフトウェア
Intel® Gaudi SynapseAIソフトウェア・スイートは、Gaudiデバイス上でPyTorchプログラムを最小限の変更でシームレスに実行することを可能にします。 SynapseAIは、グラフコンパイラ、ランタイム、テンソル演算に最適化されたカーネル、および集団通信ライブラリを提供します。 図1は、Intel® Gaudi® のソフトウェア・スタックとその主要コンポーネントを示しています。 SynapseAIの詳細は公式ドキュメントをご覧ください。
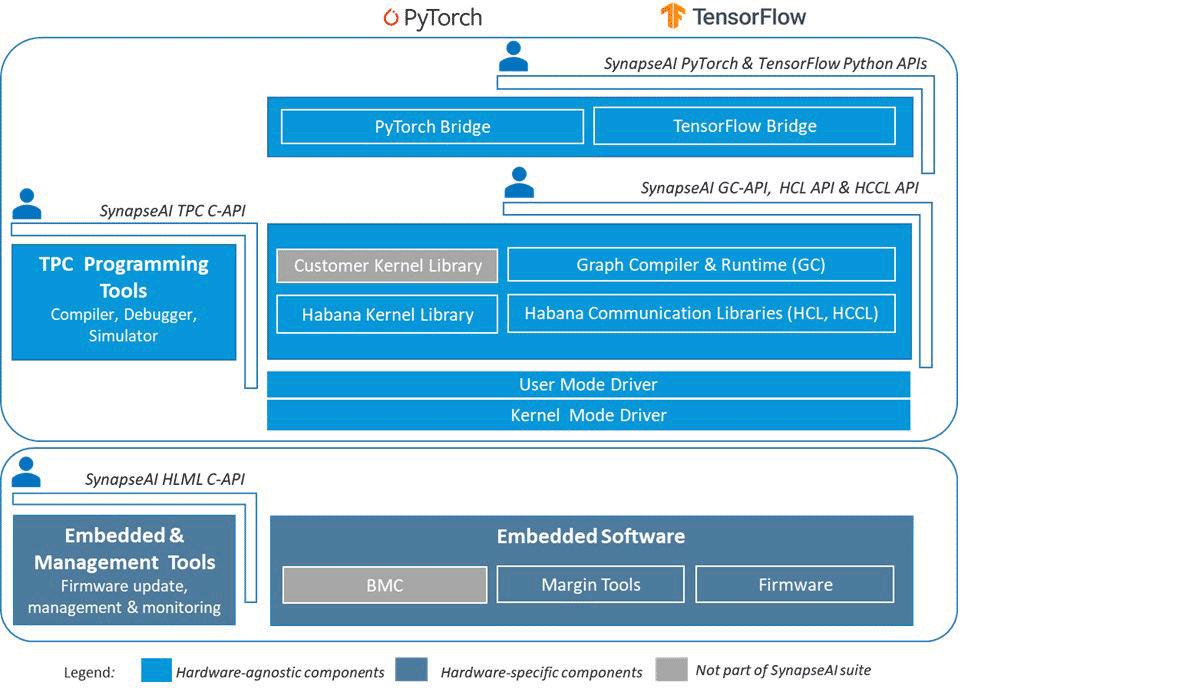
MLプログラマにとって最も人気のあるライブラリの1つがPyTorchで、開発者はPyTorchがGaudi 2のようなIntelアクセラレータ上でeagerモードまたはlazyモードで動作することを知って興奮するはずです。必要なのは、Gaudiが提供するPyTorchのビルドをインストールする��か(インストールマトリックスはこちら)、Dockerイメージの1つから起動するだけです。 一般的に、HuggingFace/PyTorchのコードをGaudiハードウェア上で実行するには、最小限のコード修正が必要です。 これらの変更には通常、tensor.cuda()の代入が含まれます。 tensor.to('hpu')を使ったコマンド コマンドを使うか、Composerや HF TrainerのようなPyTorchのトレーナーを使います!
LLM研修の実績
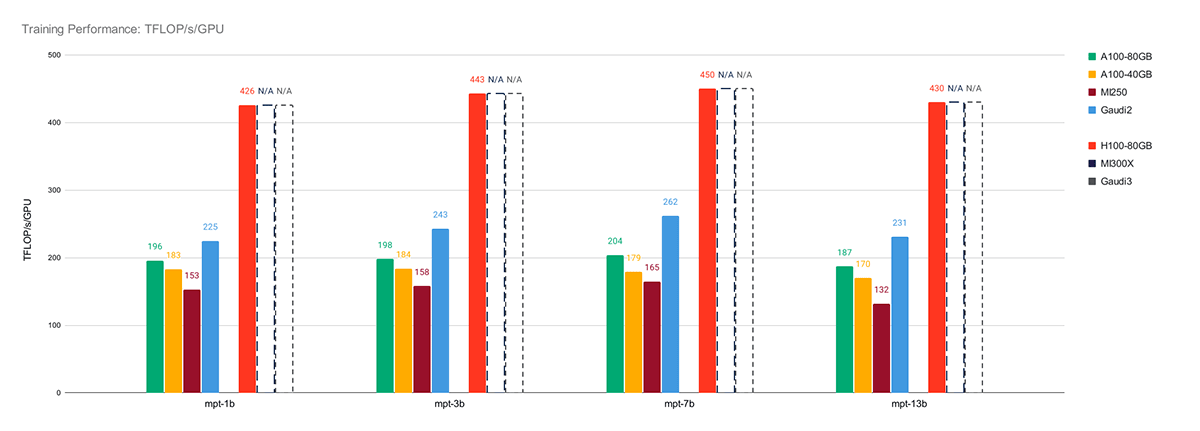
シングルノードのLLMトレーニング性能については、IntelR GaudiR 2は、SynapseAI 1.12とBF16混合精度トレーニングで260TFLOP/s/デバイス以上に達し、現在の市場で2番目に速いAIチップであることがわかりました。 IntelR GaudiR 2とNVIDIAおよびAMD GPUの比較については、 図2を 参照してください。
各プラットフォームで、シーケンス長2048、BF16混合精度、ZeRO Stage-3分散学習アルゴリズムのMPTモデルを使用して、LLM Foundryの同じ学習スクリプトを実行しました。 NVIDIA または AMD システムでは、このアルゴリズムは PyTorch FSDP を使って sharding_strategy で実装されます:FULL_SHARD.Intelシステムでは、これは現在、ステージ:3のDeepSpeed ZeRO�を介して行われますが、近い将来、FSDPのサポートが追加される予定です。
また、各システムで、利用可能な最も最適化されたスケールドットプロダクトアテンション(Scaled-dot-Product-Attention:SDPA)の実装を使用しました:
- NVIDIA: Triton FlashAttention-2
- AMD: ROCm ComposableKernel FlashAttention-2
- Intel: Gaudi TPC FusedSDPA
最後に、各システムで各モデルのマイクロバッチサイズを調整し、最大のパフォーマンスを達成しました。 すべてのトレーニング性能測定は、ハードウェアFLOPsではなくモデルFLOPsを報告しています。 詳しくはベンチマークのREADMEをご覧ください。
IntelR GaudiR 2を同世代のNVIDIA A100およびAMD MI250 GPUと比較したところ、Gaudi 2がA100-80GBに対して平均1.22倍、A100-40GBに対して平均1.34倍、MI250に対して平均1.59倍のスピードアップを実現し、明確な勝者であることがわかりました。
NVIDIA H100と比較した場合、IntelR GaudiR 2の平均パフォーマンスはH100の0.55倍です。 今後、次世代Intel Gaudi 3は、Gaudi 2の4倍のBF16性能と1.5倍のHBM帯域幅を持つことが公表されており、H100の強力なライバルとなります。
このブログではBF16トレーニングに焦点を当てていますが、FP8トレーニングが主要なアクセラレータ(NVIDIA H100/H200、AMD MI300X、IntelR GaudiR 2/Gaudi 3)のスタンダードになる日も近いと予想しており、今後のブログでその数値を報告することを楽しみにしています。 IntelR GaudiR 2では、SynapseAIバージョン1.13からFP8トレーニングがサポートされています。 NVIDIA H100とIntelR GaudiR 2のFP8予備トレーニング結果については、MLPerf Training 3.1 GPT3の結果をご覧ください。
さて、性能は素晴らしいですが、ドルあたりの性能はどうでしょうか?ありがたいことに、NVIDIAとIntelのアクセラレータの価格は公開されており、平均的なトレーニングのドルあたりのパフォーマンスを計算することができます。 以下の価格はオンデマンドの時間単価であり、割引後の価格を反映していない場合があります:
| システム | クラウドサービスプロバイダー | オンデマンド $/時間 | オンデマンド $/時間/デバイス | 平均MPTトレーニングBF16パフォーマンス [TFLOP/s/デバイス] | ドル当たりのパフォーマンス [ExaFLOP / $] |
|---|---|---|---|---|---|
| 8xA100-80GB | AWS | $40.79/時間 | $5.12/時間/GPU | 196 | 0.1378 |
| 8xA100-40GB | AWS | $32.77/時間 | $4.10/時間/GPU | 179 | 0.1572 |
| 4xMI250 | N/A | N/A | N/A | 152 | N/A |
| 8x Gaudi 2 | IDC | $10.42/時間 | $1.30/時間/デバイス | 240 | 0.6646 |
| 8xH100 | AWS | $98.32/時間 | $12.29/時間/GPU | 437 | 0.1280 |
表2:Amazon Web Services(AWS)とIntel Developer Cloud(IDC)で利用可能なさまざまなAIアクセラレータのトレーニングパフォーマンス/ドル
AWSとIDCが公開したオンデマンドの見積もり価格に基づき、IntelR GaudiR 2は、NVIDIA A100-80GBに対して平均4.8倍、NVIDIA A100-40GBに対して平均4.2倍、NVIDIA H100に対して平均5.19倍と、ドルあたりのトレーニングパフォーマンスが最も優れていることがわかりました。 繰り返しますが、これらの比較は、異なるクラウドプロバイダーの顧客固有の割引に基づいて異なる場合があります。
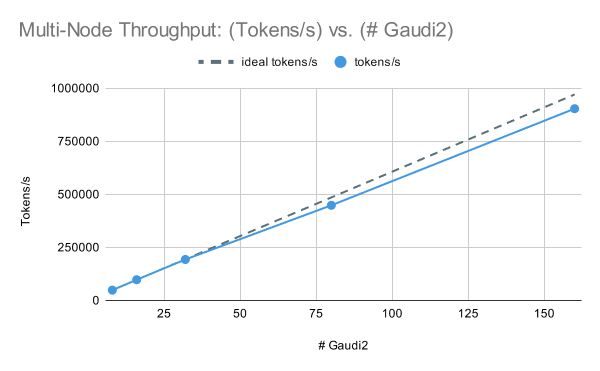
マルチノードの性能に話を移すと、IntelR GaudiR 2クラスターはLLMトレーニングにおいて優れたスケーリング性能�を発揮します。 図3では、MPT-7Bモデルを[1, 2, 4, 10, 20]ノードでグローバル訓練バッチサイズサンプルを固定して訓練したところ、1ノード(Gaudi 2の8倍)で262TFLOP/s/デバイス、20ノード(Gaudi 2の160倍)で244TFLOP/s/デバイスの性能が得られました。 これらの結果では、マルチノードのパフォーマンスを最大化するために、ZeRO Stage-3ではなくZeRO Stage-2のDeepSpeedを使用したことに注意してください。
トレーニングの設定とパフォーマンスの測定方法の詳細については、LLM Foundryトレーニングのベンチマークページをご覧ください。
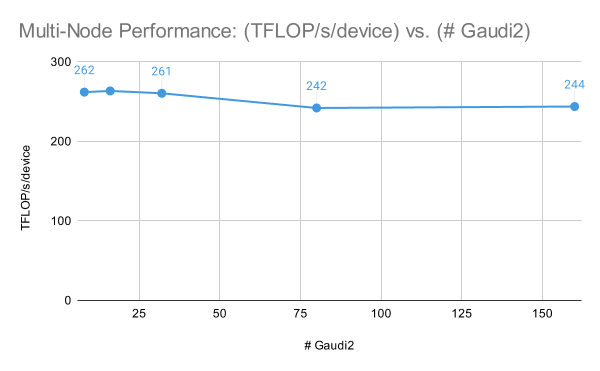
これらの結果に加え�、Intel のMLPerf Training 3.1が最大 384 倍の Gaudi 2 上で GPT3-175B をトレーニングしていることを考慮すると、私たちはより高いデバイス数でのIntelR GaudiR 2 のパフォーマンスを楽観視しており、今後より大規模なIntelR GaudiR 2/Gaudi 3 クラスターでの結果を共有できることを楽しみにしています。
LLMコンバージェンス
IntelR GaudiR 2上でのトレーニングの安定性をテストするため、チンチラ最適トークンバジェットを使用して、C4データセット上でMPT-1B、MPT-3B、MPT-7Bモデルをゼロからトレーニングし、インテル® Gaudiプラットフォーム上で高品質なモデルを正常にトレーニングできることを確認しました。
マルチノードのGaudi 2クラスタ上で、BF16混合精度とDeepSpeed ZeRO Stage-2で各モデルを学習させ、最大限のパフォーマンスを引き出しました。 1B、3B、7Bモデルは、それぞれ64、128、128のGaudi 2アクセラレータで学習されました。 全体的にトレーニングは安定しており、浮動小数点数による問題は見られませんでした。
最終的なモデルを標準的なICL(in-context-learning)ベンチマークで評価したところ、IntelR GaudiR 2で学習させたMPTモデルは、オープンソースのCerebras-GPTモデルと同様の結果を達成しました。 これらは、同じパラメータ数とトークンバジェットで学習されたオープンソースのモデル群であり、モデルの品質を直接比較することができます。 結果は表2参照。 すべてのモデルは、LLM Foundryの評価ハーネスを使用し、同じプロンプトを使用して評価されました。
これらの収束結果は、お客様がインテルAIアクセラレーターで高品質のLLMをトレーニングできることを確信させるものです。
![図4:MPT-[1B, 3B, 7B]の訓練損失曲線。](https://www.databricks.com/sites/default/files/inline-images/db-850-blog-image-5.png)
| モデル | パラメーター | トークン | アークシー | アークイー | ブールキュー | ヘラスワグ | PIQA | ウィノグラード | ウィノグランド | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| セレブラ-GPT-1.3B | 1.3B | 26B | .245 | .445 | .583 | .380 | .668 | .630 | .522 | .496 |
| インテル MPT-1B | 1.3B | 26B | .267 | .439 | .569 | .499 | .725 | .667 | .516 | .526 |
| セレブラ-GPT-2.7B | 2.7B | 53B | .263 | .492 | .592 | .482 | .712 | .733 | .558 | .547 |
| インテル MPT-3B | 2.7B | 53B | .294 | .506 | .582 | .603 | .754 | .729 | .575 | .578 |
| セレブラ-GPT-6.7B | 6.7B | 133B | .310 | .564 | .625 | .582 | .743 | .777 | .602 | .600 |
| インテル MPT-7B | 6.7B | 133B | .314 | .552 | .609 | .676 | .775 | .791 | .616 | .619 |
表2:MPT-[1B, 3B, 7B]とCerebras-GPT-[1.3B、 2.7B, 6.7B]。 各モデルのペアは、同じような構成で訓練され、標準的なコンテキスト内学習(ICL)タスクで同じようなゼロショット精度(高いほど良い)に達します
LLM推論
推論に移り、Optimum Habanaパッケージを活用し、Gaudi 2ハードウェア上でHuggingFace TransformerライブラリのLLMを使った推論ベンチマークを実行しました。 Optimum Habanaは、HuggingFace TransformerライブラリとGaudi 2アーキテクチャ間のシームレスな統合を促進する、効率的な仲介役です。 この互換性により、サポートされているHuggingFaceモデルをGaudi 2プラットフォーム上に直接、すぐに導入することができます。 注目すべきは、必要なパッケージがインストールされた後、LLaMa2モデルファミリーがGaudi 2環境と互換性があることが確認されたことです。
NvidiaのA100およびH100デバイス上での推論ベンチマークには、LLM用に最近導入された高度な推論ソリューションであるTRT-LLM(実験が行われた2023年11月16日現在のメインブランチ)を利用しました。 TRT-LLMは、Nvidiaハードウェア上のLLMの推論性能を最適化するために特別に設計されており、様々なNVIDIAライブラリから利用可能な最良のソフトウェアを活用しています。 これらの数値を得るために、NVidiaのTRT-LLMライブラリが提供する標準ベンチマーク設定を使用しています。 標準的なベンチマーク構成では、GPTアテンションとGEMMプラグインでFP16データ型を使用してLlama-70Bを実行します。 すべての比較数値は、両ハードウェアのBF16データ型で行われていることに注意してください。 FP8はどちらのハードウェアでも利用可能ですが、ここではベンチマークには使用していません。 FP8の実験結果は、将来のブログで公開したいと思います。
図5は、Llama2-70Bモデルのレイテンシ-スループット曲線を、プロファイルされた3つのハードウェア構成すべてについて示しています。 3つのハードウェア構成すべてで、同じモデルと同じ入出力長を使用しました。 すべてのシステムでBF16モデルのウェイトと計算を使用しました。 このプロットにより、ユーザーは設定されたレイテンシ目標に基づき、指定されたハードウェア構成で達成可能なスループットを推定することができます。 8x Gaudi 2は、この結果から8x A100-80GBと8x H100の間に位置しています。 しかし、バッチサイズが小さい場合(つまり、低レイテンシ領域)、8xGaudi 2は8xH100にかなり近づきます。 さらに分析を進めると、プリフィル時間(すなわちプロンプト処理時間)はH100よりもGaudi 2の方がはるかに遅いのに対し、Gaudi 2のトークン生成時間は後続の図に示すようにほとんど同じであることがわかります。 例えば、64人の同時ユーザーの場合、H100のプリフィル時間は1.62秒ですが、Gaudi 2では2.45秒です。 プリフィル時間の短縮は、ソフトウェアの最適化によって改善できますが、ピークFLOP数(H100は989.5、Gaudi 2は~400)に大きな開きがあるため、これはほぼ予想通りです。 次世代ガウディ3は、このギャップを埋めることが期待されています。
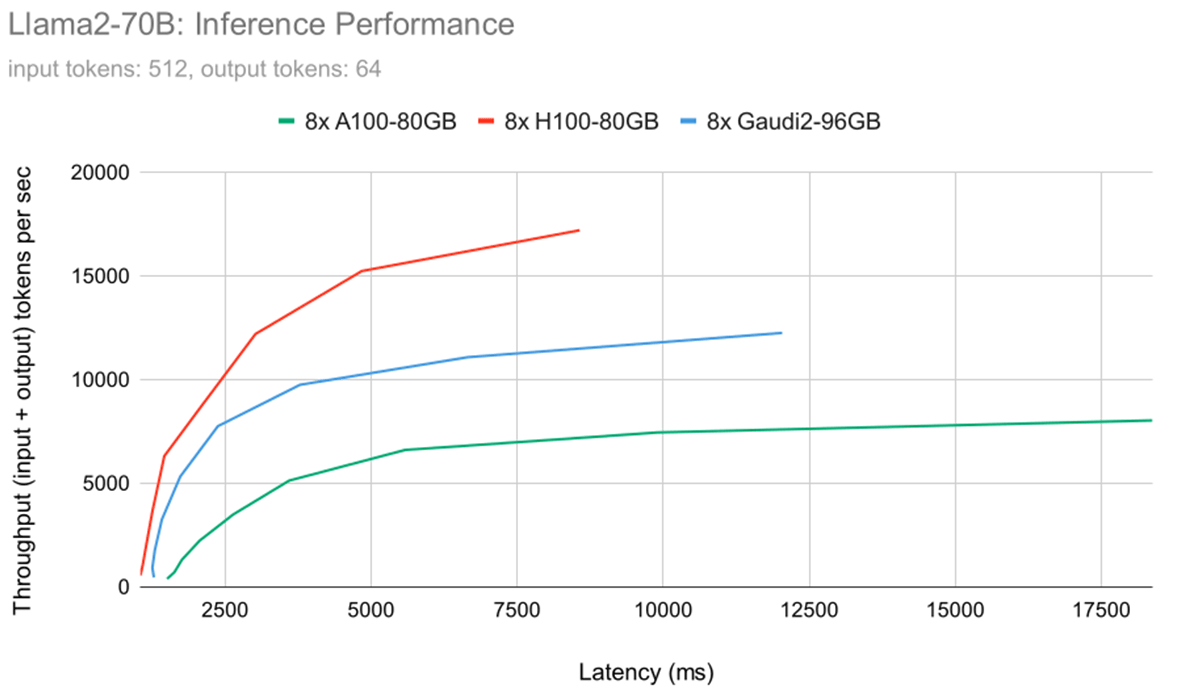
図6は、各ハードウェア・コンフィギュレーションがユーザーごとに1つのトークンを生成するのに要する時間を示しています。 特筆すべきは、重要な傾向が浮き彫りになっていることです:ユーザーあたりの出力トークンあたりの時間(TPOT)は、ほとんどのユーザー負荷シナリオにおいて、IntelR GaudiR 2とNVIDIA H100で±8%です。 ある設定ではGaudi 2の方が速く、別の設定ではH100の方が速いです。 一般的に、すべてのハードウェアにおいて、同時ユーザ数が増加すると、各トークンの生成にかかる時間も増加し、各ユーザのパフォーマンスが低下します。 この相関関係から、さまざまなユーザー負荷の下での、さまざまなハードウェア構成のスケーラビリティと効率に関する貴重な洞察が得られます。
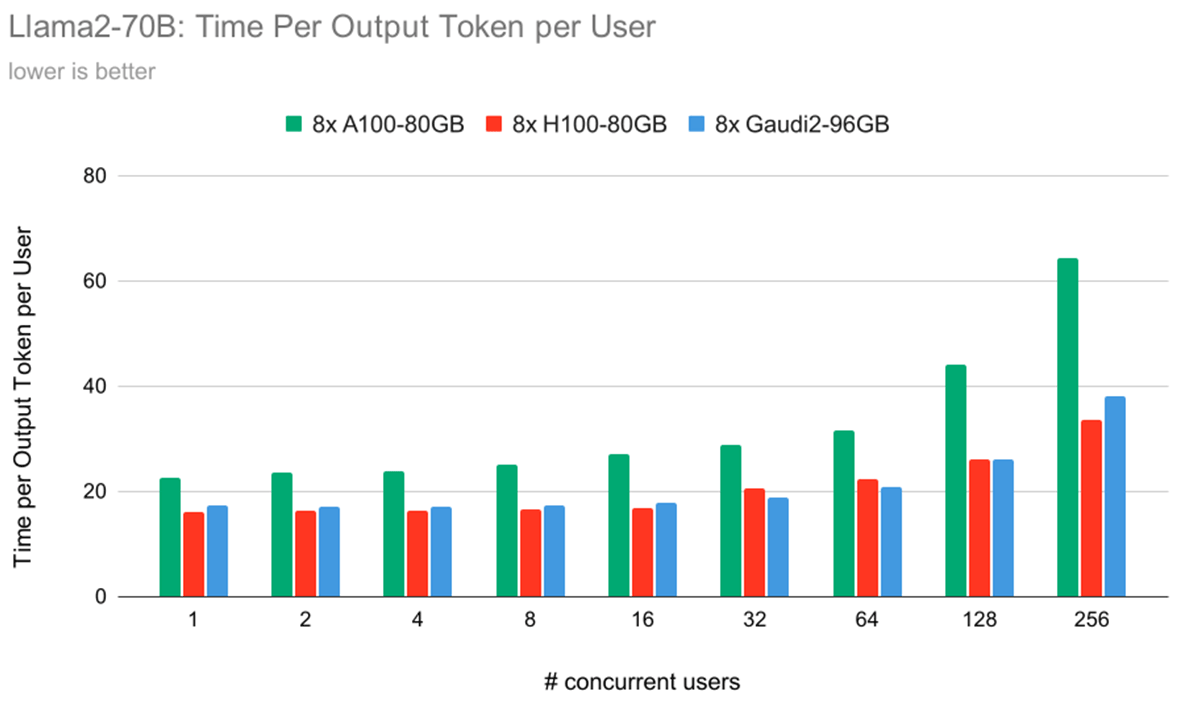
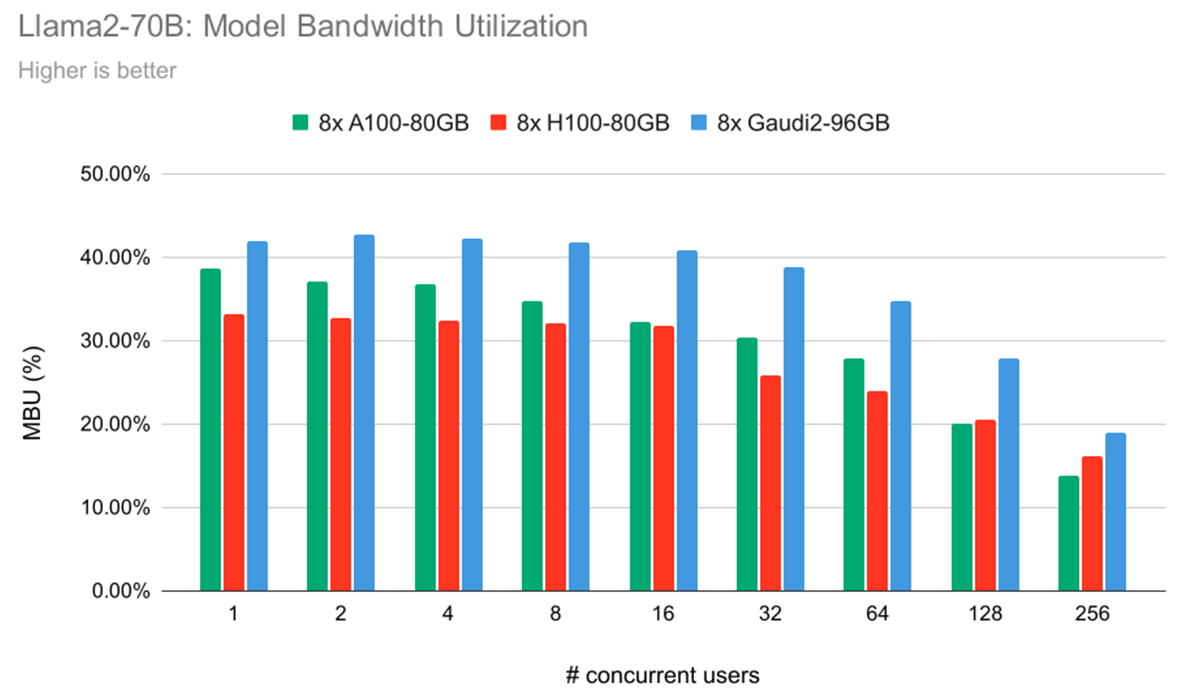
図7では、モデル帯域幅利用率(MBU)と呼ばれる指標を示しています。 MBUの概念については、以前のLLM推論ブログ記事で詳しく説明しています。 簡単に言うと、性能が主にメモリ帯域幅によって制約されるシナリオにおける効率の指標を示します。 より小さなバッチサイズでのトークン生成プロセスは、主に達成可能なメモリ帯域幅にかかっています。 この文脈での性能は、ソフトウェアとハードウェアが利用可能なピークメモリ帯域幅をいかに効果的に利用できるかに大きく影響されます。 実験では、IntelR GaudiR 2プラットフォームは、トークン生成タスクにおいてH100よりも優れたMBUを発揮することが確認されました。 これは、IntelR GaudiR 2が、A100-80GBやH100よりも、利用可能なメモリ帯域幅を活用する上で効率的であることを示しています。
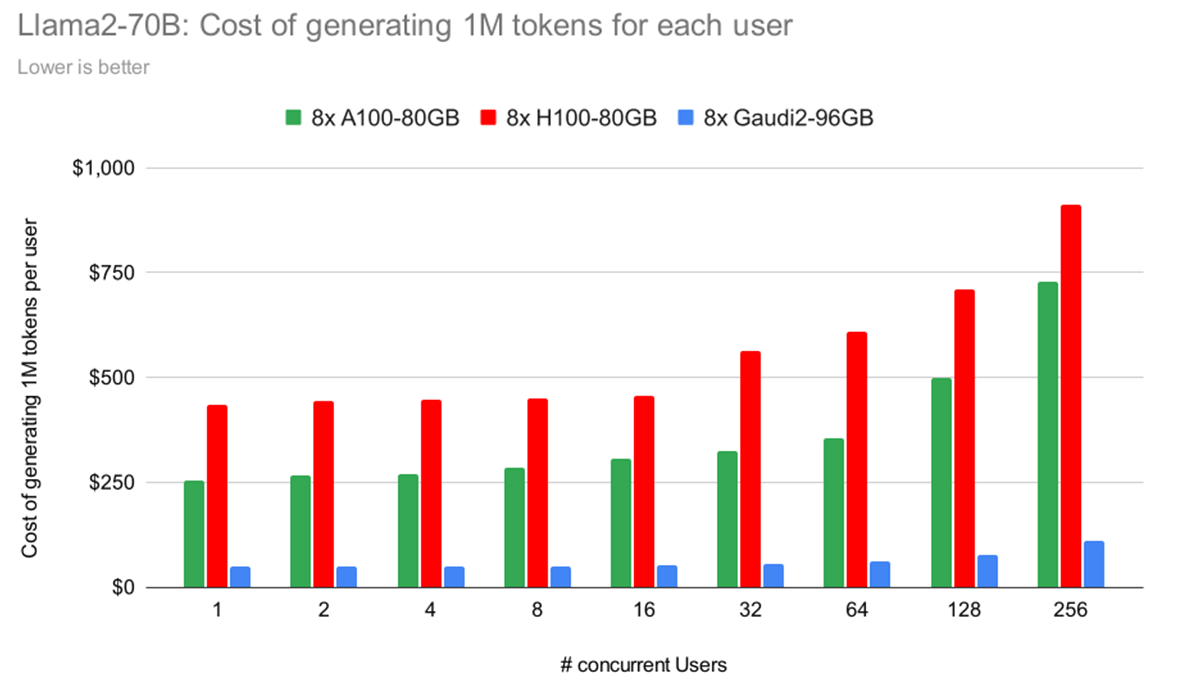
最後に、図 8では、異なるハードウェア・プラットフォーム間で、1 ユーザーあたり 100 万トークンを生成するコストを示しています。 例えば、4人の同時ユーザがいる場合、描かれている総コストは400万トークン分(ユーザ1人当たり100万トークン)です。 この計算は、表2に記載された価格詳�細に基づいています。
このデータから得られる主な洞察は以下の通り:
- H100はA100より高価ですが、その主な理由は1時間当たりのコストが2倍以上である一方、性能向上がこの増加に比例していないためです(図8に詳述)。
- Gaudi 2は、IDCが提供する競争力のある価格と、H100に匹敵する性能レベルにより、魅力的な選択肢として際立っています。
どのベンチマークもFP8(H100とGaudi 2で利用可能)や量子化を利用していないことは重要です。
次は何を?
このブログでは、IntelR GaudiR 2 が LLM のトレーニングと推論に最適であることをご紹介します。 Gaudi 2でのシングルノードとマルチノードのトレーニングはとてもうまくいきます。 チップあたりの性能は、私たちがテストしたアクセラレータの中で2番目に高く、AWSとIDCのオンデマンド価格を比較すると、ドルあたりの性能は最高です。 収束テストでは、チンチラ式の1B、3B、7Bパラメータモデルをゼロからトレーニングし、最終的なモデルの質は、参照オープンソース��モデルと同等か、それ以上であることを確認しました。
推論の面では、Gaudi 2は、すべての設定でNVIDIA A100を上回り、デコードレイテンシ(LLM推論の最もコストのかかるフェーズ)ではNVIDIA H100に匹敵し、その威力を発揮することがわかりました。 これは、IntelR GaudiR 2ソフトウェアとハードウェアスタックのおかげであり、NVIDIAの両チップよりも高いメモリ帯域幅利用率を達成しています。 別の言い方をすれば、2450GB/秒のHBM2Eメモリ帯域幅しかないGaudi 2は、3350GB/秒のHBM3帯域幅を持つH100に匹敵します。
PyTorchとオープンソースライブラリ(DeepSpeed、Composer、StreamingDataset、LLM Foundry、Habana Optimumなど)の相互運用性のおかげで、ユーザーは同じLLMワークロードをNVIDIA、AMD、 Intelで 実行したり、プラットフォーム間で切り替えることもできます。
Intel® Gaudi 3に期待することは、同じ相互運用性でありながら、さらに高いパフォーマンスを実現することです。 予想される公開情報のスペック(表1b参照)は、Intel Gaudi 3がすべての主要な競合他社(NVIDIA H100、AMD MI300X)よりも多くのFLOP/sとメモリ帯域幅を持つことを示唆しています。 Gaudi 2のトレーニングや推論の利用率が非常に高いことを考えると、Gaudi 3には非常に期待しています。 インテル® Gaudiアクセラレーターとさらに大規模なトレーニングに関する今後のブログにご期待ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。