Delta Lakeを用いたバーコード・トレーサビリティによるリコール管理
によって マックス・ケーラー による投稿
最近のデータによると、製品の欠陥によるリコールキャンペーンは増加の一途をたどっている。さらに、風評リスクや事業継続リスクは、各リコールが「底なしの穴」であることのマイナス面の可能性を示している。製品リコールは、あらゆる規模の伝統的な製造企業だけの問題ではなく、製薬会社など製品を生産するあらゆる企業に関連する。この記事では、複数の生産工場の上にある中央のデルタ湖が、問題解決のサイクルタイムを短縮することで、影響を受ける被害を劇的に減らすのに役立つ理由を論じる。さらに、運用上の欠陥を検出するためにプロセスグラフを走査するための実例を含むソリューション・アクセラレータを紹介する。
効果的なリコール管理のためのデータ分析の課題と可能性
リコールについて
メーカーが製品を生産し、顧客に出荷している状況において、重大な品質問題が発見され、どちらか一方から製品の返品を要求されることを製品リコールという。例えば、メルセデスは燃料ポンプに欠陥があったとして約14万4千台をリコールし(こちらを参�照)、BSHは爆発の恐れがあるガスコンロを17万台リコールした(こちらを参照。リコールは、製品メーカー、その顧客、サプライヤーなど、バリューチェーンの広範囲に影響を及ぼす可能性がある。
想定される損害は以下の通りである:
- 不適合コスト(NCC): NCCとは、品質問題に起因する直接的なコストである。例えば、スクラップコスト、ダウンタイムコスト、保証クレーム、リコールコストなどである。
- 風評リスク: 品質問題の結果、製造業者は顧客の品質認識を低下させる可能性がある。その結果、売上が減少する可能性がある。
- 事業継続リスク: 問題解決段階において、製造者はさらなる損害を防ぐために、製品の製造と顧客への出荷を停止することを決定するかもしれない。これはNCCと完全に直交するものではないことに注意されたい。
Statistaによると、ドイツのような製造業集約型経済では、近年リコールが増加している。さらに、アリアンツの調査(こちらを参照)によれば、「重大な」リコールは1,050万ユーロの損害につながる。しかし、ドミノ効果はこの損害をもっと大きくする可能性がある。自動車、食品・飲料、IT・��エレクトロニクスなど、影響を受ける業界は多岐にわたる。
リコールの管理には2つの意味がある。
- 製品がすでに顧客に出荷されている場合、影響を受けた製品のメーカーは、業務の継続性を確保するために、運用上の問題をできるだけ早く解消し、説明しなければならない。さらに、数個のバーコードだけが影響を受けているにもかかわらず、顧客はしばしば全時間範囲をリコールする。問題をデータで説明し、それによってどのバーコードが影響を受けたかを証明することで、損害を劇的に減らすことができる。
- 生産工程で問題が発生した場合、またはサプライヤーの原材料に既知の欠陥がある場合、影響を受ける製品のメーカーは、影響を受ける生産工程とバーコードをできるだけ早く特定し、運用上の問題を排除しなければならない。
どちらのケースでも、バーコードレベルで製造バリューチェーンを横断し、運用データで問題を説明する必要がある。 データは効果的で迅速なリコール管理の鍵である!
”正しい”データの発見と分析における問題点
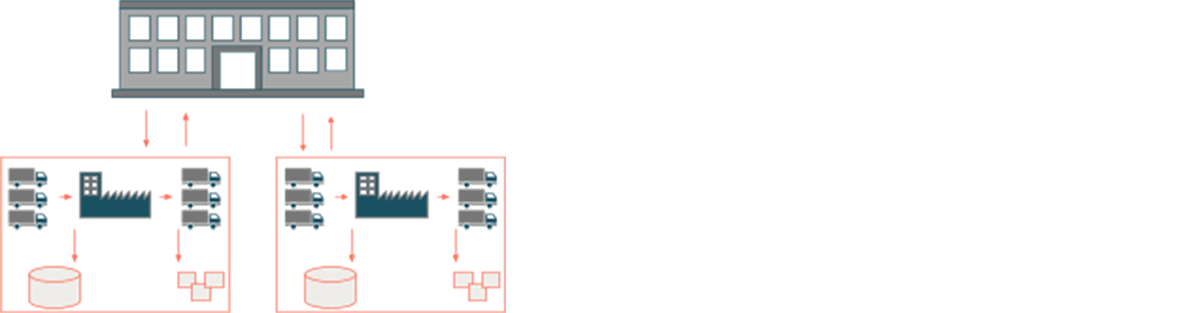
中央部門によって管理される複数の工場を持つ組織構造におけるデータ・ランドスケープには問題がある。製品が組み立てられ、完成品が顧客に出荷される(トラックが出荷する)前に、各工場に原材料が供給されると仮定しよう(トラックが入ってくることを示す)。つ��のオペレーション・システムが問題となる。一方には、原材料から完成品までの製造プロセスを制御する製造実行システム(MES)があり、他方には、完成品の物流ステップを制御する計画システム(多くの場合SAP)がある。2つの異なるシステムは、1つの工場内でバリューチェーンを横断する際に課題をもたらす。複数の工場があれば、工場の数だけこの問題の大きさが増す。
より正確には以下の課題を示す:
- セントラルビューがない ー 工場ローカルMESはデータのサイロを構築し、セントラル部門は、セントラルレベルから工場レベルまで自動でドリルダウンするのではなく、各工場の製品を独立して走査しなければならない。
- データ・リテラシーの欠如 ー データを分析するプラント・地元の専門家の数が少ない。 中央部門は各工場の詳細について疎いことが多く、IT 、工場の稼動データを理解し分析することは困難である。
- スケーラビリティの欠如 ー 前述の運用システムは、クラウドに移行するための最低限の信頼性(地域によっては障害が発生することが知られている)が与えられていないため、オンプレミスのデータベースが対象となることが多い。 一方、従来のオンプレミス・システムのストレージや計算リソースは独立して拡張できないため、データ中心のユースケースの導入を妨げている。
- 盲点 ー オンプレミスシステムでは、非構造化データやストリーミングデータに問題があり、運用上の盲点となっている。
レイクハウス

前述の課題を軽減するために、多くのメーカーはDatabricksを使って複数の生産工場の上にLakehouseを構築している。複数の生産工場の上にある"レイクハウス" は、工場ローカルの業務システムの標準化された "コピー "である。主にクラウド・オブジェクト・ストレージ上のParquetファイルで構成され、コスト効率が高く、拡張性に優れている。これらのファイルの上にメタデータ・レイヤーを置くことで、パフォーマンスの高いデータ・クエリーと変換が可能になる。データ・アクセス制御や監査といったデータ・ガバナンス機能は、Unityカタログの助けを借りて簡単に適用できる。このアーキテクチャは、データウェアハウス、ダッシュボード、機械学習、データサイエンス、データエンジニアリングなど、データ集約的な製造業のユースケースのための統一プラットフォームを表している。メーカーにとって、これは大きなメリットとなる:
- 全工場の生産データを収集することで、セントラル・ビューを提供する。中央から工場レベルへのドリルダウンは、自動化された方法で容易に可能である。
- 標準化されたデータ・コピーにより、1つの工場内の特定のリソースへの依存を減らすことができる。
- クラウド自体が、ストレージと計算リソースの独立したスケーラビリティを提供するため、データ集約的なユースケースの導入が劇的に容易になる。
- あらゆる形式のデータを、クラウドオブジェクトストレージにコスト効率よく保��存することができる。
- ストリーミング・イベントは、低レイテンシーでデルタ・レイクに取り込むことができる。
この記事ではリコールに焦点を当てているが、複数の生産工場の上にレイクハウスを設置するメリットはもっと大きい。 例えば、複数工場の設備全体の効率化、生産品質の積極的な監視、製品納入の追跡などがある。 この記事では、構造化された問題解決、すなわちバーコードのトレーサビリティのための中心的な方法論である、製造されたバーコードごとに適切なタイミングで適切なデータを組み合わせることに焦点を当てる。
バーコード・トレーサビリティの3つの例と、それに取り組むためのシンプルなデータモデル
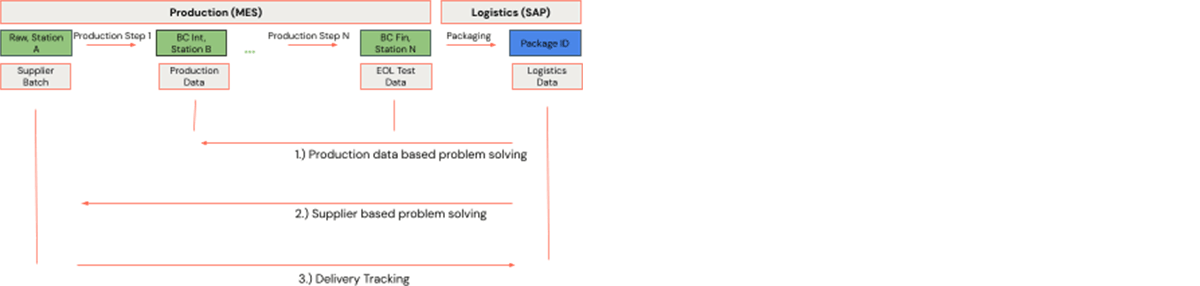
生産工程は、製品が処理されるステーションで構成される。製品はバーコードで表される。各バーコードは、1つの工場内の1つのステーションで一意である。メーカーの生産工程は、サプライヤーから届く原材料から始まる。バーコードは、例えば組立工程の結果として、生産工程に沿って変更されることがある。各ステーションでは、サプライヤーバッチ、機械データ、テストデータなど、さらなるデータが生成される。上記のプロセスは、分割や結合が含まれる可能性があるため、単純化されている。ロジスティクスのステップもまさにこのように見ることができる。ただ、作業ステップはロジスティクスに特化したもの、例えばパッケージングであり、パッケージIDがプロセスに入ることになる。生産ステップと物流ステップのシーケンスは、製造プロセスグラフを形成する。この設定で、3つの例を考える:
- 生産データに基づく問題解決 メーカーがバーコードを生産し、顧客に出荷する。顧客は、かなり多くの製品に問題があることを発見し、生産時間の全範囲をリコールした。製造業者は生産上の欠陥をなくし、実際に影響を受けたバーコードの数が限られていることをデータで理想的に説明しなければならない。この目的のために、メーカーは既知の問題がある限られた数のバーコードを取り出し、その生産工程における関連する生産データを分析する。関連データは、稼働中の生産工程をさかのぼって追跡することで特定される。これがバックワードトレーサビリティである。
- サプライヤーベースの問題解決: これは最初の例と似ているが、後方トレーサビリティが、原材料が生産に入る生産工程の一番最初まで実行されるだけである。分析の結果、すべての問題が1つの同じサプライヤーのバッチにさかのぼることができることが判明した場合、これは疑わしいことであり、さらなるサプライヤーの品質分析につながる可能性がある。
- 配送追跡: あるサプライヤーが、完成品が顧客に出荷される前に、メーカーの生産工程に入る原材料を出荷する。サプライヤーは、いくつかのバーコードが望ましい仕様に合致していないことを発見する。不運なことに、その影響を受けた原材料はすでにメーカーの製品に組み込まれている。製造業者は、影響を受けるバーコードと製造工程をできるだけ早く特定し��なければならない。該当するバーコードは、稼働中の生産工程を前方にたどることで特定される。これが前方トレーサビリティである。
幸いなことに、稼働中の生産プロセスではデータが生成される。 私たちはこれらのデータをさまざまな方法でモデル化することができる。 この記事では、前述の3つのユースケースを解決することができる非常にシンプルなテーブルの助けを借りて、データのモデリングを示す。
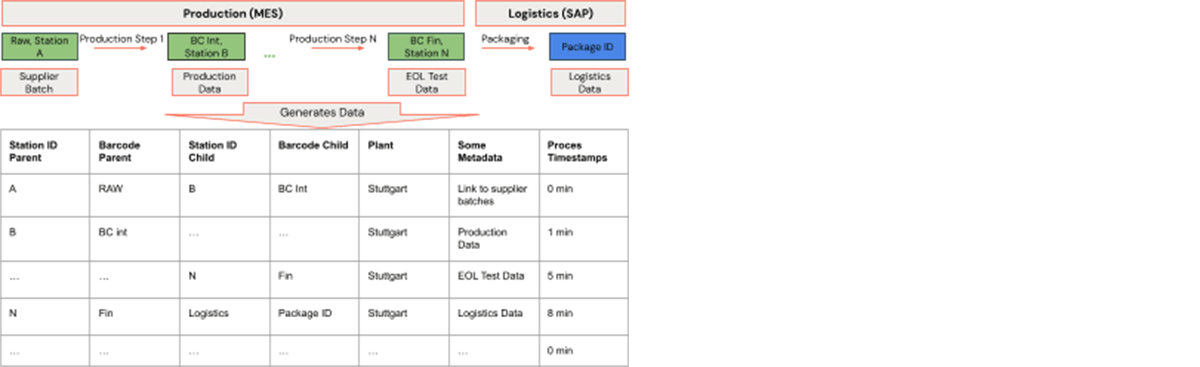
各工程ステップにおいて、ステーションID、バーコード、プラントの組み合わせが一意の親を形成し、その親はこれら3つの項目の別の組み合わせに組み立てられる。工程にはタイムスタンプがあり、プレスフィットカーブなどの他の生産データもリンクできる。グラフの用語では、各行はエッジである。バーコード、ステーションID、工場の組み合わせが頂点を形成する。すべての頂点は、エッジの集合に対して簡単に作成できる。この頂点と辺のデータは、製造工程グラフのデータ表現を形成する。つまり、バーコードのトレーサビリティとは、グラフ内の特定の頂点の近傍を見つけることなのである。
バーコード・トレーサビリティ・ソリューション・アクセラレータ
Databricks ソリューションアクセラレータは、顧客のユースケース開発を加速させるために作られたガイドである。これらは、ソリューションと業界に特化した、完全に機能するノートブックとベストプラクティスで構成されている。
この記事では、バーコード・トレーサビリティのためのソリューション・アクセラレータを簡単に紹介する。より多くの説明とコードはGit Repoにある。ここでは、基本的なステップ、つまり上記の3つの例のそれぞれに関連するコード・スニペットについて説明する。それぞれの例では、グラフをトラバースするための異なる方法を示している。これは必須ではないが、グラフをトラバースするための様々な方法を示すものである。各手法の可能性と限界についての議論は、ソリューション・アクセラレータのノートブックに概説されている。
ソリューション・アクセラレータは、実際の実例に基づいていることに注意されたい。この記事では、具体的な生産ステップや製品から抽象化し、代わりにバーコードのトレーサビリティに取り組むために適用できるコードと方法論に焦点を当てる。
製造工程グラフの作成
プロセスは以下の通りである。

"src" と"dst" の列がグラフの親と子である。 これらは、バーコード、ステーションID、工場を連結した文字列でできている。 その他のデータはカラムでリンクされている。 �プロセスの開始時刻と終了時刻はタイムスタンプとして記録される。 そうすれば、グラフフレームは簡単に作成できる。
例1:生産データに基づく問題解決
この例では、顧客から入力された一連のバーコードがあり、特定のステーション、つまりターニング・ステーションまでさかのぼりたい。 そのためにモチーフ・ファインディングを適用する。 まず、Breadth-first searchを使って、いくつかのバーコードから検索パターンを導き出す。
この結果は、検索する特定の部分グラフを抽象化したもので、辺で結ばれた頂点で記述される有効な検索パターンに簡単に変換できる。
次のステップは、フィルター式を導き出すことだ。 顧客は、問題が観察された2、3のバーコードについて報告しただけであることを考えれば、これは簡単なことである。
疑わしいプロダクション・チェーンはすべて、次のようにして見つけることができる。
この出力から関連する部分を選択すると、顧客が報告した疑わしいバーコードごとに、ターニング・ステーションでの疑わしいバーコードすべてと、ターニング・プロセスの開始時刻と終了時刻を�含む表が得られる。ターニング・ステーションは無限の時系列を記録しているため、タイムスタンプを使用して系列の疑わしい部分を導き出すことができ、問題解決はこれらの系列の目視検査に集約される。

例2:サプライヤー・ベースの問題解決
この例は最初の例と似ている。違いは、サプライヤーまでさかのぼることである。また、Motif Findingの手法を適用することもできる。異なる方法論を実証するために、Pandas UDFを使ってシングルスレッドのPythonコードを並列化する。グラフを、内部ではつながっているが全体ではつながっていないコンポーネントに分解することができれば、各コンポーネント内で独立にトレーサビリティを実行すれば十分である。すべてのコンポーネントを見つけた後、まず関連するコンポーネントにサブセットし、グラフサイズを大幅に縮小する。次のステップでは、シングルスレッドPython関数を適用して、各コンポーネント内のトレーサビリティを行い、Pandas UDFを使用して並列化する。
まず、すべての連結成分を見つける。
関連するコンポーネントへのサブセットは、すべての疑わしいバーコードを行ごとにリストしたテーブルとの内部結合の問題である。
例えば、各コンポーネントの後方トレーサビリティを行う Python 関数があるとする。
Pandas UDFを適用するには、次のようにします。
その結果、サプライヤーのすべての疑わしいバーコードとそれぞれのバッチが表となり、さらなる問題解決に使用される。
例3:配達追跡
配送追跡は、バリューチェーンの前方追跡である。バリューチェーンの一番最初にあるサプライヤーは、いくつかの疑わしいバーコードについて報告し、メーカーはすでにその原材料を製品に組み込んでいる可能性が高い。このユースケースは、製造業者のバリューチェーンの中で、さらに先のバーコードを特定することである。このユースケースは、Motif Finding、または前の2つのサブセクションで説明したPandas UDFとPython関数で解決できる。Solution Acceleratorでは、AggregateMessagesを介したメッセージパッシングの手法を適用する。これは、頂点間でメッセージを送信し、各頂点のメッセージを集約するための入門書である。まず、頂点間で送信するメッセージを定義する。
頂点に沿って繰り返しメッセージを送り、集約することで、完全なグラフを横断することができる。
これにより、各原料に関連するすべてのバーコードを含む表が簡単に得られる。
バーコード・トレーサビリティを始めよう
最近のデータによると、リコールの件数は増加し、記録された既知の事例はそれぞれ平均して数百万ドルの損害となっている。このことは、最も効果的な方法でリコールを管理する必要性を裏付けている。異なるオペレーション・システムを持つ異なる工場は、バーコードによるトレーサビリティとそれによる効果的な分析を妨げるデータのサイロ化をもたらす。複数の工場の上にある中央のデルタ・レイクは、製品の欠陥の集中分析への扉を開く。私たちのソリューション・アクセラレータを試して、あなたの組織でバーコード・トレーサビリティを構築し、問題解決のサイクルタイムを劇的に短縮することで、製品欠陥のデータ分析の有効性を向上させよう。
私たちのソリューション・アクセラレータを試して、あなたの組織でバーコード・トレーサビリティを構築し、問題解決のサイクル・タイムを劇的に短縮することによって、製品の欠陥に関するデータ分析の有効性を高めてください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。