PySpark向けPandas UDFの紹介
PySparkでネイティブPythonコードを高速に実行する方法。
によって Li Jin による投稿
Free Edition は Community Edition に代わり、追加機能が無料でご利用いただけるようになりました。今すぐ Free Edition をお試しください。
注: Spark 3.0 では、新しい pandas UDF が導入されました。詳細については、次のブログ記事をご覧ください: Apache Spark 3.0 の今後のリリースにおける新しい Pandas UDF と Python 型ヒント
これは、ニューヨークの Two Sigma Investments, LP のソフトウェアエンジニアである Li Jin によるゲストコミュニティ投稿です。このブログは Two Sigma にも掲載されています。
更新情報: このブログは、いくつかの変更を含めるために 2018 年 2 月 22 日に更新されました。
このブログ記事では、Apache Spark 2.3 の今後のリリースで導入される Pandas UDF (別名 Vectorized UDF) 機能を紹介します。これにより、Python でのユーザー定義関数 (UDF) のパフォーマンスと使いやすさが大幅に向上します。
過去数年間、Python はデータサイエンティストの デフォルト言語 となりました。 pandas、numpy、statsmodel、scikit-learn などのパッケージは広く採用され、主流のツールキットとなっています。同時に、Apache Spark はビッグデータ処理のデファクトスタンダードとなりました。データサイエンティストがビッグデータの価値を活用できるようにするため、Spark はバージョン 0.7 で Python API を追加し、ユーザー定義関数をサポートしました。これらのユーザー定義関数は 1 行ずつ処理されるため、シリアライゼーションと呼び出しのオーバーヘッドが高くなります。その結果、多くのデータパイプラインでは、UDF を Java や Scala で定義してから Python から呼び出しています。
Apache Arrow を基盤とする Pandas UDF は、両方の長所をもたらします。つまり、Python だけで低オーバーヘッドで高性能な UDF を定義できます。
Spark 2.3 では、スカラーとグループ化マップの 2 種類の Pandas UDF があります。次に、4 つの例プログラムを使用してそれらの使用方法を説明します: プラスワン、累積確率、平均の減算、最小二乗線形回帰。
スカラー Pandas UDF
スカラー Pandas UDF は、スカラー操作をベクトル化するために使用されます。スカラー Pandas UDF を定義するには、pandas.Series を引数として受け取り、同じサイズの別の pandas.Series を返す Python 関数に @pandas_udf で注釈を付けるだけです。以下に、プラスワンと累積確率の 2 つの例を使用して説明します。
プラスワン
v + 1 を計算することは、行ごとの UDF とスカラー Pandas UDF の違いを示す簡単な例です。このシナリオでは、組み込みの列演算子の方がはるかに高速に動作することに注意してください。
行ごとの UDF を使用:
Pandas UDF を使用:
上記の例では、行ごとの UDF "plus_one" と、同じ "プラスワン" 計算を実行するスカラー Pandas UDF "pandas_plus_one" を定義しています。UDF の定義は、関数デコレータ "udf" と "pandas_udf" を除いて同じです。
行ごとのバージョンでは、ユーザー定義関数は double "v" を受け取り、"v + 1" の結果を double として返します。Pandas バージョンでは、ユーザー定義関数は pandas.Series "v" を受け取り、"v + 1" の結果を pandas.Series として返します。"v + 1" は pandas.Series でベクトル化されているため、Pandas バージョンは行ごとのバージョンよりもはるかに高速です。
スカラー pandas UDF を使用する場合、次の 2 つの重要な要件があることに注意してください。
- 入力および出力シリーズは同じサイズである必要があります。
- 列が複数の
pandas.Seriesに分割される方法は Spark の内部処理であるため、ユーザー定義関数の結果は分割に依存しない必要があります。
累積確率
この例では、スカラー Pandas UDF のより実用的な使用方法を示します。これは、scipy パッケージを使用して、正規分布 N(0,1) の値の 累積確率を計算します。
stats.norm.cdf はスカラー値と pandas.Series の両方で機能し、この例は行ごとの UDF でも記述できます。前の例と同様に、Pandas バージョンは "パフォーマンス比較" セクションで示されるように、はるかに高速に実行されます。
グループ化マップ Pandas UDF
Python ユーザーは、データ分析におけるスプリット・アプライ・コンバイン パターンにかなり精通しています。グループ化マップ Pandas UDF はこのシナリオのために設計されており、グループごとのすべてのデータ、たとえば「各日付について、この操作を適用する」という操作を行います。
グループ化マップ Pandas UDF は、まず Spark DataFrame を groupby 演算子で指定された条件に基づいてグ��ループに分割し、各グループにユーザー定義関数 (pandas.DataFrame -> pandas.DataFrame) を適用し、結果を結合して新しい Spark DataFrame として返します。
グループ化マップ Pandas UDF は、スカラー Pandas UDF と同じ関数デコレータ pandas_udf を使用しますが、いくつかの違いがあります。
- ユーザー定義関数の入力:
- スカラー:
pandas.Series - グループ化マップ:
pandas.DataFrame
- スカラー:
- ユーザー定義関数の出力:
- スカラー:
pandas.Series - グループ化マップ:
pandas.DataFrame
- スカラー:
- グルーピングセマンティクス:
- スカラー: グルーピングセマンティクスなし
- グループ化マップ: "groupby" 句で定義
- 出力サイズ:
- スカラー: 入力サイズと同じ
- グループ化マップ: サイズは任意
- 関数デコレータの戻り値の型:
- スカラー: 返される
pandas.Seriesの型を指定するDataType - グループ化マップ: 返される
pandas.DataFrameの各列の名前と型を指定するStructType
- スカラー: 返される
次に、グループ化マップ Pandas UDF のユースケースを説明するために、2 つの例を説明します。
平均の減算
この例では、グループごとに平均を減算するという、グループ化マップ Pandas UDF の簡単な使用方法を示します。
この例では、グループごとに v の各値から v の平均を減算します。グルーピングセマンティクスは "groupby" 関数によって定義されます。つ��まり、ユーザー定義関数への各入力 pandas.DataFrame は同じ "id" 値を持ちます。このユーザー定義関数の入力および出力スキーマは同じであるため、スキーマを指定するためにデコレータ pandas_udf に "df.schema" を渡します。
グループ化マップ Pandas UDF は、ドライバ上でスタンドアロン Python 関数としても呼び出すことができます。これはデバッグに非常に役立ちます。たとえば、次のようになります。
上記の例では、まず Spark DataFrame の小さなサブセットを pandas.DataFrame に変換し、次にそれに対して subtract_mean をスタンドアロン Python 関数として実行します。関数ロジックを確認した後、データセット全体で UDF を Spark で呼び出すことができます。
最小二乗線形回帰
最後の例では、グループごとに OLS 線形回帰を実行する方法を statsmodels を使用して示します。各グループについて、統計モデル Y = bX + c に従って、X = (x1, x2) のベータ b = (b1, b2) を計算します。
This example shows that grouped map Pandas UDFs can be used with any arbitrary Python function: pandas.DataFrame -> pandas.DataFrame. The returned pandas.DataFrame can have a different number of rows and columns than the input.
Performance Comparison
Lastly, we want to show a performance comparison between row-at-a-time UDFs and Pandas UDFs. We ran micro benchmarks for three of the above examples (plus one, cumulative probability and subtract mean).
Configuration and Methodology
We ran the benchmark on a single-node Spark cluster on Databricks Community Edition.
Configuration details:
Data: A 10M-row DataFrame with an Int column and a Double column
Cluster: 6.0 GB Memory, 0.88 Cores, 1 DBU
Databricks runtime version: Latest RC (4.0, Scala 2.11)
For the detailed implementation of the benchmark, check the Pandas UDF Notebook.
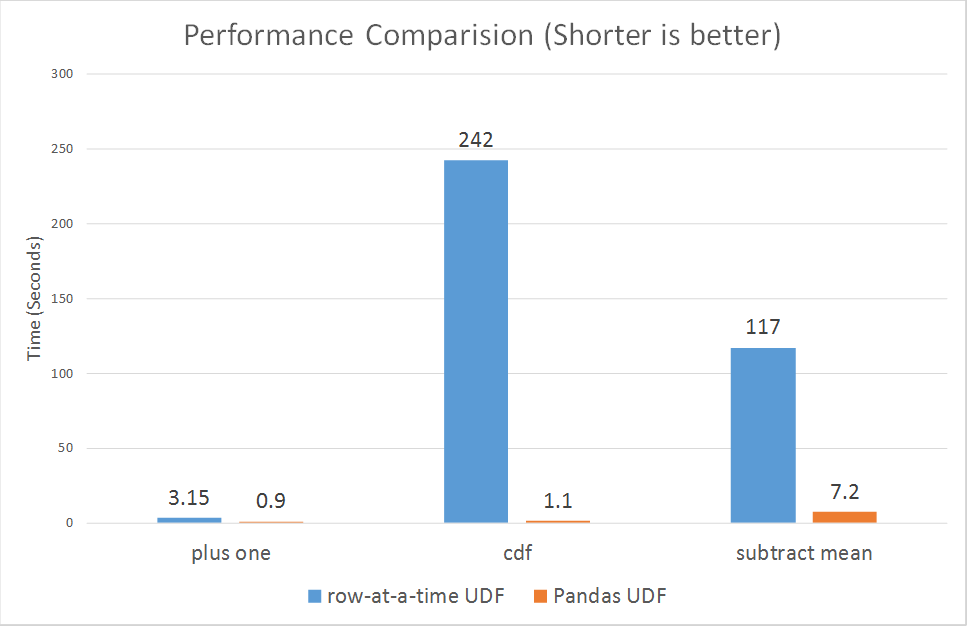
As shown in the charts, Pandas UDFs perform much better than row-at-a-time UDFs across the board, ranging from 3x to over 100x.
Conclusion and Future Work
The upcoming Spark 2.3 release lays the foundation for substantially improving the capabilities and performance of user-defined functions in Python. In the future, we plan to introduce support for Pandas UDFs in aggregations and window functions. The related work can be tracked in SPARK-22216.
Pandas UDFs are a great example of the Spark community effort. We would like to thank Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li, and many others for their contributions. Finally, special thanks to the Apache Arrow community for making this work possible.
What's Next
You can try the Pandas UDF notebook, and this feature is now available as part of Databricks Runtime 4.0 beta.
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。