製造業における洞察:低レイテンシーのセンサーデータでのストリーミング積分の計算
によって TJ Cycyota 、 バラト・ペリヤサミー による投稿
データエンジニアは、複雑でノイズの多いデータから洞察を引き出すために、数学と統計学に頼っています。 最も重要な領域は微積分です。微積分では、積分(最も一般的には曲線下の面積を計算すること)が得られます。 これは、レートを表す多くのデータを統合して有用な測定値を生成できるため、エンジニアにとって便利です。 例えば
- ポイント・イン・タイムのセンサーの測定値は、一度統合されると、時間加重平均を生成することができます。
- 車両速度の積分は、移動距離の計算に使用できます。
- データ転送量は、ネットワーク転送速度を統合したものです。
もちろん、ほとんどの生徒はある時点で積分の計算方法を学びますし、計算自体もバッチで静的なデータでは簡単です。 しかし、�機器のパフォーマンスしきい値に基づくアラートの設定や、ロジスティクスのユースケースにおける異常の検出など、ビジネス価値を実現するために低レイテンシーで増分的な積分計算を必要とする一般的なエンジニアリングパターンがあります。
| ポイント・イン・タイム測定: | 計算に使用される積分: | 低レイテンシーのビジネスユースケース & 価値 |
|---|---|---|
| 風速 | 時間加重平均 | コスト回避のため、動作しきい値で精密機器をシャットダウン |
| 速度 | 距離 | ロジスティクスの遅れを予測して顧客に警告 |
| 転送レート | 総輸送量 | ネットワーク帯域幅の問題や異常なアクティビティを検出 |
積分の計算は、実世界のセンサーデータに取り組む現代のデータエンジニアにとって、重要なツールです。 これらはほんの一例に過ぎず、以下に説明するテクニックは多くのデータエンジニアリングパイプラインに適応できますが、このブログの残りの部分では、時間加重平均を導き出すために実世界のセンサーデータでストリーミング積分を計算することに焦点を当てます。
豊富なセンサー
60ヘルツで送信される風力タービンの温度センサーは、1日に500万以上のデータポイントを生成します。 これをタービン1基あたり100個のセンサーで計算すると、1台の装置で1日に数GBのデータが得られることになります。 また、ほとんどの物理的プロセスでは、各測定値は前の測定値とほぼ同じである可能性が高いことを考慮してください。
今日のIoT生産システムの多くは、この膨大なデータを抽出する方法を備えています。 多くのセンサー、またはその中間システムは、あるバイナリ状態から別のバイナリ状態への変化や、前回と5%異なる測定値など、"興味深い何か" が発生した場合にのみ測定値を送信するように設定されています。 したがって、データエンジニアにとっては、新しい測定値がないこと自体が重要である場合もあれば(システムには何も変化がない)、現場でのネットワーク停止によりデータの到着が遅れたことを意味する場合もあります。
機器故障の分析と予防を担当するサービスエンジニアのチームにとって、タイムリーな洞察を導き出せるかどうかは、大量のセンサーデータを使用可能な分析テーブルに変換するデータエンジニアにかかっています。 私たちは、各ロケーション/センサーのペアについて、値の時間加重平均で10分間隔にセンサーの測定値の狭い、付加のみのストリームを集約する要件に焦点を当てます:
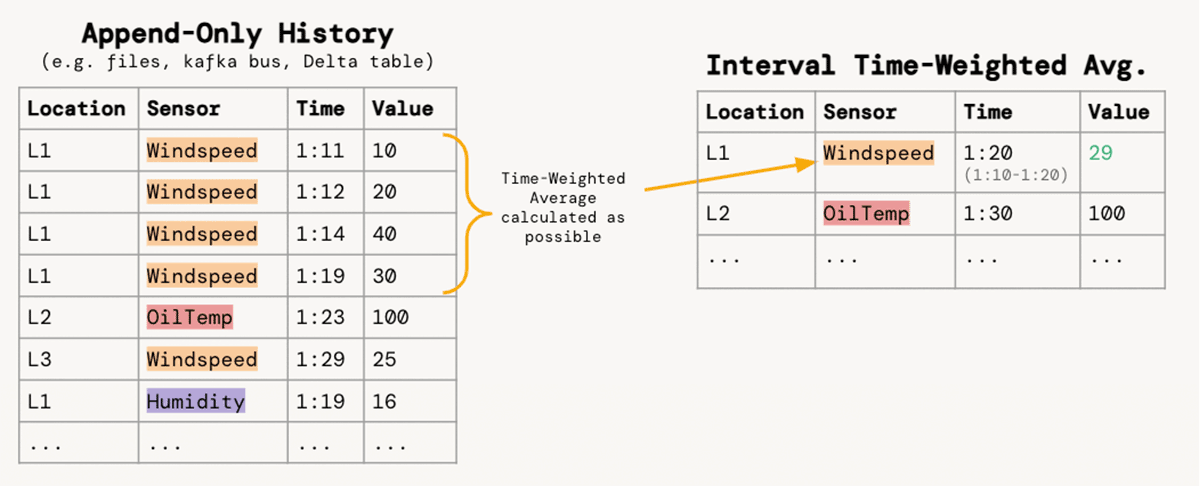
余談:積分の復習
簡単に言えば、積分とは曲線の下の面積のことです。 方程式を近似し、任意の曲線の積分を記号的に計算するロバストな数学的手法がありますが、リアルタイムのストリーミングデータの目的では、データが時間と共に到着するため、より効率的に計算できるリーマン和を使用した数値近似に依存します。 積分の応用がなぜ重要かを説明するために、以下の例を考えてみましょう:
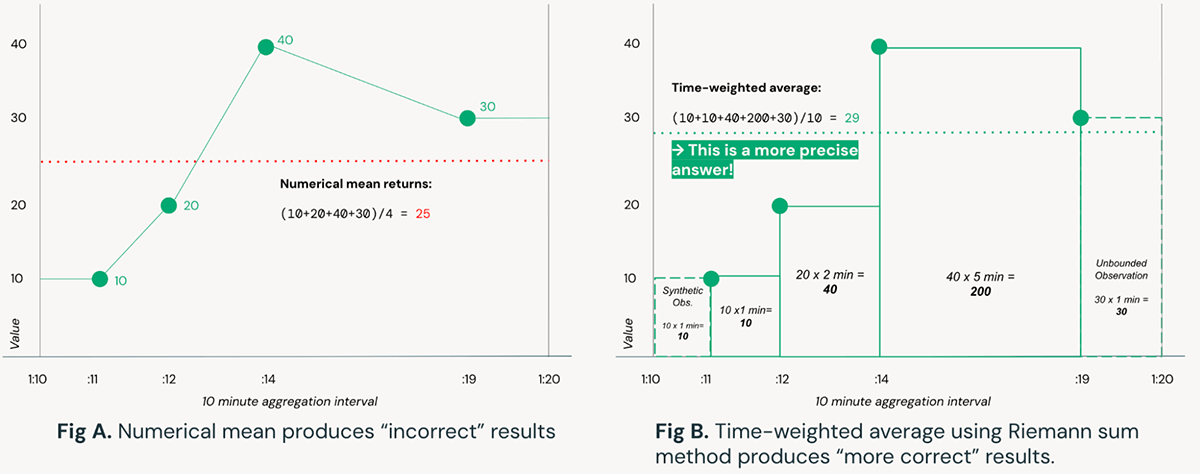
図Aは、ある時間間隔におけるセンサーの読み取り値の平均を計算するための単純な数値手段に頼ったものです。 これとは対照的に、図Bは、時間加重平均を計算するためにリーマン和のアプローチを使用しており、より正確な答えが得られます。 風力タービンのような複雑なシステムでは、これが定常運転と機器の故障の分かれ目になるかもしれません。
ソリューションの概要
米国の大手電力会社では、大量のタービン・データを予防保守やその他の独自のユースケースのための実用的な洞察に変えるエンドツーエンド・ソリューションの一部として、このパターンを導入しました。 下図は、数百台のマシンから取り込まれた生のタービンデータから、クラウドストレージからの取り込み、Delta Live Tablesでオーケストレーションされた高性能ストリーミングパイプライン、そしてユーザー向けのテーブルとビューへの変換を示しています:
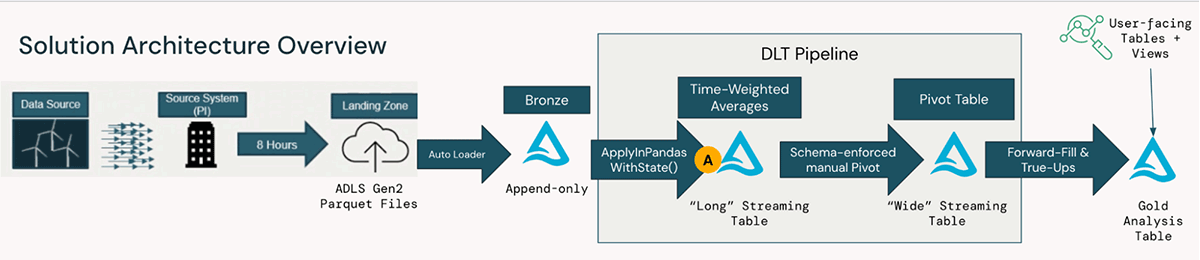
コードサンプル(delta-live-tables-notebooks githubを参照)は、上記のラベルを付けた変換ステップA、特にステートフルな時間加重平均計算のためのApplyInPandasWithState()に焦点を当てています。 Pi HistoriansのようなIoTデータを扱う他のソフトウェアツールとの連携を含む残りのソリューションも、Databricks Data Intelligence Platformのオープンソース標準と柔軟性によって簡単に実装できます。
積分のステートフル処理
タービン・センサーからのデータを迅速に処理するには、ストリームに含まれるデータを考慮する必要があります。 この例では、各タービン+センサーの組み合わせについて、10 分間の集計を計算します。 データは継続的に到着し、パイプラインは利用可能になるとデータのマイクロバッチを処理するため、時間間隔が完了したとみなすことができる時点まで、各集約ウィンドウの状態を追跡する必要があります。(構造化ストリーミングウォーターマークで制御されます)
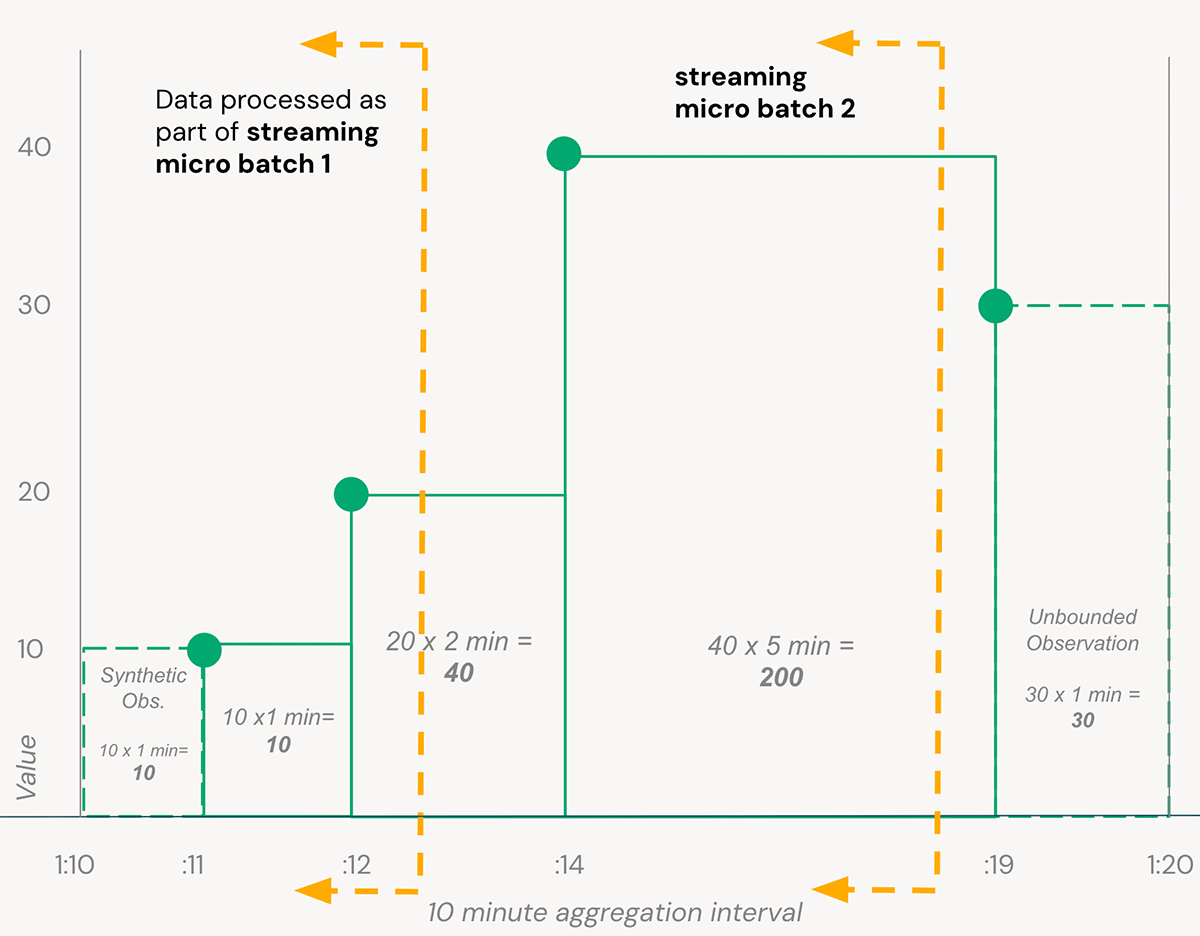
Databricksの宣言型ETLフレームワークであるDelta Live Tables(DLT)でこれを実装�することで、ストリームチェックポイントや計算の最適化といった運用上の問題よりも、変換ロジックに集中することができます。 完全なコードサンプルはサンプルリポジトリを参照してください。ここでは、SparkのApplyInPandasWithState()関数を使用して、DLTパイプラインでステートフルな時間加重平均を効率的に計算する方法を紹介します:
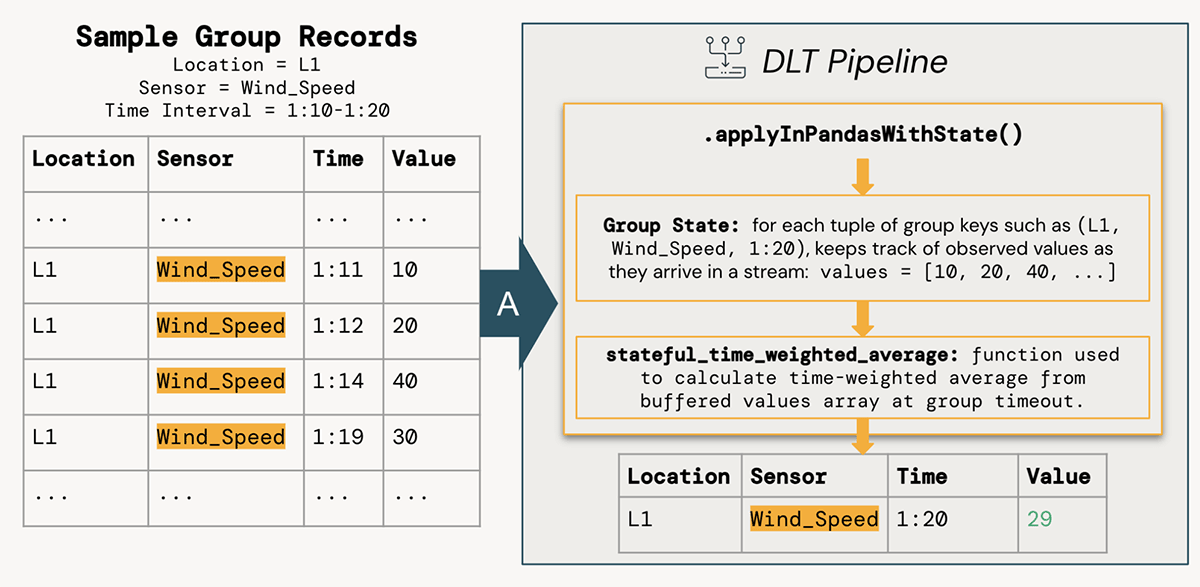

groupBy().applyInPandasWithState()の中で、stateful_time_weighted_averageというシンプルなPandas関数を使用して、時間加重平均を計算しています。 この関数は、ストリームが十分に後のタイムスタンプ値(ウォーターマークによって制御される)を見たときに、そのグループが「閉じる」ことができるまで、各状態グループの観測値を効果的に「バッファ」します。 これらのバッファリングされた値は、リーマン和を計算するためのシンプルなPython関数に渡されます。
このアプローチ�の利点は、単一のPandas DataFrame上で動作する堅牢でテスト可能な関数を書くことができることですが、この関数は、Sparkクラスタ内のすべてのワーカーで同時に何千もの状態グループに対して並列計算することができます。 状態を追跡し、場所+センサー+時間間隔のグループごとにいつ行を出すかを決定する機能は、timeoutConf設定と関数内のstate.hasTimedOutメソッドの使用で処理されます。
結果と応用
このブログの関連コードは、サンプルデータを使用したDelta Live Tablesパイプラインでのこのロジックのセットアップを説明しており、どのDatabricksワークスペースでも実行可能です。
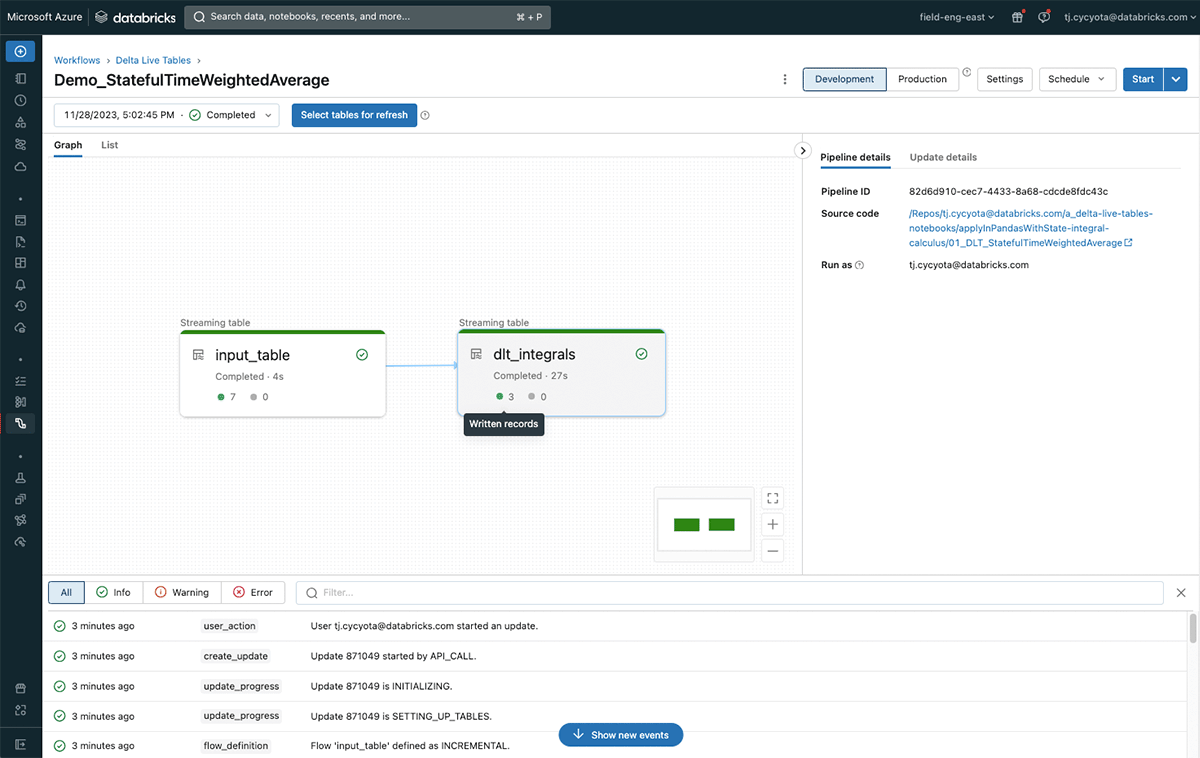
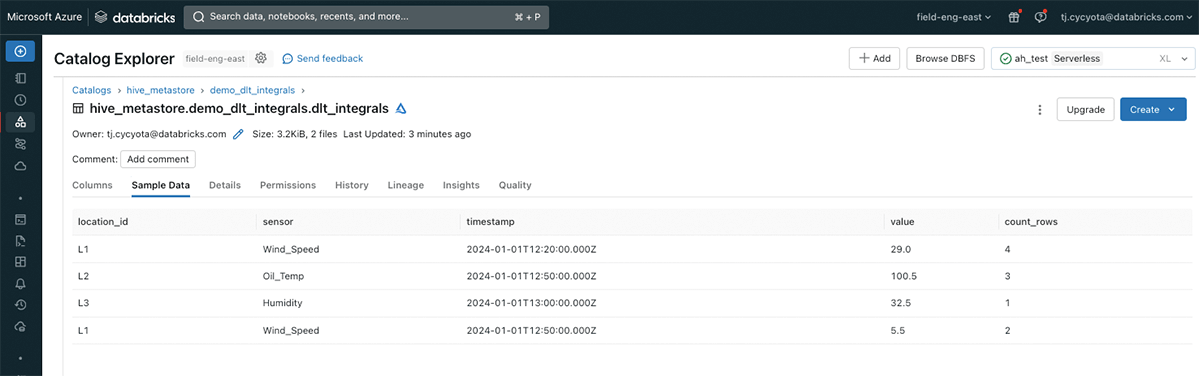
その結果、多くのIoTユースケースにおいて、大量のストリーミングデータに対して、時間加重平均などの積分ベースのメトリクスを効率的かつインクリメンタルに計算できることが実証されました。
このソリューションを導入したアメリカの電力会社にとって、その効果は絶大でした。 何千台もの風力タービンを一律に集計するアプローチにより、メンテナンス、パフォーマンス、その他のエンジニアリング部門のデータ利用者は、複雑な傾向を分析し、機器の信頼性を維持するための事前対策を講じることができます。 この統合されたデータは、故障予測に関連する将来の機械学習ユースケースの基盤としても機能し、大量の振動データと組み合わせることで、さらにリアルタイムに近い分析を行うことができます。
Databricksを使えば、ストリーミングデータを含むビジネスクリティカルなアプリケーションに簡単に適用できます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。