企業のAI化を真の意味で加速する「モデルリスクマネジメント」
によって アントワーヌ・アメンド(Antoine Amend), Satish Garla, Mario Schlener (EY), Wissem Bouraoui (EY) 、 Tarek Elguebaly (EY) による投稿
EYのMario Schlener、Wissem Bouraoui、Tarek Elguebalyには、このジャーニーを通してのサポート、このブログとソリューションアクセラレータへの貢献に対して特別な感謝を申し上げます。
Original: Model Risk Management, a true accelerator to corporate AI
翻訳: junichi.maruyama
モデルリスク管理(MRM) - 金融サービス業界の多くのモデル開発者やデータサイエンティストにこれほどの不安をもたらす3文字の頭字語は稀である。MRMは、ガバナンスとコンプライアンスチームが、誤ったモデルや誤用されたモデルによって引き起こされる悪影響を慎重に特定し、軽減するための規律である。人工知能(AI)や機械学習(ML)モデルに限らず、AI/MLモデルは銀行で管理されているモデルのごく一部であり、��その範囲はエンドユーザーのコンピューティングアプリケーション、複雑な統計パッケージ、ルールベースのプロセスにも容易に及ぶ。
しかし、第4次産業革命が技術的・分析的なブレークスルーをもたらした一方で、過去のAI実験(例:TwitterチャットボットTay)や企業スキャンダル(例:Cambridge Analytica)により、AIの危険性や説明不足、また組織が考慮しなければならない新しいリスク要因(倫理や公平性など)に対する認識がさらに高まっています。ChatGPTやGenerative AIなどの新しいモデルが金融サービス業界で多くの話題を呼んでいるように、AI/MLは、データガバナンスや、プライバシー、情報セキュリティ、第三者リスク管理などのリスク管理の枠組みとの連携をより強固にする必要があります。
コンプライアンス・オフフィサー - AIの暗黒騎士
銀行や保険会社のモデルは、その複雑さにかかわらず、独立した専門家チームによって徹底的に見直され、その唯一の責任は、モデル化アプローチの欠点を特定することです。AIの世界に精通した新しい世代の技術者にとって、このプロセスはしばしば逆効果で、時代遅れで、やや恩着せがま��しいものと見なされ、多くの実務家は自分のスキルが問われることを好まない。しかし、これは真実からかけ離れたものではありません。
独立検証ユニット(IVU)は、単にモデリング戦略の欠点を特定するだけでなく、リスクが最初から特定され、有害な結果を軽減するためにモデル開発のライフサイクル全体を通じて必要なステップが取られていたことを検証する。リスクを軽減できない場合、少なくともリスクを理解し、明確にし、定量化する必要があります。結局のところ、リスク管理はすべての金融サービス機関(FSI)の主要な機能である。
厳格な開発基準を実施し、企業ガイドラインを定義し、すべてのモデルの規制遵守を確認することで、時には自らの人気を犠牲にしながら、コンプライアンス担当者とモデル検証者は企業AIのダークナイトとなっています。金融エコシステムの整合性を守り、モデルの有効性を高め(モデルが目的に合っている)、企業や顧客の関連リスクを低減し、分析プロジェクトの市場投入までの時間を短縮しています。
モデルの説明可能性 vs モデルの透明性
MLモデルはしばしば「ブラックボックス」であり、その解釈を難しくする。モデルの説明可能性の問題には、しばしば簡単な答えがある: Shapley Additive Explanations、一般にSHAP値として知られている。この方法は、MLモデルの解釈可能性を高めるために、実務家によって多用されています。しかし、モデルの結果に対するある特徴の影響力(正または負)をうまく示すことができても、予測自体の品質を評価することはできないため、コンプライアンスチームは、信用引受などの重要な意思決定プロ�セスにおいて、XGBoostなどの技術よりも一般化線形モデル(GLM)などのシンプルなアプローチを優先せざるを得ない。これは、現状維持の限界です。
もしこの技術が、100や1000のパラメータで学習させたより複雑なモデルにある程度の透明性をもたらすのに使えるとしたら、10億のパラメータで学習させた新世代のAIにはどう適用できるのでしょうか?私たちの新しいオープンソースイニシアチブであるDolly,は、生成AIの商業利用を民主化することを目的としており、60億のパラメータで訓練されています!しかし、最も重要なことは、線形回帰のような最も説明しやすい手法であっても、このモデルが訓練されたデータを把握していなかったり、実稼働している現在のバージョンを知らなかったりすると、ブラックボックスと見なされることです。
そこで、ドキュメンテーションと開発ガイドラインが、AIの説明可能性に取って代わるのです。世界中のモデルリスクに関するガイダンスでは、モデルのライフサイクル全体(設立から廃止まで)を通して、効果的な文書化の必要性が非常に強調されています。
SR 11-7 モデルリスク管理(U.S. Federal Reserve Boardより):
[...] 文書化は、モデル開発プロセスにおいて必要な要素である。これは、他の関係者がモデルを理解し、実装し、比較のための適切なベンチマークを構築できるようにするものです。
E-23 カナダのOSFI:
[...] モデルオーナーは、モデルのライフサイクルの各段階において、すべてのモデル関�係者が容易にアクセスできるような完全な文書を維持する責任を負うべきである。
モデルの説明可能性は、各入力パラメータの理解よりも、その開発経緯と概念の健全性にあると考える。モデルは、そのライフサイクルにおいて、データ、メトリクス、仮定、ツール、フレームワーク、そしてモデル関係者による決定など、多くのタスクを経ます。AIに必要な透明性をもたらすには、データ、インフラ、プロセス、コード、モデルを結びつける必要があります。このシンプルさこそが、Databricks Lakehouseの約束です。
より良い関係を築くために
私たちは、金融サービス業界における効果的なモデルリスク管理の極めて重要性を理解しています。だからこそ、完全なモデル監査可能性を提供し、コンプライアンスから推測を取り除くAI説明可能性のためのDatabricks and EY Model Risk Management Acceleratorを紹介できることを嬉しく思います。私たちのアクセラレータは、データが拡大し、モデリング技術が進化するにつれて、エンドユーザーがモデルの透明性と解釈可能性を達成できるようにします。AIガバナンスに必要なインプットを満たすことを目標に、このソリューションは、モデルを文書化し、最適化されたタイムラインで規制とビジネスの両方に関連する変更に対処するための一貫性のある合理的なアプローチを提唱します。
このアクセラレータは、規制基準に準拠した再利用可能なノートブックを活用し、自動生成されるモデル文書化ソリューションを金融サービス企業に提供します。また、このソリューションは、データの可視化や設定可能なダッシュボード・レポートなど、充実した製品群に接続され、チームは統一された分析アーキテクチャ上に構築された自動化・集中化ツール、ラボ、ライブラリーを活用することが可能です。これにより、モデルのライフサイクル活動の管理とガバナンスを合理化することができます。
金融サービス企業が当社のMRMアクセラレーターを活用することで、以下のようなメリットがあります:
- 可視化およびレポート機能の強化により、金融サービス企業は情報に基づいた意思決定を行い、リスク・エクスポージャーをより深く理解できるようになります。
- モデルの開発、検証、実装、および問題管理を自動化し、全体的な効率を向上させます。
- インベントリ全体にわたるリアルタイムのリスクレポートと分析により、商品/ポートフォリオレベルでの全体的な健全性をチェックできるため、リスクを積極的に監視・軽減し、ビジネスへの悪影響の可能性を低減することができます。
Databricks Lakehouseによるユニファイド・ガバナンス
Databricks Lakehouseは、データウェアハウスシステムの信頼性とパフォーマンスを、データレイク機能が提供する経済性、スケール、柔軟性と組み合わせた、最新のクラウドデータアーキテクチャです。1,000社以上のFSIに採用されているこのパターンは、銀行、保険会社、資産運用会社が、リスク管理からマーケティング分析まで、重要性の異なるさまざまなユースケースにおいて、データから価値を引き出すことを支援します。
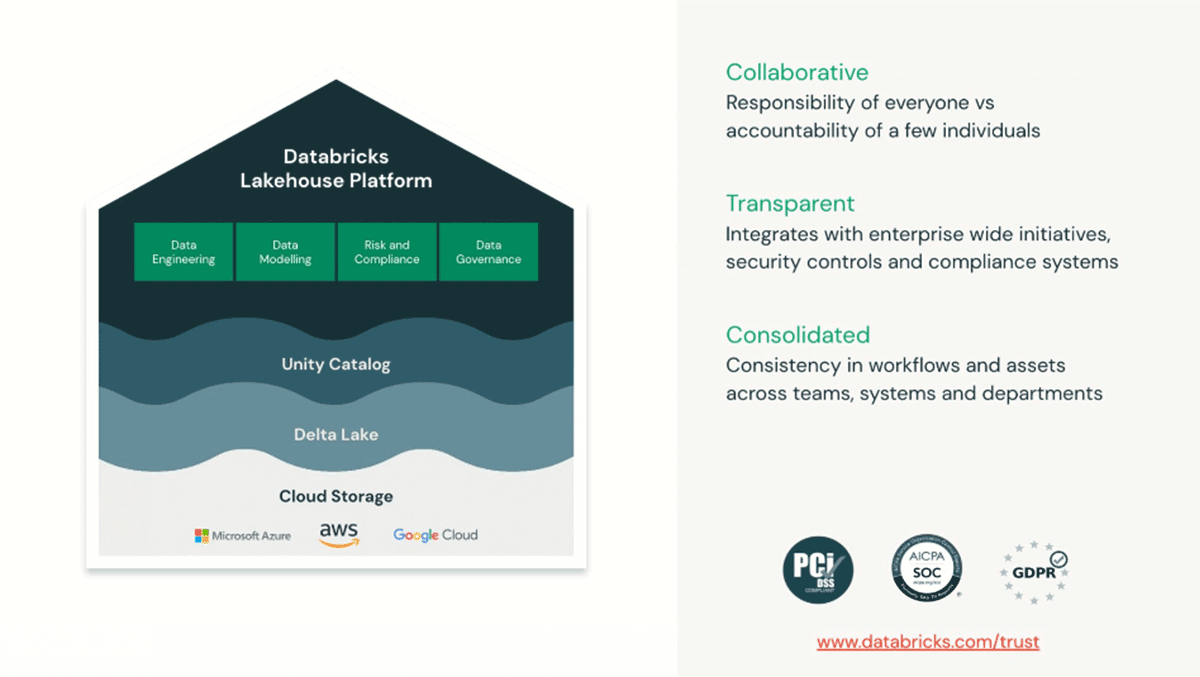
オープンソースの標準に基づいて構築されたレイクハウスアーキテクチャの約束は、データの取り込みから価値の創造まで、データのバリューチェーン全体を通して使用されるすべての不要なステップと異なるテクノロジーを簡素化することです。
Delta Lake は、Databricks Lakehouse Platformのデータとテーブルを保存するための土台となるストレージレイヤーです。Delta Lakeのテーブルを変更する操作は、それぞれ新しいテーブルのバージョンを作成します。履歴情報を使って、操作を監査したり、特定の時点のテーブルを照会したりすることができます(タイムトラベルとも呼ばれます)。
MLFlowは、MLと非MLの実験をすべて追跡し、モデルパラメータ、メトリクス、ライブラリ、依存関係、異なるバージョンを自動的に記録しますが、同様に "as-of code" (例えば、実験時の関連ノートブック)と "as-of data" をキャプチャします。
シンプルなアーキテクチャは、シンプルなガバナンスモデルをもたらします。Unity Catalog��は、データの上流と下流の使用を追跡し、それに応じてアクセスポリシーを適用することができる単一のガラス窓となります(モデルの所有者、データの所有者など)。以下の例では、与信判断に使用される複雑なワークフローを表現し、変換に使用されるデータ、モデルのトレーニング、モデルの評価をすべて同じ有向非循環グラフ(DAG)にリンクしています。
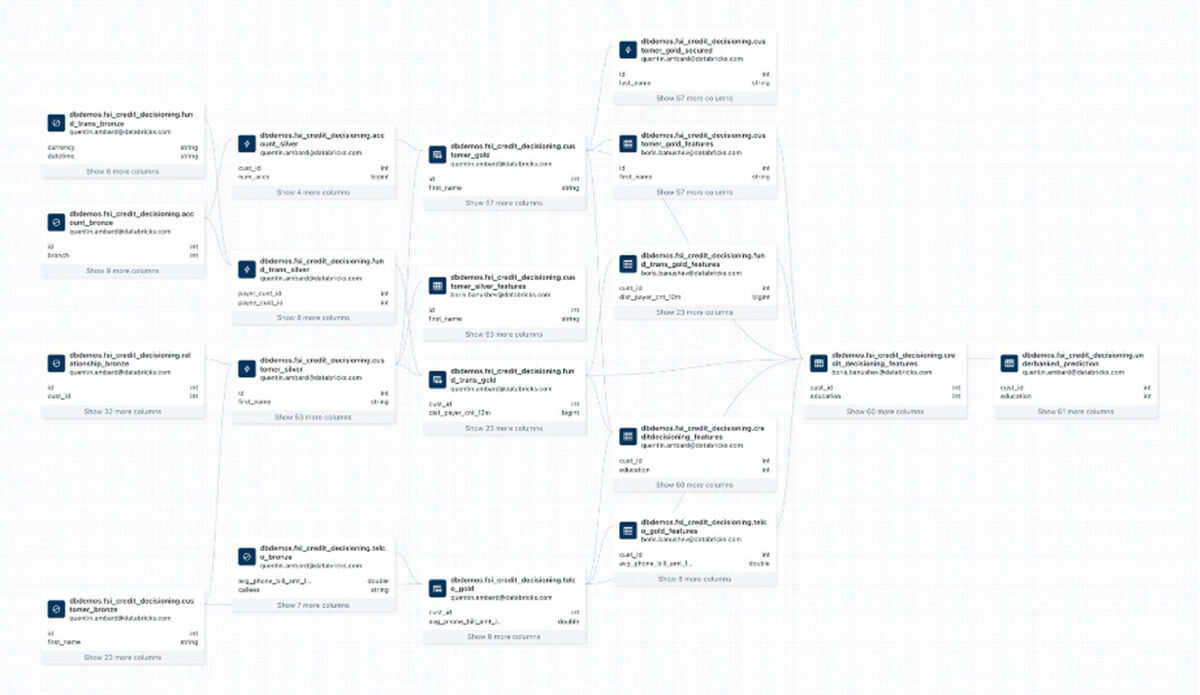
データ、インフラ依存関係、モデル、関連する実験をプログラム的にまとめることで、Unity Catalogはモデルの運用と再現に必要な堅牢なファウンデーションを提供します。しかし、第2、第3の防衛ラインによる「一貫性」と「完全性」のチェックを満たすために必要な厳格な文書化は、技術そのものでは解決できない。
モデルのドキュメント
標準化、プロセスの簡素化、一貫性を持たせるために、コンプライアンスとモデルガバナンスのチームは、通常、中央のグループによって運営されており、モデル開発者のドキュメントの一般的な要素を網羅する標準的なテンプレートを公表することが多い。テンプレートは、多くのユースケースにほぼ適用できますが、各ビジネスエリアがそれぞれのニーズに合うように調整することがよくあります。その結果、矛盾が生じ、検証時間が長くなることがあります。
- このプロセスでは、複数のシステムからデータを引き出す必要があり、実験追跡のための手書きのメモを過去にさかのぼって確認することもあります。
- 開発者は、ありふれたコピーペーストやフォーマット作業よりも、モデリング作業に集中することを望む。
- 異なるモデルグループによる構造の不一致は、標準の維持に困難をもたらす。
- モデルグループやモデルタイプによって異なるため、標準を維持するのが難しくなります。
- 要求されるビジネス要件とタイムラインは、品質の高いドキュメントに時間的な制約を課すことがあります。
- モデルグループの種類が多く、モデルや規制の変化が激しいため、モデルガバナンス・ポリシーチームがアップデートやスタンダードを展開することが困難である。
しかし、根本的な問題は、モデル文書そのものではなく、この文書がどのように提供され、実施されているかにあります。モデル開発プロセスとは別の活動として、通常は事後的に(すなわち、モデルが構築された後に)処理されるこのプロセスは、多くの手作業、管理オーバーヘッド、モデル開発者と検証チーム間の不必要な行き違いコミュニケーションを引き起こし、長い納期をもたらし、モデルがもはや目的に適さない(例えば、顧客の行動が変化した)かもしれないという点までモデルの機能性に影響を与えます。
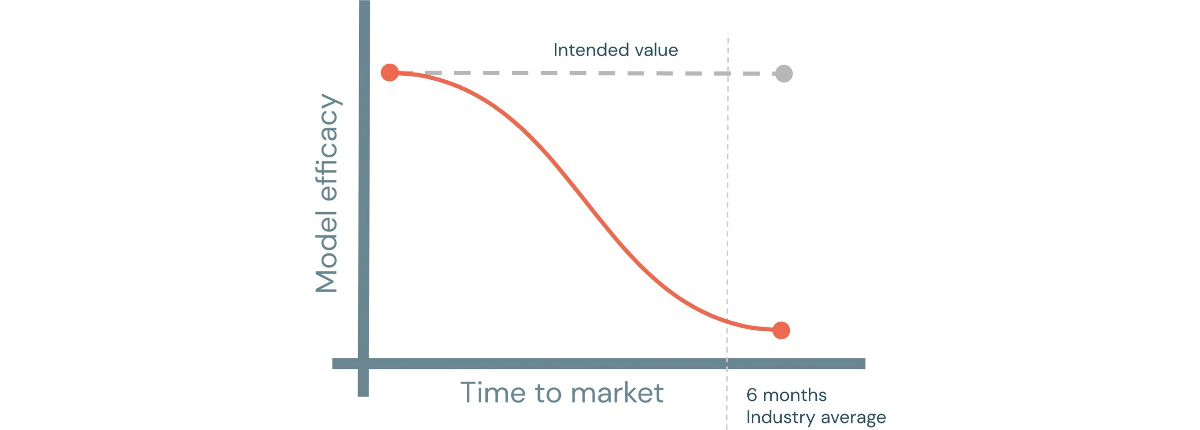
しかし、文書化を個別の活動として強制するのではなく、テンプレートノートブックやマークダウンコメンタリーを通じてモデルの開発プロセスに組み込み、モデル検証の前に開発者を一連のステップに誘導することで、このダイナミズムを変えることができます。IVUプロセスで必要とされる質問のほとんどは、(モデル開発段階で)前もって対処することができ、モデル検証の成功率を高め、分析ユースケースの探求から制作までの時間を劇的に短縮することができます。
モデルドキュメントのためのソリューションアクセラレータ
EYとDatabricksが共同開発したMRMのための新しいソリューションアクセラレータは、複数のモデルアーティファクトの詳細を抽出することでドキュメントを自動生成します。Databricks Lakehouseアーキテクチャの上に構築されたテンプレート駆動型のフレームワークであり、モデルのドキュメント化に必要なすべてのアーティファクトを容易に抽出することができます。
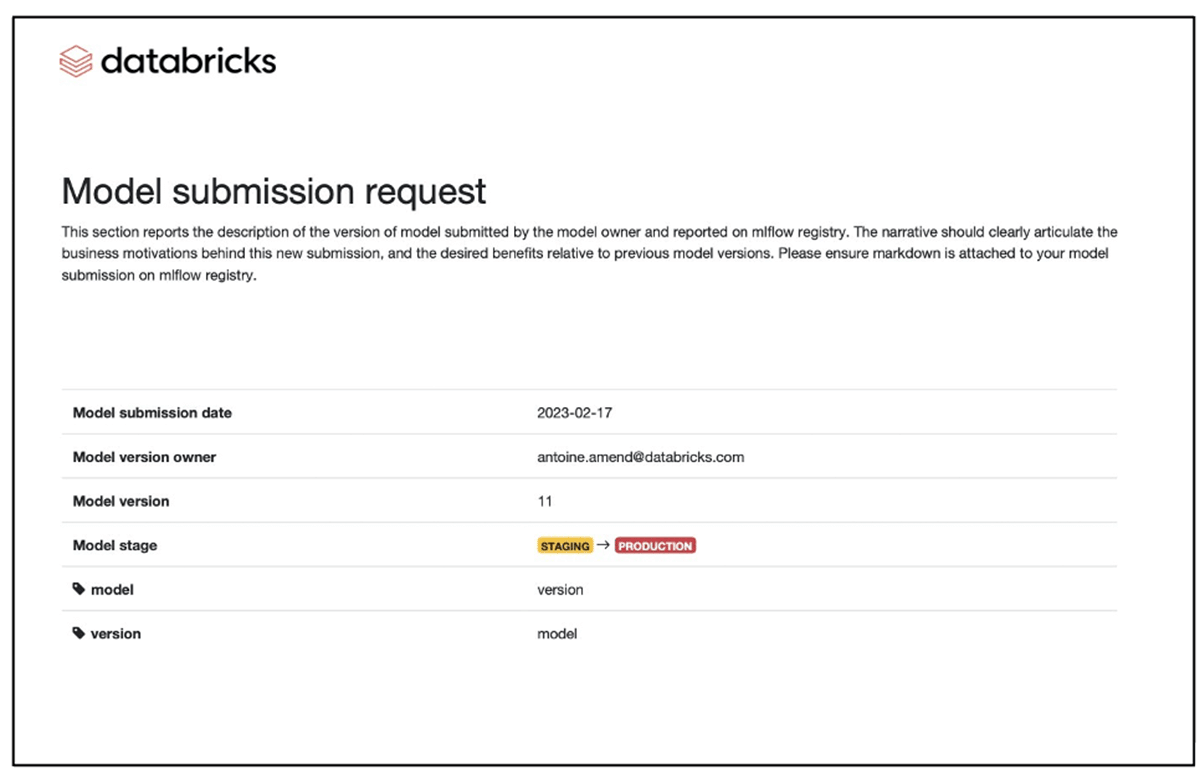
テンプレートは、Databricksのノートブックベースのツールで、モデル開発者の主題に応じた構造とプレースホルダーがあらかじめ用意されています。マークダウンテキスト、Latex数式、コード、グラフィックスをサポートするプレースホルダーを持つノートブックなので、モデル開発のプレースマットをモデルドキュメントに拡張したり、その逆を簡単に行うことができるようになっています。

モデル成果物のニーズを満たすだけでなく、このソリューションはデータガバナンスとリネージを抽出することでモデルドキュメントの有効性を拡張し、モデル成果物を報告するための完全なツールとなっています。
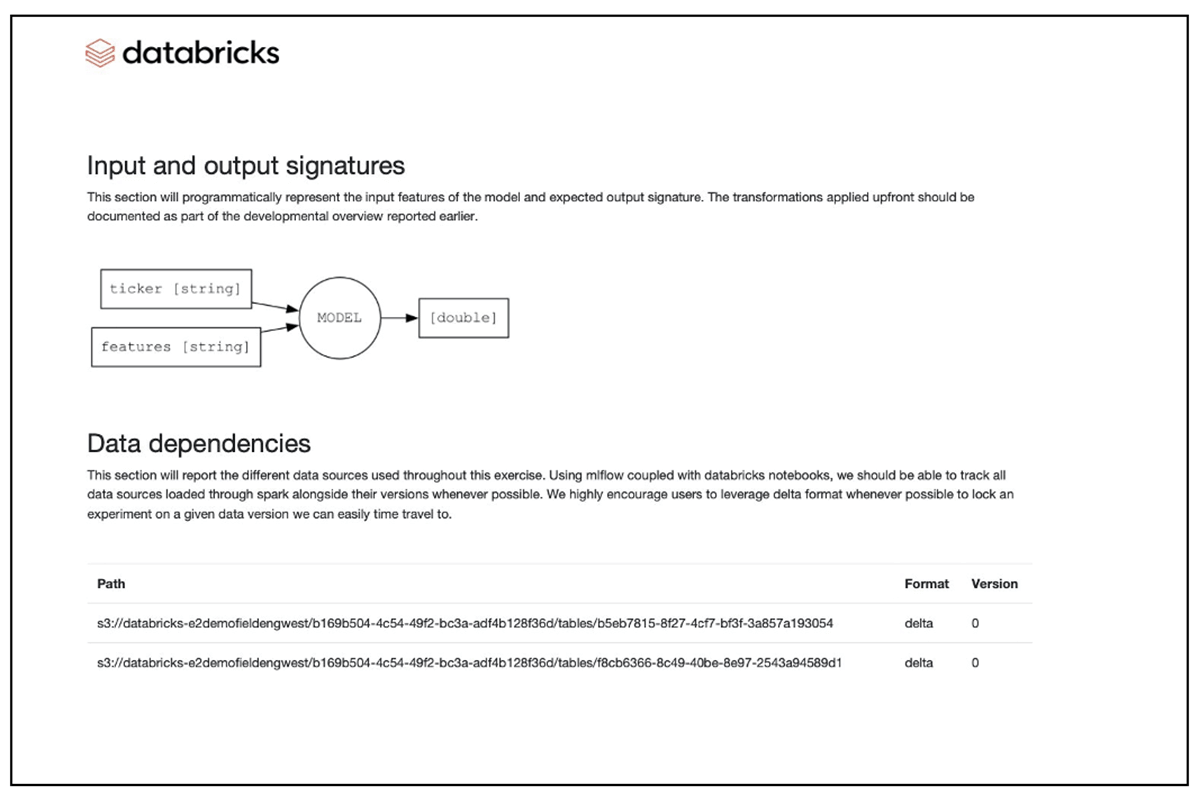
このユーティリティ・ライブラリは、ドキュメントを自動生成するための技術的な基盤とフレームワー�クを提供します。これはコインの片側を表しています。もう一つの側面は、対象モデルに関連する文書の設計、構造、および内容に関するものです。EY MRM suiteは、複数のモデルフレームワーク、規制当局のガイドライン、および多くのFSIのカスタムニーズをサポートする主題知識を持ち、金融サービス業界のビジネスドメインに対応する実証済みのモデル文書テンプレートを提供します。
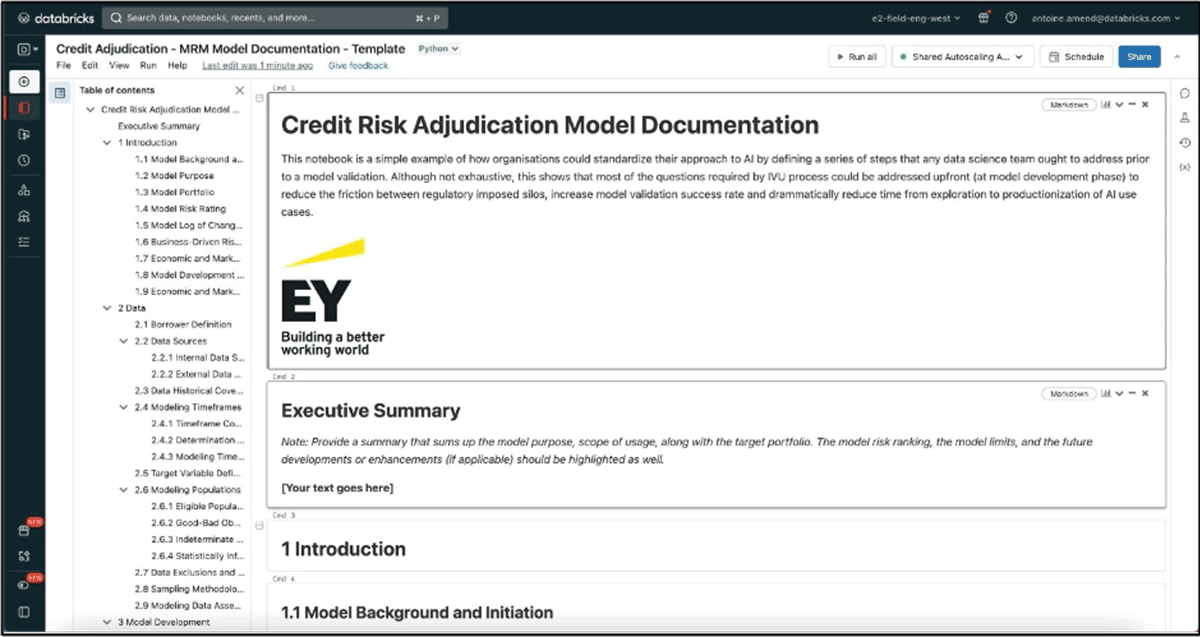
再利用可能なノートブックを通じて利用できるこれらのテンプレートは、同じ汎用的で再利用可能なフレームワークの上に構築されたドキュメントアドオンとなり、企業のモデル開発戦略に一貫性をもたらすことができ、企業AIへの真の加速装置となります。同様のアプローチを採用することで、規制対象企業がモデル提供のライフサイクルを12ヶ月から数週間に短縮しているのを見たことがあります。
モデルリスク管理のためのlakehouseの詳細については、新しいsolution accelerator をチェックし、DatabricksまたはEYの担当者にお問い合わせください。
この記事に反映されている見解は著者の見解であり、必ずしもアーンスト・アンド・ヤングLLPやEYのグローバル組織の他のメンバーの見解を反映するものではありません。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。