MPT-7B のご紹介:商用利用可能なオープンソース LLM の新基準
によって データブリックス AI 研究チーム による投稿
MosaicML Foundation Seriesの最初のモデル、MPT-7Bをご紹介します。MPT-7Bは、1兆トークンのテキストとコードでスクラッチからトレーニングされたTransformerモデルです。オープンソースで商用利用が可能であり、LLaMA-7Bと同等の品質を実現しています。MPT-7Bは、MosaicMLプラットフォーム上で9.5日間、人的介入なしで約20万ドルのコストでトレーニングされました。
大規模言語モデル(LLM)は世界を変えていますが、十分なリソースを持つ研究機関以外では、これらのモデルのトレーニングとデプロイは非常に困難です。この状況を受けて、MetaのLLaMAシリーズ、EleutherAIのPythiaシリーズ、StabilityAIのStableLMシリーズ、Berkeley AI ResearchのOpenLLaMAモデルなど、オープンソースLLMを中心に活発な動きが見られます。
本日、MosaicMLは、上記のモデルの限界に対処し、LLaMA-7Bに匹敵(そして多くの点で凌駕する)商用利用可能なオープンソースモデルを最終的に提供するために、MPT(MosaicML Pretrained Transformer)と呼ばれる新しいモデルシリーズをリリースします。これで、チェックポイントのいずれかから開始するか、スクラッチからトレーニングするかを選択して、独自のプライベートMPTモデルをトレーニング、ファインチューニング、デプロイできるようになります。参考として、ベースのMPT-7Bに加えて、3つのファインチューニング済みモデルもリリースします。MPT-7B-Instruct、MPT-7B-Chat、そしてコンテキスト長が65kトークンであるMPT-7B-StoryWriter-65k+です!
当社のMPTモデル��シリーズは以下の特徴を備えています。
- 商用利用ライセンス(LLaMAとは異なり)。
- 大量のデータでトレーニング(LLaMAと同様の1兆トークンに対し、Pythiaは300B、OpenLLaMAは300B、StableLMは800B)。
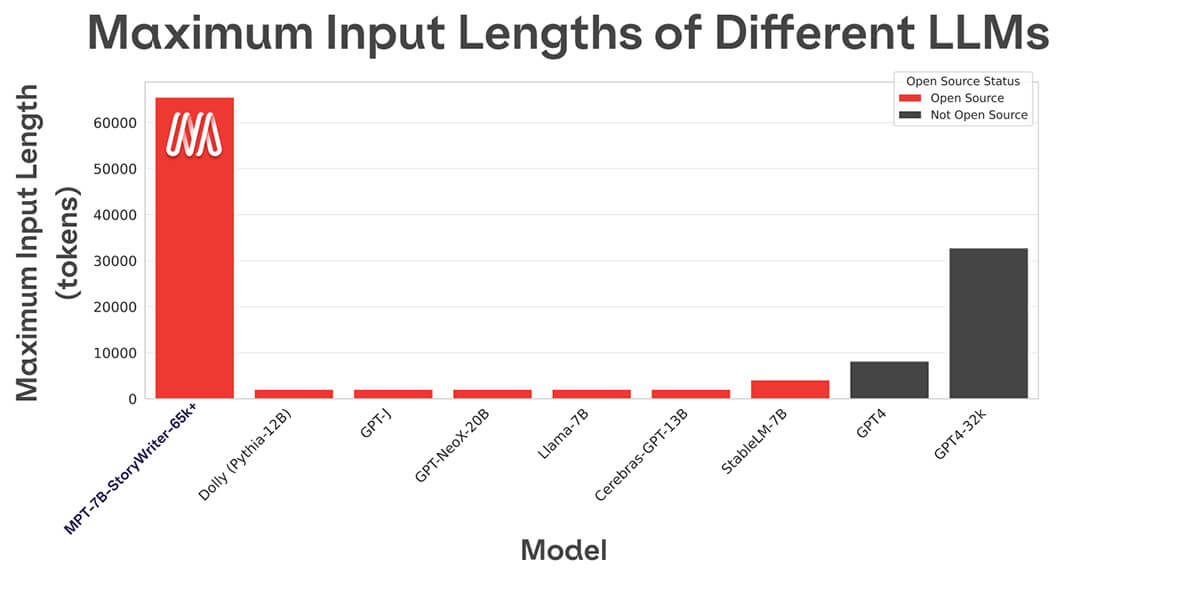
- ALiBiのおかげで非常に長い入力を処理可能(最大65kの入力でトレーニングし、最大84kまで処理可能。他のオープンソースモデルは2k-4k)。
- 高速なトレーニングと推論に最適化(FlashAttentionおよびFasterTransformer経由)。
- 非常に効率的なオープンソーストレーニングコードを搭載。
MPTをさまざまなベンチマークで厳密に評価した結果、MPTはLLaMA-7Bが設定した高い品質基準を満たしました。
本日、ベースモデルであるMPTと、このベースモデルを構築する多くの方法を示す3つのファインチューニング済みバリアントをリリースします。
MPT-7B ベース:
MPT-7B Baseは、67億パラメータを持つデコーダー型Transformerです。MosaicMLのデータチームがキュレーションした1兆トークンのテキストとコードでトレーニングされました。このベースモデルには、高速なトレーニングと推論のためのFlashAttentionと、ファインチューニングおよび長コンテキストへの外挿のためのALiBiが含まれています。
- ライセンス: Apache-2.0
- HuggingFaceリンク: https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+は、非常に長いコンテキスト長の物語を読み書きするために設計されたモデルです。books3データセットのフィルタリングされたフィクションサブセットで、コンテキスト長65kトークンでMPT-7Bをファインチューニングして構築されました。推論時には、ALiBiのおかげで、MPT-7B-StoryWriter-65k+は65kトークンを超える外挿も可能であり、A100-80GB GPUの単一ノードで最大84kトークンまでの生成を実証しました。
- ライセンス: Apache-2.0
- HuggingFaceリンク: https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instructは、短形式の指示追従モデルです。Databricks Dolly-15kとAnthropic's Helpful and Harmlessデータセットから派生した、当社もリリースするデータセットでMPT-7Bをファインチューニングして構築されました。
- ライセンス: CC-By-SA-3.0
- HuggingFaceリンク: https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chatは、対話生成のためのチャットボットライクなモデルです。ShareGPT-Vicuna、HC3、Alpaca、Helpful and Harmless、およびEvol-InstructデータセットでMPT-7Bをファインチューニングして構築されました。
- ライセンス: CC-By-NC-SA-4.0(非商用利用のみ)
- HuggingFaceリンク: https://huggingface.co/mosaicml/mpt-7b-chat
企業やオープンソースコミュニティがこの取り組みを基盤として構築してくれることを願っています。モデルチェックポイントと並行して、当社の新しいMosaicML LLM Foundryを通じて、MPTの事前トレーニング、ファインチューニング、評価のための全コードベースをオープンソース化しました!
このリリースは単なるモデルチェックポイント以上のものです。MosaicMLの通常の効率性、使いやすさ、そして細部への徹底的なこだわりを重視した、優れたLLMを構築するための完全なフレームワークです。これらのモデルは、MosaicMLのNLPチームが、顧客が使用するのと同じツールでMosaicMLプラットフォーム上で構築したものです(Replitのような顧客に聞いてみてください!)。
MPT-7Bは、開始から終了まで人的介入ゼロでトレーニングされました。440基のGPUで9.5日以上にわたり、MosaicMLプラットフォームは4件のハードウェア障害を検出し、対処し、トレーニング実行を自動的に再開しました。また、アーキテクチャと最適化の改善により、壊滅的な損失スパイクは発生しませんでした。MPT-7Bの空のトレーニングログブックをご覧ください!
独自のカスタムMPTのトレーニングとデプロイ
MosaicMLプラットフォームで独自のカスタムMPTモデルの構築とデプロイを開始したい場合は、こちらからサインアップして開始してください。
データ、トレーニング、推論に関する詳細なエンジニアリング情報については、以下のセクションに進んでください。
4つの新しいモデルに関する詳細については、以下をお読みください!
Mosaic Pretrained Transformers (MPT) のご紹介
MPTモデルは、パフォーマンス最適化されたレイヤー実装、トレーニングの安定性を高めるアーキテクチャ変更、位置埋め込みをALiBiに置き換えることによるコンテキスト長の制限の排除といった、いくつかの改善が施されたGPTスタイルのデコーダーオンリーTransformerです。これらの変更により、��顧客は損失スパイクから逸脱することなく効率的に(MFUで40-60%)MPTモデルをトレーニングでき、標準的なHuggingFaceパイプラインとFasterTransformerの両方でMPTモデルを提供できます。
MPT-7B (ベースモデル)
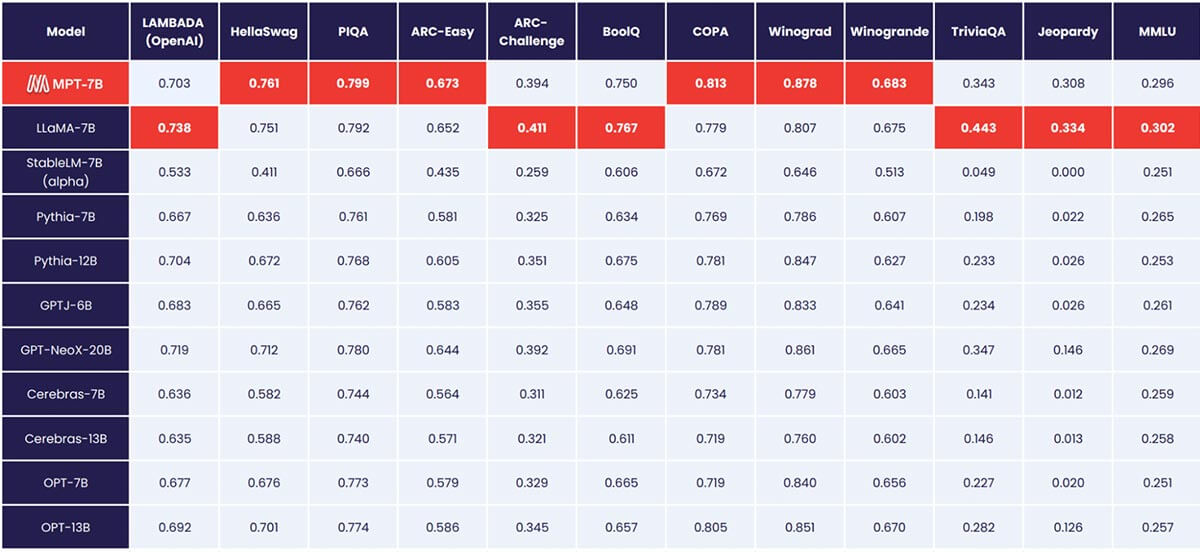
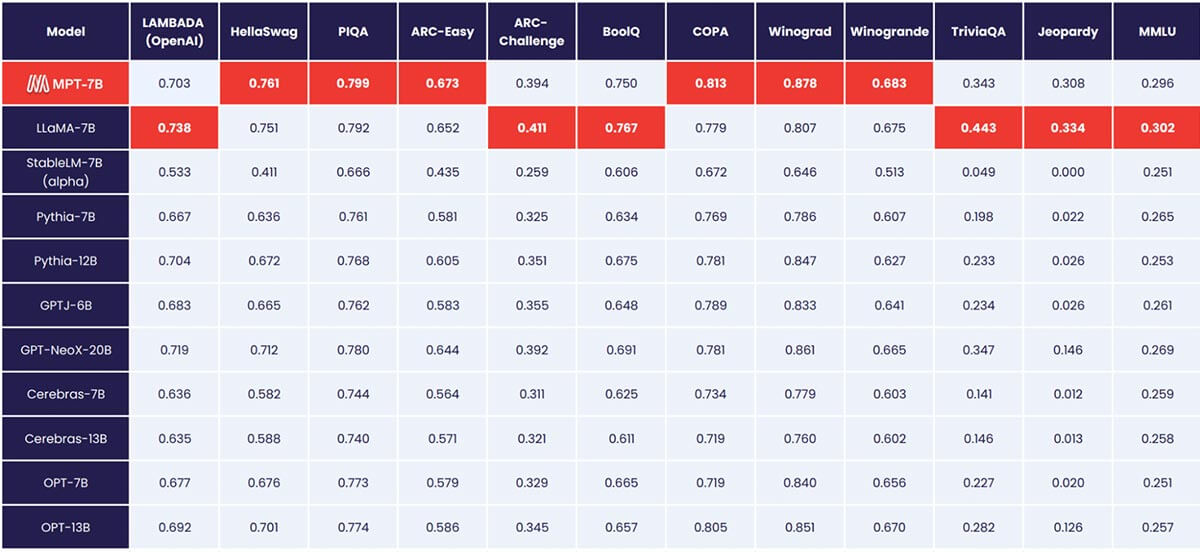
MPT-7BはLLaMA-7Bの品質に匹敵し、標準的な学術タスクでは他のオープンソースの7B~20Bモデルを上回ります。モデル品質を評価するために、インコンテキスト学習(ICL)で一般的に使用される11のオープンソースベンチマークをコンパイルし、業界標準の方法でフォーマットして評価しました。また、挑戦的な質問に対する事実に基づいた回答を生成するモデルの能力を評価するために、独自の自己キュレーションされたJeopardyベンチマークも追加しました。
MPTと他のモデルとのゼロショットパフォーマンスの比較については、表1を参照してください。
{kind=link}
公平な比較を行うため、各モデルを完全に再評価しました。モデルのチェックポイントを、同じ(空の)プロンプト文字列とモデル固有のプロンプトチューニングなしで、オープンソースのLLM Foundry eval frameworkで実行しました。評価の詳細については、Appendixをご覧ください。以前のベンチマークでは、私たちのセットアップは、単一のGPUで他の評価フレームワークよりも8倍高速であり、複数のGPUでシームレスに線形スケーリングを実現します。FSDPの組み込みサポートにより、大規模モデルの評価や、さらなる高速化のためのより大きなバッチサイズの利用が可能になります。
コミュニティの皆様には、独自のモデル評価に私たちの評価スイートをご利用いただき、さらに多くのデータセットやICLタスクタイプを追加したプルリクエストを送信していただくことで、可能な限り厳密な評価を保証できることを願っています。
MPT-7B-StoryWriter-65k+
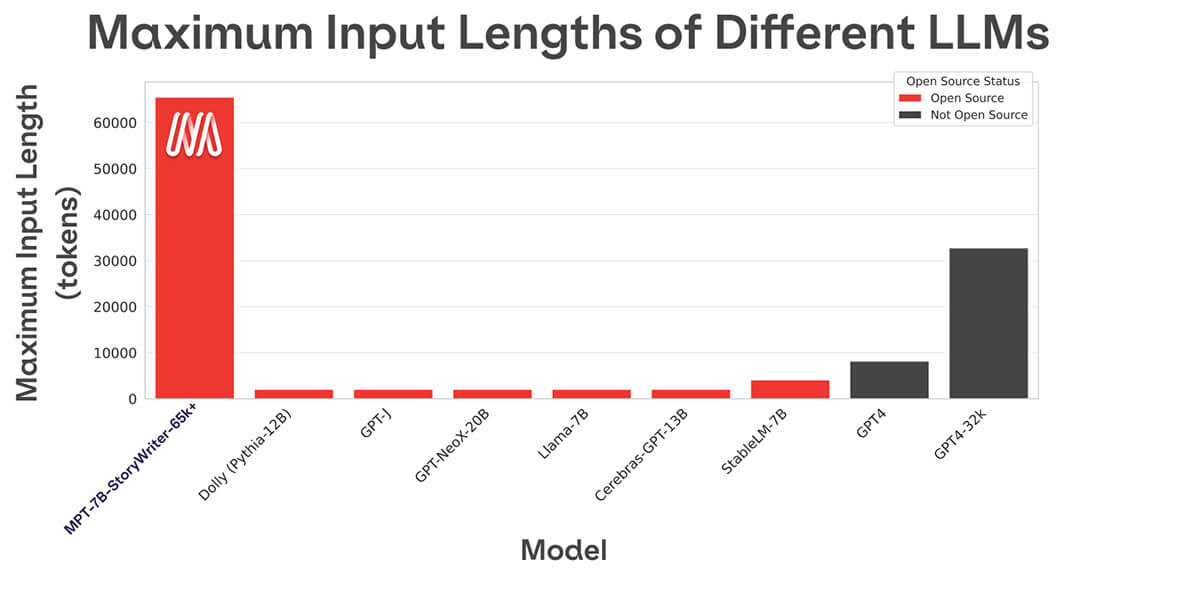
ほとんどのオープンソース言語モデルは、数千トークンまでのシーケンスしか扱えません(Figure 1を参照��)。しかし、MosaicMLプラットフォームと8xA100-80GBの単一ノードを使用すれば、MPT-7Bを簡単にファインチューニングして65kまでのコンテキスト長を扱えるようになります!このような極端なコンテキスト長の適応を扱える能力は、MPT-7Bの主要なアーキテクチャ上の選択肢の1つであるALiBiに由来します。
この機能を披露し、65kのコンテキストウィンドウで何ができるか考えていただくために、MPT-7B-StoryWriter-65k+をリリースします。StoryWriterは、MPT-7Bをベースに、books3コーパスに含まれるフィクション書籍の65kトークン抜粋で2500ステップファインチューニングされました。事前学習と同様に、このファインチューニングプロセスでは次のトークン予測目的関数が使用されました。データ準備後、トレーニングに必要なのは、ComposerとFSDP、アクティベーションチェックポインティング、そしてマイクロバッチサイズ1でした。
The Great Gatsbyの全文は約68kトークンです。そこで、StoryWriterにThe Great Gatsbyを読ませ、エピローグを生成させました。生成されたエピローグの1つがFigure 2に示されています。StoryWriterはThe Great Gatsbyを約20秒(毎分約15万語)で読み込みました。長いシーケンス長のため、その「タイピング」速度は他のMPT-7Bモデルよりも遅く、毎分約105語です。
StoryWriterは65kのコンテキスト長でファインチューニングされましたが、ALiBiにより、モデルはトレーニングされた入力よりもさらに長い入力、この場合はThe Great Gatsbyの68kトークン、テストでは最大84kトークンまで外挿す��ることが可能です。
{kind=link}
他のオープンソースモデルの最長のコンテキスト長は4kです。GPT-4は8kのコンテキスト長を持ち、別のモデルバリアントは32kのコンテキスト長を持ちます。

{kind=link}
エピローグは、The Great Gatsbyの全文(約68kトークン)をモデルへの入力として提供し、その後に「Epilogue」という単語を追加して、モデルがそこから生成を続けることによって生成されました。
MPT-7B-Instruct
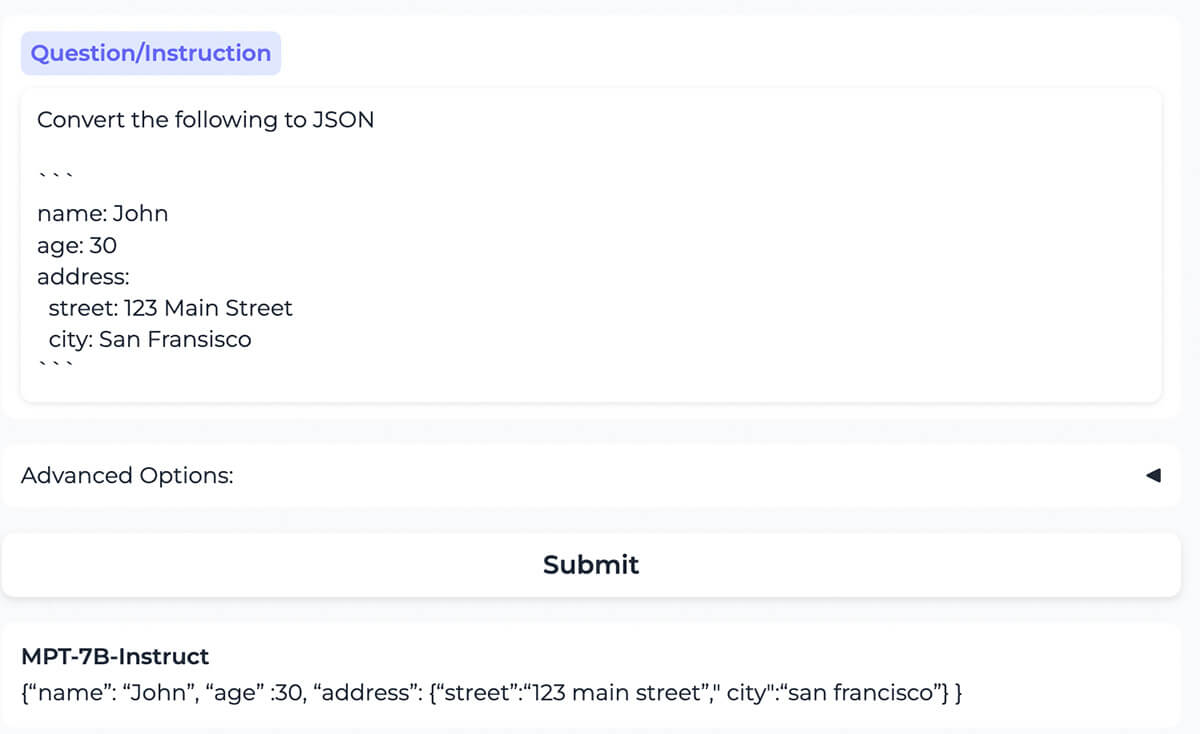
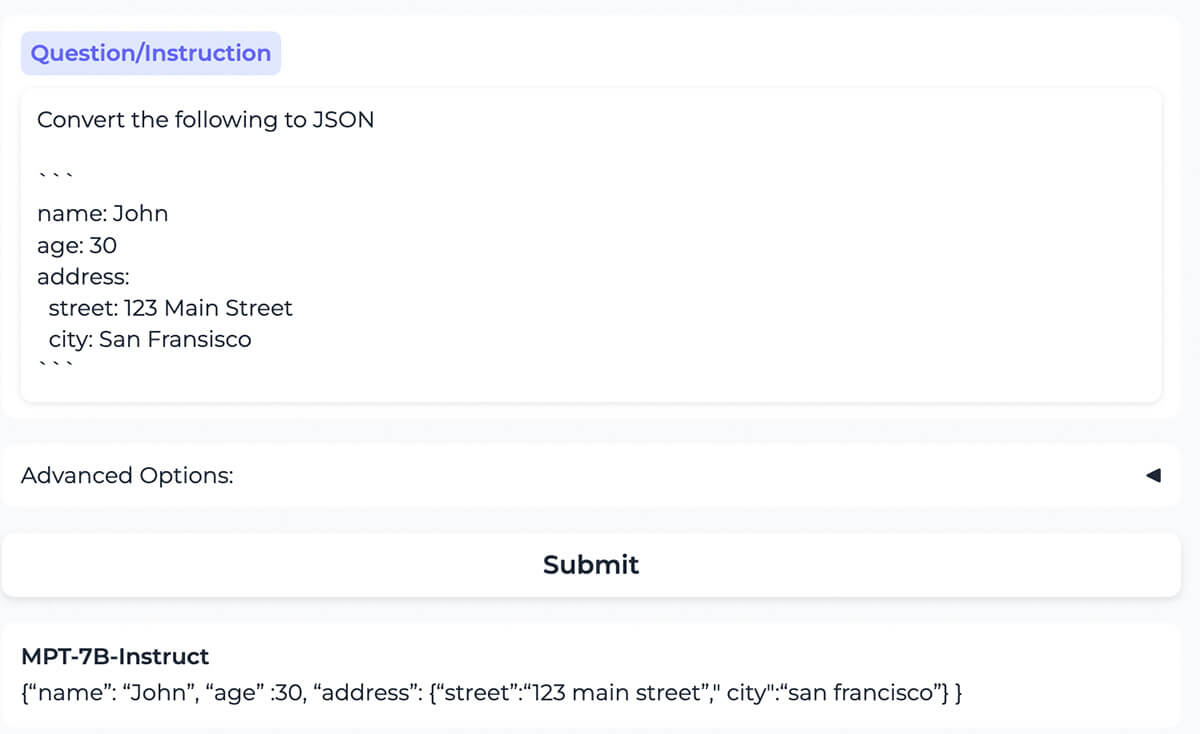{kind=link}
モデルは、YAML形式でフォーマットされたコンテンツを、同じコンテンツのJSON形式に正しく変換します。
LLMの事前学習は、モデルに入力されたテキストの続きを生成するように教えます。しかし実際には、LLMに入力は指示として扱われ、それに従うことを期待します。Instruction finetuning(指示ファインチューニング)は、LLMがこのように指示に従うようにトレーニングするプロセスです。巧妙なプロンプトエンジニアリングへの依存を減らすことで、instruction finetuningはLLMをよりアクセスしやすく、直感的で、すぐに使用できるものにします。instruction finetuningの進歩は、FLAN、Alpaca、Dolly-15kデータセットのようなオープンソースデータセットによって推進されてきました。
私たちは、商用利用可能な指示追従バリアントであるMPT-7B-Instructを作成しました。Dollyの商用ライセンスは気に入っていましたが、より多くのデータが必要だったので、AnthropicのHelpful & HarmlessデータセットのサブセットでDollyを拡張し、データセットサイズを4倍にしながら商用ライセンスを維持しました。
ここでリリースされるこの新しい集約データセット(here)を使用してMPT-7Bをファインチューニングした結果、商用利用可能なMPT-7B-Instructが生まれました。Anecdotally、MPT-7B-Instructは効果的な指示追従モ�デルであると考えています。(インタラクションの例については、Figure 3を参照してください。)1兆トークンにわたる広範なトレーニングにより、MPT-7B-Instructは、ベースモデルであるPythia-12Bがわずか3000億トークンしかトレーニングされていない、より大きなdolly-v2-12bと競争できるはずです。
私たちは、MPT-7B-Instructのコード、ウェイト、およびオンラインデモをリリースします。MPT-7B-Instructの小さなサイズ、競争力のあるパフォーマンス、そして商用ライセンスがコミュニティにとってすぐに価値のあるものになると期待しています。
MPT-7B-Chat

{kind=link}
AIを使用して絶滅危惧種を保護するという問題に対する高レベルのアプローチを提案し、次にKerasを使用したPythonでの実装を提案するチャットモデルとのマルチターンの会話。
また、MPT-7Bの会話バージョンであるMPT-7B-Chatも開発しました。MPT-7B-Chatは、ShareGPT-Vicuna、HC3、Alpaca、Helpful and Harmless、およびEvol-Instructを使用してファインチューニングされており、幅広い会話タスクやアプリケーションに対応できる十分な能力を備えています。ChatML形式を使用しており、システムメッセージをモデルに渡すための便利で標準化された方法を提供し、悪意のあるプロンプトインジェクションを防ぐのに役立ちます。
MPT-7B-Instructがより自然で直感的な指示追従インターフェースの提供に焦点を当てているのに対し、MPT-7B-Chatは、ユーザーにとってシームレスで魅力的なマルチターンの対話を提供することを目指しています。(インタラクションの例については、Figure 4を参照してください。)
MPT-7BおよびMPT-7B-Instructと同様に、MPT-7B-Chatのコード, ウェイト、およびオンラインデモをリリースします。
How we built these models on the MosaicML platform
The models released today were built by the MosaicML NLP team, but the tools we used are the exact same ones available to every customer of MosaicML.
Think of MPT-7B as a demonstration – our small team was able to build these models in only a few weeks, including the data preparation, training, finetuning, and deployment (and writing this blog!). Let's take a look at the process of building MPT-7B with MosaicML:
Data
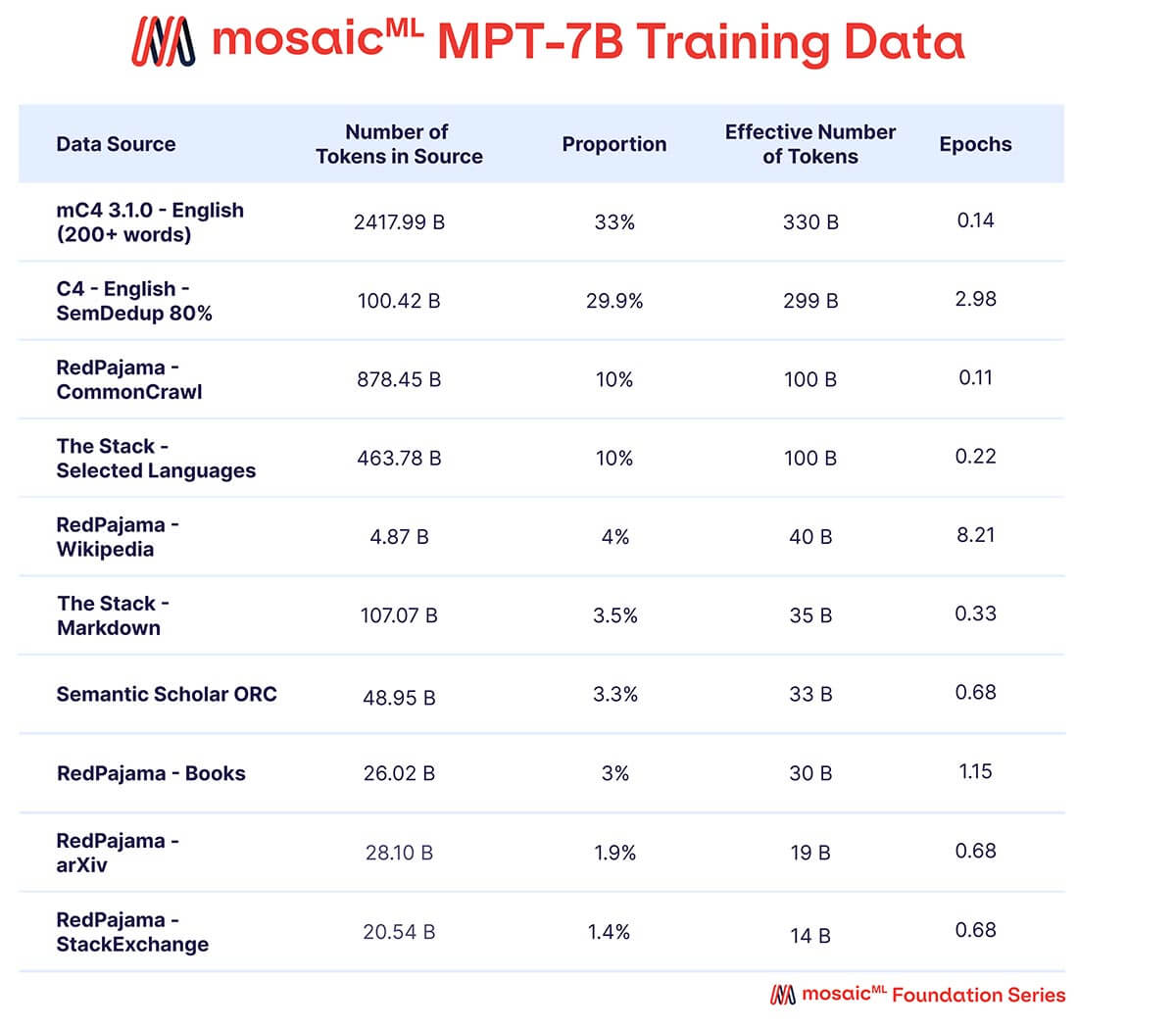
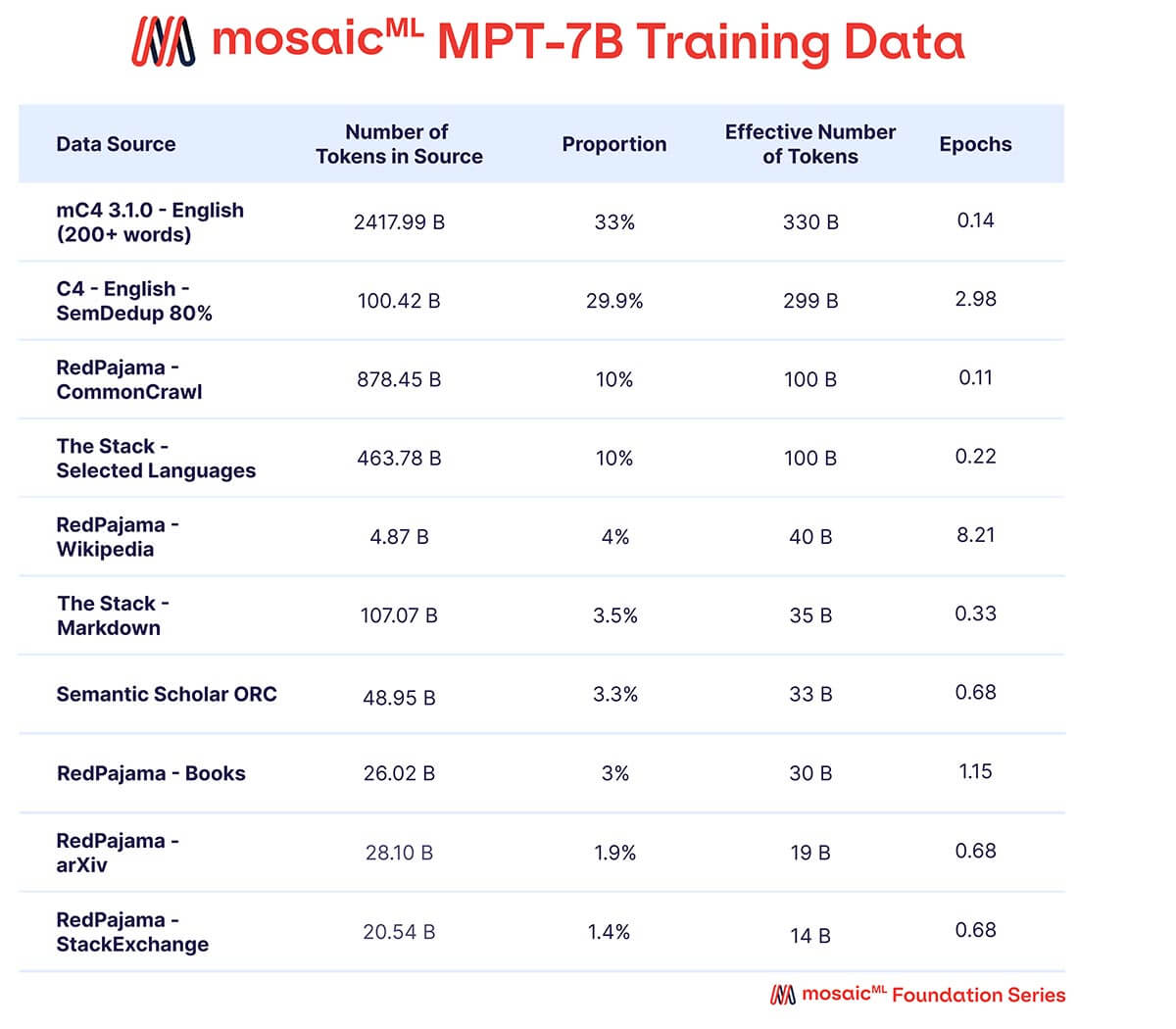
We wanted MPT-7B to be a high-quality standalone model and a useful jumping off point for diverse downstream uses. Accordingly, our pretraining data came from a MosaicML-curated mix of sources, which we summarize in Table 2 and describe in detail in the Appendix. Text was tokenized using the EleutherAI GPT-NeoX-20B tokenizer and the model was pretrained on 1 trillion tokens. This dataset emphasizes English natural language text and diversity for future uses (e.g., code or scientific models), and includes elements of the recently-released RedPajama dataset so that the web crawl and Wikipedia portions of the dataset contain up-to-date information from 2023.
{kind=link}
A mix of data from ten different open-source text corpora. Text was tokenized using the EleutherAI GPT-NeoX-20B tokenizer, and the model was pre-trained on 1T tokens sampled according to this mix.
Tokenizer
We used EleutherAI's GPT-NeoX 20B tokenizer. This BPE tokenizer has a number of desirable characteristics, most of which are relevant for tokenizing code:
- Trained on a diverse mix of data that includes code (The Pile)
- Applies consistent space delimitation, unlike the GPT2 tokenizer which tokenizes inconsistently depending on the presence of prefix spaces
- Contains tokens for repeated space characters, which allows superior compression of text with large amounts of repeated space characters.
The tokenizer has a vocabulary size of 50257, but we set the model vocabulary size to 50432. The reasons for this were twofold: First, to make it a multiple of 128 (as in Shoeybi et al.), which we found improved MFU by up to four percentage points in initial experiments. Second, to leave tokens available that can be used in subsequent UL2 training.
Efficient Data Streaming
We leveraged MosaicML's StreamingDataset to host our data in a standard cloud object store and efficiently stream it to our compute cluster during training. StreamingDataset provides a number of advantages:
- Obviates the need to download the whole dataset before starting training.
- Allows instant resumption of training from any point in the dataset. A paused run can be resumed without fast-forwarding the dataloader from the start.
- Is fully deterministic. Samples are read in the same order regardless of the number of GPUs, nodes, or CPU workers.
- Allows arbitrary mixing of data sources in: simply enumerate the your data sources and desired proportions of the total training data, and StreamingDataset handles the rest. This made it extremely easy to run preparatory experiments on different data mixes.
Check out the StreamingDataset blog for more details!
Training Compute
All MPT-7B models were trained on the MosaicML platform with the following tools:
- Compute: A100-40GB and A100-80GB GPUs from Oracle Cloud
- Orchestration and Fault Tolerance: MCLI and MosaicML platform
- Data: OCI Object Storage and StreamingDataset
- Training software: Composer, PyTorch FSDP, and LLM Foundry
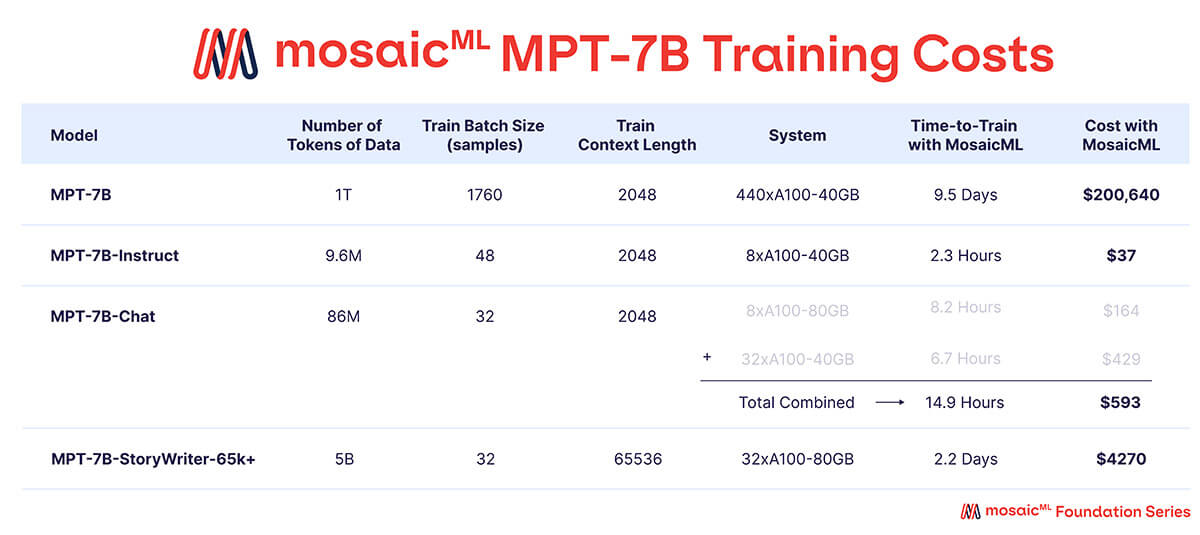
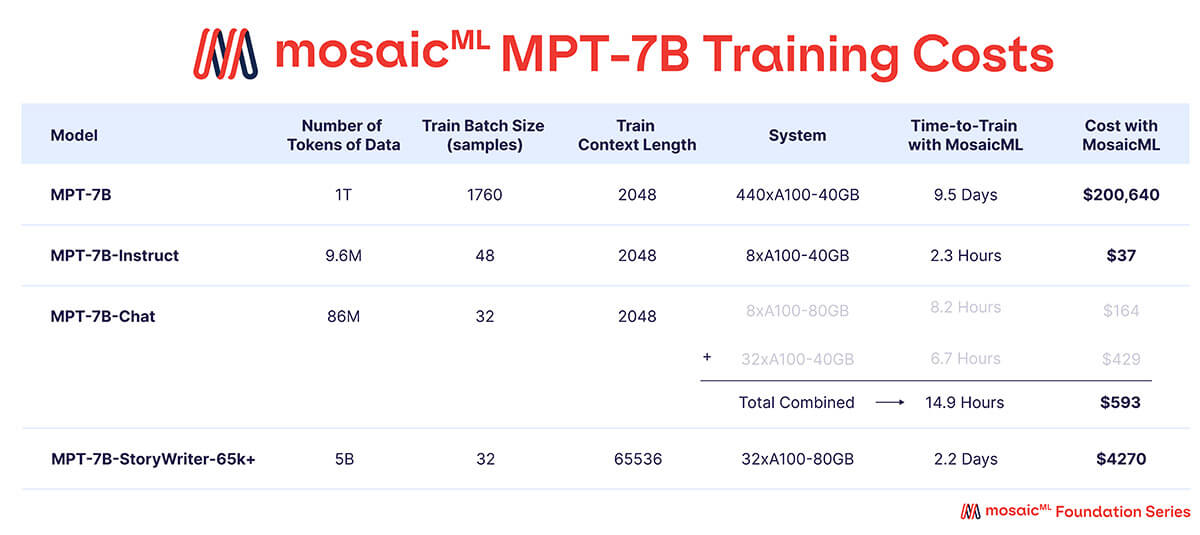
As shown in Table 3, nearly all of the training budget was spent on the base MPT-7B model, which took ~9.5 days to train on 440xA100-40GB GPUs, and cost ~$200k. The finetuned models took much less compute and were much cheaper – ranging between a few hundred and few thousand dollars each.
{kind=link}
Time to Train' is the total runtime from job start to finish, including checkpointing, periodic evaluation, restarts, etc. 'Cost' is computed with pricing of $2/A100-40GB/hr and $2.50/A100-80GB/hr for reserved GPUs on the MosaicML platform.
Each of these training recipes can be fully customized. For example, if you'd like to start from our open source MPT-7B and finetune it on proprietary data with a long context length, you can do that today on the MosaicML platform.
As another example, to train a new model from scratch on a custom domain (e.g. on biomedical text or code), simply reserve short-term large blocks of compute with MosaicML's hero cluster offering. Just pick the desired model size and token budget, upload your data to an object store like S3, and launch an MCLI job. You will have your very own custom LLM in just days!
Check out our earlier LLM blog post for guidance on the times and costs to train different LLMs. Find the latest throughput data for specific model configurations here. In line with our previous work, all MPT-7B models were trained with Pytorch FullyShardedDataParallelism (FSDP) and without tensor- or pipeline- parallelism.
Training Stability
As many teams have documented, training LLMs with billions of parameters on hundreds-to-thousands of GPUs is incredibly challenging. Hardware will fail frequently and in creative and unexpected ways. Loss spikes will derail training. Teams must "babysit" the training run 24/7 in case of failures and apply manual interventions when things go wrong. Check out the OPT logbook for a candid example of the many perils awaiting anyone training an LLM.
At MosaicML, our research and engineering teams have worked tirelessly over the last 6 months to eliminate these issues. As a result, our MPT-7B training logbook (Figure 5) is very boring! We trained MPT-7B on 1 trillion tokens from start to finish with no human intervention. No loss spikes, no mid-stream learning rate changes, no data skipping, automatic handling of dead GPUs, etc.

{kind=link}
MPT-7B was trained on 1T tokens over the course of 9.5 days on 440xA100-40GB. During that time the training job encountered 4 hardware failures, all of which were detected by the MosaicML platform. The run was automatically paused and resumed upon each failure, and no human intervention was required.

{kind=link}
ハードウェア障害が発生した場合、MosaicMLプラットフォームは自動的に障害を検出し、ジョブを一時停止し、破損したノードを隔離してから、ジョブを再開します。MPT-7Bのトレーニング実行中に、このような障害が4回発生しましたが、その都度ジョブは自動的に再開されました
どうやってこれを実現したのでしょうか?まず、アーキテクチャと最適化の改善により、収束の安定性に取り組みました。MPTモデルでは、位置エンコーディングの代わりにALiBiを使用しており、これにより損失スパイクに対する耐性が向上することがわかりました。また、AdamWの代わりにLion optimizerでMPTモデルをトレーニングしており、これにより安定した更新マグニチュードが得られ、オプティマイザの状態メモリが半分になります。
次に、MosaicMLプラットフォームのNodeDoctor機能を使用してハードウェア障害を監視�・解決し、JobMonitor機能を使用してこれらの障害が解決された後に実行を再開しました。これらの機能により、実行中に4回のハードウェア障害が発生したにもかかわらず、開始から終了まで人間の介入なしにMPT-7Bをトレーニングすることができました。自動再開がMosaicMLプラットフォームでどのように見えるかの詳細については、図6を参照してください。
推論
MPTは、推論のために高速、簡単、かつ安価にデプロイできるように設計されています。まず、すべてのMPTモデルはHuggingFace PretrainedModelの基本クラスからサブクラス化されているため、HuggingFaceエコシステムと完全に互換性があります。MPTモデルをHuggingFace Hubにアップロードしたり、標準的なパイプライン(例:`model.generate(...)`)を使用して出力を生成したり、HuggingFace Spacesを構築したり(こちらで一部ご覧いただけます!)することができます。
パフォーマンスについてはどうでしょうか?MPTの最適化されたレイヤー(FlashAttentionや低精度レイヤー正規化など)により、`model.generate(...)`を使用した際のMPT-7Bの標準パフォーマンスは、LLaMa-7Bのような他の7Bモデルよりも1.5倍〜2倍高速です。これにより、HuggingFaceとPyTorchだけで高速で柔軟な推論パイプラインを簡単に構築できます。
しかし、本当に最高のパフ�ォーマンスが必要な場合はどうでしょうか?その場合は、MPTウェイトを直接FasterTransformerまたはONNXにポートしてください。スクリプトと手順については、LLM Foundryの推論フォルダを確認してください。
最後に、最高のホスティング体験のために、MPTモデルをMosaicMLの推論サービスに直接デプロイしてください。MPT-7B-Instructのようなモデルのマネージドエンドポイントから開始したり、最適なコストとデータプライバシーのために独自のカスタムモデルエンドポイントをデプロイしたりできます。
次は何?
このMPT-7Bのリリースは、MosaicMLが2年間かけて構築し、実戦でテストしてきたオープンソースソフトウェア(Composer、StreamingDataset、LLM Foundry)と独自のインフラストラクチャ(MosaicML トレーニングおよび推論)の集大成です。これにより、顧客はあらゆるコンピューティングプロバイダー、あらゆるデータソースで、効率性、プライバシー、コストの透明性を備えてLLMをトレーニングでき、最初から物事を正しく行うことができます。
MPT、MosaicML LLM Foundry、およびMosaicMLプラットフォームは、カスタムLLMをプライベート、商用、およびコミュニティ用途で構築するための最良の出発点であると信じています。チェックポイントをファインチューニングする場合でも、ゼロから独自のモデルをトレーニングする場合でも同様です。コミュニティがこれらのツールと成果物をどのように活用していくかを楽しみにしています。
重要なのは、今日のMPT-7Bモデルはほんの始まりに過ぎないということです!お客様がより困難なタスクに対処し、製品を継続的に改善できるよう、MosaicMLは今後もますます高品質な基盤モデルを生成していきます。すでにエキサイティングな後続モデルがトレーニング中です。それらについての詳細は近日中にお知らせします!
謝辞
事前トレーニングデータセットのキュレーション、優れたトークナイザーの選択、その他多くの有益な議論にご協力いただいたAI2の皆様に感謝いたします⚔️
付録
データ
mC4
Multilingual C4 (mC4) 3.1.0は、2022年8月までのソースを含む、Chung et al.によるオリジナルのmC4のアップデートです。英語のサブセットを選択し、各ドキュメントに以下のフィルタリング基準を適用しました。
- 最も一般的な文字はアルファベットであること。
- 文字の92%以�上が英数字であること。
- ドキュメントが500語を超える場合、最も一般的な単語が総単語数の7.5%を超えないこと。ドキュメントが500語以下の場合、最も一般的な単語が総単語数の30%を超えないこと。
- ドキュメントは200語以上50000語以下であること。
最初の3つのフィルタリング基準はサンプル品質の向上に使用され、最後のフィルタリング基準(ドキュメントは200語以上50000語以下)は事前トレーニングデータの平均シーケンス長を増やすために使用されました。
mC4は、Dodge et al.による継続的な取り組みの一環としてリリースされました。
C4
Colossal Cleaned Common Crawl (C4)は、Raffel et al.によって導入された英語のCommon Crawlコーパスです。内部実験により、これがC4でトレーニングされたモデルにとってパレート改善であることが示されたため、Abbas et al.のセマンティック重複排除プロセスを適用して、C4内の類似度が最も高い20%のドキュメントを削除しました。
RedPajama
RedPajamaデータセットのいくつかのサブセットを含めました。これは、TogetherによるLLaMAのトレーニングデータを再現する試みです。具体的には、CommonCrawl、arXiv、Wikipedia、Books、およびStackExchangeのサブセットを使用しました。
The Stack
コード生成機能をモデルに持たせたかったため、6.4TBのコードデータコーパスであるThe Stackに注目しました。約2.9TBに重複排除(MinHashLSH経由)されたThe StackのバリアントであるThe Stack Dedupを使用しました。データセットサイズを削減し、関連性を高めるために、The Stackの358のプログラミング言語のうち18のサブセットを選択しました。
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
内部実験により、最大20%のコード(および80%の自然言語)でトレーニングしても自然言語評価に悪影響がないことが示されたため、事前トレーニングトークンの10%をコードで構成することを選択しました。
また、The Stack DedupのMarkdownコンポーネントを抽出し、これを独立した事前トレーニングデータサブセット(つまり、10%のコードトークンに含まれない)として扱いました。この動機は、マークアップ言語ドキュメントは主に自然言語であり、自然言語トークン予算に含めるべきであるということです。
Semantic Scholar ORC
Semantic Scholar Open Research Corpus (S2ORC)は、英語の学術論文のコーパスであり、高品質なデータソースと見なしています。以下の品質フィルタリング基準を適用しました。
- 論文はオープンアクセスであること。
- 論文にはタイトルと抄録があること。
- 論文は英語であること(cld3を使用して評価)。
- 論文は少なくとも500語と5つの段落があること。
- 論文は1970年以降、2022年12月1日より前に公開されたこと。
- 論文で最も頻繁に出現する単語はアルファベットのみで構成され、ドキュメントの7.5%未満に表示されること。
これにより9.9M件の論文が得られました。最新のデータセットバージョンを取得するための手順はこちらで、元の論文はこちらで確認できます。データセットのフィルタリング済みバージョンはAI2から提供していただきました。
評価タスク
Lambada: 書籍コーパスからキュレーションされた5153件のテキストサンプル。モデルが次の単語を予測することが期待される、数百語の段落で構成されています。
PIQA: 物理的な直感に訴える二項選択式の質問1838件。例:「質問:ハンガーにかけた服を移動するとき、どうすれば簡単に運べますか?」、「回答:「空の丈夫なハンガーをいくつか用意し、それに�服をかけたハンガーをいくつか引っ掛けて、一度にすべて運びます。」
COPA: 「XYZ、したがって/なぜならTUV」の形式の文100件。モデルがしたがって/なぜならの後に続く2つの可能な方法から選択する二項選択式の質問として提示されます。例:{"query": "その女性は機嫌が悪かった、したがって", "gold": 1, "choices": ["彼女は友人と世間話を始めた。", "彼女は友人に放っておいてくれと言った。"]}
BoolQ: 関連情報を含む文章に基づいた、はい/いいえで答える質問3270件。質問トピックはポップカルチャーから科学、法律、歴史など多岐にわたります。例:{"query": "文章:カーミット・ザ・フロッグはマペットのキャラクターであり、ジム・ヘンソンの最もよく知られた作品です。1955年に導入されたカーミットは、数多くのマペット作品、特にセサミストリートやマペット・ショー、そして他のテレビシリーズ、映画、スペシャル、広報活動などを通して、ストレートマンの主人公を務めてきました。ヘンソンは当初1990年に亡くなるまでカーミットを演じていましたが、スティーブ・ホイットマイアがその時点から2016年にその役を解任されるまでカーミットを演じました。カーミットは現在マット・フォーゲルが演じています。彼はまた、マペット・ベビーでフランク・ウェルカーによって、その他のアニメーションプロジェクトで時折、そして2018年のマペット・ベビーのリブートでマット・ダンナーによって声が当てられています。 質問:カーミット・ザ・フロッグはセサミストリートに出演したことがありますか? ", "choices": ["いいえ", "はい"], "gold": 1}
Arc-Challenge: 科学に関する4つの選択肢がある難しい多肢選択問題1172件
Arc-Easy: 科学に関する4つの選択肢がある簡単な多肢選択問題2376件
HellaSwag: 現実のシナリオが提示され、モデルがそのシナリオの最も可能性の高い結論を選択する必要がある4つの選択肢がある多肢選択問題10042件
Jeopardy: 科学、世界史、アメリカ史、言葉の起源、文学の5つのカテゴリからのJeopardyの質問2117件。モデルは正確な正解を提供する必要があります
MMLU: 57の多様な学術カテゴリからの多肢選択問題14,042件
TriviaQA: 自由応答形式のポップカルチャートリビア問題11313件
Winograd: モデルが代名詞の参照先が最も可能性が高いものを解決する必要がある273件のスキーマ問題
Winogrande: モデルが曖昧な文のどちらが論理的により可能性が高いかを解決する必要がある1,267件のスキーマ問題(文の両方のバージョンは構文的に有効です)
MPT Hugging Face Spaces プライバシーポリシー
当社のMPT Hugging Face Spaces プライバシーポリシーをご覧ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。