RLVRの力:Databricksで先導的なSQL推論モデルを訓練する
企業向けのシンプルなレシピ
によって データブリックス AI 研究チーム による投稿
更新: 研究成果の詳細は、arXivで公開中の新しい技術レポートをご覧ください。
更新(2025年8月12日): RLVRを用いて学習させた当モデルは、自己一貫性(Self-Consistency)と組み合わせることで、Bird Benchの「単一モデル」総合カテゴリにおいてトップの性能を達成しました!自己一貫性の有無(複数回のLLM呼び出しの許可・不許可)にかかわらず、他の単一モデルを上回る性能を示しています。以下では、単一モデルかつ単一LLM呼び出し(つまり、自己一貫性を使用しない)のカテ�ゴリにおいて、どのようにして最高性能のモデルを実現したかを解説します。今回の結果は、RLVRトレーニングの強力な効果と、自己一貫性のようなテスト時コンピュート(推論時の計算戦略)が、いかにうまく機能・融合するかを示すものです。なお、Best-of-nとRLVRの両機能は、Agent Bricksを通じてお客様へ順次提供を開始しています。
Databricksでは、強化学習(RL)を用いて、お客様が直面する問題や、Databricks AssistantやAI/BI Genieなどの製品向けの推論モデルを開発しています。これらのタスクには、コードの生成、データの分析、組織知識の統合、ドメイン固有の評価、そしてドキュメントからの情報抽出(IE)などが含まれます。コーディングや情報抽出のようなタスクは、報酬が確認できることが多いです -- 正確さは直接チェックできます(例えば、テストの通過、ラベルの一致)。これにより、学習した報酬モデルなしで強化学習を行うことができ、これをRLVR(検証可能な報酬を伴う強化学習)と呼びます。他のドメインでは、カスタムの報酬モデルが必要な場合もあります -- これもDatabricksがサポートしています。この投稿では、RLVRの設定に焦点を当てています。
RLVRの力を示す一例として、データサイエンスの人気のある学術的なベンチマークであるBIRDに対して、私たちの訓練スタックを適用しました。このベンチマークは、自然言語のクエリをデータベースで実行するSQLコードに変換するタスクを研究しています。これはDatabricksのユーザーにとって重要な問題であり、SQLの専門家でない人々がデータと対話することを可能にします。これはまた、最高の独自のLLMでも箱から出してすぐにはうまく機能しない難しいタスクです。BIRDは、このタスクの現実世界の複雑さやDatabricks AI/BI Genie(図1)のような実際の製品の全範囲を完全に捉えているわけではありませんが、その人気性により、データサイエンスにおけるRLVRの有効性をよく理解されたベンチマークで測定することができます。
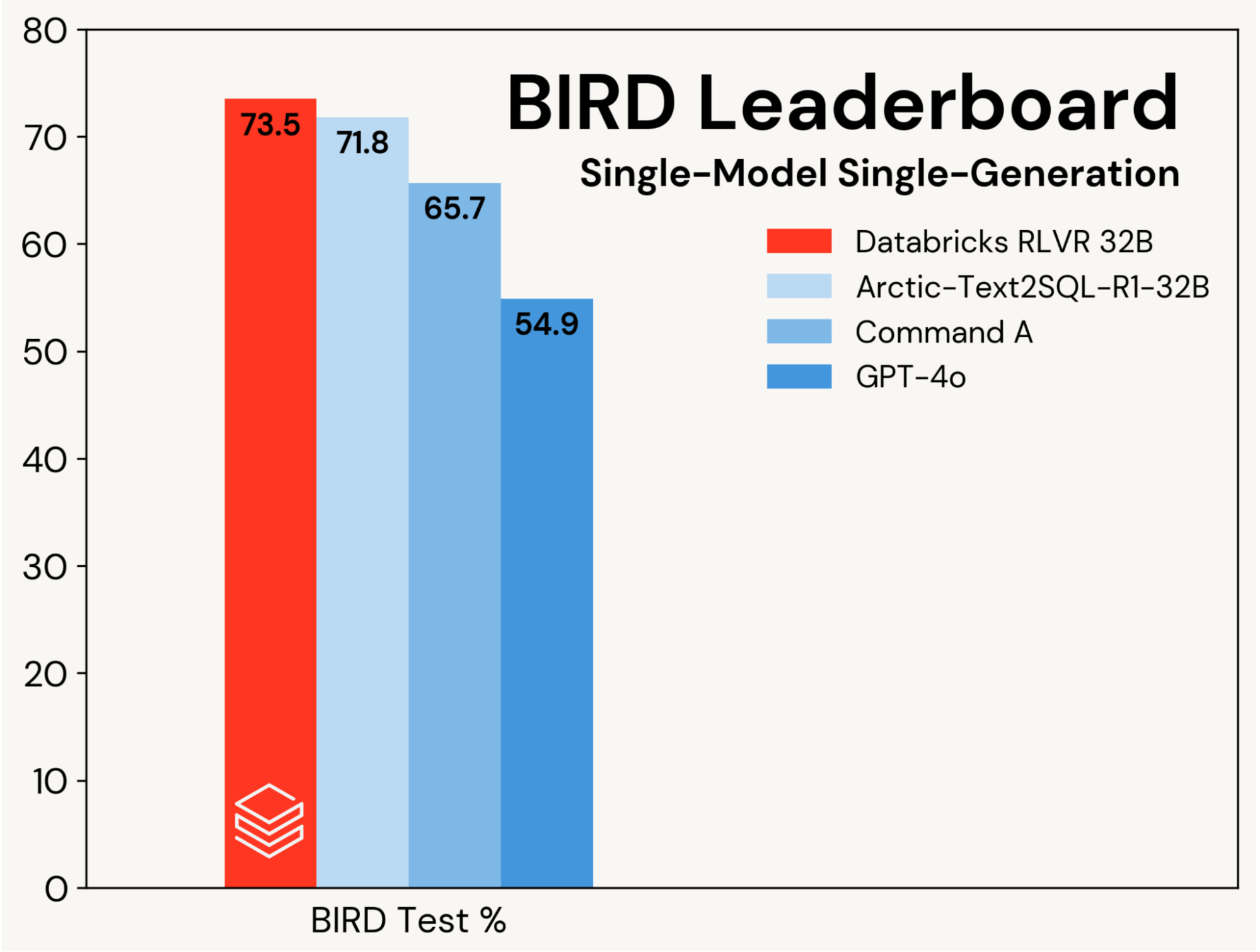
私たちは、RLVRを使用してベースのSQLコーディングモデルを改善することに焦点を当てており、これらの利益をエージェンティックな設計による改善から分離しています。進捗は、BIRDリーダーボードの単一モデル、単一世代トラック(つまり、自己一貫性なし)で測定され、これはプライベートなテストセットで評価します。
私たちは、このベンチマークで新たな最先端のテスト精度73.5%を達成しました。これは、私たちの標準的なRLVRスタックを使用し、BIRDの訓練セットだけで訓練した結果です。このトラックでの前回の最高スコアは71.8%[1]で、これはBIRDの訓練セットを追加のデータで増強し、独自のLLM(GPT-4o)を使用して達成されました。私たちのスコアは、元のベースモデルよりも8.7パーセントポイント高く、独自のLLMに対する大幅な改善です(図2を参照)。この結果は、RLVRのシンプルさと汎用性を示しています:私たちは、既製のデータと、Agent Bricksで展開している標準的なRLコンポーネントを使用して、このスコアを達成しました。そして、これは私たちがBIRDに初めて提出した結果です。RLVRは、十分な訓練データが利用可能な場合に、AI開発者が考慮すべき強力なベースラインです。
私たちは、BIRDの開発セットに基づいて提出物を構築しました。Qwen 2.5 32B Coder Instructが最良の出発点であることがわかりました。このモデルは、Databricks TAO – オフラインRL方法、および私たちのRLVRスタックを使用して微調整しました。このアプローチと丁寧なプロンプトとモデルの選択は、私たちをBIRDベンチマークのトップに導くのに十分でした。この結果は、AI/BI GenieやAssistantのような人気のあるDatabricks製品を改善し、お客様がAgent Bricksを使用してエージェントを構築するのを支援するために私たちが使用している同じ技術の公開デモンストレーションです。
私たちの結果は、RLVRの力と私たちの訓練スタックの有効性を強調しています。Databricksのお客様も、私たちのスタックを使用して推論ドメインで素晴らしい結果を報告しています。このレシピは強力で、組み合わせ可能で、さまざまなタスクに広く適用可能だと考えています。DatabricksでRLVRをプレビューしたい場合は、こちらからお問い合わせください。
1表1を参照 https://arxiv.org/pdf/2505.20315
著者: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。