PySpark Native Plottingのご紹介
PySpark DataFrameから簡単にビジュアライゼーションを作成
によって Xinrong Meng 、 Ruifeng Zheng による投稿
- PySpark Native Plottingの紹介:このブログでは、PySparkに組み込みの視覚化機能が必要である理由を説明し、Spark上のPandas APIとネイティブpandas DataFramesからユーザーが期待する機能との整合性を図っています。
- 主な特長と機能:私たちは、さまざまなサポートされているプロットタイプ、PySparkのプロットが効率的なデータ処理戦略(例えば、サンプリング、グローバルメトリクス)をどのように活用しているか、そしてPlotlyとの統合による視覚化について説明します。
- 実用的な例:私たちは、実用的な例を用いてPySparkプロットをデモンストレーションし、視覚化の作成とカスタマイズのガイド、プロットから得られる行動可能な洞察のハイライトを行います。
はじめに
Databricks Runtime 17.0(リリースノート)でPySparkにネイティブプロットが導入されたことを大変嬉しく思います。これはデータ可視化にとって大きな進歩です。データを視覚化するためにツール間を行き来する必要はもうありません。今では、PySparkのデータフレームから直接美しく直感的なプロットを作成できます。それは速く、シームレスで、直接組み込まれています。この待望の機能により、データの探索がこれまで以上に簡単でパワフルになりました。
PySparkでビッグデータを扱うことは常に強力で、特に大規模なデータセットの変換や分析においてはその力を発揮します。PySparkのデータフレームはスケールとパフォーマンスのために構築されていますが、ユーザーは以前、プロットを生成するためにそれらをApache Spark™上のPandas APIのデータフレームに変換する必要がありました。しかし、この追加のステップは可視化ワークフローを必要以上に複雑にしていました。PySparkとpandasスタイルのDataFramesの構造の違いは、しばしば摩擦を引き起こし、データを視覚的に探索するプロセスを遅らせました。
例
以下は、PySparkプロットを使用して、さまざまな製品カテゴリーでの売上、利益、利益率を分析する例です。
まず、以下に示すように、異なる製品カテゴリーの売上と利益データを含むデータフレームから始めます:
私たちの目標は、売上と利益の関係を視覚化し、さらに利益率を追加の視覚次元として組み込むことで、分析をより意味のあるものにすることです。以下はプロットを作成する��ためのコードです:
“fig”は“plotly.graph_objs._figure.Figure”型であることに注意してください。既存のPlotly機能を使用してレイアウトを更新することで、その見た目を向上させることができます。調整後の図は次のようになります:
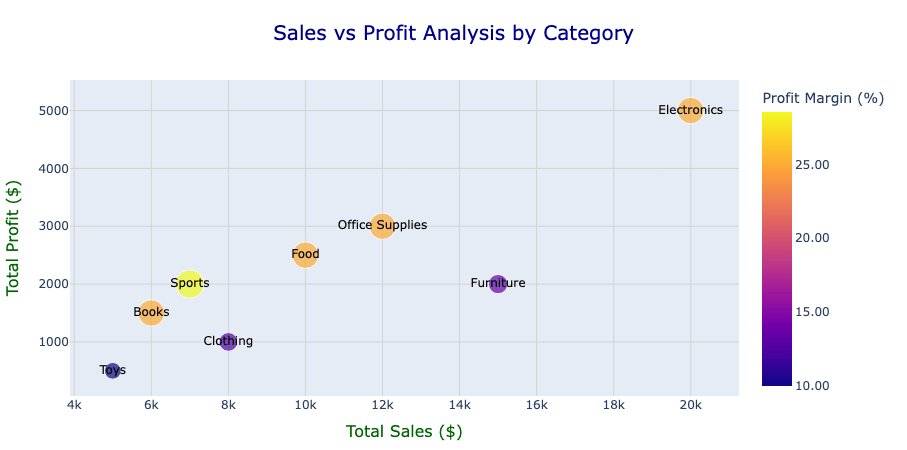
図から、さまざまなカテゴリーにおける売上と利益の間に明確な関係が見て取れます。例えば、エレクトロニクスは高い売上と利益を示していますが、利益率は比較的適度で、収益生成は強力ですが、効率の向上の余地があることを示しています。
PySparkプロットの特徴
ユーザーインターフェース
ユーザーは、PySparkデータフレームのプロットプロパティを呼び出し、サブメソッドとしてまたは“kind”パラメータを設定することで、希望するプロットタイプを指定することでPySparkプロットと対話します。例えば:
あるいは同等に:
このデザインは、Apache Spark上のPandas APIとネイティブのpandasのインターフェースに合わせており、pandasのプロットに既に慣れているユーザーにとって一貫性のある直感的な体験を提供します。
サポートされているプロットタイプ
PySparkプロットは、ライン、バー(水平を含む)、エリア、スキャッター、パイ、ボックス、ヒストグラム、密度/KDEプロットなど、一般�的なチャートタイプを多数サポートしています。これにより、ユーザーはPySparkのデータフレームから直接トレンド、分布、比較、関係を視覚化することができます。
内部処理について
この機能は、豊富でインタラクティブなプロット機能を提供するデフォルトの視覚化バックエンドとしてPlotly(バージョン4.8以降)によって動作し、ほとんどのプロットのデータ処理にはネイティブのpandasが内部的に使用されています。
プロットタイプにより、PySparkプロッティングのデータ処理は3つの戦略のうちの1つを通じて処理されます:
- トップN行: プロットプロセスは、DataFrameから限られた数の行(デフォルト:1000)を使用します。これは“spark.sql.pyspark.plotting.max_rows”を使用して設定できます。オプション、これにより迅速な洞察に効率的です。これはバープロット、水平バープロット、パイプロットに適用されます。
- サンプリング: ランダムサンプリングは、全データセットを処理することなく全体の分布を効果的に表現します。これにより、代表性を維持しながらスケーラビリティが確保されます。これはエリアプロット、ラインプロット、スキャッタープロットに適用されます。
- グローバルメトリクス: ボックスプロット、ヒストグラム、および密度/KDEプロットの場合、計算はデータセット全体で行われます。これにより、データ分布の正確な表現が可能となり��、統計的な正確さが確保されます。
このアプローチは、各プロットタイプのApache Sparkプロット戦略に対するPandas APIを尊重し、さらなるパフォーマンスの改善を提供します:
- サンプリング:以前は、データセット全体を二度通過する必要がありました - 一度目はサンプリング比率を計算し、二度目は実際のサンプリングを行うためです。私たちは、レザボワーサンプリングに基づく新しい方法を実装し、それを一回のパスに縮小しました。
- サブプロット:各列がサブプロットに対応する場合、すべての列のメトリクスを一緒に計算するようになり、効率が向上しました。
- MLベースのプロット:これらのプロットのために専用の内部SQL式を導入し、コード生成などのSQL側の最適化を可能にしました。
まとめ
PySpark Native Plottingは、PySparkと直感的なデータ可視化の間のギャップを埋めます。この機能により、PySparkユーザーはPySparkのデータフレームから直接高品質のプロットを作成することができ、データ分析をこれまで以上に迅速かつアクセスしやすくします。ぜひDatabricks Runtime 17.0でこの機能を試して、データ可視化体験を向上させてください!
もっと探求してみませんか?PySpark APIドキュメンテーションをチェックして、詳細なガイドと例を確認してください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。