Santalucía Seguros: 顧客サービスとエージェントの生産性を向上させるエンタープライズレベルの RAG を構築する
によって エドゥアルド・フェルナンデス・カリオン(サンタルシア・セグロス), マヌエル・バレロ・メンデス(サンタルシア・セグロス) 、 Luis Herrera による投稿
Translation Review by Akihiro.Kuwano
保険業界では、顧客は自分のニーズに応える、パーソナライズされた、迅速で効率的なサービスを求めています。 一方、保険代理店は、複数の場所からさまざまな形式で大量のドキュメントにアクセスする必要があります。 100 年以上家族をサポートしてきたスペインの企業 Santalucía Seguros は、顧客サービスとエージェントの生産性を向上させるために、製品、補償範囲、手順などに関するエージェントの問い合わせをサポートできる GenAI ベースの仮想アシスタント (VA) を実装しました。
VA は Microsoft Teams 内でアクセスされ、あらゆるモバイル デバイス、タブレット、コンピューターから、エージェントの質問に自然言語でリアルタイムに、24 時間 365 日対応で回答できます。 このアクセスにより、保険代理店の日常業務がはるかに簡単になります。 たとえば、顧客が補償範囲について質問すると、数秒以内に回答が得られます。 応答の速さは顧客満足度にプラスの影響を与えるだけでなく、即時かつ正確な回答を提供することで製品の販売を促進します。
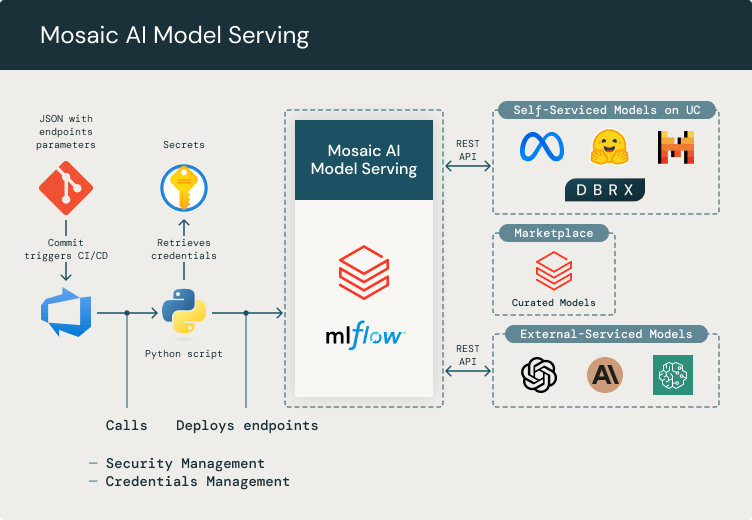
ソリューション アーキテクチャは、 DatabricksとMicrosoft Azureを搭載した Santalucía の Advanced アナリティクス プラットフォーム上で実行される Retrieval Augmented Generation (RAG) フレームワークに基づいており、柔軟性、プライバシー、セキュリティ、スケーラビリティを提供します。 このアーキテクチャにより、最新のドキュメントを埋め込みベースのベクター ストアに継続的に取り込むことができ、情報をインデックス化して迅速に検索および取得できるようになります。 RAG システムは、Databricks のオープンソース LLMOps ソリューションである MLflow の pyfunc モデルとして設定されています。 Databricks Model Servingまた、クエリのすべてのLLM モデルをホストするために、 エンドポイントも使用しました。
新しいリリースの継続的な配信をサポートしながら、優れたLLMOpsプラクティスと応答品質を維持することは、新しく取り込まれたドキュメントをRAGシステムにシームレスに統合する必要があるため、困難な場合があります。 応答の品質を確保することは当社のビジネスにとって非常に重要であり、以前に提供されたリリースの品質に悪影響を与えないことを保証せずにソリューションのコードの一部を変更する余裕はありません。 これには、回答の正確性と信頼性を維持するために、徹底的なテストと検証プロセスが必要です。 私たちは、Databricks データ インテリジェンス プラットフォームで利用可能な RAG ツールを使用して、出力に関するガバナンスとガードレールを備え、リリースに常に最新のデータが含まれるようにしました。
次に、高品質でスケーラブル、かつ持続可能なGenAIベースの仮想アシスタントの開発を成功させるために不可欠な重要な要素を掘り下げます。 これらの要素により、ソリューションの開発、展開、評価、監視、提供が容易になりました。 ここでは、その中でも特に重要なものを2つ紹介します。
Databricks モデルサービング
Databricks Model Serving を使用すると、GPT-4 や 入手可能なその他のモデルなどの外部 LLM をDatabricks Marketplace プラットフォームに簡単に統合できます。 これらのサードパーティ モデルの構成、資格情報、アクセス許可を管理し、 Databricks Model Serving を介してアクセスできるようにします。これにより、あらゆるアプリケーションやサービスが統一された方法でモデルを使用できるようになります。また、開発チームが新しいモデルを簡単に追加できる抽象的なレイヤーを提供することで、サードパーティのAPI統合が不要になります。Databricks Model Serving は、トークンの消費、資格情報、セキュリティ アクセスの管理を可能にするため、私達にとって非常に重要です。私達は、適切なCI/CD Databricksワークスペースにエンドポイントをデプロイする プロセスを備えたシンプルな git リポジトリを使用して、リクエストに応じて新しいエンドポイントを作成およびデプロイするための簡単な方法を構築しました。
開発者は、Databricks エンドポイントを介して間接的に LLM モデル (たとえば、Azure OpenAI API などの外部サービスや、Databricks Marketplace からデプロイできるセルフホスト型のその他のサードパーティ モデル) と対話できます。 私たちは、git リポジトリを通じてプラットフォームに新しいモデルをデプロイし、そこで資格情報とエンドポイントをパラメーター化するための構成 JSON を定義します。 私たちはこれらの認証情報をAzure Key vaultに安全に保管し、MLflowを使用してCI/CDパイプラインでDatabricksにモデルをデプロイしています。
新しいリリース前の LLM as a judge for evaluation
RAG応答の品質を評価することは、Santalucíaにとって非常に重要です。 新しいドキュメントをボットに取り込むたびに、更新されたバージョンをリリースする前に、アシスタントのパフォーマンスを確認する必要があります。 つまり、ユーザーが応答の品質を評価するのを待つことはできません。代わりに、システム自体が本番運用に拡張する前に品質を評価できなければなりません。
私たちが提案するソリューションでは、CI/CD パイプライン内の判定として大容量の LLM を使用します。 退役軍人省の回答がどの程度優れているかを追跡するには、まず、専門家によって検証された一連の質問のグラウンドトゥルースを作成する必要があります。 たとえば、新しい製品の補償範囲を VA に含める場合は、ドキュメントを入手し、(手動または LLM の支援を受けて) ドキュメントに関する一連の質問と各質問に対する予想される回答を作成する必要があります。 ここで重要なのは、リリースごとに、グラウンドトゥルースの一連の質問と回答によってモデルの堅牢性が高まることを認識することです。
The LLM-as-a-judge は、期待される回答と VA によって提供される回答間の正確性、関連性、一貫性を測定するための自然言語ベースの基準で構成されています。 したがって、グラウンドトゥルースの各質問と回答のペアについて、ジャッジ(the judge)は品質の採点を監督します。 たとえば、次のような基準を設計できます。
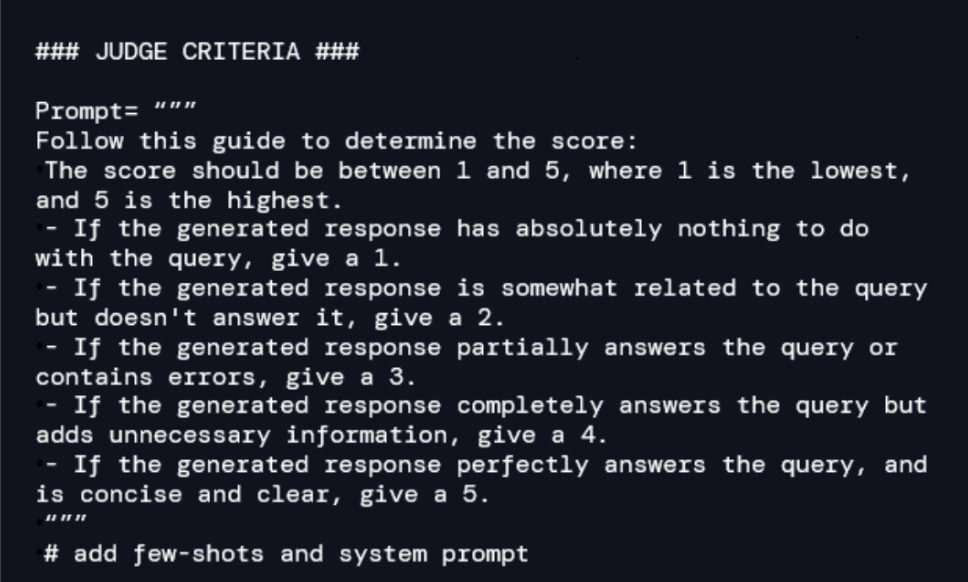
CI/CD パイプライン内で評価プロセスを確立します。 VAはグラウンドトゥルースを使用して各質問に回答し、ジャッジ(the judge)は期待される回答とVAから提供された回答を比較してスコアを割り当てます。 以下は、2 つの質問の例です。
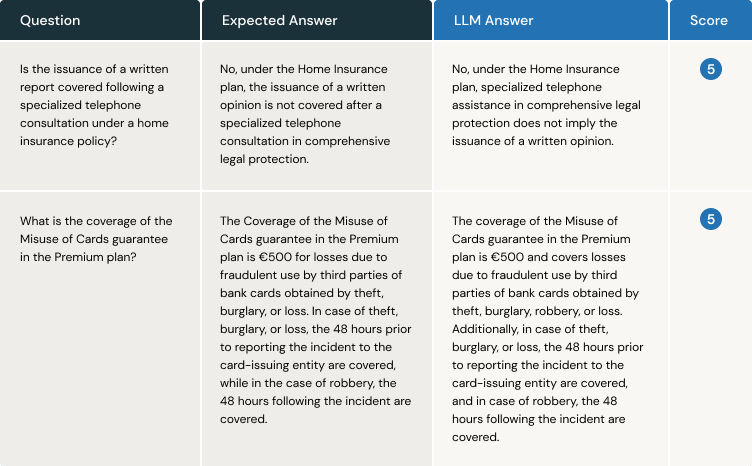
最初の利点は明らかです。VA が情報を取得して応答を生成する際に故障していることをユーザーから通知されるのを待つ必要がありません。 さらに、プロンプトなど、コードの一部に微調整を加える必要があることがよくあります。 このような評価システムは、グラウンドトゥルースと LLM をジャッジ(the judge)として基づいており、ユーザー エクスペリエンスを向上させるためにプロンプトに加えられた変更が、以前に配信されたリリースからの応答の品質に影響を与えているかどうかを検出できます。
まとめ
サンタルチアは、GenAIベースの仮想アシスタント用のRAGフレームワークを使用して、強力で適応性の高いアーキテクチャを実装し�ました。 Databricks のソリューションは、外部のLLMモデルと Databricks の Advanced アナリティクス プラットフォームを組み合わせ、データとモデルのプライバシー、セキュリティ、制御を保証します。 応答のスピードと品質は、ビジネスと顧客満足度にとって非常に重要です。 Databricks Model Servingと LLM-as-a-judge として使用することで、仮想アシスタントはLLM展開のベスト プラクティスを実証しながら、ユーザーの期待を上回りました。 当社は、応答品質、パフォーマンス、コストの面でソリューションをさらに改善することに注力しており、Databricks チームとのさらなるコラボレーションを楽しみにしています。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。