DatabricksとMathworksを使用したMATLABおよびSimulinkモデルのスケーリング
によって ジェニー・パーク, チャンダナ・パドマナバン, スーザン・ミルザ, ザカリー・ジェイコブソン, アンディ・ザ, マイケル・ブラウン, ア��ルヴィンド・ホサグラハラ 、 アンダース・ソランダー による投稿
あなたがヘルスケア、航空宇宙、製造業、政府などのどの業界から来ていても、ビッグデータという言葉は見知らぬものではないでしょう。しかし、そのデータが現在のMATLABまたはSimulinkモデルにどのように統合されるかは、今日あなたが直面している課題かもしれません。これがDatabricksとMathworkのパートナーシップが2020年に構築され、顧客が大規模なデータからより迅速に有意義な洞察を得るための支援を続けている理由です。これにより、エンジニアは新しいコードを学ぶことなくMathworksでアルゴリズム/モデルの開発を続けることができ、Databricks Data Intelligence Platformを利用して、それらのモデルをスケールしてデータ分析を行い、モデルを反復的に訓練しテストすることができます。
例えば、製造業では、予測保守が重要なアプリケーションです。エンジニアは、MATLABの高度なアルゴリズムを利用して機械データを分析し、潜在的な設備の故障を驚くほど正確に予測することができます。これらの高度なシステムは、バッテリーの故障を最大2週間前まで予測することができ、積極的なメンテナンスを可能にし、車両や機械の運用における高額なダウンタイムを最小限に抑えます。
このブログでは、事前チェックリスト、いくつかの人気のある統合オプション、「始める方法」の指示、およびDatabricksのベストプラクティスに基づいた参照アーキテクチャをカバーし、あなたのユースケースを実装します。
プレフライトチェックリスト
統合プロセスを開始するために答えるべき一連の質問がここにあります。MathworksとDatabricksの技術サポート担当者に回答を提供して、彼らがあなたのニーズに合わせて統合プロセスを調整できるようにします。
- Unity Catalogを使用していますか?
- MATLAB Compiler SDKを使用していますか? MATLAB Compiler SDKのライセンスはありますか?
- あなたはMacOSまたはWindowsを使用していますか?
- どのようなモデルやアルゴリズムを使用していますか?モデルはMATLABまたはSimulink、または両方を使用して構築されていますか?
- これらのモデルはどのMATLAB/Simulinkツールボックスを使用していますか?
- Simulinkモデルの場合、*.matファイルとして保存される必要がある状態変数/パラメーターはありますか?モデルは中間状態/結果を*.matファイルに書き込んでいますか?
- あなたはどのMATLABランタイムバージョンを使用していますか?
- どのDatabricks Runtimeバージョンにアクセスできますか?最低必要なのは10です
DatabricksでのMATLABモデルのデプロイ
DatabricksでMATLABモデルを統合する方法は多数ありますが、このブログでは、お客様が実装したいくつかの人気のある統合アーキテクチャについて説明します。開始するには、Databricks用のMATLABインターフェースをインストールして、SQLインターフェース、RestAPI、テストと開発のためのDatabricks Connect、そして製造用途のコンパイラオプションなどの統合方法を探索する必要があります。
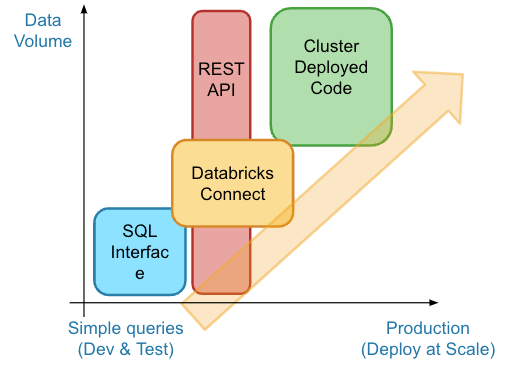
統合方法の概要
DatabricksへのSQLインターフェース
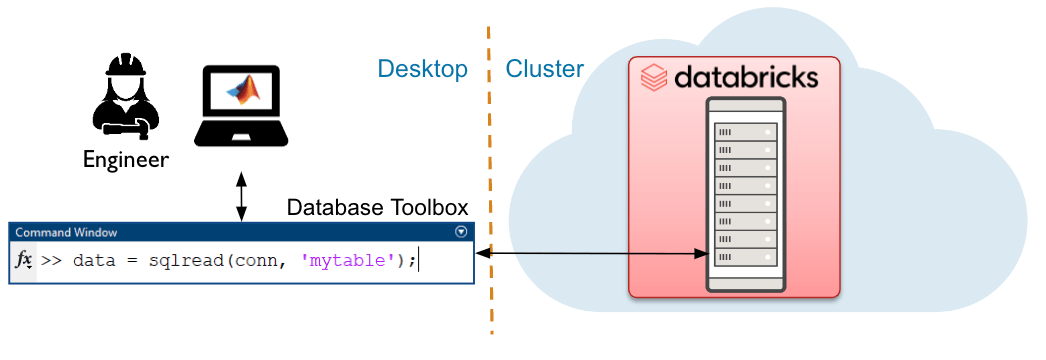
SQLインターフェースは、モデストなデータ量に最適で、データベースのセマンティクスを使用して迅速かつ簡単にアクセスできます。ユーザーは、Database Toolboxを使用してMATLABから直接Databricksプラットフォームのデータにアクセスできます。
DatabricksへのRestAPI
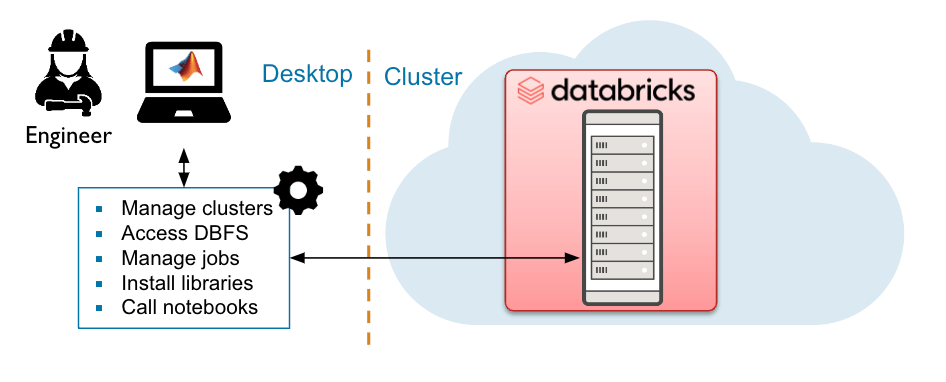
REST APIを使用すると、ユーザーはDatabricks環境内のジョブとクラスタを制御することができます。これには、Databricksリソースの制御、自動化、データエンジニアリングワークフローなどが含まれます。
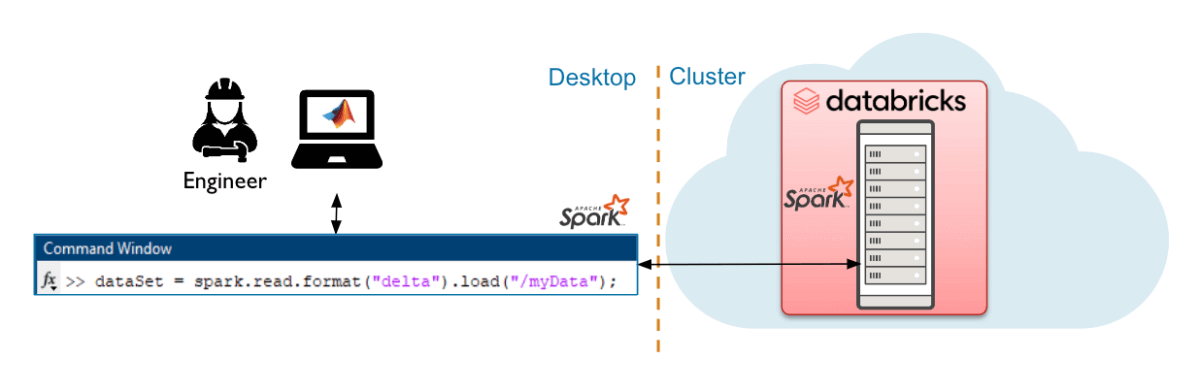
Databricks Connect Interface to Databricks
Databricks Connect(DB Connect)インターフェースは、中から大規模なデータ量に最適で、ローカルのSparkセッションを使用してDatabricksクラスター上でクエリを実行します。
MATLAB Compiler SDKを使用して、Databricksで大規模に実行するためのMATLABのデプロイ
MATLAB Compiler SDKはMATLABの計算をデータに持ち込み、スパークを介して大量のデータボリュームを使用して生産をスケールアップします。デプロイされたアルゴリズムは、オンデマンド、スケジュール、またはデータ処理パイプラインに統合して実行することができます。
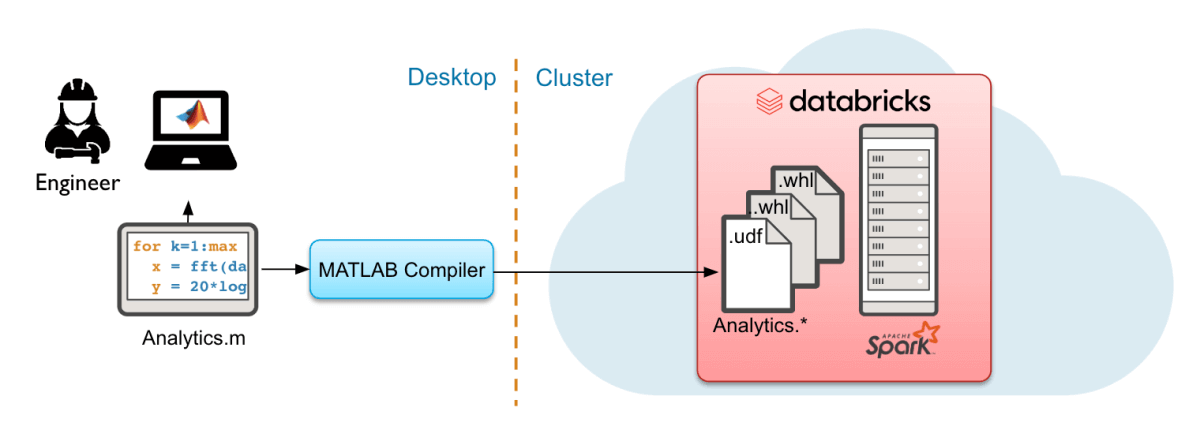
これらのデプロイメント方法の詳細な手順については、MATLABとDatabricksチームにお問い合わせください。
次のステップ
インストールとセットアップ
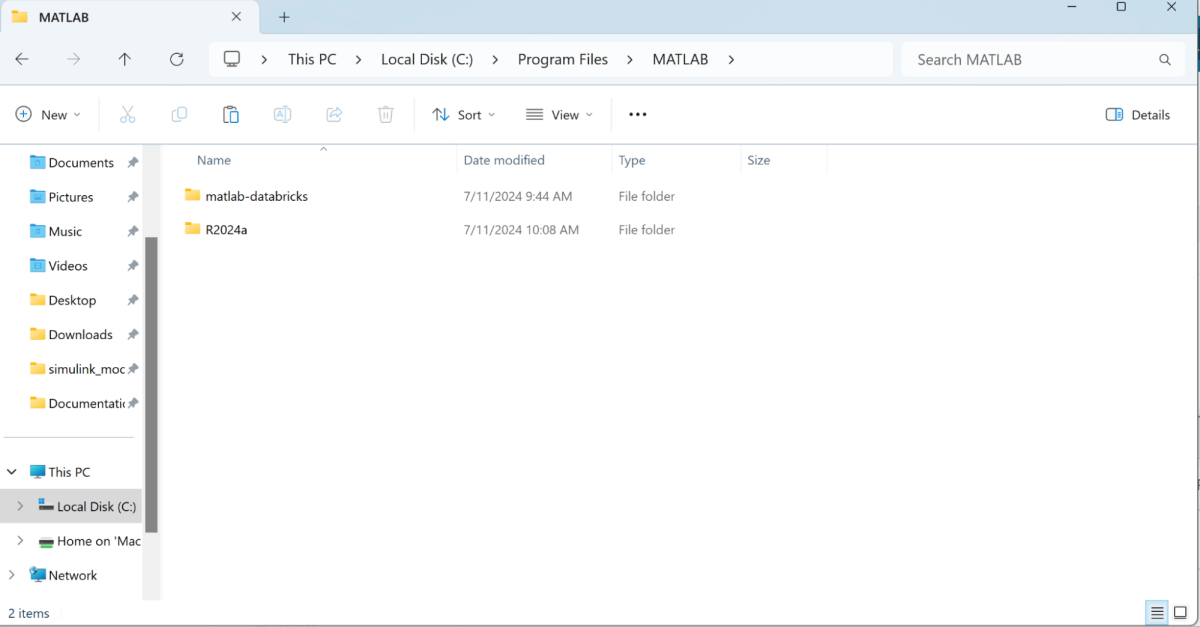
- Databricks用のMATLABインターフェースに移動し、下までスクロールして「Databricks用のMATLABインターフェースをダウンロード」ボタンをクリックしてインターフェースをダウンロードします。zipファイルとしてダウンロードされます。
- 圧縮されたzipフォ�ルダ“matlab-databricks-v4-0-7-build-...”をProgram Files\ MATLAB内に展開します。展開すると“matlab-databricks”フォルダが表示されます。このフォルダとこの階層にフォルダがあることを確認してください:
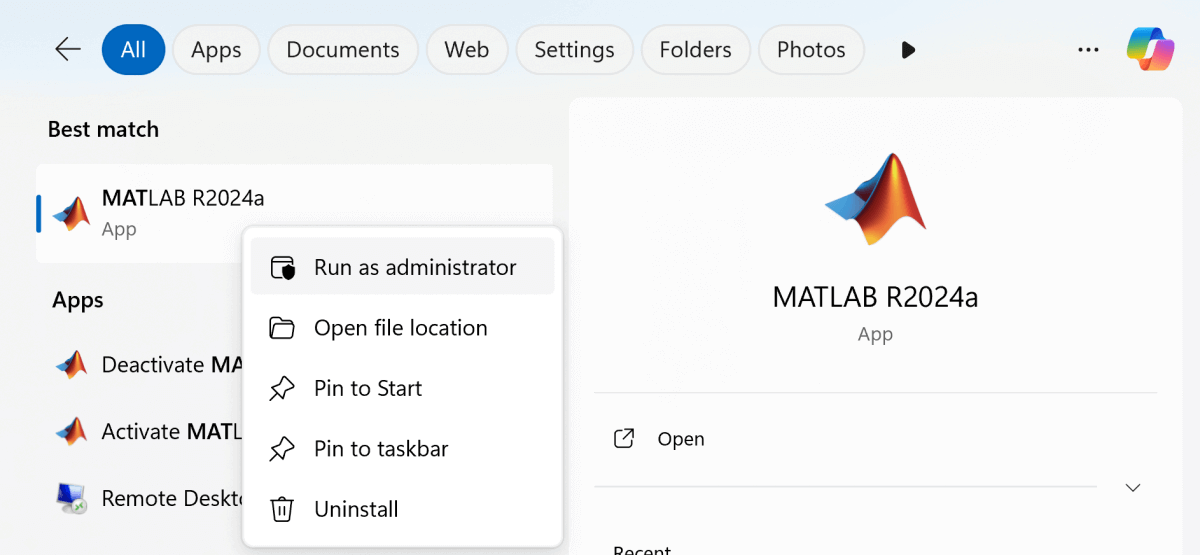
- ローカルのデスクトップアプリケーションからMATLABアプリケーションを起動し、管理者として実行することを確認してください
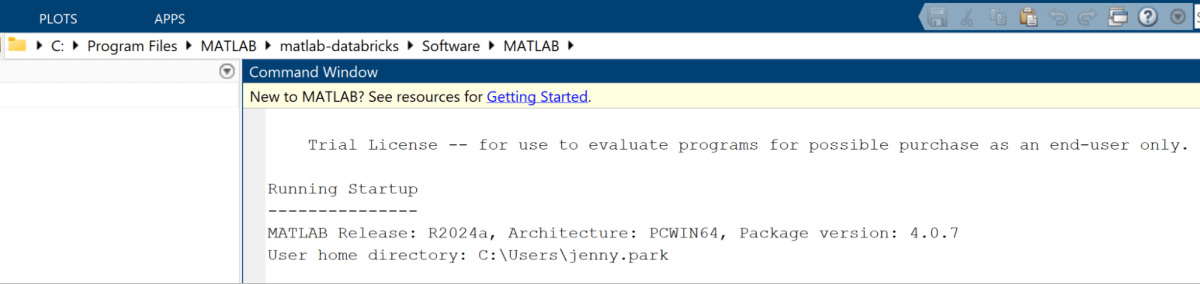
- MATLABのコマンドラインインターフェースに移動し、「ver」と入力して、必要なすべての依存関係があることを確認します:

- 次に、Databricksクラスターにランタイムをインストールする準備が整いました:
- このパスに移動します:C:\Program Files\MATLAB\matlab-databricks\Software\MATLAB: cd <C:\[Your path]\Program Files\MATLAB\matlab-databricks\Software\MATLAB>
- フォルダーアイコンの隣に現在のディレクトリパスが表示されているはずです。上記に書かれたパスと同じように見えることを確認し、�現在のフォルダに
install.mが利用可能であることを確認します。
- MATLABターミナルから
install()を呼び出します - クラスターの設定に関するいくつかの質問が表示されます。
- 認証方法、Databricksのユーザー名、Databricksをホストするクラウドベンダー、Databricksの組織IDなど

- 認証方法、Databricksのユーザー名、Databricksをホストするクラウドベンダー、Databricksの組織IDなど
- 「このパッケージのダウンロードしたzipファイルへのローカルパスを入力してください(あなたのローカルマシン上のものを指定してください)」とプロンプトが表示されたとき
- MATLABの圧縮zipファイルへのパスを提供する必要があります。例:C:\Users\someuser\Downloads\matlab-databricks-v1.2.3_Build_A1234567.zip
- ジョブは以下に示すようにDatabricksで自動的に作成されます(ジョブのタイムアウトが30分以上に設定されていることを確認してください。タイムアウトエラーを避けるため)
- このステップが成功裏に完了すると、あなたのパッケージは使用準備が整うはずです。MATLABを再起動し、
startup()を実行する必要があります。これにより、設定と構成が確認されます。
Databricks用のMATLABコードのインストールとパッケージングの確認
- 次の手順で、一つの統合オプション、Databricks-Connectを簡単にテストすることができます:
spark = getDatabricksSessionds = spark.range(10)Ds.show- これらが機能しない場合、最も可能性の高い問題は、サポートされているコンピュート(DBR14.3LTSがテストに使用されました)に接続されていないことや、`startup()`の出力の認証ヘッダーの下にリストされている設定ファイルを変更する必要があることです。
- あなたの .whl をアップロードしてくださいファイルをDatabricksボリュームに
- ノートブックを作成し、“MATLAB install cluster”をノートブックにアタッチし、.whlから関数をインポートします。ラッパーファイル
MATLABモデルを使用したDatabricksでのバッチ/リアルタイムユースケースの参照アーキテクチャ
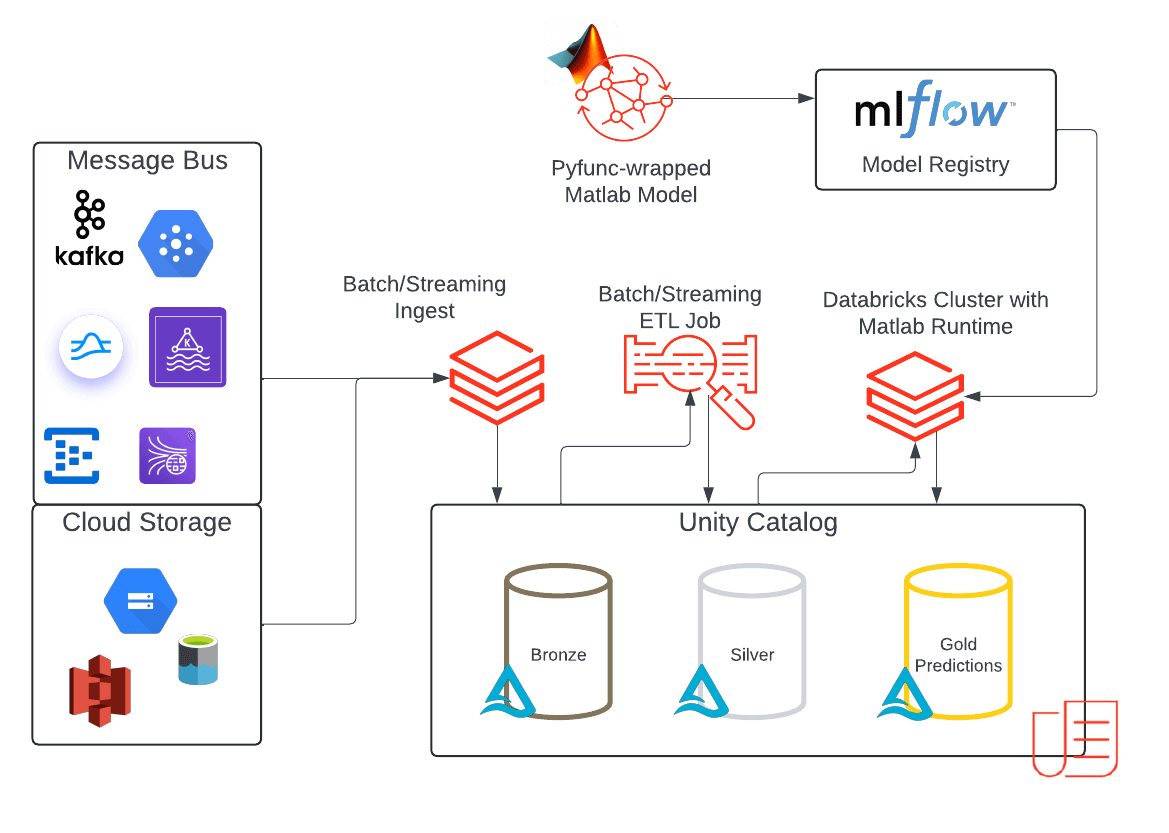
このアーキテクチャは、MATLABモデルを組み込んだDatabricksでのエンドツーエンドのMLバッチまたはストリーミングのユースケースの参照実装を示しています。このソリューションは、Databricks Data Intelligence Platformを最大限に活用します:
- このプラットフォームは、Unity Catalog(UC)へのストリーミングまたはバッチデータの取り込みを可能にします。
- 受信データは、未処理のデータを表すブロンズテーブルに保存されます。
- 初期処理と検証の後、データはSilverテーブルに昇格し、クリーンで標準化されたデータを表します。
- MATLABモデルは.whlとしてパッケージ化されていますファイルは、ワークフローやインタラクティブクラスタでカスタムパッケージとして使用する準備ができています。これらのホイールファイルは、前述のようにUCボリュームにアップロードされ、今ではUCによってアクセスが管理されるようになりました。
- UCで利用可能なMATLABモデルを、Volumesパスからクラスタスコープのライブラリとしてクラスタにロードできます。
- その後、MATLABライブラリをクラスタにインポートし、カスタムpyfunc MLflowモデルオブジェクトを作成して予測します。MLflowの実験でモデルをログに記録すると、異なるモデルバージョンと対応するpython wheelバージョンを簡単かつ再現性のある方法で保存し、追跡することができます。
- 入力データと一緒にUCスキーマにモデルを保存し、他のカスタムモデルと同様にMATLABモデルの権限を管理できます。これらは、UCボリュームにロードされたコンパイル済みのMATLABモデルに設定したものとは別の権限になることがあります。
- 一度登録されると、モデルは予測を行うためにデプロイさ�れます。
- バッチおよびストリーミングの場合 - モデルをノートブックにロードし、predict関数を呼び出します。
- リアルタイムの場合 - サーバーレスのModel Servingエンドポイントを使用してモデルを提供し、REST APIを使用してクエリします。
- ワークフローを使用してジョブをオーケストレーションし、バッチ取り込みをスケジュールするか、継続的にデータを取り込み、MATLABモデルを使用して推論を実行します。
- あなたの予測をUnity CatalogのGoldテーブルに保存し、ダウンストリームのユーザーが利用できるようにします。
- Lakehouse Monitoringを利用して、出力予測を監視します。
まとめ
MATLABをDatabricksプラットフォームに統合したい場合、現在存在する異なる統合オプションを取り上げ、エンドツーエンドの実装とインタラクティブな開発体験のオプションについて説明したアーキテクチャパターンを提示しました。MATLABをプラットフォームに統合することで、Spark上の分散コンピューティングの利点、Deltaによる強化されたデータアクセスとエンジニアリング機能、そしてUnity Catalogを使用したMATLABモデルへの安全なアクセス管理を活用できます。
これらの追加リソースをチェックしてください:
ビッグデータ処理について知りたかったすべてのこと(ただし、尋ねるのが怖すぎた)» Developer Zone - MATLAB & Simulink
DatabricksとMathWorksを使用したエンジニアと科学者のための実用的な洞察
電気故障検出の変革:DatabricksとMATLABの力
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。