意識不明の患者問題:ヘルスケアとライフサイエンスにおけるエンティティ解決の重要性の考察
このブログは、Stardogのシニア・ソリューション・アーキテクト、ティム・セドラックとの共同執筆です。
ヘルスケアとライフサイエンスでは、正確さがすべてです。 エンティティの解決(同じものを参照する複数のデータソースのレコードを特定、照合、統合するプロセス)に関しては、特にそうです。
医療機関やライフサイエンス企業にとって、これは複雑かつ重要な課題です。 幸いなことに、Databricks データインテリジェンスプラットフォームはこのような問題にも簡単に対応できます。 この革新的なソリューションはレイクハウス・アーキテクチャで構築され、セマンティック・レイヤーとしてStardog Voiceboxを使用しています。
医療における実体解決の重要性を示す実例を見てみましょう。 そして、今日組織が直面している課題に対する解決策についてお話します。
ERにおける患者識別-最も重要なエンティティ解決
あなたが救急外来の医師だとしましょう。 意識不明の患者(交通事故の被害者)が緊急治療を必要としています。 相手の命を救う可能性のある決断を素早く下す必要があります。 選択の根拠となる情報が多ければ多いほど、結果は良くなります。 患者の病歴は? アレルギーは? どのような薬を服用していますか?
ありがたいことに、電子カルテ(EHR)のおかげで、データへの迅速かつ大規模なアクセスが容易になりました。 しかし、患者の記録を取り出すには、まずその患者が誰なのかを特定する必要があります。 運転免許証は役に立つかもしれませんが、それが最新で正確なものであることをどうやって確認できますか? メインストリート122番地のボブ・スミスは、メインストリート122番地のロバート・スミスと同一人物ですか?
あなたは今、ID解決と呼ばれる技術的な困難に直面しています。 正しい答えを素早く見つけることが、命を救うことにつながるのです。 間違った答えを見つけると、壊滅的な結果になるかもしれません。
ID解決は、エンティティ解決という大きな領域における一つの問題です。 エンティティ解決の目的は、重複を排除し、各エンティティが一意に表現されるようにすることです。 その結果、さまざまなデータセットにわたるエンティティの包括的で正確なビューが得られます。
患者の成果を直接改善するためのデータ課題の克服
患者識別は、ヘルスケアやライフサイエンスにおける様々なエンティティ解決の課題の一部です。 これらの問題をうまく管理することは、患者の体験に大きなプラスの効果をもたらします。 そのような課題は、以下のようなさまざまなツールに存在します:
- デジタル・フロントドア:医療提供者や支払者とのすべてのデジタル・インタラクションにおける患者の単一IDは、患者の体験を向上させることができ、患者を唯一の存在として理解する必要があります。
- マスター患者インデックス:医療記録の統一されたディレクトリは、各患者の一意の識別子の信頼性に依存し、新しい異種ソースからのデータを迅速に組み込むことができるシステム上に構築されている場合、よりスケーラブルです。
- 医師データの照合:医療記録や研究データベースにわたる医師の統一された信頼できるプロフィールを作成するには、多様なデータセットを調整する必要があります。
- 施設データのマッチング:病院、診療所、その他の施設に関する情報を正確にリンクさせて業務を改善することは、複雑な作業です。
患者体験を向上させるためにこれらすべてのツールを最適化するには、強固なエンティティ解決が必要です。 しかし、この古典的に複雑な問題には、いくつかの技術的な課題があります。
- データの品質とばらつき:一貫性のないデータ形式、タイプミス、欠損値、その他のデータ品質の問題は、エンティティの正確な照合を著しく阻害します。
- スケーラビリティ:データベースが大きくなるにつれ、レコードのマッチングの計算量は指数関数的に増加します。
- データ照合の曖昧さ:異なるレコードが類似した情報や重複した情報を持つことがあり、それらが同じエンティティを参照しているかどうかの判断が曖昧になることがあります。
- 言語と意味の違い:グローバルなデータベースでは、言語、命名規則、文化的なニュアンスの違いが、エンティティを正確に解決する複雑さに拍車をかけます。
以前のブログでは、Databricksでエンティティ解決の問題を解決するための様々な戦略をご紹介しました。 本日は、StardogとDatabricksを併用することで、医療機関やライフサイエンス企業がエンティティの解決に取り組み、転帰の改善と価値の抽出を迅速に行えるようになることをご紹介します。
Stardogとは?
Stardogは、ナレッジグラフ・テクノロジーを使用することで、データガバナンスとアクセス制御を前提に、大企業のユーザーがどのような質問に対しても、信頼でき、タイムリーで正確な回答を得ることを妨げる、データのサイロ化、スプロール化、コンテキストの問題を解決します。
Stardogのお客様は、Databricksの内外に保存されているデータのコンテキスト化されたビューを作成します。 データは、データポイント間の概念的な関係に基づく情報のネットワークとして探索することができます。 この「セマンティック・レイヤー」では 、データが存在するストレージ・システムの外にデータを移動する必要はありません。
Stardogはまた、組織が大規模な言語モデル(LLM)を採用するのを妨げる幻覚などのGenerative AIのリスクを最小限に抑えるのに役立ちます。 MosaicMLのプラットフォームを活用して微調整を行うStardog Voiceboxは、LLMとKnowledge Graphを活用した、規制対象の企業向けの幻覚のない会話データプラットフォームです。 そのような反応は、データからだけでなく、それが何を意味するのかにも通じています。 Voiceboxへの早期アクセスはStardog Cloudで利用可能で、Stardog CloudはPartner Connectを通じてDatabricksと統合されます。
Stardog Voiceboxは、患者、医療提供者、施設、処置などのビジネス・オ�ブジェクトに関連するデータを、データ・ランドスケープ全体で識別し、リンクすることができます。 その結果、ヘルスケアやライフサイエンスのユースケースをサポートし、Databricksのパワーを活用してスケールの大きなデータ処理を行うことで、より良い意思決定が可能になります。
実際のソリューション
StardogとDatabricksのエンティティ解決マッチング機能を実証するために、CMS(Centers for Medicare and Medicaid Services)のNPPES(National Plan and Provider Enumeration System)とCMSのOpenPaymentsのサンプルデータセットを使用しました。 NPPESには個々の医師の基本的なディレクトリ情報が含まれており、OpenPaymentsには医薬品や耐久性医療機器(DME)と医師との関係が開示されています。 私たちの目標は、OpenPaymentsに登録されている医師のディレクトリ情報を特定することです。
ノートブック、データ、モデルを共有するためのオープンマーケットであるDatabricks Marketplaceからデータセットをインポートし、pyspark.sqlを使用してソース間でデータを正規化します。 次に、データ・モデリングを簡素化するビジュアル・アプリケーションであるStardog Designerを使用して、医師、診療所所在地、専門分野の概念をキャプチャするベースライン・データ・モデルを作成しました。 Stardog Designerのデータソースマッピング機能を使用して、National ProvidersとOpen Paymentsのデータセットをこのデータモデルに合わせました。
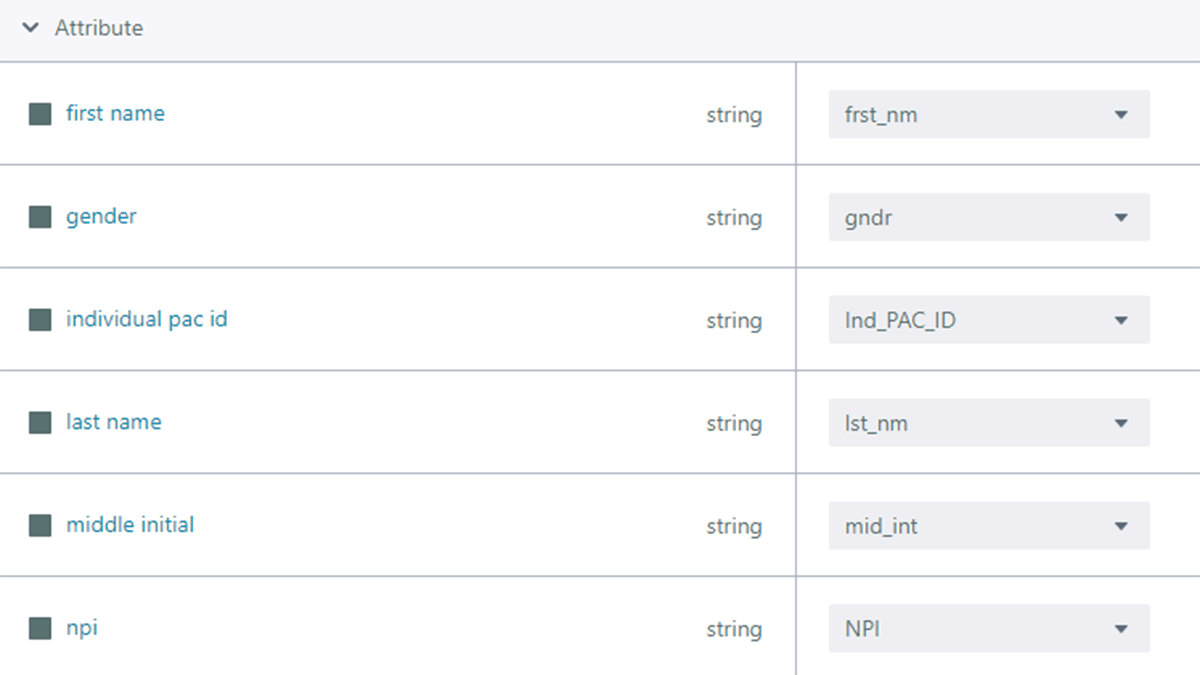
{kind=link}
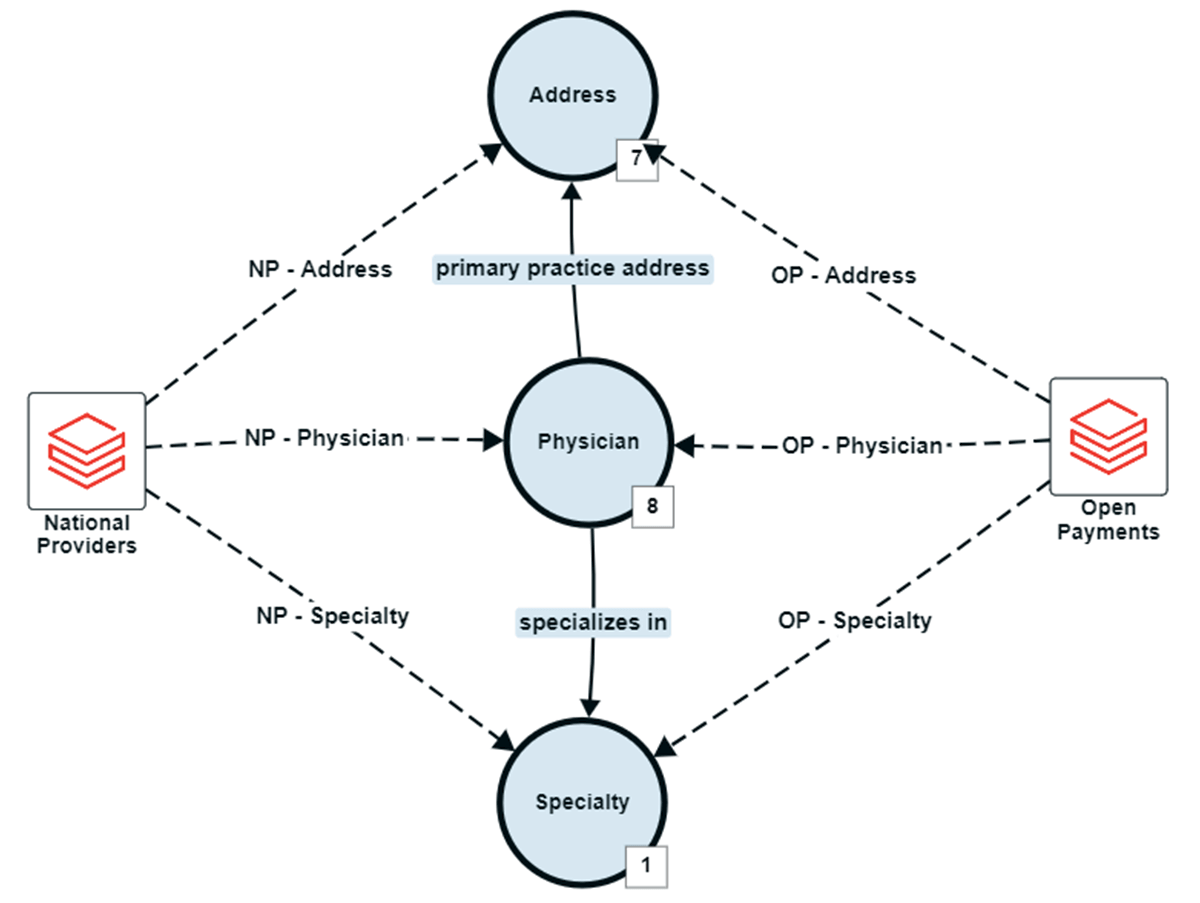
{kind=link}
DesignerからStardog Explorerに公開されると、ビジネスユーザはナレッジグラフでエンタープライズデータを視覚的に探索し、クエリできるようになり、仮想化機能(この場合はDatabricks)によって外部ソースに対して連携クエリを実行できます。
Stardogのエンティティ解決サービスは、教師なし機械学習に駆動され、現在、現実世界のエンティティを解決するための要となっています。エンティティ解決技術を通じて、National ProvidersとOpen Paymentsのデータセット内のレコードが特定され、リンクされます。 ユーザーは、データベース名、クエリ、フィールド名のキー、ターゲットグラフなどの主要な詳細を提供します。 Stardogはクエリを実行し、エンティティ解決ジョブを実行し、指定されたグラフに結果を書き込みます。
Stardogの外部コンピュート機能は、エンティティ解決ワークロードをDatabricks Sparkにプッシュし、クエリは仮想化を使ってDatabricks SQLに変換されます。 この連携アプローチにより、シームレスなデータアクセスと統合が可能になり、StardogとDatabricksのギャップを埋めることで効率性が向上します。
また、類似度のしきい値を設定することで、マッチング精度を微調整することもできました。 このしきい値を超えるエンティティは、一致または重複として識別され、エンティティ解決プロセスを洗練させるカスタマイズ可能なレイヤーをユーザーに提供します。
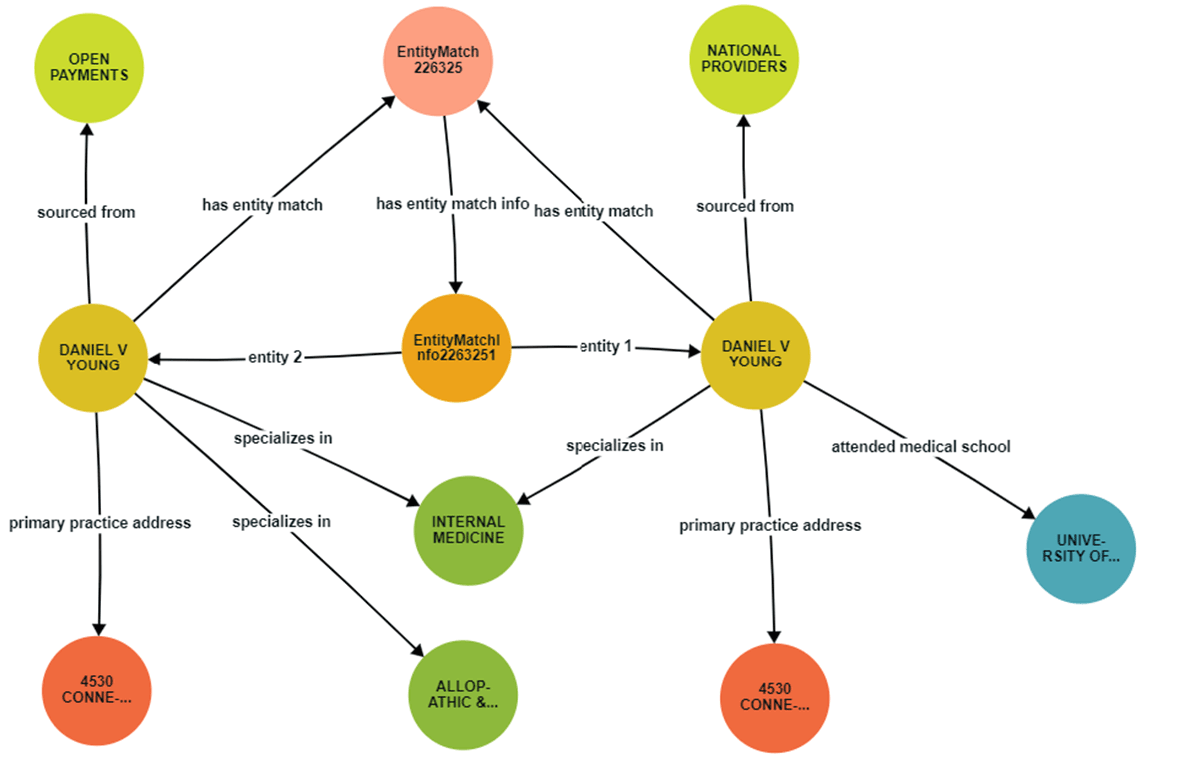
治療経験と治療成績の向上を目指す医療・ライフサイエンス機関にとって、異なるデータベースからの記録を統合することは非常に重要です。 レイクハウスアーキテクチャをベースに構築されたDatabricksデータインテリジェンスプラットフォームは、セ��マンティックレイヤーとしてStardogを組み合わせることで、面倒で脆い従来のアプローチに代わる、堅牢でスケーラブルな選択肢を提供します。 これは、医師データや医療施設など、データセット全体の包括的なビューを必要とするあらゆるエンティティの解決の課題にも及びます。
エンティティを解決するStardogとDatabricksの効果に基づき、Stardog Voiceboxのユーザは、この統合されたデータを平易な言葉で扱うことができ、その潜在能力を最大限に引き出すことができます。 このアプローチにより、データ統合が合理化され、ヘルスケアおよびライフサイエンスの専門家が情報に基づいた意思決定を大規模に行えるようになります。
Githubリポジトリにあるステップバイステップの手順で、今すぐ始めましょう。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。