Unity Catalogにおける、ビジネスコンテキストを持つ統合データディスカバリ
ドメイン、インテリジェントなキュレーション、共有セマンティクスは、チームが信頼できるデータと AI アセットを見つけてアクセスするのにどのように役立つか
• エンタープライズ規模では、チームはアナリティクスワークフローとAIワークフロー全体で適切なデータを見つけ、理解し、検証することに苦労しています。• Databricks Discoverは、ビジネスコンテキスト、信頼性、アクセスをUnity Catalogに直接組み込むことで、検出を統合します。• ドメイン、インテリジェントなキュレーション、ガバナンスの効いたアクセスは、ユーザーが自信を持ってディスカバリからアクションに移行するのを支援します。
データ ディスカバリーは、ビジネス コンテキストに基づいて構築されます。
データ資産が拡大するにつれて、多くの組織は基本的な課題、つまり、人々が適切なデータを見つけてそれを使用するかどうかを判断できるように支援することに苦労しています。チームは、次のような基本的な質問に自信を持って答えられないため、行き詰まってしまいます。このデータは存在しますか?どこにありますか?どのデータを使用すべきですか?それは何を意味しますか?信頼できますか?そして、どうすればアクセスできますか?
実際には、ディスカバリーは断片化されています。データはソースと本番システムを中心に編成されていますが、ビジネス上の意味はダッシュボード、ドキュメント、Wiki、または組織のナレッジなど、他の場所に存在します。信頼シグナルとアクセスワークフローは、人々が実際にデータを検索する場所から切り離されていることがよくあります。
ディスカバリーにビジネスコンテキストが欠けていると、ユーザーは検索や作業の重複で時間を浪費し、スチュワードはボトルネックとなり、適切なデータがすでに存在していても導入が停滞してしまいます。
すべてのデータおよびAI資産を対象とした、統合されたインテリジェントな単一の発見体験
本日、DatabricksはUnity Catalogに直接組み込まれた新しいDiscoverエクスペリエンス(現在ベータ版)を導入します。 Discoverページは、断片化されたツール固有のディスカバリーを、データ、分析、AIアセットを見つけて理解するための単一のキュレーションされた方法に置き換えます。ユーザーは、複数のツールを検索したり、どのデータセットを使用するかを推測したりする代わりに、関連性の高い信頼できるアセットを1か所で見つけることができます。
Unity Catalogは、ディスカバリに適用されるデータインテリジェンスを可能にします。その内容は次のとおりです。
- ビジネス上の意味は、ドメイン(ビジネスに沿ったアセットのグループ化)とガバナンスの効いたメタデータを通じてカタログに直接埋め込まれているため、ユーザーはデータがどこにあるかだけでなく、それが何を表しているかを理解できます。
- 認定と非推奨は、信頼性と品質のシグナルをアセットとともに表示し、チームが最も重要なデータに集中できるよう支援します
- プラットフォームネイティブのデータインテリジェンス は、使用状況、リネージ、所有権などのシグナルを使用して、アセットがどのように使用されているか、誰が責任者であるかについてのコンテキストを提供します
- 統合されたアクセスリクエストワークフローにより、ユーザーはエクスペリエンスから離れることなく、発見から実行に移ることができます。
「検出」ページは、構造化・非構造化データからダッシュボード、メトリクス、ノートブック、アプリケーション、Genie spacesなどのAIアセットに至るまで、lakehouse全体を網羅し、すべてを単一の統制されたエクスペリエンスを通じて提供します。
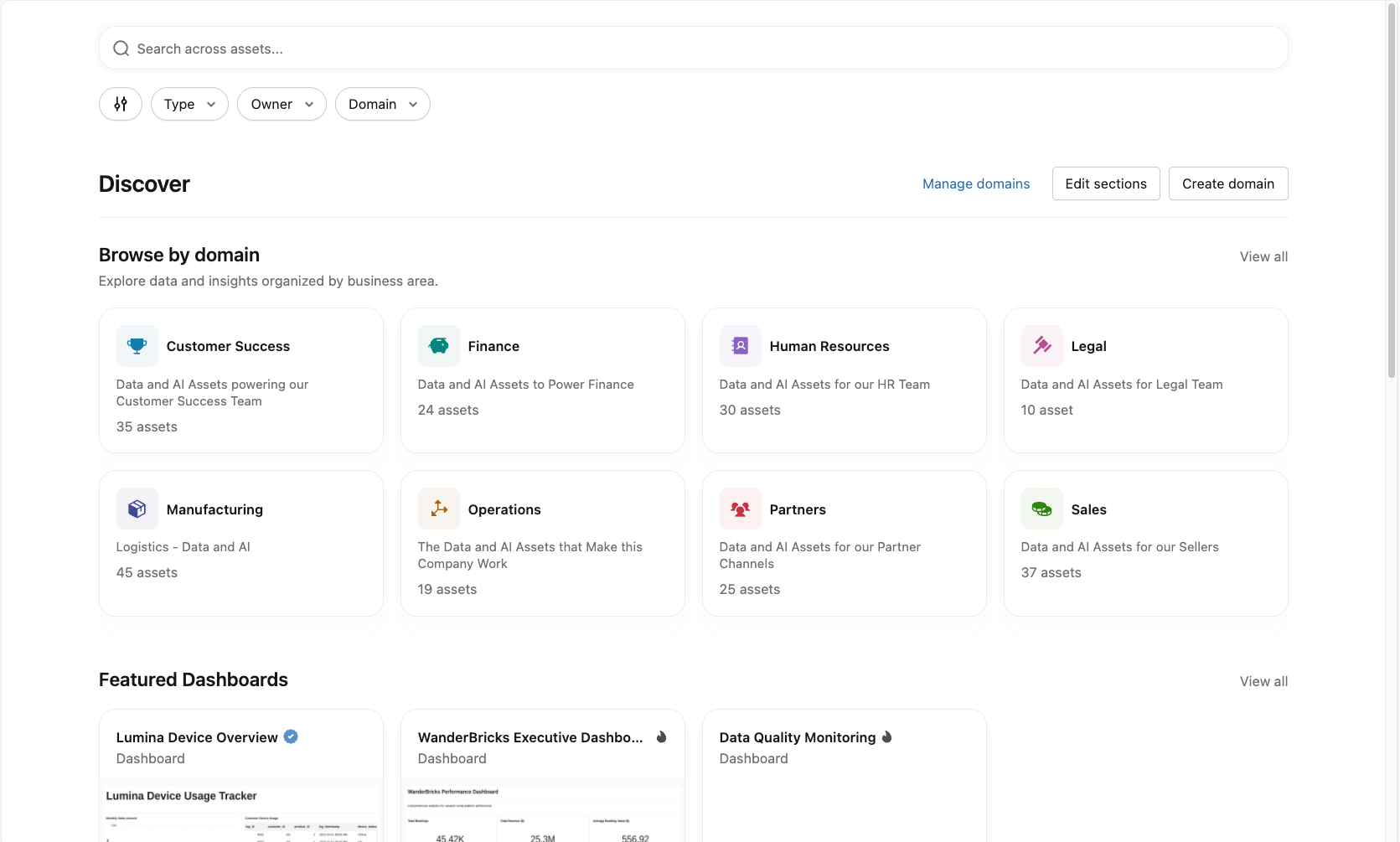
ドメイン: ビジネスの仕組みに合わせてディスカバリを体系化
現在ベータ版のドメインは、ビジネスに沿った検出の基盤を提供します。
ドメインは、アセットを厳格な技術的階層に押し込むのではなく、財務、マーケティング、顧客テレメトリーといった事業部門やユースケースごとにデータおよびアナリティクスアセットを整理します。重要なことに、アセットは複数のドメインに表示されることがあります。これにより、チームがアセットの所属先となる単一の階層を決定しなければならない、従来のフォルダー構造のトレードオフが解消されます。
ドメインは、メタデータ インテリジェンスと人間による制御を組み合わせます:
- 人気があり、頻繁に使用されるアセットが自動的に表示されます
- スチュワードは、優先度の高いアセットや新しく公開されたアセットをピン留めして、最も重要なデータセットとダッシュボードを簡単に見つけられるようにできます。
- アセットは、複数のドメインにわたって重複なくキュレーションできます
ドメインによって、スチュワードは次のことも可能になります:
- データとアナリティクスにわたって関連アセットをキュレーションします
- 各ドメインページでの閲覧エクスペリエンスをカスタマイズする
- 充実した説明を追加し、技術担当者とビジネス担当者の両方を指定します
これにより、ユーザーは直感的かつ業務に沿った方法で検出を行えるようになります。組織にとっては、硬直した階層を押し付けることなく、ビジネスのコンテキストをカタログに柔軟にエンコードできることを意味します。

人間の専門知識とインテリジェントなキュレーションによって導かれるAIシグナル
当社のDiscoverページのエクスペリエンスは、Unity Catalogの既存の機能を基盤としており、使用状況や人気度などのAIを活用したシグナルと、認定や非推奨のタグ付けによる人間によるキュレーションを組み合わせています。
認定は信頼性を示す明確な目印として機能し、ユーザーがどのアセットが推奨および承認された正式な情報源であるかをすばやく特定するのに役立ちます。AI を活用したレコメンデーションにより、ユーザーに過度な負担をかけることなく、関連性が高く価値のあるアセットが見つけやすくなります。
Discover ページでは、スチュワードがカ�スタムセクションを作成して、Discover ページおよび個々のドメインページで主要なアセットをハイライト表示することもできます。これにより、組織のデータランドスケープに不慣れなユーザーを、適切なデータと知見に導くことができます。

探索に直接組み込まれた信頼とアクセス
ディスカバリーは、ユーザーが見つけたものに基づいて行動できる場合にのみ機能します。ディスカバリーページはUnity Catalogの権限モデルに基づいて構築されており、組織はブラウズを介して広範なメタデータアクセスを許可しつつ、基盤となるデータのクエリに対するアクセス制御を適用できます。ユーザーはアセットの目的、品質、所有権を理解し、使用する準備ができたら直接アクセスをリクエストできます。
アクセスワークフローをディスカバリーに組み込むことで、チームは手動での承認を減らし、知見を得るまでの時間を短縮し、スチュワードをボトルネックにすることなくガバナンスを拡張できます。

次のステップ
Discoverページとドメインは現在、AWS、Azure Databricks、GCPでベータ版として提供されています。これらは、分散データ、ドメイン指向のチーム、そして技術ユーザーとビジネスユーザーの両方にサービスを提供するデータプラットフォームを持つ企業向けに構築されています。ぜひベータ版にご登録いただき、今後のロードマップ形成のためにフィードバックをお寄せください。実際の動作については、こちらのデモをご覧ください。
Unity Catalogがデータ、モデル、エージェント、アプリを検出可能にし、統制し、安全性を確保する方法について詳しくは、当社のウェブサイトをご覧ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイに��お届けします。