アーカイブの解放:非構造化ドキュメントを地下水探索用の検索可能なデータベースに変換
Databricks for Goodの支援により、MapAidがAIを活用して静的なアーカイブをスーダンの水危機に対する実用的な検索エンジンへと変革した方法
によって Andres David Blandon Restrepo 、 Mofeed Nagib による投稿
- MapAidはDatabricks for Goodと提携し、700件近くのスキャンされた水文地質学文書を分類およびカタログ化し、非構造化データを検索可能なデータベースに変換しました。
- マルチモーダルAIを活用して、チームは文書を分類し、スキャンされたページ画像から水関連の情報を直接抽出するサーバーレスパイプラインを構築しました。
- 研究者は、関連する過去の研究を数秒で特定し、MapAidの地下水予測モデルに直接取り込まれる井戸の記録にアクセスできるようになり、掘削成果の向上を支援しています。
はじめに
スーダン全土で、人々は飲料水、灌漑、そして生き延びるために地下水に依存していますが、生産性の高い井戸を掘り当てる保証はまったくありません。地質は複雑で、帯水層は多様であり、掘削に失敗すると数千ドルもの費用が無駄になる可能性があります。何十年にもわたる地質調査や現地レポートには、状況を改善するために必要なデータが含まれていますが、この情報はアーカイブに散逸したままで、体系的に整理されたことがないため、最も必要としている人々の目に触れることはありませんでした。
MapAidは、スタンフォード大学で設立された非営利団体であり、AIを活用したマッピングを通じて、主にアフリカの人道支援や開発に携わる人々がデータに基づいた意思決定を行えるようにすることをミッションとしています。同団体の主要ツールであるWellMaprアプリ(無料で使用可能)は、AIと地理空間データを使用して浅い地下水域を特定し、小規模農家の飲料水や灌漑用の低コストな掘削を支援しています。これらのモデルにとって重要なインプットとなるのが、井戸、掘削孔、帯水層の地質に関する過去のデータです。
スーダン知識アーカイブ協会(SUDAAK)は、このデータの最も豊富なコレクションの1つを管理しています。これには、地質調査、井戸掘削レポート、現地調査など、計5,000ページを超える約700件のスキャンされたPDF、TIFF、JPGが含まれており、wossac.com��で一般公開されています。しかし、公開されていることと、実際に利用できることは同じではありません。スーダンの特定の地域の掘削データを必要とする研究者は、何百もの文書を手作業で調べる必要がありました。データはデジタル化されていたものの、検索システムがなかったため、活用されないままでした。
マルチモーダルAIによるスキャン文書の分類
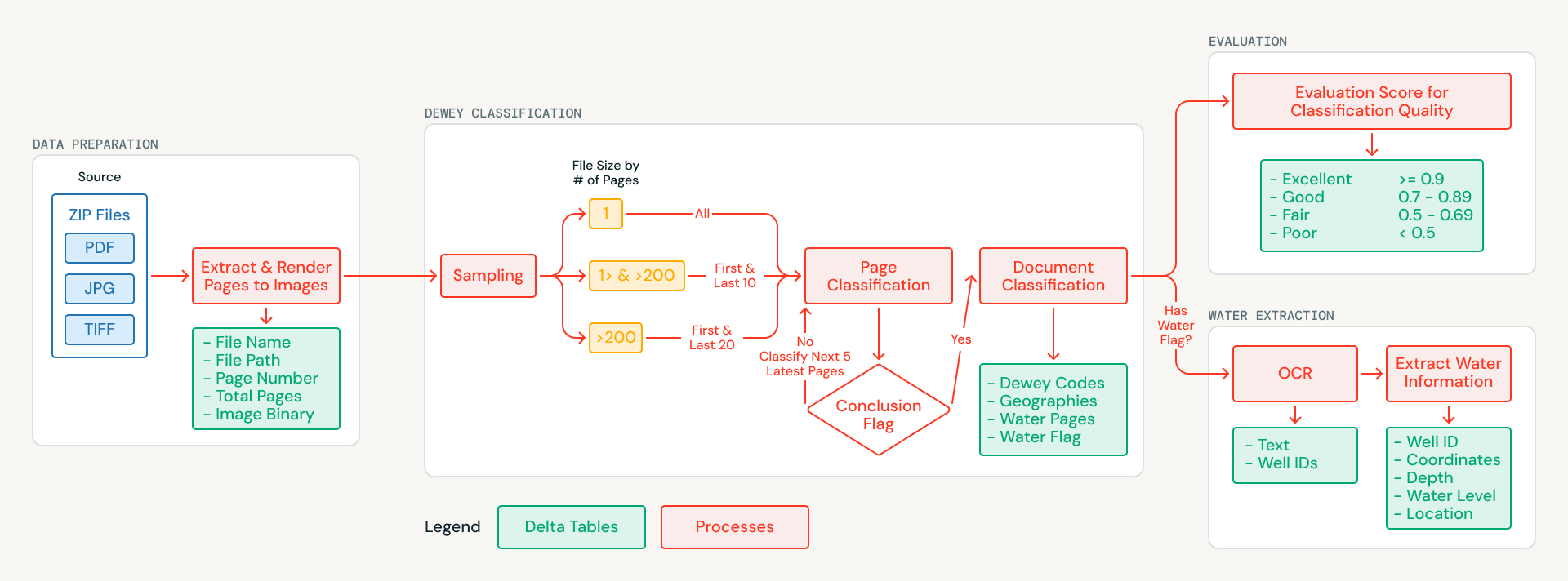
DatabricksはMapAidと提携し、アーカイブ内のすべての文書を分類し、地理情報や件名のメタデータをタグ付けし、水関連の文書から構造化された井戸や掘削孔の記録を抽出する、AI搭載のパイプラインを構築しました。このシステムは完全にDatabricks上で動作し、シングルコマンドでデプロイできるようにパッケージ化されています。本記事では、この技術的アプローチと、大量の非構造化スキャン文書から構造化された知識を抽出したいと考えているあらゆる組織にこれをどのように応用できるかについて解説します。
このアーカイブには、従来のテキスト抽出手法を適用できない課題がありました。文書は数十年前の物理的なレポートのスキャンであり、テキストレイヤーが埋め込まれていません。ページが傾いているもの、英語とアラビア語が混在しているもの、手書きの現地メモが含まれているものも多くあります。チームは、最初のステップとしてOCRを試みるのではなく、問題を「視覚的理解」として再定義しました。つまり、スキャンされたページの画像をマルチモーダルAIモデルに直接送信し、コンテンツを視覚的に解釈させるというアプローチです。
各文書のページは画像としてレンダリングされ、Unity Catalog Volumesに保存されることで、クリーンでバージョン管理された基盤データセットが作成されます。そこから、インテリジェントなサンプリング戦略によって処理コストを削減します。短い文書はすべて分析され、長い文書は最も情報量の多いセクション(表紙、はじめに、結論など)からサンプリングされます。これにより、分類の品質を維持しながら、AIの処理量を70%以上削減しました。
サンプリングされた各ページは、マルチモーダル入力と構造化されたJSON出力をネイティブにサポートするDatabricks AI Functions(ai_query)を使用して分析されます。モデルは各ページの画像を検証し、以下を返します。
- 世界共通の図書分類システムであるデューイ十進分類法コード
- コンテンツ内で言及されているスーダンの地理情報
- そのページに井戸、掘削孔、または帯水層のデータが含まれているかどうかを示す水関連フラグ
AI FunctionsはSQL内で直接実行されるため、チームは個別のモデルサービングインフラを構築することなく、プロンプトや出力スキーマの反復改善を行うことができました。ページレベルの結果は文書レベルの分類に集約され、すべての文書に対象内容と適用地域がタグ付けされた、構造化された検索可能なカタログが作成されます。
{kind=link}
構造化された井戸および掘削孔の記録の抽出
水関連フラグが立てられた文書の多くには、MapAidのWellMaprモデルが依存している、井戸の位置、掘削深度、地下水位の測定値、揚水量といった構造化データがまさに含まれています。この情報は文書全体に分散していることが多く、あるセクションに座標が表示され、別のセクションに深度の測定値が表示され、数ページ後の要約表に揚水データが表示されるといった具合です。このデータを抽出して紐付けることが、今回の提携の主要な目標でした。
水関連の各文書について、パイプラインは分類に使用されたサンプリング済みのサブセットだけでなく、すべてのページを処理します。OCRは、Foundation Model APIを通じて提供されるマルチモーダルモデルを使用してページごとに実行されます。このモデルは、英語、アラビア語、および手書きの現地メモ、表データ、混��在フォーマットのページを含む複雑なレイアウトに対応しています。OCRの実行中、システムは固有表現抽出(entity recognition)のアプローチも適用し、井戸や掘削孔の識別子をアンカーエンティティとして特定することで、複数ページにまたがる記録を単一の場所に紐付けられるようにします。
すべてのページから抽出されたテキストは統一された文書表現にマージされ、その後、2回目のパスで処理されて、場所の名前、GPS座標、掘削深度、静水位、揚水試験の揚水量を記録したJSON形式の構造化データが抽出されます。Databricks AI Functionsはスキーマ制約のあるレスポンスを強制するため、これらの属性が文書内の異なるフォーマットやセクションに現れた場合でも、一貫して取得することができます。その結果、MapAidのWellMapr予測モデルに直接統合できる、構造化された井戸および掘削孔の記録のセットが得られます。
大規模な自動品質評価
何百もの専門的な水文地質学的分類を手作業で検証するには、膨大なリソースと深い専門知識が必要になります。評価を事後に行う別個のステップとして扱うのではなく、チームは自動品質評価をパイプラインに直接組み込み、主要なステージとして位置づけました。同様にAI Functionsを介して呼び出される別のAIモデルが評価者(judge)として機能し、正確性、網羅性、一貫性をカバーする構造化されたルーブリックに基づいて、すべての分類をスコアリングします。各文書について、評価モデルは割り当てられたデューイ十進分類コードと地理タグをサンプリングされたページコンテンツと比較し、分類がモデルによって実際に観察された内容に裏付けられているかどうかをチェックします。
各評価では、カテゴリ評価(優、良、可、不可)と、スコアを説明する記述式の理由の両方が出力され、パイプラインが行ったすべての決定について監査可能な証跡が作成されます。信頼度のしきい値を下回る文書には手動レビューのフラグが立てられ、限られた人的リソースを最も重要なケースに集中させることができます。最初の完全な実行では、人間の対応が必要な分類はごく一部にとどまりました。
Databricks上での自己完結型ソリューションのデプロイ
このようなプロジェクトは、ファイルストレージ、データエンジニアリング、AI推論、構造化出力のパース、品質評価、ガバナンスなど、データとAIスタックのあらゆるレイヤーに関わります。Databricksは、これらすべてを単一のワークスペース内で提供しました。生のアーカイブファイルはUnity Catalog Volumesに保存され、すべてのパイプライン出力は、ACIDの信頼性、スキーマ進化、完全なデータリネージを備えたDelta Lakeテーブルに書き込まれます。パイプラインはサーバーレスコンピュート上のLakeflow Jobとしてオーケストレーションされるため、MapAidは各実行で消費した分だけを支払�います。
システム全体がDatabricks Asset Bundleとしてパッケージ化されているため、シングルコマンドでデプロイ、更新、実行が可能です。MapAidは、複数のクラウドサービスにまたがる専門知識がなくてもメンテナンスできる、自己完結型のソリューションを導入することができました。パイプラインのロジックは処理対象の特定のアーカイブから切り離されているため、同じシステムを他の水関連アーカイブ、他の地域、または大量のスキャン文書を分類して検索可能にする必要がある他のドメインにも適応させることができます。
現場における意義
最初の完全な実行において、パイプラインは以下の成果を上げました。
- 654件の文書および5,570ページの分類
- 3時間未満で完了
- 自動評価により、分類の95%が「優秀」または「良好」と評価
- アーカイブの約50%に水関連のデータが含まれていると特定
- 地名、深度、出水量測定値を含む、299件の構造化された井戸およびボーリング孔の記録を抽出
このパイプラインにより、専門家が数週間から数ヶ月かけて行っていた作業が、わずか数時間で完了するプロセスへと短縮されました。現在、アーカイブは分類、地域、または水デ��ータの有無によって検索可能です。座標と深度データを含む抽出されたすべての記録は、MapAidの地下水予測に直接取り込まれ、掘削の成功率向上と、水を必要とするコミュニティへのより迅速な給水を支援しています。
SUDAAKが新しい文書のデジタル化を進める中、このパイプラインは1つのコマンドで新しいバッチを処理できるため、アーカイブの拡大に合わせてカタログを常に最新の状態に保つことができます。MapAidの活動はエチオピアやマラウイを含む東アフリカ全域に及んでおり、同様の未分類のアーカイブはアフリカ大陸全体に存在します。この手法とインフラストラクチャは、拡張(スケール)する準備が整っています。
MapAidの最高経営責任者(CEO)であるRupert Douglas-Bate氏は、このパートナーシップについて次のように述べています。「進化を続ける当社のAIシステム『WellMapr』は、持続可能な地下水源を低コストで探索・特定することに革命をもたらすことを目指していますが、そのためには井戸水のデータが必要です。ロータリーインターナショナルを通じてつながったDatabricks for Goodとのコラボレーションにより、この目標に向けた私たちのミッションは大幅に加速しました。Databricks for Goodプロジェクトは、Sudan Association for Archiving Knowledge(SUDAAK)の支援を受けて、当社のOnline Water Library(OWL)を開発する上で不可欠なものでした。Databricksのチームは、スーダンの水と土壌に関する歴史的なデータが整理されずに大量に保管されていたアーカイブを、デューイ十進分類法を用いて構造化されたシステムへと変換するのを支援してくれました。これにより、持続可能な地下水井戸のデータを低コ��ストかつ迅速に特定できるようになり、現在ではWellMaprアルゴリズムの開発に役立てられています。MapAidは、干ばつを緩和するための重要な開発ツールとしてOWLを活用できることを嬉しく思っています。適切なパートナーが協力し合えば、それを最も必要としている人々のために『不可能なこと』を達成できるという証明です。」
その他のプロボノプロジェクトについては、以下をご覧ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。