データベースの新時代:Lakebase
によって Ali Ghodsi(アリ・ゴディシ), スタス・ケルヴィッチ, ヘイッキ・リンナカンガス, ニキータ・シャムグノフ, Arsalan Tavakoli-Shiraji(アルサラン・タバコリ・シラジ), Patrick Wendell(パトリック・ウェンデル), Reynold Xin(レイノルド・シン) 、 Matei Zaharia による投稿
- 運用データベースは、今日のAI駆動型アプリケーションには設計されていません。それらは分析とAIスタックの外部に位置し、手動での統合を必要とし、現代の開発ワークフローに必要な柔軟性を欠いています。
- Lakebaseは、計算とストレージの分離を含むOLTPデータベースの新しいアーキテクチャを導入し、独立したスケーリングとブランチングを可能にします。
- レイクハウスと深く統合されたLakebaseは、運用データワークフローを��簡素化します。これにより、壊れやすいETLパイプラインと複雑なインフラが排除され、チームはより迅速に動き、統一されたデータプラットフォーム上でインテリジェントなアプリケーションを提供することができます。
長年にわたり、データベースはソフトウェアの基盤であり、eコマースのチェックアウトフローからエンタープライズリソースプランニングまで、あらゆるものを静かに支えてきました。世界のあらゆるソフトウェア、あらゆるアプリケーション、あらゆるワークフロー、あらゆるAI生成コードは、最終的にその下にデータベースに依存しています。その過程で、アプリケーションの構築方法は完全に再発明されてきましたが、基盤となるデータベースは1980年代からほとんど変化していません。それらは、現代のクラウド以前のアーキテクチャに基づいており、以下の問題を抱えています。
- 運用が脆弱でコストがかかる:従来のデータベースは、最もデリケートなインフラストラクチャの1つと見なされており、信頼性の高い運用には通常、専門家チームが「卵の上を歩く」ように細心の注意を払う必要があります。コンピューティングとストレージは、厳格でモノリシックな単一ユニットにバンドルされています。これにより、チームはピーク時の容量に合わせてプロビジョニングする必要があり、高価なアイドルリソースが発生します。負荷がプロビジョニングされた容量を超えて急増すると、データベースが応答しなくなる可能性があります。さらに悪いことに�、データベースのスナップショットを取得したり、GDPRクリーンアップクエリを実行したりするなどの単純なメンテナンスタスクでさえ、データベース全体がダウンする可能性があります。
- 開発体験がぎこちない:従来のデータベースは、最新のアジャイル開発ワークフローとは相性が悪いです。コードの場合、コードベースの完全に分離されたクローンである開発用のgitブランチを作成するには1秒もかかりません。データベースの場合、プロビジョニングに数分、場合によっては数時間かかり、本番データベースの高忠実度クローンを作成するのは非常にコストがかかり、本番データベースをダウンさせるリスクがあります。AI駆動開発の台頭により、このプレッシャーはさらに高まっています。AIエージェントは、実験のために一時的で分離された環境を即座に起動する必要があります。
- 極端なベンダーロックイン: データベースの移行は、組織内の最も恐ろしい技術プロジェクトの1つです。モノリシックアーキテクチャは、データを出し入れする唯一の方法がデータベースエンジン自体を介することであることを意味します。これにより、重大なベンダーロックインが発生し、組織は特定のベンダーに深く依存することになります。
データベースを進化させる時が来ました。
Lakebaseとは?
従来のデータベースの制限に対処する新しいシステムが出現し始めています。Lakebaseは、トランザクションデータベースの最良の要素とデータレイクの柔軟性および経済性を組み合わせた、新しいオープンアーキテクチャです。Lakebaseは、根本的に新しい設計によって可能になります。コンピューティングとストレージを分離し、データベースのデータを低コストのクラウドストレージ(「レイク」)にオープンフォーマットで直接配置し、トランザクションコンピューティングレイヤーをその上で独立して実行できるようにします。
この分離が中心的なブレークスルーです。従来のデータベースは、CPUとストレージを1つのモノリシックシステムにバンドルしており、単一の大きなマシンとしてプロビジョニング、管理、および支払いを行う必要があります。Lakebaseはこのレイヤーを分割します。データはレイクにオープンに存在し、データベースエンジンは即座にスケールできる完全に管理されたサーバーレスコンピューティングレイヤー(例:Postgres)になります。このアーキテクチャは、数十年にわたってデータベースを定義してきたコスト、複雑さ、ロックインの多くを排除し、特に開発者が多くのインスタンスを起動し、自由に実験し、使用したものにのみ支払いたいと考えている最新のAIおよびエージェント駆動型ワークロードにとって強力です。
Lakebaseには次の主要な機能があります。
ストレージとコンピューティングの分離:データはクラウドオブジェクトストレージ(「レイク」)に安価に保存され、コンピューティングは独立して弾力的に実行されます。これにより、大規模なスケール、高い同時実行性、および1秒未満でゼロまでスケールダウンする機能(レガシーデータベースシステムでは不可能)が可能になり、高価なデータベースマシンをアイドル状態に保つ必要がなくなります。
無制限で低コスト、耐久性の高いストレージ:データがレイクに存在するため、ストレージは実質的に無限になり、固定容量のインフラストラクチャを必要とする従来のデータベースシステムよりも劇的に安価になります。そして、そのストレージはクラウドオブジェクトストレージ(例:S3)の耐久性によってバックアップされており、デフォルトで99.999999999%の耐久性を提供します。これは、ストレージ冗長性のためのレプリカを必要とする従来のデータベースセットアップ(ほとんどの場合非同期で更新されるため、二重障害の場合に多くの構成でデータ損失の可能性があります)よりもはるかに優れています。
弾力的なサーバーレスPostgresコンピューティング:Lakebaseは、需要に応じて即座にスケールアップし、アイドル時にはスケールダウンする、完全に管理されたサーバーレスPostgresを提供します。コストは使用量に直接一致するため、バーストワークロード、開発環境、および一時インスタンスを起動するAIエージェントに最適です。
インスタントブランチング、クローニング、リカバリ:データベースは、開発者がコードをブランチするようにブランチおよびクローンできます。ペタバイト規模のデータベースでも数秒でコピーでき、高速な実験、安全なロールバック、および運用オーバーヘッドなしでのインスタント復元が可能になります。
統合されたトランザクションおよび分析ワ�ークロード:LakebaseはLakehouseとシームレスに統合され、OLTPとOLAPの間で同じストレージレイヤーを共有します。これにより、トランザクションデータを移動または複製することなく、リアルタイム分析、機械学習、およびAI駆動の最適化を直接実行できます。
オープンでマルチクラウド設計:オープンフォーマットで保存されたデータは、プロプライエタリなロックインを回避し、AWS、Azure、およびそれ以降での真のポータビリティを可能にします。組み込みのマルチクラウド機能は、災害復旧、長期的な自由、および時間の経過とともにより強力な経済性をサポートします。
これらがLakebaseの主要な属性です。エンタープライズグレードのトランザクションシステムには、セキュリティ、ガバナンス、監査、高可用性などの追加機能が必要ですが、Lakebaseを使用すると、これらの機能は1つのオープンな基盤に1回だけ実装および管理すれば済みます。Lakebaseはデータベースの次の進化を表します。クラウド、開発者、AI時代のために再構築されたトランザクションシステムです。
データベースアーキテクチャの進化
新しい時代が必要な理由を理解するには、過去50年間のデータベースアーキテクチャの進化を振り返ることが役立ちます。この進化を3つの明確な世代として捉えています。
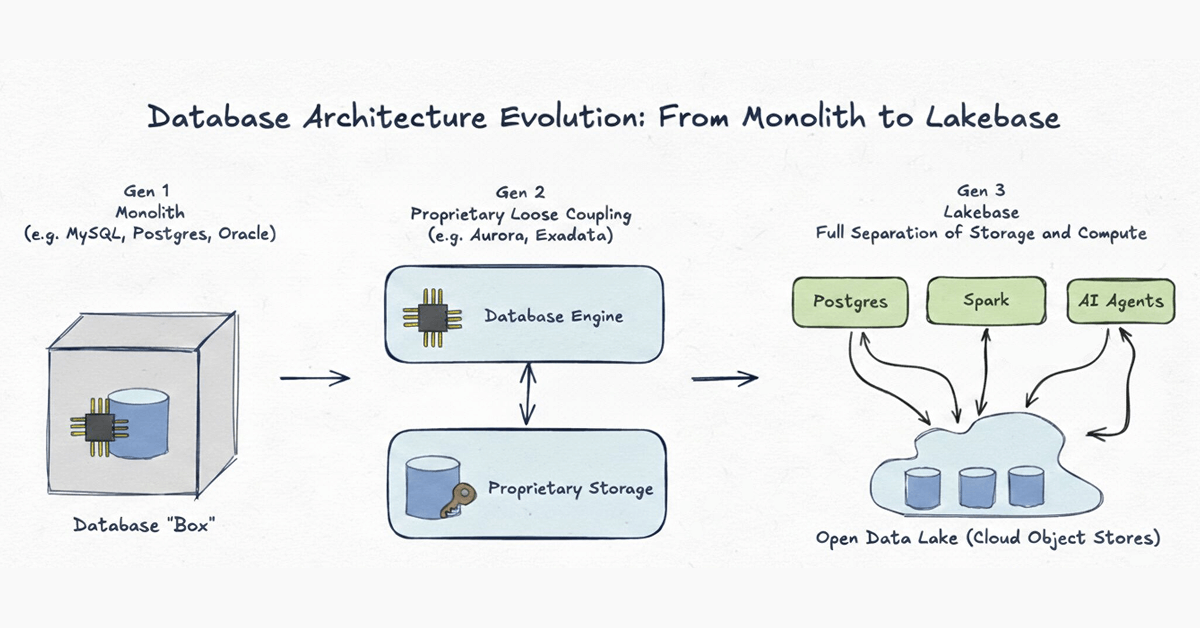
第1世代:モノリス
例: MySQL、Postgres、クラシックOracle
データベースシステムは、絶対的なモノリスとして始まりました。クラウド以前の時代、ネットワークはあらゆるシステムの最も遅い部分でした。高性能データベースを設計する唯一の方法は、コンピューティング(CPU/RAM)とストレージ(ディスク)を単一の物理マシン内で緊密に結合することでした。これは1980年代のハードウェアの制限には理にかなっていましたが、データがプロプライエタリな形式で閉じ込められ、スケーリングがより大きなボックスを購入することを意味する、厳格なケージを作成しました。
第2世代:ストレージのプロプライエタリな疎結合
例: Aurora、Oracle Exadata
クラウドインフラストラクチャが改善されるにつれて、ベンダーはストレージとコンピューティングを物理的に分離し、ストレージをプロプライエタリなバックエンドティアに移行しました。これらのシステムは、スループットの限界を押し広げたエンジニアリングの驚異でした。しかし、 それらは十分ではありませんでした。 分離は純粋に内部的な最適化でした。データは単一のエンジンのみがアクセスできるプロプライエタリな形式内にロックされたままであるため、第2世代システムは構造的な行き止まりに苦しんでいます。
- 単一エンジンのチョークポイント: データはプライマリデータベースエンジンを介してのみアクセスでき、これがボトルネックになります。AIエージェントや大規模なデータにアクセスする分析エンジンにとっては困難です。
- 分析の摩擦: 大規模なデータベースファイルをOLAPエンジンが直接アクセスできないため、分析クエリの実行は依然として困難であり、通常はデータを移動するために複雑なETLが必要です。
- クラウドロックイン: ストレージレイヤーは、特定のクラウドプロバイダーのプロプライエタリなインフラストラクチャに緊密に結合されていることがよくあります。これにより、マルチクラウド相互運用性が困難になり、真のクロスクラウド高可用性および災害復旧(HADR)が不可能になります。ベンダーのリージョンが失敗した場合、データは立ち往生します。
これらのシステムは、最終的な第3世代への移行状態にあると考えています。
第3世代:Lakebase - レイク上のオープンストレージ
Lakebaseは、分離されたアーキテクチャを究極の論理的な結論に導きます。第2世代と同様に、コンピューティングとストレージを分離しますが、重要な違いがあります。 ストレージインフラストラクチャとデータ形式の両方が完全にオープンです。
このアーキテクチャ上に構築することで、前述の3つの課題を解決できます。
- よりシンプルな運用による信頼性の向上とコスト削減: プロビジョニング、スケールアップ、スケールダウン、ブランチング、スナップショット、リカバリなどの一般的な操作を数秒で完了できます。高価なクエリは、本番トラフィックに影響を与えることなく、異なる弾力的なコンピューティングインスタンスで実行できます。
- Gitのような開発者エクスペリエンス: 本番データベースの高忠実度ブランチに基づいた、アプリケーションの実験と開発がより迅速になります。開発者やAIエージェントにとって、これはデータベースがコードと同じくらい速く動くことを意味します。
- 極端なベンダーロックインの解消: クラウドオブジェクトストアに保存されたオープンフォーマットのデータにより、ロックインが大幅に軽減されます。エンジンの種類に関係なく、データはご自身で所有できます。
多くの点で、Lakebaseは、安価で信頼性の高いオブジェクトストレージとクラウドの弾力性が利用可能になった今日、OLTPデータベースを再設計する必要がある場合に構築するものと言えます。組織がクラウドとAIを採用してより迅速に動くにつれて、このモデルはトランザクションシステムの構築のための標準的な基盤になると予想されます。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。