eBook
Databricks、Spark、Delta Lake のワークロードを最適化する包括的ガイド



常駐ソリューションアーキテクト、Himanshu Arora
リードプロダクトスペシャリスト、Prashanth Babu Velanati Venkata
序章
このドキュメントは、Databricks、Apache Spark™、Delta Lake の重要なベストプラクティスと最適化手法のほとんど(全てではないにしても)を 1 か所に集約することを目的としています。全てのデータエンジニアとデータアーキテクトは、最適化されたコスト効率の高い効率的なデータパイプラインを設計・開発する際のガイドとして活用できます。コストは後付けではなく、プロジェクト開始当初から最も重要な非機能要件の一つとして扱われるべきです。そのため、本書で取り上げたベストプラクティスは全て、データパイプラインの開発と本番運用をとおして考慮すべきものです。本書はいくつかのセクションに分かれており、それぞれが特定の問題文に焦点を当て、それに対する可能なあらゆる解決策を提供するために深く掘り下げています。
常駐ソリューションアーキテクト、Himanshu Arora
リードプロダクトスペシャリスト、Prashanth Babu Velanati Venkata
序章
このドキュメントは、Databricks、Apache Spark™、Delta Lake の重要なベストプラクティスと最適化手法のほとんど(全てではないにしても)を 1 か所に集約することを目的としています。全てのデータエンジニアとデータアーキテクトは、最適化されたコスト効率の高い効率的なデータパイプラインを設計・開発する際のガイドとして活用できます。コストは後付けではなく、プロジェクト開始当初から最も重要な非機能要件の一つとして扱われるべきです。そのため、本書で取り上げたベストプラクティスは全て、データパイプラインの開発と本番運用をとおして考慮すべきものです。本書はいくつかのセクションに分かれており、それぞれが特定の問題文に焦点を当て、それに対する可能なあらゆる解決策を提供するために深く掘り下げています。
Delta Lake - レイクハウス形式
Delta Lake は、データレイクに信頼性、セキュリティ、パフォーマンスを提供するオープンフォーマットのストレージレイヤーです。これにより、Spark、PrestoDB、Flink、Trino、Hive などのコンピューティングエンジンと、Python、SQL、Scala、Java、Rust、Ruby 用の API を使用してレイクハウスアーキテクチャを構築できます。Parquet、Avro、ORC などの他のオープンフォーマットに比べて、次のような多くの利点があります。
- Deltaは、オープンソースの Parquet フォーマットの上に、ACID トランザクション、高性能、その他多くの機能を保証するプロトコルです。Deltaはオープンソースで、完全なプロトコルはここにあります。
- Delta Lake は ACID トランザクションをサポートし、バッチとストリーミングのパラダイムを統合することで、増分データの削除/挿入/更新トランザクションを簡素化します。
- Delta は、タイムトラベルを可能にし、テーブルのポイントインタイムスナップショットバージョンを読むことができます。
- また、Delta は、効率的なデータレイアウト、インデックス作成、データスキッピング、キャッシングなど、多くのパフォーマンス強化機能を備えています。
したがって、全てのメリットを享受するために、Delta デフォルトのデータレイクストレージフォーマットとして使用することを強く��お勧めします。Databricks DBR 8.x 以上では、Delta Lake がデフォルトのフォーマットです。
基礎となるデータレイアウト
Delta テーブルの下には、データを格納する Parquet ファイルがあります。また、_delta_log というサブディレクトリがあり、Parquet ファイルのすぐ隣に Delta のトランザクションログが格納されています。これらのパーケットファイルのサイズは、クエリのパフォーマンスにとって非常に重要です。
極小ファイル問題は、ビッグデータの世界ではよく知られた問題です。テーブルの基礎となる極小ファイルが多すぎると、極小ファイルを開いたり閉じたりするのに時間がかかるため、読み取りレイテンシが悪化します。
この問題を避けるには、ファイルサイズを 16 MB~1 GB の間に設定するのが最適です。これは、作業負荷と特定の使用ケースに基づいてケースバイケースで設定可能です。
Databricks Runtime 11.3 以上を使用して、Unity Catalog(Databricks のデータカタログ) にカタログされたマネージド Delta テーブルを作成する場合、Databricks が自動チューニング機能の一部としてバックグラウンドで自動的にこのタスクを実行するため、基礎となるファイルサイズの最適化や、Delta テーブルのターゲットファイルサイズの設定について心配する必要はありません。将来的には、この機能は外部テーブルでも利用できるようになる予定です。
それ以外の場合は、特定の Spark ジョ��ブを使用してファイルを手動で圧縮して適切なファイルサイズを取得する必要がありますが、Delta テーブルにはすぐに使えるビンパッキング(圧縮)機能が備わっているため、これは必要ありません。Delta では、以下に詳述する 2 つの方法でビンパッキングを行うことができます。
1. 最適化と Z オーダー
OPTIMIZE はファイルを圧縮して最大 1 GB のファイルサイズにします。これは設定可能です。このコマンドは基本的に、設定したサイズ(設定されていない場合はデフォルトで 1 GB)にファイルのサイズを調整しようとします。OPTIMIZE コマンドと ZORDER を組み合わせることもできます。ZORDER は、選択した列に基づいてデータを物理的にソートしたり、同じ場所に配置したりします。
![]()
- Z オーダーには、常にカーディナリティの高いカラム(例えば、orders テーブルの
customer_id)を選択します。通常、日付カラムはカーディナリティが低いカラムなので、Z オーダーに使用すべきではありません。パーティショニングカラムとして使用する方が適しています(ただし、常にテーブルをパーティショニングする必要はありません。詳細は後述のパーティショニングセクションを参照してください)。Z オーダーでは、フィルター句や下流クエリの結合キーとして最も頻繁に使用されるカラムを選択します。 - 列数が多すぎると Z オーダー効果が低下するため、4 列以上は使用しないでください。
- OPTIMIZE コマンドは、ジョブ自体の一部としてではなく、必ず別のジョブクラスタで実行してください。そうしないと、対応するジョブの SLA に影響する可能性があります
- OPTIMIZE コマンドは計算負荷が高いため、計算最適化インスタンスファミリーを推奨します。
- OPTIMIZE(ZORDER の有無にかかわらず)は、下流のクエリパフォーマンスを向上させるために、ファイルレイアウトを維持するために、1 日 1 回(または週 1 回、または要件に応じて)など、定期的に実行する必要があります。
2. 自動最適化
Auto optimize は、その名の通り、Delta テーブルへの個々の書き込み中に、小さなファイルを自動的にコンパクト化する機能で、デフォルトでは、128 MB のファイルサイズを達成しようとします。これには 2 つの機�能があります。
1. 書き込みの最適化
Optimize Write は、実際のデータに基づいて Apache Spark のパーティションサイズを動的に最適化し、各テーブルパーティションに対して 128 MB のファイルの書き出しを試みます。同じ Spark ジョブの中で行われます。
2. オートコンパクト
Spark ジョブの完了後、Auto Compact は新しいジョブを起動し、ファイルをさらに圧縮して128 MB のファイルサイズを達成できるかどうかを確認します。
![]()
- 適切なファイルサイズを得るために、手動 OPTIMIZE(ZORDER の有無にかかわらず)コマンドをまだ利用していない場合は、常に optimizeWrite テーブルプロパティを有効にしてください。最適化された書き込みは、ターゲットテーブルのパーティショニング構造に従ってデータのシャッフルを必要とすることに留意してください。このシャッフルには当然、追加コストが発生します。しかし、書き込み時のスループット向上がシャッフルのコストをペイする可能性があります。そうでない場合でも、データをクエリする際のスループッ�ト向上により、この機能の価値はあるはずです。
- ジョブが SLA に厳密に縛られていない場合は、autoCompact テーブルプロパティを有効にして、Delta ビンパッキングをさらに活用することもできます。
3. パーティショニング
パーティショニングは、パーティションカラムをフィルターとして提供したり、パーティションカラムで結合したり、パーティションカラムで集約したり、パーティションカラムでマージしたりすると、スキャン時に不要なデータパーティション(サブフォルダーなど)をスキップすることができるため、クエリを高速化することができます。
![]()
- Databricks では、1TB 未満のテーブルにはパーティションを設定せず、インジェスト時のクラスタリングを自動的に有効にすることを推奨しています。この機能は、デフォルトで全てのテーブルに対して、データがインジェストされた順番に基づいてデータをクラスタリングします。
- 各パーティションのデータが少なくとも 1 GB になる場合は、カラム単位でパーティショニングできます。
- パーティションカラムには、常にカーディナリティの低いカラム(たとえば、年や日付)を選択します。
- パーティションカラムを選択する際に、Delta の生成カラム機能を利用することもできます。生成されたカラムは、Delta タブ内の他のカラムに対してユーザーが指定した関数に基づいて値が自動的に生成される特殊なタイプのカラムです。
4. ファイルサイズ調整
自動最適化(128 MB)または最適化(1 GB)で目標とするデフォルトのファイルサイズが適切でない場合は、必要に応じて微調整できます。ターゲットファイルサイズの設定にdelta.targetFileSize テーブルプロパティを使用すると、自動最適化と最適化は代わりに指定されたサイズになるようにビンパックします。
delta.tuneFileSizesForRewrites テーブルプロパティをオンにすることで、ターゲットファイルサイズを手動で設定したくない場合に、このタスクを Databricks に委譲することもできます。このプロパティを true に設定すると、Databricks はワークロードに基づいてファイルサイズを自動的に調整します。例えば、Delta テーブル上で多くのマージを行う場合、マージ操作を高速化するために、ファイルは自動的に 1 GB よりもはるかに小さいサイズに調整されます。

データシャッフリング - なぜ起こるのか、どう制御するのか
データのシャッフルは、結合、集計、ウィンドウ操作などの幅広い変換の結果として発生します。ワーカーノード間でネットワークを介してデータを送信するため、高価なプロセスです。私たちは、シャッフルの効率と速度を排除または改善するために、いくつかの最適化アプローチを使用することがあります。
1. ブロードキャストハッシュ結合
データのシャッフルを完全に避けるには、結合する 2 つのテーブルまたは DataFrame(小さい方)の一方をブロードキャストします。テーブルはドライバによってブロードキャストされ、ドライバはそれを全てのワーカーノードにコピーします。
結合を実行すると、Spark は 10 MB 未満のテーブルを自動的にブロードキャストします。ただし、以下に示すように、このしきい値を調整して、さらに大きなテーブルをブロードキャストすることもできます。
クエリ内のテーブルのいくつかが小さなテーブルであることがわかっている場合、ヒントを使用して明示的にブロードキャストするように Spark に指示できます。
Spark 3.0 以降には AQE(Adaptive Query Execution)が搭載されており、いずれかの結合側の実行時統計が適応型ブロードキャストハッシュ結合のしきい値(デフォルトでは 30 MB)よりも小さい場合に、ソートマージ結合をブロードキャストハッシュ結合(BHJ)に変換することもできます。次の構成を変更してこのしきい値を増やすこともできます。
![]()
- ブロードキャストハッシュ結合は完全外側結合ではサポートされていないことに注意してください。右外側 join では左側テーブルのみがブロードキャストされ、その他の左 join では右側テーブルのみがブロードキャストされます。
- 大容量のメモリ(32 GB 以上)搭載したドライバーを使用している場合は、ブロードキャストのしきい値を 200 MB 程度に上げても問題ありません。
- ヒントや PySpark のブロードキャスト関数を使って、常に小さいテーブルを明示的に��ブロードキャストします。
- AQE が自動的に小さいテーブルをブロードキャストしてくれるのに、なぜ明示的に小さいテーブルをブロードキャストする必要があるのでしょうか?その理由は、AQE はクエリの実行中にクエリを最適化するからです。
- Spark は両側でデータをシャッフルする必要があり、その後、AQE のみがシャッフルステージの統計に基づいて物理プランを変更し、ブロードキャスト結合に変換することができます。
- したがって、ヒントを使用して小さいテーブルを明示的にブロードキャストする場合、シャッフルは完全にスキップされ、ジョブはプランを最適化するために AQE の介入を待つ必要はありません。
- 1 GB を超えるテーブルはブロードキャストしないでください。ブロードキャストはドライバ経由で行われ、1 GB 以上のテーブルではドライバの OOM が発生したり、大きな GC の一時停止によりドライブが応答しなくなったりします。
- ディスクとメモリ上のテーブルのサイズは決して同じではないことに注意してください。Delta テーブルは Parquet ファイルでバックアップされ、データによって圧縮のレベルが異なります。Spark はディスク上のサイズに基づいてテーブルをブロードキャストするかもしれませんが、解凍して列から行の形式に変換した後、メモリ上では非常に大きなサイズ(8 GB 以上)になるかもしれません。Spark はブロードキャストできるテーブルサイズに 8 GB というハードリミットを設けています。そのため、このような状況ではジョブが例外で失敗する可能性があります。この場合の解決策は、
spark.sql.autoBroadcastJoinThresholdを -1 に設定することでブロードキャストを無効にし、ディスクとメモリの両方で本当に小さいテーブルのヒント(またはPySparkのブロードキャスト関数)を使用して明示的にブロードキャストを行うか、spark.sql.autoBroadcastJoinThresholdを -1 に設定する代わりに 100 MB や 50 MB のような小さい値に設定することです。 - ドライバは常に 1 GB までのデータしかメモリに収集することができず、それ以上はドライバでエラーが発生し、ジョブが失敗します。しかし、10 MB より大きなテーブルをブロードキャストしたいので、この問題に遭遇する危険性があります。この問題は、以下のドライバ設定の値を大きくすることで解決できます。
- これはドライバの設定なので、クラスタが起動したら変更できないことに注意してください。したがって、クラスタの詳細オプションで Spark config として設定する必要があります。32 GB を超えるメモリを持つドライバでは、このパラメータを 8 GB に設定すると、ほとんどの状況で問題なく動作するようです。ブロードキャストハッシュ結合が非常に大きなテーブルをブロードキャストする場合、この値を 16 GB に設定することも理にかなっています。
- Photon では、エクゼキュータ側のブロードキャストを行っています。そのため、Photon でDatabricks Runtime(DBR) を使用する場合は、以下のドライバの設定を変更する必要はありません。
2. ハッシュ結合をソートマージ結合よりシャッフルする
ほとんどの場合、Spark はテーブルをブロードキャストできない場合にソートマージ結合(SMJ)を選択します。ソートマージ結合は最もコストがかかります。シャッフルハッシュジョイン(SHJ)は、SMJ のように余分なソートステップを必要としないため、状況によっては(全てではありませんが)ソートマージよりも高速であることがわかっています。Spark に SMJ よりも SHJ を使用することを通知できる設定があり、Spark は可能な限り SMJ の代わりに SHJ を使用するようにします。これは、Spark が常に SMJ よりも SHJ を選択するという意味ではありません。単に、このオプションに対するあなたの好みを定義しているだけです。
また、Databricks Photon エンジンは、ソートマージ結合をシャッフルハッシュ結合に置き換えて、クエリパフォーマンスを向上させています。
![]()
- �各ジョブで
preferSortMergeJoin設定オプションを false に設定する必要はありません。関係するジョブの最初の実行では、この値をデフォルト(true)のままにしておくことができます。 - 問題のジョブが多くの結合を実行し、多くのデータシャッフルを伴うため、希望するSLAを満たすのが難しい場合は、このオプションを使用して、
preferSortMergeJoin値を false に変更できます。
3. コストベースオプティマイザ(CBO)の活用
Spark SQL では、コストベースオプティマイザ(CBO)を使用してクエリプランを改善できます。これは、複数の結合を含むクエリで特に有効です。CBO はデフォルトで有効になっています。CBO を無効にするには、以下の設定を変更します。
CBO が機能するためには、テーブルとカラムの統計情報を収集し、常に最新の状態に保つことが重要です。統計情報に基づいて、CBO は最も経済的な結合戦略を選択します。そのため、以下の SQL コマンドをテーブル上で実行し、統計情報を計算する必要があります。統計情報は Hive メタストアに格納されます。
結合の再オーダー
より高速なクエリ実行のために、CBO は ANALYZE TABLE コマンドで計算された統計情報を使用して、テーブルを結合する最適な順序を見つけることもできます(例えば、小さいテーブルを最初に結合すると、パフォーマンスが大幅に向上します)。結合の並べ替え��は INNER 結合と CROSS 結合に対してのみ機能します。この機能を利用するには、以下の設定を行います。
![]()
- CBO の最適化を適切に活用するためには、ANALYZE TABLE コマンドを定期的に実行する必要があります(できれば 1 日 1 回、またはデータが 10% 以上変異したときのいずれか早いほう)。
- Delta テーブルが日常的に再作成または上書きされる場合、ANALYZE TABLE コマンドは、同じジョブまたはパイプラインの一部としてテーブルが上書きされた直後に実行する必要があります。これはパイプライン全体の SLA に影響を与えます。結果として、このようなケースでは、ダウンストリームのパフォーマンス向上と現在のジョブの実行時間との間でトレードオフが生じます。CBO 最適化を現在のジョブの SLA に影響させたくない場合は、オフにすることができます。
- ジョブの一部として ANALYZE TABLE コマンドを実行しないでください。別のジョブクラスタ上で別のジョブとして実行する必要があります。例えば、Optimize、Z-order、Vacuum などのコマンドを実行している同じ nightly notebook の中で実行することができます。
- 1 つのクエリで多くの内部結合や交差結合が実行される場合、結合の並べ替えを活用します。
- Spark の Adaptive Query Execution(AQE)は、実行時にクエリプランをその場でより良いものに変更しますが、ANALYZE TABLE コマンドで計算された統計情報も利用します。したがって、ANALYZE TABLE コマンドを定期的に実行して、テーブルの統計情報を更新しておくことをお勧めします。

データ流出 - なぜ起こるのか、どうすれば防げるのか
Spark SQL のシャッフルパーティション数(結合や集約などのワイド変換を実行するために使用する CPU コア数)のデフォルト設定は 200 ですが、これは必ずしも最適な値ではありません。その結果、各 Spark タスク(または CPU コア)には処理するための大量のデータが与えられ、各コアが利用可能なメモリがそのデータ全てを収めるのに不十分な場合、データの一部はディスクに流出します。ディスクへのデータ流出は、データのシリアル化、逆シリアル化、ディスクへの読み取りと書き込みなどを伴うため、コストのかかる操作です。流出は確実に回避する必要があり、そのためにはシャッフルパーティションの数を調整する必要があります。Spark SQL のシャッフルパーティションの数を調整する方法はいくつかあります。
1. AQE オートチューニング
Spark AQE には、 autoOptimizeShuffle(AOS)という機能があり、適切なシャッフルパーティション数を自動的に見つけることができます。オートチューニングを有効にするには、以下のコンフィギュレーションを設定します。
注意:異常に高い圧縮
AOS には一定の制限があります。ソーステーブルの圧縮率が異常に高い(20 倍から 40 倍)場合、AOS は正しいシャッフルパーティション数を推定できないことがあります。
高度に圧縮されたテーブルを識別するには、2 つの方法があります。
1. Spark UI SQL DAG
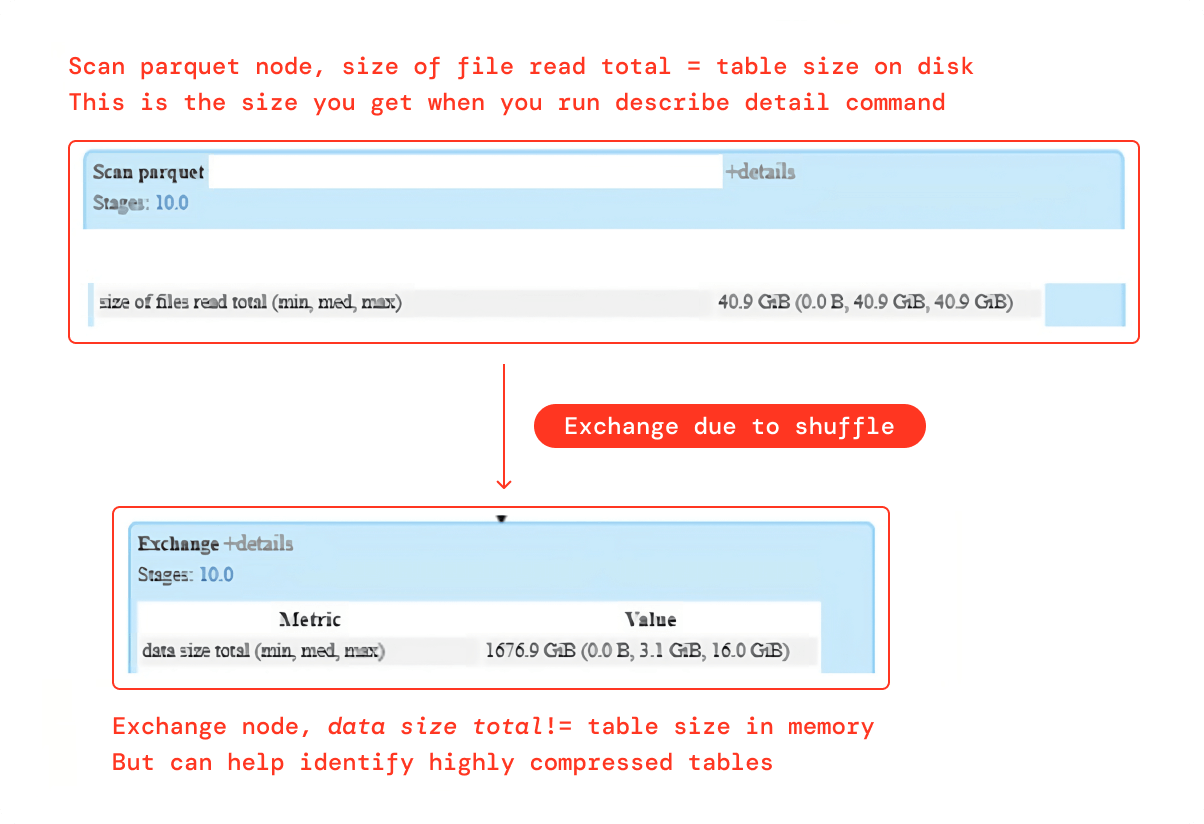
Exchange ノードの "data size total" メトリクスはメモリ上のテーブルの正確なサイズを提供しませんが、非常に圧縮されたテーブルを特定するのに役立ちます。スキャンパーケットノードはディスク内のテーブルの正確なサイズを提供します。前述のケースでは、Exchange ノードのデータサイズはディスク上のサイズよりも 40 倍大きく、テーブルがディスク上で高圧縮されている可能性が高いことを示しています。
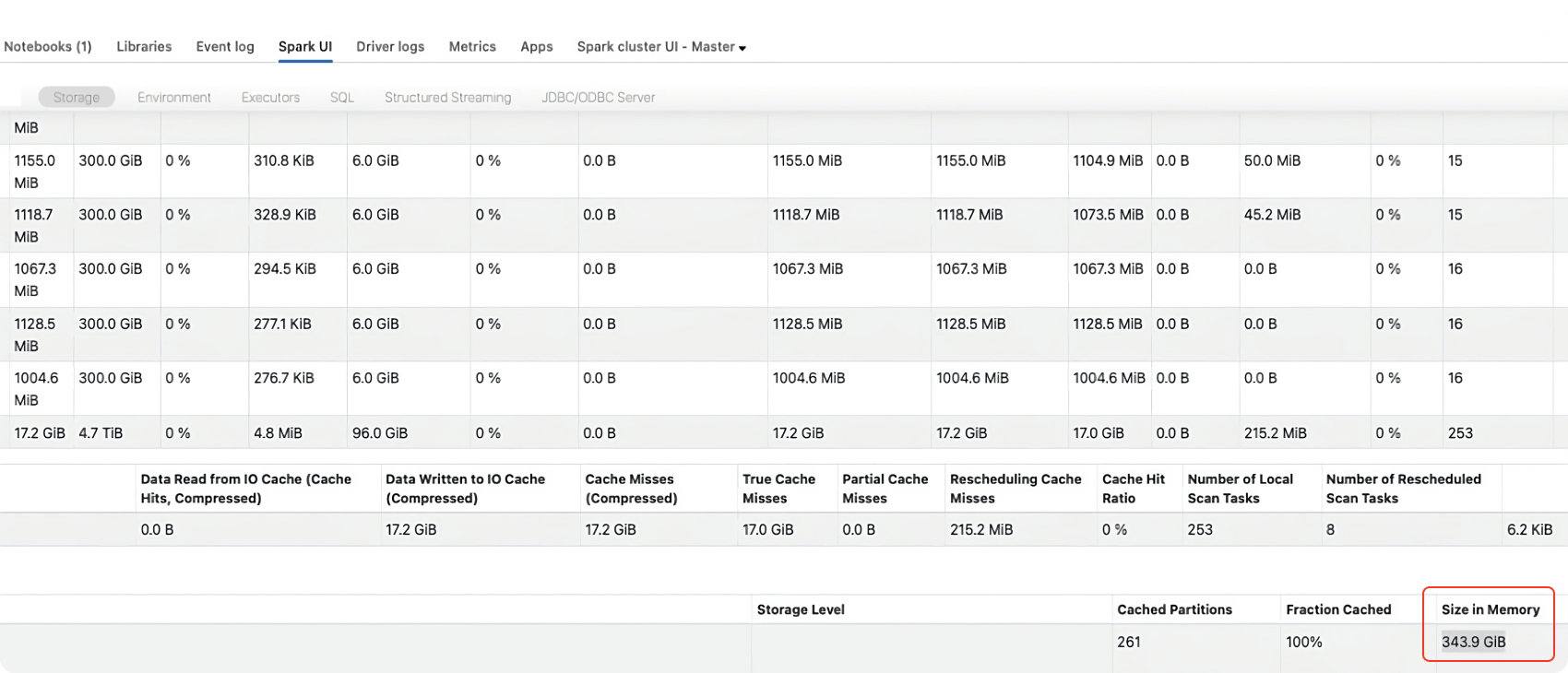
2. テーブルをキャッシュする
テーブルをメモリ上にキャッシュすることで、メモリ上の実際のサイズを把握することができます。以下はその方法です。
Spark UI の storage タブを参照して、上記のコマンドを実行した後のメモリ上のテーブルのサイズを確認してください。
解決策: この影響に対処するには、AQE が初期シャッフルパーティション数(デフォルト 128 MB)を決定する際に使用するパーティションサイズあたりの値を、以下のように小さくします。
preshufflePartitionSizeInBytes の値を 16 MB に下げた後、AOS がまだパーティション数を正しく計算しておらず、大量のデータ流出が発生する場合は、preshufflePartitionSizeInBytes の値をさらに 8 MB に下げる必要があります。それでも流出の問題が解決しない場合は、次のセクションで説明するように、AOS を無効にしてシャッフルパーティション数を手動で調整するのが最善です。
2. 手動による微調整
シャッフルパーティションの数を手動で微調整する必要があります。
- シャッフルされたデータの総量。以下の例のように、Spark クエリを一度実行し、Spark UI を使用してこの値を取得します。
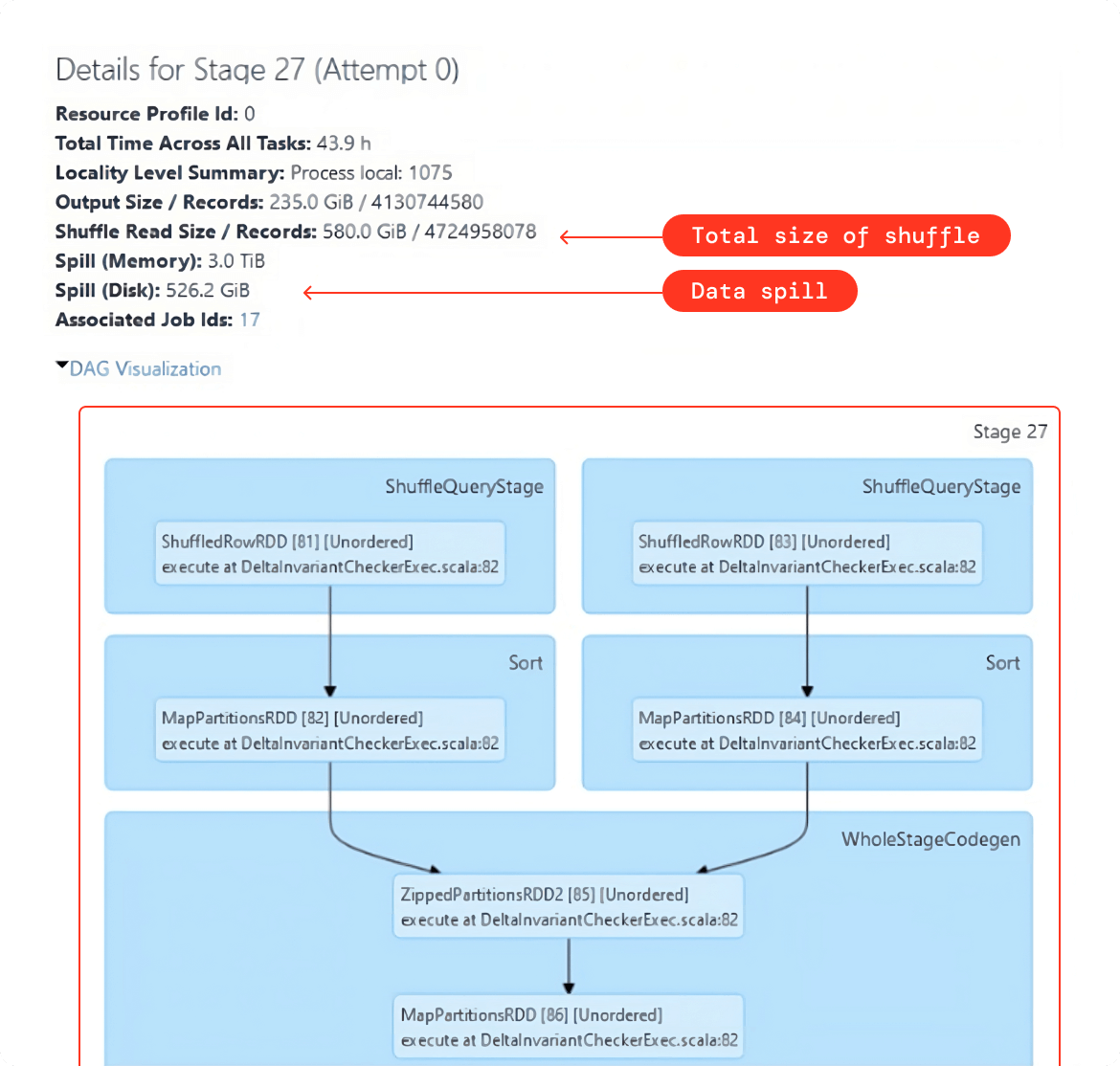
- 経験則として、シャッフル・パーティションの数を調整した後、各タスクがおよそ 128 MB~200 MB のデータを処理していることを確認する必要があります。この値は、以下の例のように、Spark UI のシャッフルステージのサマリーメトリクスで確認できます。

そこで、正しいシャッフルパーティションの数を計算する式を示します。
![]()
- タスクごとに処理するデータの最適サイズは、およそ 128 MB です。ほとんどの場合はうまくいきます。クエリで何らかのデータ爆発が起きている場合はうまくいかないかもしれません。その場合はより小さい値を選択する必要があるかもしれません。データ爆発についてはこのドキュメントの後の方で説明します。
- 自動調整(AOS)を使用せず、手動でシャッフルパーティションを微調整しない場合は、経験則として、ワーカーの CPU コア数の 2 倍、または 3 倍に設定してください。
- 1 つのノートブックに複数の Spark SQL クエリが存在する可能性があるため、クエリごとにシャッフルパーティション数を微調整するのは時間のかかる作業です。そのため、1 つのシャッフルステージでシャッフルされるデータ量の合計が最も大きいクエリに対して微調整を行い、その値をノートブック全体で 1 回設定することをお勧めします。
- データに歪みがある場合、シャッフルパーティションを微調整してもデータの流出には役立ちません。その場合、まずデータのスキューを取り除く必要があります。詳しくは次のデータスキューのセク��ションを参照してください。
データの歪み - 識別と修正
データスキューとは、データの分布が不均一なために、少数の CPU コアだけが大量のデータを処理することになる状況のことです。例えば、データが一様に分布していないカラムを使用して結合や集計を行うと、シャッフルステージにスキューが発生し、終了までに多くの時間がかかることになります(実際には何回か試行しても失敗する可能性があります)。
スキューの特定
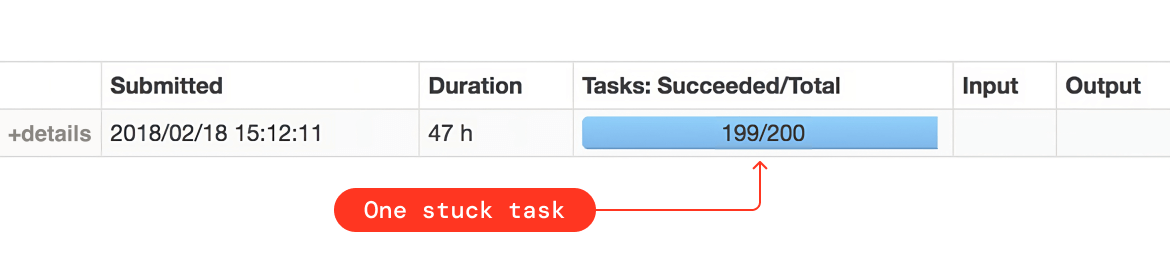
- シャッフルステージの Spark タスクが全て終了しているにもかかわらず、そのうちの 1 つか 2 つだけが長時間ハングしている場合は、スキューの兆候です。この情報は Spark UI からも取得できます。
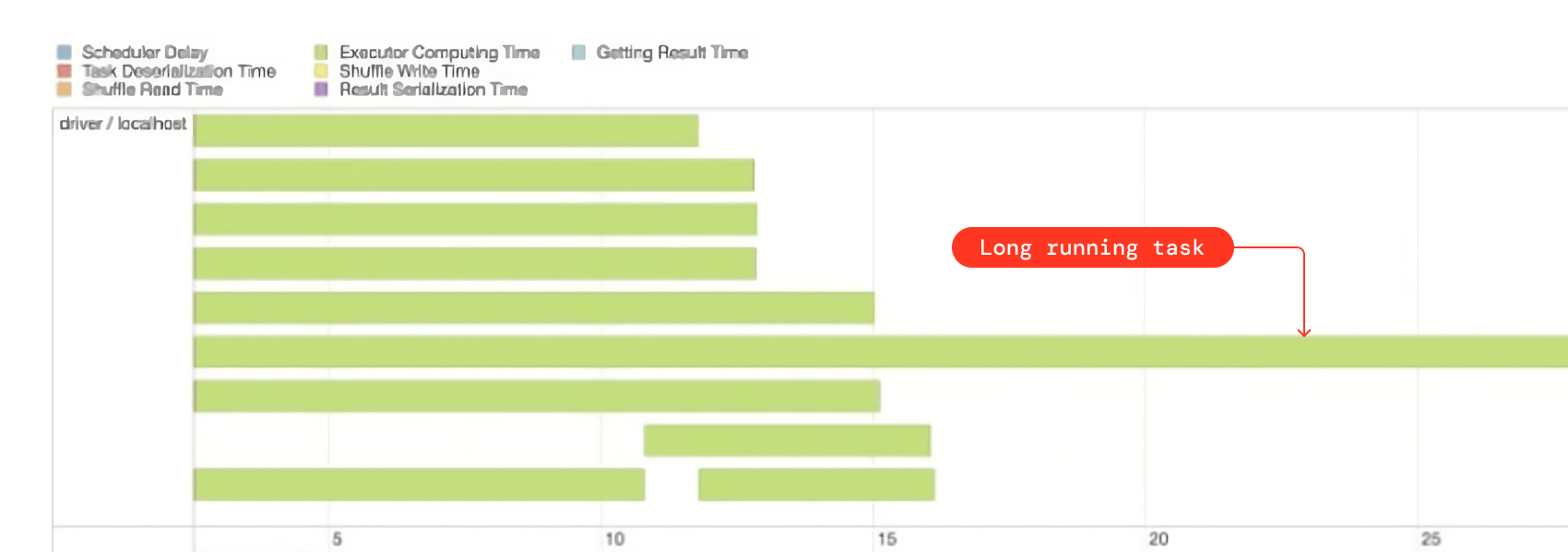
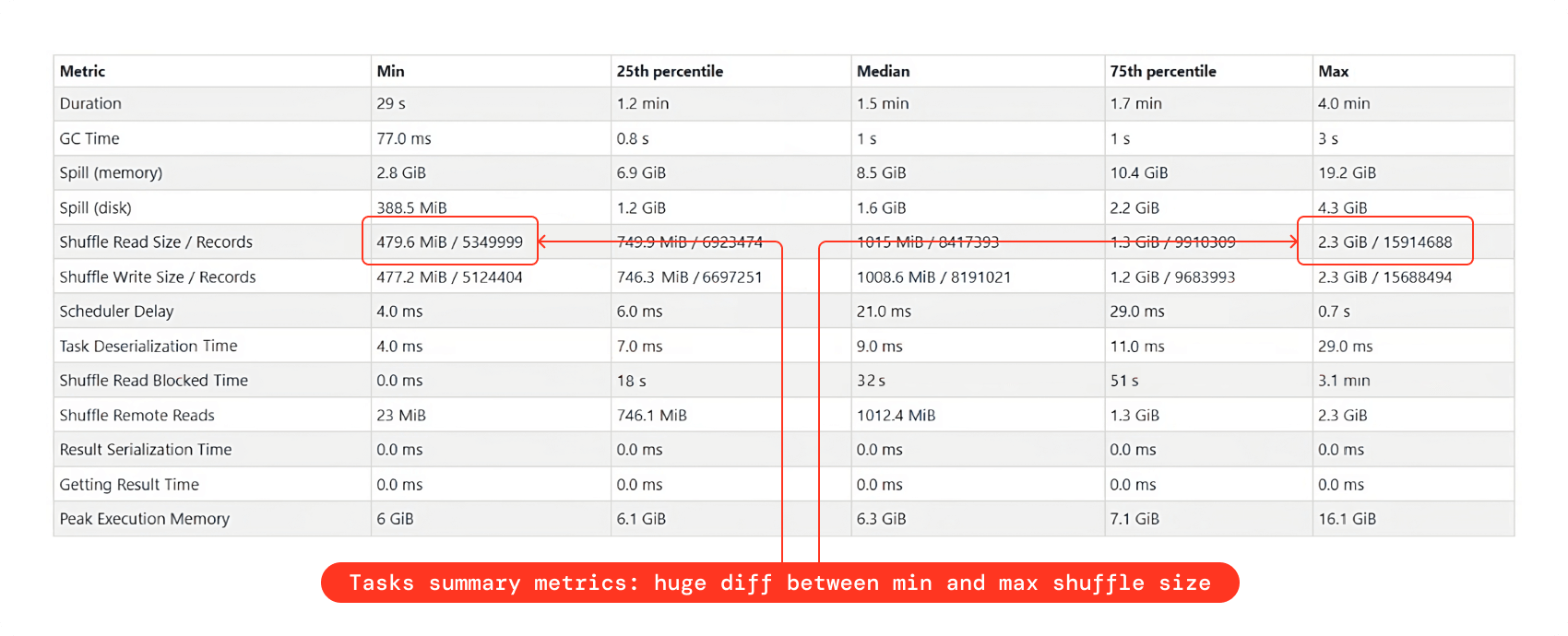
- タスクサマリーメトリックスで、シャッフルリードサイズの最小値と最大値の間に大きな差がある場合、それはデータの歪みを示しています。
- シャッフルパーティションの数を微調整しても、データの流出が多い場合は、実は歪度が原因かもしれません。
- 最後に、単純に結合列や集約列でグル��ープ化しながら行数をカウントすることもできます。行数の間に大きな差がある場合、それは間違いなくスキューです。
スキューの修正
- 歪んだ値のフィルタリング
偏りのある値をフィルタリングできれば、問題は簡単に解決します。例えば、NULL 値を多く含むカラムを使用して結合した場合、データの傾きが発生します。このシナリオでは、NULL 値をフィルタリングすることで問題を解決できます。 - スキューヒント
テーブル、列、できればデータスキューの原因となっている値も特定できる場合は、スキューヒントを使用してそのことを明示的に Spark に伝え、Spark が解決を試みることができます。 - AQEのスキュー最適化Spark 3.0+ の AQE は、データのスキューを動的に解決することもできます。デフォルトでは有効になっていますが、無効にしたい場合は以下の設定を false にしてください。
デフォルトでは、少なくとも 256 MB のデータを持ち、平均パーティションサイズの 5 倍以上のサイズのパーティションは、AQE によって歪んだパーティションとみなされます。これらの値を変更して、デフォルトの AQE の動作を微調整��することもできます。ジョブに 2,000 個を超えるシャッフルパーティションがあると、Spark は特定のシャッフルブロックサイズを追跡できなくなります。代わりに、平均サイズしか保持されないため、AQE ではスキューを検出できなくなります。この問題を解決するには、シャッフルパーティションの数を 2,000 個未満に減らすか、次の Spark 構成をシャッフルパーティション数よりも大きい値に変更してください。
- ソルティング
上記の方法がどれもうまくいかない場合、唯一の選択肢はソルティングを行うことです。これは、歪んだカラム値の接尾辞としてランダムな整数を付加することで、歪んだ大きなパーティションを小さなパーティションに分割する方法です。このサンプルノートブック(cmd7 以降)を参照し、ソルティング技術を使用してデータのゆがみの問題を修正してください。この例は、結合クエリにおけるデータのゆがみを修正する方法を示しています。
ここで、歪んだ集計クエリがあるとしましょう。データのゆがみを改善するためにソルティングを使用することはできますが、この状況では、ゆがみの原因となっている値に対して部分的なソルティングを実行するだけです。ある電子商取引組織で、全顧客の最終取引日を調べたいのですが、customer_id の値 xyz が不均等に分布しているためにデータが歪んでいるとします。��そこで、この歪度を修正するために、次のように部分的なソルティングを行います。

![]()
上記の順番で、これらの解決策を試してみてください。つまり、ソルティングはコードの変更を必要とするため、最初の選択ではなく、最後の選択とすべきです。ヒントと AQE の解決策は、実装がずっと簡単です。

データ爆発 - その原因、結果、解決策
特定の変換ステップの後の Spark ジョブの実行中に、データ量が異常に大きく増加することがあり、これはデータの爆発と見なされます。この結果、クエリの実行が大幅に遅くなります。以下に、データの爆発につながる可能性のある、最も一般的な変換をいくつか挙げます。
1. データ爆発機能
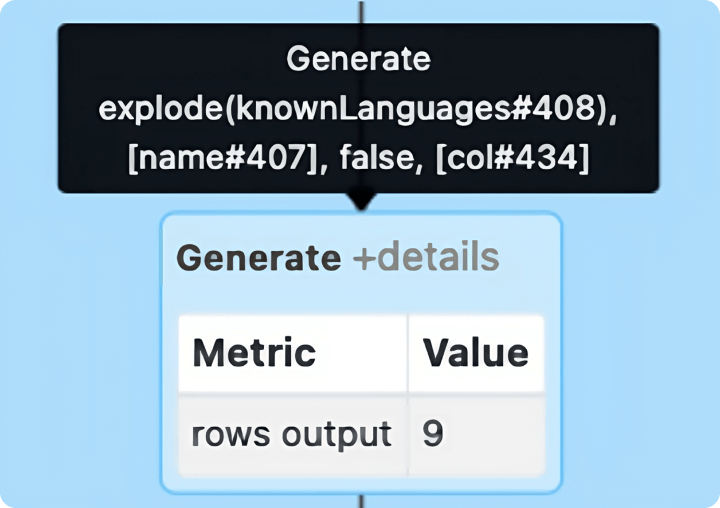
JSON、Parquet、Delta、XMLなどのフォーマットで構造化ファイルを扱う場合、配列、リスト、マップなどのコレクションでデータを取得することがよくあります。このような場合、Spark で効率的に処理するために、コレクションの列を行に変換する explode() 関数が便利です。この explode 操作は、データ量を大幅に増やすことができます。explode 操作は、上図のように Spark UI の Generate ノードで表されます。
2. 結合操作
クエリが遅くなる一般的な原因は、予想以上に多くの行を生成する結合です。これはしばしば "行の爆発 "と呼ばれます。Spark UI の SortMergeJoin または ShuffleHashJoin ノードの rows output メトリックを参照して、行が爆発する可能性があることを確認してください。
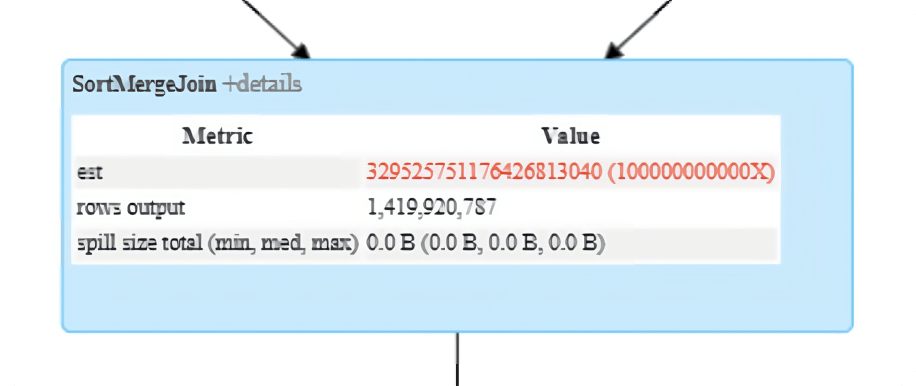
インパクト
Parquet や Delta などのソースから入力データを読み取る際、Spark はコアあたりタスクあたり約 128 MB を読み込みます。これは、各 CPU コアで使用可能なメモリに収まる非常に適切なパーティションサイズです。しかし、データの爆発的な増加により、128 MB のデータは非常に大きなボリューム(たとえば、数 GB)に変換される可能性があります。単一の CPU コアには、その爆発したパーティションを収めるだけの十分なメモリがない場合があるため、問題があります。その結果、その後の大規模な変換では、大量のデータがディスクに流出し、クエリのパフォーマンスに大きな影響を与える可能性があります。
ソリューション
- 入力パーティションのサイズ、すなわち
spark.sql.files.maxPartitionBytes(デ��フォルト 128 MB)を小さくして、explode()関数の効果に対抗するために、より小さい入力パーティションを作成します。128 MB の代わりに、例えば 16 MB や 32 MB のようなもっと小さいパーティションサイズを選択することができます。
- read 文の直後に明示的に repartition() 関数を呼び出して、パーティションの総数を増やすことができます。これにより、各パーティションのサイズを小さくすることができます。
- 結合操作によって爆発が起こっている場合、単純な解決策はシャッフルパーティションの数を増やすことです。そうすればパーティションサイズは 128 MB よりずっと小さくなります。詳細については、手動シャッフルパーティションチューニングのセクションを参照してください。

データのスキップおよびプルーニング
処理するデータ量はクエリの性能に直接関係します。そのため、必要なデータのみを読み取り、不要なデータは全てスキップすることが非常に重要です。Spark と Delta で適用できるデータスキップとプルーニングのテクニックがいくつかあります。
1. Delta データスキッピング
Delta データスキッピングは、Delta テーブルにデータを書き込む際に、各 Parquet ファイルの最初��の 32 カラムの統計情報(最小値、最大値など)を自動的に収集します。Databricks はクエリ時にこの情報(最小値と最大値)を利用して、クエリを高速化するために不要なファイルをスキップします。
最初の 32 列以上の統計を収集するには、以下の Delta プロパティを設定します。
長い文字列の統計を収集することは、高価な操作です。長い文字列の統計を収集しないようにするには、以下に示すように、テーブルプロパティ delta.DataSkippingNumIndexedCols を設定して列に長い文字列が含まれないようにするか、delta.DataSkippingNumIndexedCols よりも大きい列に長い文字列を含む列を ALTER TABLE を使用して移動することができます。
2. カラムのプルーニング
テーブルを読み込む際、一般的には全ての列を選択しますが、これは非効率的です。余計なデータのスキャンを避けるために、ワークロードの計算の真に一部であり、下流のクエリで必要とされる列は何かを常に問い合わせてください。これらの列のみをソースデータベースから選択する必要があります。これはクエリのパフォーマンスに大きな影響を与える可能性があります。
3. 述語のプッシュダウン
これは、フィルタリングを "ベアメタル"、すなわちデータソースエンジンに押し下げることを目的としています。これは、Spark のメ��モリにロードされた後にデータセット全体を処理するのではなく、非常に低いレベルでフィルタリングが実行されるため、クエリのパフォーマンスが向上します。
述語プッシュダウンを活用するために必要なことは、ソーステーブルからデータを読み込む際にフィルタを追加することだけです。述語プッシュダウンはデータソースエンジンに依存します。Parquet、Delta、Cassandra、JDBC などのデータソースでは動作しますが、テキスト、JSON、XML などのデータソースでは動作しません。
結合操作を行う場合は、結合の前にフィルタを適用してください。経験則として、テーブル読み込み文の直後にフィルタを適用してください。
4. パーティションプルーニング
パーティション除去技術により、対応するファイルシステムからフォルダを読み込む際のパフォーマンスを最適化し、指定されたパーティション内の目的のファイルのみを読み込めるようにします。ディスク I/O を削減する目的で、不必要なデータをメモリに保持しないように、データのフィルタリングを可能な限りソースの近くにシフトすることに対処します。
パーティションプルーニングを活用するには、テーブルパーティションとして使用されるカラムにフィルタをかけるだけです。
結合操作を行う場合は、結合の前にパーティションフィルタを適用してください。経験則として、パーティションフィルタはテーブル読み取り文の直後に適用してください。
5. ダイナミックパーティションプルーニング(DPP)
Apache Spark 3.0+ では、ダイナミックパーティションプルーニング(DPP)と呼ばれる新しい最適化が実装されています。DPP は、オプティマイザが解析時に削除するパーティションを特定できない場合に発生します。特に、任意の数のディメンジョンテーブルを参照する 1 つまたは複数のファクトテーブルで構成されるスタースキーマを考えます。このような結合操作では、ディメンジョンテーブルをフィルタリングした結果のパーティションを識別することで、結合がファクトテーブルから読み取るパーティションを削除できます。この機能を利用するには、設定は不要です。Spark 3.0+ ではデフォルトで有効になっています。
6. ダイナミックファイルプルーニング(DFP)
ダイナミックファイルプルーニング(DFP)は Databricks Runtime で利用可能で、最近の全てのランタイムでデフォルトで有効になっています。その名前が示すように、DPP と同様の動作をしますが、パーティションレベルではなくファイルレベルでダイナミックプルーニングを実行し、クエリをさらに高速化します。この機能を利用するには、設定は必要ありません。DFP は Databricks Runtime 6.1 以降で自動的に有効になります。

データキャッシング - キャッシングを活用してワークロードを高速化
Delta キャッシュと Spark キャッシュは、ワークロードを高速化するために活用できる2つの異なるタイプのキャッシュです。
1. Delta キャッシュ
Delta キャッシュは、高速な中間データフォーマットを使用してノードのローカルストレージ(SSDドライブ)にリモートファイルのコピーを作成することで、データの読み取りを高速化します。
- デフォルトで Delta キャッシュが有効になっている Accelerated インスタンスを使用します(Azure クラウドのメモリ最適化カテゴリの
Standard_E16ds_v4やストレージ最適化カテゴリのStandard_L4sなど)。 - Delta キャッシュは、SSD ドライブを持つ他のインスタンスファミリー(Azure クラウドの compute-optimized カテゴリの
Fsv2 シリーズなど)のワーカーで有効にできます。Delta キャッシュを明示的に有効にするには、次の設定を行います。
2. Spark キャッシュ
Spark は cache () メソッドと persist () メソッドを使用して、Spark DataFrame の中間計算をキャッシュし、以降のアクションで再利用できるようにする最適化メカニズムを提供します。同様に、CACHE TABLE コマンドを使用してテーブルをキャッシュすることもできます。キャッシュされたデータを保存する場所 (メモリ、ディスク、メモリとディスク、シリアル化の有無など) を選択できるキャッシュモードはさまざまです。
![]()
- Spark のキャッシュは、複数の Spark アクション(例えば、count、saveAsTable、write など)が同じ DataFrame に対して実行されている場合にのみ有効です。
- Databricks では、Spark キャッシュの代わりに Delta キャッシュを使用することを推奨しています。Delta キャッシュの方がパフォーマンスが向上するためです。ディスクキャッシュに保存されたデータは、Spark キャッシュ内のデータよりも高速に読み取り、操作できます。これは、ディスクキャッシュが効率的な解凍アルゴリズムを使用し、全段階のコード生成を使用して処理を進めるための最適な形式でデータを出力するためです。
- 特に同じテーブルから何度も読み込む場合、結合や集約のような幅の広い変換を��多用する計算の多いワークロードは、Delta キャッシュの恩恵を受けることができます。このようなワークロードには、常に Delta キャッシュ対応のインスタンスを使用してください。
中間発表の結果 - 持続させるタイミング
複数の SQL クエリにまたがる大規模なパイプラインでは、多くの場合、1 つまたは複数の中間作業(またはテンポラリ、ステージング)Delta テーブルを作成する傾向があります。これにより、大きなクエリを小さなクエリに分割して、読みやすさと保守性を高めることができます。しかし、この戦略はジョブの実行時間に悪影響を及ぼします。
- ステージングテーブルをクラウドストレージに書き込みます。
- その後、以降のステップでクラウドストレージからステージングテーブルを読み戻しますが、これもまた時間がかかります。
したがって、一時ビューは遅延評価され、実際には実体化されないため、マテリアライズされた Delta テーブルの代わりに一時ビューを作成する方がよいでしょう。
![]()
- 同じ Spark ジョブで一度しか使用しない場合は、常に中間テーブルを一時ビューに変更します。
- 中間テーブルが同じ Spark ジョブで複数回使用される場合、一時ビューを使用すると Spark が関連するクエリを部分的に複数回実行する可能性があるため、一時ビューにするのではなく、Delta テーブルのままにしておく必要があります。このような状況では、Delta キャッシュ対応のワーカーインスタンスを使用し、一時テーブルをワーカーの SSD ドライブに自動的にキャッシュしてスキャンを高速化することを強くお勧めします。

Delta Merge - スピードアップしよう
MERGE オペレーションを使用することで、ソーステーブル、ビュー、または DataFrame からターゲット Delta テーブルにデータをアップサートすることができます。Delta Lake は、MERGE コマンドでの挿入、更新、削除をサポートしています。
Delta テーブル全体を日々上書き挿入する代わりに、可能な限り増分ロード戦略を使用することを推奨します。インクリメンタルロードを実現するためには、Delta Merge が不可欠です。Delta Merge は、SCD Type 2 テーブルの作成や CDC(Change Data Capture)のユースケースにも使用できま�す。Delta Merge の使用例をいくつかご紹介します:マージを使用した SCD Type 2、マージを使用した変更データの取り込み。
内部のマージ
舞台裏でのマージ操作は2つのステップで行われます:
- ON 節の条件を使用してソースとターゲットを内部結合し、ドライバに一致する行を含むターゲットのファイルリストを返します。
- このステップには 2 つの可能性があり、条件によって以下のいずれかが実行されます:
- ステップ 1 でターゲットに一致する行がなかった場合、追加のみの書き込みが実行され、ソースがターゲットに追加される。
- そうでなければ、完全な外部結合が実行され、マージされるソースとステップ 1 で生成された一致するファイル間の変更が統合される。
マージの課題
以下の理由により、パフォーマンス上の問題が発生することがあります:
- マージ操作のON句でマッチさせる十分具体的な条件がない場合、多くのデータを書き換えてしまうことになります。これはマージの速度を低下させます。
- 各マージ後に大量のデータを書き換える場合、Z-orderによるソートは台無しになるため、ソートを維持するために各マージ後にZ-orderを実行する必要があるかもしれません。
マージ最適化
私たちは、上記の課題を解決するために、以下の最適化技術を使用することができます:
ターゲットテーブルのデ�ータレイアウト
ターゲットテーブルに大きなファイル(例えば500 MB~1 GB)が含まれている場合、ファイルが大きければ大きいほど、少なくとも 1 つの一致する行が見つかる可能性が高くなるため、マージ操作のステップ 1 でそれらのファイルの多くがドライブに戻されます。このため、多くのデータが書き換えられることになります。したがって、マージの多いテーブルでは、ケースバイケースや作業量によって異なりますが、ファイルサイズを 16 MB から 64 MB まで小さくすることをお勧めします。詳細はファイルサイズのチューニングのセクションを参照してください。
パーティションプルーニング
無関係なパーティションを破棄するために、マージ操作の ON 句にパーティションフィルターを指定します。詳細はこの例を参照してください。
ファイルプルーニング
関連性のないファイルを破棄するために、マージ操作の ON 句にフィルターとして Z 順列(もしあれば)を指定します。ON 句で AND 演算子を使用して複数の条件を追加できます。
ブロードキャスト結合
Delta マージは裏で結合を実行するため、ソース DataFrame が十分に小さい(<= 200 MB)場合、ターゲット Delta テーブルにマージされるソース DataFrame を明示的にブロードキャストすることで、結合を高速化することができます。詳細については、ブロードキャスト結合のセクションを参照してください。
低シャッフルマージ
- これは新しい MERGE アルゴリズムで、変更されていないデータの既存のデータ構成(Z次クラスタリングを含む)を維持すると同時に、パフォーマンスを向上させることを目的としています。
- この "低シャッフル "MERGE では、更新された行のみが操作によって再編成され、変更されていない行は操作前と同じ順序とファイルグループのままです。
低シャッフルマージは Databricks Runtime 10.4 以上でデフォルトで有効になっています。それ以前のバージョンの Databricks Runtime では、spark.databricks.delta.merge.enableLowShuffle 設定を true に設定することで有効にすることができます。
データのパージ - 古くなったデータの対処法
Delta には、使用されていない古いデータファイルをパージする VACUUM 機能があります。これは、テーブルディレクトリから、Delta によって管理されていない全てのファイルと、テーブルのトランザクションログの最新の状態でなくなったデータファイルを削除し、保持のしきい値よりも古いファイルを��削除します。デフォルトのしきい値は 7 日間です。
必要に応じて、以下のようにデフォルトの保持しきい値を変更することができます。
VACUUM は、_delta_log を含むアンダースコア(_)で始まる全てのディレクトリをスキップします。ログファイルは、チェックポイント操作の後、自動的に非同期で削除されます。ログファイルのデフォルトの保存期間は 30 日間で、delta.logRetentionDurationで設定できます。
![]()
- 古いスナップショットやコミットされていないファイルは、テーブルへの同時実行中のリーダやライタによってまだ使用されている可能性があるため、保持間隔は少なくとも 7 日間に設定することをお勧めします。VACUUM がアクティブなファイルを削除すると、同時実行中の読者が失敗する可能性があります。
deltaTable.deletedFileRetentionDurationとdelta.logRetentionDurationを同じ値に設定し、データとトランザクション履歴の保持期間を同じにします。- Delta テーブルに適用されるトランザクションの頻度に応じて、毎日/毎週 VACUUM コマンドを実行��します。
- このコマンドは決してジョブの一部として実行せず、専用のジョブクラスタ上で別のジョブとして実行してください。通常は OPTIMIZE コマンドと一緒に実行します。
- VACUUM はそれほど集約的な処理ではありません。(主なタスクはファイルのリストアップで、これはワーカー上で並列処理されます。実際のファイル削除はドライバが処理します)1~4 ワーカーの小さな自動スケーリングクラスタで十分です。
Delta Live Tables(DLT)
Delta Live Tables(DLT)は、信頼性の高いバッチとストリーミングデータパイプラインの構築と管理を容易にし、Databricks レイクハウスプラットフォームに高品質データを供給します。
また、宣言型パイプラインの開発、データ検証の自動化、監視とリカバリのための深い視覚化が、データエンジニアリングチームによる ETL の開発と管理をシンプルにします。
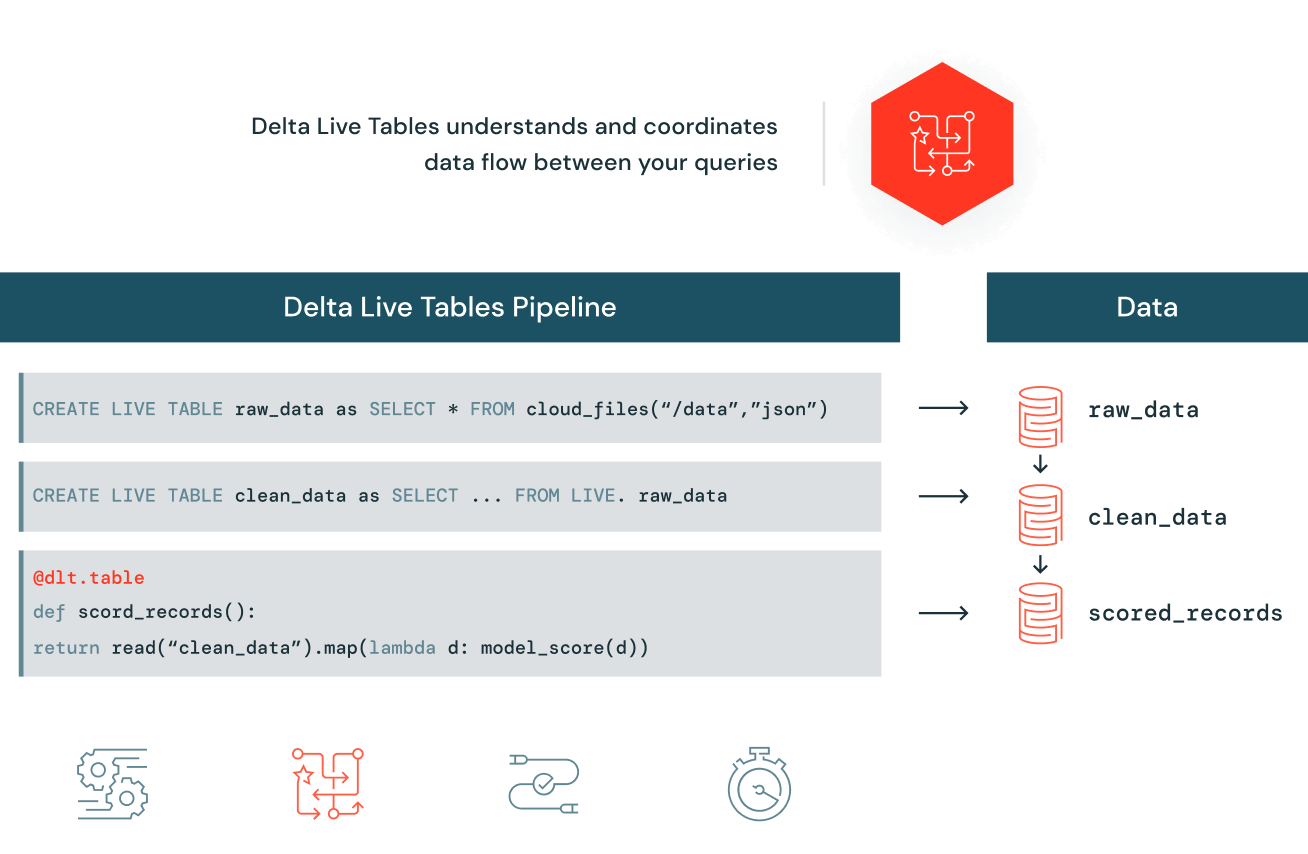
データパイプラインの構築・維持を容易に
Delta Live Tables では、データソース、変換ロジック、データの状態を指定することで、SQL または Python でエンドツーエンドのデータパイプラインを容易に定義できます。サイロ化したデータ処理ジョブを手動でつなぎ合わせる必要はありません。パイプラインにおけるデータの依存関係を自動的に維持し、環境を�問わないデータ管理で ETL パイプラインを再利用します。バッチまたはストリーミングモードで実行し、テーブル毎に増分または完全なコンピューティングを指定できます。
データ品質を自動チェック
Delta Live Tables は、高品質なデータを提供し、ダウンストリームのユーザーによる正確かつ有用な BI、データサイエンス、機械学習の実行を支援します。検証と整合性チェックにより、品質の低いデータのテーブルへの流入を防止し、事前に定義されたエラーポリシー(データの失敗、ドロップ、アラート、隔離)を使用して、データ品質のエラーを回避できます。また、データ品質の傾向を時系列に監視して、データの進化や、変更が必要な箇所についての気づきを得ることもできます。
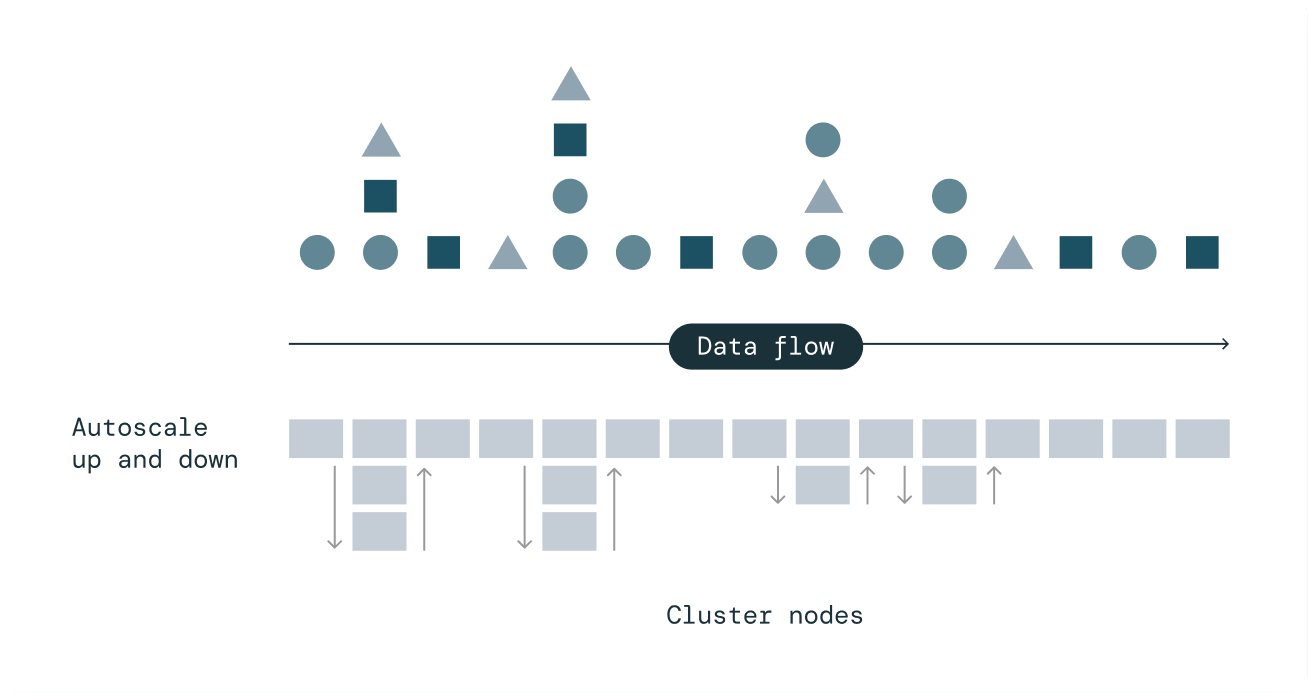
効率的なコンピューティング自動スケーリングによる費用対効果の高いストリーミング
Delta Live Tables の拡張オートスケーリングは、突発的で予測不可能なストリーミングワークロードを処理するために設計されています。エンドツーエンドの SLA を維持する一方で、必要な数のノードまでスケールアップするだけでクラスタの使用率を最適化し、使用率が低い場合はノードを正常にシャットダウンして不要なコストを回避します。
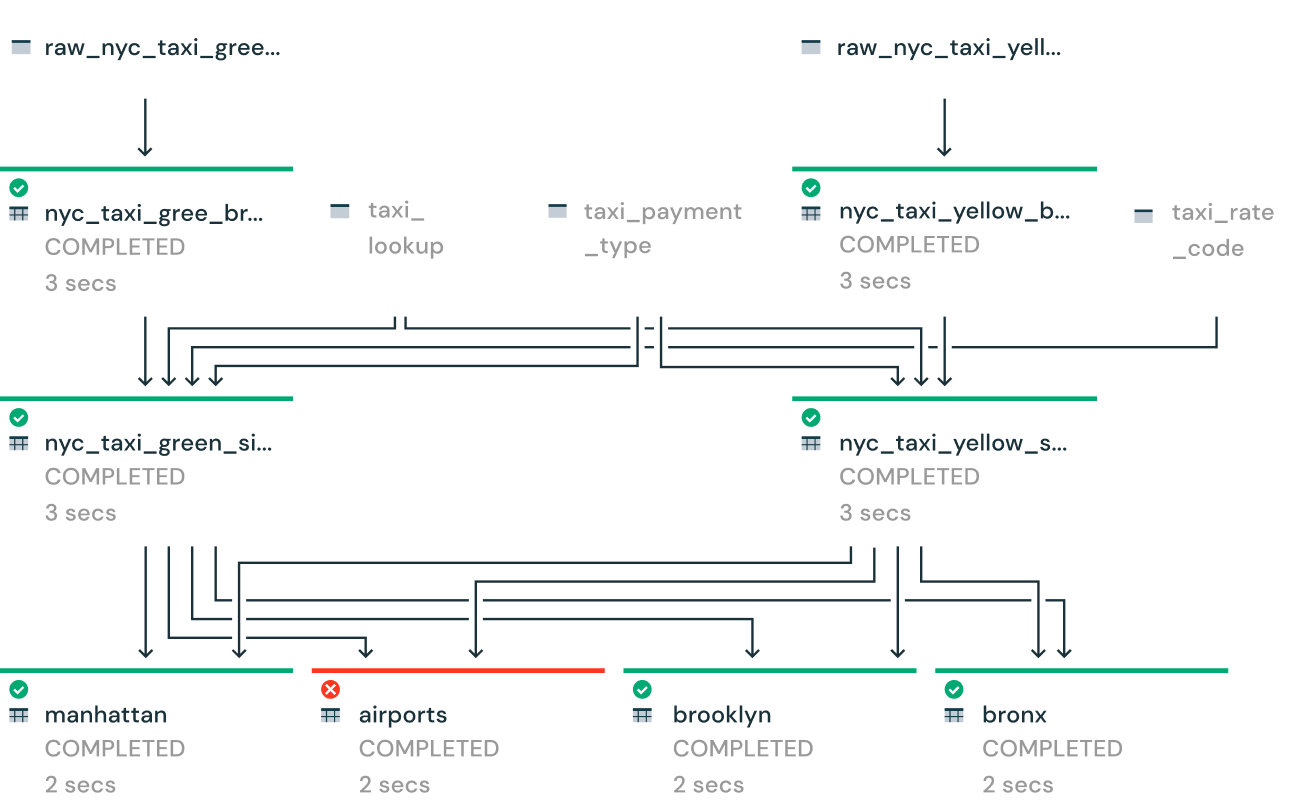
パイプラインの状況を詳細に把握
パイプラインの運用状況やデータリネージュを視覚的に追跡できるツールが利用できます。自動エラー処理とリプレイ機能でダウンタイムを短縮し、シングルクリックのデプロイメントとアップグレードでメンテナンスが効率化します。
![]()
- DLT はマネージド ETL フレームワークであり、DLT がクラスタ、オートスケール、障害時の再試行、その他の設定調整を含む運用タスクをバックグラウンドで処理する間、ユーザーはビジネス関連のコードを書くことに集中することができます。したがって、Spark のチューニング、クラスタの設定とチューニング(後述)、Delta のメンテナンスタスクなどを気にしなくて済むように、できるだけ DLT をデータエンジニアリングワークロードに使用することをお勧めします。
Databricks クラスタの構成とチューニング
万能クラスタと自動クラスタの比較
- 万能クラスタは、開発および/またはテスト段階でのアドホック�なクエリ実行とインタラクティブなノートブック実行にのみ使用されるべきです。
- 自動化ジョブには万能クラスタを使用しないでください。代わりに、ジョブにはエフェメラル(自動化ジョブとも呼ばれる)クラスタを使用してください。
- 万能クラスタではなく、自動クラスタを選択することで、 DBU コスト を削減することができます。
- また、 SQL ウェアハウス を活用してSQL クエリを実行することもできます。SQL ウェアハウスは、 SQL コマンド を実行できるコンピュートリソースで Databricks SQL 内のデータオブジェクトに対して実行できます。SQL ウェアハウスはサーバーレスでも利用可能で、即座にコンピュートへのアクセスを提供します。
自動スケーリング
Databricks は クラスタオートスケーリング というユニークな機能を提供します。ここでは、オートスケールをいつ、どのように活用するかについてのガイドラインを紹介します。
- アドホッククエリの実行、対話型ノートブックの実行、最小ワーカー数を 1 に設定した対話型クラスタを使用したパイプラインの開発/テストでは、常にオートスケーリングを使用してください。両者を組み合わせることで、コスト削減につながります。
- 本番環境のオートスケーリングジョブクラスタでは、ジョブが 1 ワーカー以上のリソースを必要とする場合、最小インスタンスを 1 に設定しないでください。その代わり、最小限のコンピュート要件に基づいて大きな値を設定します。スケールアップの時間を節約できます。
- Spark のシャッフルパーティションを微調整して、特定のジョブのワーカーコアを全て使用し、そのジョブが独自のジョブクラスタを持っている場合は、必ずしもオートスケーリングを採用する必要はありません。コストを完全にコントロールできるため、これは最良の選択肢です。しかし、予期せぬデータ急増に備えて計算リソースのバッファを確保したい場合は、オートスケーリングを使用することができます。この場合、1 日の予測データ負荷と必要なSLAに基づいて最小限のワーカー数を選択し、必要なときに自動スケーリングで追加できるよう、バッファとして数人(例えば 2~ 4 人)のワーカーを追加しておくだけです。
- Databricksのワークフローでは、同じパイプラインに属する多数のタスク(ジョブ)でジョブクラスタを共有することができます。共有ジョブクラスタ上で多くのジョブが並列実行されている場合、そのジョブクラスタの自動スケーリングを有効にして、スケールアップして全ての並列ジョブにリソースを供給できるようにする必要があります。
- 自動スケーリングは、Spark Structured Streaming ワークロードには使用しないでください。Enhanced Autoscaling と呼ばれる機能のおかげで、Delta Live Tables のストリーミングワークロードでは、オートスケーリングがかなりうまく機能します。
ワークロードに応じたインスタンスタイプ
作業負荷のタイプに基づいてインスタンスファミリーを選択するための一般的なガイドライン:
| VM カテゴリー | ワークロードタイプ |
|---|---|
| メモリ最適化 |
|
| コンピューティング最適化 |
|
| ストレージ最適化 |
|
| GPU 最適化 |
|
| 汎用 |
|
ワーカー数
適切なワーカー数を選択するには、Spark ジョブの計算とメモリのニーズを把握するために、いくつかの試行と反復が必要です。以下は、そのためのガイドラインです。
- 本番ジョブでは、単一のワーカーを決して選択しないでください。
- 小規模なワークロード(例えば、結合や集約のような大規模な変換を伴わないジョブ)では、2~4 人のワーカーで開始します。
- 結合や集約のような幅広い変換を伴う中規模から大規模のワークロードでは、8~10 人のワーカーで開始し、必要に応じてスケールアップします。
- シャッフルパーティションを微調整して、全てのクラスタコアを完全に使用できるようにします。
- おおよその実行時間は、最初に数回実行すればわかります。SLA に違反するようであれば、ワーカーを増やすべきです。
- シャッフルパーティションが微調整され、データのスキューやスピルの問題が解決されていれば、ワーカーを追加してもコストが高くなることはありません。このような状況では、作業員を増やせばそ�れに比例して総実行時間が短縮され、結果としてコストはほぼ同じになります。
スポットインスタンス
- スポットインスタンスを使用して、市場価格を下回る料金で予備の VM インスタンスを使用できます。
- インタラクティブなアドホック/共有クラスタに最適です。
- SLA のない本番ジョブに使用可能。
- SLA が厳しい本番ジョブにはお勧めしません。
- ドライバーにスポットインスタンスを使用しないでください。
自動終了
- コスト削減のため、指定した非アクティブ期間(分)が経過するとクラスタを終了します。
- 自動終了 を万能クラスタで有効にし、アイドル状態のクラスタが夜間や週末に稼働しないようにします。
- クラスタはデフォルトで 120 分で自動終了するように設定されていますが、さらにコストを削減するために、これを 10~15 分など、もっと低い値に変更することができます。
クラスタの使用
クラスタを最大限に活用していることを確認する必要があります。シャッフルパーティションの数によっては、ジョブが完了するまでにクラスタ上で何度も繰り返し実行される可能性があるため、経験則では、全てのワーカーコアがアクティブに稼働し、どの繰り返しにおいてもアイドル状態にならないようにすることです。確実な唯一の方法は、シャッフルパーティションの数を常にワーカーコアの総数の掛��け算に設定することです。
Ganglia UI は、全てのコアが完全に接続されていることを確認するのに役立ちます。Ganglia UI には、メトリクスタブの下に固定されているクラスタ UI から直接アクセスできます。
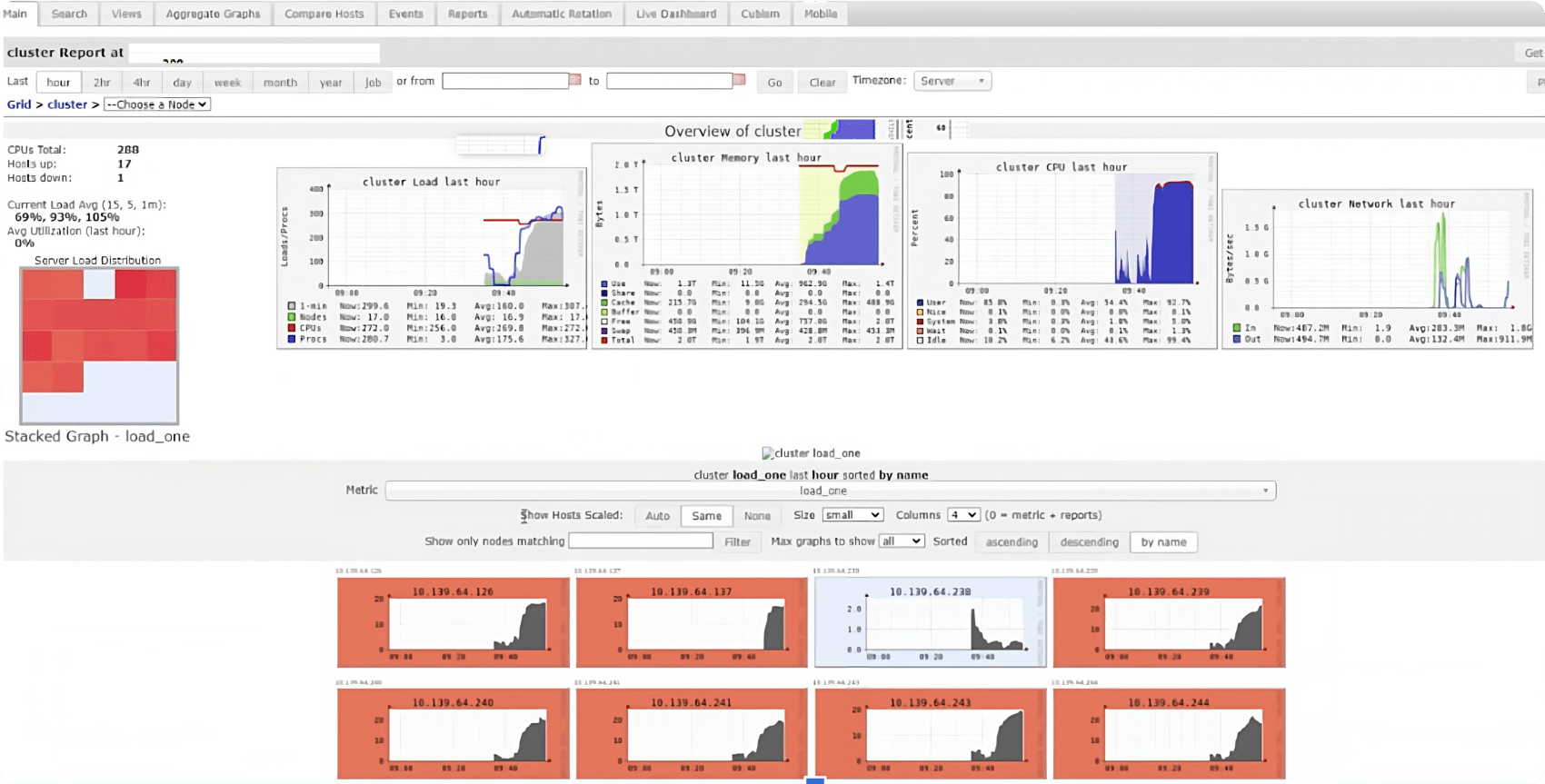
Ganglia UI で注意すべき点:
- クラスタの平均負荷は常に 80% 以上でなければならない。
- クエリ実行中、クラスタ負荷分布グラフ(UI の左側)の四角は(ドライバノードを除いて)全て赤くなり、全てのワーカーコアがフル稼働していることを示す。
- クラスタメモリの使用率を最大化する(少なくとも60%-70%、あるいはそれ以上)。
- Ganglia メトリクスは、Databricks Runtime 12.2 以下でのみ使用できる。
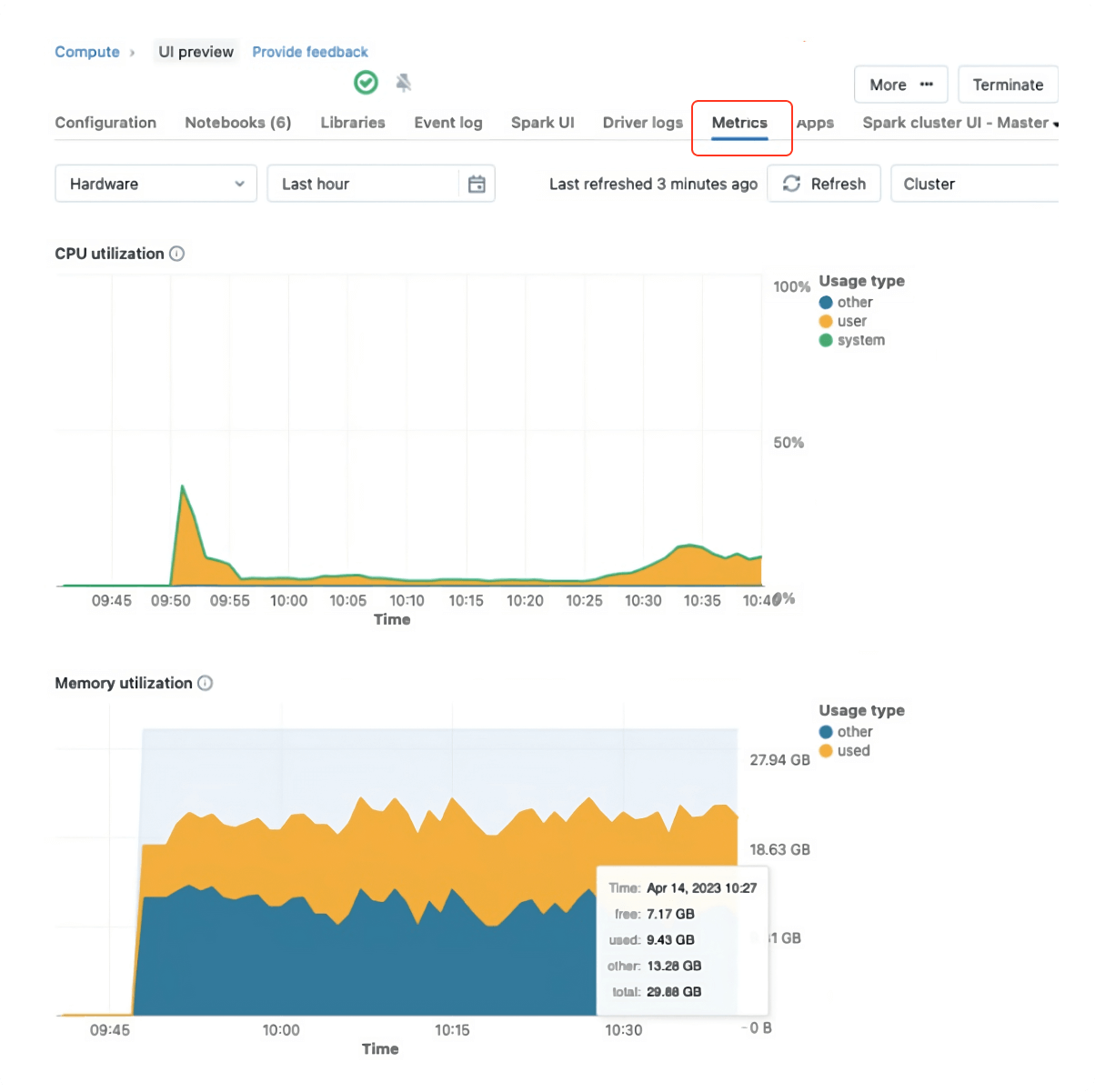
Databricks Runtime 13 以降では Ganglia は、より安全で強力な新しいクラスタメトリクス UI に置き換えられ、すっきりとしたデザインでシンプルなユーザーエクスペリエンスを実現しています。そのため、DBR 13 以降では、この新しい UI を活用してクラスタの使用状況を確認できます。
クラスタポリシー
クラスタポリシーは、一連のルールに基づいてクラスタを構成する機能を制限します。クラスタポリシーを効果的に使用すると、管理者は次のことが可能になります。
- 所定の設定でクラスタを作成するユーザを制限する。
- クラスタあたりの最大コストを制限することにより、コストをコントロールする(1 時間あたりの価格に寄与する値を持つ属性に制限を設定することにより)。
- ユーザーインターフェイスを簡素化し、より多くのユーザーが独自のクラスタを作成できるようにする(いくつかの値を修正し、非表示にすることで)。
クラスタポリシーのベストプラクティスガイド を参照して、クラスタガバナンスの展開を計画し、成功させる。
インスタンスプール
Databricks プールは、すぐに使用できるアイドル状態のインスタンスセットを維持することで、クラスタの起動時間と自動スケーリング時間を短縮します。クラスタがプールにアタッチされると、プールのアイドルインスタンスを使用してクラスタノードが作成されます。プール内でインスタンスがアイドル状態の場合、Azure VM コストのみが発生し、DBU コストは発生しません。
プールは、SLA が厳しいワークロードに推奨され、コストを最小限に抑えながら処理時間を改善するために、追加のコンピュート�リソースへの高速アクセス(高速オートスケール)が要件となります。
Photon
Photon は、Databricks レイクハウスプラットフォームの次世代エンジンであり、非常に高速なクエリ性能を、より低いコストで提供します。Photon は Apache Spark API と互換性があり、既存の Spark コードとすぐに連携し、標準的な Databricks Runtime と比較して大幅なパフォーマンス向上を実現します。Photon の利点は以下のとおりです。
- 大量のデータ(100 GB 以上)を処理し、集約や結合を含むクエリの高速化。
- Delta キャッシュからデータが繰り返しアクセスされる場合のパフォーマンス向上。
- 多数のカラムと多数の小さなファイルを持つテーブルに対して、よりロバストなスキャン/読み取りパフォーマンスを実現。
- UPDATE、DELETE、MERGE INTO、INSERT、CREATE TABLE AS SELECT を使用した Delta の書き込みの高速化。
- 結合の改善
以下の特性を持つワークロードでは、(評価と性能テストの後に)Photon を有効にすることを推奨します。
- Delta MERGE オペレーションで構成される ETL パイプライン
- クラウドストレージへの大量データの書き込み(Delta/Parquet)
- 大規模データセットのスキャン、結合、集計、小数計算
- ストレージに到着した新しいデータを段階的かつ効率的に処理するオートローダー
- SQL を使用したインタラクティブ/アドホッククエリ
その他
- 最新の Databricks Runtime (DBR)は LTS バージョンを使用してください。ほとんどの場合、最新の Databricks ランタイムは以前のバージョンよりも高速です。
- 古い DBR では Spark ジョブがスタックしたりゾンビ化したりする可能性があるため、万能クラスタを定期的に、少なくとも週に 1 回(ビジー状態のクラスタでは毎日)再起動します。
- 以下の場合にのみ、大きなドライバーノード(4~8 コア、16~32 GB でほぼ十分)を構成します。
- 大きなデータセットが返される/収集される(
spark.driver.maxResultSizeも通常大きくなります) - 大規模なブロードキャスト結合を実行中
- 同じクラスタ上で多数の(50 以上の)ストリームまたは同時実行ジョブ/ノートブック:
- DLT は、パイプラインの完全な DAG を決定し、可能な限り最適化された方法で実行するため、Delta Live Tables は、このようなワークロードに適しているかもしれません。
- 大きなデータセットが返される/収集される(
- 単一ノードライブラリ(例:Pandas)を使用するワークロードでは、単一ノードのデータサイエンスクラスタを使用することをお勧めします。このようなライブラリはクラスタのリソースを分散的に利用しないためです。
- クラスタタグを Databricks クラスタに関連付けることで、コストを特定のチーム/部門に帰属させることができます。クラスタタグは、基盤となるクラウドリソース(VM、ストレージ、ネッ��トワークなど)に自動的に伝搬されます。
- このようなシャッフルを多用するワークロードでは、ノード間のデータ転送時のネットワーク I/O を減らすために、より大きなノードサイズを使用することを推奨します。
- 大容量の RAM(>128 GB)を搭載したワーカーを選択すると、ジョブがより効率的に実行できるようになりますが、ガベージコレクション中に長い休止時間が発生し、パフォーマンスに悪影響を及ぼし、場合によってはジョブが失敗することもあります。したがって、128 GB 以上の RAM を搭載したワーカーを選択することはお勧めできません。ワーカーのメモリとは別に、長いガベージコレクション(GC)休止を避ける方法がいくつかあります。
collect()関数を呼び出してドライバーのデータを収集しないこと- toPandas() 関数にも適用される
- Spark キャッシュよりも Delta キャッシュを優先する
- 上記のいずれの解決策も役に立たない場合は、代わりに G1GC ガベージコレクタを使用します。Advance cluster options の Spark config セクションで
spark.executor.defaultJavaOptionsとspark.executor.extraJavaOptionsを-XX:+UseG1GC値に設定します。
- 特定のクラスタサイズの例については、Databricks ドキュメントのクラスタサイズ設定例を参照してください。
まとめ
本書では、Spark、Delta、Databricks の最適化戦略と戦術を数多く取り上げてきました。本書の目的は、読者が分散コンピューティング上で実行するビッグデータワークロードを開発する際に遭遇する可能性のあるさまざまな課題、およびこれらの困難を特定するための方法とその解決策を認識することです。このようなガイドは、企業がコストを削減し、より少ないリソースでより多くの成果を上げようとしている現在の経済情勢において、データエンジニアとデータアーキテクトがエンジニアリングと SLA のコストを管理し、クラウドリソースを最大限に活用するうえで本当に役立つ可能性があります。
Databricks は、グローバルで唯一のデータ & AI 企業です。コムキャスト、コンデナストをはじめ、フォーチュン 500 企業の過半数を含む世界中の 9,000 を超える企業が、Databricks のレイクハウスプラットフォームを利用して、データ、分析、AI の統合を実現しています。Databricks は、米国カリフォルニア州サンフランシスコに本社を置き、世界中に事業所を配しています。Apache Spark、Delta Lake、MLflow のオリジナル開発メンバーによる創業以来、Databricks は、データの活用によって難題解決に挑む組織の支援に取り組んでいます。Twitter、LinkedIn、Facebook での情報発信も行っております。ぜひご覧ください。
© Databricks 2023.無断転用は禁止されています。Apache、Apache Spark、Spark、および Spark のロゴは、Apache Software Foundation の商標です。
プライバシーポリシー | 利用規約