Build Reliable and Cost Effective Streaming Data Pipelines With Delta Live Tables’ Enhanced Autoscaling
by Paul Lappas, Li Zhang, Alex Ott, Kiavash Kianfar, Yuhong Chen and Prashanth Babu Velanati Venkata
This year we announced the general availability of Delta Live Tables (DLT), the first ETL framework to use a simple, declarative approach to building reliable data pipelines. Since the launch, Databricks continues to expand DLT with new capabilities. Today we are excited to announce that Enhanced Autoscaling for Delta Live Tables (DLT) is now generally available. Analysts and data engineers can use DLT to quickly create production-ready streaming or batch data pipelines. You only need to define the transformations to perform on data using SQL or Python, and DLT understands your pipeline's dependencies and automates compute management, monitoring, data quality, and error handling.
DLT Enhanced Autoscaling is designed to handle streaming workloads which are spiky and unpredictable. It optimizes cluster utilization for streaming workloads to lower your costs while ensuring that your data pipeline has the resources it needs to maintain consistent SLAs. As a result, you can focus on working with data with the confidence that the business has access to the freshest data and that your costs are optimized. Many customers are already using Enhanced Autoscaling in production today, from startups to enterprises like Nasdaq and Shell. DLT Enhanced Autoscaling is powering production use cases at customers like Berry Appleman & Leiden LLP (BAL), the award-winning global immigration law firm:
“DLT’s Enhanced Autoscaling enables a leading law firm like BAL to optimize our streaming data pipelines while preserving our latency requirements. We deliver report data to clients 4x faster than before, so they have the information to make more informed decisions about their immigration programs.” —Chanille Juneau, Chief Technology Officer, BAL

Streaming data is mission critical
Streaming workloads are growing in popularity because they allow for quicker decision making on enormous amounts of new data. Real time processing provides the freshest possible data to an organization's analytics and machine learning models enabling them to make better, faster decisions, more accurate predictions, offer improved customer experiences, and more. Many Databricks users are adopting streaming on the lakehouse to take advantage of lower latency, fault tolerance, and support for incremental processing. We have seen tremendous adoption of streaming among both open source Apache Spark users and Databricks customers. The graph below shows the weekly number of streaming jobs on Databricks over the past three years, which has grown from a few thousand to a few million and is still accelerating.
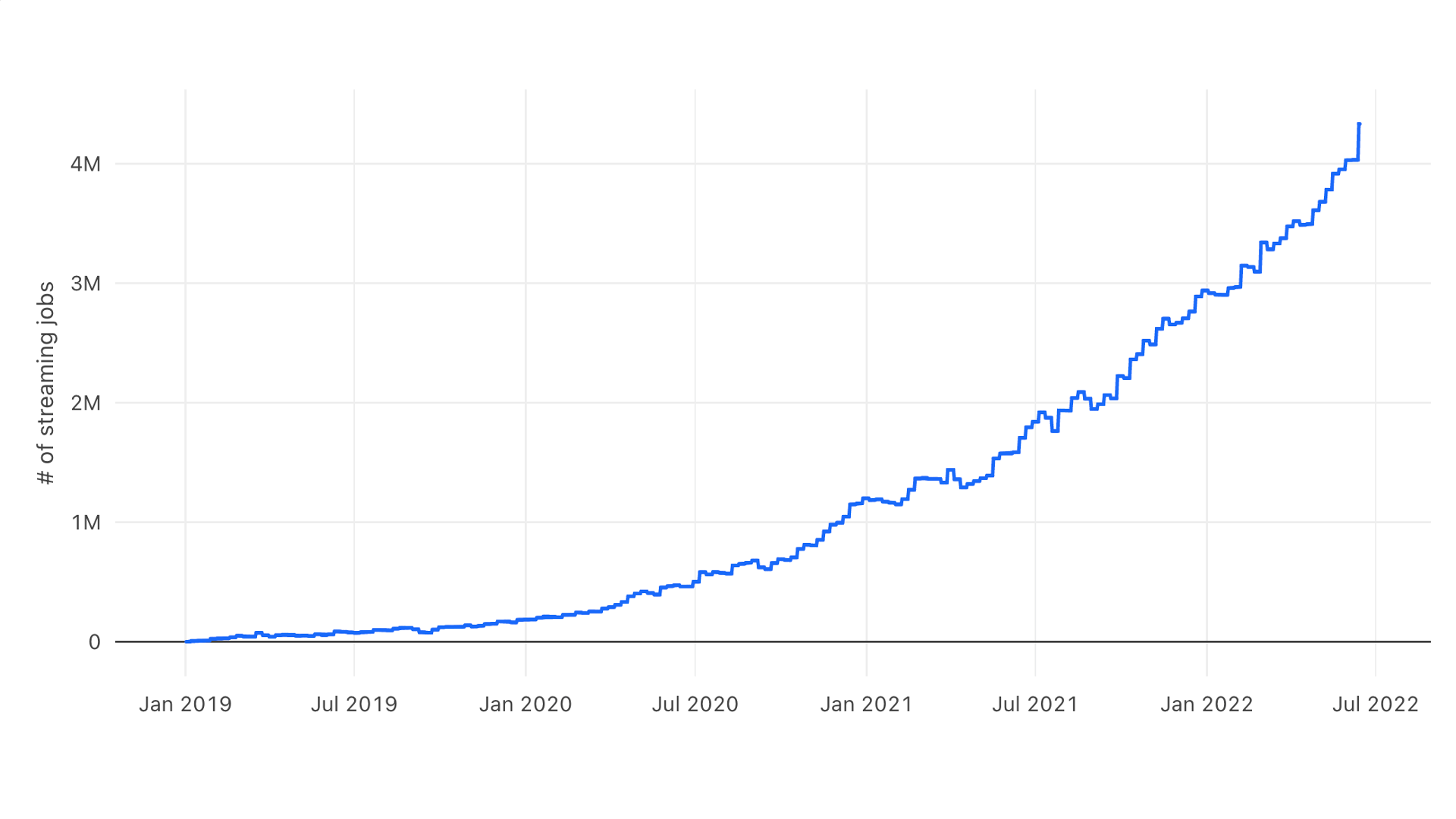
There are many types of workloads where data volumes vary over time: clickstream events, e-commerce transactions, service logs, and more. At the same time, our customers are asking for more predictable latency and guarantees on data availability and freshness.
Scaling infrastructure to handle streaming data while maintaining consistent SLAs is technically challenging, and it has different, more complicated needs than traditional batch processing. To solve this problem, data teams often size their infrastructure for peak loads, which results in low utilization and higher costs. Manually managing infrastructure is operationally complex and time consuming.
Databricks introduced cluster autoscaling in 2018 to solve the problem of scaling compute resources in response to changes in compute demands. Cluster autoscaling has saved our customers money while ensuring the necessary capacity for workloads to avoid costly downtime. However, cluster autoscaling was designed for batch-oriented processes where the compute demands were relatively well known and did not fluctuate over the course of a workflow. DLT’s Enhanced Autoscaling was built to specifically handle the unpredictable flow of data that can come with streaming pipelines, helping customers save money and simplify their operations by ensuring consistent SLAs for streaming workloads.
DLT Enhanced Autoscaling intelligently scales streaming and batch workloads
DLT with autoscaling spans many use cases across all industry verticals including retails, financial services, and more. In this example, we've picked a use case analyzing cybersecurity events.Let’s see how Enhanced Autoscaling for Delta Live Tables removes the need to manually manage infrastructure while delivering fresh results with low costs. We will illustrate this with a common, real-world example: using Delta Live Tables to detect cybersecurity events.
Cybersecurity workloads are naturally spiky - users log into their computers in the morning, walk away from desks for lunch, more users wake up in another timezone and the cycle repeats. Security teams need to process events as quickly as possible to protect the business while keeping costs under control.
In this demo, we will ingest and process connection logs produced by Zeek, a popular open source network monitoring tool.
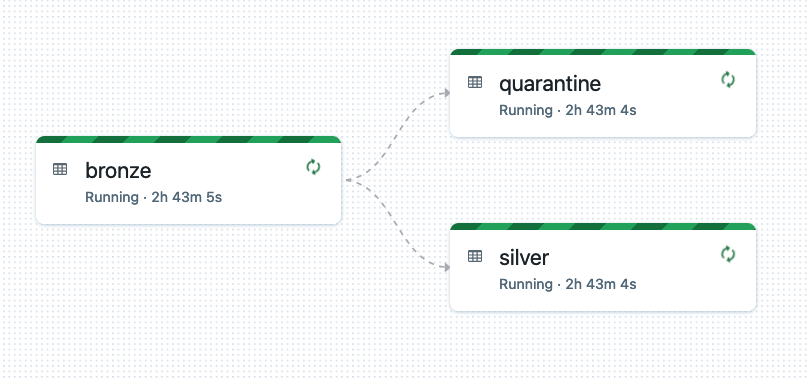
The Delta Live Tables pipeline follows the standard medallion architecture - it ingests JSON data into a bronze layer using Databricks Auto Loader, and then moves cleaned data into a silver layer, adjusting data types, renaming columns, and applying data expectations to handle bad data. The full streaming pipeline looks like this, and is created from just a few lines of code:
For analysis we will use information from the DLT event log, which is available as a Delta table.
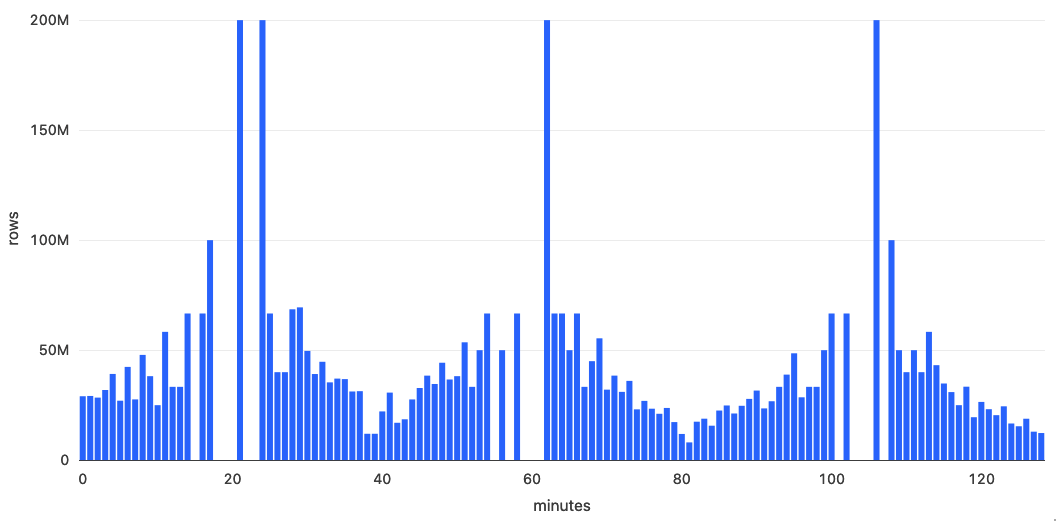
The graph below shows how the cluster size with enhanced autoscaling increases with the data volume and decreases when the data volume decreases and the backlog is processed.
As you can see from the graph, the ability to automatically increase and decrease the cluster's size significantly saves resources.
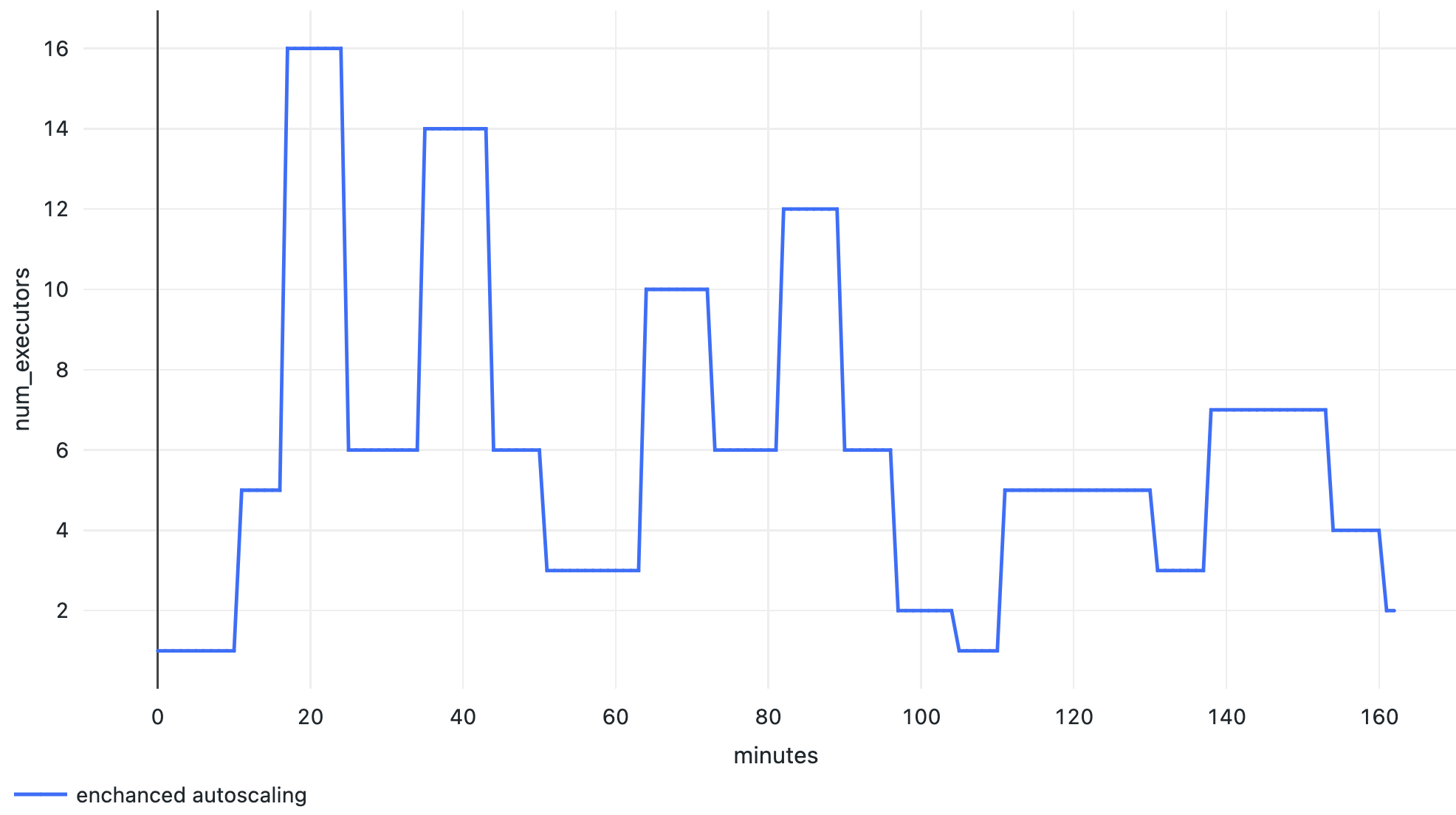
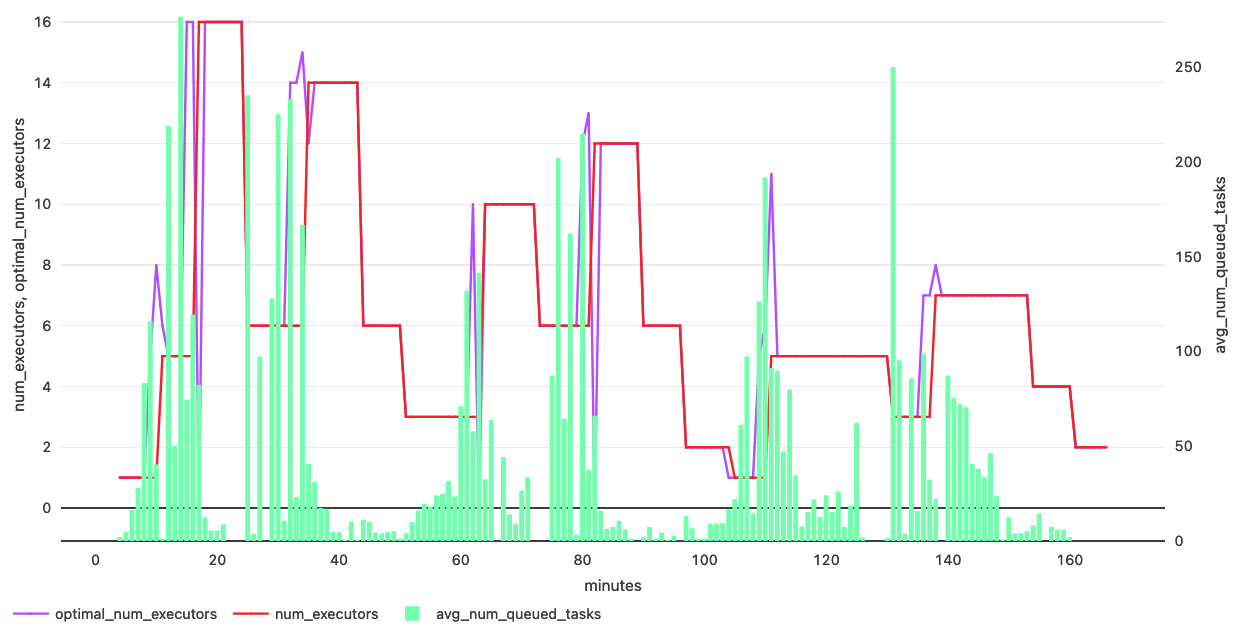
Delta Live Tables collects useful metrics about the data pipeline, including autoscaling and cluster events. Cluster resources events provide information about the current number of executors and task slots, utilization of task slots and number of queued tasks. Enhanced Autoscaling uses this data in real-time to calculate the optimal number of executors for a given workload. For example, we can see in the graph below that an increase in the number of tasks results in an increase in the number of executors launched, and when the number of tasks goes down, executors are also removed to optimize cost:
Conclusion
Given changing, unpredictable data volumes, manually sizing clusters for best performance can be difficult and risk overprovisioning. DLTs Enhanced Autoscaling maximizes cluster utilization while reducing the overall end-to-end latency to reduce costs.
In this blog article, we demonstrated how DLT's Enhanced Autoscaling scales up to meet streaming workload requirements by selecting the ideal amount of compute resources based on the current and projected data load. We also demonstrated how, in order to reduce expenses, Enhanced Autoscaling will scale down by deactivating cluster resources.
Get started with Enhanced Autoscaling and Delta Live Tables on the Databricks Lakehouse Platform
Enhanced Autoscaling is enabled automatically for new pipelines created in the DLT user interface. We encourage users to enable Enhanced Autoscaling on existing DLT pipelines by clicking on the Settings button in the DLT UI. DLT pipelines created through the REST API must include a setting to enable Enhanced Autoscaling (see docs). For DLT pipelines where no autoscaling mode is specified in the settings, we will gradually roll out changes to make Enhanced Autoscaling the default.
Watch the demo below to discover the ease of use of DLT for data engineers and analysts alike:
If you are a Databricks customer, simply follow the guide to get started. If you are not an existing Databricks customer, sign up for a free trial, and you can view our detailed DLT Pricing here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.