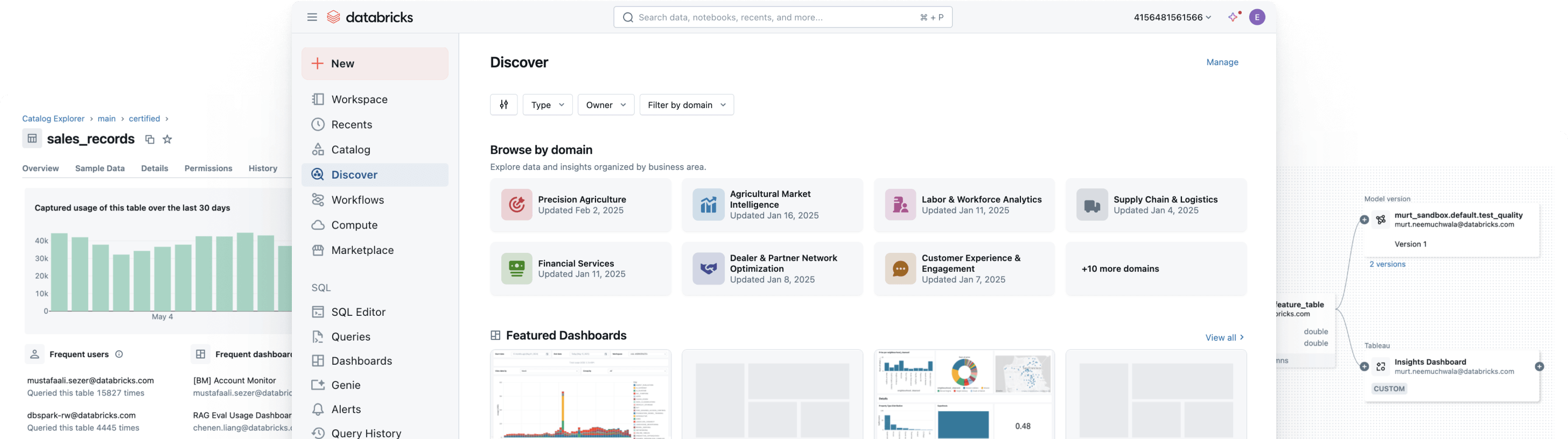
トップチームは統一されたオープンなガバナンスで成功しますガバナンス、発見、監視、共有 - すべて一箇所で
データとAI全体で開放的で知的なガバナンスを通じて、データランドスケープを統一し、コンプライアンスを合理化し、より速く信頼性のある洞察を引き出しますガバナンスを統合
構造化データ、非構造化データ、MLモデル、ビジネス指標を問わず、一貫した発見、アクセス、品質監視、コンプライアンスコントロールを任意のクラウドで実施します。統一されたガバナンスにより、リスクを減らし、監査を簡素化し、コントロールを妥協することなくデータアクセスを加速できます。
オープン
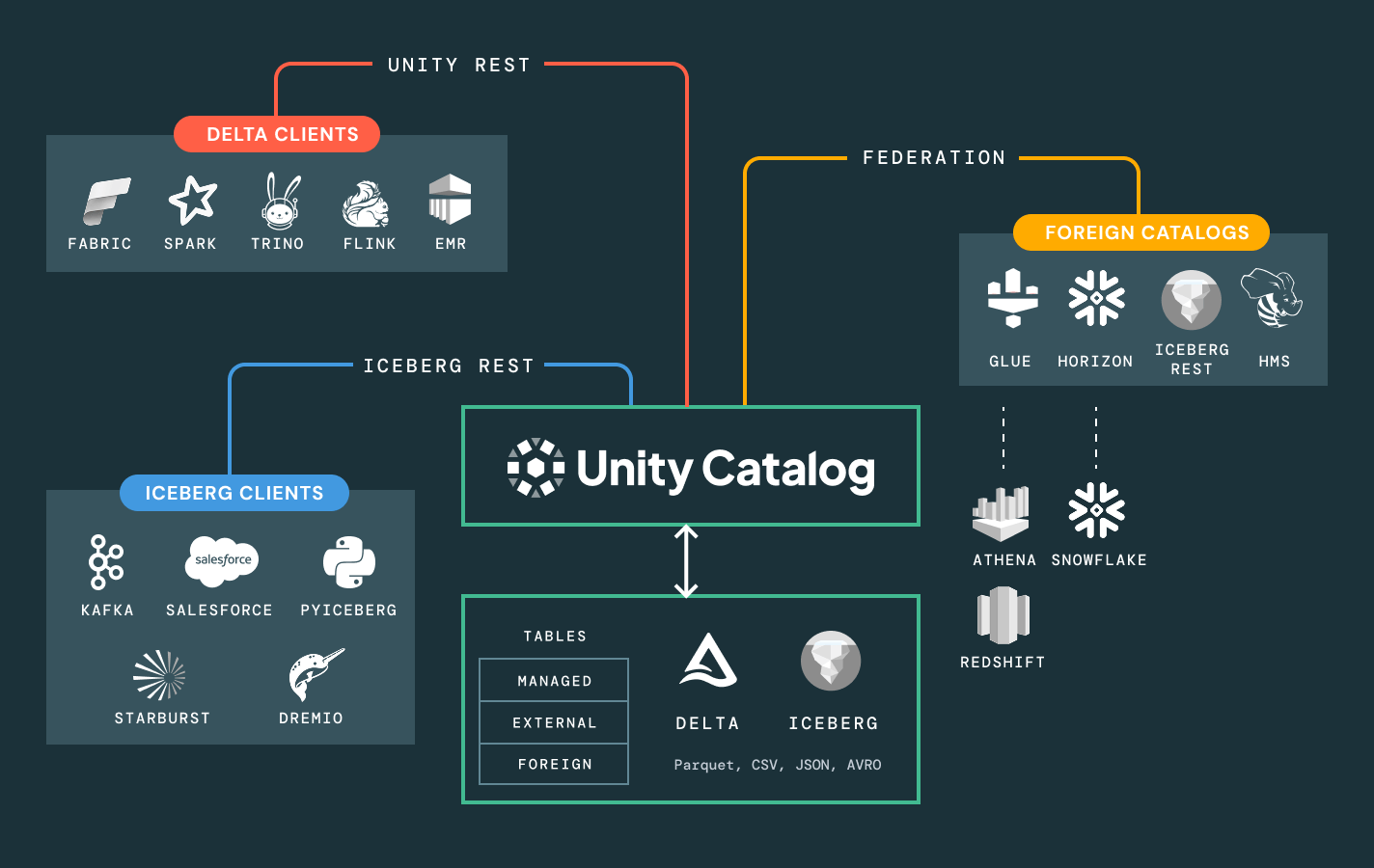
プラットフォームロックインから解放されます。お選びのオープンレイクハウスフォーマット(Delta、Apache Iceberg™、Hudi、Parquet)を活用し、移行なしで外部データソースに接続し、オープンAPIを通じて既存のBI、AI、カタログツールと統合します。データを内部またはパートナーと共有している場合でも、セキュアでスケーラブルなオープンスタンダードベースのコラボレーションを実現します。
組み込みのインテリジェンス
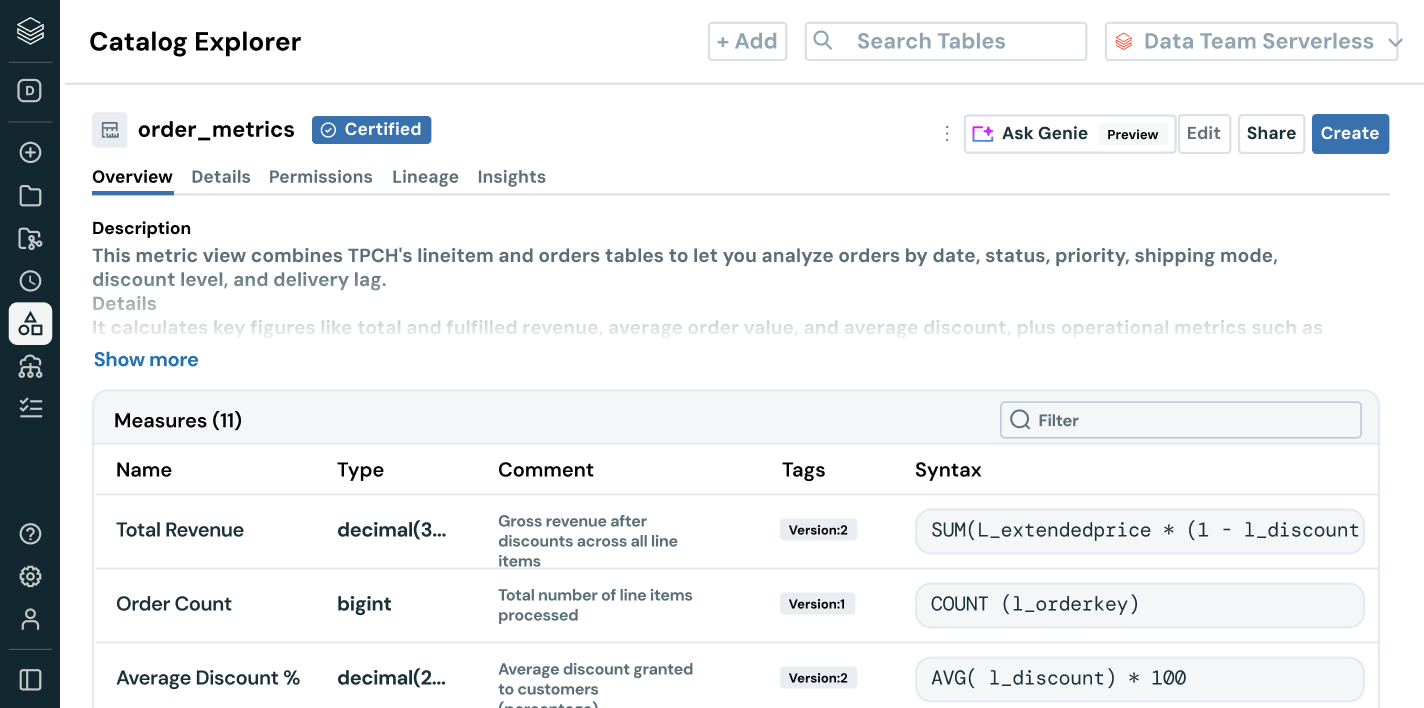
データの発見とアクセス管理を超えて - ユーザーにビジネスコンテキストを提供します。組み込みの系統、使用洞察、ビジネスセマンティクスにより、ユーザーはデータをより早く見つけ、理解し、探索できます。AIによる文書化、自然言語検索、会話型スペースが、技術者とビジネスユーザーがデータから意思決定に至るまでのプロセスを加速し、完全なビジネス�コンテキストを提供します。
組み込みのインテリジェントガバナンス
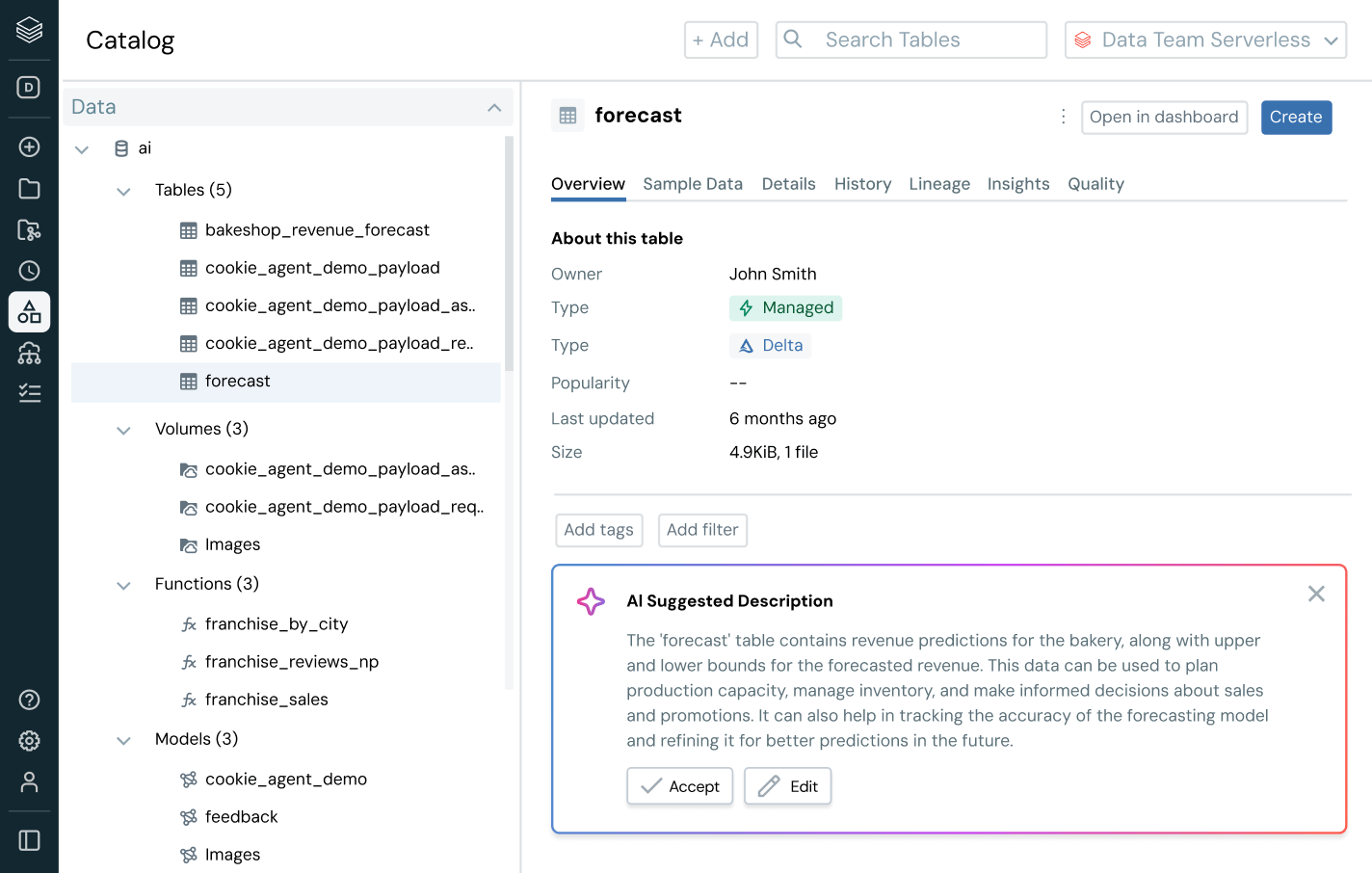
インテリジェントなガバナンスを用いて、全体のデータとAIエステートを通じて発見、コンプライアンス、監視を簡素化しますDelta Lake、Apache Iceberg、Hudi、Parquetなどのオープンデータフォーマットを通じて、すべての構造化データ、�非構造化データ、ビジネス指標、AIモデルのための統一カタログ。

その他の機能
統一されたガバナンスでデータの全ビジネス価値を引き出します

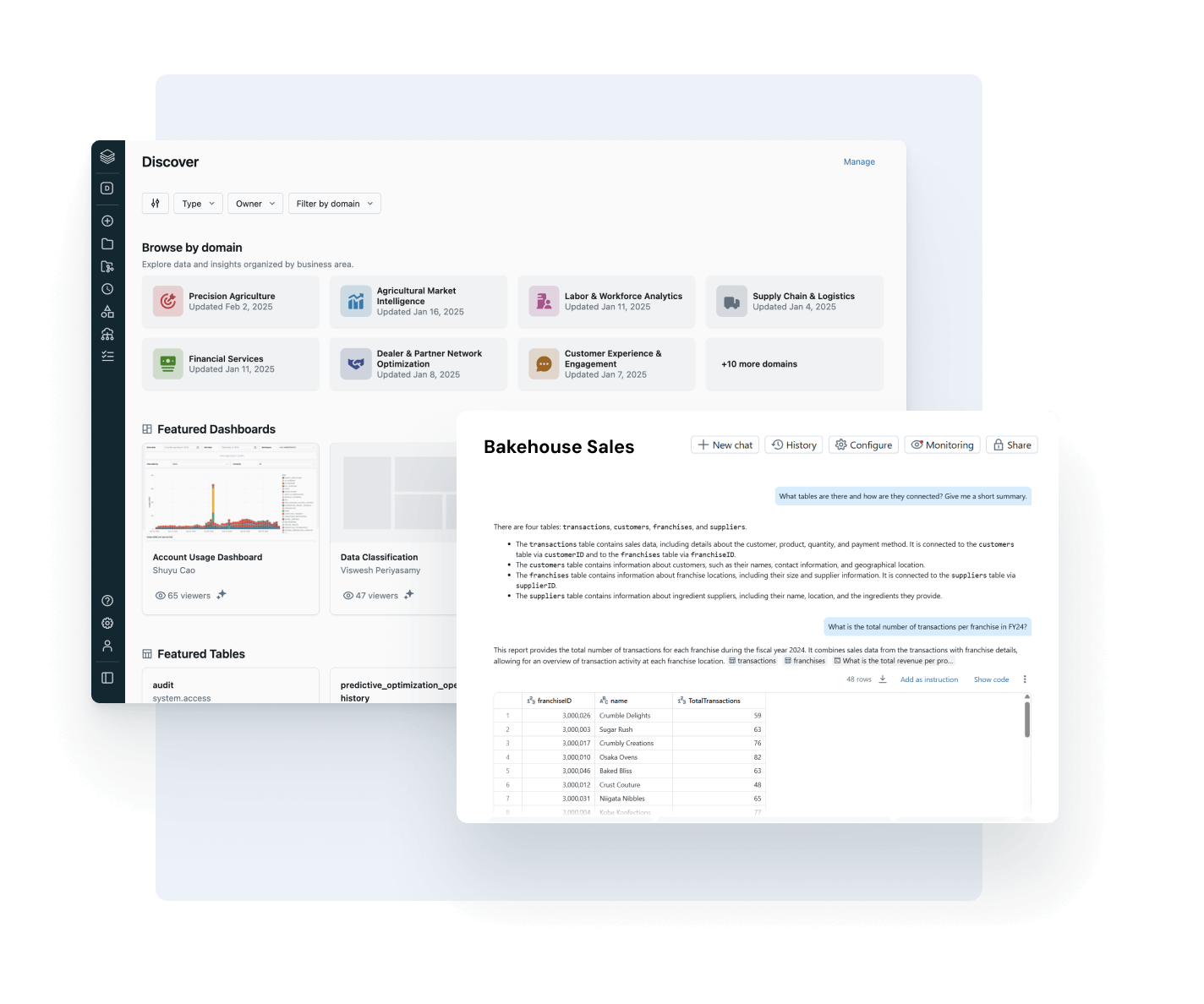
すべてのユーザーが正しいデータを見つけ、信頼し、使用できるようにします
あなたの最も価値のあるデータ資産を見つけやすく、理解しやすくします - 会社全体で。
- 自動キュレーションされたディスカバリーは、信頼性の高い、高影響力のデータアセットを提供します
- AIによる文書化、タグ、使用洞察は豊かなコンテキストを追加します
- ガバナンスされたビジネスセマンティクスが、チームとツールを通じて一貫した、信頼できる指標を提供します
- AI/BI Genieとの会話型インターフェースが、ビジネスユーザーがSQLを必要とせずにデータを探索するのを助けます
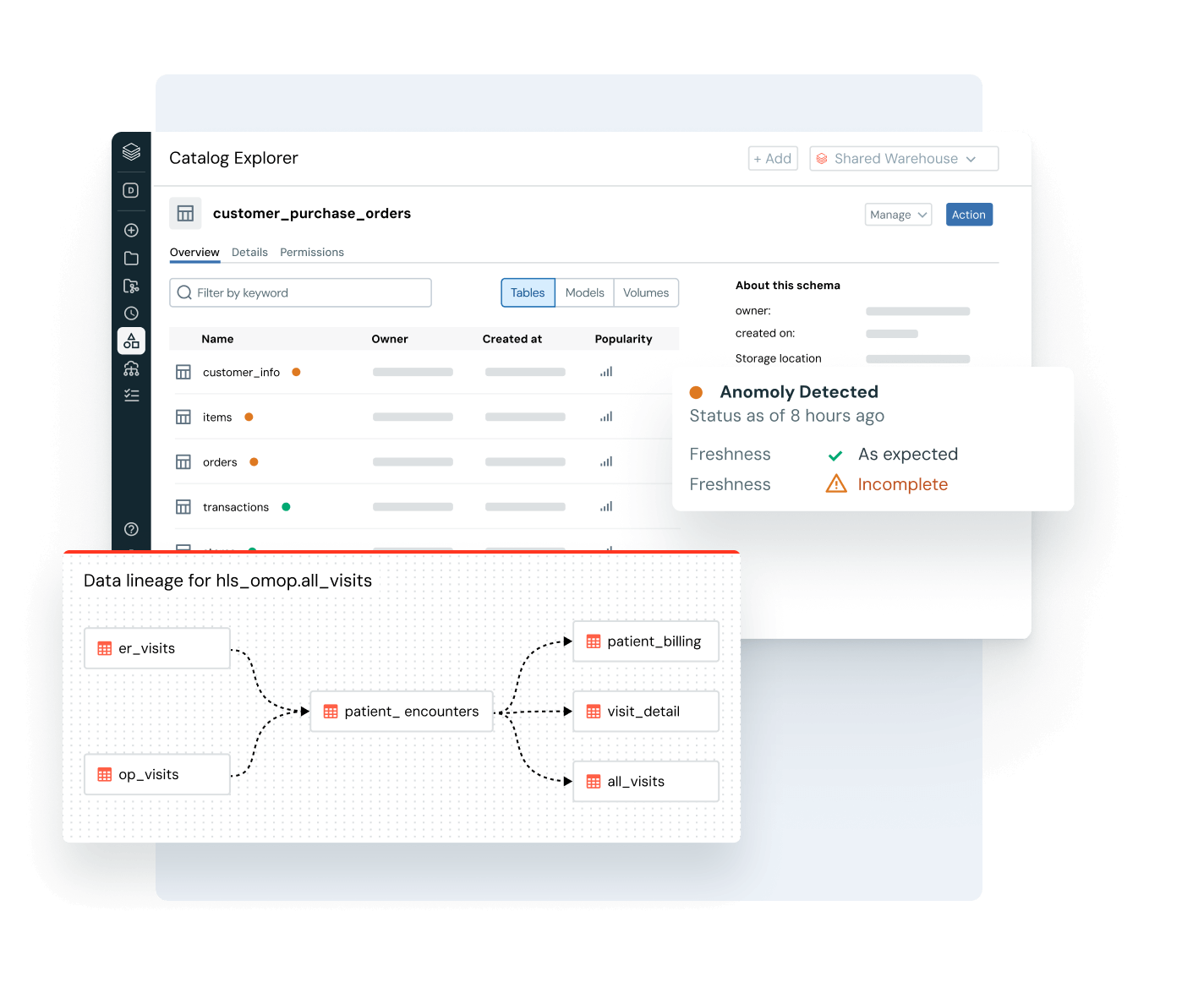
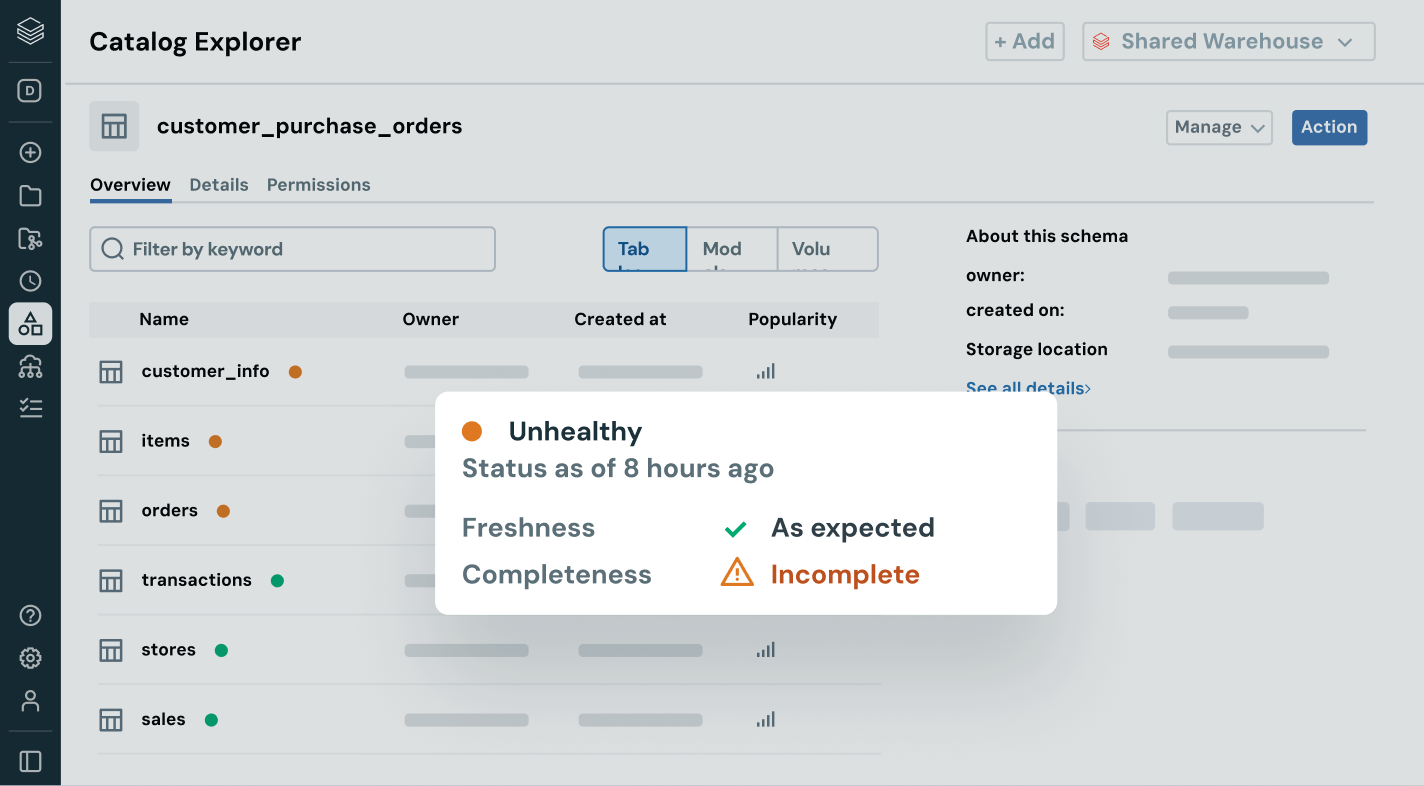
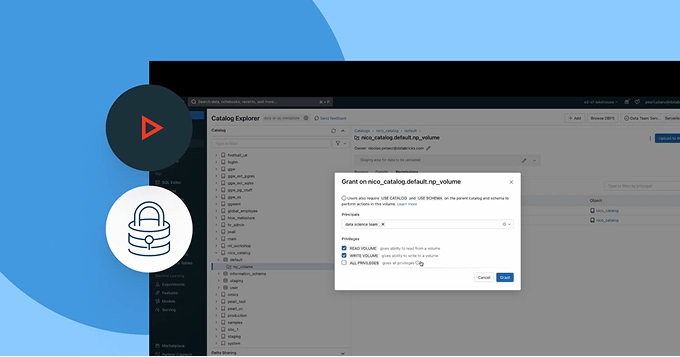
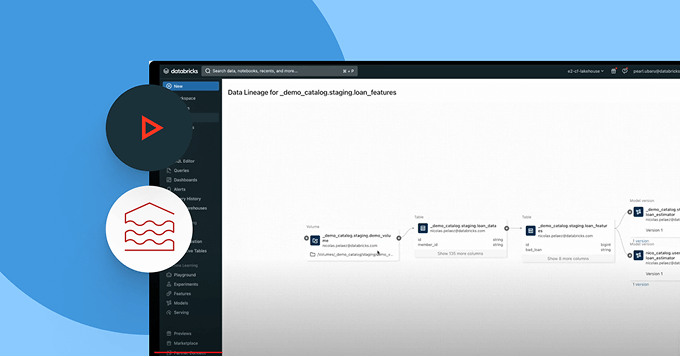
頼りにするデータが新鮮で完全で信頼できることを確認します
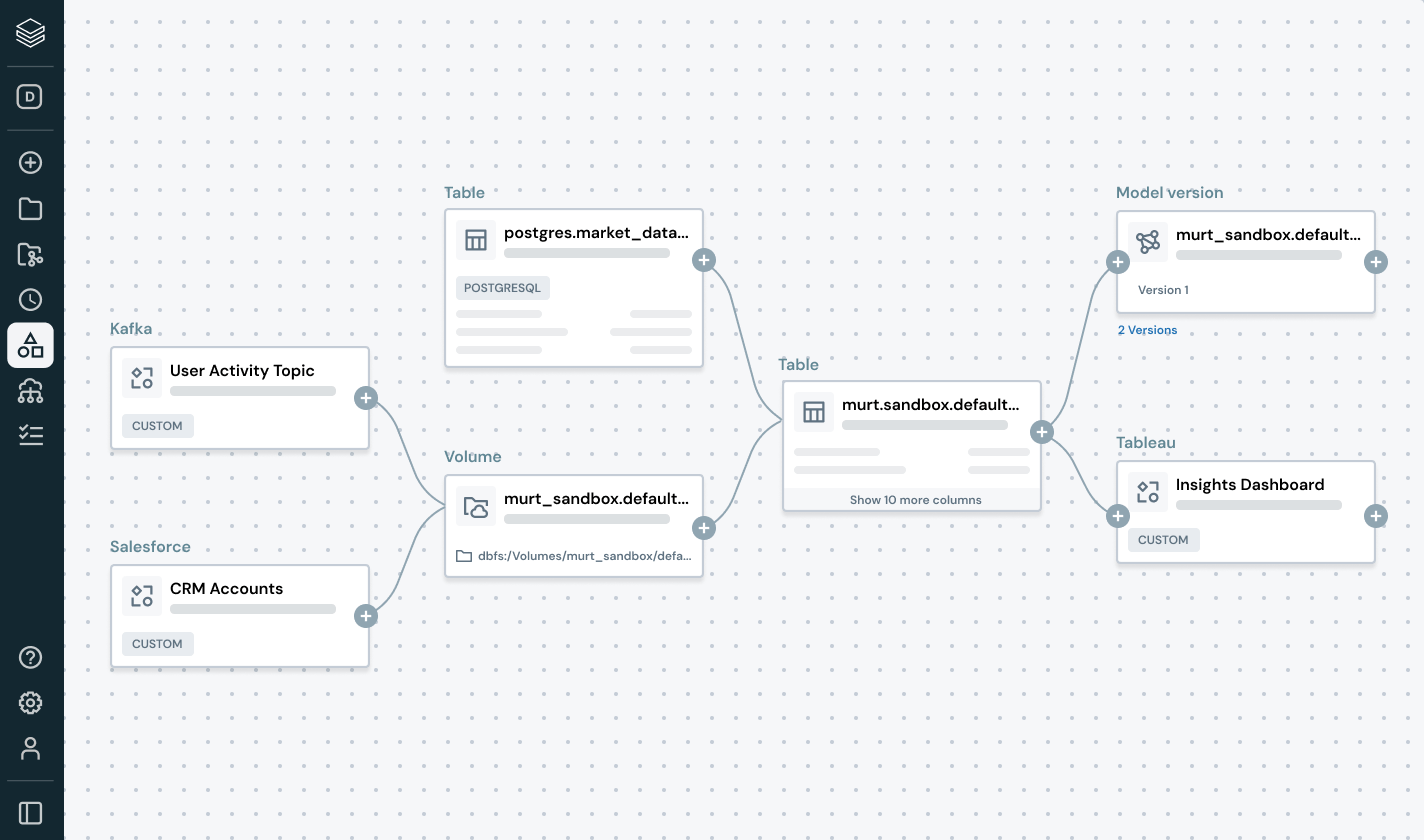
系統と品質信号の完全な可視性を持つことで、データ問題を積極的に検出し、解決します。
- データの健康状態を新鮮さ、完全性、異常検出で監視します
- パイプライン、モデル、ダッシュボード全体のエンドツーエンドの系譜を追跡
- 壊れたデータとAIパイプラインの下流への影響を評価します
- 各アセットとともに品質洞察を公開することで信頼を強化します
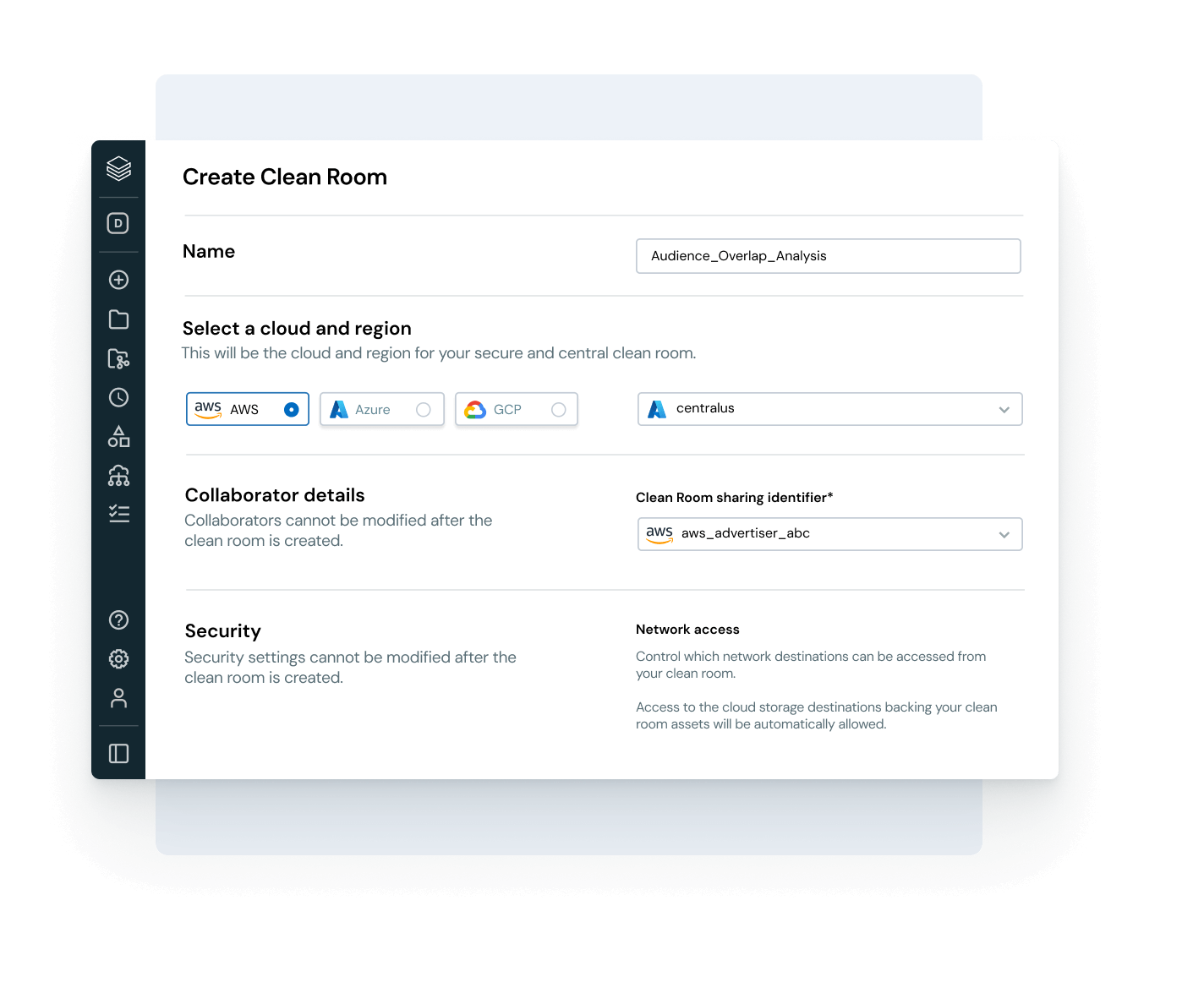
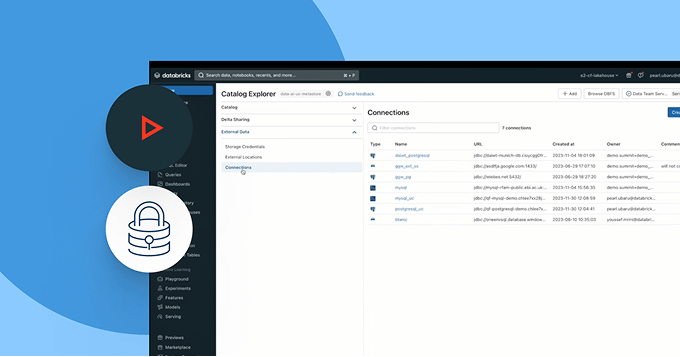
クラウドやパートナー間で安全でオープンなコラボレーションを可能にします
サイロを壊し、データとAIの共有をスケールします - 完全なガバナンス制御を持ちながら。
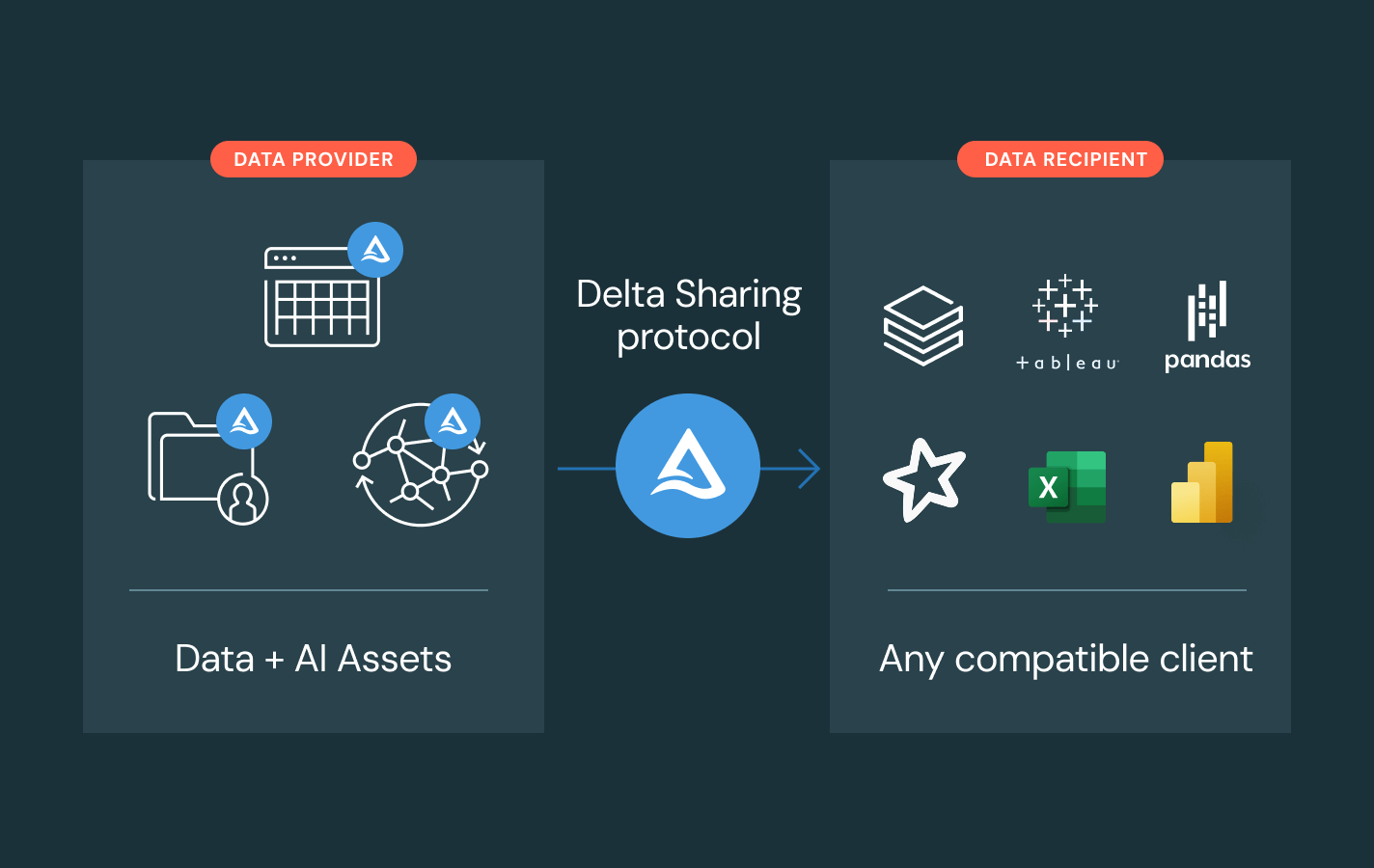
- Delta Sharingを使用して、チーム、クラウド、パートナー間でガバナンスされたデータとAI資産を共有します
- セキュアでプライバシーを保護したコラボレーションのためのClean Roomsを使用します
- 開放的な共有基準でベンダーロックインを避けます
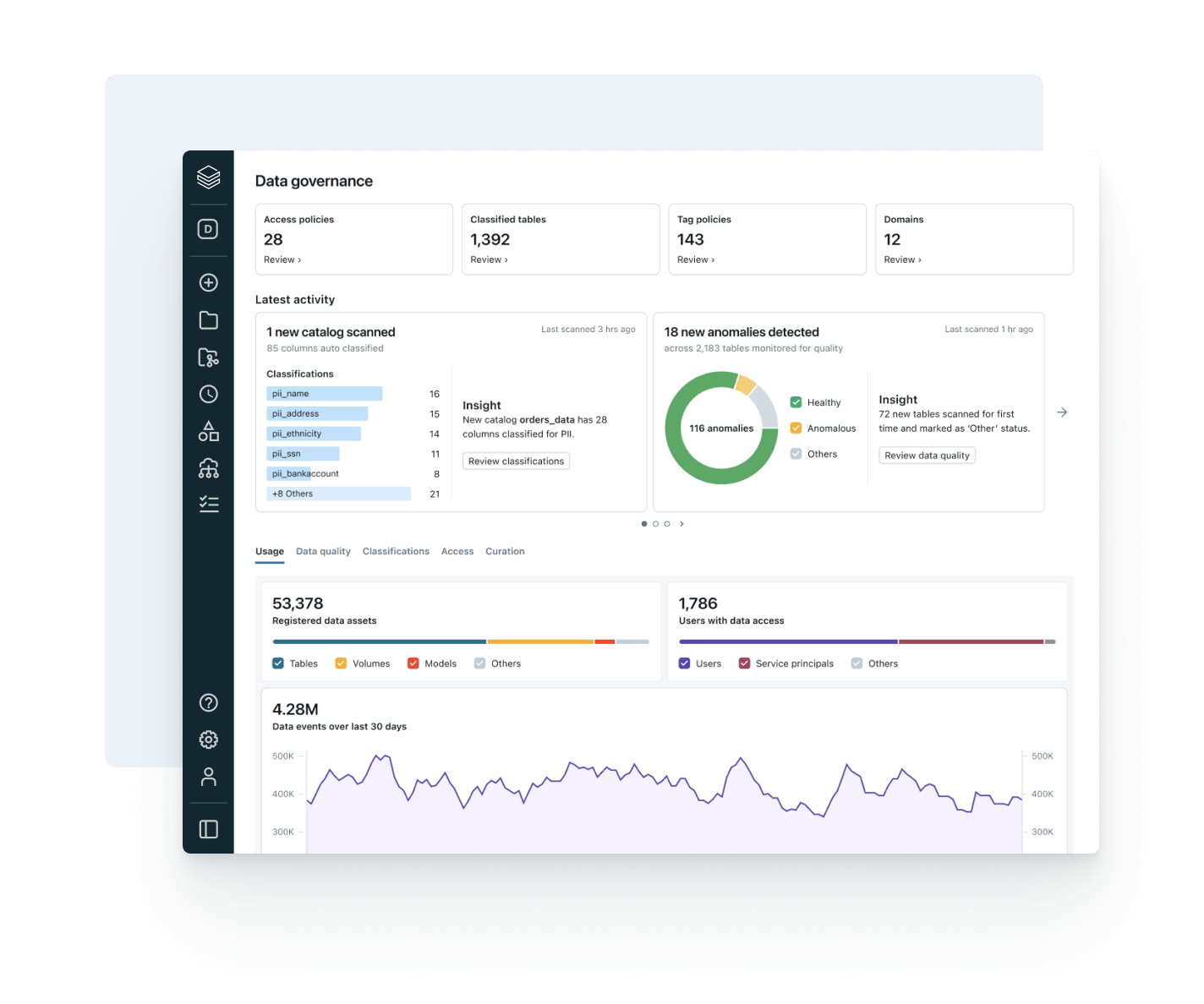
データの使用をビジネス価値と運用コストと一致させます
組み込みの観測性を使用して支出を最適化し、ガバナンスの採用を促進し、ROIを増加させます。
- ユーザー、チーム、ビジネスユニット間でのデータ消費の傾向を追跡します
- 系統を計算とストレージ使用にリンクし、最適化レバーを特定します
- 一つのUIでポリシーの採用とデータアクセスパターンを監視します
- データ製品オーナーがデータの価値を測定し、報告することを可能にします
Unity Catalogのデモを探索します

さらに詳しく
ガバナンス、コラボレーション、データインテリジェンスを通じてUnity Catalogの力を拡張する製品を探索します。
Databricks Clean Room
生のデータへの直接アクセスを提供せずに、複数のパーティからの共有データを分析します。

Databricks Marketplace
データ、AI、分析アセット(MLモデルやノートブックなど)のオープンマーケット。

Delta Sharing
プラットフォーム間でのデータとAIの共有に対するオープンソースのアプローチ。中央集権的なガバナンスとレプリケーションなしでライブデータを共有します。

AI/BI Genie
生成型AIによって駆動される会話型体験で、ビジネスチームがデータを探索し、リアルタイムで自己サービスの洞察を得るためのものです。

Databricks Assistant
タスクを自然言語で説明すると、Assistant が SQL クエリの生成、複雑なコードの説明、エラーの自動修正をします。
Databricks デ��ータ・インテリジェンス・プラットフォーム
Databricks データ・インテリジェンス・プラットフォームで利用可能なあらゆるツールを活用し、組織全体のデータと AI をシームレスに統合できます。



