Databricksでのインテリジェントなデータウェアハウジング - クローン
このリファレンスアーキテクチャは、Databricks Data Intelligence Platformが、統合されたレイクハウス上でストリーミングとバッチのデータ取り込み、ガバナンスの行き届いたストレージ、スケーラブルなSQLアナリティクス、統合されたAIを組み合わせることで、モダンなデータウェアハウジングとBIをどのように実現するかを示しています。
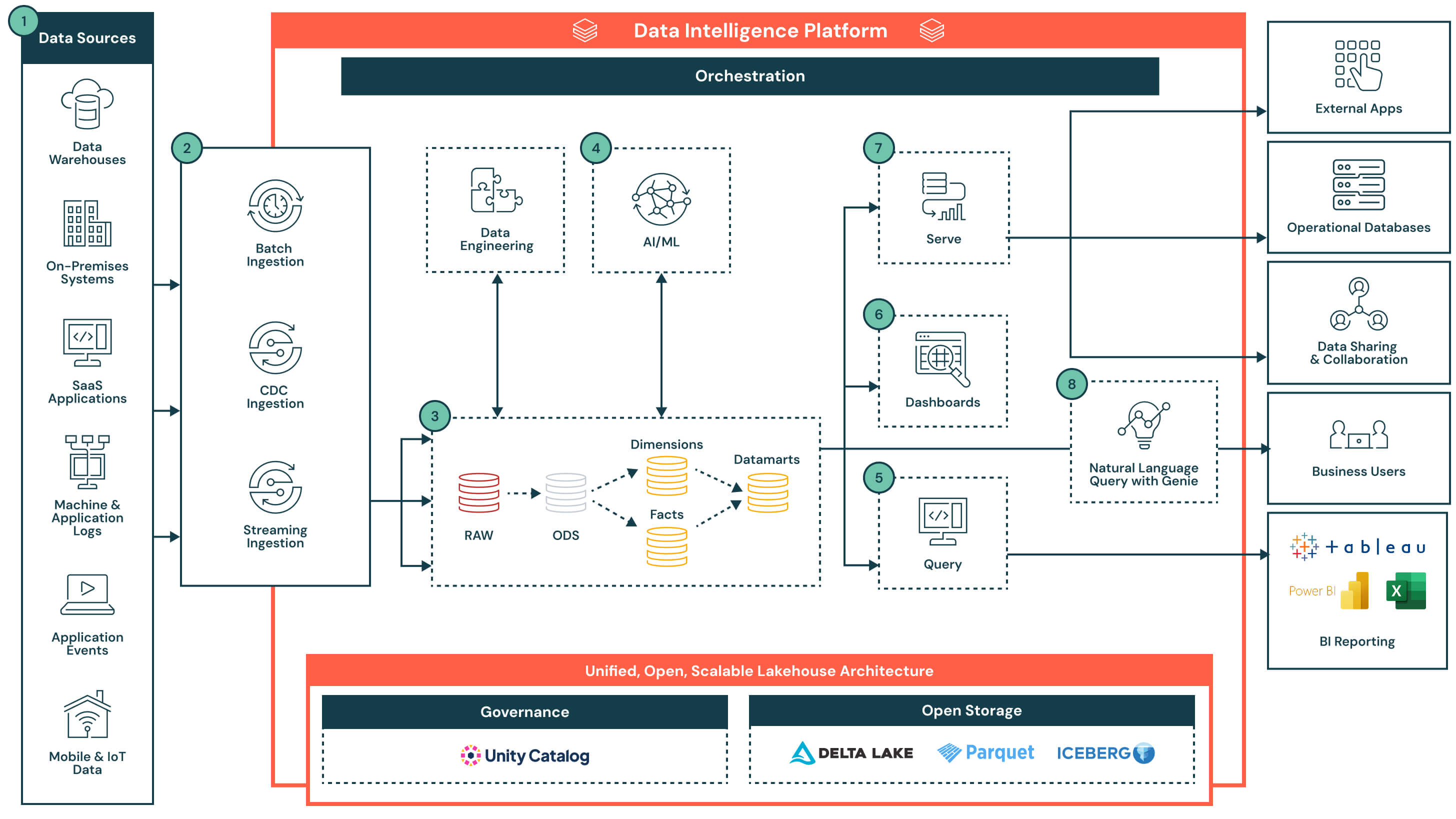
アーキテクチャの概要
このアーキテクチャは、セキュリティ、ガバナンス、パフォーマンスに関するエンタープライズ基準を満たしながら、従来のレポート作成、リアルタイムのダッシュボード、予測モデリング、セルフサービス分析をサポートします。
このソリューションは、Databricks Lakehouseを基盤とするDatabricks Data Intelligence Platformが、データチームとビジネス関係者の双方のニーズを満たしながら、組織のデータウェアハウス戦略の近代化をどのように支援するかを示しています。
このアーキテクチャは、Unity Catalogによって管理される、オープンでガバナンスの効いたレイクハウスから始まります。データは、稼働中のデータベース、SaaSアプリ、イベントストリーム、ファイルシステムなどのさまざまなシステムから取り込まれ、中央のストレージレイヤーに格納されます。プラットフォームのデータインテリジェンスは、ETLやSQL分析から、ダッシュボード、AIのユースケースに至るまで、あらゆる処理を強力にサポートします。SQL、BIツール、自然言語クエリによる柔軟なアクセスをサポートすることで、プラットフォームはデータプロダクトの提供を加速し、組織全体でインサイトを活用できるようにします。
ユースケース
技術的なユースケース
- 多様なソースからの構造化、非構造化、バッチ、ストリーミングデータの取り込み
- 堅牢な宣言型ETLパイプラインの構築
- メダリオンアーキテクチャを使用したファクト、ディメンション、データマートのモデリング
- レポート作成やダッシュボード表示のための高並列SQLクエリの実行
- 下流工程での利用に向けて、MLの出力をウェアハウスに直接統合
ビジネスユースケース
- 売上、業務、または顧客メトリクスに関するリアルタイムダッシュボードの提供
- Genieのような自然言語インターフェースを介したアドホックな探索の実現
- 需要予測や解約モデリングなどの予測ユースケースのサポート
- 部門間やパートナーとの間での、ガバナンスの効いたデータプロダクトの共有
- 財務、マーケティング、プロダクトチームへの、迅速で信頼性の高いインサイトの提供
データインテリジェンスによる主な機能
このアーキテクチャのデータインテリジェンスコンポーネントにより、プラットフォームはよりスマートで適応性が高くなり、さまざまなペルソナやワークロードで使いやすくなります。システム全体にAIとメタデータ認識を適用することで、エクスペリエンスをシンプルにし、意思決定を自動化します。
- 自然言語インターフェース(Genie): ビジネスコンテキストを理解し、ユーザーが日常の言葉でデータに関する質問を行えるようにします
- セマンティック認識: テーブル、列、使用パターンの間の関係を認識し、結合、フィルター、または計算を提案します
- 予測最適化: 過去のワークロードに基づいて、クエリのパフォーマンスとコンピュートの割り当てを継続的に調整します
- 統合ガバナンス: データ資産のタグ付け、分類、使用状況の追跡を行い、検出をより直感的かつ安全にします
- 主な機能: データとユーザーに適応する、自己最適化プラットフォーム
- 差別化要因: データインテリジェンスは、後から追加されたものではなく、取り込み、クエリ、ガバナンス、可視化の全体に組み込まれています
主な機能と差別化要因を備えたデータフロー
- データソース: データは、エンタープライズアプリケーション(SAP、Salesforceなど)、データベース、IoTデバイス、アプリケーションログ、外部APIなど、多種多様なシステムに保存されます。これらのソースは、構造化、半構造化、または非構造化データを生成します。
- データ取り込み: バッチジョブ、変更データキャプチャ(CDC)、またはストリーミングを介してデータを取り込みます。これらのパイプラインは、ソースシステムやユースケースに応じて、ほぼリアルタイムまたはスケジュールされた間隔でレイクハウスアーキテクチャにデータを供給します。
- 主な差別化要因: 個別のインフラストラクチャやパイプラインを必要とせず、バッチ、ストリーミング、CDCのすべてのモダリティに対応する統合された取り込み
- データ変換、ETL、宣言型パイプライン: 取り込まれたデータは、メダリオンアーキテクチャを通じて変換され、未加工データから精選されたデータへと段階的に洗練されます。
- RawゾーンからBronzeゾーン: 外部ソースシステムから取り込まれたデータ。このレイヤーの構造は、データの変換や更新を行うことなく、ソースシステムのテーブル構造を「そのまま」反映します。
- BronzeゾーンからSilverゾーン: 取り込まれたデータを標準化およびクレンジングします
- SilverゾーンからGoldゾーン: ビジネスロジックを適用して、再利用可能なモデルを作成します
- ファクトとディメンション → データマート: 下流の分析用にデータを集計および精選します
- 主な差別化要因: リネージ、オブザーバビリティ、スキーマ進化が組み込まれた、本番環境グレードの宣言型パイプライン
- AIユースケース向けに精選されたデータ: データマートから精選されたデータを使用して、機械学習モデルのトレーニングや適用を行うことができます。これらのモデルは、需要予測、異常検知、顧客スコアリングなどのユースケースをサポートします。
- モデルの出力は、従来のウェアハウスデータとともに保存されるため、SQLやダッシュボードを介して簡単にアクセスできます
- 要件に応じて、結果をスケジュールに従って更新したり、リアルタイムでスコアリングしたりできます
- 主な差別化要因: 分析ワークロードとAIワークロードを同じプラットフォーム上にコロケーション(併置)するため、データの移動は不要です。モデルの出力は、ネイティブでクエリ可能な、ガバナンスの効いた資産として扱われます。
- 組み込みのクエリ・エディタとクエリ履歴
- クエリは、データマートまたは強化されたモデル出力から、ガバナンスが効いた最新の結果を返します
- 主な差別化要因: Databricks Lakehouseを使用すると、BIツールからデータを直接クエリできるため(複製は不要)、複雑さが軽減され、追加のライセンスコストが不要になり、全体的なTCOを削減できます。サーバーレスコンピュートとインテリジェントな最適化を組み合わせることで、最小限のチューニングでデータウェアハウスクラスのパフォーマンスを実現します。
- 自然言語入力を使用したビジュアライゼーションの作成
- フィルターやドリルダウンを使用して、インタラクティブにダッシュボードを修正・探索
- Databricksワークスペース外のユーザーを含め、組織全体でダッシュボードを公開し、安全に共有
- 主な差別化要因: ガバナンスが効いたリアルタイムデータに基づいてダッシュボードを構築・探索するための、ローコードかつAI支援による体験を提供
- トランザクションの意思決定のために、下流のアプリケーションや運用データベースと共有
- 分析用のコラボレーティブなノートブックで使用
- 統合されたガバナンスのもと、Delta Sharingを介してパートナー、チーム、または外部のコンシューマーに配信
- ダッシュボードにあらかじめ組み込まれていない、アドホックでインタラクティブなリアルタイムの質問に対応
- 時間の経過とともに変化するビジネス用語やコンテキストにインテリジェントに適応
- Unity Catalogを介して、既存のデータガバナンスとアクセス制御を活用
- コンプライアンスと透明性のために、自然言語クエリの監査可能性と追跡可能性を提供
- 主な差別化要因: 変化するビジネスコンセプトに継続的に適応し、SQLの専門知識を必要とせずに、コンテキストを認識した正確な回答を提供
- ガバナンス: Unity Catalogは、すべてのワークロードにわたって、一元化されたアクセス制御、リネージ、監査、データ分類を提供します
- パフォーマンス: Photonエンジン、インテリジェントなキャッシュ、ワークロードを認識する最適化により、手動でのチューニングなしで高速なクエリを実現します
- オーケストレーション: 組み込みのオーケストレーションにより、バッチおよびストリーミングワークロード全体でデータパイプライン、AIワークフロー、スケジュールされたジョブを管理し、依存関係の管理とエラー処理をネイティブにサポートします
- オープンストレージ: データはオープンフォーマット(Delta Lake、Parquet、Iceberg)で保存されるため、ツール間の相互運用性、プラットフォーム間のポータビリティ、ベンダーロックインのない長期的な耐久性が実現します
- モニタリングと監査可能性: クエリのパフォーマンス、パイプラインの実行、ユーザーアクセスをエンドツーエンドで可視化し、管理とコスト管理を向上させます
- 主な差別化要因: プラットフォームレベルのサービスは、後から重ねられたものではなく統合されているため、すべてのデータワークフロー、クラウド、チームにわたって、ガバナンス、自動化、パフォーマンスが一貫して確保されます


