하둡에서 레이크하우스 아키텍처로 마이그레이션하기 위한 5가지 단계
작성자: 하쉬 나룰라
Hadoop에서 레이크하우스 아키텍처 와 같은 최신 클라우드 기반 아키텍처로 마이그레이션하는 결정은 기술적 결정이 아니라 비즈니스 결정입니다. 이전 블로그에서 저희는 모든 조직이 Hadoop과의 관계를 재평가해야 하는 이유를 자세히 살펴보았습니다. 기술, 데이터 및 비즈니스 부문의 이해관계자가 기업을 Hadoop에서 전환하기로 결정하면 실제 전환을 시작하기 전에 고려해야 할 몇 가지 고��려 사항 이 있습니다. 이번 블로그에서는 실제 마이그레이션 프로세스 자체에 대해 구체적으로 살펴보겠습니다. 성공적인 마이그레이션을 위한 주요 단계와 차세대 데이터 기반 혁신을 촉발하는 데 있어 레이크하우스 아키텍처가 수행하는 역할에 대해 알아봅니다.
마이그레이션 단계
솔직히 말해 봅시다. 마이그레이션은 결코 쉽지 않습니다. 하지만 마이그레이션은 부작용을 최소화하고 비즈니스 연속성을 보장하며 비용을 효과적으로 관리하도록 구성할 수 있습니다. 이를 위해 Hadoop 에서 마이그레이션을 다음 다섯 가지 주요 단계로 나누는 것을 제안합니다.
- 관리
- 데이터 마이그레이션
- 데이터 처리 중
- 보안 및 거버넌스
- SQL 및 BI 레이어
1단계: 관리
관리 관점에서 Hadoop의 몇 가지 필수 개념을 살펴보고, 이러한 개념이 Databricks와 어떻게 비교되고 대조되는지 알아보겠습니다.
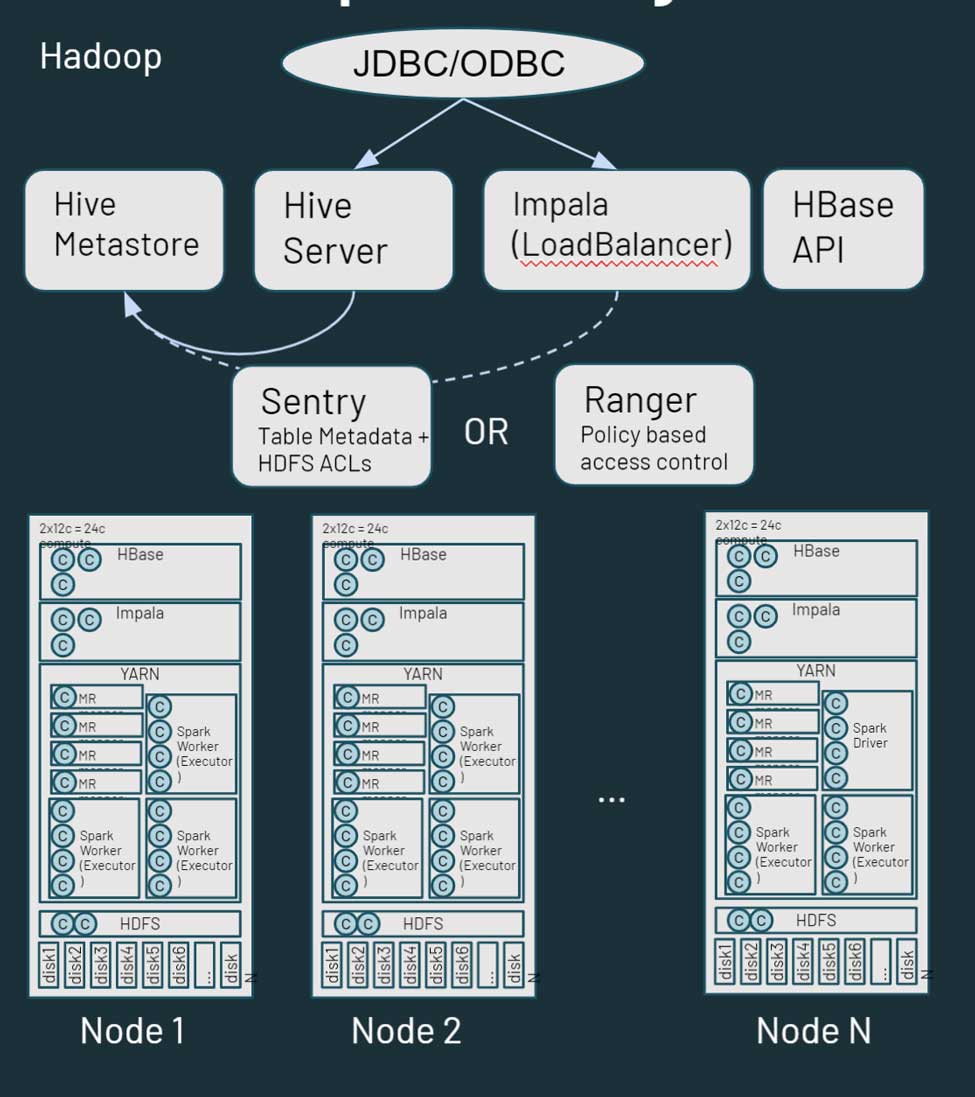
Hadoop은 본질적으로 단일형 분산 스토리지 및 컴퓨팅 플랫폼입니다. 여러 노드와 서버로 구성되며 각 노드와 서버는 자체 스토리지, CPU, 메모리를 갖추고 있습니다. 작업은 이 모든 노드에 분산됩니다. ��리소스 관리는 YARN을 통해 수행되며, YARN은 워크로드가 compute 공유량을 확보할 수 있도록 최선을 다합니다.
Hadoop은 메타데이터 정보도 포함합니다. HDFS에 저장된 자산에 대한 구조화된 정보를 포함하는 Hive metastore가 있습니다. Sentry 또는 Ranger를 활용하여 데이터에 대한 액세스를 제어할 수 있습니다. 데이터 액세스 관점에서 사용자와 애플리케이션은 HDFS(또는 해당 CLI/API)를 통해 직접 데이터에 액세스하거나 SQL 유형 인터페이스를 통해 액세스할 수 있습니다. 또한 SQL 인터페이스는 JDBC/ODBC 연결을 통해 일반 SQL(또는 경우에 따라 ETL 스크립트)용 Hive를 사용하거나 대화형 쿼리용 Hive on Impala 또는 Tez를 사용할 수 있습니다. Hadoop은 HBase API 및 관련 데이터 소스 서비스도 제공합니다. 하둡 에코시스템에 대한 자세한 내용은 여기를 참조하세요.
다음으로, 이러한 서비스가 Databricks Lakehouse Platform에서 어떻게 매핑되거나 처리되는지 논의해 보겠습니다. Databricks에서 가장 먼저 주목해야 할 차이점 중 하나는 Databricks 환경에서 여러 클러스터를 보게 된다는 것입니다. 각 클러스터는 특정 사용 사례, 특정 프로젝트, 비즈니스 단위, 팀 또는 개발 그룹에 사용될 수 있습니다. 더 중요한 것은 이러한 clusters가 일시적으로 사용되도록 설계되었다는 점입니다. 작업 클러스터의 경우, 클러스터 수명은 워크플로 기간 동안만 지속되도록 설계되었습니다. 워크플로가 실행되고 완료되면 환경이 자동으로 해체됩니다. 마찬가지로, 개발자 간에 컴퓨팅 환경이 공유되는 대화형 사용 사례의 경우, 이 환경을 업��무일 시작 시 가동하여 개발자들이 하루 종일 코드를 실행하도록 할 수 있습니다. 비활성 기간 동안 Databricks는 플랫폼에 내장된 (구성 가능한) 자동 종료 기능을 통해 자동으로 환경을 해체합니다.
Hadoop과 달리 Databricks는 HBase나 SOLR과 같은 데이터 스토리지 서비스를 제공하지 않습니다. 데이터는 객체 스토리지 내의 파일 스토리지에 저장됩니다. HBase 또는 SOLR과 같은 많은 서비스는 클라우드 내 대안 또는 동등한 기술을 제공합니다. 클라우드 네이티브 또는 ISV 솔루션일 수 있습니다.
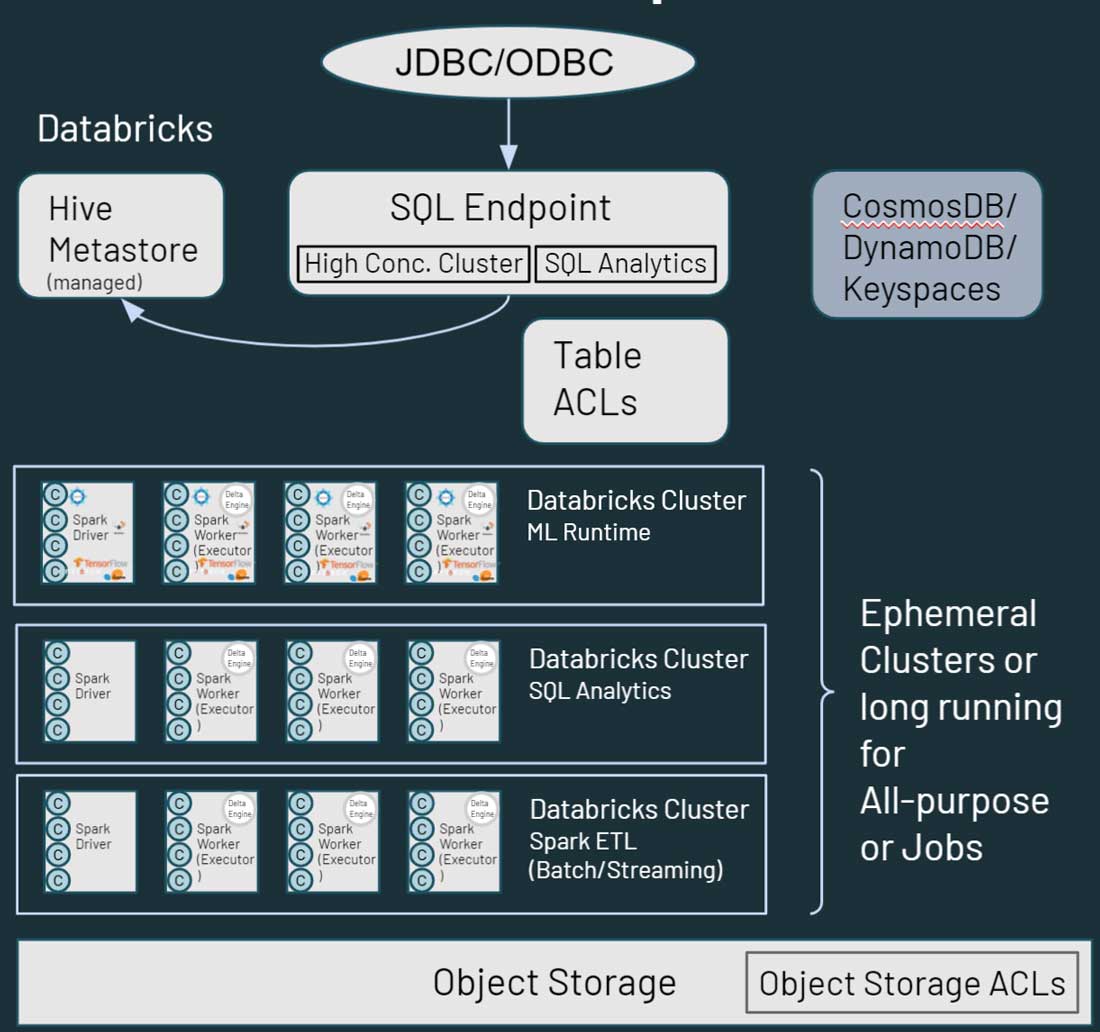
위 다이어그램에서 볼 수 있듯이 Databricks의 각 클러스터 노드는 Spark driver 또는 worker에 해당합니다. 여기서 핵심은 서로 다른 Databricks 클러스터가 서로 완전히 격리된다는 것입니다. 이를 통해 특정 프로젝트 및 사용 사례에 대해 엄격한 SLA를 충족할 수 있습니다. 스트리밍 또는 실시간 사용 사례를 다른 배치 지향 워크로드와 완전히 격리할 수 있으며, 오랫동안 클러스터 리소스를 독점할 수 있는 장기 실행 작업을 수동으로 격리하는 것에 대해 걱정할 필요가 없습니다. 다양한 사용 사례를 위한 컴퓨팅으로 새 클러스터를 바로 가동할 수 있습니다. 또한 Databricks는 스토리지와 컴퓨팅을 분리하고 AWS S3, Azure Blob Storage, Azure Data Lake Store(ADLS)와 같은 기존 클라우드 스토��리지를 활용하도록 지원합니다.
Databricks에는 클라우드 스토리지에 있는 데이터 자산에 대한 구조화된 정보를 저장하는 default 관리형 Hive metastore도 있습니다. 또한 AWS Glue, Azure SQL Server 또는 Azure Purview와 같은 외부 메타스토어 사용을 지원합니다. 객체 스토리지 권한뿐만 아니라 Databricks 내에서 테이블 ACL과 같은 보안 제어도 지정할 수 있습니다.
데이터 액세스 측면에서 Databricks는 사용자가 데이터와 상호 작용하는 방식에 있어 Hadoop과 유사한 기능을 제공합니다. 클라우드 스토리지에 저장된 데이터는 Databricks 환경에서 여러 경로를 통해 액세스할 수 있습니다. 사용자는 대화형 쿼리 및 분석을 위해 SQL Endpoints와 Databricks SQL을 사용할 수 있습니다. 또한 클라우드 스토리지에 저장된 데이터에 대한 데이터 엔지니어링 및 Machine Learning 기능을 위해 Databricks 노트북을 사용할 수도 있습니다. Hadoop의 HBase는 Azure CosmosDB 또는 AWS DynamoDB/Keyspaces에 매핑되며, 이는 다운스트림 애플리케이션을 위한 서빙 레이어로 활용될 수 있습니다.
2단계: 데이터 마이그레이션
Hadoop 배경 지식이 있으므로 대부분의 청중이 HDFS에 이미 익숙하다고 가정하겠습니다. HDFS는 Hadoop 배포에 사용되는 스토리지 파일 시스템으로 하둡 클러스터 노드의 디스크를 활용합니다. 따라서 HDFS를 확장할 때는 클러스터 전체에 용량을 추가해야 합니다(즉, compute와 스토리지를 함께 확장해야 합니다). 여기에는 추가 하드웨어의 조달 및 설치가 포함되는 경우 상당한 시간과 노력이 소요될 수 있습니다.
클라우드 내에서, AWS S3, Azure Data Lake Storage 또는 Blob Storage나 Google Storage와 같��은 클라우드 스토리지 형태로 거의 무한한 스토리지 용량을 사용할 수 있습니다. 유지 관리나 상태 확인이 필요 없으며, 배포되는 순간부터 기본 내장된 이중화와 높은 수준의 내구성 및 가용성을 제공합니다. 데이터를 마이그레이션하려면 네이티브 클라우드 서비스를 사용하는 것이 좋으며, 마이그레이션을 용이하게 해주는 여러 파트너/ISV가 있습니다.
그렇다면 어떻게 시작해야 할까요? 가장 일반적으로 권장되는 경로는 듀얼 수집 전략으로 start하는 것입니다(즉, 온프레미스 환경 외에 클라우드 스토리지에도 데이터를 업로드하는 피드를 추가하는 것입니다). 이렇게 하면 기존 설정에 영향을 주지 않고 클라우드 내에서 새로운 사용 사례(새로운 데이터 활용)를 시작할 수 있습니다. 조직 내 다른 그룹의 동의를 얻으려는 경우, 우선 이를 백업 전략으로 내세울 수 있습니다. HDFS는 엄청난 규모와 노력 때문에 전통적으로 백업이 어려웠기 때문에, 어쨌든 데이터를 클라우드에 백업하는 것은 생산적인 이니셔티브가 될 수 있습니다.
대부분의 경우 기존 데이터 전송 도구를 활용하여 피드를 분기하고 Hadoop뿐만 아니라 클라우드 스토리지에도 쓸 수 있습니다. 예를 들어, Informatica나 Talend와 같은 도구/프레임워크를 사용하여 Hadoop에 데이터를 처리하고 쓰는 경우, 추가 단계를 추가하여 클라우드 스토리지에 쓰도록 하는 것은 매우 쉽습니다. 일단 데이터가 클라우드 내에 있으면, 그 데이터를 다룰 수 있는 여러 가지 방법이 있습니다.
데이터 방향 측면에서 데이터는 온프레미스에서 클라우드로 가져오거나 온프레미스에서 클라우드로 푸시할 수 있습니다. 데이터를 클라우드로 푸시하는 데 활용할 수 있는 일부 도구로는 클��라우드 네이티브 솔루션(Azure Data Box, AWS Snow Family 등), DistCP(Hadoop 도구), 기타 타사 도구 및 사내 프레임워크가 있습니다. 푸시 옵션은 일반적으로 보안 팀으로부터 필요한 승인을 받는 것이 더 쉽습니다.
클라우드로 데이터를 가져오기 위해 클라우드에서 트리거되는 Spark/Kafka 스트리밍 또는 배치 수집 파이프라인을 사용할 수 있습니다. 배치의 경우 파일을 직접 수집하거나 JDBC 커넥터를 사용하여 관련 업스트림 기술 플랫폼에 연결하고 데이터를 가져올 수 있습니다. 물론 이를 위해 사용할 수 있는 타사 도구도 있습니다. 푸시 옵션은 두 가지 중 더 널리 받아들여지고 이해되는 옵션이므로 풀 접근 방식에 대해 좀 더 자세히 살펴보겠습니다.
가장 먼저 온프레미스 환경과 클라우드 간의 연결을 설정해야 합니다. 이는 인터넷 연결과 게이트웨이를 통해 달성할 수 있습니다. AWS Direct Connect, Azure ExpressRoute 등과 같은 전용 연결 옵션을 활용할 수도 있습니다. 경우에 따라 조직이 클라우드를 처음 사용하는 것이 아니라면, 이미 이 설정이 되어 있을 수 있으므로 Hadoop 마이그레이션 프로젝트에 재사용할 수 있습니다.
또 다른 고려 사항은 Hadoop 환경 내의 보안입니다. Kerberos 환경인 경우 Databricks 측에서 처리할 수 있습니다. 클러스터 startup 시 실행되는 Databricks 초기화 스크립트를 구성하여 필요한 Kerberos 클라이언트를 설치 및 구성하고, 클라우드 스토리지 위치에 저장된 krb5.conf 및 keytab 파일에 액세스한 다음, 최종적으로 kinit() 함수를 실행하면 Databricks 클러스터가 Hadoop 환경과 직접 상호 작용할 수 있습니다.
마지막으로 외부 공유 메타스토어도 필요합니다. Databricks에는 default로 배포되는 메타스토어 서비스가 있지만 외부 메�타스토어 사용도 지원합니다. 외부 메타스토어는 Hadoop과 Databricks에서 공유되며 온프레미스(Hadoop 환경) 또는 클라우드에 배포할 수 있습니다. 예를 들어, Hadoop에서 실행 중인 기존 ETL 프로세스가 있고 아직 Databricks로 마이그레이션할 수 없는 경우, 기존 온프레미스 메타스토어로 이 설정을 활용하여 Databricks가 Hadoop의 최종 큐레이팅된 데이터세트를 사용하도록 할 수 있습니다.
3단계: 데이터 처리
명심해야 할 주요 사항은 데이터 처리 관점에서 Databricks의 모든 것이 Apache Spark를 활용한다는 것입니다. MapReduce, Pig, Hive QL, Java와 같은 모든 Hadoop 프로그래밍 언어는 Pyspark, Scala, Spark SQL 또는 R을 통해 Spark에서 실행되도록 변환할 수 있습니다. 코드 및 IDE와 관련하여 Apache Zeppelin과 Jupyter Notebook을 모두 Databricks Notebook으로 변환할 수 있지만 Jupyter Notebook을 가져오는 것이 조금 더 쉽습니다. Zeppelin Notebook은 가져오기 전에 Jupyter 또는 Ipython으로 변환해야 합니다. 데이터 과학팀이 Zeppelin 또는 Jupyter에서 계속 코딩하기를 원한다면 Databricks Connect를 사용할 수 있습니다. 이를 통해 로컬 IDE(Jupyter, Zeppelin 또는 IntelliJ, VScode, RStudio 등)를 활용하여 Databricks에서 코드를 실행할 수 있습니다.
Apache Spark™ 작업을 마이그레이션할 때 가장 큰 고려 사항은 Spark 버전입니다. 온프레미스 하둡 클러스터에서 이전 버전의 Spark를 실행 중일 수 있습니다. Spark 마이그레이션 가이드 를 사용하여 변경 사항을 확인하고 코드에 미치는 영향을 파악할 수 있습니다. 고려해야 할 또 다른 사항은 RDD를 데이터프레임으로 변환하는 것입니다. RDD는 Spark 2.x 버전까지 흔히 사용되었으며 Spark 3.x에서도 계속 사용할 수 있지만, 그럴 경우 Spark 옵티마이저의 전체 기능을 활용하지 못할 수 있습니다. 가능한 한 RDD를 데이터프레임으로 변경하는 것을 권장합니다.
마지막으로, 마이그레이션 중에 고객에게서 흔히 발견되는 함정 중 하나는 로컬 Hadoop 환경에 대한 하드코딩된 참조입니다. 물론 이러한 참조는 업데이트해야 하며, 그렇지 않으면 새 설정에서 코드가 손상됩니다.
다음으로, 대부분 코드 재작성이 수반되는 비 Spark 워크로드 변환에 대해 이야기해 보겠습니다. MapReduce의 경우, 경우에 따라 Java 라이브러리 형태의 공유 로직을 사용하면 Spark에서 코드를 활용할 수 있습니다. 하지만 MapReduce가 아닌 Spark 환경에서 실행하려면 코드의 일부를 다시 작성해야 할 수도 있습니다. 새로운 환경에서는 JDBC 소스를 사용하여 (MapReduce 명령이 아닌) Spark 명령 집합을 실행하므로 Sqoop은 비교적 쉽게 마이그레이션할 수 있습니다. Sqoop에서 매개변수를 지정하는 것과 동일한 방식으로 Spark 코드에서 매개변수를 지정할 수 있습니다. Flume의 경우, 저희가 본 대부분의 사용 사례는 Kafka에서 데이터를 사용하고 HDFS에 쓰는 것과 관련이 있습니다. 이 작업은 Spark Streaming을 사용하여 쉽게 수행할 수 있습니다. Flume 마이그레이션의 주요 작업은 구성 파일 기반 접근 방식을 Spark에서 보다 프로그래밍적인 접근 방식으로 변환해야 한다는 것입니다. 마지막으로, Hadoop 외부에서 주로 드래그 앤 드롭 방식의 셀프 서비스 수집 도구로 사용되는 Nifi가 있습니다. Nifi는 클라우드에서도 활용할 수 있지만, 많은 고객이 클라우드로 마이그레이션하는 기회를 이용하여 Nifi를 클라우드에서 사용할 수 있는 다른 최신 도구로 대체하고 있습니다.
HiveQL을 마이그레이션하는 것은 아마도 모든 작업 중에서 가장 쉬운 작업일 것입니다. Hive와 Spark SQL 사이에는 높은 수준의 호환성이 있으므로 대부분의 쿼리는 Spark SQL에서 있는 그대로 실행할 수 있어야 합니다. HiveQL과 Spark SQL 사이에는 DDL에 약간의 사소한 변경 사항이 있습니다. 예를 들어 Spark SQL은 HiveQL의 "FORMAT" 절 대신 "USING" 절을 사용합니다. 코드를 Spark SQL 형식으로 변경하는 것이 좋습니다. 그러면 옵티마이저가 Databricks에서 코드에 대한 최상의 실행 계획을 준비할 수 있기 때문입니다. Hive SerDes 및 UDF를 계속 활용할 수 있으므로 HiveQL을 Databricks로 마이그레이션하는 것이 훨씬 쉬워집니다.
워크플로 오케스트레이션과 관련하여 작업 제출 방식의 잠재적인 변경 사항을 고려해야 합니다. Spark 제출 시맨틱을 계속 활용할 수 있지만, 더 빠르고 원활하게 통합되는 다른 옵션도 사용할 수 있습니다. Databricks 작업 및 Delta Live Tables를 활용하여 코드가 없는 ETL로 Oozie 작업을 대체하고 Databricks 내에서 엔드투엔드 데이터 파이프라인을 정의할 수 있습니다. 외부 처리 종속성이 포함된 워크플로의 경우 자동화/스케줄링을 위해 Apache Airflow, Azure Data Factory 등과 같은 기술에서 동등한 워크플로/파이프라인을 만들어야 합니다. Databricks의 REST API를 사용하면 거의 모든 스케줄링 플랫폼을 통합하고 Databricks와 함께 작동하도록 구성할 수 있습니다.
KnowledgeLens에서 만든 MLens라는 자동화된 도구도 있으며, 이 도구는 Hadoop에서 Databricks로 워크로드를 마이그레이션하는 데 도움이 될 수 있습니다. MLens는 일부 Hive 관련 특정 기능을 Spark SQL로 변환하는 것을 포함하여 PySpark 코드와 HiveQL을 마이그레이션하는 데 도움을 주어 Spark SQL 옵티마이저의 전체 기능과 성능상의 이점을 활용할 수 있도록 합니다. 또한 곧 Oozie 워크플로를 Airflow, Azure Data Factory 등으로 마이그레이션하는 것을 지원할 계획입니다.
4단계: 보안 및 거버넌스
보안 및 거버넌스에 대해 살펴보겠습니다. Hadoop 환경에는 Ambari나 Cloudera Manager, 또는 Impala나 Solr와 같은 관리 콘솔에 연결하기 위한 LDAP 통합 기능이 있습니다. Hadoop에는 또한 다른 서비스와의 인증에 사용되는 커버로스가 있습니다. 권한 부여 관점에서 Ranger와 Sentry는 가장 일반적으로 사용되는 도구입니다.
Databricks를 사용하면 SAML 2.0을 지원하는 모든 ID 공급자와 Single Sign On(SSO) 통합이 가능합니다. 여기에는 Azure Active Directory, Google Workspace SSO, AWS SSO 및 Microsoft Active Directory가 포함됩니다. 권한 부여를 위해 Databricks는 Databricks 개체에 대한 ACL(액세스 제어 목록)을 제공하며, 이를 통해 노트북, 작업, 클러스터와 같은 엔터티에 대한 권한을 설정할 수 있습니다. 데이터 권한 및 액세스 제어의 경우, 테이블 ACL 및 뷰를 정의하여 열 및 행 액세스를 제한하고, Databricks가 작업 공간 로그인 자격 증명을 스토리지 레이어(S3, ADLS, Blob Storage)로 전달하여 데이터 액세스 권한이 있는지 확인하는 자격 증명 통과와 같은 기능을 활용할 수 있습니다. 속성 기반 제어 또는 데이터 마스킹과 같은 기능이 필요한 경우 Immuta 및 Privacera와 같은 파트너 도구를 활용할 수 있습니다. 엔터프라이즈 거버넌스 관점에서 Databricks를 AWS Glue, Informatica Data Catalog, Alation 및 Collibra와 같은 엔터프라이즈 데이터 카탈로그에 연결할 수 있습니다.
5단계: SQL 및 BI 계층
�앞서 설명했듯이 Hadoop에는 임시 쿼리 및 분석뿐만 아니라 ETL을 수행하기 위한 인터페이스로 Hive와 Impala가 있습니다. Databricks에서는 Databricks SQL을 통해 유사한 기능을 사용할 수 있습니다. 또한 Databricks SQL은 Delta 엔진을 통해 최고의 성능을 제공하며 자동 확장 클러스터를 통해 동시성이 높은 사용 사례를 지원합니다. 델타 엔진에는 C++로 처음부터 새로 빌드된 새로운 MPP 엔진인 Photon도 포함되어 있으며, 데이터 수준과 명령어 수준 병렬 처리를 모두 활용하도록 벡터화되었습니다.
Databricks는 Tableau, PowerBI, Qlik, Looker와 같은 BI 도구와의 기본 통합은 물론 이러한 도구에서 활용할 수 있는 고도로 최적화된 JDBC/ODBC 커넥터를 제공합니다. 새로운 JDBC/ODBC 드라이버는 오버헤드가 매우 적고(1/4초), Apache Arrow를 사용하여 전송 속도가 50% 더 높으며, 훨씬 빠른 메타데이터 검색 작업을 지원하는 여러 메타데이터 작업도 제공합니다. Databricks는 PowerBI용 SSO도 지원하며, 다른 BI/대시보드 도구에 대한 SSO 지원도 곧 제공될 예정입니다.
Databricks는 위에서 언급한 노트북 환경 외에도 기본 내장된 SQL UX를 갖추고 있어, SQL 사용자에게 SQL 워크벤치, 간단한 대시보드 및 알림 기능을 갖춘 자신만의 렌즈를 제공합니다. 이를 통해 데이터를 데이터 웨어하우스나 다른 플랫폼으로 다운스트림으로 이동할 필요 없이 데이터 레이크 내의 데이터에 대해 SQL 기반 데이터 변환 및 탐색적 분석을 수행할 수 있습니다.
다음 단계
lakehouse 아키텍처와 같은 최신 클라우드 아키텍처로의 마이그레이션 여정을 고려할 때 기억해야 할 두 가지 사항이 있습니다.
- 이 여정에 주요 비즈니스 이해관계자들을 반드시 함께 참여시켜야 합니다. 이것은 기술 결정인 동시에 비즈니스 결정이기도 하므로, 비즈니스 이해관계자들이 이 여정과 그 최종 상태를 납득하도록 해야 합니다.
- 또한 여러분은 혼자가 아니며, Databricks와 파트너사 전반에 걸쳐 이 작업을 충분히 수행하여 반복 가능한 모범 사례를 구축하고 조직의 시간, 비용, 리소스를 절약하며 전반적인 스트레스를 줄여주는 숙련된 리소스가 있다는 점을 기억하십시오.
- Hadoop에서 Databricks로의 기술 마이그레이션 가이드 를 다운로드하여 단계별 지침, 노트북, 코드를 확인하고 마이그레이션을 시작하세요.
Databricks가 비즈니스 가치를 높이는 방법에 대해 자세히 알아보고 Hadoop 마이그레이션 계획을 시작하려면 www.databricks.com/solutions/migration을 방문하세요.

최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.