Databricks Lakehouse 기반 데이터 메시 구축, 2부
작성자: 베른하르트 월터, Sharon Richardson, Guillermo Schiava D'Albano, 파와릿 라오선타라, Amr Ali , 프랜 메디나 카스트로
지난 블로그 "Databricks Lakehouse와 Data Mesh"에서는 Databricks Lakehouse를 기반으로 한 Data Mesh를 소개했습니다. 이 블로그에서는 Databricks Lakehouse 기능이 아키텍처 관점에서 Data Mesh를 어떻게 지원하는지 살펴보겠습니다.
Data Mesh는 구매하는 기술이나 솔루션이 아니라 아키텍처 및 조직 패러다임입니다. 하지만 Data Mesh를 효과적으로 구현하려면 데이터 페르소나 간의 협업을 보장하고, 데이터 품질을 제공하며, 모든 데이터 및 AI 워크로드 전반에 걸쳐 상호 운용성과 생산성을 촉진하는 유연한 플랫폼이 필요합니다.
Databricks Lakehouse Platform의 기능이 이러한 요구 사항을 어떻게 충족하는지 살펴보겠습니다.
Data Mesh의 기본 구성 요소는 일반적으로 다음 구성 요소로 구성된 데이터 도메인입니다.
- 소스 데이터 (도메인 소유)
- 셀프 서비스 컴퓨팅 리소스 및 오케스트레이션 (Databricks Workspaces 내)
- 다른 팀 및 도메인에 제공되는 도메인 중심 데이터 제품
- 비즈니스 사용자가 소비할 준비가 된 인사이트
- 연합 컴퓨팅 거버넌스 정책 준수
아래 그림에 나와 있습니다.
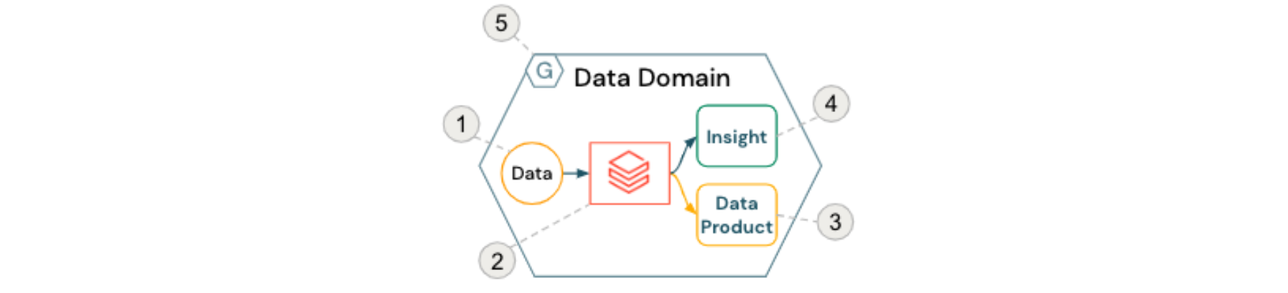
도메인 간 협업 및 셀프 서비스 분석을 촉진하기 위해 액세스 제어 메커니즘 및 데이터 카탈로깅과 같은 일반 서비스가 중앙에서 제공되는 경우가 많습니다. 예를 들어, Databricks Unity Catalog는 데이터 검색 및 계보와 같은 정보 카�탈로깅 기능뿐만 아니라 오늘날 많은 조직에서 원하는 세분화된 액세스 제어 및 감사 강제 기능을 제공합니다.
Data Mesh는 다양한 토폴로지로 배포될 수 있습니다. 최신 디지털 네이티브 기업 외부에서는 완전히 독립적인 도메인을 가진 고도로 분산된 Data Mesh는 일반적으로 권장되지 않습니다. 이는 도메인 팀이 비즈니스 로직과 고품질 데이터에 집중하는 것을 방해하고 복잡성과 오버헤드를 초래하기 때문입니다. 기업에서 자주 볼 수 있는 두 가지 인기 있는 예는 조화된 Data Mesh와 허브 앤 스포크 Data Mesh입니다.
1) 조화된 Data Mesh 접근 방식
조화된 데이터 메시는 도메인 내 자율성을 강조합니다.
- 데이터 도메인은 도메인별 데이터 제품을 생성하고 게시합니다.
- 데이터 검색은 Unity Catalog에서 자동으로 활성화됩니다.
- 데이터 제품은 피어 투 피어 방식으로 소비됩니다.
- 도메인 인프라는 다음을 통해 조화됩니다.
- 보안 및 규정 준수를 보장하는 플랫폼 청사진
- 셀프 서비스 플랫폼 서비스 (도메인 프로비저닝 자동화, 데이터 카탈로깅, 메타데이터 게시, 데이터 및 컴퓨팅 리소스에 대한 정책)
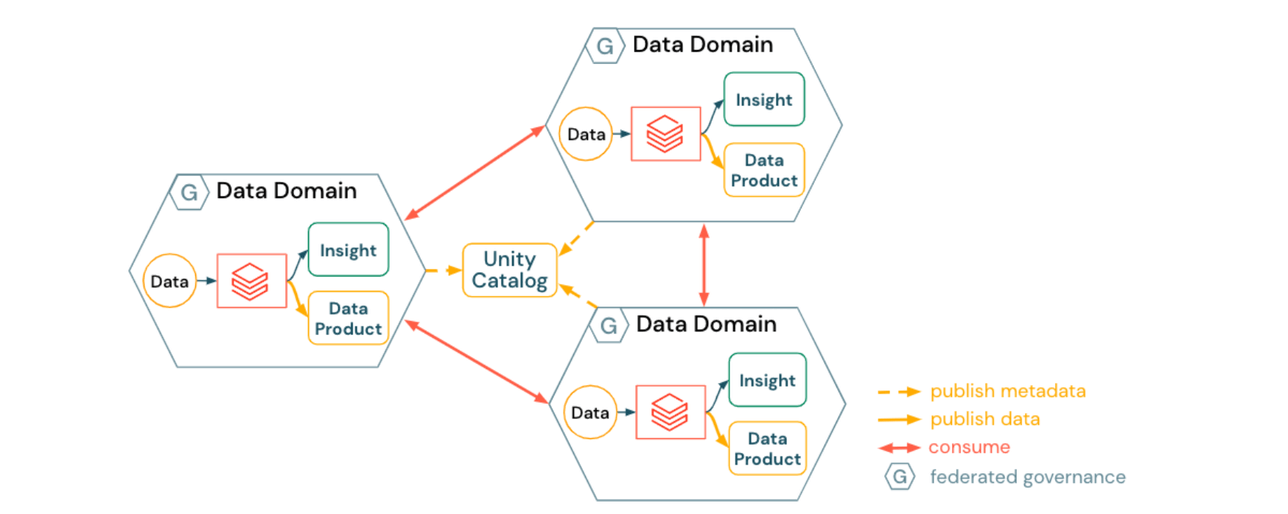
조화된 접근 방식의 영향은 다음과 같습니다.
- 각 데이터 도메인은 상호 운용성 및 인프라 관리를 위한 표준 및 모범 사례를 준수해야 합니�다.
- 각 데이터 도메인은 액세스 제어, 기본 스토리지 계정 또는 이벤트 브로커(스트리밍 데이터 제품용)와 같은 인프라와 같은 주제에 대해 더 많은 시간과 노력을 독립적으로 소비합니다.
이 접근 방식은 기술의 폭과 깊이가 다른 글로벌 조직에서 최신 모범 사례 및 정책을 완전히 동기화하는 데 어려움을 겪을 수 있으므로 어려울 수 있습니다.
2) 허브 앤 스포크 Data Mesh 접근 방식
허브 앤 스포크 Data Mesh는 공유 가능한 데이터 자산 및 단일 도메인에 논리적으로 속하지 않는 데이터를 관리하기 위한 중앙 집중식 위치를 통합합니다.
- 데이터 도메인(스포크)은 도메인별 데이터 제품을 생성합니다.
- 데이터 제품은 Unity Catalog에 등록된 대부분의 자산을 소유하고 관리하는 데이터 허브에 게시됩니다.
- 데이터 허브는 다음과 같은 데이터 도메인에 대한 일반 서비스 플랫폼 작업을 제공합니다.
- 관리되는 위치로의 셀프 서비스 데이터 게시
- Unity Catalog를 통한 데이터 카탈로깅, 계보, 감사 및 액세스 제어
- 시간 여행 및 GDPR 프로세스(도메인 전반)와 같은 데이터 관리 서비스 (예: 잊힐 권리 요청)
- 데이터 허브는 데이터 도메인으로도 작동할 수 있습니다. 예를 들어, 날씨, 시장 조사 또는 표준 거시 경제 데이터와 같은 일반 또는 외부에서 획득한 데이터 세트에 대한 파이프라인 또는 도구입니다.
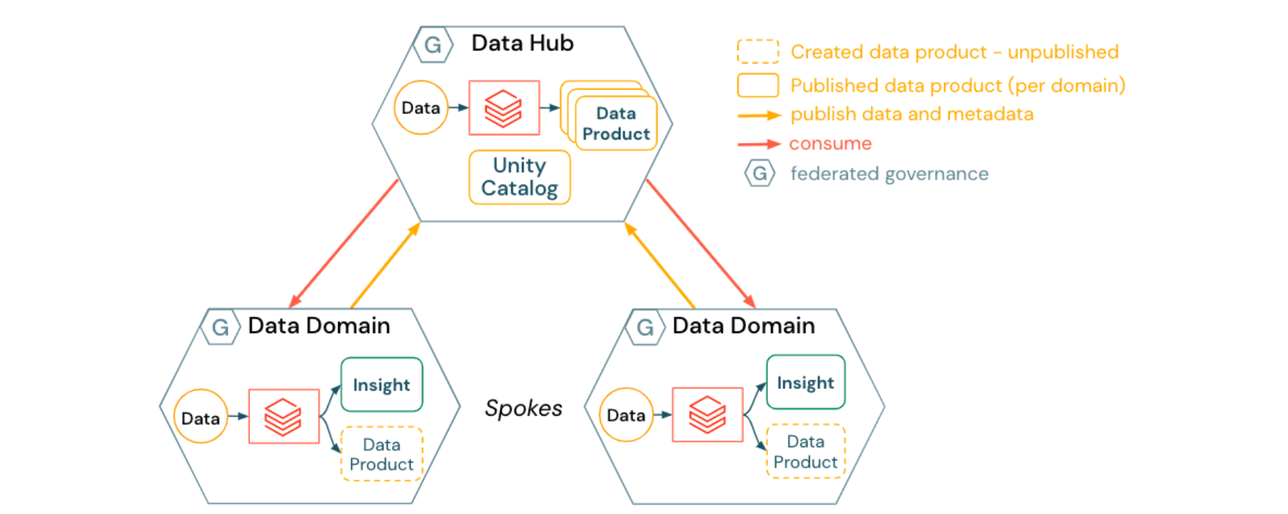
허브 앤 스포크 Data Mesh에 대한 영향은 다음과 같습니다.
- 데이터 도메인은 중앙에서 개발 및 배포된 데이터 서비스를 활용하여 비즈니스 및 데이터 변환 로직에 더 집중할 수 있습니다.
- 인프라 자동화 및 셀프 서비스 컴퓨팅은 데이터 허브 팀이 데이터 제품 게시의 병목 현상이 되는 것을 방지하는 데 도움이 될 수 있습니다.
이러한 접근 방식 모두에서 도메인은 다음과 같은 일반적이고 반복적인 요구 사항을 가질 수 있습니다.
- 데이터 수집 도구 및 커넥터
- MLOps 프레임워크, 템플릿 또는 모범 사례
- CI/CD, 데이터 품질 및 모니터링을 위한 파이프라인
우수 사례 센터와 같은 중앙 집중식 기술 및 전문 지식 풀을 보유하는 것은 도메인 전반에 걸쳐 일반적인 반복 활동과 각 도메인에서 사용할 수 없는 틈새 전문 지식이 필요한 비정기 활동 모두에 유익할 수 있습니다. 또한 완전한 조화된 데이터 메쉬와 허브 앤 스포크 모델 간에 약간의 변형이 있을 수 있습니다. 예를 들어, 논리적으로 단일 도메인에 속하지 않는 데이터 자산을 호스팅하고 여러 도메인에서 사용되는 외부에서 획득한 데이터를 관리하기 위한 최소한의 글로벌 데이터 허브를 갖는 것입니다. Unity Catalog는 Databricks 배포 내에서 데이터가 관리되는 모든 곳에서 인증된 데이터 검색을 제공하는 데 중요한 역할을 합니다.
Data Mesh 확장 및 발전
배포된 Data Mesh 논리 아키텍처의 유형에 관계없이 많은 조직은 클라우드 지역, 클라우드 공급자 및 법인에 걸쳐 운영 모델을 만드는 과제에 직면하게 될 것입니다. 또한 조직이 데이터 자산의 제품화(및 잠재적으로 수익화)로 발전함에 따라 엔터프라이즈급 상호 운용 가능한 데이터 공유는 내부 도메인 간의 협업뿐만 아니라 회사 간의 협업에도 여전히 중요합니다.
Delta Sharing은 다음과 같은 이점을 제공하는 이 문제에 대한 솔루션을 제공합니다.
- Delta Sharing은 조직, 지역 및 기술 경계를 넘어 도메인 간에 데이터 제품을 안전하게 공유하기 위한 개방형 프로토콜입니다.
- Delta Sharing 프로토콜은 공급업체에 구애받지 않으며(광범위한 클라이언트 생태계 포함), 동일한 기술 스택이나 클라우드 공급업체를 사용할 필요 없이 다른 도메인 또는 다른 회사 간의 다리 역할을 합니다.
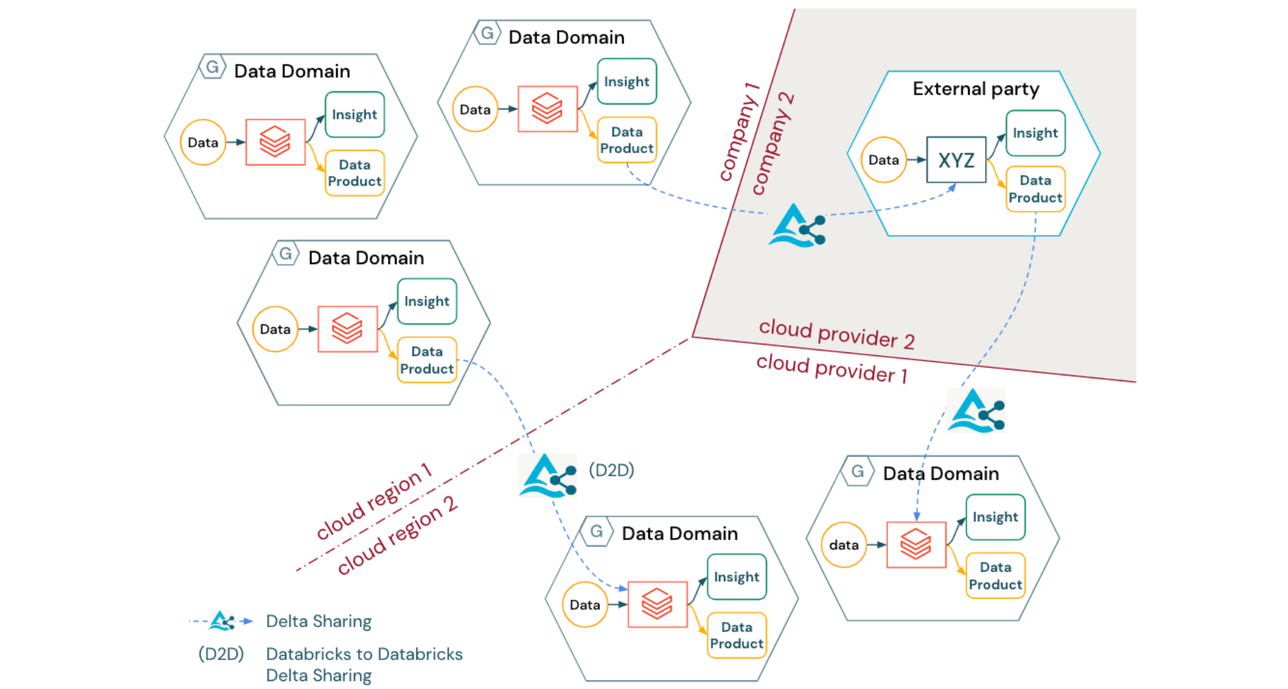
결론
Data Mesh와 Lakehouse는 모두 엔터프라이즈 데이터 웨어하우스 및 기존 데이터 레이크의 일반적인 문제점과 단점으로 인해 등장했습니다[1][2]. Data Mesh는 생산성과 데이터 가치를 개선하기 위한 비즈니스 비전과 요구 사항을 포괄적으로 설명하는 반면, Databricks Lakehouse는 최대 상호 운용성, 비용 효율성 및 단순성으로 이러한 요구 사항을 충족하기 위한 개방적이고 확장 가능한 기반을 제공합니다. 이 글에서는 연합 거버넌스를 지원하면서 협업과 생산성을 향상시키는 Databricks Lakehouse 플랫폼의 두 가지 예시 기능에 중점을 두었습니다.
- Unity Catalog는 Data Mesh에서 독립적인 데이터 게시, 중앙 집중식 데이터 검색 및 연합 컴퓨팅 거버넌스를 지원하는 기능입니다.
- Delta Sharing은 클라우드 및 지역 전반에 걸쳐 배포된 대규모의 전 세계적으로 분산된 조직을 위한 기능입니다. Delta Sharing은 복제 없이 도메인 간에 최신 데이터를 효율적이고 안전하게 공유합니다.
하지만 Databricks에는 Data Mesh 여정에서 다양한 사용자에게 유용한 기능이 많이 있습니다. 예를 들어:
- 배치 및 스트리밍 워크로드를 모두 지원하는 고품질 셀프 서비스 데이터 파이프라인을 위한 Workflows 및 Delta Live Tables
- 데이터 제품을 위한 여러 복사본/데이터 저장소를 유지 관리해야 하는 도메인 팀의 부담을 줄여주는 Lake에서 직접 성능 좋은 BI 및 SQL 쿼리를 지원하는 Databricks SQL
- 데이터 과학 및 머신러닝 팀 간의 공유 및 재사용을 촉진하는 Databricks Feature Store
Data Mesh를 위한 Lakehouse에 대해 자세히 알아보세요:
- Matei Zaharia: Data Mesh and Lakehouse
- Zalando & Thoughtworks: Data Lakehouse and Data Mesh—Two Sides of the Same Coin
- Databricks: Meshing About with Databricks
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.