8가지 데이터 레이아웃 오해 해부: Liquid Clustering이 파티셔닝보다 뛰어난 이유
현대적인 레이크하우스의 데이터 레이아웃
작성자: 제프리 공, Yu Xu , Rahul Mahadev
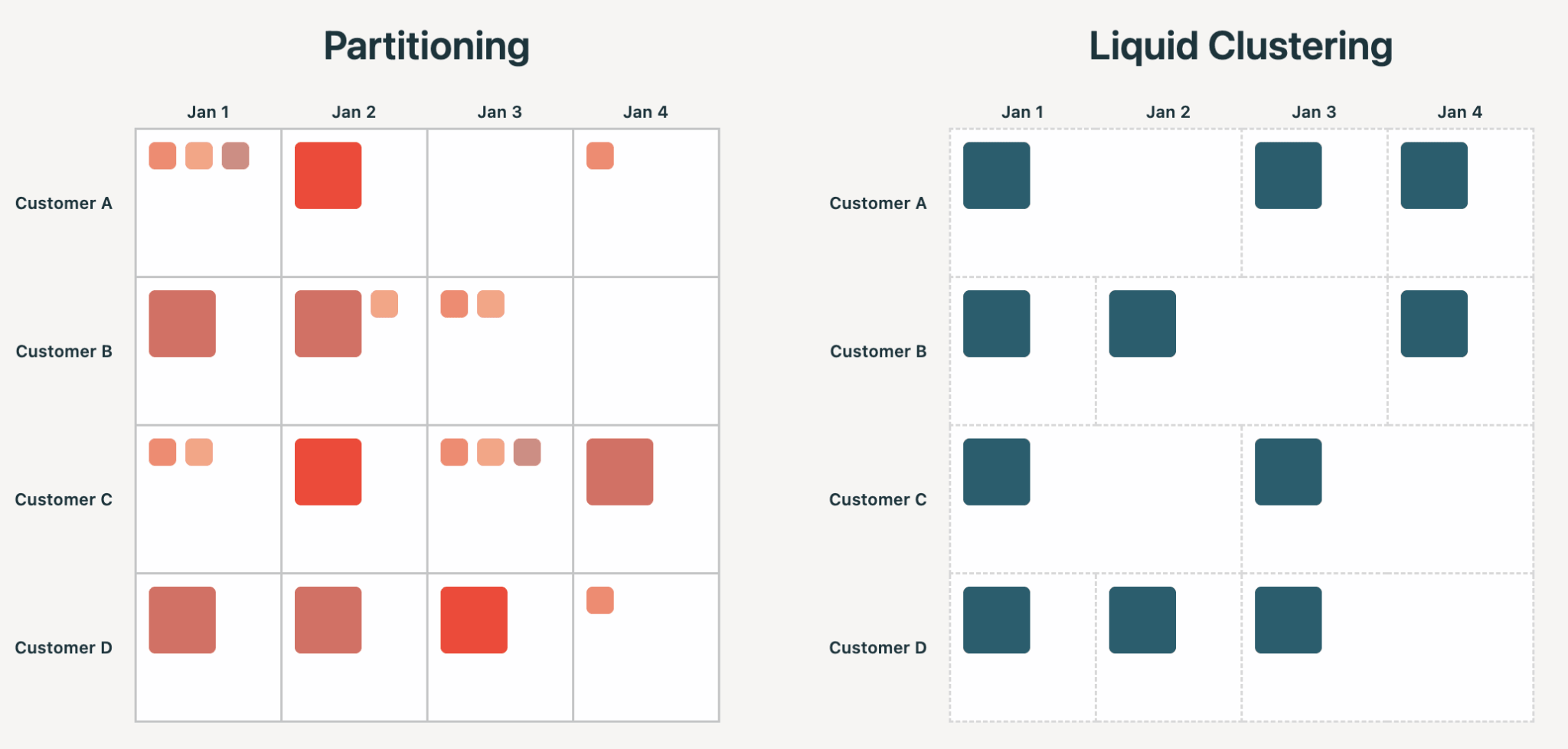
- Liquid Clustering은 파티셔닝의 한계를 피하면서 파티셔닝보다 뛰어난 성능을 발휘하는 개방형 테이블 형식의 데이터 레이아웃입니다.
- 8가지 일반적인 오해로 인해 팀이 파티셔닝에 얽매여 있지만, 더 이상 유효하지 않습니다.
- Liquid Clustering을 사용하는 고객들은 쿼리 지연 시간, 쓰기 처리량, 스토리지 효율성 및 데이터 최신성에서 극적인 개선을 보고했으며, 가장 큰 이점은 페타바이트 규모에서 복합적으로 나타납니다.
소개
데이터 레이아웃은 컴퓨팅에서 가장 오래된 문제 중 하나입니다.
15년 이상 Hadoop과 Hive가 등장한 이후 파티셔닝은 처리 및 분석을 위한 데이터의 물리적 구성 표준 방식이었습니다. 그러나 오늘날의 레이크하우스는 사람이 재파티셔닝하는 것보다 훨씬 빠르게 변화하는 에이전트, 실시간 파이프라인 및 쿼리 패턴을 처리합니다.
Liquid Clustering은 현대적인 표준이며, 고객들은 프로덕션 환경에서 페타바이트 규모의 테이블을 포함하여 모든 규모에서 이를 실행하고 있습니다. 이 블로그에서는 레이크하우스에서 Liquid Clustering이 왜 우수한지 살펴봅니다. 또한 일반적인 데이터 레이아웃에 대한 8가지 오해를 풀고, 파티셔닝된 테이블을 Liquid Clustering으로 전환한 팀의 성공 사례 3가지를 소개하며, 향후 출시될 기능을 미리 보고, 시작하는 방법을 보여드리겠습니다.
현대적인 레이크하우스에서 Liquid Clustering이 우수한 이유
Hive 스타일 파티셔닝은 사용자에게 테이블 생성 시점에 파일 구조에 반영되는 데이터의 물리적 구성에 대한 커밋을 강요합니다. 카디널리티가 너무 높은 열을 선택하면 수십억 개의 작은 파일이 생성됩니다. 잘못된 열을 선택하면 쿼리가 빨라지는 대신 느려질 수 있습니다. 어느 쪽이든 테이블을 다시 작성해야 합니다. 잘못 선택하는 경우가 많습니다. 저희 분석에 따르면 Hive 스타일 파티셔닝은 75% 이상의 경우 과도한 파티셔닝과 작은 파일 문제를 야기합니다.
Liquid는 클러스터링 키를 엔진이 최적의 파일 구성을 안내하는 데 사용하는 입력으로 취급합니다. 키는 언제든지 변경하거나 Automatic Liquid Clustering을 통해 지능적으로 선택할 수 있습니다. 카디널리티는 제약 조건이 아니며, 불필요한 재작성 없이 레이아웃을 시간이 지남에 따라 발전시킬 수 있습니다.
Liquid Clustering의 모든 이점은 위 원칙에서 파생됩니다. 더 나은 스큐 처리, 행 수준 동시성, 작은 파일 문제 없음, 다차원 클러스터링 및 낮은 쓰기 증폭입니다.
2026년에는 레이아웃이 테이블의 구현 세부 정보가 되어야 하며, 읽거나 쓰는 모든 엔진이 이를 활용해야 합니다. 에이전트가 레이크하우스에 진입하여 이전보다 더 많은 데이터를 생성하고 소비함에 따라 이는 점점 더 중요해지고 있습니다. 사람과 에이전트는 Hive 스타일 파티셔닝의 잠재적인 부작용이 없는 허용적인 인터페이스가 필요합니다.
일반적인 데이터 레이아웃에 대한 8가지 오해 풀기
Liquid Clustering은 2024년에 일반적으로 사용 가능해졌습니다. 그 이후로 고객들이 대규모로 실행하면서 지속적으로 개선해 왔습니다. 그동안 Liquid Clustering 및 파티셔닝에 대한 몇 가지 일반적인 오해가 지속되어 왔으며, 오늘 이를 풀고자 합니다.
오해 #1: 파티셔닝은 디렉토리를 파일 대신 건너뛸 수 있으므로 더 빠르다
오해 내용: 파티셔닝을 사용하면 Spark 또는 다른 엔진이 내부의 어떤 파일도 열지 않고 전체 디렉토리를 건너뛸 수 있습니다.
현실: 디렉토리 건너뛰기는 Delta 및 Iceberg와 같은 최신 오픈 테이블 형식에서는 존재하지 않습니다. 예를 들어 Delta는 모든 데이터 파일과 열별 통계를 추적하는 트랜잭션 로그를 사용하며, 건너뛰기는 디렉토리 구조가 아닌 해당 통계에 대해 수행됩니다. 엔진은 쿼리 계획을 위해 디렉토리를 나열하지 않습니다. 트랜잭션 로그를 읽고, 통계에 대해 필터를 평가하고, 일치하지 않는 파일을 건너뜁니다. Liquid Clustering도 동일한 메커니즘을 사용합니다. 데이터가 `date=x/hour=y/`에 있든 클러스터링된 파일의 평면 디렉토리에 있든 엔진은 파일 단위로 건너뜁니다. 잃어버릴 디렉토리 수준의 바로가기는 없습니다.
오해 #2: 낮은 카디널리티 열에서 필터링할 때 파티셔닝이 더 좋다
오해 내용: 고유 값이 적은 열의 경우 파티셔닝은 완벽한 데이터 분리와 좋은 파일 크기를 제공합니다.
현실: Liquid Clustering은 낮은 카디널리티 최적화를 적용해야 할 때를 자동으로 감지합니다. 예를 들어 (date, user_id)로 클러스터링하고 date의 카디널리티가 낮으면 시스템은 각 파일이 단일 날짜의 행만 포함하도록 합니다. 그런 다음 Z-Ordering과 같은 다른 정렬 기술에 의존할 필요 없이 user_id와 같은 더 높은 카디널리티 열은 각 날짜의 파일 내에서 더 세분화된 정렬에 자동으로 사용됩니다.
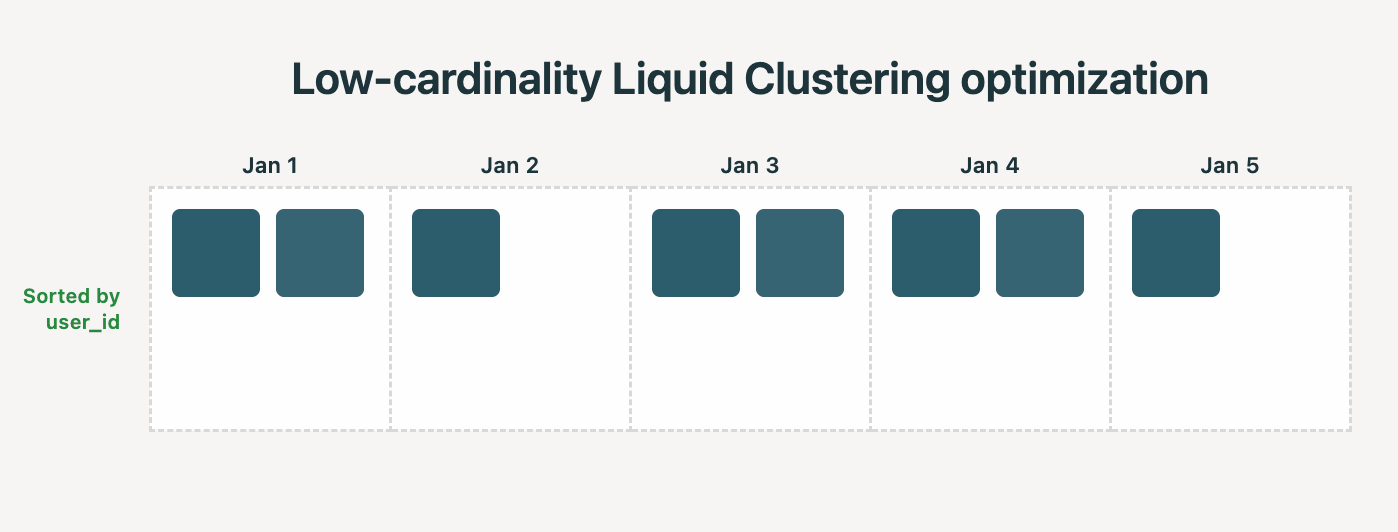
실제 데이터 웨어하우징 벤치마크에서 이 Liquid 최적화를 벤치마킹하는 동안 다음과 같은 개선 사항을 확인했습니다. 클러스터링 시간 35% 감소 및 쿼리 시간 22% 단축.
또한 Liquid Clustering은 높은 카디널리티 열에서 클러스터링할 때 파티셔닝보다 더 나은 성능을 내도록 설계되었으며, 항상 좋은 크기의 파일을 생성하려고 합니다.
오해 #3: Liquid Clustering은 메타데이터 전용 작업을 지원하지 않는다
오해 내용: 메타데이터 전용 작업은 파티셔닝을 통해서만 고유하게 지원됩니다. 파티션 경계와 일치하는 DELETE는 테이블 메타데이터만 업데이트하고, 파티션 열에 대한 집계는 파일을 스캔하지 않고 계산할 수 있습니다. Liquid Clustering은 동일한 작업을 수행할 수 없습니다.
현실: Liquid Clustering은 DELETE, COUNT, DISTINCT 및 GROUP BY 쿼리를 포함한 메타데이터 전용 작업도 지원합니다. 엔진은 데이터 건너뛰기에 사용하는 것과 동일한 파일별 min/max 통계를 사용하여 쿼리 답변이 메타데이터만으로 계산될 수 있는지 여부를 결정합니다. 벤치마크에서 Liquid Clustering된 테이블에 대한 메타데이터 전용 DELETE는 전체 재작성 DELETE보다 ~90% 더 빠르게 실행되었습니다. 다른 메타데이터 전용 집계 쿼리는 최대 27배의 속도 향상을 보였습니다.
오해 #4: Liquid Clustering은 페타바이트 규모에서 잘 작동하지 않는다
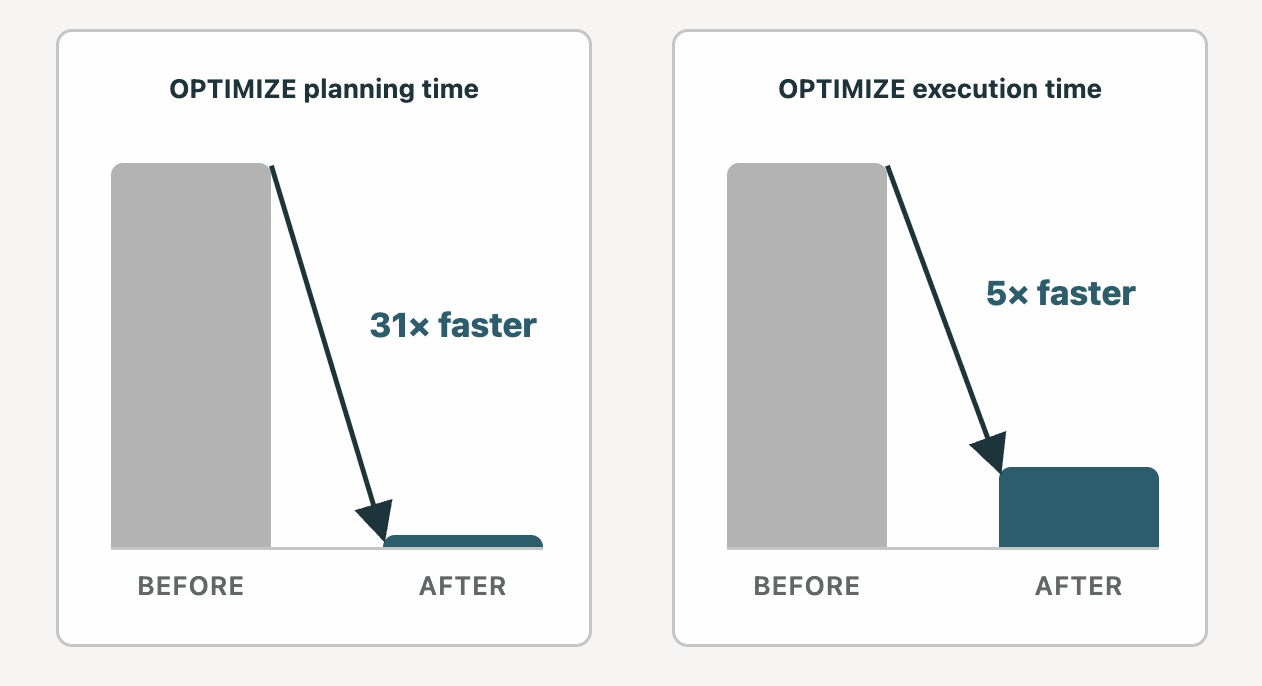
오해 내용: PB 규모 테이블에 대한 OPTIMIZE는 몇 시간 동안 실행될 수 있으며 유지 관리 비용이 너무 높습니다.
현실: OPTIMIZE에 상당한 개선을 이루었으며, 수십 개의 고객�이 프로덕션에서 PB 규모의 Liquid Clustering된 테이블을 보유하고 있습니다. 2년 전에는 OPTIMIZE의 첫 번째 단계인 계획이 경우에 따라 10 PB Liquid 테이블에서 최대 12시간이 걸릴 수 있었습니다. 그 이후로 계획 시간을 23분으로 단축했습니다. OPTIMIZE의 두 번째 단계인 실행은 Medium DBSQL 클러스터에서 5배 더 빨라졌습니다.
오해 #5: Liquid Clustering은 일부 독자에게만 이점을 제공한다
오해 내용: Liquid Clustering은 UC 관리 Delta 테이블을 읽는 Databricks 독자에게만 유용합니다.
현실: Liquid Clustering은 쓰기 측면의 최적화입니다. 엔진이 효율적인 데이터 건너뛰기를 위해 파일을 구성하는 방식입니다. 출력은 Delta/Iceberg와 같은 오픈 테이블 형식으로 작성된 min/max 통계가 포함된 표준 Parquet 파일입니다. 호환되는 모든 독자(예: 오픈 소스 Apache Spark, DuckDB 등)는 해당 통계를 사용하여 파일을 건너뛸 수 있습니다. Liquid Clustering은 외부/관리 및 Delta/ Iceberg 테이블 모두에서 사용할 수 있으며, 독자와 관계없이 이점을 적용할 수 있습니다.
오해 #6: 동시 ETL에는 파티셔닝이 필요하다
오해 내용: 동시 ETL에는 쓰기 경계가 필요합니다. 파티셔닝 없이는 동일한 테이블을 업데이트하는 두 작성자가 충돌할 위험이 있으며, Delta/Iceberg 동시성 제어는 둘 중 하나를 재시도하거나 실패하게 만듭니다. 파티션을 나누고 각 작성자에게 테이블의 자체 슬라이스를 제공하여 두 파이프라인이 동일한 파일을 건드리지 않도록 합니다.
현실: 파티션 단위로 작동하는 것은 이전 동시성 모델에 대한 해결책이었습니다. 파일 수준 동시성만 있는 파티셔닝과 달리 Liquid는 행 수준 동시성을 제공합니다. 서로 다른 행을 업데이트하는 두 작성자는 해당 행이 동일한 파일에 있더라도 더 이상 충돌하지 않습니다. 이는 팀이 직렬화를 피하기 위해 쓰기 경계를 유지하기 위해 테이블을 파티셔닝하는 주요 이유 중 하나를 제거합니다. Liquid Clustering을 사용하면 ETL이 동일한 테이블에 대해 쉽게 동시적으로 작동할 수 있습니다.
신화 #7: Z-Ordering은 파티셔닝의 단점을 보완합니다
신화는 이렇습니다: 파티셔닝은 파티션 열의 필터를 처리하고, Z-Ordering은 나머지를 처리합니다. OPTIMIZE ZORDER BY를 실행하면 엔진은 파티션 구성과 일치하지 않는 필터에 대한 최적의 건너뛰기를 위해 데이터를 정렬합니다.
현실: Z-Ordering은 파티셔닝을 구하지 못합니다. 실제로 자체적인 구조적 문제가 있습니다.
- 첫 번째는 낮은 클러스터링 품질입니다. Z-Order는 테이블 전체에 걸쳐 실제 순서를 유지하지 않습니다. 동일한 열의 값이 여러 파일에 분산될 수 있으므로 파일당 최소/최대 범위가 더 넓어지고 쿼리는 Liquid를 사용할 때보다 적은 파일을 건너뜁니다.
- 두 번째는 불필요한 재작성입니다. Z-Order는 새 데이터가 들어올 때 주기적으로 다시 실행해야 하며, 각 재실행은 클러스터링 품질을 복원하기 위해 많은 양의 이전 데이터(이미 클러스터링되었을 수 있음)를 다시 작성합니다. 지속�적인 수집으로 Z-Order를 사용하여 데이터를 잘 클러스터링된 상태로 유지하는 비용은 테이블과 함께 증가합니다.
Liquid는 쓰기 시점을 포함하여 점진적으로 클러스터링하므로 불필요한 재작성 없이 레이아웃이 최적으로 유지됩니다.
신화 #8: 파티셔닝은 선택적 데이터 덮어쓰기에 필요합니다
신화는 이렇습니다: 데이터를 선택적으로 덮어쓰는 기능은 동적 파티션 덮어쓰기를 통해서만 사용할 수 있습니다.
현실: 선택적 덮어쓰기는 Liquid 테이블에서 기본적으로 작동합니다. Databricks는 REPLACE USING 및 REPLACE ON을 지원하며, 이는 Liquid 클러스터링, 파티셔닝 또는 일반 비클러스터링 테이블의 모든 데이터 레이아웃에서 데이터를 선택적으로 덮어쓰기 위한 두 가지 SQL 구문입니다. Spark 구성을 요구하는 동적 파티션 덮어쓰기와 달리 REPLACE USING 및 REPLACE ON은 클래식 클러스터, SQL 웨어하우스 및 서버리스를 포함한 모든 컴퓨팅에서 사용할 수 있습니다. 작업은 원자적이며 선택한 모든 열과 일치합니다.
성공 사례: 파티셔닝에서 Liquid Clustering으로 마이그레이션
Arctic Wolf의 3.8 PB 보안 원격 분석 테이블에서 7.7배 쿼리 속도 향상
Arctic Wolf는 하루에 1조 개 이상의 이벤트를 수집하는 3.8 PB 이상의 보안 원격 분석 테이블을 실행하며, 위협 헌터는 최신 데이터에 의존하여 활성 공격을 탐지합니다.
Predictive Optimization을 사용하여 Unity Catalog 관리 테이블에서 파티셔닝에서 Liquid Clustering으로 마이그레이션한 후 Arctic Wolf는 다음과 같은 결과를 보았습니다.
- 90일 쿼리가 51초에서 6.6초로 감소
- 파일 수가 4백만 개에서 2백만 개로 감소
- 데이터 최신성이 몇 시간에서 몇 분으로 개선
Bolt의 중요 CDC 테이블에 대한 읽기 및 쓰기 성능 향상
Bolt는 최근 파티셔닝된 테이블을 ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY를 사용하여 인플레이스로 Liquid로 변환하는 Liquid Conversion(현재 비공개 미리 보기)을 시도했습니다. TB 규모의 CDC 테이블에서 Liquid Clustering으로 변환한 후 다음과 같은 읽기 및 쓰기 이점을 관찰했습니다.
- 쓰기 처리량(초당 행 수)이 138% 증가
- 읽기 시간이 최대 63% 감소했으며, 9개의 대표 쿼리에서 평균 21% 감소
Liquid Clustering은 각 쓰기가 수행하는 작업을 크게 줄여 가장 중요한 CDC 테이블의 처리량을 크게 늘렸습니다. 읽기 성능도 전반적으로 향상되었습니다. 가장 좋은 점은 파티셔닝에서 변환을 실시간 수집과 함께 제로 다운타임으로 실행했다는 것입니다. 이를 통해 Liquid Clustering은 플랫폼 규모에서 필요한 성능과 안정성을 정확히 제공했습니다. —Bolt의 선임 플랫폼 엔지니어인 Marcin
페타바이트 규모의 내부 워크로드에서 5.9배 쿼리 시간 단축
내부적으로 1.1 PB 테이블을 실행하며, 이 테이블은 하루에 수천 번 쿼리되며 대부분 엔지니어가 프로덕션 조사 및 관찰 가능성 대시보드를 실행하는 데 사용됩니다. 원래는 시간 범위 스캔이 지배적일 것이라는 가정 하에 date와 hour로 파티셔닝되었습니다. 그러나 그 가정은 불완전한 것으로 밝혀졌습니다. 시간 범위 스캔이 일반적이었지만, 테이블은 source 및 id로도 자주 쿼리되어 엔진이 관련 날짜 및 시간 파티션의 모든 파일을 스캔하여 몇 개의 행을 찾아야 했습니다.
source와 id를 파티션으로 추가하는 것은 구별되는 값이 너무 많기 때문에 실현 가능하지 않았습니다. 이렇게 하면 수십억 개의 작은 파일이 생성되었을 것입니다. Liquid Clustering은 이러한 절충을 제거하여 시간 및 추가 식별자 열을 동시에 클러스터링할 수 있도록 하면서도 좋은 파일 크기를 유지했습니다.
| 레이아웃 | |
|---|---|
| 이전 | date, hour로 파티셔닝됨 |
| 이후 | date, hour, source, id으로 클러스터링됨 |
벤치마크 결과 16개의 대표적인 프로덕션 쿼리에서 상당한 성능 향상이 나타났습니다:
| 메트릭 | 이전 (파티셔닝됨) | 이후 (Liquid) | 개선 사항 |
|---|---|---|---|
| 실행 시간 | 406초 | 70초 | 5.9배 속도 향상 |
| 읽은 바이트 수 | 3.5 TB | 0.48 TB | 86% 적은 바이트 읽음 |
테이블 자체의 크기도 줄었습니다. 총 크기는 1.1 PB에서 0.8 PB로 27% 감소했으며, 이는 기본 데이터 변경 없이 이루어졌습니다. 더 잘 클러스터링된 파일은 더 효율적으로 압축되며, 과도한 파티셔닝으로 인한 작은 파일 문제가 사라집니다.
Liquid Clustering의 향후 계획
Liquid-to-Liquid 조인 최적화: 최대 51% 더 빠르게, 셔플은 87% 감소
현재 Liquid 테이블을 클러스터링 열 기준으로 조인할 때 데이터가 이미 해당 열 기준으로 구성되어 있더라도 전체 데이터 셔플이 필요할 수 있습니다. Co-clustered joins(현재 비공개 미리보기)는 이러한 셔플을 자동으로 제거합니다. 실제 데이터 웨어하우징 벤치마크에서 Liquid-to-Liquid 조인은 최적화 없이 동일한 쿼리를 실행했을 때보다 약 51% 더 빠르게(28분 → 14분) 실행되었고 셔플되는 데이터는 87% 적었습니다(1.2 TiB → 150 GiB).
파티셔닝된 테이블의 쉬운 Liquid 변환
이전에는 파티셔닝된 테이블을 Liquid Clustering으로 변환하려면 전체 테이블 다시 쓰기와 REPLACE TABLE을 사용한 다운스트림 호환성 문제 또는 이중 쓰기 및 계획된 다운타임을 통한 전환이 필요했습니다. 저희는 다운타임과 다시 쓰기를 최소화하는 새로운 명령(현재 비공개 미리보기)을 도입하여 이 변환을 더 쉽게 만들고 있습니다.
Liquid Clustering 시작하기
Liquid Clustering으로 테이블을 생성하세요:
또는 Predictive Optimization을 사용하는 UC 관리 테이블의 경우, 워크로드 및 쿼리 패턴에 따라 클러스터링 키를 지능적으로 선택하는 Automatic Liquid Clustering을 사용하여 다음을 수행할 수 있습니다:
Liquid Clustering은 현대적인 Lakehouse의 레이아웃입니다. 다음 테이블에서 사용해 보거나 지금 바로 계정 팀에 문의하여 파티셔닝된 테이블을 Liquid로 변환하고 Co-Clustered 조인에 대한 비공개 미리보기를 사용해 보세요!
DAIS에서 저희를 놓치지 ��마세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.