Serverless JAR 개발 및 배포
작성자: Achille Negrier, Edward Feng, Giorgi Kikolashvili , Shiyu Wang
- 즉각적인 시작 시간과 제로 클러스터 관리로 Scala 또는 Java로 작성된 Serverless JAR를 실행하세요.
- Databricks Connect를 사용하여 즐겨 사용하는 IDE에서 개발하고 실제 데이터 및 프로덕션과 유사한 환경에서 테스트하세요.
- 유휴 시간이나 인스턴스 획득 비용이 아닌, 사용량 기반의 탄력적인 요금제로 작업한 만큼만 지불하세요.
Serverless JAR 및 Databricks Connect를 사용한 Scala
Serverless JAR를 사용하면 팀에서 완전히 관리되는 Serverless 컴퓨팅 환경에서 Scala 및 Java Spark 작업을 구축하고 실행할 수 있습니다. 팀은 클러스터 관리의 운영 부담 없이, 이미 신뢰하는 언어로 프로덕션 수준의 Spark 파이프라인을 계속 구축할 수 있습니다:
- 빠른 시작: Serverless를 사용하면 Scala 및 Java 작업이 몇 분이 아닌 몇 초 만에 시작됩니다. 엔지니어는 클러스터가 시작될 때까지 기다리지 않고 즉시 코드를 실행하고 반복할 수 있습니다.
- 버전 없는 업그레이드: Serverless는 항상 최신 지원 Spark 런타임에서 실행되므로 Databricks Runtime 업그레이드를 계획하거나 관리할 필요가 없습니다.
- 관리할 인프라 없음: 클러스터 프로비저닝, 용량 계획, 런타임 관리가 필요 없습니다. Databricks는 인프라, 확장 및 성능 최적화를 자동으로 처리하므로 개발자는 코드 작성에 집중할 수 있습니다.
- 사용한 만큼만 지불: 항상 켜져 있는 클러스터나 유휴 용량에 비용을 지불하는 대신, 팀은 실제로 사용한 컴퓨팅에 대해서만 청구됩니다.
Serverless JAR는 어떻게 작동하나요?
Lakeflow Jobs를 Serverless 컴퓨팅에서 실행할 수 있습니다. Serverless JAR는 Spark 4(Scala 2.13) 및 Spark Connect를 기반으로 구축되며, Python과 동일한 아키텍처를 사용합니다. 사용자 코드와 엔진의 분리는 버전 없는 업그레이드를 가능하게 하고, 종속성 충돌을 제거하며, Lakeguard를 통한 네이티브 세분화된 액세스 제어를 가능하게 합니다.
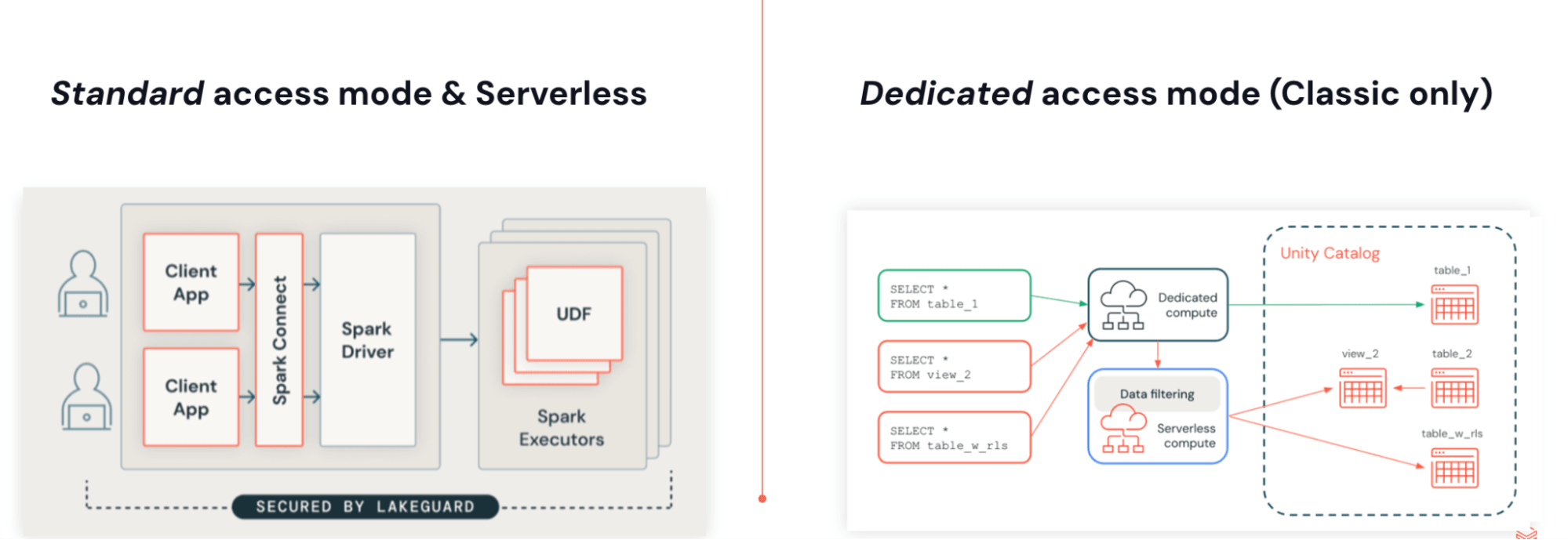
이 아키텍처에는 몇 가지 주요 이점이 있습니다:
- 버전 없는 실행: 애플리케이션이 더 이상 특정 Databricks Runtime 버전에 종속되지 않습니다. Serverless는 항상 최신 지원 런타임에서 실행되므로 Databricks Runtime 업그레이드를 계획, 예약 또는 관리할 필요가 없습니다.
- Lakeguard를 통한 네이티브 세분화된 액세스 제어: 모든 실행이 서버에서 이루어지므로 Databricks는 낮은 비용으로 행 수준 필터 및 속성 기반 액세스 제어(ABAC)를 적용할 수 있습니다.
- 슬림하고 독립적인 종속성 집합: Serverless 환경은 Spark와 격리되어 실행되므로 독립적이고 축소된 종속성 집합을 제공할 수 있으며, 이는 종속성 충돌도 제거합니다.
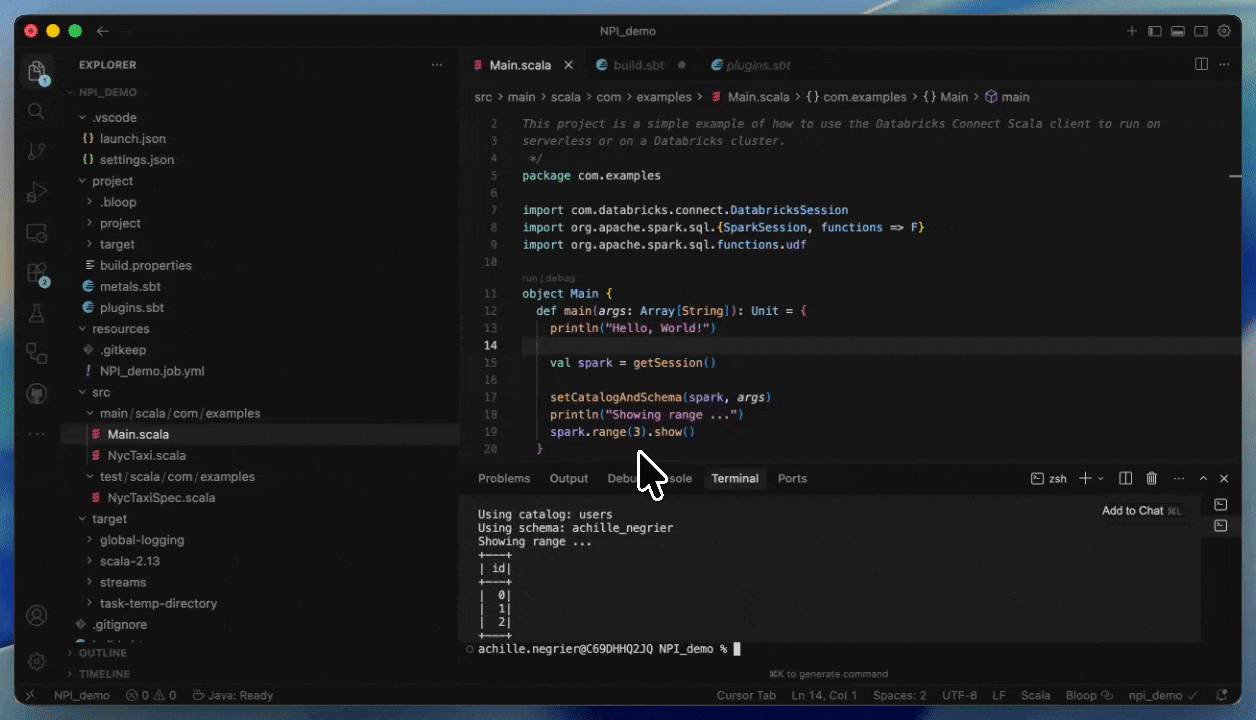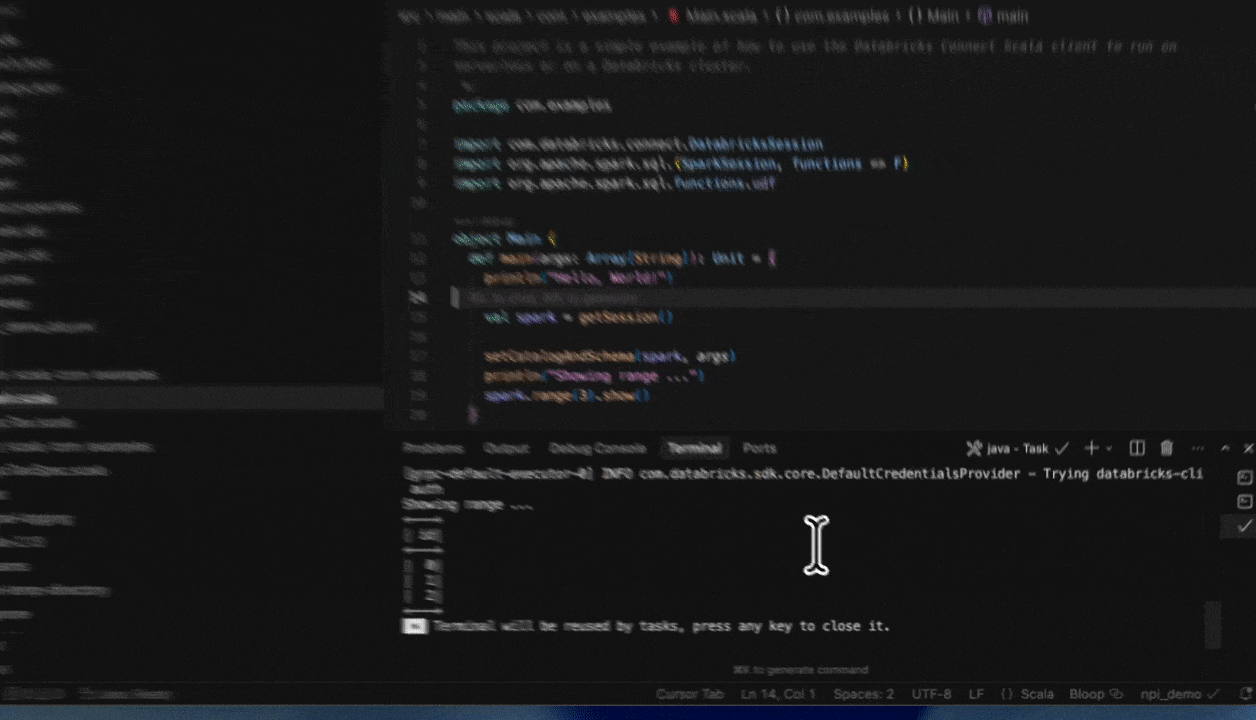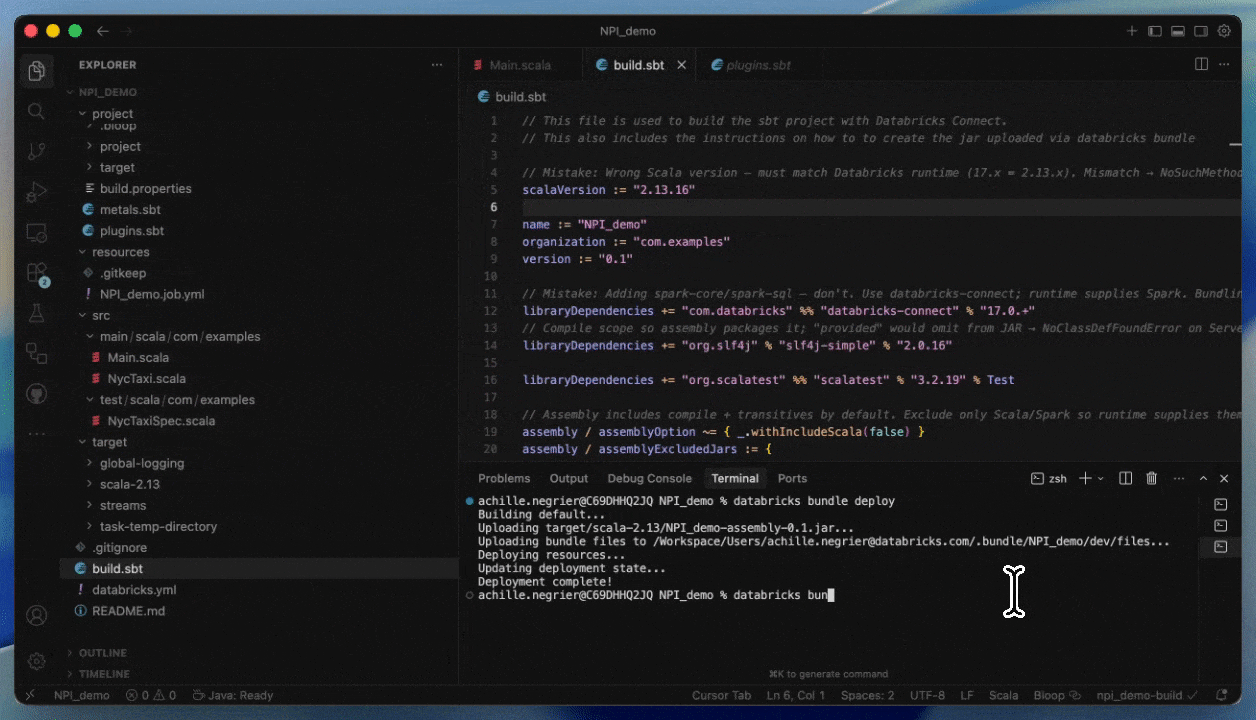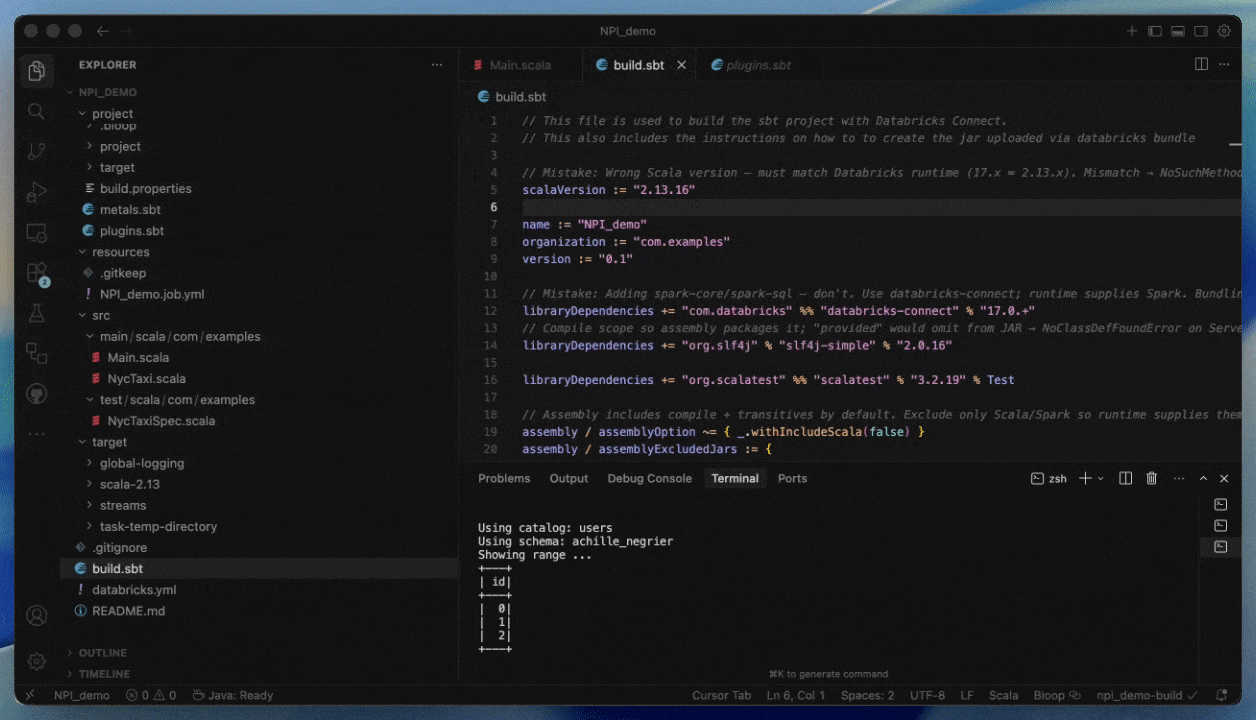
Databricks Connect 및 Databricks Asset Bundles를 사용한 개발
Databricks Connect를 사용하면 IntelliJ 또는 Cursor와 같은 IDE에서 Serverless 컴퓨팅을 사용하여 거의 즉각적인 시작 시간으로 코드를 대화형으로 작성하고 디버그할 수 ��있습니다.
IDE를 벗어나지 않고 실제 데이터 및 환경을 테스트할 수 있으므로 개발 주기가 더 빠르고 안정적입니다. 개발이 완료되면 Databricks Asset Bundles를 사용하여 작업을 프로덕션화할 수 있습니다.
JAR를 제공하여 Serverless에 배포하는 방법
1단계: Serverless용 JAR 컴파일
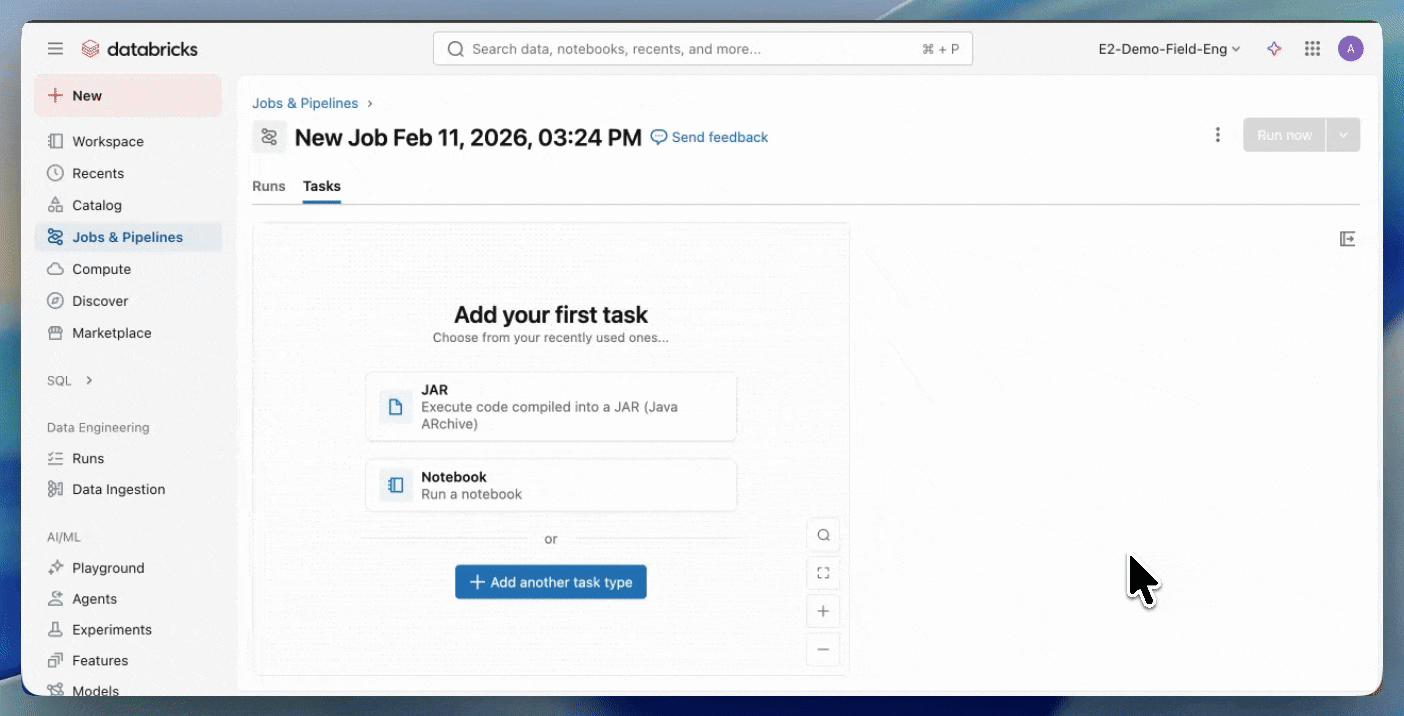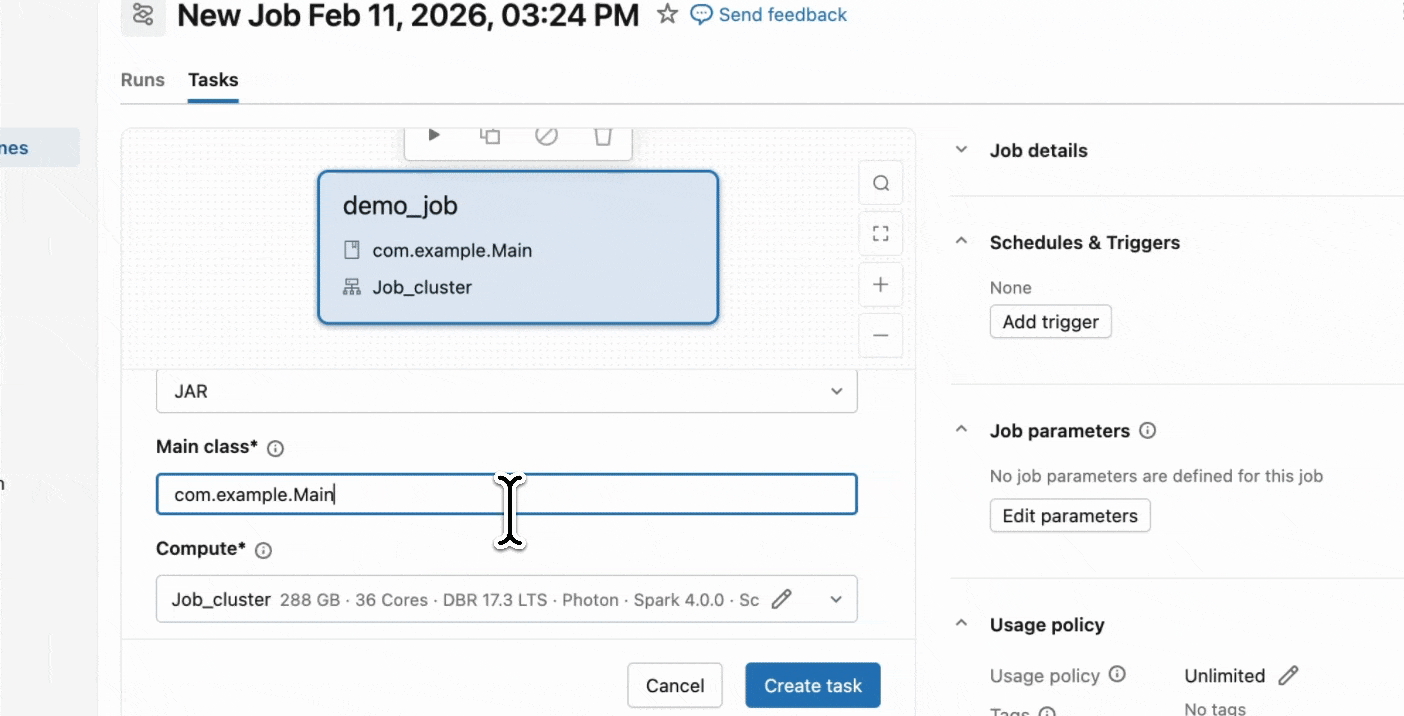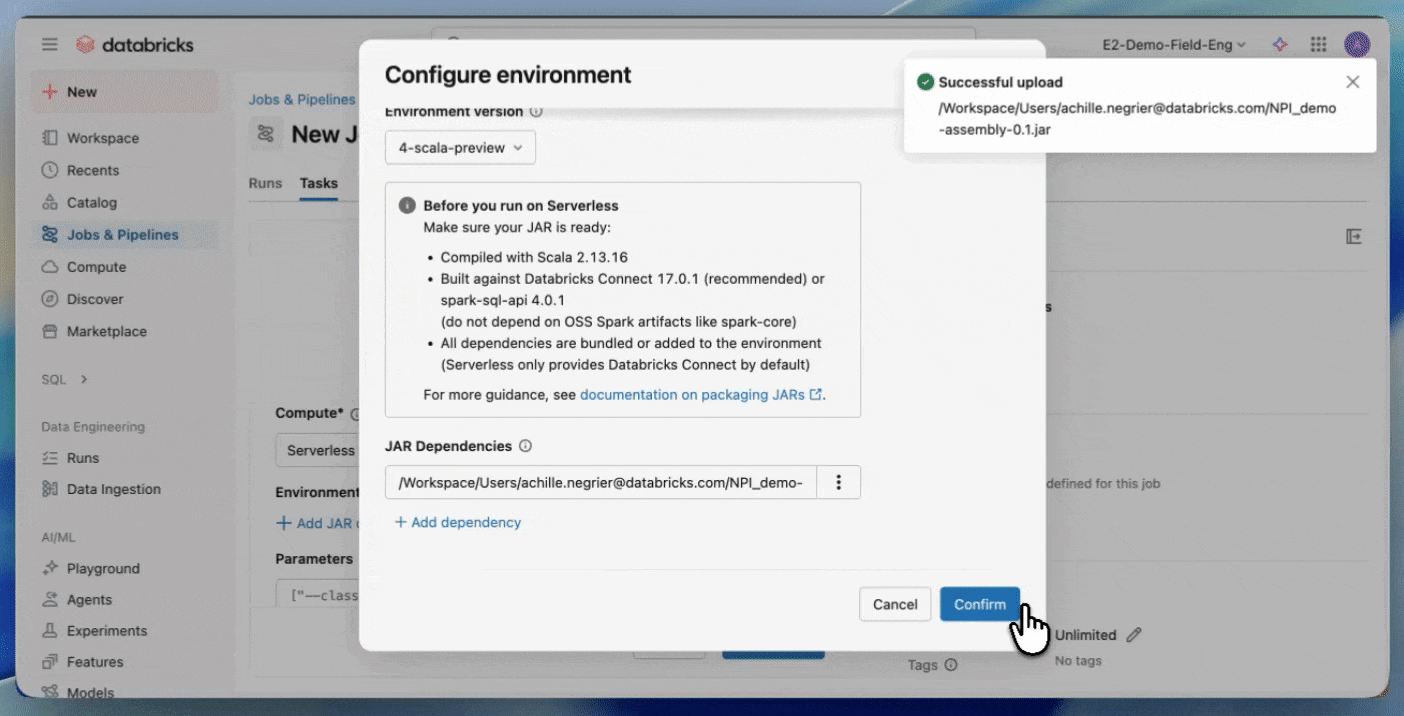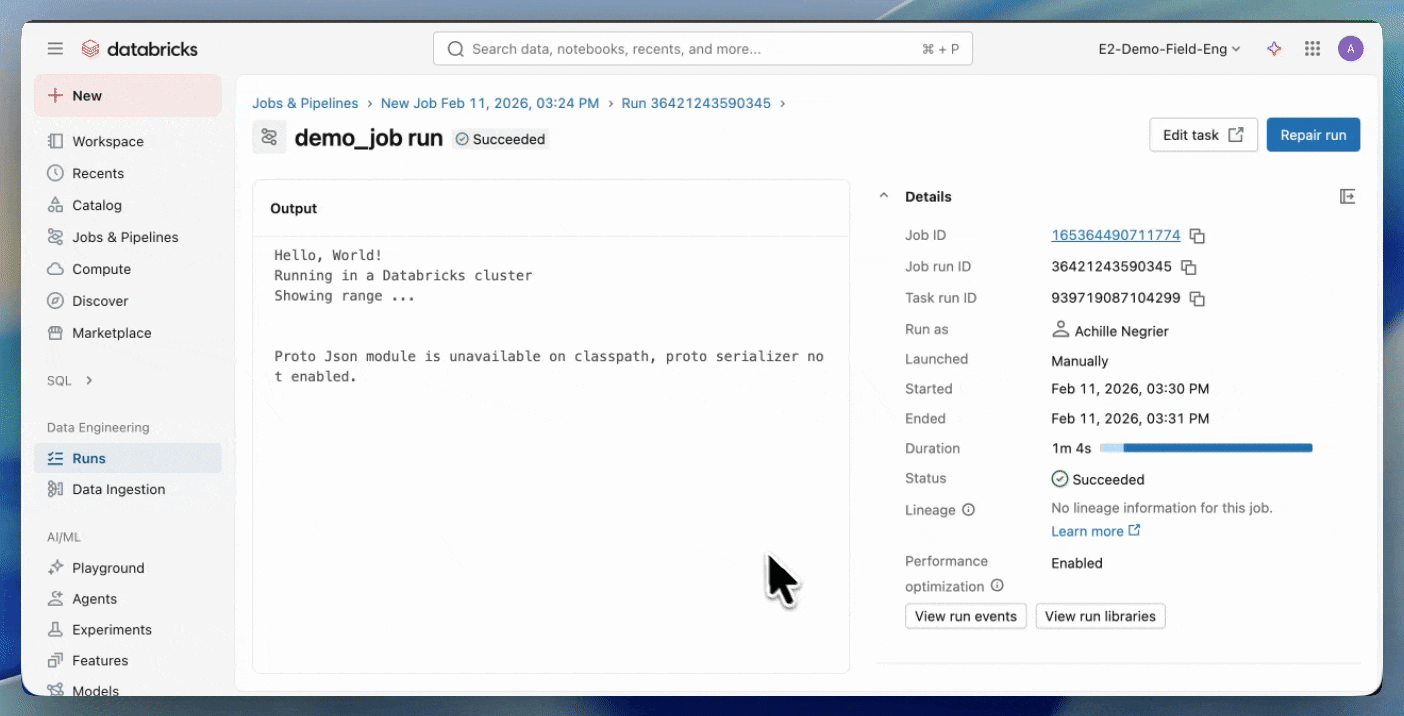
- Spark 4(Scala 2.13) 및 Spark Connect로 컴파일
- 비-Spark 종속성을 명시적으로 번들링하거나 추가 JAR로 제공
2단계: Serverless 작업 생성
- JAR를 Unity Catalog 볼륨 또는 UC 작업 영역 폴더에 업로드합니다.
- JAR 작업을 사용하여 새 작업을 생성하고 컴퓨팅으로 Serverless를 선택합니다.
Serverless JAR 시작하기
빠르게 시작하려면 Databricks Asset Bundle 템플릿을 사용하여 Scala 작업을 개발하고 배포하는 튜토리얼을 따르세요. JAR를 수동으로 컴파일하는 튜토리얼은 Serverless 컴퓨팅에서 Scala 코드 실행을 참조하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.