Databricks 산업별 데이터 모델로 데이터 모델링을 빠르게 시작해 보세요
세계 최대 40개 산업을 위해 사전 구축되고 규칙 검증을 거친 실버 레이어 지원 데이터 모델로, Databricks 플랫폼에서 즉시 배포하고 거버넌스를 적용할 수 있습니다.
작성자: Amr Ali, Drew Triplett, Franco Patano , Shelley Shaffery
- 바로 사용할 수 있는 40개 이상의 산업 데이터 모델. 40개 산업을 위한 사전 구축되고 규칙 검증을 거친 실버 레이어 모델이 두 가지 범위(MVM 및 ECM)로 제공되며, 그대로 배포하거나 맞춤 설정할 수 있습니다.
- 거버넌스가 적용된 완전한 아티팩트 세트. 하나의 model.json(SQL DDL, DBML, 온톨로지 포함)으로 제공되며, Delta 테이블, 외래 키, 분류 태그, 메트릭 뷰와 함께 Unity Catalog에 배포됩니다.
- 몇 시간 만에 배포 완료. Unity Catalog에서 model.json을 지정하고 카탈로깅 스타일을 선택하기만 하면 분류 및 FK 검증이 완료된 실버 레이어를 얻을 수 있습니다.
산업 데이터 모델의 문제점
지난 30년 동안 규제가 엄격하고 데이터가 방대한 산업 분야에서는 산업 데이터 모델을 구매하라는 똑같은 지름길을 제안받아 왔습니다. 보험업계의 ACORD, 헬스케어 분야의 FHIR 및 HL7, 리테일 분야의 ARTS가 대표적입니다. 표준화 기구나 벤더가 발행한 수백, 때로는 수천 개의 테이블이 단 하나의 라이선스로 1년 치의 작업을 해결할 수 있는 것처럼 홍보됩니다.
솔깃한 제안이지만, 현실은 훨씬 더 고통스럽습니다. 산업 데이터 모델은 해당 분야의 모든 비즈니스의 평균치에 불과합니다. 여러분의 제품 라인, 지리적 위치, 규제 환경, 기존 시스템의 제약 조건, 명명 규칙, 조직의 형태를 알지 못하며, 여러분의 비즈니스를 차별화하는 요소가 무엇인지도 모릅니다. 결국 실무 팀은 채워 넣을 일도 없는 수백 개의 테이블, 자신들의 용어와 맞지 않는 명명 규칙, 워크로드에 필요하지 않은 관계 방향을 그대로 떠안게 됩니다. 템플릿을 구매해서 얻는 가치의 대부분은 이를 다듬고, 이름을 바꾸고, 다시 연결하는 데 소모됩니다. 이는 템플릿이 원래 덜어주었어야 할 바로 그 작업들입니다.
실제로 프로덕션 분석과 ML을 구동하는 견고한 분석 데이터 모델을 구축하려면 역사적으로 수개월에서 수년이 걸렸습니다.
저희는 다른 방식을 제안하고자 합니다. 세계 최대 규모의 40개 산업군을 위해 퍼블릭 리포지토리에서 바로 사용할 수 있고, Databricks의 Silver 레이어로 즉시 배포 가능한 사전 구축된 레이크하우스 산업 데이터 모델 라이브러리를 공개합니다. 각 산업 데이터 모델은 두 가지 범위로 제공되며, 14개의 다양한 모델링 도메인에 걸친 200개 이상의 엄격한 구조적 규칙 세트를 기반으로 구축되어 첫날부터 프로덕션급 결과물을 보장합니다. 또한, 이 모델들은 경직되거나 고정된 데이터 모델이 아니므로 필요에 따라 조직에 맞게 발전시키고 맞춤화할 수 있습니다.
레이크하우스에서 이 데이터 모델들의 위치
Databricks 메달리온 아키텍처에서 Bronze는 원시 데이터를, Silver는 모든 분석가, BI 도구, 데이터 사이언티스트가 읽는 정제된 분석 기준 모델을, Gold는 파생 메트릭, KPI 및 집계를 보유합니다.
이 기준 데이터 모델들이 바로 Silver 레이어입니다. Lakeflow와 Auto Loader가 수집을 처리합니다. 각 모델은 churn_score 또는 monthly_revenue_summary와 같이 미리 계산된 메트릭과 함께 제공됩니다. 기준 모델은 분석의 기초입니다. 즉, 비즈니스 개념이 신뢰할 수 있는 테이블로 변환되어 BI 도구, 피처 파이프라인 및 다운스트림 집계에 사용할 준비를 마치는 곳입니다.
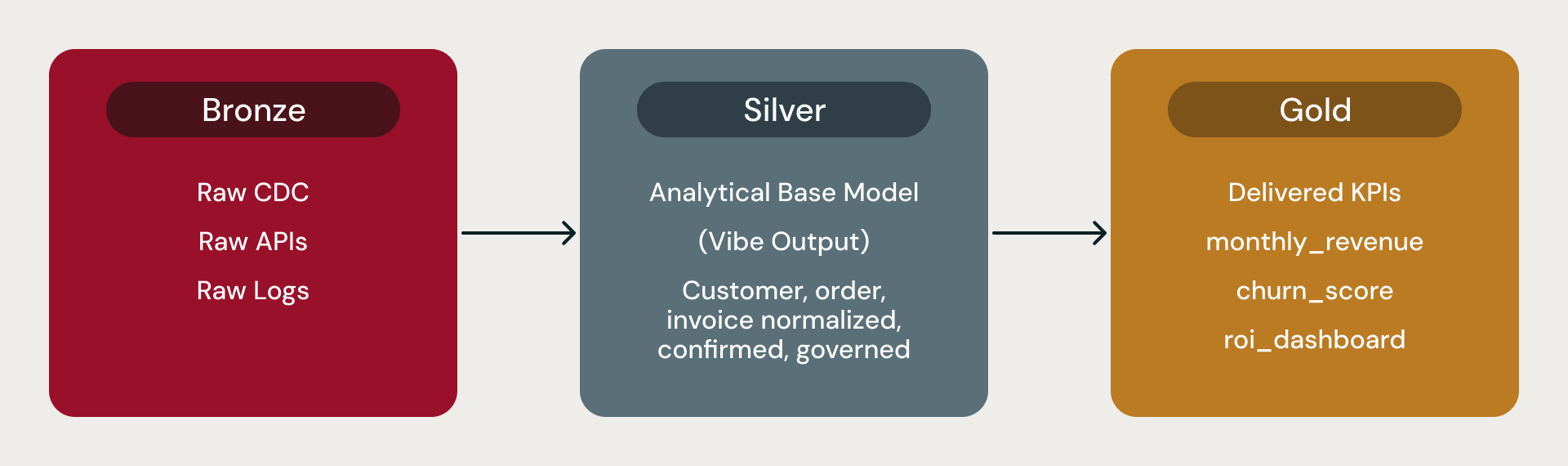
Bronze, Silver, Gold
두 가지 범위: MVM 및 ECM
모든 기준 모델은 두 가지 범위로 게시됩니다. 둘 다 동일한 논리적 model.json에서 배포되고, 동일한 규칙을 따르며, 테이블당 동일한 속성 깊이를 가집니다. 차이점은 범위의 너비입니다.
최소 실행 가능 모델(MVM). ECM 테이블 수의 30~50% 수준입니다. 필수적인 비즈니스 기능만 포함합니다. SMB, 신속한 배포, 개념 증명(PoC) 및 MVP에 이상적입니다. MVM은 단순한 뼈대나 데모용 장난감이 아닙니다. 모든 테이블은 대응하는 ECM 테이블과 동일한 수준의 풍부한 속성을 가지고 있습니다. 가벼움은 더 적은 도메인과 더 적은 테이블에서 오는 것이지, 결코 부실한 테이블에서 오는 것이 아닙니다.
확장 범위 모델(ECM). 전체 범위를 커버합니다. 기업 백오피스를 포함한 모든 부�서가 포함됩니다. Fortune 100 기업 모델에 기대되는 모든 도메인을 갖추고 있습니다. 최대의 너비를 제공합니다.
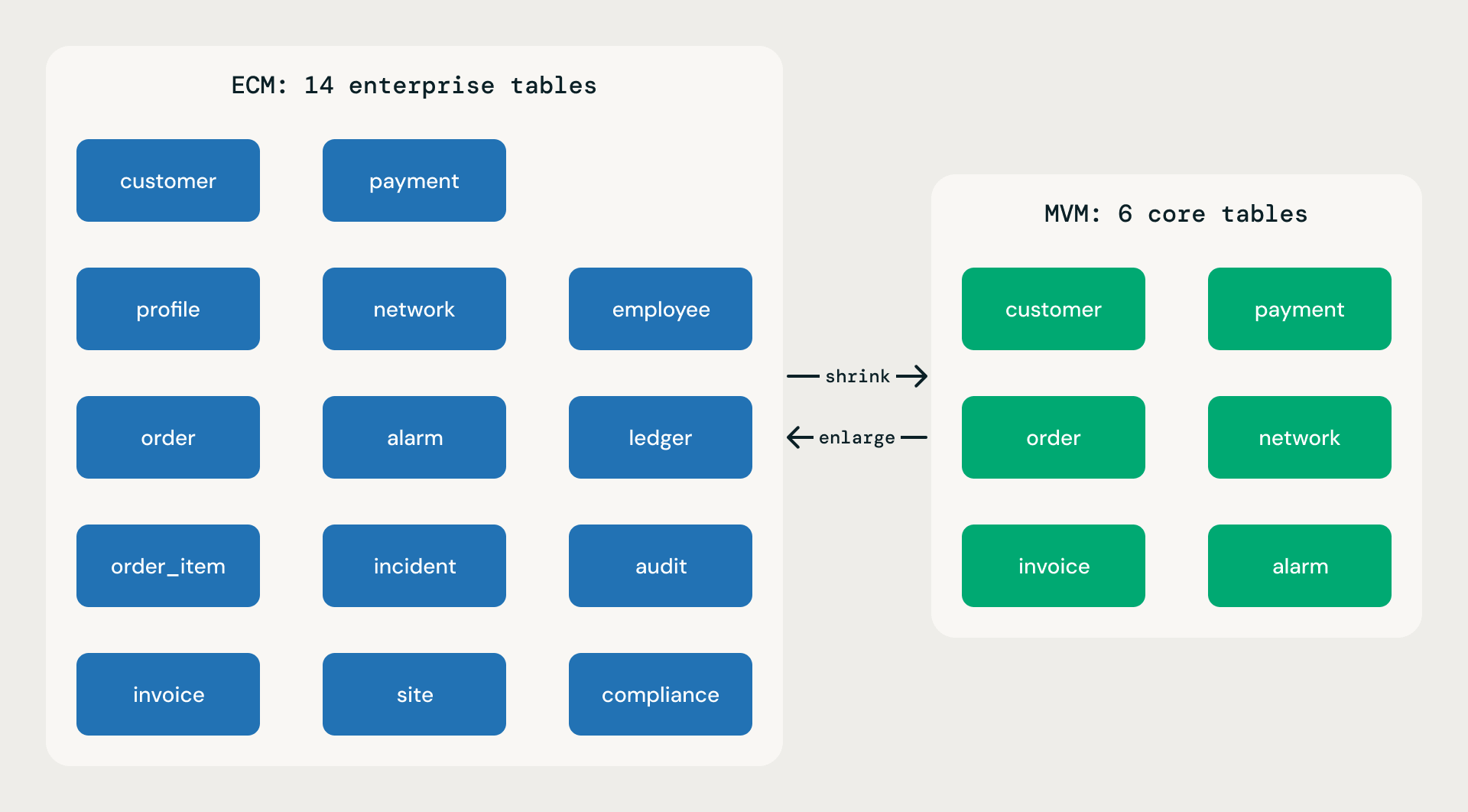
MVM vs ECM 범위
왜 두 가지 범위가 모두 중요할까요? 조직이 모델을 비즈니스 데이터에 맞추는 데 시간을 허비하는 대신, 레이크하우스에서 신속하게 분석을 시작할 수 있도록 돕는 것이 목표이기 때문입니다. 따라서 적절한 범위로 시작하는 것 자체가 시간을 절약하는 길입니다.
두 범위는 별개로 유지 관리되는 라인이 아닙니다. 단 한 번의 변환을 통해 서로 유도할 수 있습니다. shrink ecm은 핵심 제품을 보호하고 필수 외래 키를 유지하는 MVM 하위 집합을 생성하며, enlarge mvm은 그 반대 작업을 수행합니다. 어떤 버전도 덮어쓰이지 않으며, 두 작업 모두 기존 버전과 함께 번호가 매겨진 새 버전을 생성합니다.
이 모델들이 특별한 이유
저희가 공개하는 기준 모델은 단순히 위원회 표준 산업 템플릿의 이름만 바꾼 것이 아닙니다. 모든 모델링 단계에서 구조적 품질을 강제하는 규율 있고 규칙 기반의 AI 에이전트에 의해 생성됩니다. 몇 가지 주요 특징은 다음과 같습니다.
산업 티어별 크기 조정. 모든 모델은 해당 분야의 실제 복잡성에 맞게 크기가 조정됩니다. 분류기는 규제 밀도, 당사자 복잡성, 제품 계층 구조 깊이, 인프라 관리, 산업 표준 모델, 트랜잭션 복잡성, 운영 시스템 환경의 7가지 차원을 사용하여 각 산업을 5개 티어 중 하나로 분류합니다. 이 티어에 따라 도메인 수, 도메인당 제품 수, 속성 깊이가 결정됩니다.
| 티어 | 레이블 | 주요 특징 | MVM 도메인 | ECM 도메인당 제품 수 |
|---|---|---|---|---|
| tier_1 | 초고복잡 | 금융, 보험, 대형 제약 | 15–22 | 14–28 |
| tier_2 | 고복잡 | 통신, 에너지, 헬스케어 | 12–18 | 14–26 |
| tier_3 | 보통 | 제조, 리테일 | 10–15 | 12–24 |
| tier_4 | 표준 | 물류, 농업 | 8–12 | 10–20 |
| tier_5 | 단순 | 컨설팅, SaaS, 미디어 | 5–8 | 8–18 |
산업별 전문 용어. 각 모델은 해당 분야에서 실제로 사용하는 용어를 채택합니다. 통신 분야에는 msisdn, arpu, imsi, cdr이 적용됩니다. 광업 분야에는 rom, cut_off_grade, jorc가 적용됩니다. 헬스케어 분야에는 icd, cpt, drg가 적용됩니다. 금융 분야에는 iban이 적용됩니다. 이는 나중에 대충 덧붙인 것이 아니라, 열 이름, 기본 키 규칙, 거버넌스 태그의 구조를 결정하는 핵심 요소입니다.
3대 부문 프레임워크. 모든 모델은 세 개의 동심원 고리로 구성됩니다.
- Operations(운영)은 비즈니스가 물리적으로 수행하는 활동(네트워크, 플릿, 공장, 인프라 등)을 의미합니다.
- Business(비즈니스)는 서비스 대상과 수익 창출 방식(고객, 청구, 제품, 영업 등)을 의미합니다.
- Corporate(기업 지원)는 이를 지원하는 프레임워크(인사(HR), 재무, 컴플라이언스 등)를 의미합니다.
이 비율은 규칙(rule G06-R001)에 의해 강제됩니다. Operations와 Business가 전체 도메인의 최소 80%를 차지해야 하며, Corporate는 최대 20%로 제한됩니다. 이는 제약 없는 모델링에서 가장 흔히 발생하는 실패 유형, 즉 모델의 절반이 인사(HR), 재무, 법무로 채워지고 정작 비즈니스를 실제로 구동하는 운영 핵심 요소는 부실해지는 현상을 방지합니다.
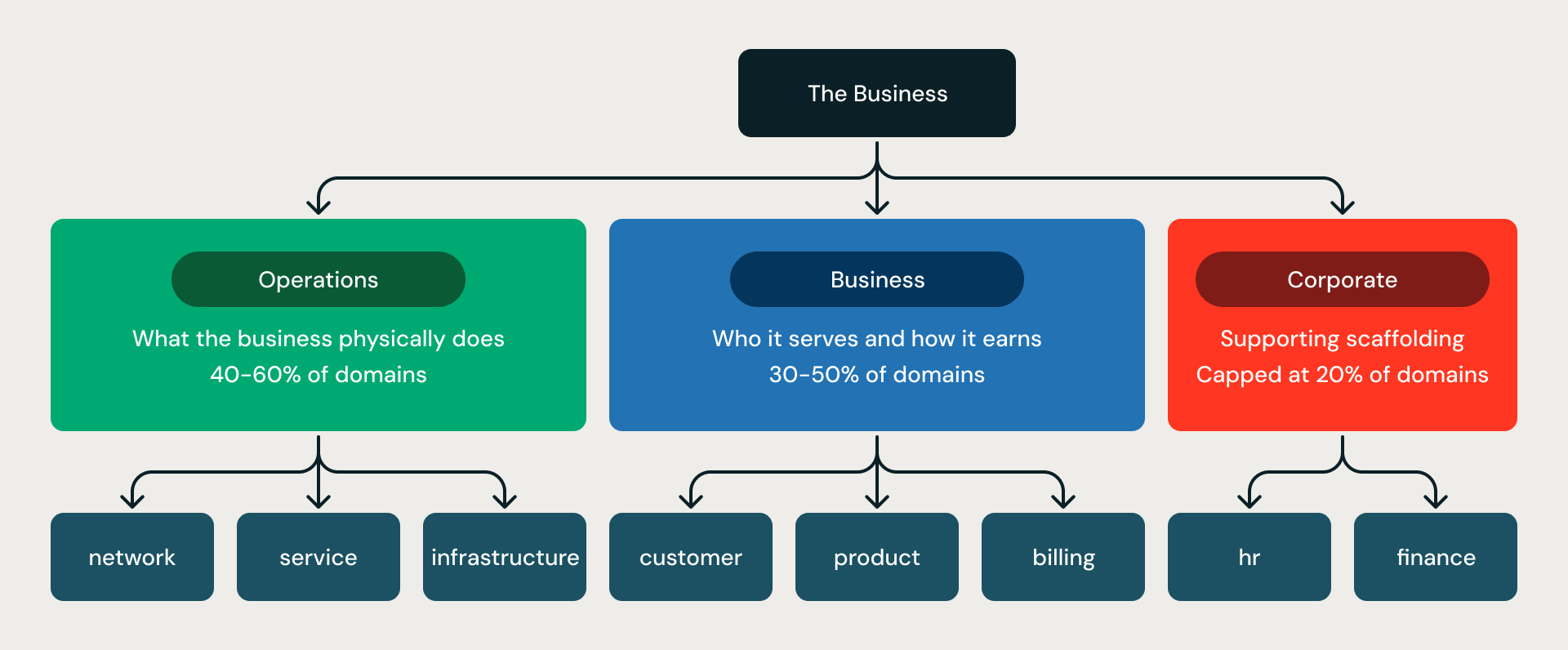
3대 부문
6단계 계층 구조. 모든 모델은 동일한 엄격한 형태를 따릅니다: Organization(조직) → Division(부문) → Domain(도메인) → Subdomain(하위 도메인) → Product(제품) → Attribute(속성). 이 계층 구조는 단순한 권장 사항이 아닙니다. 구조적 규칙, 두 단계의 아키텍트 검토, 그리고 모든 파이프라인의 끝에서 수행되는 정적 분석을 통해 강제됩니다.
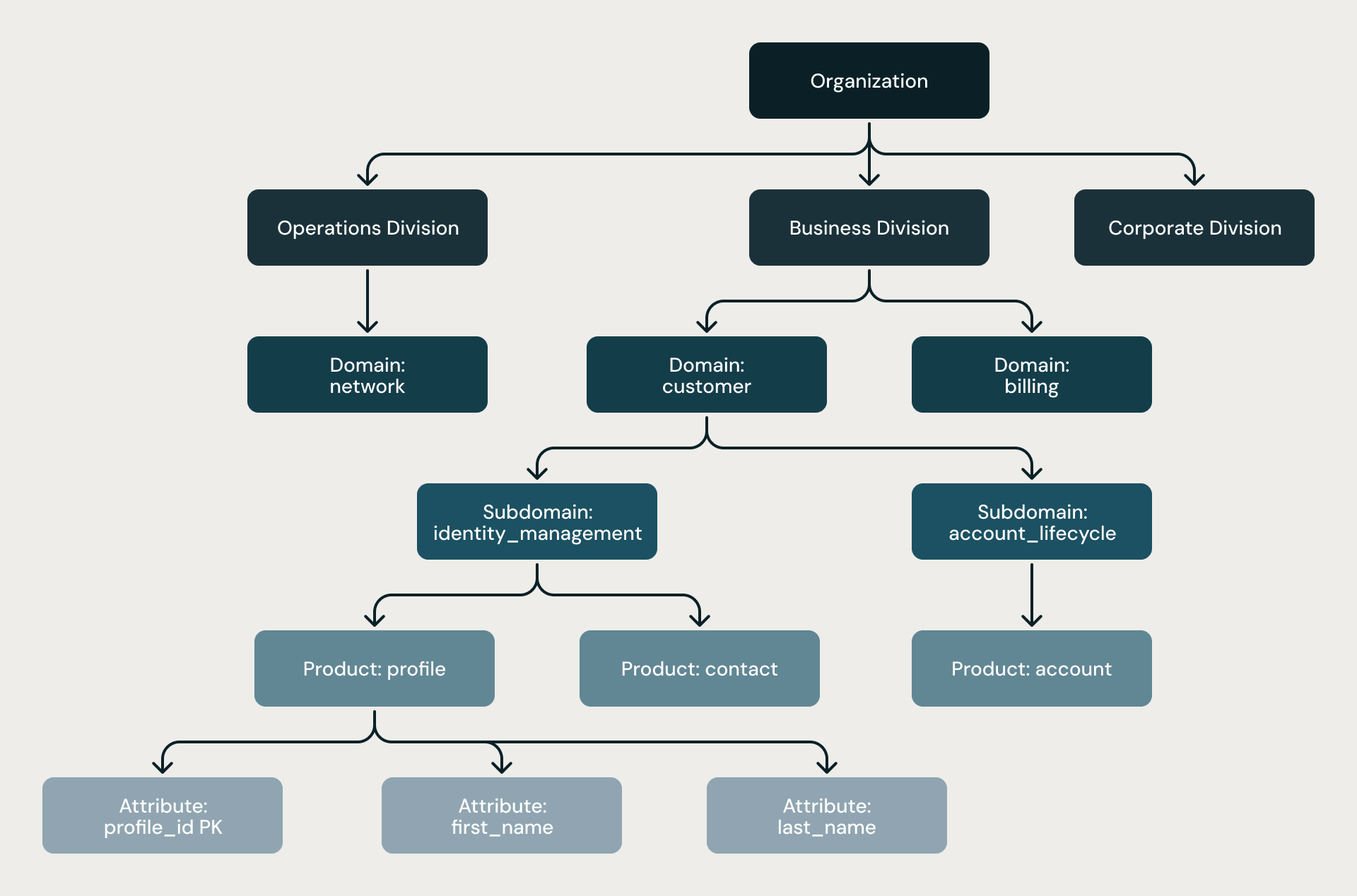
4단계 계층 구조
200개 이상의 강제 규칙. 모든 기준 모델은 명명 규칙, 의미론적 중복 제거, 외래 키, 기본 키, 정규화, 도메인 구조, 데이터 유형, 분류 태그, 관계/DAG 강제, 품질, 제품 디자인, 분위기(vibe) �제약 조건, 물리적 스키마 배포, 하위 도메인 크기 조정을 포함한 14개 이상의 그룹으로 구성된 200개 이상의 규칙에 대해 검증을 거칩니다. 모든 테이블에는 기본 키가 있어야 합니다. 모든 외래 키는 실제 대상을 가리켜야 합니다. 모든 도메인은 조직도 테스트를 통과해야 합니다. 즉, “실제로 이 이름을 가진 부서나 팀이 조직 내에 존재할 수 있는가?”라는 질문에 답할 수 있어야 합니다. 순환 참조가 없어야 하고, 사일로가 없어야 하며, 엄격한 단일 진실 공급원(SSOT) 원칙을 준수해야 합니다.
하나의 논리적 모델, 세 가지 물리적 레이아웃. 각 기준 모델은 환경에 독립적인 단일 model.json 파일로 제공됩니다. 동일한 논리적 모델이 세 가지 카탈로그 스타일로 Unity Catalog에 깔끔하게 배포됩니다: 단일 카탈로그(단일 거버넌스 경계), 부문별 카탈로그(Operations / Business / Corporate 격리), 또는 도메인별 카탈로그(데이터 메시 친화적). 다른 스타일로 재배포하더라도 논리적 모델은 전혀 수정되지 않습니다.
실행 예시: 항공사 ECM 모델 v1
이를 구체적으로 보여드리기 위해, 현재 리포지토리에 제공되고 있는 항공사 ECM을 소개합니다.
| 메트릭 | 값 |
|---|---|
| Model Scope | ECM v1 |
| Total Domains | 19 |
| Total Subdomains | 60 |
| Total Products | 420 |
| Total Attributes | 17,278 |
| Primary Keys | 420 |
| Foreign Keys | 2,877 |
| Avg Attributes/Product | 41.1 |
| 메트릭 뷰 | 203 |
그래프로 시각화하면 전체 DAG는 다음과 같습니다(각 직사각형은 도메인, 작은 원은 테이블, 선은 FK 링크입니다).

연결된 DAG 형태의 Airline ECM v1
19개의 도메인은 3개의 부문으로 깔끔하게 나뉩니다. Operations는 airport, crew, fleet, flight, inventory, maintenance, route를 포함합니다. Business는 ancillary, cargo, loyalty, passenger, reservation, revenue, service, ticket을 포함합니다. Corporate는 compliance, finance, safety, workforce를 포함합니다.

부문별 Airline 도메인
단일 도메인인 flight operations를 상세히 살펴보면 실무 수준에서 구조를 명확하게 파악할 수 있습니다. resource loading, flight operations, passenger services 하위 도메인에는 운영 분석가가 실제로 사용하는 제품인 leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment가 포함되어 있습니다. (모든 원은 테이블이고, 모든 선은 FK 관계입니다)

Flight 도메인
더 나아가 cargo 도메인 내의 단일 데이터 제품인 Air Waybill(awb)을 상세히 살펴보면 교차 도메인 링크가 어떻게 작동하는지 정확히 확인할 수 있습니다. awb는 passenger 도메인의 corporate_account, airport의 station, flight의 leg, finance의 profit_center, ledger_account, company_code, 그리고 compliance의 screening_result와 연결됩니다. 이것들은 화물 수익 분석가가 매일 실행하는 조인(join)이며, 교차 도메인 DAG가 이를 지원하도록 구축되었기 때문에 존재합니다.

Air Waybill 데이터 제품
배포 시 제공되는 사항
모든 기본 모델은 완전한 아티팩트 세트와 함께 제공됩니다.
논리적 아티팩트. 단일 model.json(기본 교환 형식), 사람이 읽을 수 있는 readme.md, 도메인, 제품 및 속성의 플랫 내보내기, Excel 및 CSV 내보내기, SQL DDL 파일(도메인당 하나씩 및 교차 도메인 FK 파일), DBML 스키마 다이어그램 및 RDF/Turtle 온톨로지.
Unity Catalog에 배포할 때의 물리적 아티팩트. Unity Catalog 스키마(카탈로그 스타일에 따라 도메인당 또는 하위 도메인당 하나), 모든 제품에 대한 Delta 테이블, 종속성 순서로 적용된 외래 키(foreign-key) 제약 조건, Unity Catalog 분류 태그(PII, restricted, public), 재사용 가능한 KPI 정의를 위한 Databricks 메트릭 뷰, 즉각적인 탐색을 위해 유효한 FK 참조가 포함된 합성 샘플 데이터.
model.json 파일은 기본 교환 단위입니다. git에 커밋하고, 두 버전의 차이를 비교하고, 여러 환경에 걸쳐 공유해 보세요. 운영 환경에 대한 액세스 권한을 제공하지 않고도 보안 검토자에게 전달할 수 있습니다. 세 가지 다른 카탈로그 스타일로 dev, staging, prod에 다시 배포하여 논리적 콘텐츠가 바이트 단위까지 동일한 세 가지 환경을 확보하세요.
이 접근 방식의 강점
- 속도. 이전에는 몇 달씩 걸리던 Silver 레이어 기반 구축이 이제는 배포 단계 하나로 해결됩니다.
- 특화성. 모델은 해당 분야의 언어(전문 용어, 규제 형태, 운영 현실 등)를 사용합니다.
- 규칙 적용 범위. 200개 이상의 강제 적용 가능한 규칙 덕분에 수동으로 작성된 대부분의 모델이 도달하지 못하는 일관성을 제공합니다.
- 거버넌스. 민감한 데이터가 포함된 모든 열이 분류되고 태그가 지정됩니다. 모든 PK/FK는 단일 규칙을 따릅니다. 모든 카탈로그 스타일은 재현 가능합니다.
- 다양한 형태. 동일한 아티팩트가 관계형 스키마, DBML 다이어그램, 지식 그래프 온톨로지, 물리적 Unity Catalog 배포가 될 수 있습니다.
- 논리-물리 분리. 하나의 model.json, 세 가지 카탈로그 스타일. 재작업 없이 다시 배포할 수 있습니다.
고려할 사항
기본 모델은 시작점일 뿐, 최종 결과물이 아닙니다. 도메인 전문 지식은 여전히 중요합니다. 해당 비즈니스 내부에서 일하는 실무자만이 볼 수 있는 방식으로 전문가 검토를 거치면 모델이 항상 개선됩니다. 매우 좁은 하위 수직 시장(sub-vertical)은 주류 산업에 비해 기본 제공되는 형태가 덜 자연스러울 수 있습니다. 또한 엄격한 데이터 모델 승인 위원회가 있는 조직은 여전히 결과물에 대한 검토를 거쳐야 합니다. 달라지는 것은 아티팩트의 속도이지, 이를 관리해야 하는 요구 사항이 아닙니��다.
저희는 이러한 절충이 적절하다고 생각합니다. 몇 시간 만에 배포되고 구조적으로 견고한 기본 모델이, 조정하는 데 1년이 걸리는 템플릿보다 훨씬 더 나은 시작점입니다.
지금 바로 사용해 보세요
40개의 Lakehouse 산업 데이터 모델 리포지토리는 https://github.com/databricks-industry-solutions/databricks-industry-data-models에 있습니다. 각 산업 분야는 MVM과 ECM을 모두 제공합니다. 조직에 맞는 범위를 선택하고 Unity Catalog를 지정하기만 하면, 분석 준비가 완료되고 배포 및 분류되었으며 FK 검증을 거친 Silver 레이어를 확보할 수 있습니다.
다음 단계
기본 모델은 시작점일 뿐입니다. 그렇기 때문에 모든 모델이 v1 단계에 머물러 있으며, 이것이 최종 형태는 아닙니다. 모든 조직에는 아무리 훌륭한 범용 모델이라도 정확히 맞출 수 없는 고유한 용어, 부서 및 비즈니스 프로세스가 있습니다. 다음 포스트에서는 자연어 AI 모델링 에이전트를 사용하여 v1 모델을 맞춤화하고 발전시키는 방법을 살펴보겠습니다. 원하는 변경 사항을 일반 영어로 설명하면 원본의 구조적 엄격함을 유지하면서 맞춤형 버전(v2, v3 등)을 생성할 수 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세��요.