MapInPandas 및 Delta Live Table을 사용하여 일반적이지 않은 파일 형식을 확장성있게 처리하기
작성자: TJ Cycyota
다양한 파일 형식
최신 데이터 엔지니어링의 영역에서, 데이터브릭스 레이크하우스 플랫폼은 안정적인 스트리밍 및 배치 데이터 파이프라인을 구축하는 프로세스를 간소화합니다. 그러나 잘 알려지지 않았거나 일반적이지 않은 파일 형식을 처리하는 것은 여전히 레이크하우스로 데이터를 수집하는 데 있어 어려운 과제입니다. 데이터 제공을 담당하는 업스트림 팀이 데이터를 저장하고 전송하는 방법을 결정하기 때문에 조직마다 표준이 달라집니다. 예를 들어, 데이터 엔지니어는 스키마가 해석의 여지가 있는 CSV나 파일 이름에 확장자가 없거나 독점 파일 형식이어서사별도의 판독기가 필요한 파일로 작업해야 할 때가 있습니다. "이 데이터를 Parquet으로 가져올 수 있나요?" 라고 요청�하는 것만으로도 문제가 해결되는 경우도 있지만, 성능 좋은 파이프라인을 구축하기 위해 좀 더 창의적인 접근 방식이 필요한 경우도 있습니다.
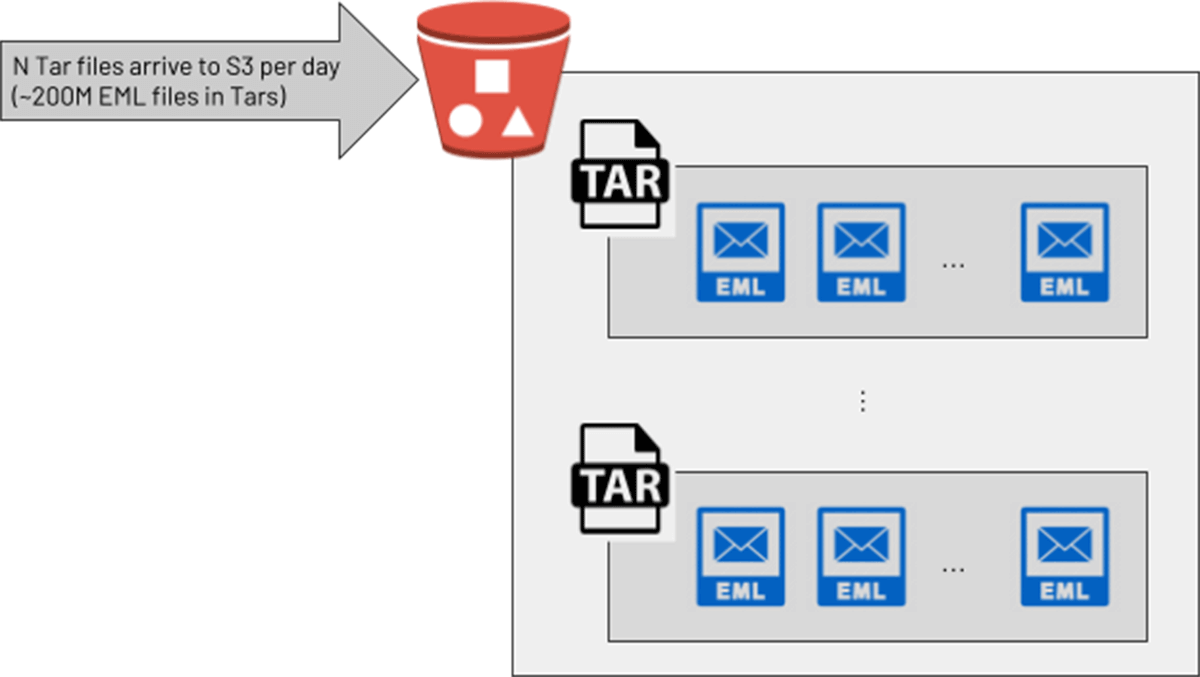
한 대형 고객의 데이터 엔지니어링 팀은 사이버 보안 사용 사례를 위해 이메일의 원시 텍스트를 Databricks에서 처리하기를 원했습니다. 데이터를 제공하는 팀은 이를 압축된 Tar 파일로 제공했는데, 각 Tar 파일에는 많은 이메일(.eml) 파일이 포함되어 있었습니다. 고객의 개발 환경에서 엔지니어들은 적절한 솔루션을 고안해냈습니다. PySpark UDF가 Python "tarfile" 라이브러리를 호출하여 각 Tar를 문자열 배열로 변환한 다음, 기본 PySpark explode() 함수를 사용하여 배열의 각 이메일에 대해 새 행을 반환하는 것이었습니다. 테스트 환경에서는 이 방법이 해결책으로 보였지만, 훨씬 더 큰 Tar 파일(압축 전에는 최대 300Mb의 이메일 파일)이 있는 프로덕션 환경으로 이동하자 파이프라인에서 메모리 부족 오류로 인해 클러스터 충돌이 발생하기 시작했습니다. 하루에 2억 개의 이메일을 처리해야 하는 프로덕션 목표에 따라 보다 확장 가능한 솔루션이 필요했습니다.
모든 파일 형식을 처리하는 MapInPandas()
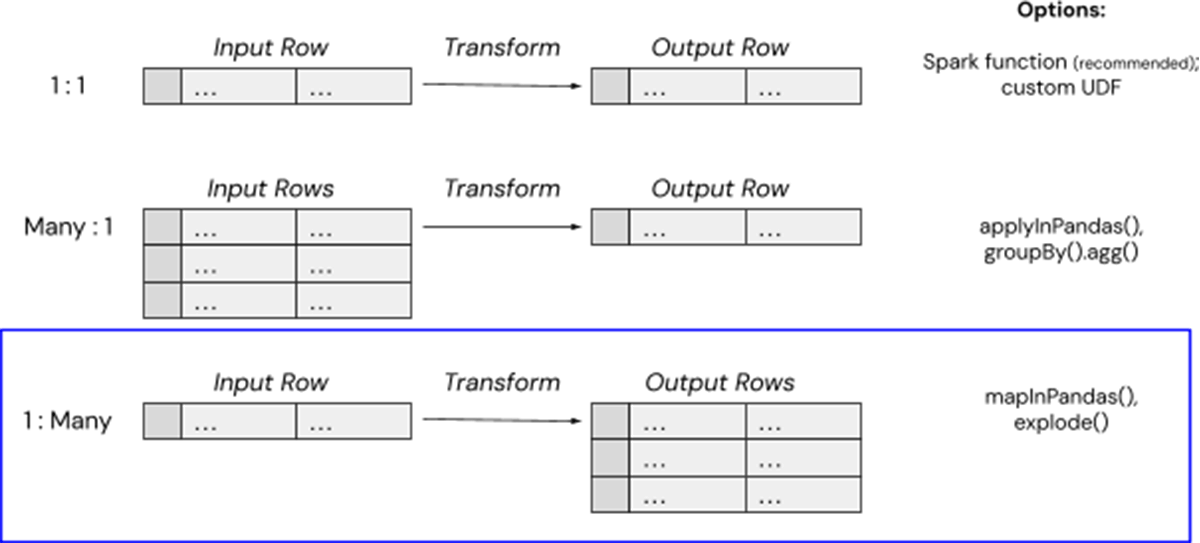
데이터브릭에서 복잡한 데이터 변환을 처리하는 몇 가지 간단한 방법이 있는데, 이 경우 mapInPandas()를 사용해 단일 입력 행(예: 대용량 Tar 파일의 클라우드 저장 경로)을 여러 출력 행(예: 개별 .eml 텍스트 파일의 내용)에 매핑할 수 있습니다. Spark 3.0.0에 도입된 mapInPandas()를 사용하면 Python 네이티브 함수를 사용하여 Spark 데이터프레임의 각 행에 대해 임의의 작업을 효율적으로 완료하고 둘 이상의 반환 행을 생성할 수 있습니다. 이 하이테크 고객이 압축 파일을 각 이메일의 내용을 포함하는 사용 가능한 여러 행으로 '압축 해제'하는 데 필요한 것은 바로 이 기능이었으며, 동시에 Spark UDF의 메모리 오버헤드를 피할 수 있었습니다.
파일 압축 해제를 위한 mapInPandas()
이제 기본 사항을 알았으니 이 고객이 시나리오에 어떻게 적용했는지 살펴봅시다. 아래 다이어그램은 관련된 아키텍처 단계의 개념적 모델 역할을 합니다:
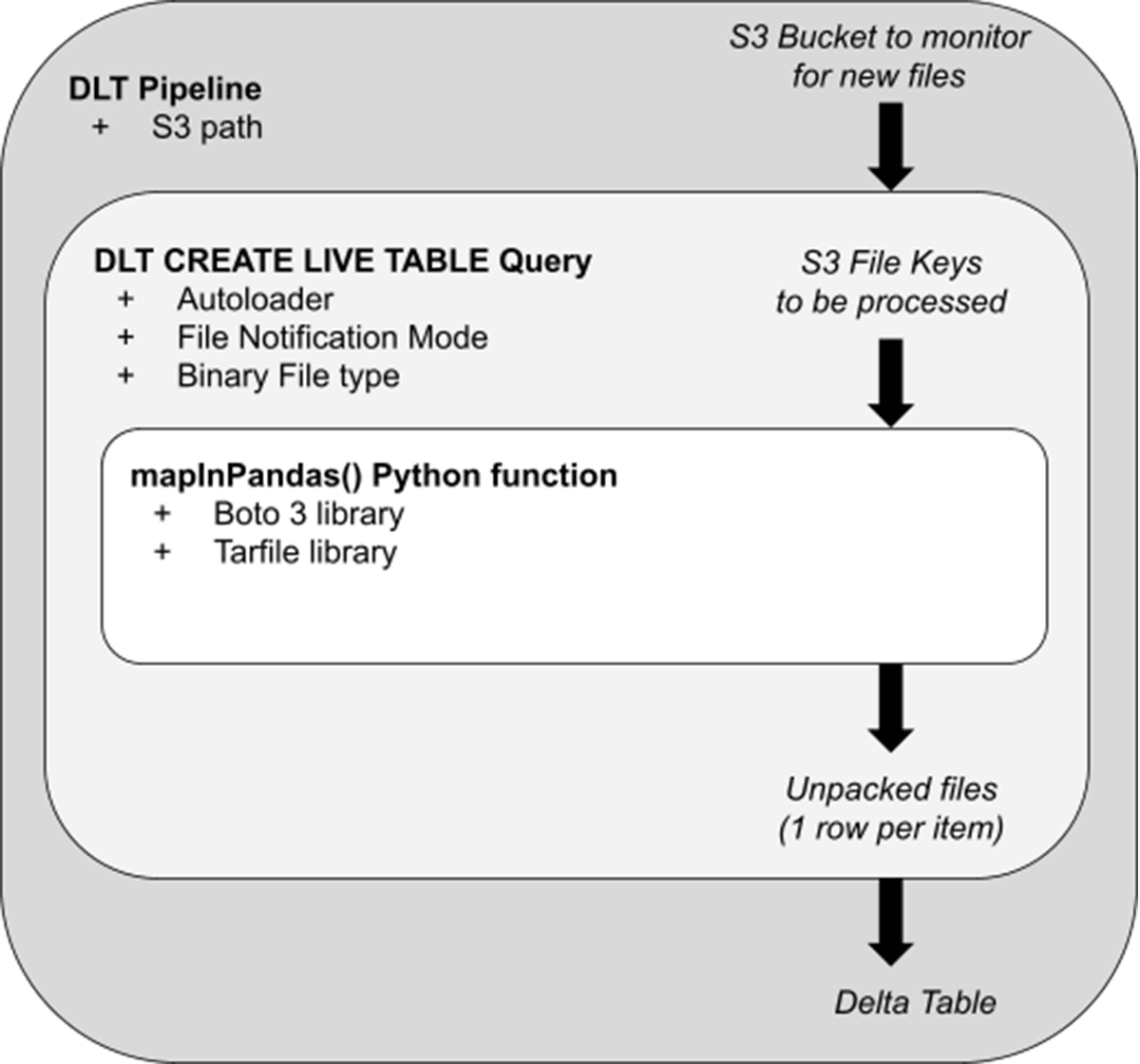
- 델타 라이브 테이블(DLT) 파이프라인은 언패킹 및 기타 로직을 위한 오케스트레이션 계층 역할을 합니다. 프로덕션 모드에서 이 스트리밍 파이프라인은 S3에 도착하는 새 Tar 파일을 선택하여 압축을 해제합니다. Photon을 사용하지 않은 파이프라인에 대한 사전 테스트에서 기본 DLT 클러스터 설정으로 최대 430Mb의 Tar 파일을 클러스터에 메모리 부담을 주지 않고 빠르게 처리(배치당 30초 미��만)했습니다. 향상된 자동 확장 기능을 사용하면 각 작업자가 압축 풀기를 병렬로 실행하기 때문에 DLT 클러스터는 들어오는 파일 볼륨에 맞게 확장 및 축소됩니다.
- 파이프라인 내에서 “CREATE STREAMING TABLE” 쿼리는 파이프라인이 수집하는 S3 경로를 지정합니다. File Notification 모드를 사용하면 파이프라인은 도착하는 새 Tar 파일 목록을 효율적으로 수신하고, 압축을 풀기 위해 해당 파일 “Key”를 전달합니다.
- mapInPandas() 함수에 전달되는 파일 목록은 판다 데이터 프레임의 Iterator 형태로 처리할 파일 목록입니다. 표준 boto3 라이브러리와 tar 전용 Python 처리 라이브러리(Tarfile)를 사용하여 각 파일의 압축을 풀고 모든 원시 이메일에 대해 하나의 반환 행을 생성합니다.
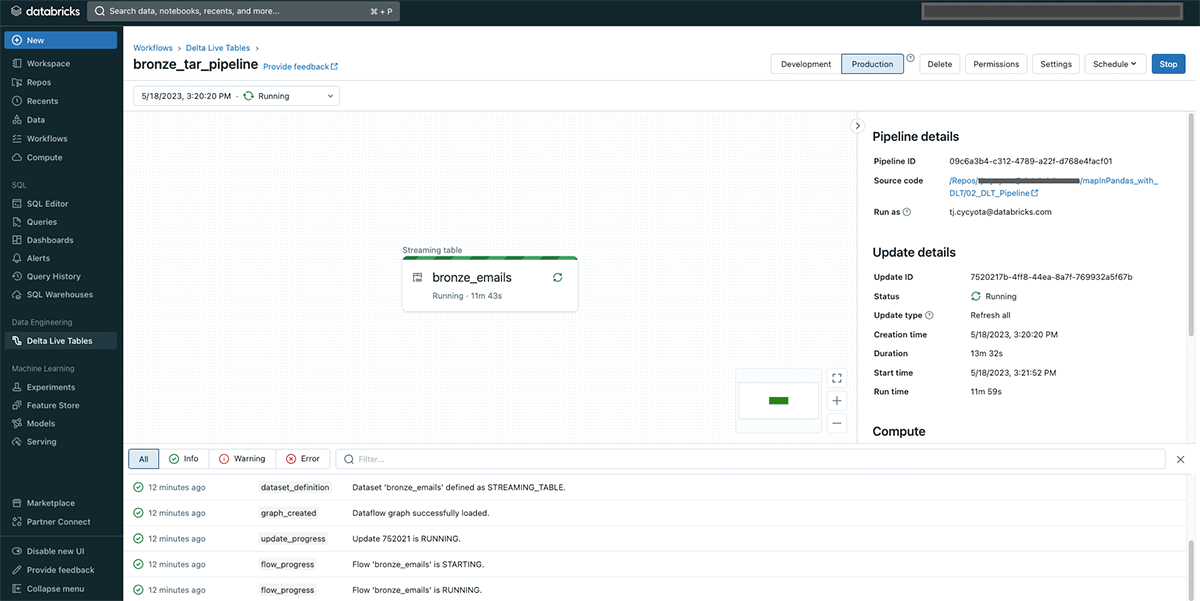
최종 결과물은 이메일 데이터가 포함된 분석이 가능한 델타 테이블이며, 데이터브릭스 SQL 또는 노트북에서 쿼리할 수 있으며, email_id 열을 통해 압축이 풀린 각 이메일을 고유하게 식별할 수 있습니다:
이 솔루션을 보여주는 노트북에는 파이프라인 구성 설정뿐만 아니라 전체 mapInPandas() 로직이 포함되어 있습니다. 여기에서 확인하세요.
추가적인 활용방법
여기에 설명된 접근 방식을 통해 중요한 비즈니스 애플리케이션을 위해 짧은 지연 시간으로 Tar 이메일 파일을 처리할 수 있는 확장 가능한 솔루션을 갖추게 되었습니다. 기본 코드를 변경하지 않고도 파이프라인을 연속에서 트리거로 전환할 수 있기 때문에 파일 도착 시점에 맞춰 델타 라이브 테이블을 신속하게 조정할 수 있습니다. 이 예에서는 S3에서 원시 파일을 수집하는 ‘bronze 계층에 중점을 두었지만, 이 파이프라인은 정리, 강화, 집계 단계를 통해 쉽게 확장하여 비즈니스 사용자와 머신 러닝 애플리케이션이 이 귀중한 데이터 소스를 사용할 수 있도록 할 수 있습니다.
하지만 보다 일반적으로 이 mapInPandas() 접근 방식은 Spark를 사용하기 어려운 모든 파일 처리 작업에 잘 작동합니다:
- Spark에서 지원되지 않는 코덱/포맷이 없는 파일 수집하기
- 파일 이름에 파일 형식이 없는 파일 처리:
file123이 실제로는 "tar" 형식의 파일이지만 .tar.gz 파일 확장자없이 저장된 경우 - Zstandard 압축 알고리즘과 같이 독점적이거나 잘 사용하지 않은 확장자를 가진 파일 처리: MapInPandas 함수의 가장 안쪽 루프를 행을 내보내는 데 필요한 Python 라이브러리로 바꾸기만 하면 됩니다.
- 메모리 부족 없이 대용량, monolithic 또는 비효율적으로 저장된 파일을 데이터프레임 행으로 분해합니다.
델타 라이브 테이블 노트북의 더 많은 예는 여기에서 확인하시거나, 고객들이 프로덕션에서 DLT를 어떻게 사용하고 있는지 여기에서 확인하세요.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.