10 Billionen Stichproben pro Tag: Skalierung über traditionelle Monitoring-Infrastruktur hinaus bei Databricks
Wie wir eine Überwachungsplattform für das exponentielle Wachstum von Databricks entwickelt haben
von David Yuan, Yi Jin, Karan Bavishi, HC Zhu und Joey Beyda
- Die Überwachungssysteme von Databricks verwalten über 5 Milliarden aktive Zeitreihen in Echtzeit über AWS, Azure und GCP.
- Um diese Systeme trotz schneller Skalierung zuverlässig und wartungsarm zu halten, haben wir unsere TSDB- und Aggregationsebenen durch Anpassung von Open-Source-Überwachungslösungen neu konzipiert.
- Angesichts des starken Wachstums bei Metriken zur Fehlerbehebung mit hoher Kardinalität haben wir eine neuartige, auf dem Lakehouse basierende Plattform namens Hydra entwickelt. Dieser Ansatz hat umfangreiche Debugging-Funktionen in massivem Maßstab und 50-mal günstigere Speicherung als unser bestehender Stack ermöglicht.
Die Überwachungsinfrastruktur von Databricks hat sich im letzten Jahr mehr als verdreifacht. Sie erfasst jetzt 5 Milliarden aktive Zeitreihen in Echtzeit und verarbeitet über 10 Billionen Stichproben pro Tag. Bei dieser massiven Skalierung stellten wir fest, dass Standardlösungen ineffizient oder schwer an unsere Anforderungen anzupassen waren. Dieser Beitrag beschreibt, was wir stattdessen entwickelt haben: eine skalierbare Plattform, die das Beste aus dem Open-Source-Monitoring-Ökosystem nutzt und gleichzeitig Anpassungen für unsere einzigartigen Bedürfnisse integriert.
Ingenieure bei Databricks sind auf Überwachungssysteme angewiesen, die uns schnell über Probleme informieren, Skalierungen und Rollbacks automatisieren und intelligente Fehlerbehebung ermöglichen. Diese Systeme müssen hochgradig zuverlässig sein, damit wir sicher sein können, dass wir während eines potenziellen Vorfalls nicht im Dunkeln tappen. Die Entwicklung dieser Infrastruktur für die Databricks-Skalierung war jedoch keine leichte Aufgabe:
- Neben den Anforderungen an Skalierbarkeit, Zuverlässigkeit und Effizienz betreiben wir unsere Systeme weltweit in rund 70 Cloud-Regionen über jede der 3 großen Clouds. Wir müssen trotz Unterschieden zwischen den Clouds und sogar einzelnen Regionen eine gleichwertige Leistung erzielen.
- Angesichts dieser Breite und Vielfalt kann der Betrieb einer großen Infrastruktur schnell unhaltbar werden. Das System muss so "hands-off" wie möglich sein – selbstheilend und selbsterskalierend, anstatt dass unsere Oncalls jeden regionalen Stack direkt verwalten – und dennoch einfache Schnittstellen für Benutzer bieten.
- Mit dem Wachstum von Serverless- und KI-Workloads bei Databricks ist die Fluktuation in unserer Infrastruktur sprunghaft angestiegen, was zu schnellen Erhöhungen der Kardinalität von Metriken führte. Wir konnten hochgradig kardiologische Überwachungsdaten nicht mehr wie bisher verarbeiten und speichern, aber wir wollten die Debugging-Workflows, auf die sich die Ingenieure verlassen, weiterhin beibehalten.
Angesichts dieser Herausforderungen litt der alte Überwachungsstack von Databricks unter Zuverlässigkeitsproblemen. Wir machten uns daran, eine neue, zuverlässige Plattform zu entwickeln, die den Erwartungen unserer Ingenieure gerecht wird. Seitdem haben wir 3 Schlüsselprobleme gelöst:
- Architektur einer zuverlässigen und effizienten Zeitreihendatenbank (TSDB)
- Einführung von Metrikaggregationen zum Schutz von TSDBs vor Kardinalität
- Ermöglichung einer hochgradig dimensionalen Fehlerbehebung mit dem Databricks Lakehouse
Thanos Zeitreihendatenbanken
Was sind TSDBs?
TSDBs sind eine Kernkomponente traditioneller Überwachungssystemarchitekturen. Diese spezialisierten Datenbanken sind darauf ausgelegt, große Mengen von Zeitreihenmetrikdaten aufzunehmen und Lesezugriffe mit hoher QPS und geringer Latenz in Echtzeit zu bedienen. Sie sind besonders optimal für Abfragemuster im Monitoring wie Alarme und Dashboard-Aktualisierungen, die das wiederholte Ausführen derselben Abfragen und das Erhalten blitzschneller Ergebnisse basierend auf den neuesten Daten erfordern.
Die alten TSDBs von Databricks waren für eine um eine Größenordnung geringere Skalierung ausgelegt und wurden in den letzten Jahren zu einem großen Engpass für uns. Tatsächlich war das Hauptproblem für die Zuverlässigkeit der gesamten Überwachungsinfrastruktur die Schwierigkeit, unsere TSDBs zu skalieren. Dies ist für viele andere Unternehmen ein seltenes Unterfangen, aber angesichts des exponentiellen Wachstums von Databricks mussten wir dies fast täglich tun.
Daher entwickelten wir eine neue TSDB mit dem Codenamen Pantheon, die ein Fork des Open-Source-Projekts Thanos der CNCF ist. Wir haben erfolgreich auf über 160 Thanos-Instanzen in allen Regionen von drei Cloud-Anbietern skaliert, mit insgesamt rund 5 Milliarden aktiven In-Memory-Zeitreihen und über 10 Billionen täglich aufgenommenen Stichproben. Unsere größte Instanz beherbergt etwa 300 Millionen In-Memory-Zeitreihen und unterstützt fast 1.000 PromQL-Abfragen pro Sekunde; wir betreiben auch kleine 3-Knoten-Bereitstellungen und alles dazwischen. Aufgrund der Breite, Skalierung und Vielfalt unserer Bereitstellungen stoßen wir oft auf Thanos-Randfälle und Leistungsoptimierungen und tragen diese zur Open-Source-Community zurück.
Die Migration zu Pantheon hat uns ermöglicht, Millionen von Dollar an jährlichen Cloud-Kosten einzusparen, während die Ausfallzeiten der Überwachungsinfrastruktur um das ~5-fache reduziert und viele Quellen manueller Arbeit eliminiert wurden. Die Architektur von Pantheon ist unten dargestellt, und die folgenden Abschnitte erläutern mehrere wichtige Designentscheidungen, die diese Erfolge ermöglicht haben.
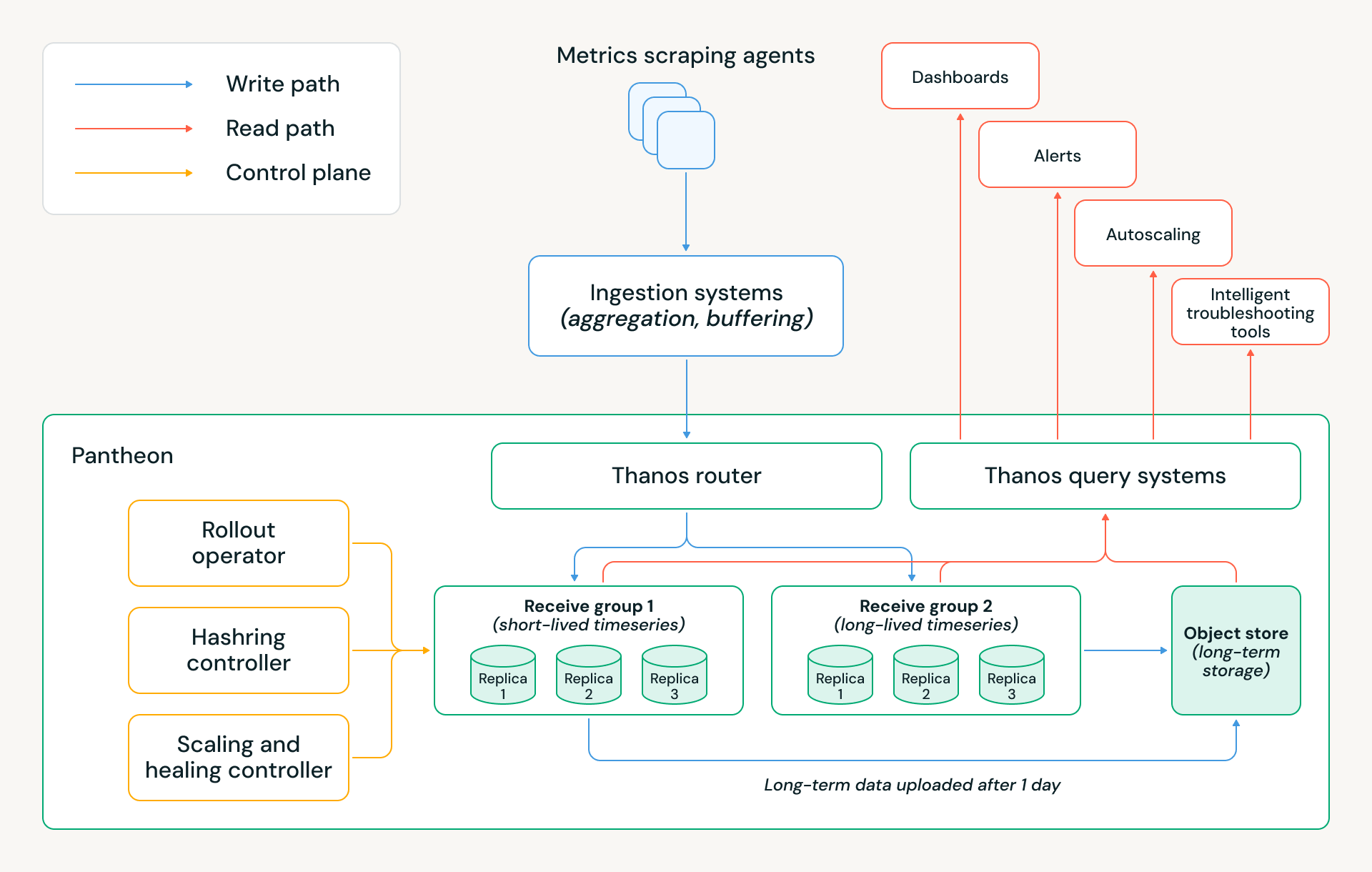
Speicherarchitektur
Ein Schlüsselelement von Thanos ist seine gestufte Speicherarchitektur. Die neuesten Zeitreihen werden im Speicher gehalten, die Zeitreihen der letzten 24 Stunden werden auf der Festplatte gespeichert und alle älteren Daten werden im Objektspeicher aufbewahrt. Das bedeutet, dass Alarme und andere Echtzeitabfragen strenge Leistungsanforderungen erfüllen können, da sie typischerweise von den neuesten Daten abhängen. Gleichzeitig ermöglicht die Nutzung von Objektspeicher die Entkopplung von Compute und Speicher; ein Cluster kann hochskaliert werden, ohne alle seine historischen Daten über die Datenbankknoten neu verteilen zu müssen.
Diese Architektur hat unseren wichtigsten Engpass (Scale-ups) behoben und die Grundlage für die Kosteneinsparungen von Pantheon gelegt. Wir haben mehrere weitere Optimierungen vorgenommen:
- Speicherbeibehaltung: Wir setzen zwei Receive-Gruppen mit unterschiedlichen Speicherbeibehaltungsrichtlinien ein: eine optimiert für langlebige Zeitreihen von persistenten Diensten, die zwei Stunden Stichproben im Speicher hält, und eine andere, die für kurzlebige Zeitreihen von den ephemeren Workloads von Databricks optimiert ist und nur 30 Minuten im Speicher hält. Diese Aufteilung spiegelt die Lebensdauer wider, die wir für Serverless-Workloads bei Databricks beobachtet haben, und reduziert den Speicherbedarf und die Cloud-Kosten erheblich, während die Korrektheit erhalten bleibt.
- Receive-Gruppenstruktur: Jede Gruppe wird absichtlich als drei isolierte Kubernetes StatefulSets implementiert, die drei Replikaten entsprechen, anstatt als ein einzelner großer Hash-Ring. Dieses Design bewahrt die dreifache Replikation mit Quorum-Schreibvorgängen und bietet gleichzeitig eine stärkere operative und Datenisolation. Diese Konfiguration ermöglicht es uns, ein gesamtes StatefulSet während Releases oder Knotenrotationen parallel zu aktualisieren oder neu zu starten, ohne das Quorum zu verletzen oder die Schreibverfügbarkeit zu beeinträchtigen, was den täglichen Betrieb erheblich vereinfacht.
- Multitenancy: Pantheon nutzt die Thanos-Multitenancy, um getrennte Mandantensätze über Receive-Gruppen hinweg zu hosten. Auf der Router-Ebene wenden wir regelbasierte Mandantenattribution an und leiten den Mandanten für jede Datenstichprobe ab, indem wir den Metriknamen und ausgewählte Labels inspizieren. Dies ermöglicht es, Stichproben innerhalb desselben Schreibbatches an verschiedene Mandanten – und damit an verschiedene Receive-Gruppen – zu leiten, ohne Änderungen am Upstream-Client vornehmen zu müssen.
- At-least-once-Uploads: Um die Kosten weiter zu optimieren und die Korrektheit zu gewährleisten, laden nur zwei der drei StatefulSets Blöcke in den Objektspeicher hoch. Dies reduziert redundanten Upload-Verkehr und Cloud-Speicherkosten, während die Datenhaltbarkeit und Konsistenzgarantien durch Replikation und Quorum-Semantik aufrechterhalten werden.
Pantheon Control Plane
Bei unserer globalen Skalierung reichen manuelle Operationen, Best-Effort-Kubernetes-Automatisierung oder Vanilla-Thanos-Verhalten nicht aus. Jede Freigabe, jedes Skalierungsereignis oder jeder Hostausfall muss sicher, automatisch und mit minimalem menschlichen Eingriff gehandhabt werden, während das Quorum und die Datenverfügbarkeit erhalten bleiben. Um dies zu erreichen, führt Pantheon eine speziell entwickelte Control Plane ein, die für die Orchestrierung des Lebenszyklus und der Kapazitätsentscheidungen der Thanos-Komponenten verantwortlich ist. Sie besteht aus drei Schlüsselcontrollern:
- Rollout Operator: Koordiniert Releases und Skalierungen über drei isolierte Receive StatefulSets hinweg und garantiert das Quorum für Lese- und Schreibvorgänge. Er ermöglicht schnellere Releases durch parallele StatefulSet-Updates und stellt sicher, dass zu keinem Zeitpunkt mehr als eine Replik verfügbar ist.
- Hashring Controller: Verwaltet, welche Receive-Endpunkte für den Router sichtbar sind. Nur fehlerfreie, vollständig bereite Pods werden dem Hashring hinzugefügt, und Entfernungen werden während des Scale-downs oder der Wartung gestaffelt. Dies entkoppelt die Verkehrsverwaltung vom Pod-Lebenszyklus und verhindert versehentliche Quorum-Verletzungen oder Teil-Routing während dynamischer Clusteränderungen.
- Autoscaling and Self-Healing Controller: Skaliert Cluster basierend auf Pantheon-spezifischem Ingestions- und Ressourcendruck anstelle von generischen Kubernetes-Signalen. Ein integriertes Heiler-System erkennt und behebt kontinuierlich gängige Fehlermodi – wie fehlerhafte Hosts, überlastete Pods oder beschädigte WALs – und ermöglicht es dem System, sich ohne Eingreifen des Operators selbst zu erholen. In unserer Größenordnung greifen diese Automatisierungen Dutzende Male pro Woche.
Kardinalität und Aggregation
Was ist Kardinalität und warum ist sie wichtig?
Metrikbesitzer fügen oft Labels wie Knoten-ID oder Pod-ID hinzu, um Probleme mit bestimmten Dimensionen zu debuggen und Vorfälle schneller zu beheben. Dies führt jedoch zu einer klassischen Herausforderung der Beobachtbarkeit: der Verwaltung der Kardinalität. Die Kardinalität einer Metrik ist die Anzahl der eindeutigen Kombinationen ihrer Labels. Wenn sich die Anzahl der von Ihnen überwachten Pods verzehnfacht, verzehnfacht sich auch die Kardinalität jeder Metrik mit einem Pod-ID-Label. Die Kardinalität ist der primäre Skalierungsfaktor für eine TSDB, und das Wachstum der Kardinalität bestehender Metriken erhöht die Kosten und den Skalierungsdruck auf Pantheon.
Schnelles Infrastrukturwachstum ist eine Herausforderung, mit der wir bei Databricks gesegnet sind. Gleichzeitig mit dem signifikanten Wachstum unserer Kundenbasis und der Produktnutzung haben viele Kunden kürzlich unsere Serverless-Computing-Architektur übernommen, und unsere Serverless-Compute-Plattform startet täglich zig Millionen VMs. Da immer mehr Workloads zu Serverless migriert werden, wird die Infrastruktur, die wir überwachen, immer kurzlebiger, und die Lebensdauer dieser Identifikations-Labels wird immer kürzer.
Dies hat dazu geführt, dass die Kardinalität explodiert ist und die Skalierbarkeits- und Kostenvorteile von Pantheon aufgefressen hat. Daher mussten wir viel intelligenter werden, welche Metrikdaten wir speichern. Hier kam die „Aggregation“ ins Spiel: das Entfernen teurer Labels von Serverless-Systemen während der Aufnahme, während gleichzeitig eine aggregierte, unternehmensweite Ansicht für Servicebesitzer bereitgestellt wird. Eine automatisierte Aggregationsstrategie für Metriken hat es uns ermöglicht, die Kurve des Kardinalitätswachstums zu „biegen“ und sicherzustellen, dass die Überwachungsinfrastruktur nicht schneller skalieren muss als der Rest von Databricks.
Aggregationsarchitektur
Der Aufbau einer zuverlässigen Aggregationsinfrastruktur im großen Maßstab ist schwierig, da sie zustandsbehaftet ist. Aggregatoren, die Millionen von Eingabezählern verwalten, müssen in der Lage sein, Zurücksetzungen korrekt zu handhaben – wenn eine Eingabe-Zeitreihe verschwindet, sollte der aggregierte Ausgabewert weiterhin monoton steigen, anstatt abzufallen. Da Metriken über Aggregatoren partitioniert sind, müssen Sie auch Szenarien wie Pod-Neustarts und Lastungleichgewichte handhaben.
Diese Probleme werden oft durch die Verwendung eines Messaging-Systems wie Kafka für Partitionierungszuweisungen und die Pflege vorheriger Daten gelöst; dies ist in unserem Maßstab kostspielig und erhöht die Aufnahmeverzögerung, die Echtzeit-Anwendungsfälle beeinträchtigt. Der alternative Ansatz besteht darin, den In-Memory-Zustand in Aggregatoren zu speichern und Metriken zwischen Aggregatoren umzuleiten, um die Zuweisung zu honorieren. Dies führt jedoch zu Datenverlust, wenn ein Aggregator neu bereitgestellt wird; in einer anfänglichen Version unserer Aggregationsinfrastruktur machte dieses Verhalten aggregierte Metriken für unsere Benutzer fast unverständlich.
Um dies nahtlos zu ermöglichen, haben wir stattdessen unser eigenes Aggregationssystem mit Telegraf und dem Databricks „Auto-Sharder“-Dienst Dicer entwickelt. Diese Architektur verwendet eine intelligente Sticky-Routing-Methode anstelle des Umleitens von Metriken zwischen Aggregatoren, was die Fehlerfälle bei der Neukonfiguration behoben hat. Mit anderen Optimierungen, die wir auf Telegraf aufgesetzt haben, konnten wir die Pipeline in unserer größten Region auf über 1 GB/s und Tausende von Aggregationsregeln skalieren.
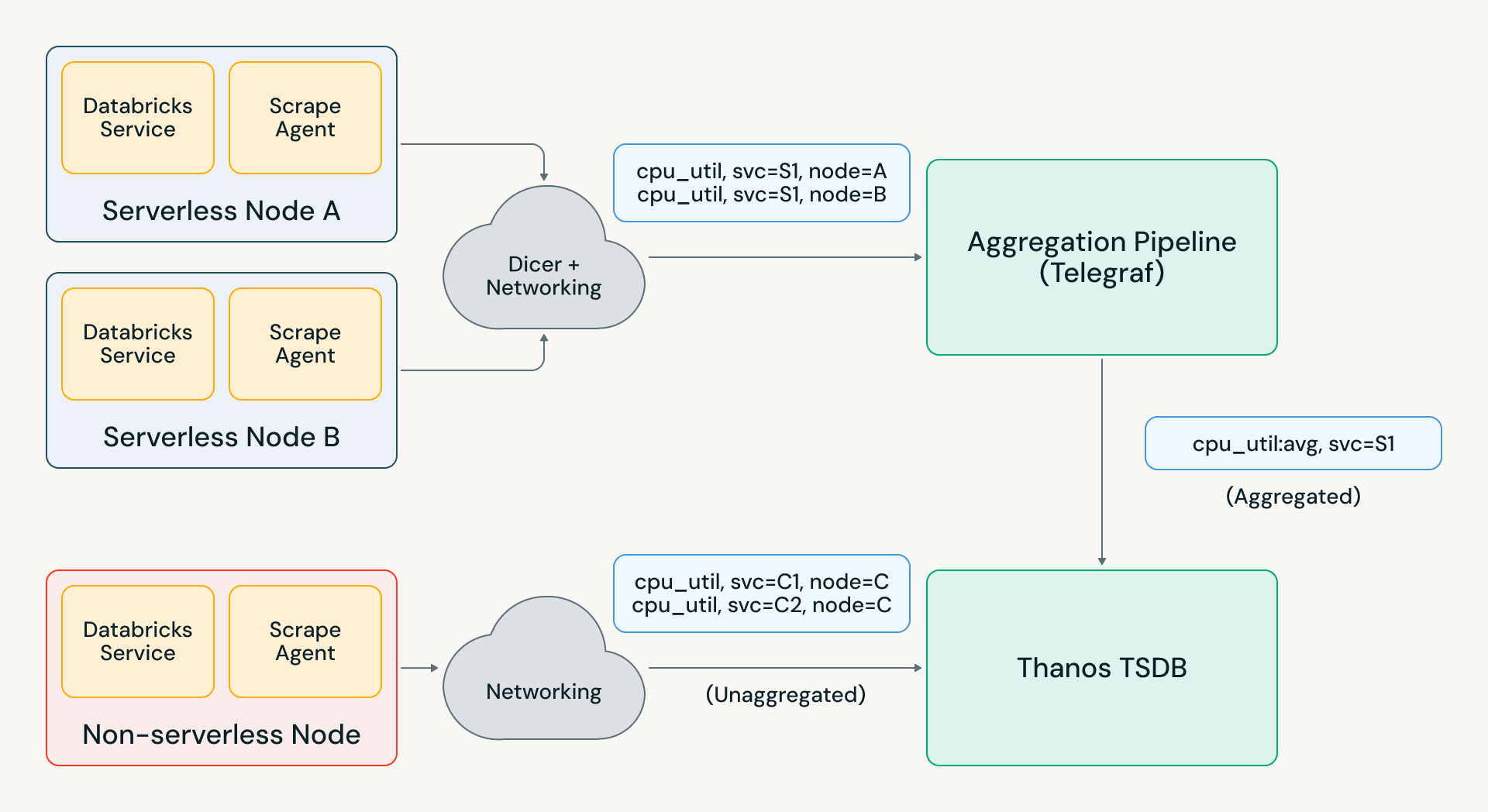
Diese neue Aggregationspipeline wurde effektiv zum Schutzschild, der unsere TSDBs vor langfristigem Kardinalitätswachstum sowie unerwarteten Metrikspitzen schützt. Beispielsweise führte ein kürzlicher Vorfall in der Databricks-Infrastruktur zu einem 2- bis 5-fachen Anstieg der Metrik-Last in verschiedenen Regionen. Telegraf absorbierte den Großteil dieser Last, und Pantheon verzeichnete nur einen Anstieg von 20 %, wodurch Ingenieure im gesamten Unternehmen Debugging- und Alarmabfragen ohne Auswirkungen durchführen konnten.
Hochkardinale Daten auf dem Lakehouse
Das Problem mit der Aggregation
Unsere Aggregationsinfrastruktur ermöglicht es uns, Pantheon vor exponentiellem Kardinalitätswachstum zu schützen, aber das hat seinen Preis – sie entfernt genau die Dimensionen, die Ingenieure bei Vorfällen benötigen. Betrachten Sie eine globale Flotte mit:
- Millionen aktiver Knoten in den letzten 2 Stunden
- Mehrere Mandanten pro Knoten
- Kurzlebige Workloads
- Schnelles Autoscaling
Aggregierte Metriken sagen Ihnen:
- Die CPU-Auslastung auf Regionsebene ist erhöht
- Die Latenz auf Serviceebene steigt sprunghaft an
Aber sie sagen Ihnen nicht:
- Welcher Mandant den Swap-Druck verursacht
- Welcher Knoten abgestürzt ist
- Welcher Shard isoliert ist
- Welcher Workload „noisy“ ist
Databricks-Ingenieure benötigten immer noch eine Lösung zur Fehlerbehebung bei Workloads, die auf diesen hochkardinalen Labels basierten. Diese „Nadel im Heuhaufen“-Szenarien erforderten die effiziente Speicherung und Verarbeitung riesiger Datenmengen, was Pantheon nicht konnte. Um diese Anwendungsfälle zu unterstützen, suchten wir nach einer anderen Speicherarchitektur, die nicht durch Kardinalitätswachstum begrenzt wäre.
Der Lakehouse kommt ins Spiel!
Unsere wichtigste Erkenntnis: Der Databricks Lakehouse ist perfekt dafür geeignet! Er entkoppelt Speicher (günstiger Objektspeicher + Delta Lake) von Rechenleistung (Streaming + Abfragecluster) und ist in beiden Dimensionen massiv skalierbar.
Mit den besten Fähigkeiten von Databricks haben wir eine neue Plattform für rohe Fehlerbehebungsdaten namens Hydra entwickelt, die hochkardinale Debugging-Funktionen in massivem Maßstab ermöglicht hat. Hydra nimmt 20 Milliarden unaggregierte, aktive Zeitreihen von Millionen von Knoten weltweit auf, erreicht eine End-to-End-Datenaktualität von 5 Minuten und eine 50-mal günstigere Datenspeicherung als Thanos.
Diese Erfolge wurden durch Hydras Lakehouse-natives Design ermöglicht:

- Wir verwenden Apache Spark™ Structured Streaming auf Databricks, um kontinuierliche Aufnahmejobs auszuführen, die Metrikdaten inkrementell verarbeiten, sobald sie eintreffen, und sie in Delta Lake schreiben. Structured Streaming ermöglicht es Ihnen, Streaming-Berechnungen genauso auszudrücken, wie Sie Batch-Jobs schreiben, jedoch mit kontinuierlicher, inkrementeller Verarbeitung und Exactly-Once-Semantik für eine zuverlässige Aufnahme.
- Um Millionen von Objektspeicherdateien effizient zu entdecken und aufzunehmen, nutzen wir Databricks Auto Loader, eine Hochdurchsatz-Structured-Streaming-Quelle, die neue Dateien verfolgt und inkrementell verarbeitet, ohne dass eine manuelle Auflistung oder Zustandsverwaltung erforderlich ist. Auto Loader speichert automatisch Metadaten über entdeckte Dateien und skaliert, um Ankunftsraten nahezu in Echtzeit zu bewältigen.
- Wir partitionieren die Aufnahme auch nach Regionen und setzen unabhängige Streaming-Jobs über verschiedene geografische Gebiete hinweg ein. Dies ermöglicht es jeder Pipeline, unabhängig zu skalieren, minimiert die Latenz zwischen Regionen und reduziert den Schadensradius im Falle von Ausfällen. Zusammen ermöglichen diese Designentscheidungen, dass rohe Metrikdaten innerhalb von Minuten nach der Erstellung abfragbar sind, selbst bei einem Volumen von mehreren Milliarden Serien, während die Dashboard-Systeme performant bleiben.
Vereinheitlichte Schnittstellen
Der Aufbau von Hydra war nicht nur eine Infrastrukturherausforderung, sondern auch eine Herausforderung im Schnittstellendesign. Von Anfang an haben wir Hydra um kritische Benutzerreisen (CUJs) für unsere Ingenieure herum entworfen und nicht um Speicherschichten oder Aufnahme-Pipelines. Unser Ziel war einfach: Ingenieure sollten mit hochkardinalen Metriken über dieselben Schnittstellen arbeiten können, auf die sie bereits angewiesen sind.
Abfrage über Grafana
Die meisten Ingenieure beginnen ihren Debugging-Workflow in Grafana. Sie erwarten, PromQL zu schreiben, vorhandene Dashboards zu verwenden, in Labels zu bohren und während Vorfällen schnell zu wechseln.
Um diesen Workflow zu erhalten, integriert sich Hydra direkt mit Grafana, indem es die Ausführung von PromQL-Abfragen gegen in Databricks gespeicherte Daten ermöglicht. Wir haben eine PromQL-zu-SQL-Konvertierungsschicht erstellt, die PromQL-Ausdrücke in SQL-Abfragen übersetzt, die auf Delta-Tabellen im Lakehouse ausgeführt werden. Dieser Ansatz ermöglicht es Ingenieuren, die vertraute PromQL-Syntax und Dashboards ohne Änderungen weiter zu verwenden. Gleichzeitig werden die zugrunde liegenden Abfragen gegen groß angelegte Delta-Tabellen und nicht gegen eine In-Memory-TSDB ausgeführt.
Direkter SQL-Zugriff in Databricks
Während Grafana ideal für das Live-Debugging ist, erfordern einige Untersuchungen eine tiefere Analyse. Ingenieure müssen möglicherweise Metriken mit Deployment-Metadaten verknüpfen, Metriken mit Protokollen korrelieren, breite Zeitbereichsscans durchführen, Anomalieerkennung durchführen oder Datensätze für erweiterte Analysen exportieren.
Hydra stellt die zugrunde liegenden Delta-Tabellen auch direkt in Databricks bereit. Ingenieure können diese Tabellen mit Databricks SQL oder Notebooks abfragen, was flexible Analysen ermöglicht, die über herkömmliche Überwachungsworkflows hinausgehen.
Da die Daten im Lakehouse liegen, können sie mit anderen Unternehmensdatensätzen verknüpft und unter denselben Sicherheits- und Zugriffskontrollen verwaltet werden. Dies verwandelt Observability-Daten in ein erstklassiges Analyse-Asset und nicht in ein isoliertes Monitoring-Silo.
Vereinheitlichte Metrik-Semantik
Ein wichtiges Designprinzip von Hydra ist, dass Ingenieure unsere Ingestion-Architektur nicht verstehen müssen. Unabhängig davon, ob auf eine Metrik über den TSDB-basierten aggregierten Pfad oder den Lakehouse-basierten Rohmetrikpfad zugegriffen wird, bleibt die Schnittstelle konsistent.
Metrik-Namen, Label-Semantiken und Metadaten-Dimensionen sind über Umgebungen hinweg vereinheitlicht. Service-Teams geben Metriken einmal über eine standardisierte Schnittstelle aus. Die Plattform kümmert sich um Aggregation, Rohdatenspeicherung, Ingestion, Speicherung und Abfrage-Routing. Dieses einheitliche Modell reduziert den kognitiven Aufwand und eliminiert die Notwendigkeit für Teams, separate Konfigurationen für verschiedene Observability-Backends zu verwalten.
Zukünftig arbeiten wir daran, die Leistung von Hydra zu verbessern, damit es eine ähnliche Datenaktualität wie Pantheon erreicht und sich die beiden Erfahrungen noch weiter annähern.
Wichtige Erkenntnisse
Um die Databricks Monitoring-Infrastruktur zu skalieren, mussten wir auf Zuverlässigkeit, Effizienz, Bedienbarkeit und Entwicklerfreundlichkeit optimieren. „Skalieren“ bedeutete für uns mehr als nur die Vergrößerung unserer Deployments. Es bedeutete:
- Einbau von Resilienz und Automatisierung in unsere grundlegende Architektur, um einen „hands-off“-Betrieb für diese globalen und sich ständig ändernden Systeme zu erreichen
- Überdenken aus erster Hand, welche Systeme für verschiedene Monitoring-Anwendungsfälle notwendig waren, von der Alarmierung über die Fehlerbehebung bis hin zur Analyse über Datenquellen hinweg
- Weiterentwicklung unserer Architektur, da sich der Rest der Databricks-Infrastruktur parallel zu uns transformiert hat
Dies werden für uns niemals endende Reisen sein, und sie sind beispielhaft dafür, warum Infrastruktur-Engineering ein so dynamischer Bereich bei Databricks ist. Wenn Sie gerne schwierige technische Probleme lösen und uns auf dieser Reise begleiten möchten, besuchen Sie databricks.com/careers!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.