Open-Sourcing von Dicer: der Auto-Sharder von Databricks
Aufbau hochverfügbarer geshardeter Dienste im großen Scale für hohe Performance und niedrige Kosten
von Atul Adya, Colin Meek, Jonathan Ellithorpe, Vivek Jain und Yongxin Xu
- Open Sourcing von Dicer: Wir stellen Dicer offiziell als Open Source zur Verfügung – das grundlegende Auto-Sharding-System, das bei Databricks zur Erstellung schneller, skalierbarer und hochverfügbarer Sharded-Dienste eingesetzt wird.
- Das Was und Warum von Dicer: Wir beschreiben die Probleme der heute typischen Dienstarchitekturen, warum Auto-Sharder benötigt werden, wie Dicer diese Probleme löst und diskutieren seine Kernabstraktionen und Anwendungsfälle.
- Erfolgsgeschichten: Das System treibt derzeit geschäftskritische Komponenten wie den Unity Catalog und unsere SQL-Query-Orchestrierungs-Engine an, wo es Verfügbarkeitseinbrüche erfolgreich beseitigt und Cache-Trefferquoten von über 90 % bei Pod-Neustarts aufrechterhalten hat.
1. Ankündigung
Heute freuen wir uns, die Veröffentlichung einer unserer wichtigsten Infrastrukturkomponenten als Open Source bekannt zu geben: Dicer, der Auto-Sharder von Databricks. Dies ist ein grundlegendes System, das für den Aufbau von skalierbaren und hochzuverlässigen Sharded-Diensten mit geringer Latenz entwickelt wurde. Es arbeitet im Hintergrund jedes wichtigen Databricks-Produkts und ermöglicht es uns, eine durchgehend schnelle Benutzererfahrung zu bieten, während gleichzeitig die Effizienz der Flotte verbessert und die Cloud-Kosten gesenkt werden. Dicer erreicht dies durch die dynamische Verwaltung der Sharding-Zuweisungen, um die Dienste auch bei Neustarts, Ausfällen und wechselnden Workloads reaktionsschnell und resilient zu halten. Wie in diesem Blogpost beschrieben, wird Dicer für eine Vielzahl von Anwendungsfällen verwendet, darunter Performance-Serving, Arbeitsaufteilung, Batching-Pipelines, Datenaggregation, Mandantenfähigkeit, Soft-Leader-Election, effiziente GPU-Auslastung für KI-Workloads und mehr.
Indem wir Dicer der breiteren Community zur Verfügung stellen, freuen wir uns auf die Zusammenarbeit mit Industrie und Wissenschaft, um den Stand der Technik beim Aufbau robuster, effizienter und hochperformanter verteilter Systeme voranzutreiben. Im Rest dieses Beitrags erörtern wir die Motivation und die Designphilosophie hinter Dicer, teilen Erfolgsgeschichten aus dem Einsatz bei Databricks und geben einen Leitfaden, wie Sie das System selbst installieren und damit experimentieren können.
2. Motivation: Über zustandslose und statisch geshardete Architekturen hinausgehen
Databricks bietet eine schnell wachsende Suite von Produkten für Datenverarbeitung, Analytics und KI an. Um dies in Scale zu unterstützen, betreiben wir Hunderte von Diensten, die einen massiven Zustand verwalten und dabei reaktionsfähig bleiben müssen. In der Vergangenheit hatten sich Databricks-Ingenieure auf zwei gängige Architekturen verlassen, aber beide verursachten mit dem Wachstum der Dienste erhebliche Probleme:
2.1. Die versteckten Kosten von zustandslosen Architekturen
Die meisten Dienste bei Databricks begannen mit einem zustandslosen Modell. In einem typischen zustandslosen Modell behält die Anwendung keinen In-Memory-Zustand über Anfragen hinweg bei und muss die Daten bei jeder Anfrage erneut aus der Datenbank lesen. Diese Architektur ist von Natur aus kostspielig, da jede Anfrage einen Datenbankzugriff verursacht, was sowohl die Betriebskosten als auch die Latenz in die Höhe treibt [1].
Um diese Kosten zu mindern, führten Entwickler oft einen Remote-Cache (wie Redis oder Memcached) ein, um die Datenbank zu entlasten. Obwohl dies den Durchsatz und die Latenz verbesserte, konnten dadurch mehrere grundlegende Ineffizienzen nicht behoben werden:
- Netzwerklatenz: Jede Anfrage zahlt immer noch die "Steuer" von Netzwerk-Hops zur Caching-Schicht.
- CPU-Overhead: Erhebliche Zyklen werden für die (De-)Serialisierung verschwendet, während Daten zwischen dem Cache und der Anwendung verschoben werden [2].
- Das „Overread“-Problem: Zustandslose Dienste rufen oft ganze Objekte oder große Blobs aus dem Cache ab, nur um einen kleinen Teil der Daten zu verwenden. Diese Overreads verschwenden Bandbreite und Speicher, da die Anwendung den Großteil der Daten verwirft, für deren Abruf sie gerade Zeit aufgewendet hat [2].
Der Umstieg auf ein Sharded-Modell und das Caching von Zuständen im Speicher beseitigte diese Overhead-Ebenen, indem der Zustand direkt mit der Logik, die ihn verarbeitet, zusammengelegt wurde. Allerdings führte statisches Sharding zu neuen Problemen.
2.2. Die Fragilität von statischem Sharding
Vor Dicer setzten geshardete Dienste bei Databricks auf Techniken des statischen Shardings (z. B. konsistentes Hashing). Dieser Ansatz war zwar einfach und ermöglichte unseren Diensten, den Zustand effizient im Arbeitsspeicher zu cachen, führte aber zu drei kritischen Problemen im Produktionsbetrieb:
- Nichtverfügbarkeit bei Neustarts und automatischer Skalierung: Die mangelnde Koordination mit einem Cluster-Manager führte zu Ausfallzeiten oder Leistungseinbußen bei Wartungsarbeiten wie Rolling Updates oder bei der dynamischen Skalierung eines Dienstes. Statische Sharding-Schemata passten sich nicht proaktiv an Änderungen der Backend-Mitgliedschaft an und reagierten erst, nachdem ein Knoten bereits entfernt worden war.
- Längeres Split-Brain-Problem und längere Ausfallzeiten bei Fehlern: Ohne zentrale Koordination könnten Clients inkonsistente Ansichten über die Gruppe der Backend-Pods entwickeln, wenn Pods abstürzten oder zeitweise nicht mehr reagierten. Dies führte zu "Split-Brain"-Szenarien (bei denen zwei Pods glaubten, denselben Key zu besitzen) oder sogar zum vollständigen Ausfall des Kundenverkehrs (bei denen kein Pod glaubte, den Key zu besitzen).
- Das Hot-Key-Problem: Per Definition kann statisches Sharding Key-Zuweisungen nicht dynamisch neu verteilen oder die Replikation als Reaktion auf Lastverschiebungen anpassen. Folglich würde ein einzelner "Hot Key" einen bestimmten Pod überlasten, wodurch ein Engpass entstünde, der kaskadierende Ausfälle in der gesamten Flotte auslösen könnte.
Als unsere Dienste immer weiter wuchsen, um die Nachfrage zu befriedigen, erwies sich statisches Sharding schließlich als eine schreckliche Idee. Dies führte zu der allgemeinen Überzeugung unter unseren Ingenieuren, dass zustandslose Architekturen der beste Weg seien, um robuste Systeme zu bauen, auch wenn dies Leistungs- und Ressourcenkosten mit sich brachte. Das war ungefähr zu der Zeit, als Dicer eingeführt wurde.
2.3. Neudefinition des Narrativs von Sharded Dienste
Die Produktionsrisiken des statischen Shardings brachten im Gegensatz zu den Kosten für einen zustandslosen Betrieb mehrere unserer wichtigsten Dienste in eine schwierige Lage. Diese Dienste setzten auf statisches Sharding, um unseren Kunden eine reaktionsschnelle Benutzererfahrung zu bieten. Die Umstellung auf ein zustandsloses Modell hätte eine erhebliche Performanceeinbuße mit sich gebracht, ganz zu schweigen von zusätzlichen Cloud-Kosten für uns.
Wir haben Dicer entwickelt, um das zu ändern. Dicer behebt die grundlegenden Mängel des statischen Shardings, indem es eine intelligente Steuerungsebene (Control Plane) einführt, die die Shard-Zuweisungen eines Dienstes kontinuierlich und asynchron aktualisiert. Es reagiert auf eine Vielzahl von Signalen, darunter Anwendungszustand, Last, Beendigungsbenachrichtigungen und andere Umgebungseingaben. Dadurch hält Dicer die Dienste selbst bei Rolling Restarts, Abstürzen, Autoscaling-Ereignissen und Phasen mit starker Lastverschiebung (Load Skew) hochverfügbar und gut ausbalanciert.
Als Auto-Sharder baut Dicer auf einer langen Reihe von Vorgängersystemen auf, darunter Centrifuge [3], Slicer [4] und Shard Manager [5]. Im nächsten Abschnitt stellen wir Dicer vor und beschreiben, wie es dazu beigetragen hat, die Performance, Zuverlässigkeit und Effizienz unserer Dienste zu verbessern.
3. Dicer: Dynamisches Sharding für hohe Performance und Verfügbarkeit
Wir geben nun einen Überblick über Dicer, seine Kernabstraktionen und beschreiben seine verschiedenen Anwendungsfälle. Freuen Sie sich auf einen technischen Deep Dive in das Design und die Architektur von Dicer in einem zukünftigen Blogpost.
3.1 Dicer-Überblick
Dicer modelliert eine Anwendung so, dass sie Anfragen bedient (oder anderweitig Arbeit verrichtet), die mit einem logischen Key verknüpft sind. Beispielsweise könnte ein Dienst, der Benutzerprofile bereitstellt, Benutzer-IDs als seine Keys verwenden. Dicer sharded die Anwendung, indem es kontinuierlich eine Zuweisung von Keys zu Pods generiert, um den Dienst hochverfügbar zu halten und die Last auszugleichen.
Um auf Anwendungen mit Millionen oder Milliarden von Schlüsseln zu skalieren, arbeitet Dicer mit Schlüsselbereichen statt mit einzelnen Schlüsseln. Anwendungen stellen Keys für Dicer mithilfe eines SliceKey (ein Hash des Anwendungsschlüssels) dar, und ein zusammenhängender Bereich von SliceKeys wird als Slice bezeichnet. Wie in Abbildung 1 dargestellt, ist ein Dicer- Assignment eine Sammlung von Slices, die zusammen den gesamten Anwendungsschlüsselraum abdecken, wobei jeder Slice einer oder mehreren Ressourcen zugewiesen ist (d. h. Pods). Dicer teilt, mergt, repliziert und weist Slices als Reaktion auf Signale zum Zustand und zur Last der Anwendung dynamisch neu zu. Dadurch wird sichergestellt, dass der gesamte Schlüsselraum immer fehlerfreien Pods zugewiesen ist und kein einzelner Pod überlastet wird. Dicer kann auch „Hot Keys“ erkennen, sie in ihre eigenen Slices aufteilen und solche Slices mehreren Pods zuweisen, um die Last zu verteilen.
Abbildung 1 zeigt ein Beispiel für eine Dicer-Zuweisung auf 3 Pods (P0, P1 und P2) für eine Anwendung, die nach Benutzer-ID geshardet ist, wobei der Benutzer mit der ID 13 durch SliceKey K26 (d. h. ein Hash der ID 13) dargestellt wird und aktuell dem Pod P0 zugewiesen ist. Ein Nutzer mit hoher Auslastung mit der Nutzer-ID 42, der durch SliceKey K10 dargestellt wird, wurde in einem eigenen Slice isoliert und mehreren Pods (P1 und P2) zugewiesen, um die Last zu bewältigen.

{kind=link}
Abbildung 2 zeigt eine Übersicht über eine geshardete Anwendung, die in Dicer integriert ist. Anwendungs-Pods lernen die aktuelle Zuweisung über eine Bibliothek namens Slicelet (S für serverseitig). Das Slicelet unterhält einen lokalen Cache der neuesten Zuweisung, indem es diese vom Dicer-Dienst abruft und auf Aktualisierungen achtet. Wenn es eine aktualisierte Zuweisung erhält, benachrichtigt das Slicelet die Anwendung über eine Listener-API.
Zuweisungen, die von Slicelets beobachtet werden, sind letztendlich konsistent – eine bewusste Designentscheidung, die Verfügbarkeit und schnelle Wiederherstellung gegenüber starken Garantien für den Key-Besitz priorisiert. Unserer Erfahrung nach war dies das richtige Modell für die große Mehrheit der Anwendungen, obwohl wir planen, in Zukunft stärkere Garantien zu unterstützen, ähnlich wie bei Slicer und Centrifuge.
Anwendungen halten nicht nur die Zuweisung auf dem neuesten Stand, sondern verwenden auch das Slicelet, um bei der Bearbeitung von Anfragen oder der Ausführung von Arbeit für einen Schlüssel die Last pro Schlüssel zu erfassen. Das Slicelet aggregiert diese Informationen lokal und meldet asynchron eine Zusammenfassung an den Dicer-Dienst. Beachten Sie, dass dies wie die Zuweisungsüberwachung auch außerhalb des kritischen Pfads der Anwendung erfolgt, was eine hohe Performance gewährleistet.
Clients einer geshardeten Dicer-Anwendung finden den zugewiesenen Pod für einen bestimmten Key über eine Bibliothek namens Clerk (C für Client-Seite). Ähnlich wie Slicelets pflegen auch Clerks aktiv einen lokalen Cache der neuesten Zuweisung im Hintergrund, um eine hohe Performance bei der Key-Suche auf dem kritischen Pfad zu gewährleisten.

Schließlich ist der Dicer- Assigner der Controller-Dienst, der für die Erstellung und Verteilung von Zuweisungen auf der Grundlage von Signalen zum Zustand und zur Last der Anwendung verantwortlich ist. Im Kern steht ein Sharding-Algorithmus, der minimale Anpassungen durch Slice-Splits, Merges, Replikation/Dereplikation und Verschiebungen berechnet, um Schlüssel fehlerfreien Pods zugewiesen zu halten und einen ausreichenden Lastausgleich für die Gesamtanwendung zu gewährleisten. Der Assigner-Dienst ist mandantenfähig und darauf ausgelegt, einen Auto-Sharding-Dienst für alle geshardeten Anwendungen innerhalb einer Region bereitzustellen. Jede geshardete Anwendung, die von Dicer bedient wird, wird als Target bezeichnet.
3.2 Breite Klasse von Anwendungen, die durch Dicer verbessert werden
Dicer ist für eine Vielzahl von Systemen wertvoll, da die Möglichkeit, Workloads bestimmten Pods zuzuordnen (Affinität herzustellen), zu erheblichen Performance-Verbesserungen führt. Basierend auf unserer Erfahrung im Produktionsbetrieb haben wir mehrere Kernkategorien von Anwendungsfällen identifiziert.
In-Memory- und GPU-Serving
Dicer eignet sich hervorragend für Szenarien, in denen ein großer Datenkorpus geladen und direkt aus dem Arbeitsspeicher bereitgestellt werden muss. Indem sichergestellt wird, dass Anfragen für bestimmte Schlüssel immer dieselben Pods erreichen, können Dienste wie Key-Value-Stores eine Latenz im Sub-Millisekunden-Bereich und einen hohen Durchsatz erzielen und gleichzeitig den Overhead beim Abrufen von Daten aus einem Remote-Speicher vermeiden.
Dicer ist auch für moderne LLM-Inferenz-Workloads gut geeignet, bei denen die Aufrechterhaltung der Affinit�ät entscheidend ist. Beispiele hierfür sind zustandsbehaftete Benutzersitzungen, die Kontext in einem sitzungsbezogenen KV-Cache akkumulieren, sowie Bereitstellungen, die eine große Anzahl von LoRA-Adaptern bereitstellen und diese effizient über begrenzte GPU-Ressourcen verteilen müssen.
Steuerungs- und Schedule-Systeme
Dies ist einer der häufigsten Anwendungsfälle bei Databricks. Dazu gehören Systeme wie Cluster-Manager und Query-Orchestrierungs-Engines, die kontinuierlich Ressourcen überwachen, um Skalierung, Compute-Scheduling und Mandantenfähigkeit zu verwalten. Um effizient zu arbeiten, halten diese Systeme den Monitoring- und Steuerungszustand lokal vor, wodurch wiederholte Serialisierung vermieden und zeitnahe Reaktionen auf Änderungen ermöglicht werden.
Remote-Caches
Dicer kann verwendet werden, um Hochleistungs-Performance verteilte Remote-Caches zu erstellen, was wir bei Databricks in der Produktion umgesetzt haben. Durch die Nutzung der Funktionen von Dicer kann unser Cache nahtlos automatisch skaliert und neu gestartet werden, ohne Verlust der Trefferquote und unter Vermeidung von Lastungleichgewichten durch Hot Keys.
Arbeitsaufteilung und Hintergrundarbeit
Dicer ist ein effektives Werkzeug zur Partitionierung von Hintergrund-Tasks und asynchronen Workflows über eine Flotte von Servern hinweg. Beispielsweise kann ein Dienst, der für die Bereinigung oder Garbage Collection von Zuständen in einer riesigen Tabelle verantwortlich ist, Dicer verwenden, um sicherzustellen, dass jeder Pod für einen eindeutigen, nicht überlappenden Bereich des Keyspace verantwortlich ist, wodurch redundante Arbeit und Lock Contention vermieden werden.
Batching und Aggregation
Für Schreibpfade mit hohem Volumen ermöglicht Dicer eine effiziente Aggregation von Datensätzen. Indem zusammengehörige Datensätze an denselben Pod weitergeleitet werden, kann das System Aktualisierungen im Arbeitsspeicher batchen, bevor sie in den persistenten Speicher committet werden. Dies reduziert die erforderlichen Eingabe/Ausgabe-Operationen pro Sekunde erheblich und verbessert den Gesamtdurchsatz der Datenpipeline.
Soft-Leader-Auswahl
Dicer kann zur Implementierung einer "weichen" Leader-Selektion verwendet werden, indem ein bestimmter Pod als primärer Koordinator für einen bestimmten Schlüssel oder Shard bestimmt wird. Beispielsweise kann ein Serving-Scheduler Dicer verwenden, um sicherzustellen, dass ein einzelner Pod als primäre Autorität für die Verwaltung einer Gruppe von Ressourcen fungiert. Obwohl Dicer derzeit eine affinitätsbasierte Leader-Selektion bietet, dient es als leistungsstarke Grundlage für Systeme, die einen koordinierten Primary ohne den hohen Overhead herkömmlicher Konsensprotokolle benötigen. Wir untersuchen zukünftige Erweiterungen, um stärkere Garantien für den gegenseitigen Ausschluss für diese Workloads zu bieten.
Rendezvous und Koordination
Dicer fungiert als natürlicher Rendezvous-Punkt für verteilte Clients, die eine Echtzeit-Koordination benötigen. Indem alle Anfragen für einen bestimmten Key an denselben Pod weitergeleitet werden, wird dieser Pod zu einem zentralen Treffpunkt, an dem der gemeinsame Zustand im lokalen Speicher ohne externe Netzwerk-Hops verwaltet werden kann.
In einem Echtzeit-Chatdienst beispielsweise werden zwei Clients, die derselben "Chatraum-ID" beitreten, automatisch an denselben Pod weitergeleitet. Dies ermöglicht es dem Pod, ihre Nachrichten und ihren Zustand sofort im Speicher zu synchronisieren, wodurch die Latenz einer gemeinsam genutzten Datenbank oder einer komplexen Backplane für die Kommunikation vermieden wird.
4. Erfolgsgeschichten
Zahlreiche Dienste bei Databricks haben mit Dicer erhebliche Verbesserungen erzielt, und im Folgenden stellen wir einige dieser Erfolgsgeschichten vor.
4.1 Unity Catalog
Unity Catalog (UC) ist die einheitliche Governance-Lösung für Daten- und KI-Assets auf der gesamten Databricks-Plattform. Ursprünglich als zustandsloser Dienst konzipiert, sah sich UC mit wachsender Popularität erheblichen Skalierungsherausforderungen gegenüber, die hauptsächlich auf ein extrem hohes Lesevolumen zurückzuführen waren. Die Bearbeitung jeder Anfrage erforderte wiederholten Zugriff auf die Backend-Datenbank, was zu unannehmbar hohen Latenzzeiten führte. Herkömmliche Ansätze wie Remote-Caching waren nicht praktikabel, da der Cache inkrementell aktualisiert werden und Snapshot-konsistent mit dem Speicher bleiben musste. Darüber hinaus können Kundenkataloge Gigabytes groß sein, was die Pflege von partiellen oder replizierten Snapshots in einem Remote-Cache kostspielig macht, ohne dass dabei ein erheblicher Overhead entsteht.
Um dies zu lösen, integrierte das Team Dicer, um einen geshardeten, zustandsbehafteten In-Memory-Cache aufzubauen. Diese Umstellung ermöglichte es UC, teure Remote-Netzwerkaufrufe durch lokale Methodenaufrufe zu ersetzen, wodurch die Datenbanklast drastisch reduziert und die Reaktionsfähigkeit verbessert wurde. Die nachstehende Abbildung veranschaulicht den anfänglichen Rollout von Dicer, gefolgt von der Bereitstellung der vollständigen Dicer-Integration. Durch die Nutzung der zustandsbehafteten Affinität von Dicer erreichte UC eine Cache-Trefferquote von 90–95 % und senkte damit die Häufigkeit von Datenbank-Roundtrips erheblich.

{kind=link}
4.2 SQL-Query-Orchestrierungs-Engine
Die Query-Orchestrierungs-Engine von Databricks, die das Query-Scheduling auf Spark-Clustern verwaltet, wurde ursprünglich als zustandsbehafteter In-Memory-Dienst mit statischem Sharding erstellt. Als der Dienst skalierte, wurden die Einschränkungen dieser Architektur zu einem erheblichen Engpass; aufgrund der einfachen Implementierung erforderte die Skalierung ein manuelles Re-Sharding, was äußerst mühsam war, und das System litt unter häufigen Verfügbarkeitseinbrüchen, sogar bei Rolling Restarts.
Nach der Integration mit Dicer wurden diese Verfügbarkeitsprobleme beseitigt (siehe Abbildung 4). Dicer ermöglichte null Ausfallzeit bei Neustarts und Skalierungsvorgängen, sodass das Team durch die flächendeckende Aktivierung von Auto-Scaling den manuellen Aufwand reduzieren und die Systemrobustheit verbessern konnte. Zusätzlich löste die dynamische Lastausgleichs-Feature von Dicer die chronische CPU-Drosselung weiter auf, was zu einer konsistenteren Performance in der gesamten Flotte führte.
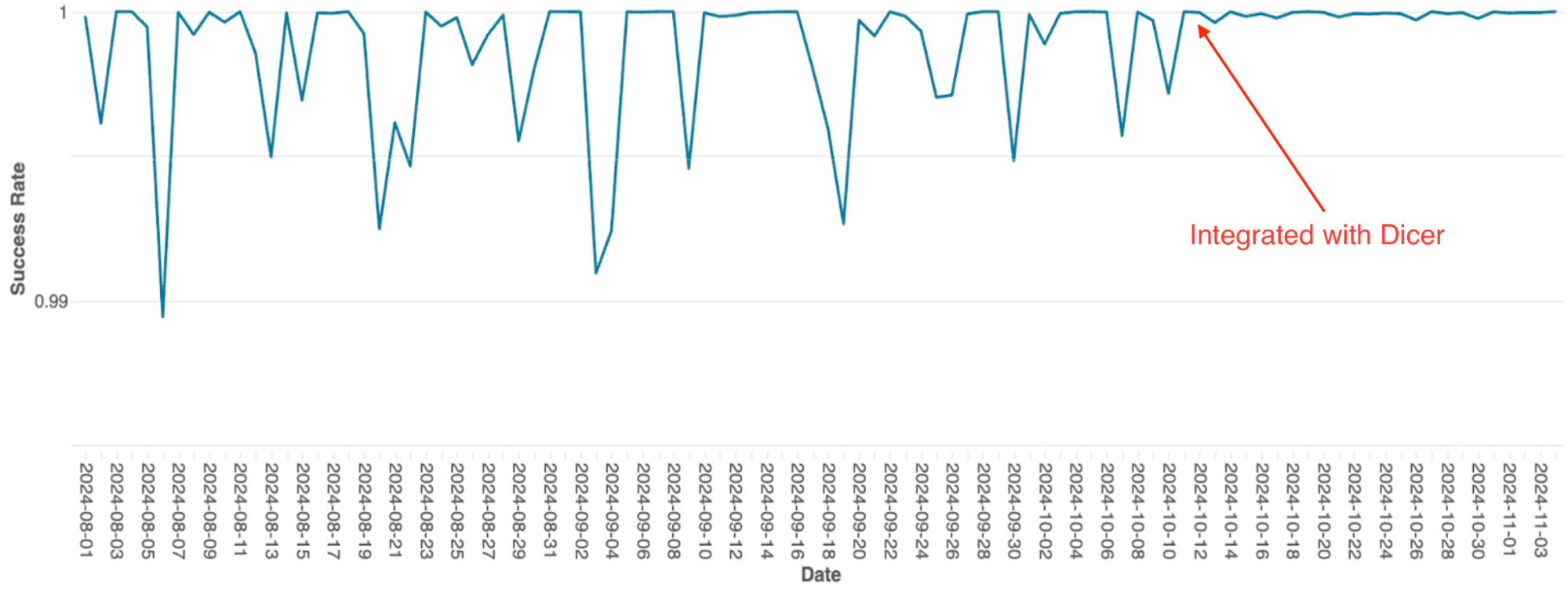
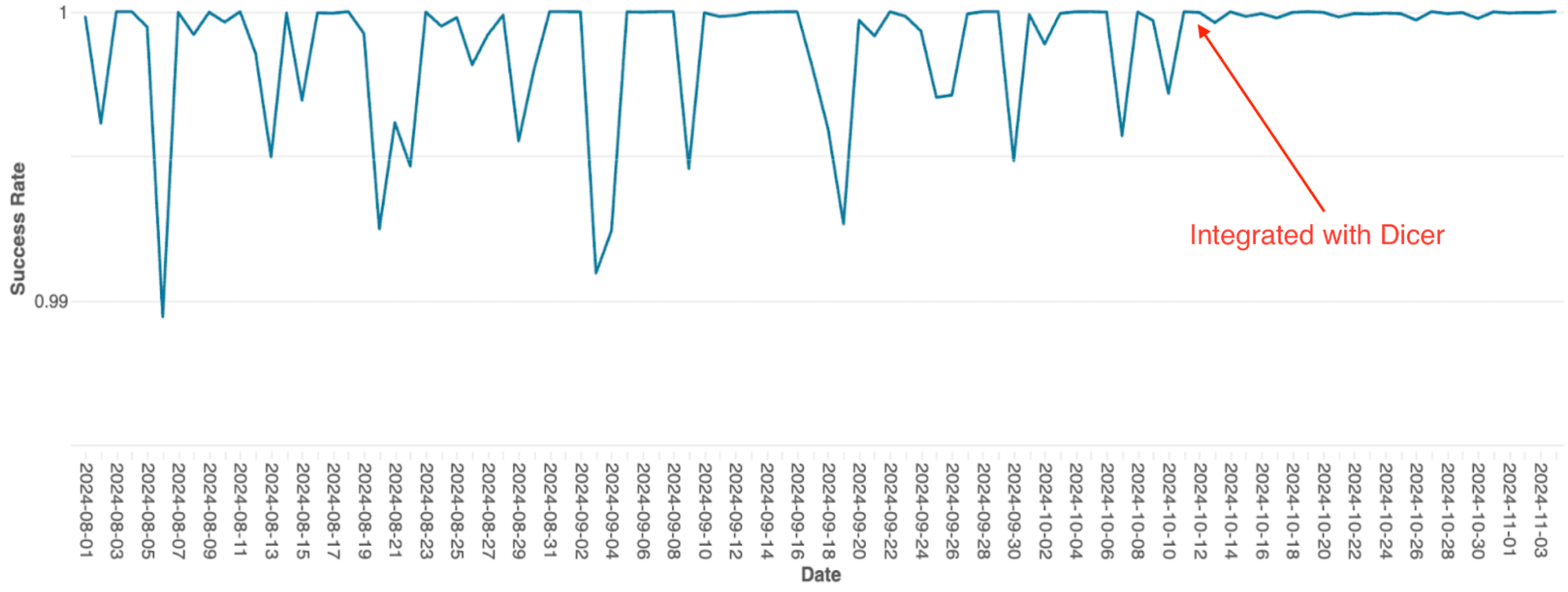{kind=link}
4.3 Softstore-Remote-Cache
Für Dienste, die nicht gesharded sind, haben wir Softstore entwickelt, einen verteilten Remote-Key-Value-Cache. Softstore nutzt eine Dicer-Feature namens State Transfer, die während des Resharding Daten zwischen Pods migriert, um den Anwendungszustand zu erhalten. Dies ist besonders wichtig bei geplanten Rolling Restarts, bei denen der gesamte Keyspace unweigerlich durchrotiert wird. In unserer Produktionsflotte machen geplante Neustarts etwa 99,9 % aller Neustarts aus, was diesen Mechanismus besonders wirkungsvoll macht und nahtlose Neustarts mit vernachlässigbaren Auswirkungen auf die Cache-Trefferquoten ermöglicht. Abbildung 5 zeigt die Trefferquoten von Softstore während eines Rolling Restarts, wobei State Transfer eine stabile Trefferquote von ~85 % für einen repräsentativen Anwendungsfall beibehält und die verbleibende Variabilität auf normale Workload-Schwankungen zurückzuführen ist.
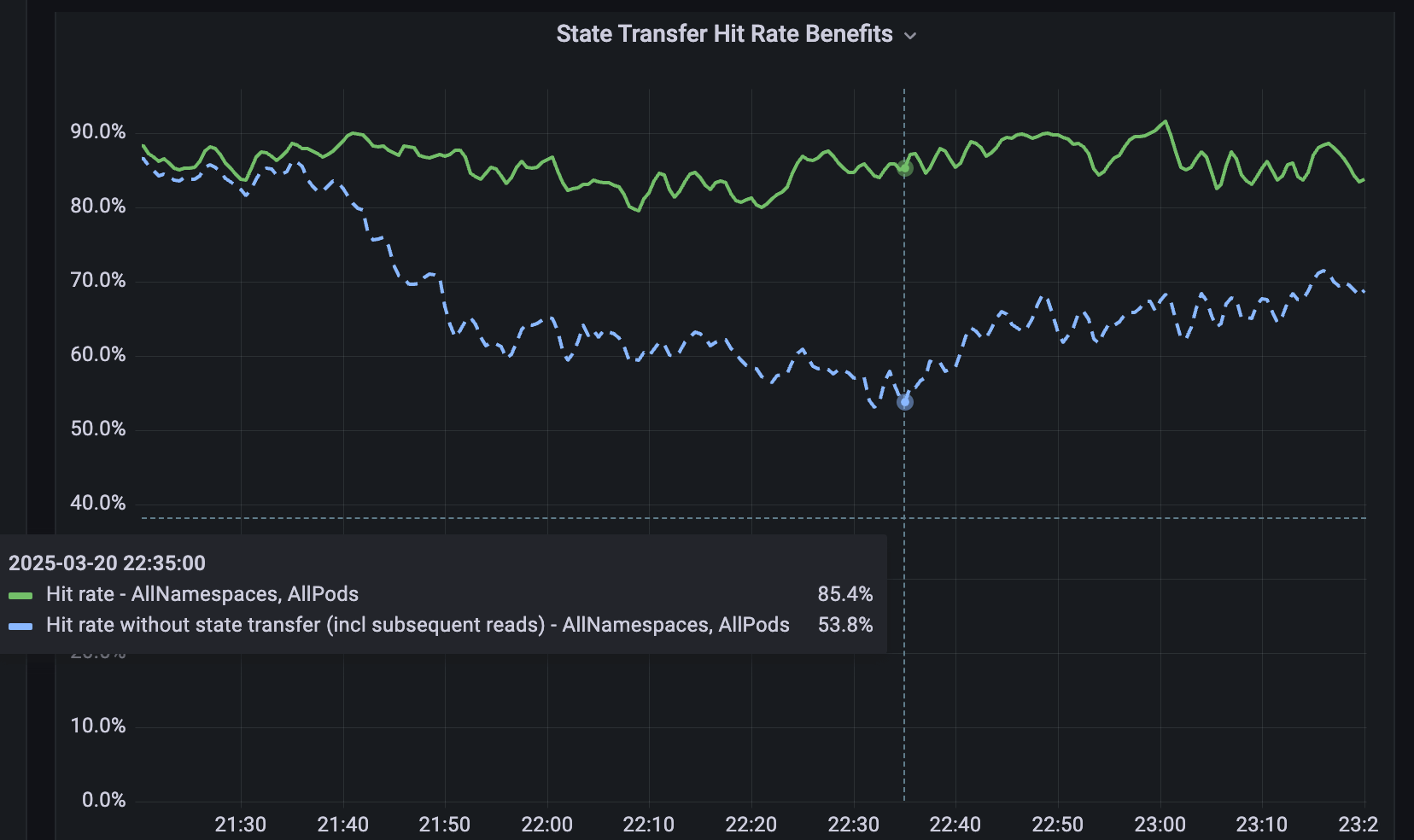
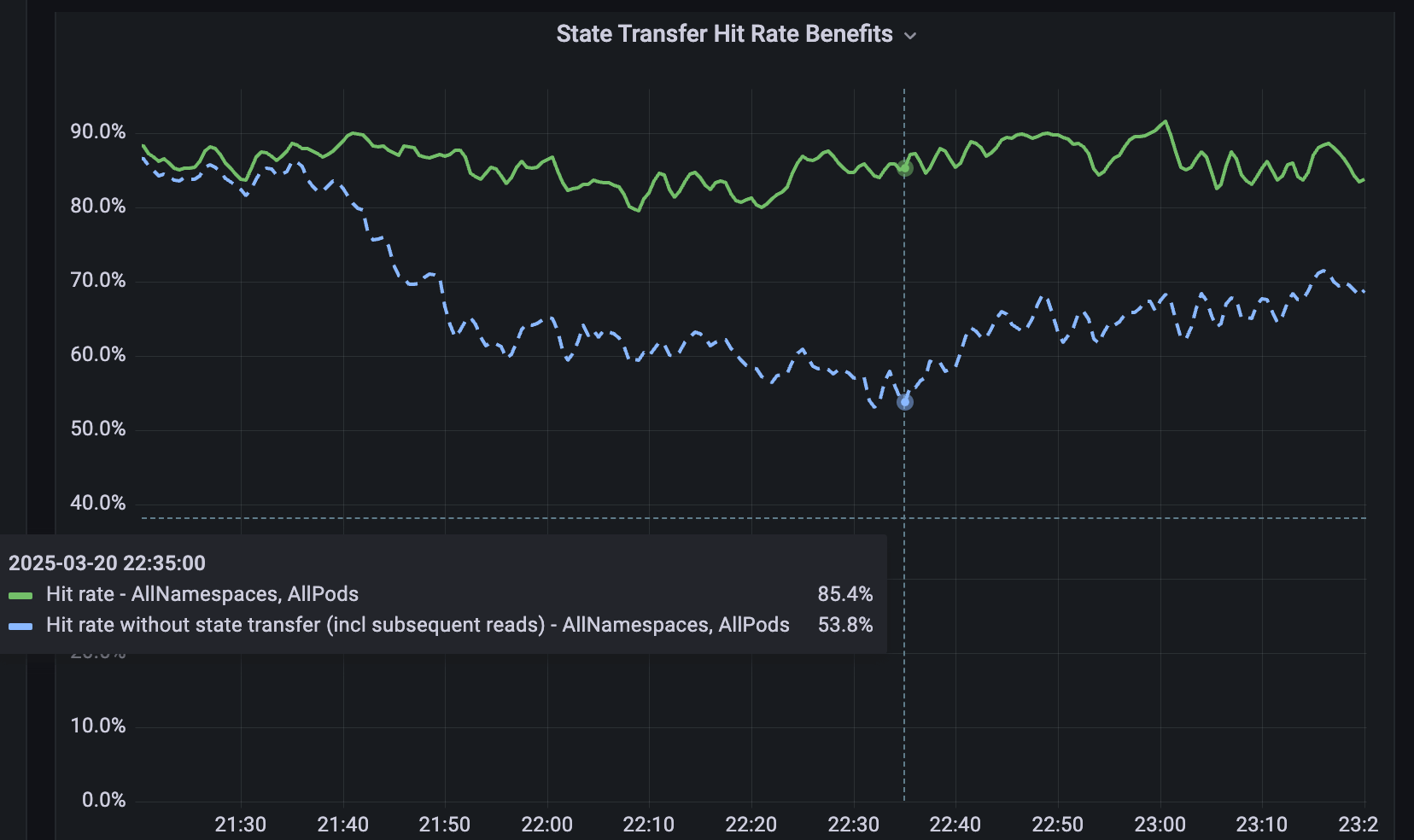{kind=link}
5. Jetzt können auch Sie es nutzen!
Sie können Dicer noch heute auf Ihrem Rechner ausprobieren, indem Sie es hier download. Eine einfache Demo, die die Verwendung zeigt, wird hier bereitgestellt – sie zeigt ein Beispiel für ein Dicer-Setup mit einem Client und einigen Servern für eine Anwendung. Bitte lesen Sie die README und den Benutzerleitfaden für Dicer.
6. Zukünftige Features und Artikel
Dicer ist ein kritischer Dienst, der bei Databricks genutzt wird und dessen Verwendung schnell zunimmt. In Zukunft werden wir weitere Artikel über die interne Funktionsweise und das Design von Dicer veröffentlichen. Wir werden auch weitere Features veröffentlichen, sobald wir sie intern entwickeln und testen, z. B. Java- und Rust-Bibliotheken für Clients und Server sowie die in diesem Beitrag erwähnten Funktionen zur Zustandsübertragung. Bitte geben Sie uns Ihr Feedback und bleiben Sie gespannt auf mehr!
Wenn du gerne schwierige technische Probleme löst und bei Databricks einsteigen möchtest, schau auf databricks.com/careers vorbei!
7. Referenzen
[1] Ziming Mao, Jonathan Ellithorpe, Atul Adya, Rishabh Iyer, Matei Zaharia, Scott Shenker, Ion Stoica (2025). Rethinking the cost of distributed caches for datacenter Dienste. Proceedings of the 24th ACM Workshop on Hot Topics in Networks, 1–8.
[2] Atul Adya, Robert Grandl, Daniel Myers, Henry Qin. Fast key-value stores: An idea whose time has come and gone. Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS ’19), 13.–15. Mai 2019, Bertinoro, Italien. ACM, 7 Seiten. DOI: 10.1145/3317550.3321434.
[3] Atul Adya, James Dunagan, Alexander Wolman. Centrifuge: Integrated Lease Management and Partitioning for Cloud Dienste. Tagungsband des 7. USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2010.
[4] Atul Adya, Daniel Myers, Jon Howell, Jeremy Elson, Colin Meek, Vishesh Khemani, Stefan Fulger, Pan Gu, Lakshminath Bhuvanagiri, Jason Hunter, Roberto Peon, Larry Kai, Alexander Shraer, Arif Merchant, Kfir Lev-Ari. Slicer: Auto-Sharding für Rechenzentrumsanwendungen. Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016, S. 739–753.
[5] Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Chunqiang Tang, et al. Shard Manager: A Generic Shard Management Framework for Geo distributed Applications. Tagungsband des ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP), 2021. DOI: 10.1145/3477132.3483546.
[6] Atul Adya, Jonathan Ellithorpe. Zustandsbehaftete Dienste: niedrige Latenz, Effizienz, Skalierbarkeit – wählen Sie drei. High Performance Transaction Systems Workshop (HPTS) 2024, Pacific Grove, Kalifornien, 15.–18. September 2024.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.