Einführung von Pandas UDFs für PySpark
So führen Sie Ihren nativen Python-Code schnell mit PySpark aus.
von Li Jin
Free Edition hat die Community Edition ersetzt und bietet erweiterte Funktionen kostenlos. Nutzen Sie Free Edition noch heute.
HINWEIS: Spark 3.0 hat eine neue pandas UDF eingeführt. Weitere Details finden Sie in diesem Blogbeitrag: Neue Pandas UDFs und Python-Typ-Hinweise in der kommenden Version von Apache Spark 3.0
Dies ist ein Gastbeitrag von Li Jin, Softwareingenieurin bei Two Sigma Investments, LP in New York. Dieser Blogbeitrag wird auch auf Two Sigma veröffentlicht.
Probieren Sie dieses Notebook in Databricks aus
UPDATE: Dieser Blogbeitrag wurde am 22. Februar 2018 aktualisiert, um einige Änderungen aufzunehmen.
Dieser Blogbeitrag stellt die Pandas UDFs (auch bekannt als Vektorisierte UDFs) in der kommenden Apache Spark 2.3-Version vor, die die Leistung und Benutzerfreundlichkeit von benutzerdefinierten Funktionen (UDFs) in Python erheblich verbessern.
In den letzten Jahren ist Python zur Standardsprache für Data Scientists geworden. Pakete wie pandas, numpy, statsmodel und scikit-learn haben große Verbreitung gefunden und sind zu den Mainstream-Toolkits geworden. Gleichzeitig ist Apache Spark zum De-facto-Standard für die Verarbeitung großer Datenmengen geworden. Um Data Scientists die Nutzung des Werts großer Datenmengen zu ermöglichen, hat Spark ab Version 0.7 eine Python-API mit Unterstützung für benutzerdefinierte Funktionen hinzugefügt. Diese benutzerdefinierten Funktionen arbeiten zeilenweise und leiden daher unter hohem Serialisierungs- und Aufruf-Overhead. Infolgedessen definieren viele Datenpipelines UDFs in Java und Scala und rufen sie dann aus Python auf.
Pandas UDFs, die auf Apache Arrow aufbauen, bieten Ihnen das Beste aus beiden Welten – die Möglichkeit, UDFs mit geringem Overhead und hoher Leistung vollständig in Python zu definieren.
In Spark 2.3 wird es zwei Arten von Pandas UDFs geben: Skalar und Grouped Map. Im Folgenden werden wir ihre Verwendung anhand von vier Beispielprogrammen veranschaulichen: Plus One, Kumulative Wahrscheinlichkeit, Mittelwert subtrahieren, Kleinste-Quadrate-Lineare-Regression.
Skalare Pandas UDFs
Skalare Pandas UDFs werden zur Vektorisierung von skalaren Operationen verwendet. Um eine skalare Pandas UDF zu definieren, verwenden Sie einfach @pandas_udf, um eine Python-Funktion zu annotieren, die pandas.Series als Argumente entgegennimmt und eine andere pandas.Series gleicher Größe zurückgibt. Nachfolgend veranschaulichen wir dies anhand von zwei Beispielen: Plus One und Kumulative Wahrscheinlichkeit.
Plus One
Das Berechnen von v + 1 ist ein einfaches Beispiel, um die Unterschiede zwischen zeilenweisen UDFs und skalaren Pandas UDFs zu demonstrieren. Beachten Sie, dass eingebaute Spaltenoperatoren in diesem Szenario viel schneller sein können.
Verwendung von zeilenweisen UDFs:
Verwendung von Pandas UDFs:
Die obigen Beispiele definieren eine zeilenweise UDF "plus_one" und eine skalare Pandas UDF "pandas_plus_one", die die gleiche "plus one"-Berechnung durchführt. Die UDF-Definitionen sind bis auf die Funktionsdeklaratoren gleich: "udf" vs "pandas_udf".
In der zeilenweisen Version nimmt die benutzerdefinierte Funktion einen Double "v" entgegen und gibt das Ergebnis von "v + 1" als Double zurück. In der Pandas-Version nimmt die benutzerdefinierte Funktion eine pandas.Series "v" entgegen und gibt das Ergebnis von "v + 1" als pandas.Series zurück. Da "v + 1" auf pandas.Series vektorisiert ist, ist die Pandas-Version wesentlich schneller als die zeilenweise Version.
Beachten Sie, dass bei der Verwendung von skalaren Pandas UDFs zwei wichtige Anforderungen gelten:
- Die Eingabe- und Ausgabeserien müssen die gleiche Größe haben.
- Wie eine Spalte in mehrere
pandas.Seriesaufgeteilt wird, ist intern für Spark, und daher muss das Ergebnis der benutzerdefinierten Funktion unabhängig von der Aufteilung sein.
Kumulative Wahrscheinlichkeit
Dieses Beispiel zeigt eine praktischere Anwendung der skalaren Pandas UDF: die Berechnung der kumulativen Wahrscheinlichkeit eines Werts in einer Normalverteilung N(0,1) unter Verwendung des scipy-Pakets.
stats.norm.cdf funktioniert sowohl mit einem Skalar als auch mit einer pandas.Series, und dieses Beispiel kann auch mit zeilenweisen UDFs geschrieben werden. Ähnlich wie im vorherigen Beispiel läuft die Pandas-Version wesentlich schneller, wie später im Abschnitt "Leistungsvergleich" gezeigt wird.
Grouped Map Pandas UDFs
Python-Benutzer sind mit dem Split-Apply-Combine-Muster in der Datenanalyse recht vertraut. Grouped Map Pandas UDFs sind für dieses Szenario konzipiert und operieren auf allen Daten einer bestimmten Gruppe, z. B. "für jedes Datum eine Operation anwenden".
Grouped Map Pandas UDFs teilen zuerst einen Spark DataFrame basierend auf den im Groupby-Operator angegebenen Bedingungen in Gruppen auf, wenden eine benutzerdefinierte Funktion (pandas.DataFrame -> pandas.DataFrame) auf jede Gruppe an, kombinieren die Ergebnisse und geben sie als neuen Spark DataFrame zurück.
Grouped Map Pandas UDFs verwenden denselben Funktionsdeklarator pandas_udf wie skalare Pandas UDFs, weisen jedoch einige Unterschiede auf:
- Eingabe der benutzerdefinierten Funktion:
- Skalar:
pandas.Series - Grouped Map:
pandas.DataFrame
- Skalar:
- Ausgabe der benutzerdefinierten Funktion:
- Skalar:
pandas.Series - Grouped Map:
pandas.DataFrame
- Skalar:
- Gruppierungssemantik:
- Skalar: keine Gruppierungssemantik
- Grouped Map: definiert durch die "groupby"-Klausel
- Ausgabegröße:
- Skalar: gleich der Eingabegröße
- Grouped Map: beliebige Größe
- Rückgabetypen im Funktionsdeklarator:
- Skalar: ein
DataType, der den Typ der zurückgegebenenpandas.Seriesangibt - Grouped Map: ein
StructType, der den Namen und Typ jeder Spalte des zurückgegebenenpandas.DataFrameangibt
- Skalar: ein
Im Folgenden werden wir anhand von zwei Beispielen die Anwendungsfälle von Grouped Map Pandas UDFs erläutern.
Mittelwert subtrahieren
Dieses Beispiel zeigt eine einfache Anwendung von Grouped Map Pandas UDFs: Subtraktion des Mittelwerts von jedem Wert in der Gruppe.
In diesem Beispiel subtrahieren wir den Mittelwert von v von jedem Wert von v für jede Gruppe. Die Gruppierungssemantik wird durch die "groupby"-Funktion definiert, d. h. jeder eingegebene pandas.DataFrame für die benutzerdefinierte Funktion hat denselben "id"-Wert. Das Eingabe- und Ausgabeschema dieser benutzerdefinierten Funktion sind gleich, daher übergeben wir "df.schema" an den Deklarator pandas_udf, um das Schema anzugeben.
Grouped Map Pandas UDFs können auch als eigenständige Python-Funktionen auf dem Treiber aufgerufen werden. Dies ist sehr nützlich für das Debugging, zum Beispiel:
Im obigen Beispiel konvertieren wir zuerst einen kleinen Teil eines Spark DataFrame in einen pandas.DataFrame und führen dann subtract_mean als eigenständige Python-Funktion darauf aus. Nachdem die Funktionslogik überprüft wurde, können wir die UDF mit Spark über den gesamten Datensatz aufrufen.
Kleinste-Quadrate-Lineare-Regression
Das letzte Beispiel zeigt, wie man eine OLS-Lineare-Regression für jede Gruppe mit statsmodels durchführt. Für jede Gruppe berechnen wir Beta b = (b1, b2) für X = (x1, x2) gemäß dem statistischen Modell Y = bX + c.
Dieses Beispiel zeigt, dass gruppierte Map Pandas UDFs mit jeder beliebigen Python-Funktion verwendet werden können: pandas.DataFrame -> pandas.DataFrame. Der zurückgegebene pandas.DataFrame kann eine andere Anzahl von Zeilen und Spalten als die Eingabe haben.
Leistungsvergleich
Zuletzt möchten wir einen Leistungsvergleich zwischen zeilenweisen UDFs und Pandas UDFs zeigen. Wir haben Mikro-Benchmarks für drei der obigen Beispiele (plus eines, kumulative Wahrscheinlichkeit und Mittelwert subtrahieren) durchgeführt.
Konfiguration und Methodik
Wir haben den Benchmark auf einem einzelnen Spark-Cluster auf der Databricks Community Edition ausgeführt.
Konfigurationsdetails:
Daten: Ein DataFrame mit 10 Mio. Zeilen und einer Int- und einer Double-Spalte
Cluster: 6,0 GB Speicher, 0,88 Kerne, 1 DBU
Databricks Runtime Version: Neueste RC (4.0, Scala 2.11)
Die detaillierte Implementierung des Benchmarks finden Sie im Pandas UDF Notebook.
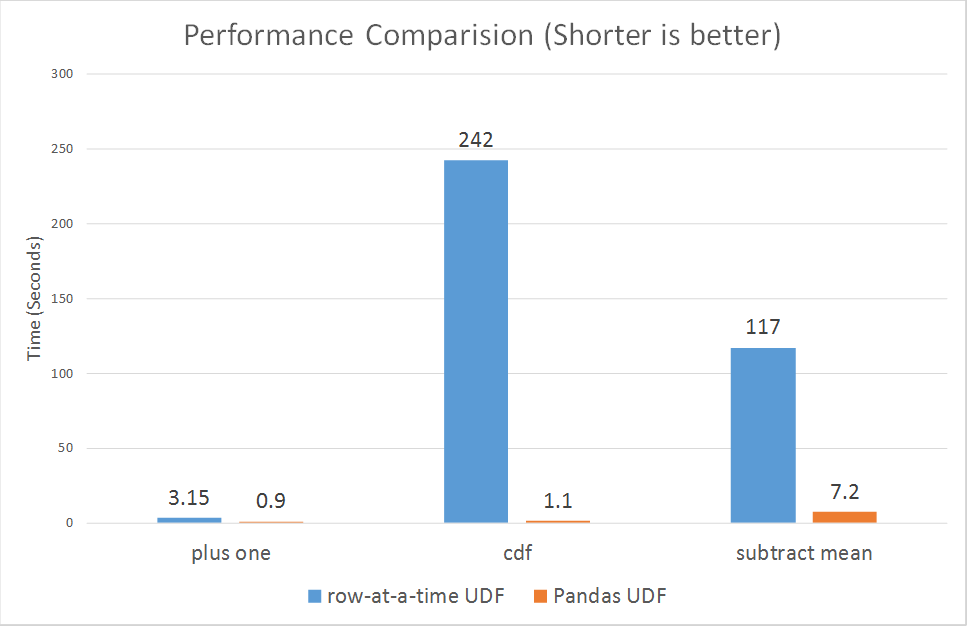
Wie in den Diagrammen gezeigt, schneiden Pandas UDFs durchweg viel besser ab als zeilenweise UDFs, mit einer Steigerung von 3x bis über 100x.
Fazit und zukünftige Arbeit
Die kommende Spark 2.3-Version legt den Grundstein für eine erhebliche Verbesserung der Fähigkeiten und Leistung von benutzerdefinierten Funktionen in Python. In Zukunft planen wir die Unterstützung für Pandas UDFs in Aggregationen und Fensterfunktionen einzuführen. Die damit verbundenen Arbeiten können unter SPARK-22216 verfolgt werden.
Pandas UDFs sind ein großartiges Beispiel für die Bemühungen der Spark-Community. Wir möchten Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li und vielen anderen für ihre Beiträge danken. Abschließend gilt ein besonderer Dank der Apache Arrow-Community, die diese Arbeit ermöglicht hat.
Nächste Schritte
Sie können das Pandas UDF Notebook ausprobieren. Diese Funktion ist jetzt als Teil der Databricks Runtime 4.0 Beta verfügbar.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.