So lösen Data Lakehouses die häufigsten Probleme bei Data Warehouses
von Ryan Boyd
Lesen Sie „Rise of the Data Lakehouse“, um mit Bill Inmon, dem Vater des Data Warehouse, zu erfahren, warum Lakehouses die Datenarchitektur der Zukunft sind.
Anmerkung der Redaktion: Dies ist der erste in einer Reihe von Beiträgen, die mit Genehmigung der Autoren größtenteils auf dem CIDR-Paper Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics basieren.
Datenanalysten, Data Scientists und Experten für künstliche Intelligenz sind oft frustriert über den grundlegenden Mangel an hochwertigen, zuverlässigen und aktuellen Daten, die für ihre Arbeit zur Verfügung stehen. Einige dieser Frustrationen sind auf bekannte Nachteile der zweistufigen Datenarchitektur zurückzuführen, die heute in der überwiegenden Mehrheit der Fortune-500-Unternehmen vorherrscht. Die offene Lakehouse-Architektur und die zugrunde liegende Technologie können die Produktivität von Datenteams und damit die Effizienz der Unternehmen, die sie einsetzen, drastisch verbessern.
Herausforderungen bei der zweistufigen Datenarchitektur
In dieser beliebten Architektur werden Daten aus dem gesamten Unternehmen aus operativen Datenbanken extrahiert und in einen Raw Data Lake geladen, der manchmal als Datensumpf bezeichnet wird, da nicht sorgfältig darauf geachtet wird, dass diese Daten nutzbar und zuverlässig sind. Anschließend wird nach einem Schedule ein weiterer ETL-Prozess (Extract, Transform, Load) ausgeführt, um wichtige Teilmengen der Daten in ein Data Warehouse für Business Intelligence und Entscheidungsfindung zu verschieben.
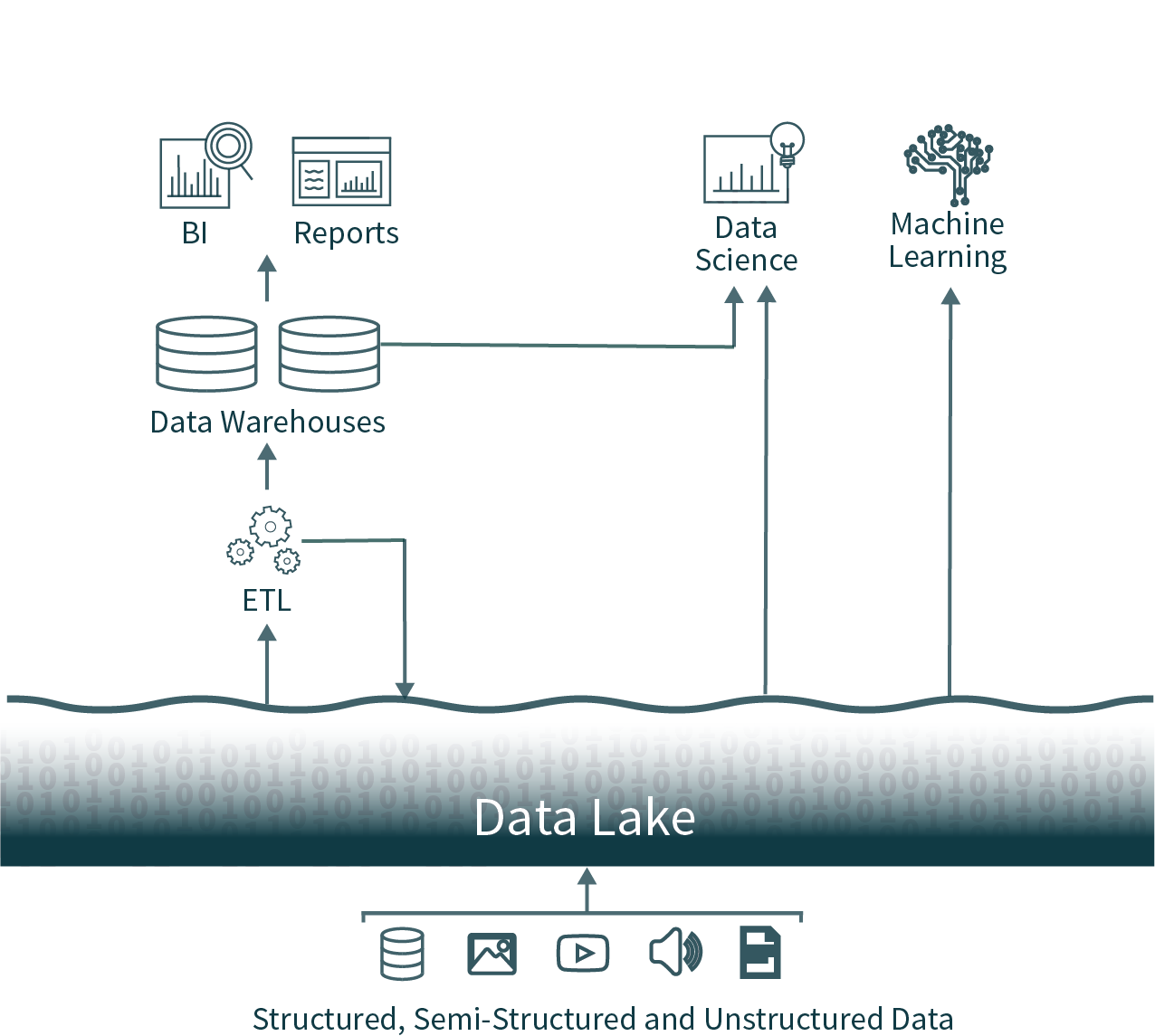
Diese Architektur stellt Datenanalysten vor eine nahezu unmögliche Wahl: zeitnahe und unzuverlässige Daten aus dem Data Lake oder veraltete und hochwertige Daten aus dem Data Warehouse zu nutzen. Aufgrund der geschlossenen Formate gängiger Data Warehousing-Lösungen ist es zudem sehr schwierig, die dominanten Open-Source-Frameworks zur Datenanalyse für hochwertige Datenquellen zu nutzen, ohne einen weiteren ETL-Vorgang einzuführen und zusätzliche veraltete Daten zu erzeugen.
Wir können das besser: Eine Einführung in das Data Lakehouse
Diese zweistufigen Datenarchitekturen, die heute in Unternehmen üblich sind, sind sowohl für die Benutzer als auch für die Data Engineer, die sie erstellen, äußerst komplex, unabhängig davon, ob sie on-premises oder in der Cloud gehostet werden.
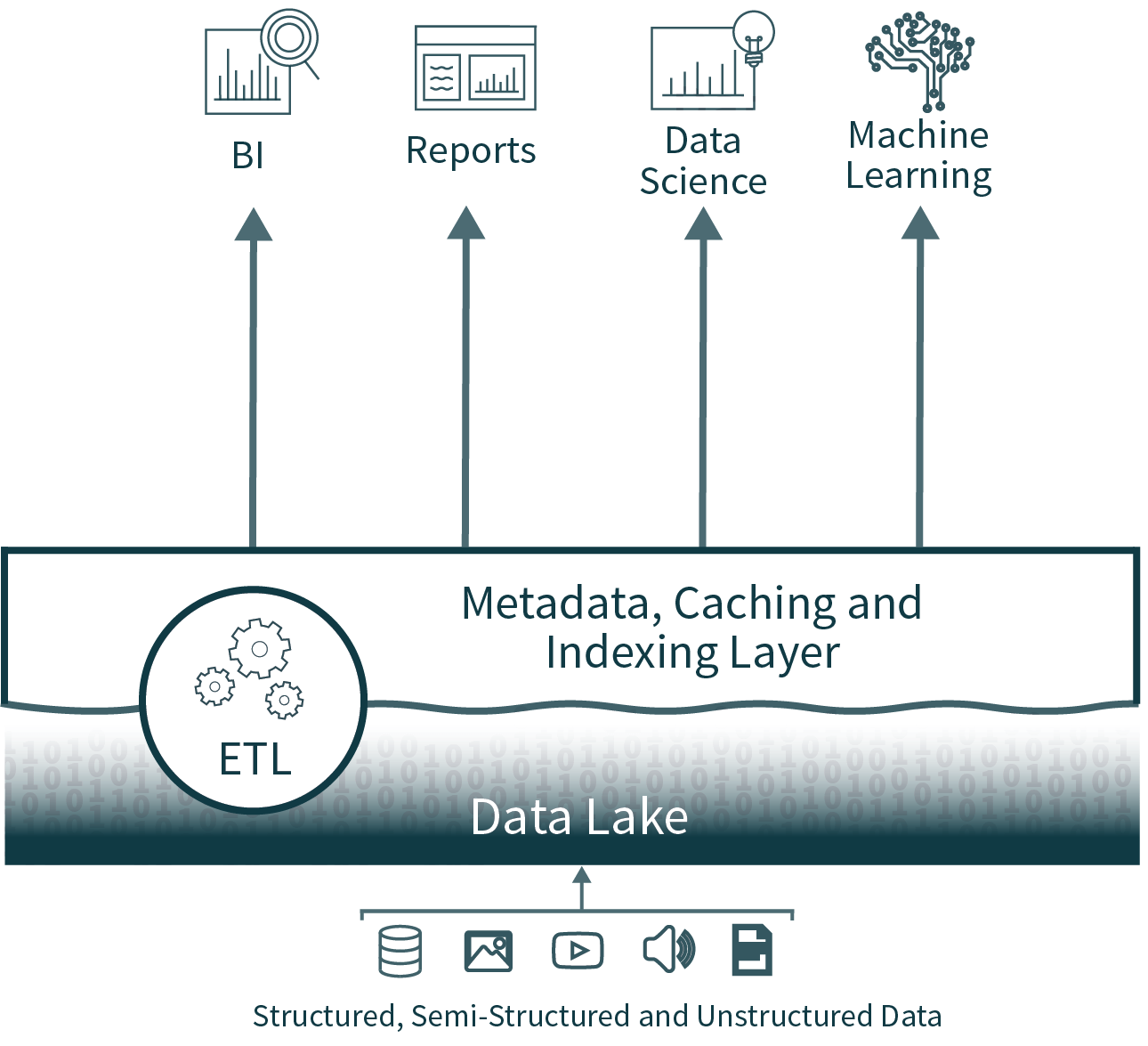
Die Lakehouse-Architektur reduziert Komplexität, Kosten und Betriebsaufwand, indem sie viele der Vorteile der Data-Warehouse-Ebene in puncto Zuverlässigkeit und Performance direkt auf dem Data Lake bereitstellt und die Warehouse-Ebene letztendlich überflüssig macht.
DATENZUVERLÄSSIGKEIT
Datenkonsistenz ist eine enorme Herausforderung, wenn mehrere Kopien von Daten synchron gehalten werden müssen. Es gibt mehrere ETL-Prozesse – Daten werden von operativen Datenbanken in den Data Lake und dann vom Data Lake in das Data Warehouse verschoben. Jeder zusätzliche Prozess führt zu zusätzlicher Komplexität, Verzögerungen und Fehlermöglichkeiten.
Durch die Eliminierung der zweiten Stufe entfernt die Data-Lakehouse-Architektur einen der ETL-Prozesse und bietet gleichzeitig Unterstützung für die Schemaerzwingung und -entwicklung direkt auf dem Data Lake. Sie unterstützt auch Funktionen wie Zeitreise, um die historische Validierung der Datenqualität zu ermöglichen.
Datenveralterung
Da das Data Warehouse aus dem Data Lake befüllt wird, sind die Daten darin oft veraltet. Dies zwingt 86 % der Analysten laut einer aktuellen Umfrage von Fivetran dazu, veraltete Daten zu verwenden.

Obwohl der Wegfall der Data Warehouse-Ebene dieses Problem löst, kann ein lakehouse auch das effiziente, einfache und zuverlässige Zusammenführen von Echtzeit-Streaming und Batch-Verarbeitung unterstützen, um sicherzustellen, dass für Analysen immer die aktuellsten Daten verwendet werden.
Eingeschränkte Unterstützung für erweiterte Analysen
Erweiterte Analytics, einschließlich machine learning und Predictive Analytics, erfordern oft die Verarbeitung sehr großer Datasets. Gängige Tools wie TensorFlow, PyTorch und XGBoost erleichtern das Lesen von Rohdaten in Data Lakes in offenen Datenformaten. Jedoch können diese Tools die meisten proprietären Datenformate nicht lesen, die von den per ETL verarbeiteten Daten in den Data Warehouses verwendet werden. Data-Warehouse-Anbieter empfehlen daher, diese Daten zur Verarbeitung in Dateien zu exportieren, was zu einem dritten ETL-Schritt sowie zu erhöhter Komplexität und Datenveralterung führt.
Alternativ können in der offenen Lakehouse-Architektur diese gängigen Toolsets direkt auf hochwertigen, zeitnahen Daten arbeiten, die im Data Lake gespeichert sind.
Gesamtbetriebskosten
Obwohl die Speicherkosten in der Cloud sinken, hat diese zweistufige Architektur für die Datenanalyse tatsächlich drei Online-Kopien von einem Großteil der Unternehmensdaten: eine in den operativen Datenbanken, eine im Data Lake und eine im Data Warehouse.
Die Gesamtbetriebskosten (TCO) erhöhen sich weiter, wenn man die erheblichen Engineeringkosten für die Synchronisierung der Daten zu den Speicherkosten hinzurechnet.
Die Data-Lakehouse-Architektur eliminiert eine der teuersten Datenkopien sowie mindestens einen zugehörigen Synchronisierungsprozess.
Wie sieht es mit der Performance für Business Intelligence aus?
Business Intelligence und Entscheidungsunterstützung erfordern eine hochperformante Ausführung von Abfragen zur explorativen Datenanalyse (EDA) sowie von Abfragen für Dashboards, Datenvisualisierungen und andere kritische Systeme. Performance-Bedenken waren oft der Grund dafür, dass Unternehmen zusätzlich zu einem Data Lake auch ein Data Warehouse unterhielten. Die Technologie zur Optimierung von Abfragen auf Data Lakes hat sich im letzten Jahr immens verbessert, wodurch die meisten dieser Performance-Bedenken hinfällig werden.
Lakehouses unterstützen Indizierung, Lokalitätssteuerungen, Abfrageoptimierung und Hot-Data-Caching, um die Performance zu verbessern. Dies führt zu einer Data-Lake-SQL-Performance, die bei TPC-DS die führender Cloud Data Warehouses übertrifft und gleichzeitig die von Data Warehouses erwartete Flexibilität und Governance bietet.
Fazit und nächste Schritte
Fortschrittliche Unternehmen und Technologen haben sich die heute verwendete zweistufige Architektur angesehen und gesagt: „Es muss einen besseren Weg geben.“ Dieser bessere Weg ist das, was wir als offenes Data Lakehouse bezeichnen, das die Offenheit und Flexibilität des Data Lake mit der Zuverlässigkeit, der Performance, der geringen Latenz und der high concurrency herkömmlicher Data Warehouses kombiniert.
Auf weitere Details zu den Performance-Verbesserungen von Data Lakes werde ich in einem kommenden Beitrag dieser Reihe eingehen.
Natürlich können Sie schummeln und vorspringen, indem Sie das vollständige CIDR-Paper lesen oder sich eine Videoserie ansehen, die tief in die zugrunde liegende Technologie des modernen Lakehouse eintaucht.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.