Apache Spark und Photon erhalten SIGMOD-Auszeichnungen
von Reynold Xin und Matei Zaharia
Diese Woche treffen sich viele der einflussreichsten Ingenieure und Forscher aus der Datenverwaltungs-Community nach zwei Jahren virtueller Treffen persönlich in Philadelphia zur ACM SIGMOD-Konferenz. Im Rahmen der Veranstaltung haben wir uns sehr über die folgenden beiden Auszeichnungen gefreut:
- Apache Spark wurde mit dem SIGMOD Systems Award ausgezeichnet.
- Databricks Photon wurde mit dem Best Industry Paper Award ausgezeichnet.
Wir dachten, wir nehmen dies zum Anlass, um die Hintergründe und unseren Weg bis hierher zu beleuchten.
Was ist ACM SIGMOD und was sind die Auszeichnungen?
ACM SIGMOD steht für die Special Interest Group in the Management of Data der Association of Computing Machinery. Wir wissen, ein langer Name. Alle sagen einfach nur SIGMOD. Es ist die prestigeträchtigste Konferenz für Datenbankforscher und -ingenieure, da viele der wegweisendsten Ideen im Bereich der Datenbanken, von Spaltenspeichern bis hin zu Abfrageoptimierungen, auf dieser Konferenz veröffentlicht wurden.
Der SIGMOD Systems Award wird jährlich an ein „System, dessen technische Beiträge einen erheblichen Einfluss auf die Theorie oder Praxis großer Datenverwaltungssysteme hatten“, verliehen. Diese Systeme haben in der Regel umfangreiche Anwendungen in der Praxis und beeinflussen zudem die Konzeption zukünftiger Datenbanksysteme. Zu den bisherigen Gewinnern gehören Postgres, SQLite, BerkeleyDB und Aurora.
Der Best Industry Paper Award wird jährlich an eine Arbeit verliehen, basierend auf der Kombination aus realen Auswirkungen, Innovation und der Qualität der Präsentation.
Der Daten- und KI-Ursprung von Apache Spark
Vor etwa einem Jahrzehnt startete Netflix einen Wettbewerb namens Netflix Prize, bei dem sie ihre riesige Sammlung von Nutzer-Filmbewertungen anonymisierten und die Teilnehmer aufforderten, Algorithmen zu entwickeln, um vorherzusagen, wie Nutzer Filme bewerten würden. Die mit 1 Million USD dotierte Trophäe würde an das Team mit dem besten Machine-Learning-Modell gehen.
Eine Gruppe von Doktoranden der UC Berkeley beschloss, an dem Wettbewerb teilzunehmen. Die erste Herausforderung, auf die sie stießen, war, dass das Tooling einfach nicht gut genug war. Um bessere Modelle zu entwickeln, benötigten sie eine schnelle, iterative Möglichkeit, große Datenmengen (die nicht auf einen Studenten-Laptop passten) zu bereinigen, zu analysieren und zu verarbeiten, und sie benötigten ein Framework, das ausdrucksstark genug war, um darauf experimentelle ML-Algorithmen zu komponieren.
Data Warehouses, die der Standard für Unternehmensdaten waren, konnten unstrukturierte Daten nicht verarbeiten und es mangelte ihnen an Ausdrucksfähigkeit. Sie besprachen diese Herausforderung mit einem anderen Doktoranden, Matei Zaharia. Gemeinsam entwickelten sie ein neues Framework für paralleles Rechnen namens Spark, mit einer neuen, innovativen, verteilten Datenstruktur namens RDDs. Spark ermöglichte es seinen Nutzern, datenparallele Operationen schnell und prägnant auszuführen.
Oder anders ausgedrückt: Code lässt sich schnell schreiben und ist schnell in der Ausführung. Eine schnelle Schreibweise ist wichtig, weil sie das Programm verständlicher macht und dazu verwendet werden kann, komplexere Algorithmen einfach zu erstellen. Eine schnelle Ausführung bedeutet, dass Nutzer schneller Feedback erhalten und ihre Modelle mit ständig wachsenden Datenmengen erstellen können.

Es stellte sich heraus, dass die Studenten nicht allein waren. Dies war die Anfangszeit von Daten- und KI-Anwendungen in der Branche, und jeder stand vor ähnlichen Herausforderungen. Aufgrund der großen Nachfrage wechselte das Projekt zur Apache Software Foundation und wuchs zu einer riesigen Community heran.
Heute ist Spark der De-facto-Standard für die Datenverarbeitung und wächst:
- Es wurde im letzten Monat allein in PyPI und Maven Central 45 Millionen Mal heruntergeladen. Dies entspricht einem Wachstum von 90 % bei den Downloads im Vergleich zum Vorjahr.
- Es wird in mindestens 204 Ländern und Regionen verwendet.
- Es rangiert auf Platz 1 der bestbezahlten Technologien in der Entwicklerumfrage 2021 von Stack Overflow.
Der SIGMOD Systems Award ist eine Bestätigung für die Akzeptanz des Projekts sowie für seinen Einfluss darauf, dass künftige Generationen von Systemen Daten und KI als ein einheitliches Paket betrachten.
Photon: Neue Workloads und Lakehouse
Als Apache Spark immer beliebter wurde, stellten wir fest, dass Unternehmen damit mehr als nur umfangreiche Datenverarbeitung und machine learning durchführen wollten: Sie wollten herkömmliche interaktive Data Warehousing-Anwendungen auf denselben Datasets ausführen, die sie auch an anderer Stelle in ihrem Unternehmen verwendeten, wodurch die Verwaltung mehrerer Datensysteme überflüssig wurde. Dies führte zum Konzept der Lakehouse -Systeme: ein einziger Datenspeicher, der eine Verarbeitung im gro�ßen Maßstab und interaktive SQL-Abfragen durchführen kann und die Vorteile von Data Warehouse- und Data Lake-Systemen kombiniert.
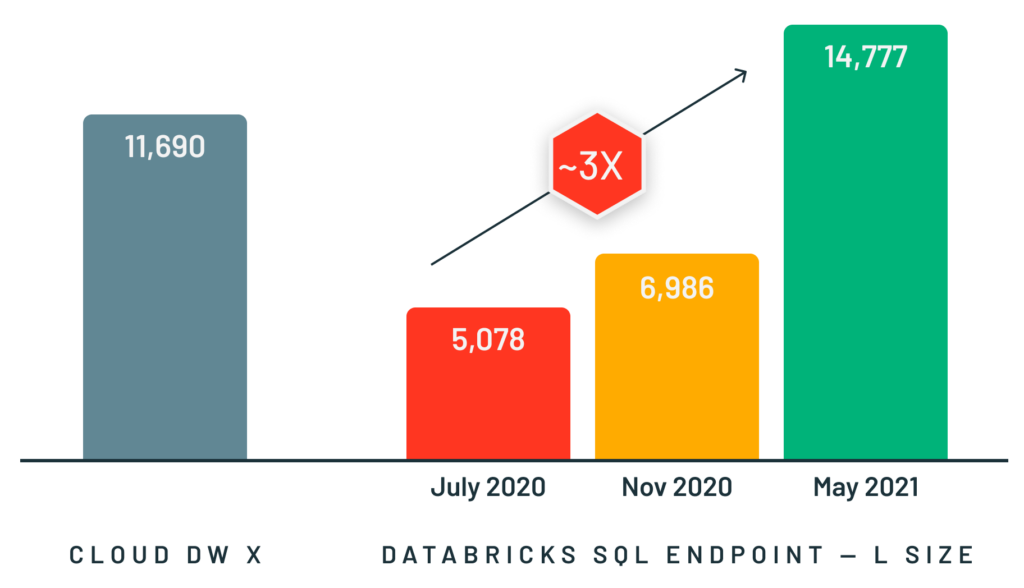
Um diese Art von Anwendungsfällen zu unterstützen, haben wir Photon entwickelt, eine schnelle, C++-basierte, vektorisierte Ausführungs-Engine für Spark- und SQL-Workloads, die hinter den vorhandenen Programmierschnittstellen von Spark läuft. Photon ermöglicht viel schnellere interaktive Abfragen sowie eine deutlich höhere Parallelität als Spark und unterstützt dabei die gleichen APIs und Workloads, einschließlich SQL-, Python- und Java-Anwendungen. Wir haben mit Photon bei Workloads jeder Größe hervorragende Ergebnisse erzielt, vom Aufstellen des Weltrekords im großen TPC-DS-Data-Warehouse-Benchmark im letzten Jahr bis hin zu einer dreimal höheren Performance bei kleinen, gleichzeitigen Abfragen.
Das Design und die Implementierung von Photon stellten eine Herausforderung dar, da die Engine die Ausdrucksstärke und Flexibilität von Spark beibehalten musste (um die breite Palette von Anwendungen zu unterstützen), niemals langsamer sein durfte (um Performance-Regressionen zu vermeiden) und bei unseren Ziel-Workloads deutlich schneller sein musste. Zudem musste Photon im Gegensatz zu einer herkömmlichen Data-Warehouse-Engine, die davon ausgeht, dass alle Daten in ein proprietäres Format geladen wurden, in der Lakehouse-Umgebung funktionieren und dabei Daten in offenen Formaten wie Delta Lake und Apache Parquet mit minimalen Annahmen über den Erfassungsprozess (z. B. Verfügbarkeit von Indizes oder Datenstatistiken) verarbeiten. Unser SIGMOD-Paper beschreibt, wie wir diese Herausforderungen angegangen sind, sowie viele technische Details der Implementierung von Photon.
Wir haben uns riesig gefreut, dass diese Arbeit als Best Industry Paper ausgezeichnet wurde, und wir hoffen, sie gibt Datenbankingenieuren und -forschern gute Anregungen zu den Herausforderungen dieses neuen Modells von Lakehouse-Systemen. Natürlich hat uns auch sehr begeistert, was unsere Kunden bisher mit Photon gemacht haben – die neue Engine macht bereits einen erheblichen Teil unserer Workload aus.
Wenn Sie an der SIGMOD teilnehmen, schauen Sie am Stand von Databricks vorbei und sagen Sie Hallo. Wir würden uns freuen, gemeinsam mit Ihnen über die Zukunft von Datensystemen zu sprechen. Als Dankeschön erhalten Sie ein „the best data warehouse is a lakehouse“-T-Shirt!

Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.