Delta Live Tables kündigt neue Funktionen und Leistungsoptimierungen an
DLT kündigt die Entwicklung von Enzyme an, einer für ETL-Workloads entwickelten Leistungsoptimierung, und startet mehrere neue Funktionen, darunter Enhanced Autoscaling
von Paul Lappas und Michael Armbrust
Seit der Verfügbarkeit von Delta Live Tables (DLT) in allen Clouds im April (Ankündigung) haben wir neue Funktionen eingeführt, um die Entwicklung zu erleichtern, das automatisierte Infrastrukturmanagement verbessert, eine neue Optimierungsschicht namens Project Enzyme angekündigt, um die ETL-Verarbeitung zu beschleunigen, und mehrere Unternehmensfunktionen sowie UX-Verbesserungen implementiert.
DLT ermöglicht es Analysten und Dateningenieuren, schnell produktionsreife Streaming- oder Batch-ETL-Pipelines in SQL und Python zu erstellen. DLT vereinfacht die ETL-Entwicklung, indem es Ihnen ermöglicht, Ihre Datenverarbeitungspipeline deklarativ zu definieren. DLT versteht die Abhängigkeiten Ihrer Pipeline und automatisiert fast alle betrieblichen Komplexitäten.
Delta Live Tables hat sich seit seiner Einführung zu einer treibenden Kraft für produktive ETL-Anwendungsfälle bei führenden Unternehmen auf der ganzen Welt entwickelt. DLT wird von über 1.000 Unternehmen genutzt, von Start-ups bis hin zu Großunternehmen, darunter ADP, Shell, H&R Block, Jumbo, Bread Finance und JLL.
Mit DLT können sich Ingenieure auf die Bereitstellung von Daten konzentrieren, anstatt Pipelines zu betreiben und zu warten, und von wichtigen Funktionen profitieren. Wir haben mehrere Unternehmensfunktionen und UX-Verbesserungen implementiert, darunter die Unterstützung für Change Data Capture (CDC), um kontinuierlich ankommende Daten effizient und einfach zu erfassen, und eine Vorschau von Enhanced Auto Scaling gestartet, das eine überlegene Leistung für Streaming-Workloads bietet. Schauen wir uns die Verbesserungen im Detail an:
Entwicklung vereinfachen
Wir haben unsere Benutzeroberfläche erweitert, um die Verwaltung des End-to-End-Lebenszyklus von ETL zu vereinfachen.
UX-Verbesserungen. Wir haben unsere Benutzeroberfläche erweitert, um die Verwaltung von DLT-Pipelines zu vereinfachen, Fehler anzuzeigen und Teammitgliedern mit umfangreichen Pipeline-ACLs Zugriff zu gewähren. Wir haben auch eine Observability-Benutzeroberfläche hinzugefügt, um Datenqualitätsmetriken in einer einzigen Ansicht anzuzeigen, und es einfacher gemacht, Pipelines direkt über die Benutzeroberfläche zu planen. Mehr erfahren.
Schaltfläche „Pipeline planen“. DLT ermöglicht es Ihnen, ETL-Pipelines kontinuierlich oder im Trigger-Modus auszuführen. Kontinuierliche Pipelines verarbeiten neue Daten, sobald sie eintreffen, und sind in Szenarien nützlich, in denen die Datenlatenz entscheidend ist. Viele Kunden entscheiden sich jedoch dafür, DLT-Pipelines im Trigger-Modus auszuführen, um die Pipeline-Ausführung und die Kosten genauer zu steuern. Um DLT-Pipelines einfach mit Databricks Jobs nach einem wiederkehrenden Zeitplan auszuführen, haben wir eine Schaltfläche „Planen“ in der DLT-Benutzeroberfläche hinzugefügt, mit der Benutzer einen wiederkehrenden Zeitplan mit nur wenigen Klicks einrichten können, ohne die DLT-Benutzeroberfläche verlassen zu müssen. Sie können auch eine Historie der Ausführungen anzeigen und schnell zu Ihren Jobdetails navigieren, um E-Mail-Benachrichtigungen zu konfigurieren. Mehr erfahren.
Change Data Capture (CDC). Mit DLT können Dateningenieure CDC einfach mit einer neuen deklarativen APPLY CHANGES INTO API in SQL oder Python implementieren. Diese neue Funktion ermöglicht es ETL-Pipelines, Quelldatenänderungen einfach zu erkennen und sie auf Datasets im gesamten Lakehouse anzuwenden. DLT verarbeitet Datenänderungen inkrementell in Delta Lake und kennzeichnet Datensätze zum Einfügen, Aktualisieren oder Löschen bei der Verarbeitung von CDC-Ereignissen. Mehr erfahren.
CDC Slowly Changing Dimensions – Typ 2. Wenn Sie mit sich ändernden Daten (CDC) arbeiten, müssen Sie oft Datensätze aktualisieren, um die aktuellsten Daten zu verfolgen. SCD Typ 2 ist eine Methode, um Aktualisierungen auf ein Ziel anzuwenden, sodass die Originaldaten erhalten bleiben. Wenn beispielsweise eine Benutzereinheit in der Datenbank zu einer anderen Adresse wechselt, können wir alle früheren Adressen für diesen Benutzer speichern. DLT unterstützt SCD Typ 2 für Organisationen, die eine Audit-Trail von Änderungen führen müssen. SCD2 behält eine vollständige Historie von Werten bei. Wenn sich der Wert eines Attributs ändert, wird der aktuelle Datensatz geschlossen, ein neuer Datensatz mit den geänderten Datenwerten wird erstellt und dieser neue Datensatz wird zum aktuellen Datensatz. Mehr erfahren.
Automatisierte Infrastrukturverwaltung
Enhanced Autoscaling (Vorschau). Das manuelle Skalieren von Clustern für optimale Leistung bei sich ändernden, unvorhersehbaren Datenvolumen – wie bei Streaming-Workloads – kann schwierig sein und zu Überprovisionierung führen. Das aktuelle Cluster-Autoscaling berücksichtigt keine Streaming-SLOs und skaliert möglicherweise nicht schnell genug hoch, selbst wenn die Verarbeitung hinter der Datenankunftsrate zurückbleibt, oder es skaliert nicht herunter, wenn die Last gering ist. DLT verwendet einen verbesserten Autoscaling-Algorithmus, der speziell für Streaming entwickelt wurde. Das Enhanced Autoscaling von DLT optimiert die Cluster-Auslastung und minimiert gleichzeitig die Gesamtlatenz. Dies geschieht durch Erkennung von Schwankungen bei Streaming-Workloads, einschließlich Daten, die auf die Aufnahme warten, und Bereitstellung der richtigen Menge an benötigten Ressourcen (bis zu einem vom Benutzer festgelegten Limit). Darüber hinaus fährt Enhanced Autoscaling Cluster bei geringer Auslastung ordnungsgemäß herunter, während die Evakuierung aller Aufgaben garantiert wird, um Beeinträchtigungen der Pipeline zu vermeiden. Infolgedessen sparen Workloads, die Enhanced Autoscaling verwenden, Kosten, da weniger Infrastrukturressourcen genutzt werden. Mehr erfahren.
Automatisierte Upgrade- & Release-Kanäle. DLT-Cluster verwenden eine DLT-Laufzeit, die auf Databricks Runtime (DBR) basiert. Databricks aktualisiert die DLT-Laufzeit etwa alle 1-2 Monate automatisch. DLT aktualisiert die DLT-Laufzeit automatisch, ohne dass eine Benutzerintervention erforderlich ist, und überwacht die Pipeline-Integrität nach dem Upgrade. Wenn DLT erkennt, dass die DLT-Pipeline aufgrund eines DLT-Laufzeit-Upgrades nicht gestartet werden kann, wird die Pipeline auf die vorherige, bekannte gute Version zurückgesetzt. Sie können frühzeitig vor Breaking Changes bei Init-Skripten oder anderem DBR-Verhalten gewarnt werden, indem Sie DLT-Kanäle nutzen, um die Vorschauversion der DLT-Laufzeit zu testen und automatisch benachrichtigt zu werden, wenn eine Regression auftritt. Databricks empfiehlt die Verwendung des CURRENT-Kanals für Produktions-Workloads. Mehr erfahren.
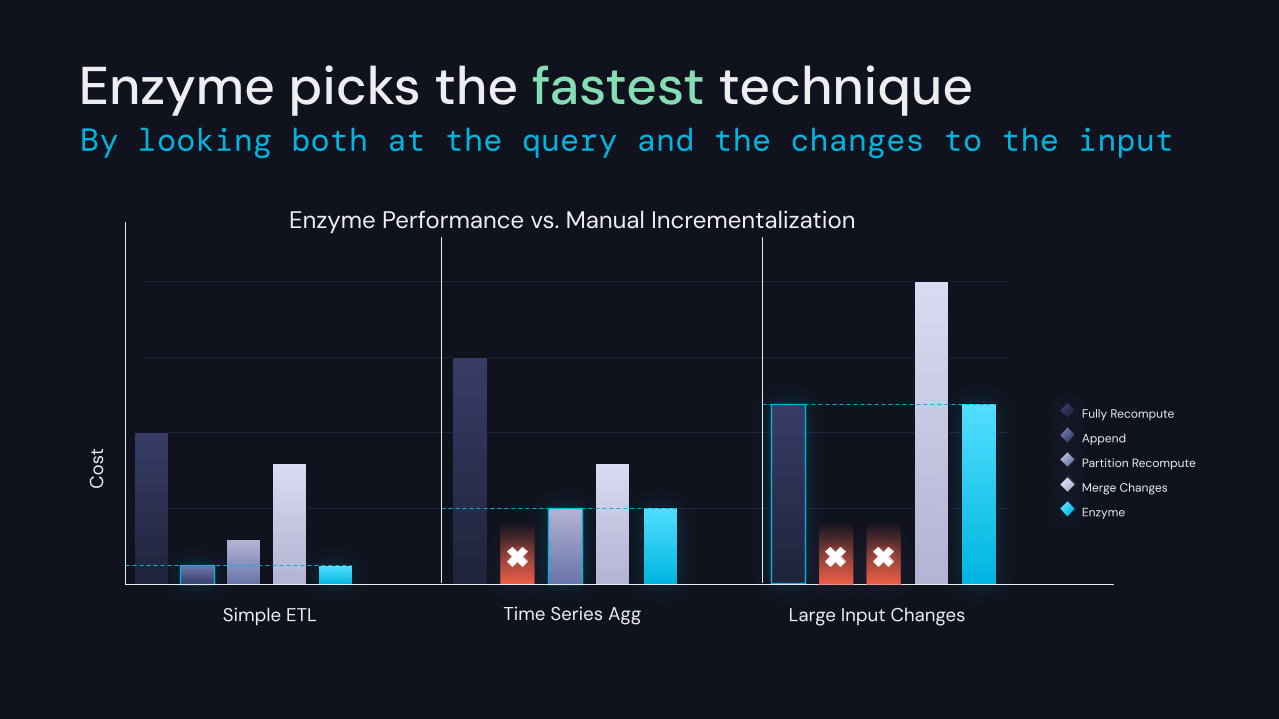
Ankündigung von Enzyme, einer neuen Optimierungsschicht, die speziell zur Beschleunigung des ETL-Prozesses entwickelt wurde
Die Transformation von Daten zur Vorbereitung für nachgelagerte Analysen ist eine Voraussetzung für die meisten anderen Workloads auf der Databricks-Plattform. Während SQL und DataFrames es Benutzern relativ einfach machen, ihre Transformationen auszudrücken, ändern sich die Eingabedaten ständig. Dies erfordert eine Neuberechnung der von ETL erzeugten Tabellen. Die Neuberechnung der Ergebnisse von Grund auf ist einfach, aber bei der Skala, auf der viele unserer Kunden arbeiten, oft zu teuer.
Wir freuen uns, Ihnen mitteilen zu können, dass wir Project Enzyme entwickeln, eine neue Optimierungsschicht für ETL. Enzyme hält eine Materialisierung der Ergebnisse einer gegebenen Abfrage, die in einer Delta-Tabelle gespeichert ist, effizient auf dem neuesten Stand. Es verwendet ein Kostenmodell, um zwischen verschiedenen Techniken zu wählen, einschließlich Techniken, die in traditionellen materialisierten Ansichten, Delta-zu-Delta-Streaming und manuellen ETL-Mustern, die von unseren Kunden häufig verwendet werden, verwendet werden.
Erste Schritte mit Delta Live Tables auf dem Lakehouse
Sehen Sie sich die Demo unten an, um die einfache Bedienung von DLT für Dateningenieure und Analysten zu entdecken:
Wenn Sie ein Databricks-Kunde sind, folgen Sie einfach der Anleitung für den Einstieg. Lesen Sie die Versionshinweise, um mehr über die Inhalte dieser GA-Version zu erfahren. Wenn Sie noch kein Databricks-Kunde sind, melden Sie sich für eine kostenlose Testversion an, und Sie können unsere detaillierten DLT-Preise hier einsehen.
Beteiligen Sie sich an der Konversation in der Databricks Community, wo datenbegeisterte Kollegen über die Ankündigungen und Updates des Data + AI Summit 2022 sprechen. Lernen. Vernetzen. Feiern.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.