Databricks Workspace Administration – Best Practices for Account, Workspace and Metastore Admins
Eine Geschichte von drei Admins
von Anindita Mahapatra, Mohan Mathews und Greg Wood
Dieser Blog ist Teil unserer Reihe „Admin Essentials“, in der wir Themen diskutieren, die für Databricks-Administratoren relevant sind. Andere Blogs umfassen unsere Best Practices für die Workspace-Verwaltung, DR-Strategien mit Terraform und viele mehr! Halten Sie Ausschau nach weiteren Inhalten, die bald erscheinen. In früheren Blogs, die sich an Administratoren richteten, haben wir besprochen, wie man eine starke Workspace-Organisation durch vorausschauendes Design und Automatisierung von Aspekten wie DR, CI/CD und System-Health-Checks aufbaut und pflegt. Ein ebenso wichtiger Aspekt der Administration ist die Organisation innerhalb Ihrer Workspaces – insbesondere wenn es um die vielen verschiedenen Arten von Admin-Personas geht, die innerhalb eines Lakehouse existieren können. In diesem Blog sprechen wir über die administrativen Überlegungen zur Verwaltung eines Workspaces, z. B. wie man:
- Richtlinien und Leitplanken einrichtet, um die Onboarding von neuen Benutzern und Anwendungsfällen zukunftssicher zu gestalten
- Die Nutzung von Ressourcen steuert
- Den zulässigen Datenzugriff sicherstellt
- Die Compute-Nutzung optimiert, um das Beste aus Ihrer Investition herauszuholen
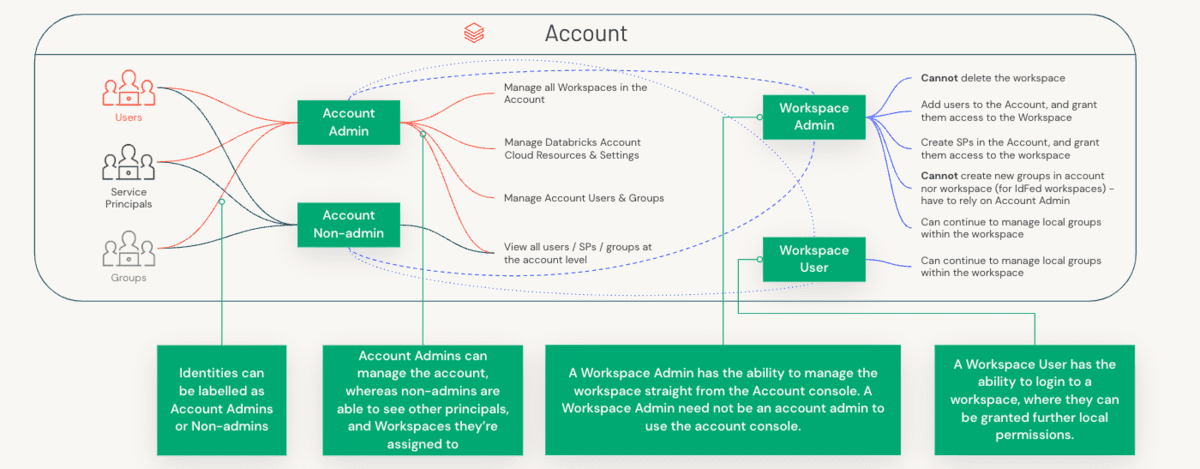
Um die Abgrenzung der Rollen zu verstehen, müssen wir zunächst den Unterschied zwischen einem Account Administrator und einem Workspace Administrator sowie die spezifischen Komponenten verstehen, die jede dieser Rollen verwaltet.
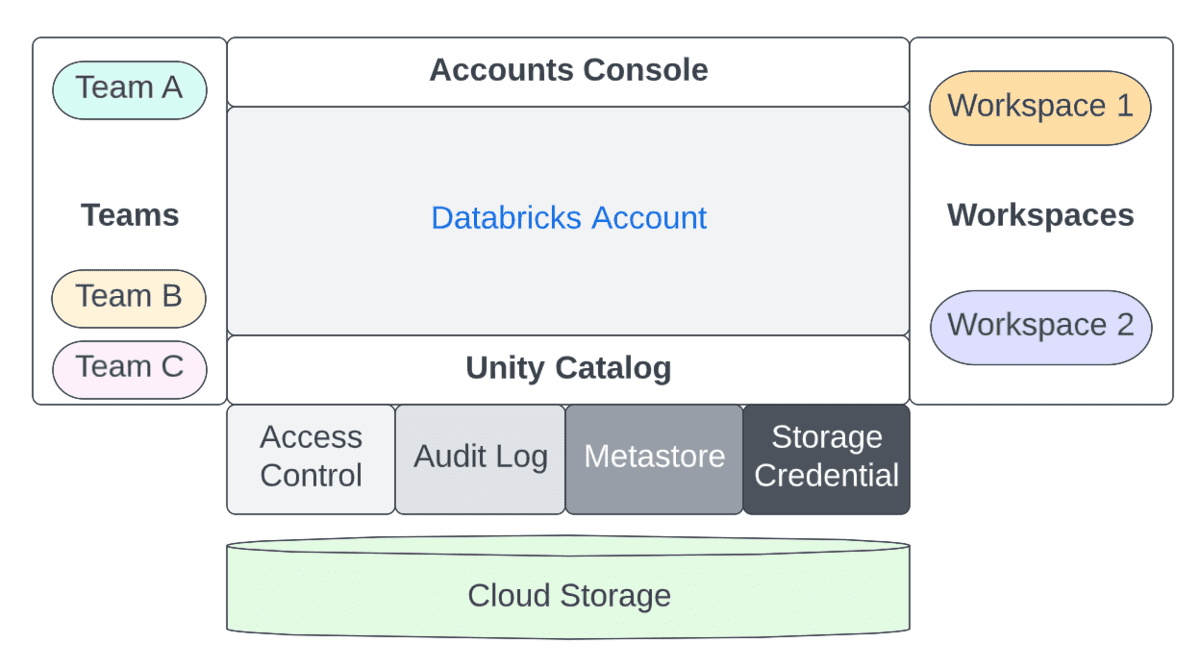
Account Admins vs. Workspace Admins vs. Metastore Admins
Administrative Belange sind sowohl auf Kontoebene (ein übergeordnetes Konstrukt, das oft 1:1 mit Ihrer Organisation abgebildet wird) als auch auf Workspace-Ebene (eine granularere Isolationsebene, die auf verschiedene Weise abgebildet werden kann, z. B. nach LOB) aufgeteilt. Betrachten wir die Aufteilung der Aufgaben zwischen diesen drei Rollen.
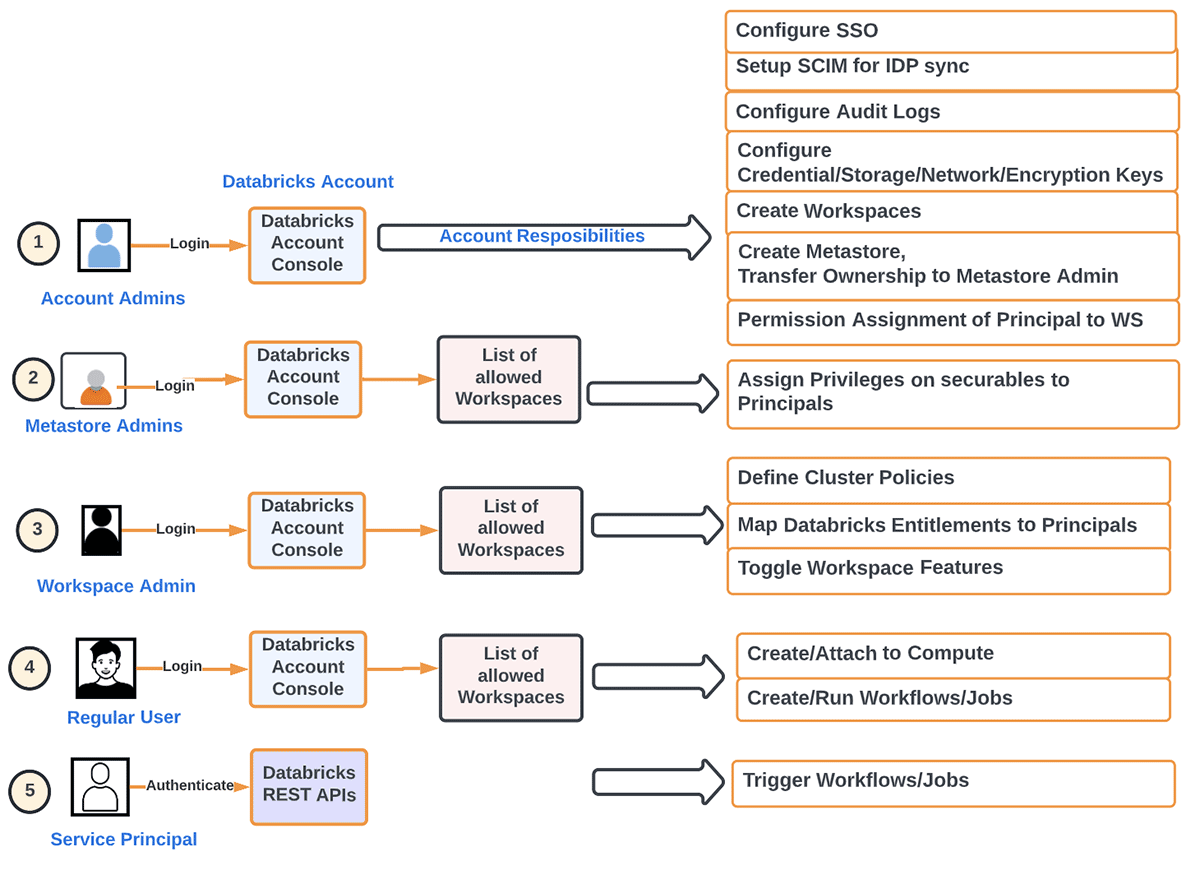
Anders ausgedrückt, können wir die Hauptverantwortlichkeiten eines Account Administrators wie folgt aufschlüsseln:
- Bereitstellung von Principals (Gruppen/Benutzer/Dienste) und SSO auf Kontoebene. Identity Federation bezieht sich auf die Zuweisung von Account-Level-Identitäten zu Workspaces direkt vom Konto aus.
- Konfiguration von Metastores
- Einrichtung von Audit Logs
- Überwachung der Nutzung auf Kontoebene (DBU, Abrechnung)
- Erstellung von Workspaces gemäß der gewünschten Organisationsmethode
- Verwaltung anderer Objekte auf Workspace-Ebene (Speicher, Anmeldeinformationen, Netzwerk usw.)
- Automatisierung von Entwicklungs-Workloads mit IaaC, um das menschliche Element in Produktions-Workloads zu entfernen
- Aktivieren/Deaktivieren von Funktionen auf Kontoebene, wie z. B. Serverless Workloads, Delta Sharing
Auf der anderen Seite sind die Hauptanliegen eines Workspace Administrators:
- Zuweisung geeigneter Rollen (Benutzer/Admin) auf Workspace-Ebene an Principals
- Zuweisung geeigneter Berechtigungen (ACLs) auf Workspace-Ebene an Principals
- Optional: SSO auf Workspace-Ebene einrichten
- Definition von Cluster-Richtlinien, um Principals zu berechtigen, damit sie
- Compute-Ressourcen (Cluster/Warehouses/Pools) definieren
- Orchestrierung (Jobs/Pipelines/Workflows) definieren
- Aktivieren/Deaktivieren von Funktionen auf Workspace-Ebene
- Zuweisung von Berechtigungen an Principals
- Datenzugriff (bei Verwendung von internem/externem Hive Metastore)
- Zugriff von Principals auf Compute-Ressourcen verwalten
- Verwaltung externer URLs für Funktionen wie Repos (einschließlich Whitelisting)
- Sicherheit und Datenschutz kontrollieren
- DBFS deaktivieren/einschränken, um versehentliche Datenexposition zwischen Teams zu verhindern
- Herunterladen von Ergebnisdaten (aus Notebooks/DBSQL) verhindern, um Datenexfiltration zu verhindern
- Zugriffskontrolle aktivieren (Workspace-Objekte, Cluster, Pools, Jobs, Tabellen usw.)
- Definition der Protokollbereitstellung auf Cluster-Ebene (d. h. Einrichtung von Speicher für Cluster-Protokolle, idealerweise über Cluster-Richtlinien)
Um die Unterschiede zwischen Account- und Workspace-Admin zusammenzufassen, erfasst die folgende Tabelle die Trennung zwischen diesen beiden Personas für einige Schlüsseldimensionen:
| Account Admin | Metastore Admin | Workspace Admin | |
|---|---|---|---|
| Workspace Management | - Workspaces erstellen, aktualisieren, löschen - Können andere Administratoren hinzufügen |
Nicht anwendbar | - Verwaltet nur Assets innerhalb eines Workspaces |
| Benutzerverwaltung | - Benutzer, Gruppen und Service Principals erstellen oder SCIM verwenden, um Daten von IDPs zu synchronisieren. - Principals mit der Permission Assignment API zu Workspaces berechtigen |
Nicht anwendbar | - Wir empfehlen die Verwendung von UC für die zentrale Steuerung all Ihrer Daten-Assets (Securables). Identity Federation ist für jeden Workspace aktiviert, der mit einem Unity Catalog (UC) Metastore verknüpft ist. - Für Workspaces, die auf Identity Federation aktiviert sind, richten Sie SCIM auf Kontoebene für alle Principals ein und stoppen Sie SCIM auf Workspace-Ebene. - Für Nicht-UC-Workspaces können Sie SCIM auf Workspace-Ebene verwenden (diese Benutzer werden jedoch auch zu Identitäten auf Kontoebene hochgestuft). - Auf Workspace-Ebene erstellte Gruppen gelten als „lokale“ Gruppen auf Workspace-Ebene und haben keinen Zugriff auf Unity Catalog |
| Datenzugriff und -verwaltung | - Metastore(s) erstellen - Workspace(s) mit Metastore verknüpfen - Metastore-Besitz an Metastore Admin/Gruppe übertragen |
Mit Unity Catalog: - Berechtigungen für alle Securables (Katalog, Schema, Tabellen, Ansichten) des Metastore verwalten - Zugriff auf Kataloge, Schemata (Datenbanken), Tabellen, Ansichten, externe Speicherorte und Speicheranmeldeinformationen an Data Stewards/Besitzer GEWÄHREN (delegieren) |
- Heute verwenden Kunden mit Hive-Metastores eine Vielzahl von Konstrukten zum Schutz des Datenzugriffs, wie z. B. Instance Profiles auf AWS, Service Principals in Azure, Table ACLs, Credential Passthrough und andere. - Mit Unity Catalog wird dies auf Kontoebene definiert und ANSI GRANTS werden verwendet, um alle Securables per ACL zu verwalten |
| Clusterverwaltung | Nicht anwendbar | Nicht anwendbar | - Cluster für verschiedene Personas/Größen für DE/ML/SQL-Personas für S/M/L-Workloads erstellen - allow-cluster-create-Berechtigung von der Standardgruppe users entfernen. - Cluster-Richtlinien erstellen, Zugriff auf Richtlinien für geeignete Gruppen gewähren - Gruppen die Berechtigung Can_Use für SQL Warehouses erteilen |
| Workflow-Verwaltung | Nicht anwendbar | Nicht anwendbar | - Sicherstellen, dass Job/DLT/Allzweck-Cluster-Richtlinien vorhanden sind und Gruppen Zugriff darauf haben - App-Purpose-Cluster vorab erstellen, die Benutzer neu starten können |
| Budgetverwaltung | - Budgets pro Workspace/SKU/Cluster-Tags einrichten - Nutzung nach Tags in der Account Console überwachen (Roadmap) - Abrechenbare Nutzungs-Systemtabelle zur Abfrage über DBSQL (Roadmap) |
Nicht anwendbar | Nicht anwendbar |
| Optimieren / Abstimmen | Nicht anwendbar | Nicht anwendbar | - Rechenleistung maximieren; Neuesten DBR verwenden; Photon verwenden - Arbeiten Sie mit den Teams für Geschäftsbereiche/Center Of Excellence zusammen, um Best Practices und Optimierungen zu befolgen, damit Sie das Beste aus Ihrer Infrastrukturinvestition herausholen |
Dimensionierung eines Workspaces zur Erfüllung des Spitzenbedarfs an Rechenleistung
Die maximale Anzahl von Cluster-Knoten (indirekt der größte Job oder die maximale Anzahl gleichzeitiger Jobs) wird durch die maximale Anzahl verfügbarer IPs im VPC bestimmt. Daher ist die korrekte Dimensionierung des VPC ein wichtiges Designkriterium. Jeder Knoten belegt 2 IPs (in Azure, AWS). Hier sind die relevanten Details für die Cloud Ihrer Wahl: AWS, Azure, GCP. Wir verwenden ein Beispiel von Databricks auf AWS, um dies zu veranschaulichen. Verwenden Sie diese, um CIDR zu IP zuzuordnen. Der für einen E2-Workspace zulässige VPC-CIDR-Bereich ist /25 - /16. Es müssen mindestens 2 private Subnetze in 2 verschiedenen Verfügbarkeitszonen konfiguriert werden. Die Subnetzmasken sollten zwischen /16 und /17 liegen. VPCs sind logische Isolationseinheiten, und solange 2 VPCs nicht miteinander kommunizieren müssen, d. h. miteinander verbunden sind, können sie den gleichen Bereich haben. Wenn sie dies jedoch tun, muss darauf geachtet werden, eine IP-Überlappung zu vermeiden. Nehmen wir ein Beispiel für einen VPC mit dem CIDR-Bereich /16:
| VPC CIDR /16 | Max. Anzahl IPs für diesen VPC: 65.536 | Einzel-/Multi-Knoten-Cluster werden in einem Subnetz gestartet |
| 2 AZs | Wenn jede AZ /17 ist: => 32.768 * 2 = 65.536 IPs, kein anderes Subnetz möglich | 32.768 IPs => maximal 16.384 Knoten in jedem Subnetz |
| Wenn jede AZ stattdessen /23 ist: => 512 * 2 = 1.024 IPs, 65.536 - 1.024 = 64.512 IPs übrig | 512 IPs => maximal 256 Knoten in jedem Subnetz | |
| 4 AZs | Wenn jede AZ /18 ist: 16.384 * 4 = 65.536 IPs, kein anderes Subnetz möglich | 16.384 IPs => maximal 8192 Knoten in jedem Subnetz |
Balance zwischen Kontrolle und Agilität für Workspace-Administratoren
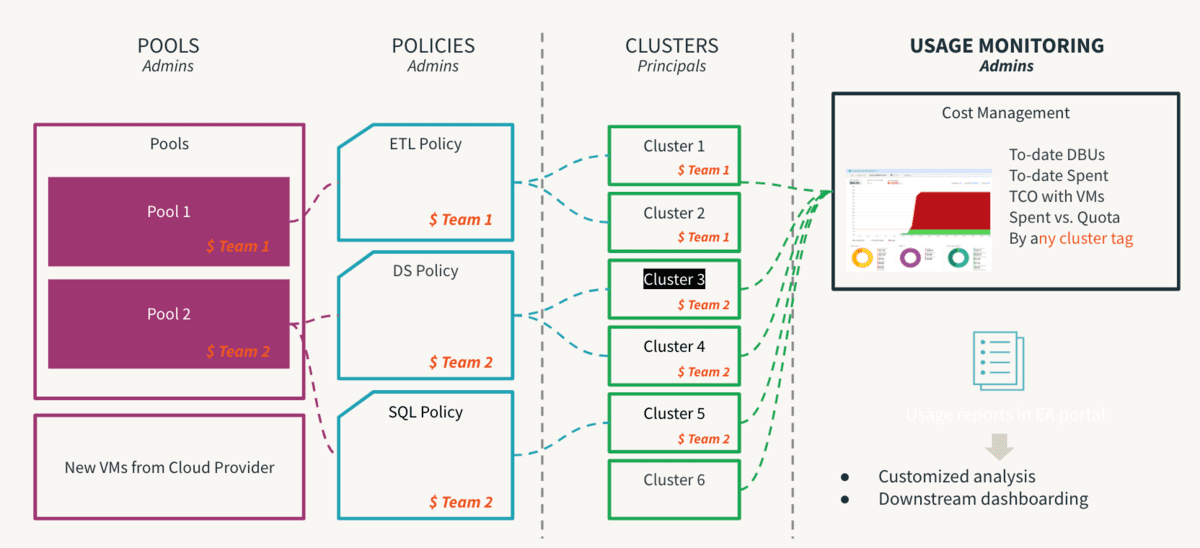
Rechenleistung ist die teuerste Komponente jeder Cloud-Infrastrukturinvestition. Daten-Demokratisierung führt zu Innovation, und die Ermöglichung von Self-Service ist der erste Schritt zur Schaffung einer datengesteuerten Kultur. In einer Multi-Tenant-Umgebung kann ein unerfahrener Benutzer oder ein unbeabsichtigter menschlicher Fehler jedoch zu unkontrollierbaren Kosten oder unbeabsichtigten Offenlegungen führen. Wenn die Kontrollen zu streng sind, entstehen Engpässe beim Zugriff und Innovation wird erstickt. Administratoren müssen also Leitplanken einrichten, um Self-Service ohne die damit verbundenen Risiken zu ermöglichen. Darüber hinaus sollten sie die Einhaltung dieser Kontrollen überwachen können. Hier kommen Cluster-Richtlinien ins Spiel, bei denen Regeln definiert und Berechtigungen zugeordnet werden, damit der Benutzer innerhalb zulässiger Grenzen agiert und sein Entscheidungsprozess erheblich vereinfacht wird. Es ist zu beachten, dass Richtlinien durch Prozesse unterstützt werden müssen, um wirklich wirksam zu sein, damit einmalige Ausnahmen durch Prozesse verwaltet werden können, um unnötiges Chaos zu vermeiden. Ein wichtiger Schritt dieses Prozesses ist die Entfernung der Berechtigung allow-cluster-create aus der Standardgruppe users in einem Workspace, damit Benutzer nur Rechenressourcen nutzen können, die von Cluster-Richtlinien verwaltet werden. Die folgenden sind die Top-Empfehlungen für Best Practices für Cluster-Richtlinien und können wie folgt zusammengefasst werden:
- Verwenden Sie T-Shirt-Größen, um Standard-Cluster-Vorlagen bereitzustellen
- Nach Workload-Größe (klein, mittel, groß)
- Nach Persona (DE/ ML/ BI)
- Nach Kompetenz (Citizen/ Advanced)
- Verwalten Sie die Governance, indem Sie die Verwendung erzwingen von
- Tags: Zuordnung nach Team, Benutzer, Anwendungsfall
- Namensgebung sollte standardisiert sein
- Einige Attribute obligatorisch zu machen, hilft bei der konsistenten Berichterstattung
- Tags: Zuordnung nach Team, Benutzer, Anwendungsfall
- Kontrollieren Sie den Verbrauch, indem Sie einschränken
- DBU-Burn-Rate und Zweck der Richtlinie
- Auto-Termination-Timeout, Skalierung min/max Größe
Überlegungen zur Rechenleistung
Im Gegensatz zu festen On-Premise-Compute-Infrastrukturen bietet die Cloud Elastizität und Flexibilität, um die richtige Rechenleistung an die betrachtete Workload und SLA anzupassen. Das folgende Diagramm zeigt die verschiedenen Optionen. Die Eingaben sind Parameter wie Art der Workload oder Umgebung, und die Ausgabe ist die Art und Größe der Rechenleistung, die am besten passt.
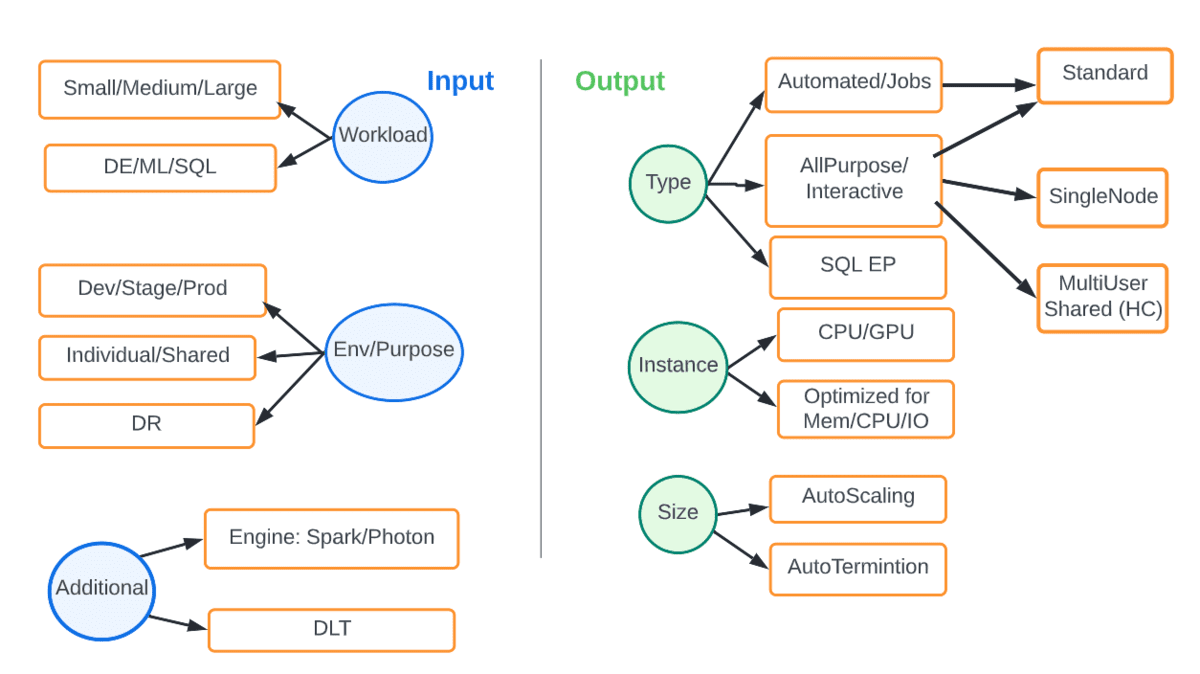
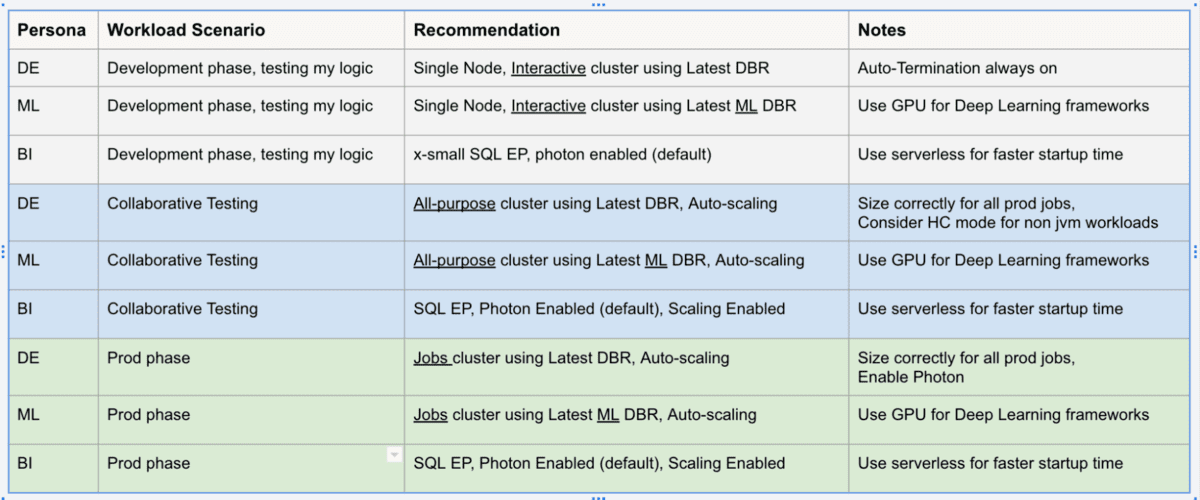
Zum Beispiel sollte eine Produktions-DE-Workload immer auf automatisierten Job-Clustern laufen, vorzugsweise mit dem neuesten DBR, mit Autoscaling und unter Verwendung der Photon-Engine. Die folgende Tabelle erfasst einige gängige Szenarien.
Workflow-Überlegungen
Nachdem die Anforderungen an die Rechenleistung formalisiert wurden, müssen wir uns Folgendes ansehen:
- Wie Workflows definiert und ausgelöst werden
- Wie Tasks gemeinsam genutzte Rechenressourcen untereinander nutzen können
- Wie Task-Abhängigkeiten verwaltet werden
- Wie fehlgeschlagene Tasks erneut versucht werden können
- Wie Versions-Upgrades (Spark, Bibliothek) und Patches angewendet werden
Dies sind Überlegungen zu Data Engineering und DevOps, die sich auf den Anwendungsfall konzentrieren und typischerweise eine direkte Angelegenheit eines Administrators sind. Es gibt einige Hygieneaufgaben, die überwacht werden können, wie zum Beispiel:
- Ein Workspace hat ein maximales Limit für die Gesamtzahl der konfigurierten Jobs. Aber viele dieser Jobs werden möglicherweise nicht aufgerufen und müssen bereinigt werden, um Platz für echte Jobs zu schaffen. Ein Administrator kann Überprüfungen durchführen, um die Liste der gültigen stillgelegten, nicht mehr benötigten Jobs zu ermitteln.
- Alle Produktionsjobs sollten als Service Principal ausgeführt werden und der Benutzerzugriff auf eine Produktionsumgebung sollte stark eingeschränkt sein. Überprüfen Sie die Job-Berechtigungen.
- Jobs können fehlschlagen, daher sollte jeder Job für Fehlerbenachrichtigungen und optional für Wiederholungsversuche konfiguriert werden. Überprüfen Sie hier email_notifications, max_retries und andere Eigenschaften
- Jeder Job sollte mit Cluster-Richtlinien verknüpft und zur Zuordnung ordnungsgemäß getaggt sein.
DLT: Beispiel für ein ideales Framework für zuverlässige Pipelines im großen Maßstab
Durch die Zusammenarbeit mit Tausenden von Kunden, großen und kleinen, in verschiedenen Branchen wurden gemeinsame Datenherausforderungen für Entwicklung und Operationalisierung offensichtlich, weshalb Databricks Delta Live Tables (DLT) entwickelt hat. Es handelt sich um eine verwaltete Plattform, die die Entwicklung und Wartung von ETL-Workloads vereinfacht, indem deklarative Pipelines erstellt werden können, bei denen Sie das „Was“ angeben und nicht das „Wie“. Dies vereinfacht die Aufgaben eines Dateningeieurs und führt zu weniger Support-Szenarien für Administratoren.
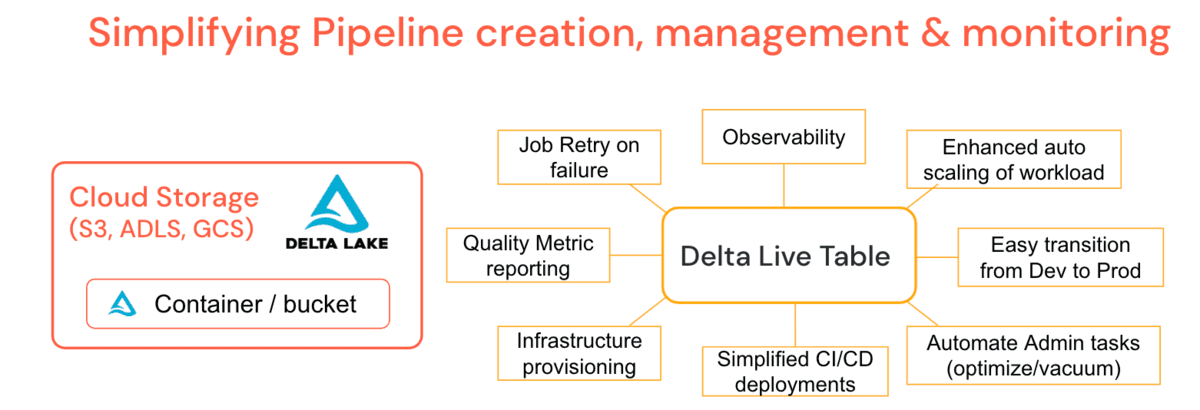
DLT integriert gängige Admin-Funktionen wie periodische optimize & vacuum Jobs direkt in die Pipeline-Definition mit einem Wartungsjob, der sicherstellt, dass diese ohne zusätzliches „Babysitting“ ausgeführt werden. DLT bietet eine tiefe Beobachtbarkeit von Pipelines für vereinfachte Operationen wie Lineage, Monitoring und Datenqualitätsprüfungen. Wenn beispielsweise der Cluster beendet wird, versucht die Plattform im Produktionsmodus automatisch einen Neustart, anstatt darauf zu angewiesen zu sein, dass der Data Engineer ihn explizit bereitgestellt hat. Enhanced Auto-Scaling kann plötzliche Datenstöße bewältigen, die eine Vergrößerung des Clusters erfordern, und skaliert dann wieder herunter. Mit anderen Worten, automatische Cluster-Skalierung & Pipeline-Fehlertoleranz sind eine Plattformfunktion. Drehscheiben-Latenzen ermöglichen es Ihnen, Pipelines im Batch- oder Streaming-Modus auszuführen und Entwicklungs-Pipelines mit relativer Leichtigkeit in die Produktion zu überführen, indem Sie die Konfiguration anstelle des Codes verwalten. Sie können die Kosten Ihrer Pipelines durch die Nutzung von DLT-spezifischen Cluster-Richtlinien kontrollieren. DLT aktualisiert auch automatisch Ihre Laufzeitumgebung, wodurch die Verantwortung von Administratoren oder Data Engineers entfällt und Sie sich nur auf die Generierung von Geschäftswert konzentrieren können.
UC: Beispiel für ein ideales Data Governance Framework
Unity Catalog (UC) ermöglicht es Unternehmen, ein gemeinsames Sicherheitsmodell für Tabellen und Dateien für alle Workspaces unter einem einzigen Konto zu übernehmen, was bisher durch einfache GRANT-Anweisungen nicht möglich war. Durch die Gewährung und Überprüfung aller Zugriffe auf Daten, Tabellen/oder Dateien von einem DE/DS-Cluster oder SQL Warehouse aus können Unternehmen ihre Audit- und Überwachungsstrategie vereinfachen, ohne auf Cloud-spezifische Mechanismen angewiesen zu sein. Die Hauptfunktionen, die UC bietet, sind:
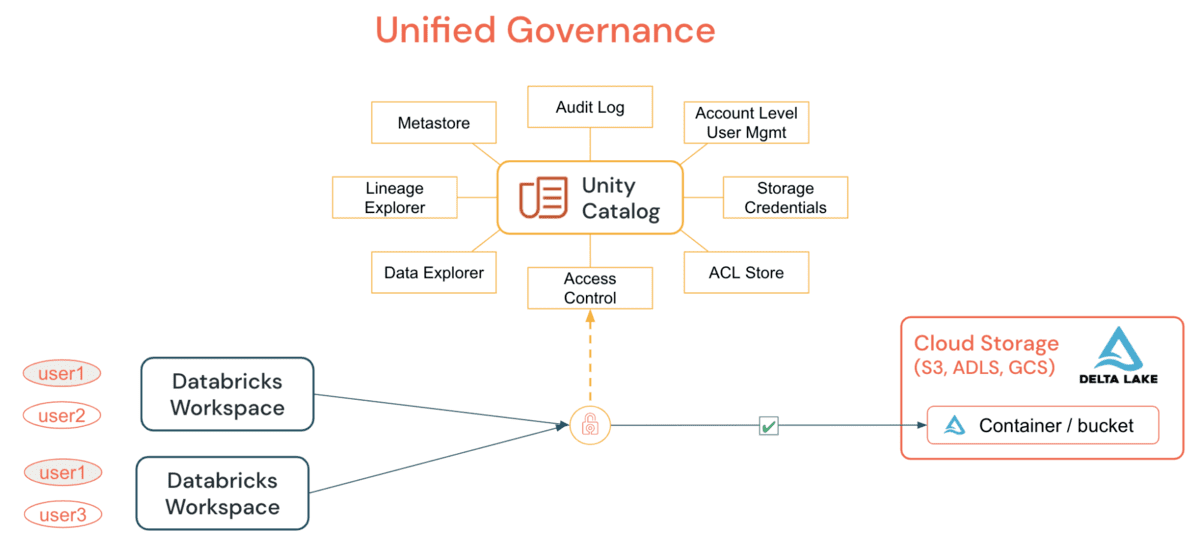
UC vereinfacht die Aufgabe eines Administrators (sowohl auf Konto- als auch auf Workspace-Ebene), indem es die Definitionen, die Überwachung und die Auffindbarkeit von Daten über den Metastore zentralisiert und die sichere gemeinsame Nutzung von Daten unabhängig von der Anzahl der angeschlossenen Workspaces erleichtert. Durch die Nutzung des „Einmal definieren, überall sichern“-Modells hat dies den zusätzlichen Vorteil, dass versehentliche Datenoffenlegung vermieden wird, wenn die Berechtigungen eines Benutzers in einem Workspace versehentlich falsch dargestellt werden und ihm so ein Hintertürchen zum Zugriff auf Daten offensteht, die nicht für seinen Konsum bestimmt waren. All dies kann einfach durch die Nutzung von Account Level Identities und Data Permissions erreicht werden. UC Audit Logging ermöglicht die vollständige Einsicht in alle Aktionen aller Benutzer auf allen Ebenen und bei allen Objekten. Wenn Sie detaillierte Audit-Protokollierung konfigurieren, wird jeder Befehl, der von einem Notebook oder Databricks SQL ausgeführt wird, erfasst. Der Zugriff auf schützenswerte Objekte kann entweder von einem Metastore-Administrator, dem Eigentümer eines Objekts oder dem Eigentümer des Katalogs oder Schemas, das das Objekt enthält, gewährt werden. Es wird empfohlen, dass der Account-Administrator die Metastore-Rolle delegiert, indem er eine Gruppe als Metastore-Administratoren nominiert, deren alleiniger Zweck die Gewährung der richtigen Zugriffsrechte ist.
Empfehlungen und Best Practices
- Die Rollen und Verantwortlichkeiten von Account-Administratoren, Metastore-Administratoren und Workspace-Administratoren sind klar definiert und ergänzen sich. Workflows wie Automatisierung, Änderungsanfragen, Eskalationen usw. sollten an die entsprechenden Eigentümer weitergeleitet werden, unabhängig davon, ob die Workspaces von einer Geschäftseinheit (LOB) eingerichtet oder von einem zentralen Center of Excellence verwaltet werden.
- Account Level Identities sollten aktiviert werden, da dies eine zentralisierte Verwaltung von Prinzipalen für alle Workspaces ermöglicht und somit die Administration vereinfacht. Wir empfehlen die Einrichtung von Funktionen wie SSO, SCIM und Audit Logs auf Kontoebene. Workspace-Level SSO ist weiterhin erforderlich, bis die SSO Federation-Funktion verfügbar ist.
- Cluster-Richtlinien sind ein mächtiges Werkzeug, das Leitplanken für effektives Self-Service bietet und die Rolle eines Workspace-Administrators erheblich vereinfacht. Einige Beispielrichtlinien finden Sie hier. Der Account-Administrator sollte einfache Standardrichtlinien basierend auf der primären Persona/T-Shirt-Größe bereitstellen, idealerweise durch Automatisierung wie Terraform. Workspace-Administratoren können diese Liste für feinere Kontrollen erweitern. In Kombination mit einem angemessenen Prozess können alle Ausnahmeszenarien problemlos bewältigt werden.
- Die laufende Nutzung für alle Workload-Typen über alle Workspaces hinweg ist für Account-Administratoren über die Account-Konsole sichtbar. Wir empfehlen die Einrichtung der Bereitstellung von Abrechnungsnutzungsprotokollen, damit diese alle in Ihrem zentralen Cloud-Speicher für Verrechnung und Analyse landen. Die Budget-API (in Vorschau) sollte auf Kontoebene konfiguriert werden, was es Account-Administratoren ermöglicht, Schwellenwerte auf Workspace-, SKU- und Cluster-Tag-Ebene zu erstellen und Benachrichtigungen über die Nutzung zu erhalten, damit rechtzeitig Maßnahmen ergriffen werden können, um die zugewiesenen Budgets einzuhalten. Verwenden Sie ein Tool wie Overwatch, um die Nutzung auf einer noch granulareren Ebene zu verfolgen und Bereiche zu identifizieren, in denen Verbesserungen bei der Nutzung von Rechenressourcen erzielt werden können.
- Die Databricks-Plattform entwickelt sich ständig weiter und vereinfacht die Aufgabe der verschiedenen Daten-Personas, indem sie gängige Admin-Funktionalitäten in die Plattform abstrahiert. Unsere Empfehlung ist, Delta Live Tables für neue Pipelines und Unity Catalog für die gesamte Benutzerverwaltung und Datenzugriffskontrolle zu verwenden.
Schließlich ist es wichtig zu beachten, dass für die meisten dieser Best Practices und tatsächlich für die meisten Dinge, die wir in diesem Blog erwähnen, Koordination und Teamarbeit für den Erfolg entscheidend sind. Obwohl es theoretisch möglich ist, dass Account- und Workspace-Admins isoliert arbeiten, widerspricht dies nicht nur den allgemeinen Lakehouse-Prinzipien, sondern erschwert auch das Leben aller Beteiligten. Vielleicht ist der wichtigste Ratschlag, den Sie aus diesem Artikel mitnehmen können, die Verbindung von Account-/Workspace-Admins + Projekt-/Datenleitern + Benutzern innerhalb Ihrer eigenen Organisation. Mechanismen wie Teams/Slack-Kanäle, eine E-Mail-Alias-Liste und/oder ein wöchentliches Treffen haben sich als erfolgreich erwiesen. Die effektivsten Organisationen, die wir hier bei Databricks sehen, sind diejenigen, die Offenheit nicht nur in ihrer Technologie, sondern auch in ihren Abläufen leben. Halten Sie Ausschau nach weiteren Blogs für Administratoren, die bald erscheinen, von Empfehlungen zur Protokollierung und Exfiltration bis hin zu spannenden Übersichten unserer Plattformfunktionen, die sich auf die Verwaltung konzentrieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.