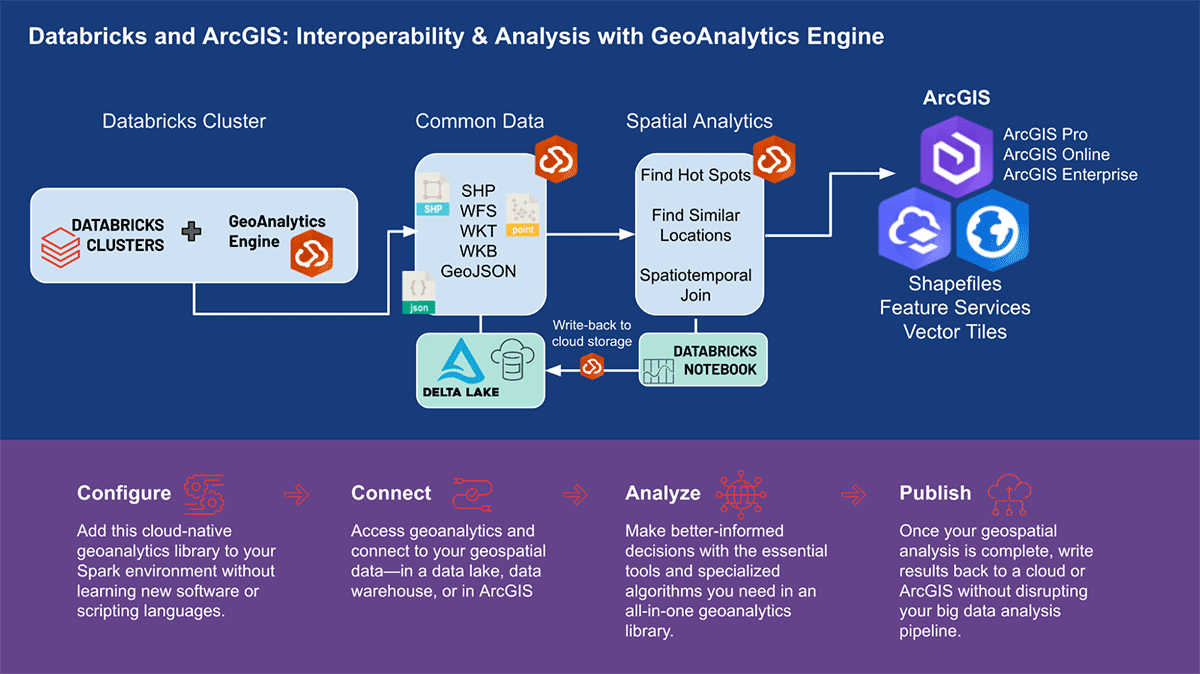
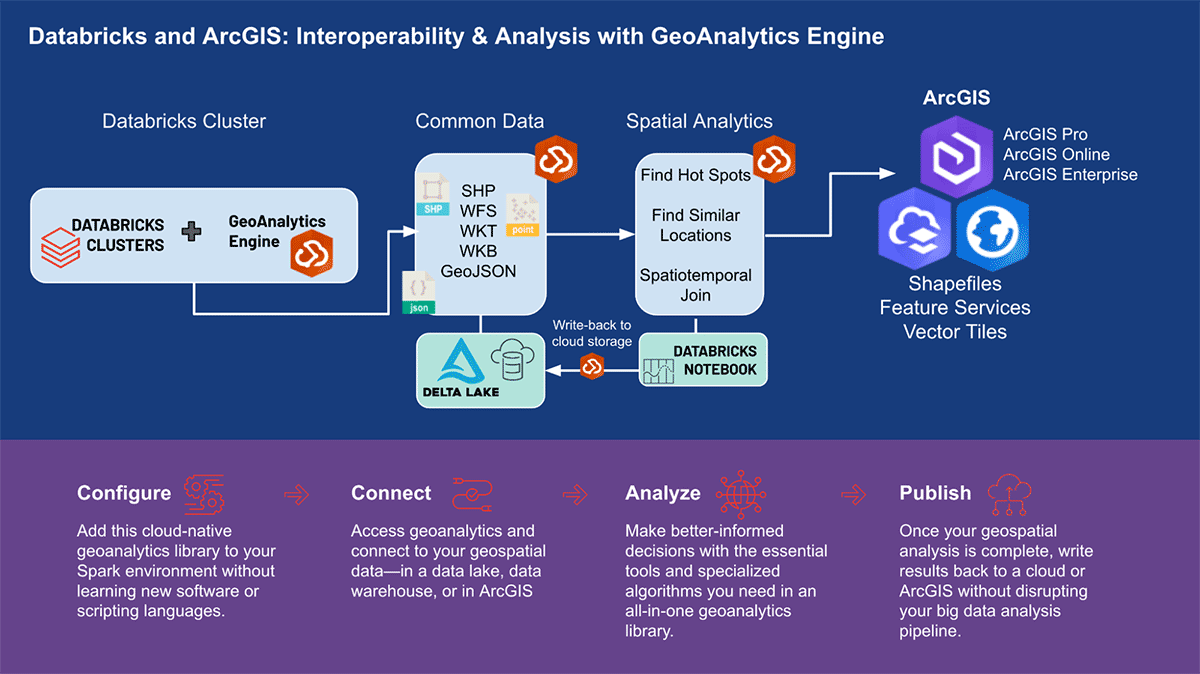
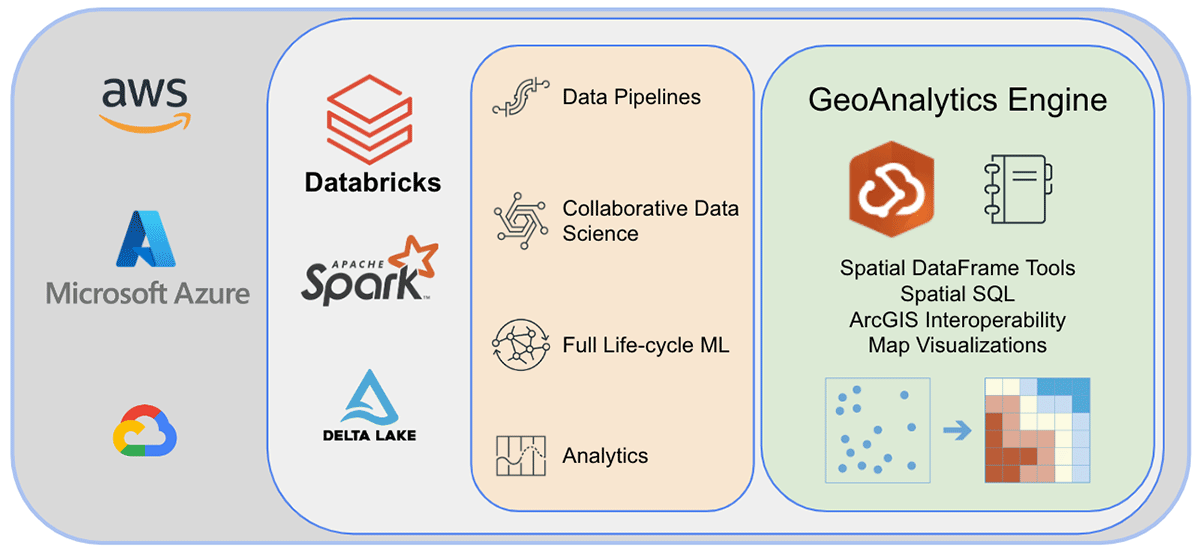
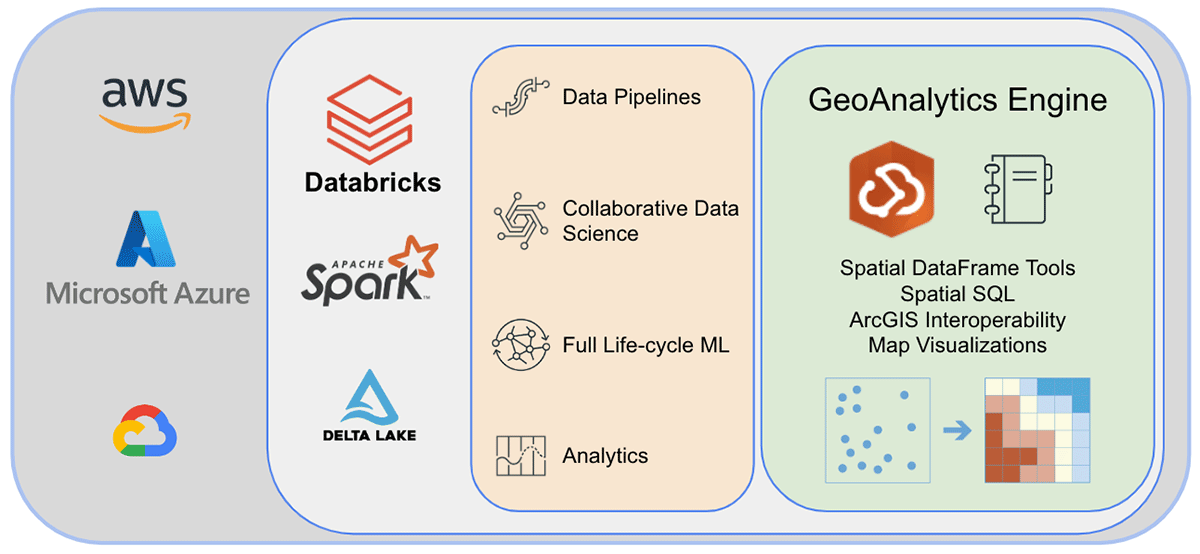
ArcGIS GeoAnalytics Engine in Databricks
Skalierbare Geodatenanalyse in einem Data Science Workflow
von Kent Marten und Arif Masrur
Dies ist ein gemeinsamer Beitrag von Esri und Databricks. Wir danken Senior Solution Engineer Arif Masrur, Ph.D. bei Esri für seine Beiträge.
Fortschritte im Bereich Big Data haben Organisationen in allen Branchen in die Lage versetzt, kritische wissenschaftliche, gesellschaftliche und geschäftliche Probleme zu lösen. Die Entwicklung von Big Data-Infrastrukturen unterstützt Datenanalysten, Ingenieure und Wissenschaftler bei der Bewältigung der Kernherausforderungen im Umgang mit Big Data – Volumen, Geschwindigkeit, Wahrhaftigkeit, Wert und Vielfalt. Die Verarbeitung und Analyse riesiger Geodatenmengen birgt jedoch eigene Herausforderungen. Jeden Tag werden Hunderte von Exabytes an standortbezogenen Daten generiert. Diese Datensätze enthalten eine breite Palette von Verbindungen und komplexen Beziehungen zwischen realen Entitäten, was fortschrittliche Werkzeuge erfordert, die in der Lage sind, diese vielschichtigen Beziehungen durch optimierte Operationen wie räumliche und raumzeitliche Joins effektiv zu verknüpfen. Die zahlreichen Geodatenformate, die für eine effiziente skalierte Analyse aufgenommen, verifiziert und standardisiert werden müssen, erhöhen die Komplexität.
Einige der Schwierigkeiten bei der Arbeit mit geografischen Daten werden durch die kürzlich angekündigte Unterstützung für integrierte H3-Ausdrücke in Databricks behoben. Es gibt jedoch viele Geodaten-Anwendungsfälle, von denen einige komplexer sind oder sich eher auf Geometrie als auf Gitterindizes konzentrieren. Benutzer können auf der Databricks-Plattform mit einer Reihe von Werkzeugen und Bibliotheken arbeiten und dabei zahlreiche Lakehouse-Funktionen nutzen.
Esri, der weltweit führende Anbieter von GIS-Software, bietet eine umfassende Palette von Werkzeugen, darunter ArcGIS Enterprise, ArcGIS Pro und ArcGIS Online, zur Lösung der oben genannten Geoanalyse-Herausforderungen. Organisationen und Datenpraktiker, die Databricks nutzen, benötigen Zugriff auf Werkzeuge, mit denen sie ihre tägliche Arbeit außerhalb der ArcGIS-Umgebung erledigen können. Deshalb freuen wir uns, die erste Version von ArcGIS GeoAnalytics Engine (im Folgenden GA Engine genannt) anzukündigen, die es Datenwissenschaftlern, Ingenieuren und Analysten ermöglicht, ihre Geodaten in ihren bestehenden Big Data-Analyseumgebungen zu analysieren. Insbesondere ist diese Engine ein Plugin für Apache Spark™, das DataFrames um sehr schnelle räumliche Verarbeitungs- und Analysefunktionen erweitert, die für die Ausführung in Databricks bereit sind.
Vorteile der ArcGIS GeoAnalytics Engine
Esris GA Engine ermöglicht Datenwissenschaftlern den Zugriff auf Geoanalysefunktionen und -werkzeuge innerhalb ihrer Databricks-Umgebung. Die Hauptmerkmale der GA Engine sind:
- Über 120 räumliche SQL-Funktionen – Erstellen Sie Geometrien, testen Sie räumliche Beziehungen und mehr mit Python- oder SQL-Syntax
- Leistungsstarke Analysewerkzeuge – Führen Sie gängige raumzeitliche und statistische Analyse-Workflows mit nur wenigen Codezeilen aus
- Automatische räumliche Indizierung – Führen Sie sofort optimierte räumliche Joins und andere Operationen durch
- Interoperabilität mit gängigen GIS-Datenquellen – Laden und speichern Sie Daten aus Shapefiles, Feature Services und Vektorkacheln
- Cloud-nativ und Spark-nativ – Getestet und bereit zur Installation auf Databricks
- Einfach zu bedienen – Erstellen Sie räumlich aktivierte Big Data-Pipelines mit einer intuitiven Python-API, die PySpark erweitert
SQL-Funktionen und Analysewerkzeuge
Derzeit bietet die GA Engine über 120 SQL-Funktionen und mehr als 15 räumliche Analysewerkzeuge, die erweiterte räumliche und raumzeitliche Analysen unterstützen. Im Wesentlichen erweitern die GA Engine-Funktionen die Spark SQL API, indem sie räumliche Abfragen auf DataFrame-Spalten ermöglichen. Diese Funktionen können mit Python-Funktionen oder in einer PySpark SQL-Abfrageanweisung aufgerufen werden und ermöglichen das Erstellen von Geometrien, das Arbeiten mit Geometrien, die Auswertung räumlicher Beziehungen, die Zusammenfassung von Geometrien und mehr. Im Gegensatz zu SQL-Funktionen, die zeilenweise unter Verwendung einer oder zweier Spalten arbeiten, sind die GA Engine-Werkzeuge sich aller Spalten in einem DataFrame bewusst und verwenden alle Zeilen, um bei Bedarf ein Ergebnis zu berechnen. Diese breite Palette von Analyse-Werkzeugen ermöglicht es Ihnen, ganze Datensätze zu verwalten, anzureichern, zusammenzufassen oder zu analysieren.
|
|
Die GA Engine ist ein leistungsstarkes Analysewerkzeug. Nicht zu übersehen ist jedoch, wie einfach die GA Engine die Arbeit mit gängigen GIS-Formaten macht. Die Dokumentation der GA Engine enthält mehrere Tutorials zum Lesen und Schreiben von und nach Shapefiles und Feature Services. Die Möglichkeit, Geodaten mit GIS-Formaten zu verarbeiten, bietet eine hervorragende Interoperabilität zwischen Databricks und Esri-Produkten.
{kind=link}
GA Engine für verschiedene Anwendungsfälle
Lassen Sie uns einige Anwendungsfälle aus verschiedenen Branchen durchgehen, um zu zeigen, wie die GA Engine von ESRI große Mengen an räumlichen Daten verarbeitet. Die Unterstützung für skalierbare räumliche und raumzeitliche Analysen soll jedem Unternehmen helfen, kritische Entscheidungen zu treffen. In drei verschiedenen Datenanalysebereichen – Mobilität, Kundenumsatz und öffentlicher Dienst – werden wir uns darauf konzentrieren, geografische Erkenntnisse aufzudecken.
Mobilitätsdatenanalyse
Mobilitätsdaten wachsen ständig und lassen sich in zwei Kategorien einteilen: menschliche Bewegung und Fahrzeugbewegung. Menschliche Mobilitätsdaten, die von Smartphone-Nutzern in Mobilfunkdienstbereichen gesammelt werden, bieten einen tieferen Einblick in menschliche Aktivitätsmuster. Bewegungsdaten von Millionen vernetzter Fahrzeuge liefern reichhaltige Echtzeitinformationen über gerichtete Verkehrsaufkommen, Verkehrsflüsse, Durchschnittsgeschwindigkeiten, Staus und mehr. Diese Datensätze sind typischerweise groß (Milliarden von Datensätzen) und komplex (Hunderte von Attributen). Diese Daten erfordern räumliche und raumzeitliche Analysen, die über grundlegende räumliche Analysen hinausgehen und sofortigen Zugriff auf fortschrittliche statistische Werkzeuge und spezialisierte Geoanalysefunktionen bieten.
Beginnen wir mit einem Beispiel für die Analyse menschlicher Bewegungen basierend auf Cell Analytics™-Daten des Esri-Partners Ookla®. Ookla® sammelt Big Data über die globale Leistung von Mobilfunkdiensten, die Abdeckung und Signalmessungen basierend auf der Speedtest®-Anwendung. Die Daten enthalten Informationen über das Quellgerät, die mobile Netzwerkverbindung, den Standort und den Zeitstempel. In diesem Fall haben wir mit einem Teildatensatz gearbeitet, der ungefähr 16 Milliarden Datensätze enthielt. Mit Werkzeugen, die nicht für parallele Operationen in Apache Spark™ optimiert sind, könnte das Lesen dieser hochvolumigen Daten und die Aktivierung für raumzeitliche Operationen Stunden an Verarbeitungszeit in Anspruch nehmen. Mit einer einzigen Codezeile mit der GeoAnalytics Engine können diese Daten in wenigen Sekunden aus Parquet-Dateien eingelesen werden.
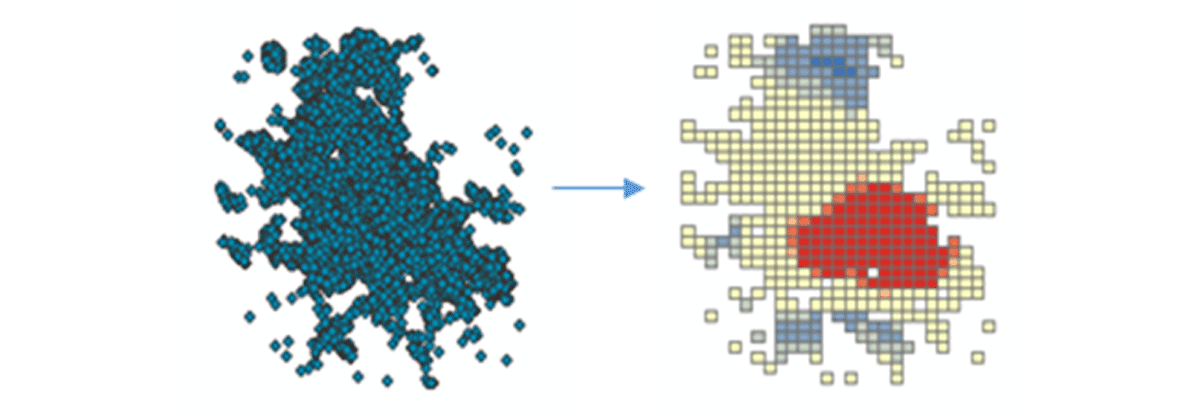
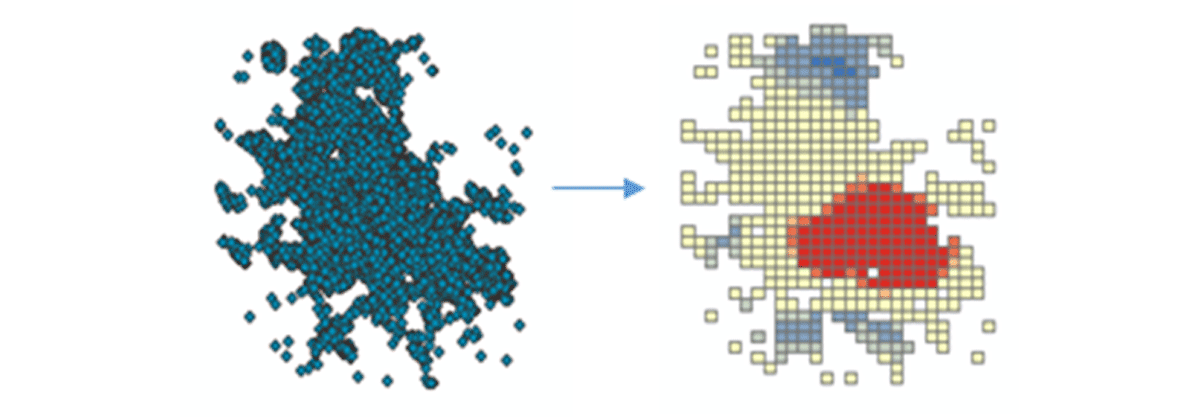
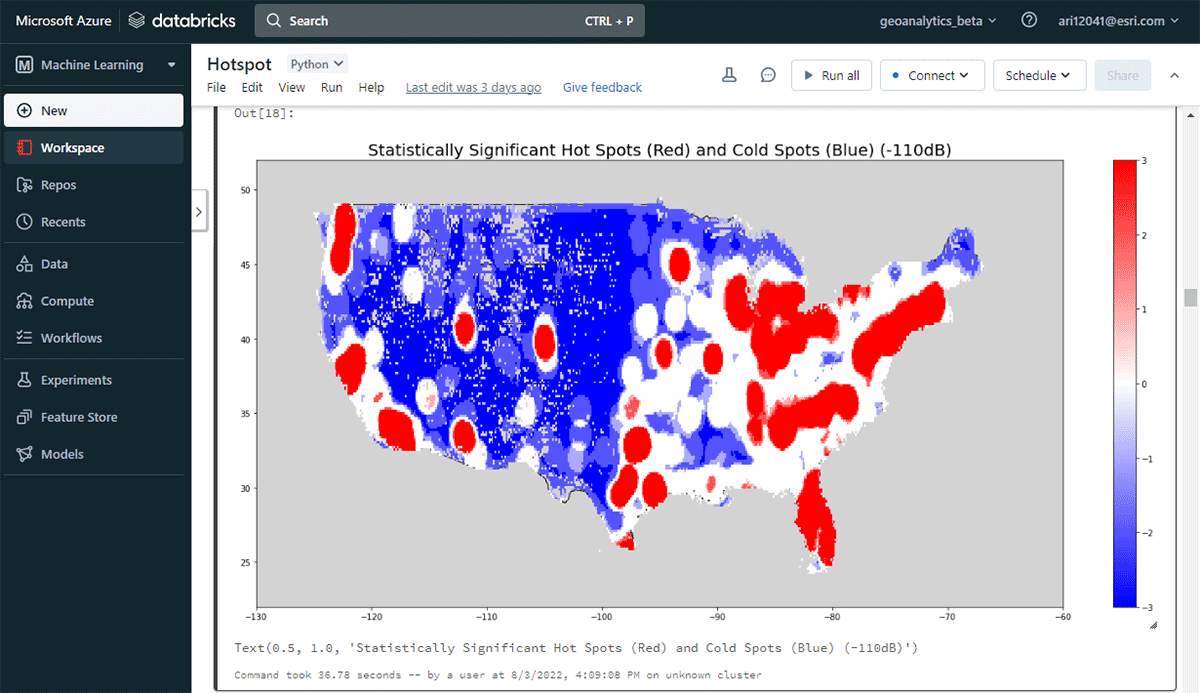
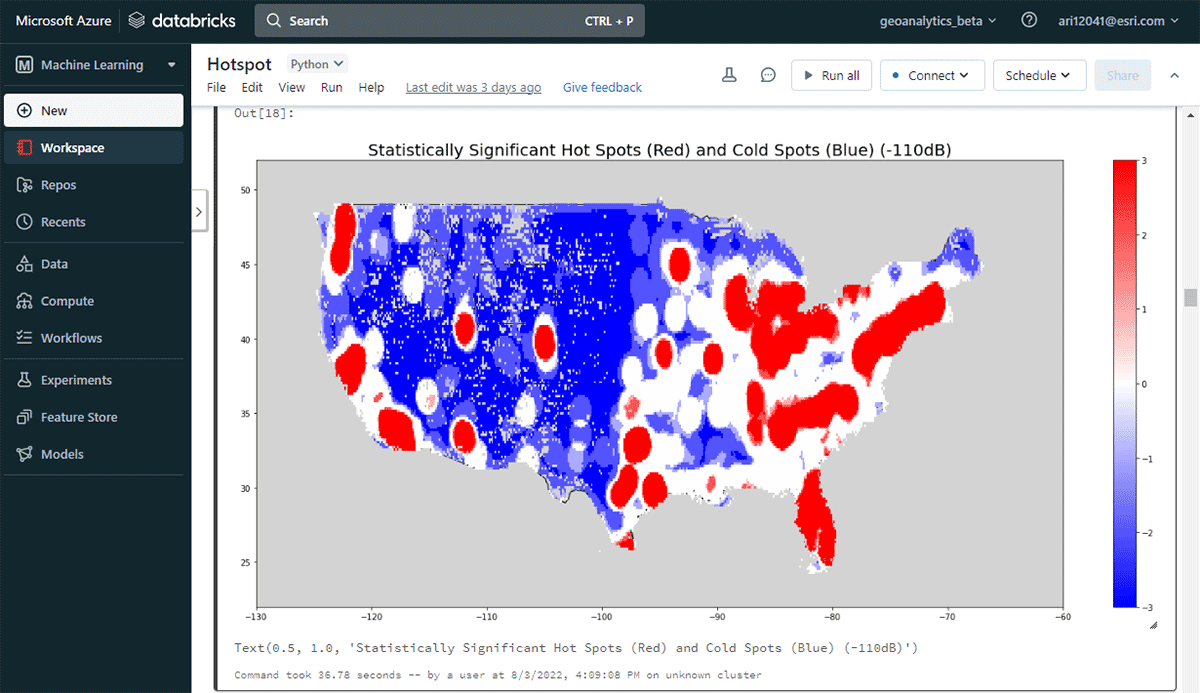
Um umsetzbare Erkenntnisse zu gewinnen, tauchen wir mit einer einfachen Frage in die Daten ein: Wie ist das räumliche Muster von Mobilgeräten über die kontinentalen Vereinigten Staaten? Dies wird uns ermöglichen, die menschliche Präsenz und Aktivität zu charakterisieren. Das FindHotSpots-Werkzeug kann verwendet werden, um statistisch signifikante räumliche Cluster von hohen Werten (Hotspots) und niedrigen Werten (Coldspots) zu identifizieren.
{kind=link}
Der resultierende DataFrame mit Hotspots wurde mit Matplotlib visualisiert und gestylt (Abbildung 2). Er zeigte viele Aufzeichnungen von Geräteeinstellungen (rot) im Vergleich zu Orten mit geringer Dichte verbundener Geräte (blau) in den zusammenhängenden Vereinigten Staaten. Wenig überraschend zeigten große städtische Gebiete eine höhere Dichte verbundener Geräte.
{kind=link}
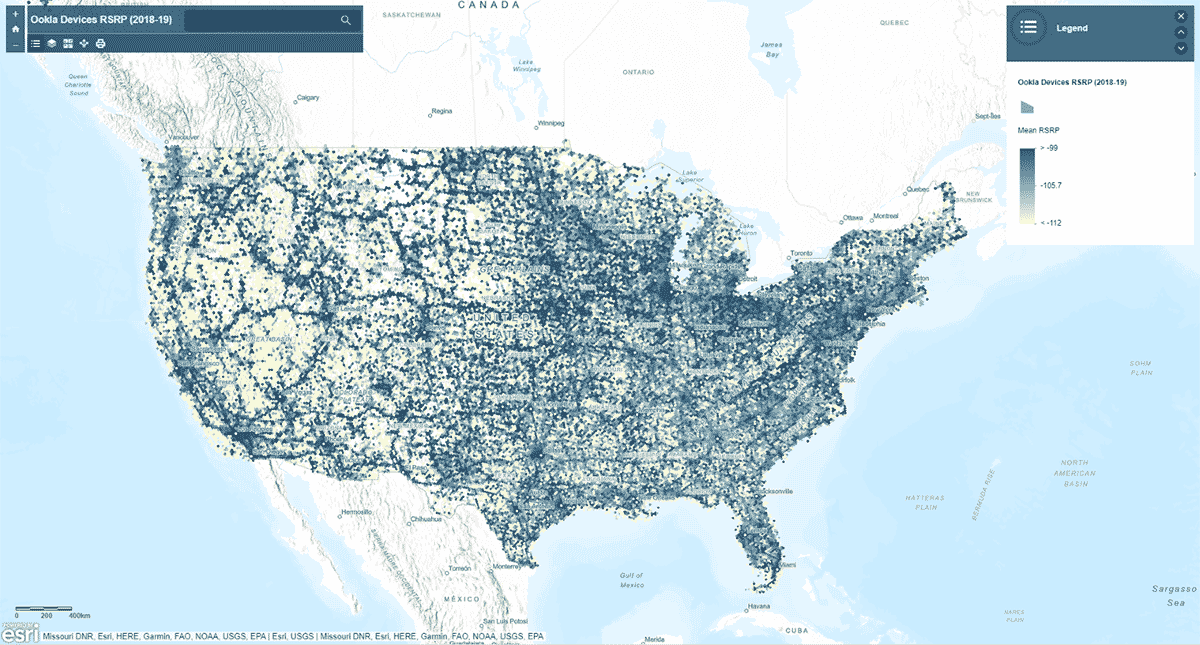
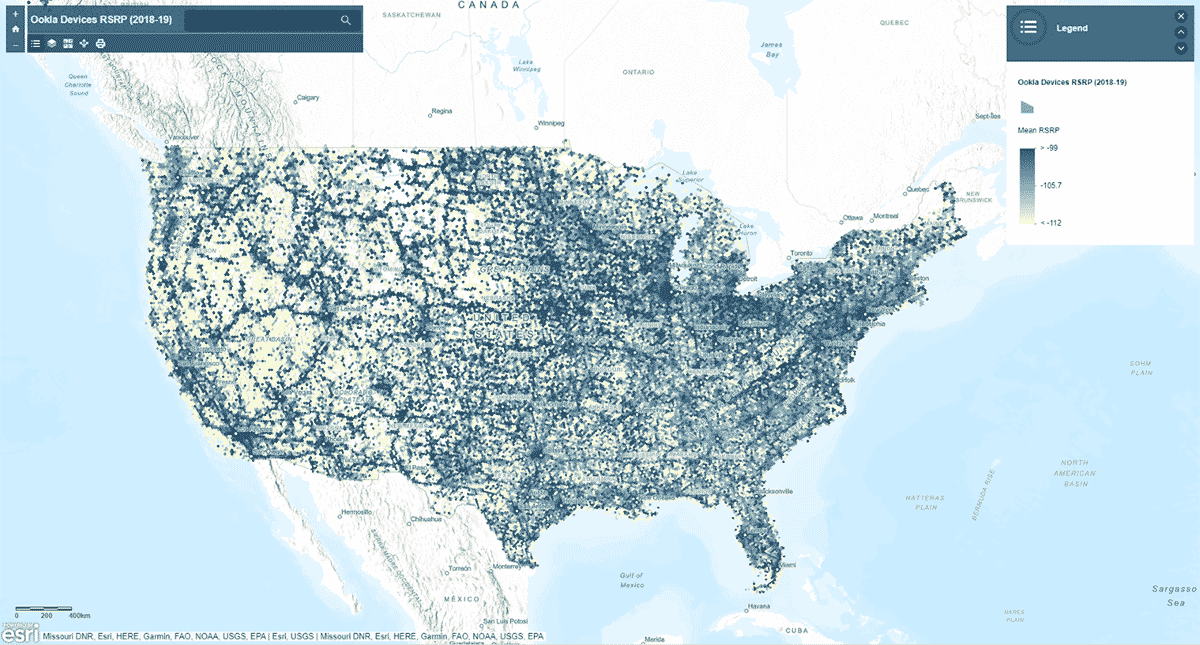
Als Nächstes fragten wir: Folgt die Signalstärke des Mobilfunknetzes einem homogenen Muster in den Vereinigten Staaten? Um das zu beantworten, wurde das Tool AggregatePoints verwendet, um Geräteeinstellungen in hexagonale Bins zusammenzufassen und Bereiche mit besonders starkem und besonders schwachem Mobilfunkdienst zu identifizieren (Abbildung 3). Wir verwendeten rsrp (reference signal received power) – ein Wert zur Messung der Mobilfunknetzsignalstärke –, um die mittlere Statistik über 15 km Bins zu berechnen. Diese Analyse beleuchtete, dass die Signalstärke des Mobilfunknetzes nicht konsistent ist – stattdessen ist sie tendenziell entlang der großen Straßennetze und städtischen Gebiete stärker.
Zusätzlich zur Darstellung des Ergebnisses mit st_plotting verwendeten wir das arcgis-Modul, veröffentlichten den resultierenden DataFrame als Feature-Layer in ArcGIS Online und erstellten eine kartenbasierte, interaktive Visualisierung.
{kind=link}
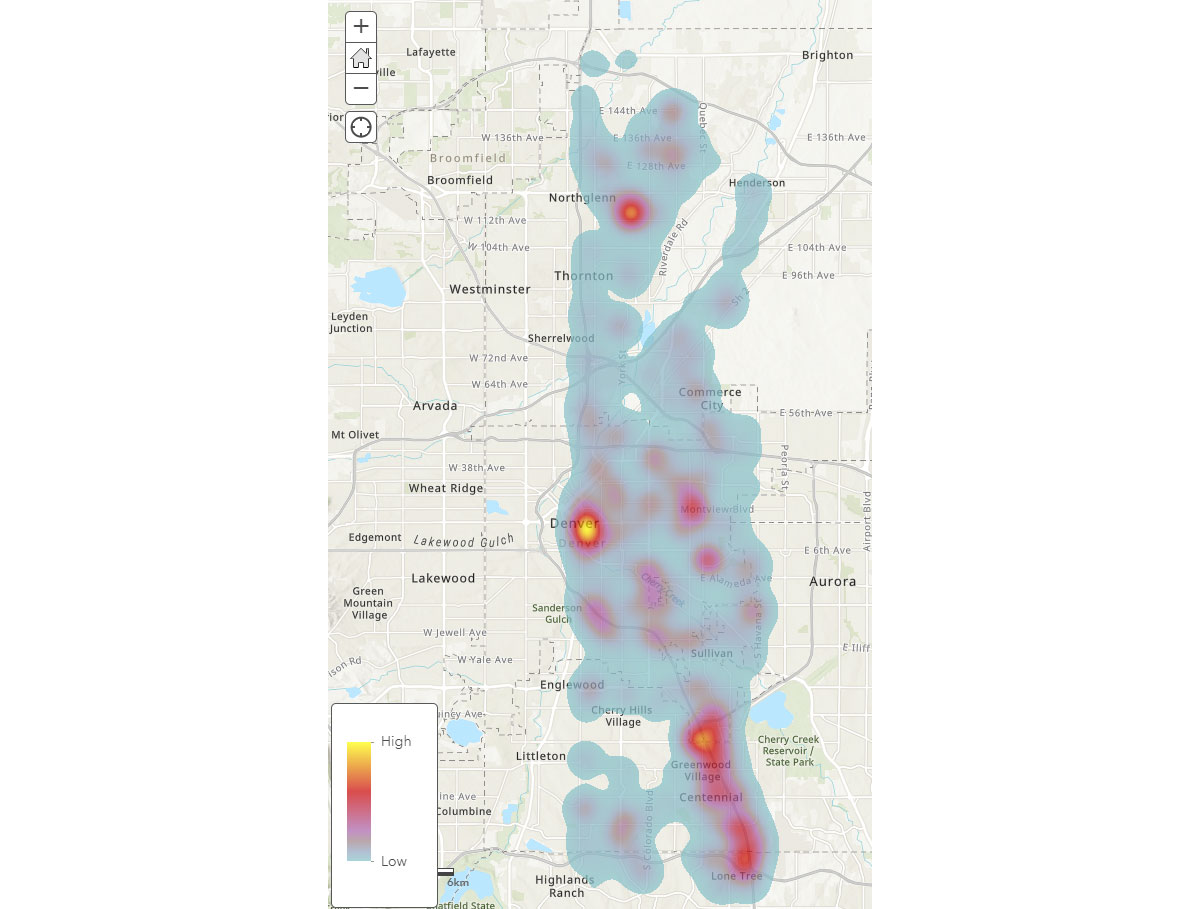
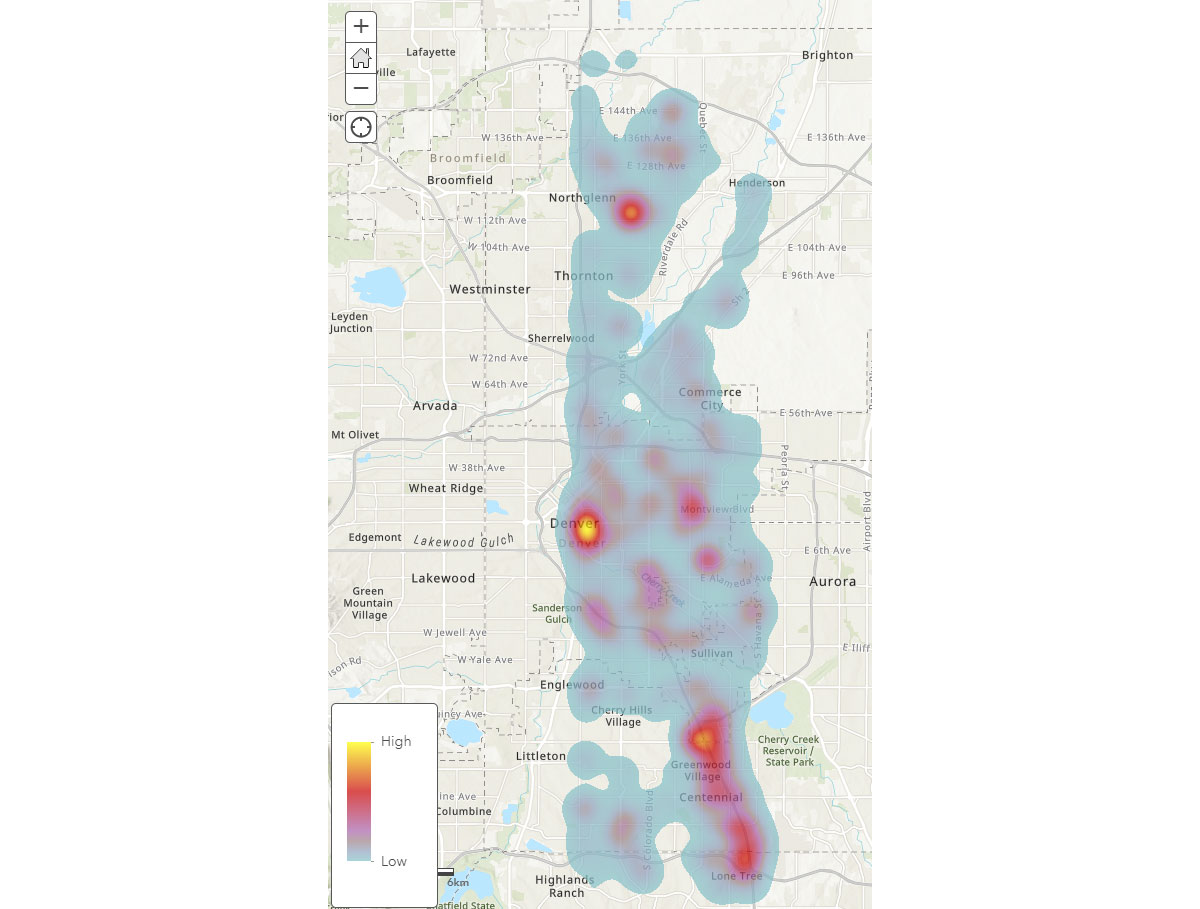
Nachdem wir nun die breiten räumlichen Muster von Mobilgeräten verstehen, wie können wir tiefere Einblicke in menschliche Aktivitätsmuster gewinnen? Wo verbringen die Menschen ihre Zeit? Um das zu beantworten, verwendeten wir FindDwellLocations, um nach Geräten in Denver, CO, zu suchen, die sich am 31. Mai 2019 (Freitag) mindestens 5 Minuten am selben allgemeinen Ort aufhielten. Diese Analyse kann uns helfen, Orte mit länger andauernder Aktivität, d. h. Verbraucherziele, zu verstehen und diese von allgemeinen Reiseaktivitäten zu trennen.
Der DataFrame result_dwell liefert uns Geräte oder Personen, die sich an verschiedenen Orten aufgehalten haben. Die Heatmap der Aufenthaltsdauer in Abbildung 4 gibt einen Überblick darüber, wo die Menschen in Denver ihre Zeit verbringen.
{kind=link}
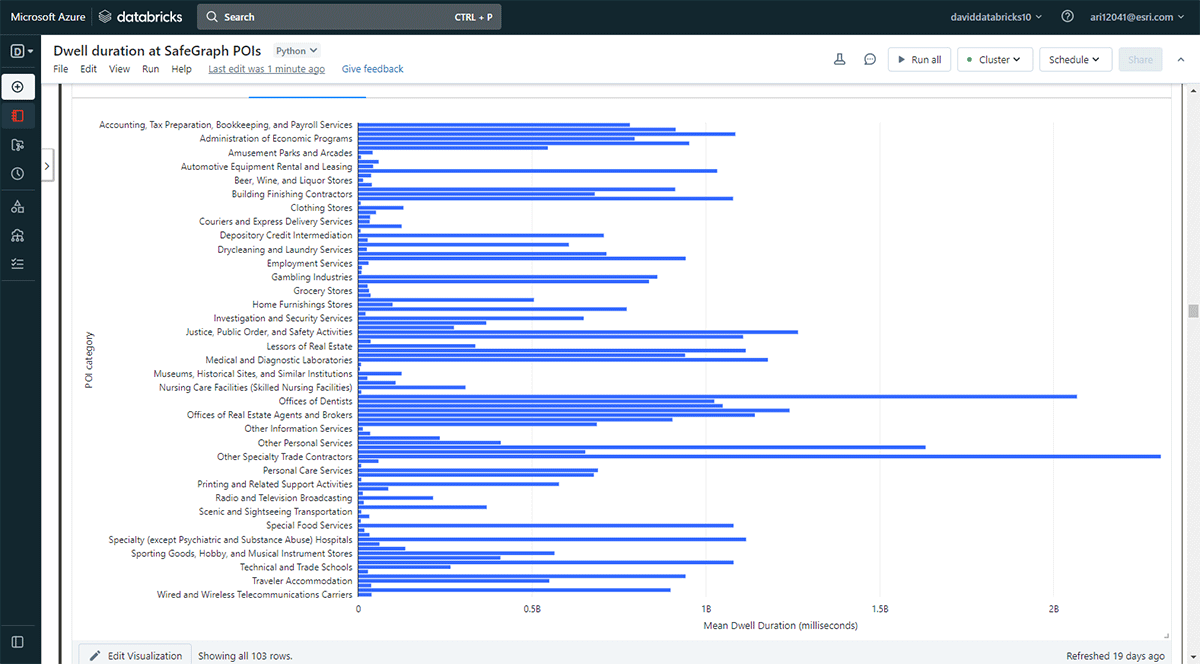
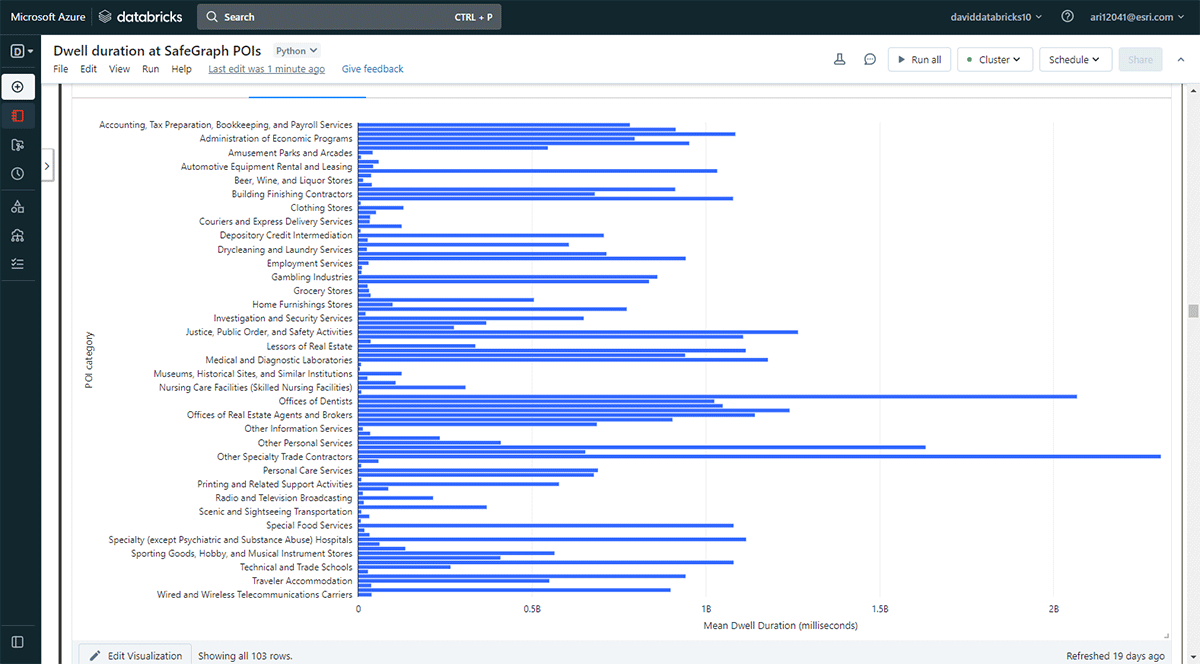
Wir wollten auch die Orte untersuchen, die Menschen länger besuchen. Um dies zu erreichen, haben wir Overlay verwendet, um zu identifizieren, welche Point-of-Interest (POI) Footprints von SafeGraph Geometry Daten mit Aufenthaltsorten (aus dem DataFrame result_dwell) am 31. Mai 2019 geschnitten haben. Mithilfe der groupBy-Funktion zählten wir die Aufenthaltsdauer verbundener Geräte für jede der Top-POI-Kategorien. Abbildung 5 hebt hervor, dass einige städtische POIs in Denver mit längeren Aufenthaltsdauern übereinstimmten, darunter Geschäfte für Bürobedarf, Schreibwaren und Geschenkartikel sowie Büros von Bauunternehmern.
{kind=link}
Dieser Beispiel-Analyseworkflow mit Cell AnalyticsTM-Daten könnte angewendet oder umfunktioniert werden, um die Aktivitäten von Menschen spezifischer zu charakterisieren. Zum Beispiel könnten wir die Daten nutzen, um Einblicke in das Konsumverhalten in der Nähe von Einzelhandelsstandorten zu gewinnen. Welche Restaurants oder Cafés besuchten diese Geräte oder Personen nach dem Einkaufen bei Walmart oder Costco? Darüber hinaus können diese Datensätze für die Bewältigung von Pandemien und Naturkatastrophen nützlich sein. Folgen die Menschen beispielsweise während einer Pandemie den Richtlinien zur öffentlichen Gesundheit? Welche städtischen Gebiete könnten die nächsten Hotspots für COVID-19 oder durch Waldbrände verursachte schlechte Luftqualität sein? Sehen wir auf einer breiteren geografischen Skala Unterschiede in der menschlichen Mobilität und Aktivität aufgrund von Einkommensungleichheit?
Transaktionsdatenanalyse
Aggregierte Transaktionsdaten über Points of Interest enthalten reichhaltige Informationen darüber, wie und wann Menschen ihr Geld an bestimmten Orten ausgeben. Das schiere Volumen und die Geschwindigkeit dieser Daten erfordern fortschrittliche räumliche Analysetools, um das Konsumverhalten klar zu verstehen: Wie unterscheidet sich das Konsumverhalten je nach Geografie? Welche Unternehmen neigen dazu, sich zu ko-lokalisieren, um profitabel zu sein? Welche Waren kaufen Verbraucher in einem physischen Geschäft (z. B. Walmart) im Vergleich zu den Produkten, die sie online kaufen? Ändert sich das Konsumverhalten während extremer Ereignisse wie COVID-19?
Diese Fragen können mit SafeGraph Spend-Daten und der GeoAnalytics Engine beantwortet werden. Zum Beispiel wollten wir identifizieren, wie die Reisemuster der Menschen während COVID-19 in den Vereinigten Staaten beeinflusst wurden. Um dies zu erreichen, analysierten wir landesweite SafeGraph Spend-Daten aus den Jahren 2020 und 2021. Im Folgenden zeigen wir die jährlichen Ausgaben (USD) von Verbrauchern für Mietwagen von Unternehmen, aggregiert auf US-Counties. Nachdem wir den DataFrame in ArcGIS Online veröffentlicht hatten, erstellten wir mit dem Swipe-Widget aus ArcGIS Web AppBuilder eine interaktive Karte, um schnell zu untersuchen, welche Counties sich im Laufe der Zeit verändert haben (Abbildung 6).
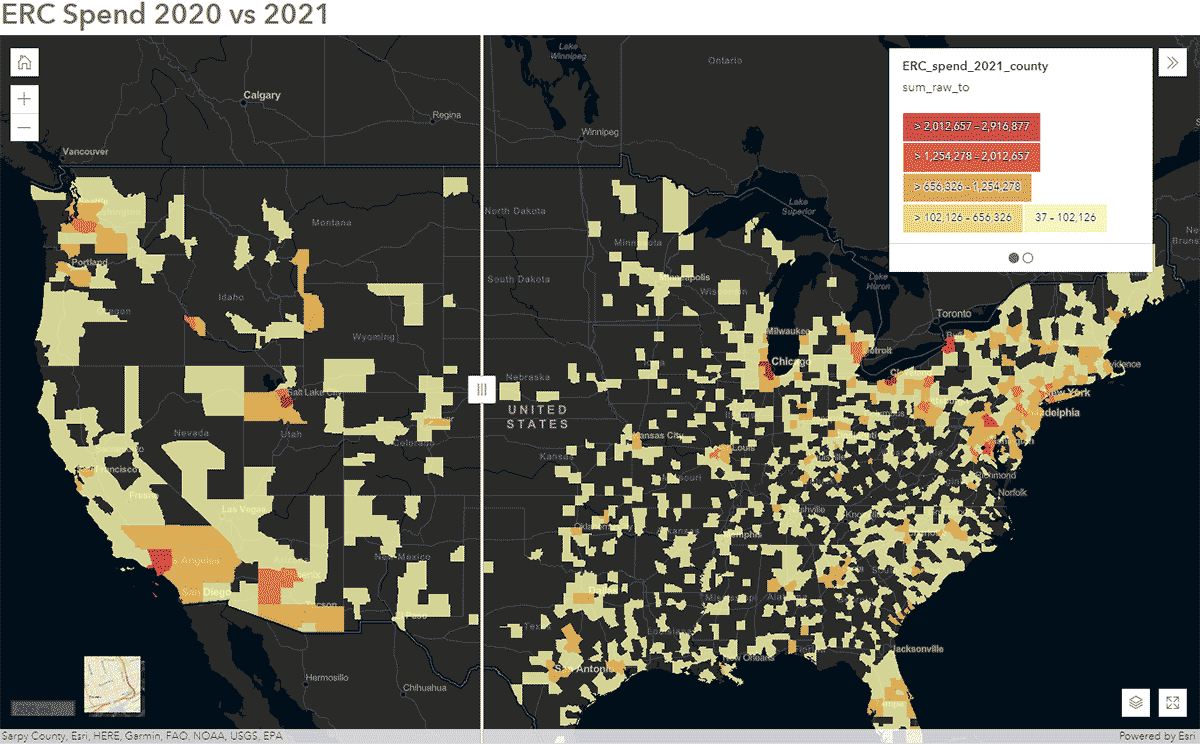
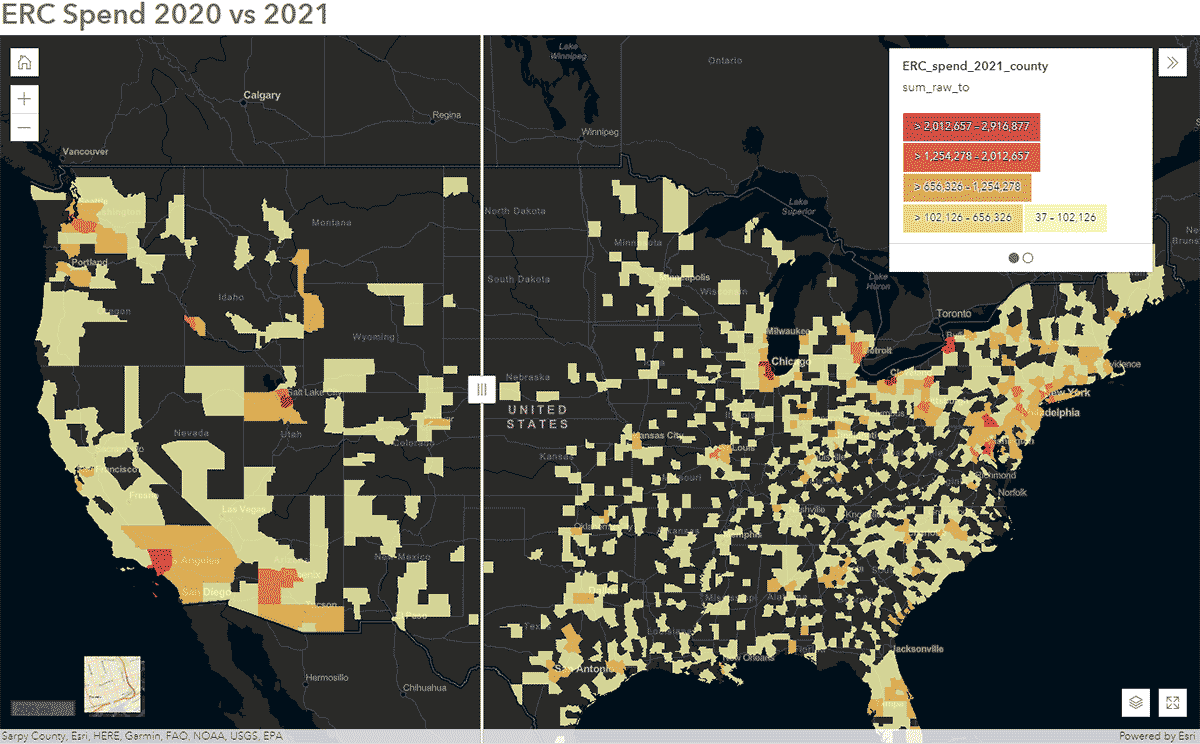{kind=link}
Als Nächstes untersuchten wir, welcher US-County im Laufe eines Jahres die höchsten Online-Ausgaben hatte und welche anderen Counties ähnliche Online-Shopping-Ausgabenmuster aufwiesen, unter Berücksichtigung von Ähnlichkeiten in Bevölkerungs- und Agrarproduktverkäufen. Basierend auf der Attributfilterung des Ausgaben-DataFrames identifizierten wir, dass Sacramento 2020 die Liste der Online-Shopping-Ausgaben anführte. Um ähnliche Gebiete zu finden, nutzten wir das Tool FindSimilarLocations, um Counties zu identifizieren, die Sacramento in Bezug auf Online-Shopping und Ausgaben am ähnlichsten oder am unähnlichsten sind, aber im Verhältnis zu Ähnlichkeiten in Bevölkerung und Landwirtschaft (Gesamtfläche der Ackerflächen und durchschnittliche Verkäufe von Agrarprodukten) (Abbildung 7).
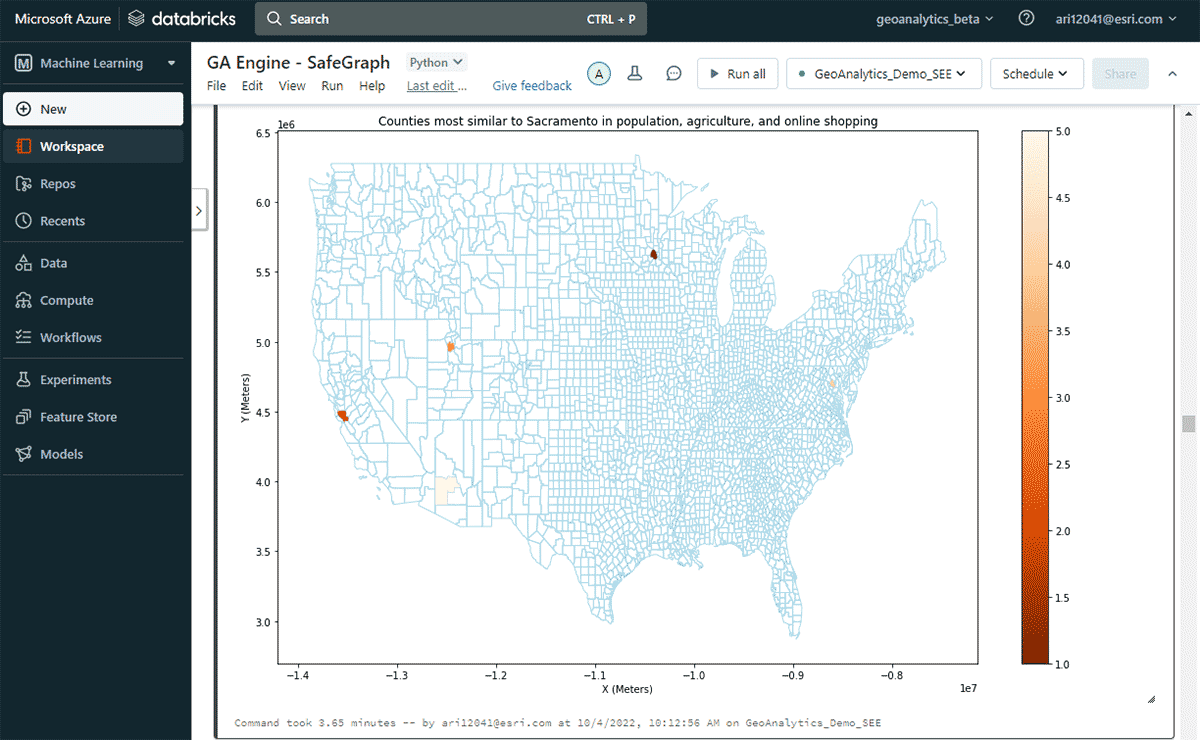
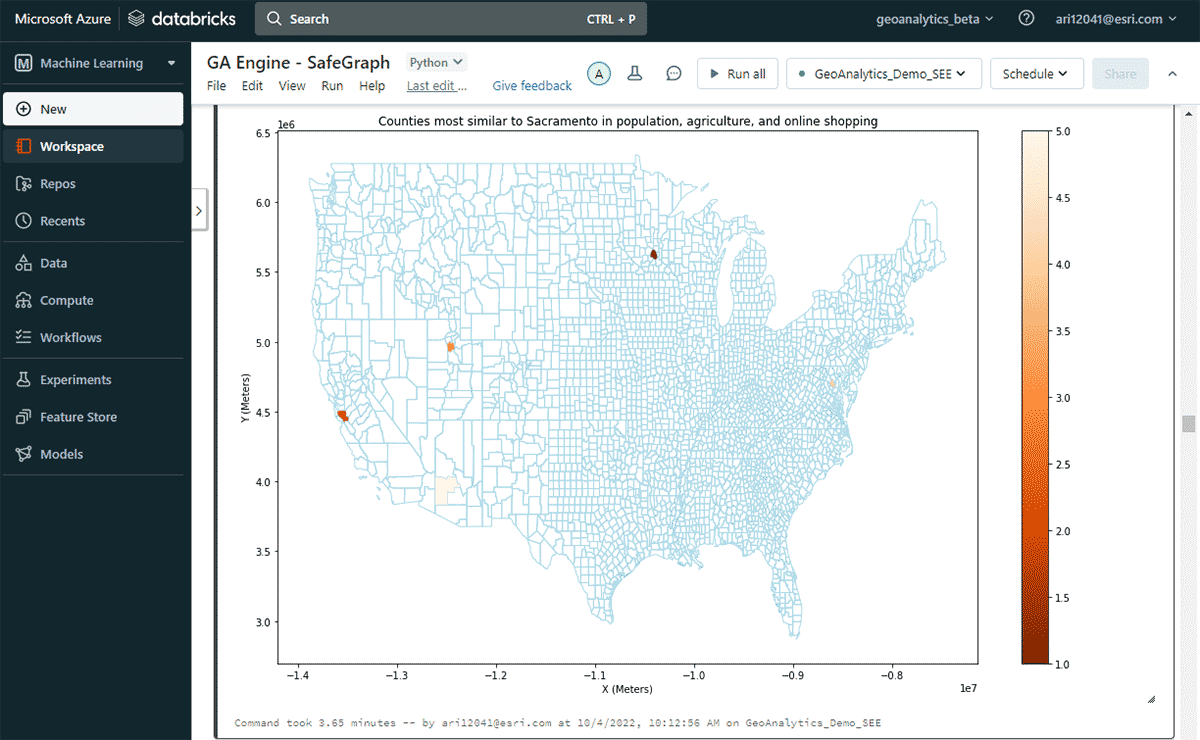{kind=link}
Analysen von öffentlichen Dienstleistungsdaten
Öffentliche Datensätze, wie z. B. 311-Anrufprotokolle, enthalten wertvolle Informationen über Nicht-Notfalldienste, die den Einwohnern zur Verfügung gestellt werden. Die zeitnahe Überwachung und Identifizierung von räumlich-zeitlichen Mustern in diesen Daten kann lokalen Regierungen helfen, Ressourcen für eine effiziente Bearbeitung von 311-Anrufen zu planen und zuzuweisen.
In diesem Beispiel war es unser Ziel, ~27 Millionen Datensätze von New Yorker 311-Serviceanfragen von 2010 bis Februar 2022 schnell zu lesen, zu verarbeiten/bereinigen und zu filtern, um dann die folgenden Fragen für die Region New York City zu beantworten:
- Welche Gebiete haben die längsten durchschnittlichen 311-Reaktionszeiten?
- Gibt es Muster bei Beschwerdetypen mit langen durchschnittlichen Reaktionszeiten?
Um die erste Frage zu beantworten, wurden die Anrufe mit den längsten Reaktionszeiten identifiziert. Anschließend wurden die Daten gefiltert, um Datensätze einzuschließen, die länger als der Mittelwert plus drei Standardabweichungen waren.
Um die zweite Frage nach signifikanten Gruppen von Beschwerden zu beantworten, nutzten wir das Tool GroupByProximity, um nach Beschwerden desselben Typs zu suchen, die sich innerhalb von 500 Fuß und 5 Tagen voneinander befanden. Anschließend filterten wir nach Gruppen mit mehr als 10 Einträgen und erstellten für jede Beschwerdegruppe eine konvexe Hülle, die zur Visualisierung ihrer räumlichen Muster nützlich sein wird (Abbildung 8). Mit st.plot() – eine leichtgewichtige Plotting-Methode, die mit der ArcGIS GeoAnalytics Engine geliefert wird – können Geometrien, die in einem DataFrame gespeichert sind, sofort angezeigt werden.
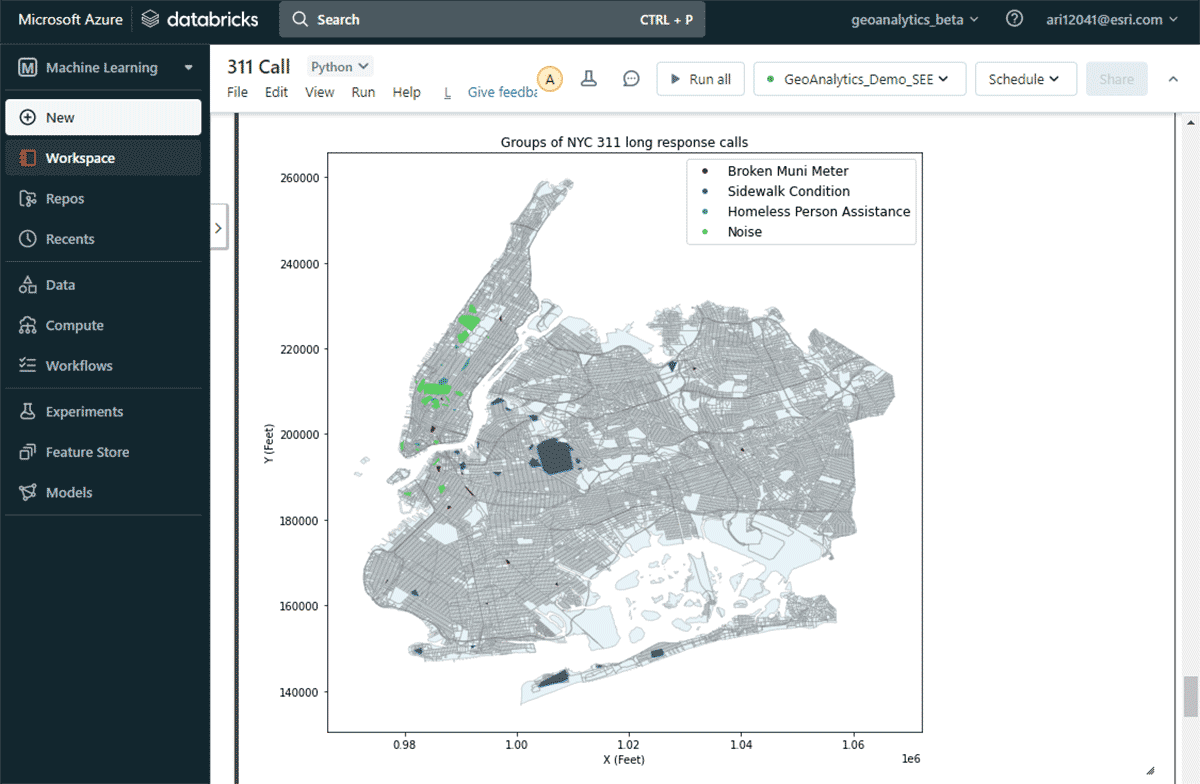
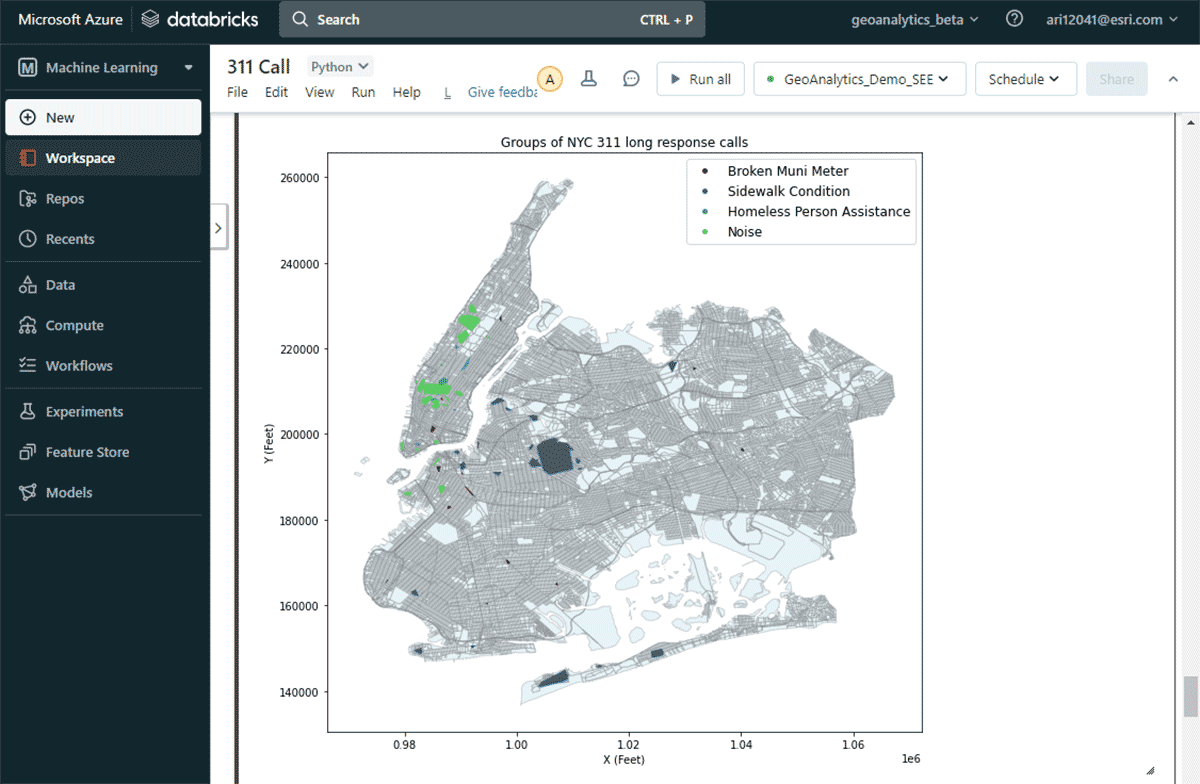{kind=link}
Mit dieser Karte war es einfach, die räumlichen Verteilungen verschiedener Beschwerdetypen in New York City zu identifizieren. Beispielsweise gab es eine beträchtliche Anzahl von Lärmbeschwerden in den Gebieten von Mid- und Lower Manhattan, während die Bedingungen der Bürgersteige in Brooklyn und Queens von größter Bedeutung sind. Diese schnellen datengesteuerten Erkenntnisse können Entscheidungsträgern helfen, umsetzbare Maßnahmen einzuleiten.
Benchmarks
Die Leistung ist ein entscheidender Faktor für viele Kunden bei der Auswahl einer Analyse-Lösung. Die Benchmark-Tests von Esri haben gezeigt, dass die GA Engine bei der Ausführung von Big-Data-Raumanalysen eine deutlich bessere Leistung erzielt als Open-Source-Pakete. Die Leistungssteigerungen nehmen mit zunehmender Datengröße zu, sodass Benutzer bei größeren Datensätzen eine noch bessere Leistung erzielen. Die folgende Tabelle zeigt beispielsweise die Rechenzeiten für eine räumliche Schnittaufgabe, die zwei Eingabedatensätze (Punkte und Polygone) mit unterschiedlichen Größen von bis zu Millionen von Datensätzen zusammenführt. Jedes Join-Szenario wurde auf einem einzelnen und einem Multi-Machine Databricks Cluster getestet.
| Eingaben für räumliche Schnitte | Rechenzeit (Sekunden) | ||
|---|---|---|---|
| Linker Datensatz | Rechter Datensatz | Einzelne Maschine | Multi-Machine |
| 50 Polygone | 6K Punkte | 6 | 5 |
| 3K Polygone | 6K Punkte | 10 | 5 |
| 3K Polygone | 2M Punkte | 19 | 9 |
| 3K Polygone | 17M Punkte | 46 | 16 |
| 220K Polygone | 17M Punkte | 80 | 29 |
| 11M Polygone | 17M Punkte | 515 (8,6 Min.) | 129 (2,1 Min.) |
| 11M Polygone | 19M Punkte | 1.373 (22 Min.) | 310 (5 Min.) |
Architektur und Installation
Bevor wir zum Ende kommen, werfen wir einen Blick unter die Haube der GeoAnalytics Engine-Architektur und untersuchen, wie sie funktioniert. Da sie Cloud-nativ und Spark-nativ ist, können wir die GeoAnalytics-Bibliothek problemlos in einer Cloud-basierten Spark-Umgebung verwenden. Die Installation der GeoAnalytics Engine-Bereitstellung in der Databricks-Umgebung erfordert minimale Konfiguration. Sie laden das Modul über eine JAR-Datei, und es läuft dann mit den vom Cluster bereitgestellten Ressourcen.
Die Installation umfasst 2 grundlegende Schritte, die für AWS, Azure und GCP gelten:
- Vorbereiten des Arbeitsbereichs
- Erstellen oder Starten eines Databricks-Arbeitsbereichs
- Hochladen der GeoAnalytics JAR-Datei in das DBFS
- Hinzufügen und Aktivieren eines Init-Skripts
- Erstellen eines Clusters
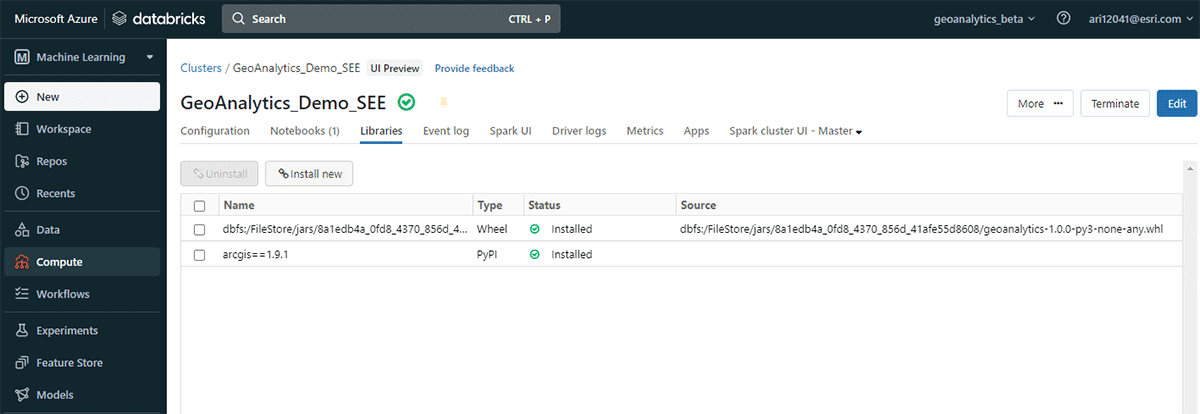
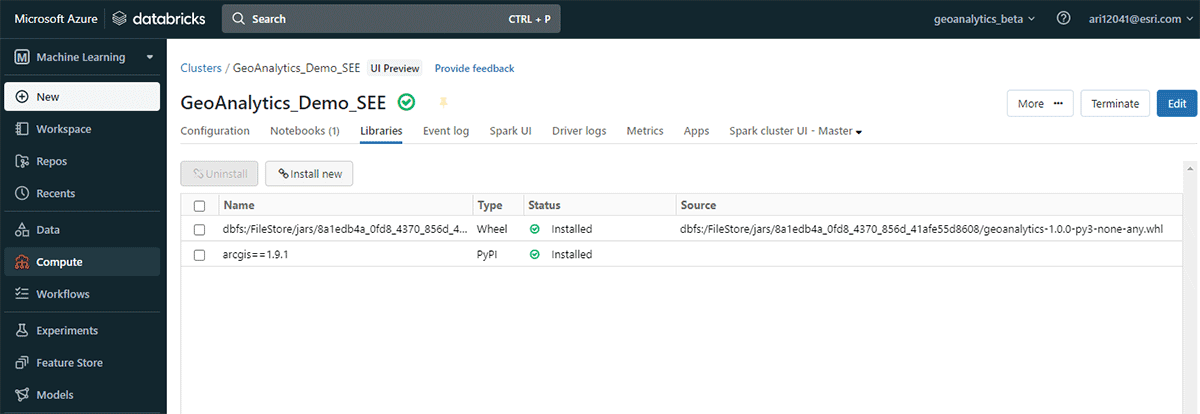{kind=link}
Nach der Installation analysieren Benutzer mit einem Python-Notebook, das an die Spark-Umgebung angehängt ist. Sie können sofort auf Databricks Lakehouse Platform-Daten zugreifen und Analysen durchführen. Nach der Analyse können Sie die Ergebnisse speichern, indem Sie sie in Ihren Data Lake, SQL Warehouse, BI (Business Intelligence)-Dienste oder ArcGIS zurückschreiben.
{kind=link}
Ausblick
In diesem Blog haben wir die Leistungsfähigkeit der ArcGIS GeoAnalytics Engine auf Databricks vorgestellt und gezeigt, wie wir die anspruchsvollsten Geodaten-Anwendungsfälle gemeinsam bewältigen können. Beziehen Sie sich auf dieses Databricks Notebook für detaillierte Referenzen der oben gezeigten Beispiele. Zukünftig wird die GeoAnalytics Engine mit zusätzlichen Funktionen erweitert, darunter GeoJSON-Export, H3-Binning-Unterstützung und Clustering-Algorithmen wie K-Nearest Neighbor.
GeoAnalytics Engine funktioniert mit Databricks auf Azure, AWS und GCP. Bitte wenden Sie sich an Ihre Databricks- und Esri-Account-Teams, um Details zur Bereitstellung der GeoAnalytics-Bibliothek in Ihrer bevorzugten Databricks-Umgebung zu erhalten. Um mehr über GeoAnalytics Engine zu erfahren und zu erkunden, wie Sie Zugang zu diesem leistungsstarken Produkt erhalten, besuchen Sie bitte die Website von Esri.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.