Jahresrückblick 2025: Databricks SQL, schneller für jede Workload
Schnellere Analytics- und KI-Workloads, auch bei der Skalierung von Daten, Data Governance und Nutzung
von Tad Rosenberg, Jeremy Lewallen, Mostafa Mokhtar, Chris Stevens und Ina Felsheim
- Im Jahr 2025 hat Databricks SQL eine um bis zu 40 % höhere Performance für Produktions-Workloads erbracht, mit automatisch angewendeten Verbesserungen.
- Verbesserte Abfragen in den Bereichen BI, ETL, Spatial Analytics und KI, selbst bei verwalteten und freigegebenen Daten und bei höherer Parallelität.
- Alle Vorteile sind ab sofort in Databricks SQL Serverless verfügbar und verbessern so die Performance und Kosteneffizienz für bestehende Workloads ohne Tuning oder Neuschreiben.
Für die meisten Datenteams geht es bei der Performance nicht mehr um eine einmalige Optimierung. Es geht darum, dass Analysen mit der Skalierung von Daten, Benutzern und Governance schneller werden, ohne die Kosten in die Höhe zu treiben.
Mit Databricks SQL (DBSQL) ist diese Erwartung in die Plattform integriert. Im Jahr 2025 verbesserte sich die durchschnittliche Leistung bei Produktions-Workloads um bis zu 40 %, ohne Tuning, ohne Neuschreiben von Abfragen und ohne manuelle Eingriffe.
Das Gesamtbild geht über einen einzelnen Benchmark hinaus. Die Performance wurde auf der gesamten Plattform verbessert: von schnelleren Dashboard-Ladezeiten und effizienteren Pipelines bis hin zu Queries, die selbst bei vorhandener Governance und gemeinsam genutzten Daten reaktionsschnell bleiben, während Geodatenanalysen und KI-Funktionen ohne zusätzliche Komplexität weiter skalieren.
Das Ziel bleibt einfach: Workloads beschleunigen und die Gesamtkosten per Default senken. Mit DBSQL Serverless, Unity Catalog Managed Tables und Predictive Optimization werden Verbesserungen automatisch in Ihrer gesamten Umgebung angewendet, sodass bestehende Workloads von der Weiterentwicklung der Engine profitieren.
Dieser Beitrag schlüsselt die Leistungssteigerungen auf, die 2025 für die Query-Engine, Unity Catalog, Delta Sharing, Storage, Spatial SQL und KI-Funktionen erzielt wurden.
Schnelle Abfrage-Performance bei jedem Workload
Databricks SQL misst die Leistung anhand von Millionen echter Kundenabfragen, die wiederholt in der Produktion ausgeführt werden. Indem wir verfolgen, wie sich diese Workloads im Laufe der Zeit verändern, messen wir die tatsächlichen Auswirkungen der Plattformverbesserungen und -optimierungen anstelle von isolierten Benchmarks.
Im Jahr 2025 erzielte Databricks SQL konsistente Performance-Steigerungen bei allen wichtigen Workload-Typen. Diese Verbesserungen werden standardmäßig durch Optimierungen auf Engine-Ebene wie Predictive Query Execution und Photon Vectorized Shuffle angewendet, ohne dass Konfigurationsänderungen erforderlich sind.
- Explorative Workloads verzeichneten die größten Zuwächse, wobei sie im Durchschnitt 40 % schneller liefen und es Analysten und Data Scientists ermöglichten, schneller mit großen Datensätzen zu iterieren.
- Business-Intelligence - Workloads wurden um etwa 20 % verbessert, was zu reaktionsschnelleren Dashboards und einer reibungsloseren interaktiven Analyse bei gleichzeitiger Nutzung führt.
- ETL-Workloads profitierten ebenfalls, da sie etwa 10 % schneller liefen und die Pipeline-Laufzeiten ohne Nachbearbeitung verkürzten.
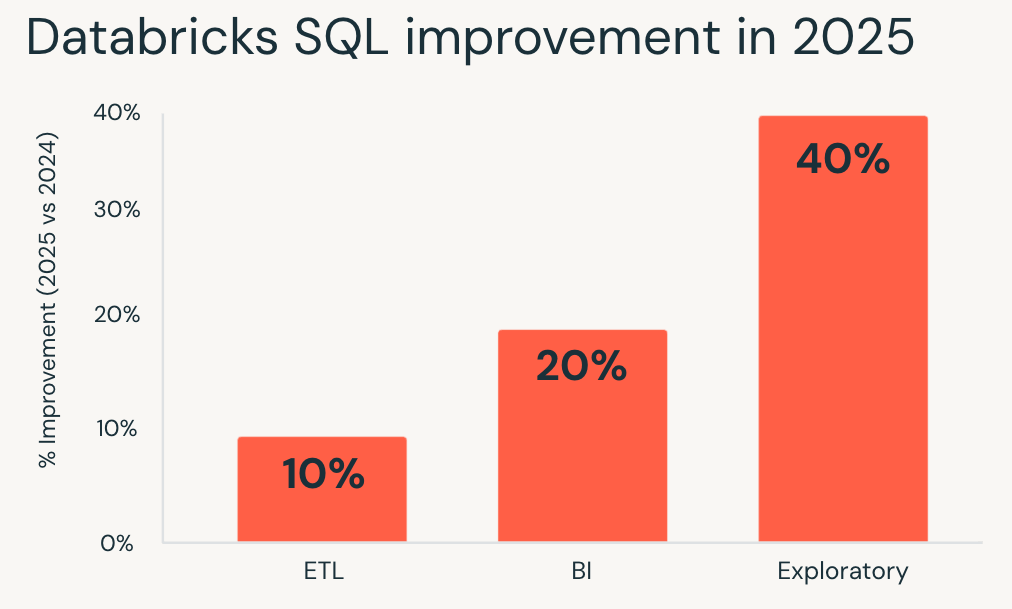
Wenn Sie Databricks SQL zuletzt vor einem Jahr evaluiert haben, laufen Ihre bestehenden Workloads heute bereits schneller.
Analytics, die auch bei der Skalierung der Governance mit Unity Catalog schnell bleiben
Mit dem Wachstum von Datenbeständen wird die Governance oft zu einer versteckten Latenzquelle. Berechtigungsprüfungen, Metadatenzugriff und Lineage-Abfragen können Abfragen verlangsamen, insbesondere in interaktiven Umgebungen mit hoher Parallelität.
2025 hat Unity Catalog diesen Aufwand erheblich reduziert. Die End-to-End-Kataloglatenz wurde um das bis zu 10-fache verbessert, was auf Optimierungen beim Katalogdienst, dem Netzwerk-Stack, dem Databricks Runtime-Client und abhängigen Diensten zurückzuführen ist.
Das Ergebnis ist dort sichtbar, wo es am wichtigsten ist:
- Dashboards bleiben auch mit granularen Zugriffskontrollen reaktionsschnell.
- Workloads mit hoher Parallelität skalieren ohne Engpässe durch Metadatenzugriff.
- Interaktive Analysen fühlen sich schneller an, wenn Nutzer verwaltete Daten in großem Umfang untersuchen.
Teams müssen sich nicht mehr zwischen starker Governance und Performance entscheiden. Mit Unity Catalog bleiben Analysen schnell, während die Governance auf mehr Daten und Benutzer ausgeweitet wird.
Delta Sharing: Gemeinsam genutzte Daten mit der Leistung nativer Daten
Das Teilen von Daten über Teams oder Organisationen hinweg war traditionell mit Kosten verbunden. Abfragen auf freigegebenen Tabellen liefen oft langsamer, und Optimierungen wurden im Vergleich zu nativen Daten ungleichmäßig angewendet.
Im Jahr 2025 schloss Databricks SQL diese Lücke. Durch Verbesserungen bei der Abfrageausführung und der Statistikweitergabe liefen Abfragen auf Tabellen, die über Delta Sharing geteilt wurden, bis zu 30 % schneller, wodurch die Performance geteilter Daten an die von nativen Tabellen angeglichen wurde.

Diese Änderung ist besonders wichtig in Szenarien, in denen sich externe Daten wie interne Daten verhalten müssen. Daten-Marketplaces, organisationsübergreifende Analysen und partnergestütztes Reporting können nun auf gemeinsam genutzten Datasets ausgeführt werden, ohne dabei an Interaktivität oder Vorhersagbarkeit einzubüßen.
Mit Delta Sharing können Teams kontrollierte Daten umfassend teilen und dabei die Performance Expectations für moderne Analysen beibehalten.
Niedrigere Speicherkosten, integrierte automatische Optimierungen
Mit wachsendem Datenvolumen wird die Speichereffizienz zu einem größeren Teil der Gesamtkosten. Komprimierung spielt eine entscheidende Rolle, aber die Auswahl von Formaten und die Verwaltung von Migrationen haben traditionell den Betriebsaufwand erhöht.
Im Jahr 2025 hat Databricks die Zstandard-Komprimierung zum default für alle neuen Unity Catalog Managed Tables gemacht. Zstandard ist ein Open Source-Komprimierungsformat, das im Vergleich zu älteren Formaten bis zu 40 % Speicherkosteneinsparungen bietet, ohne die Query-Performance zu beeinträchtigen.

Diese Vorteile gelten automatisch für neue Tabellen, und bestehende Tabellen können ebenfalls auf Zstandard migriert werden, wobei einfache Migrationstools in Kürze zur Verfügung stehen. Große Faktentabellen, lange aufbewahrte Datasets und schnell wachsende Domänen erzielen sofortige Kostensenkungen, ohne Änderungen an der Art und Weise, wie Queries geschrieben oder ausgeführt werden.
Das Ergebnis sind per default niedrigere Speicherkosten, ohne Performance-Einbußen oder zusätzliche Schritte zur Feinabstimmung.
Geodaten-Analytics ohne spezialisierte Systeme
Geodatenanalysen stellen hohe Anforderungen an die Abfrageausführung. Spatial Joins, Bereichsabfragen und geometrische Berechnungen sind rechenintensiv und erfordern bei Scale oft spezielle Systeme oder eine sorgfältige Abstimmung.
Im Jahr 2025 hat Databricks SQL die Performance für diese Workloads erheblich verbessert. Räumliche SQL-Abfragen liefen bis zu 17-mal schneller, was durch Optimierungen auf Engine-Ebene wie R-Tree-Indizierung, optimierte räumliche Joins in Photon und intelligente Bereichs-Join-Optimierung ermöglicht wurde.
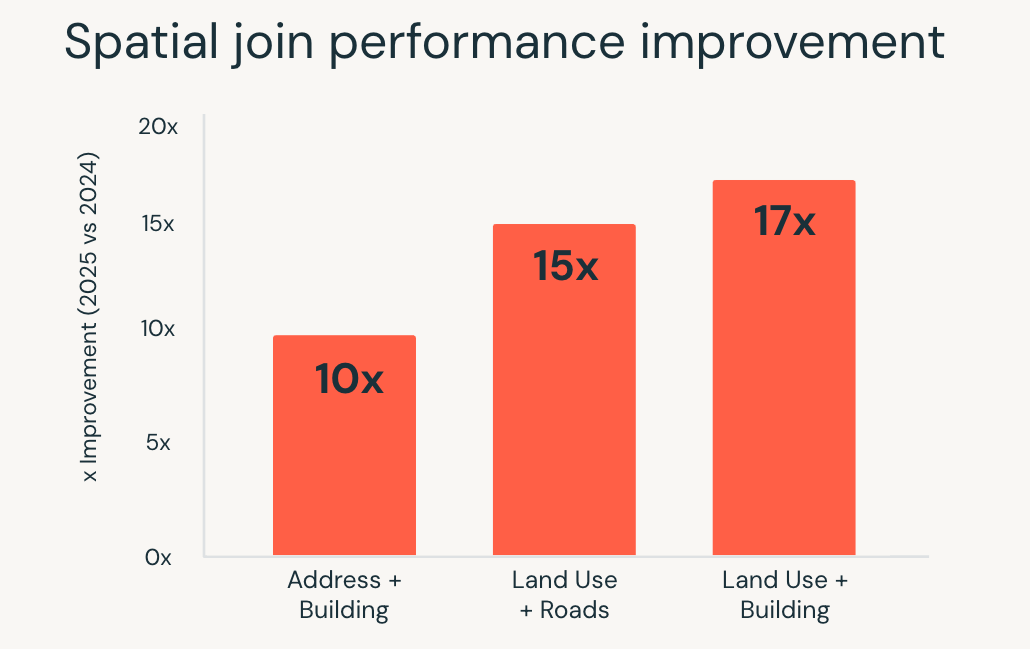
Diese Verbesserungen ermöglichen es Teams, mit Standortdaten mithilfe von Standard-SQL zu arbeiten, während die Engine die Ausführungskomplexität automatisch handhabt. Anwendungsfälle wie Standortanalysen in Echtzeit, groß angelegtes Geofencing und geografische Anreicherung laufen mit wachsenden Datenmengen schneller und konsistenter.
Räumliche Analytics erfordert keine separaten Tools oder manuelle Optimierung mehr. Komplexe geospatiale Workloads skalieren direkt in Databricks SQL.
AI Functions, skalierbare KI direkt in SQL
Die Anwendung von KI auf Daten erforderte traditionell Arbeit außerhalb des Warehouse. Textklassifizierung, Dokumenten-Parsing und Übersetzung bedeuteten oft den Aufbau separater Pipelines, die Verwaltung der Modellinfrastruktur und das Zurückführen der Ergebnisse in Analytics-Workflows.
AI Functions vereinfachen dieses Modell, indem sie KI direkt in SQL integrieren. Im Jahr 2025 hat Databricks SQL den Scale und die Performance dieser Funktionen erheblich erweitert. Eine neue, für Batch optimierte Infrastruktur lieferte eine bis zu 85-mal schnellere Performance für Funktionen wie ai_classify, ai_summarize und ai_translate, sodass große Batchjobs, die früher Stunden dauerten, in wenigen Minuten abgeschlossen werden konnten.
Databricks hat außerdem ai_parse_document eingeführt und schnell für Skalierbarkeit optimiert. Zweckgebundene Modelle für das Dokumentenverständnis, die auf Databricks Model Serving gehostet werden, lieferten im Vergleich zu Allzweck-Alternativen eine bis zu 30-mal schnellere Performance, wodurch die Verarbeitung großer Mengen unstrukturierter Inhalte direkt in Analyse-Workflows praktikabel wird.
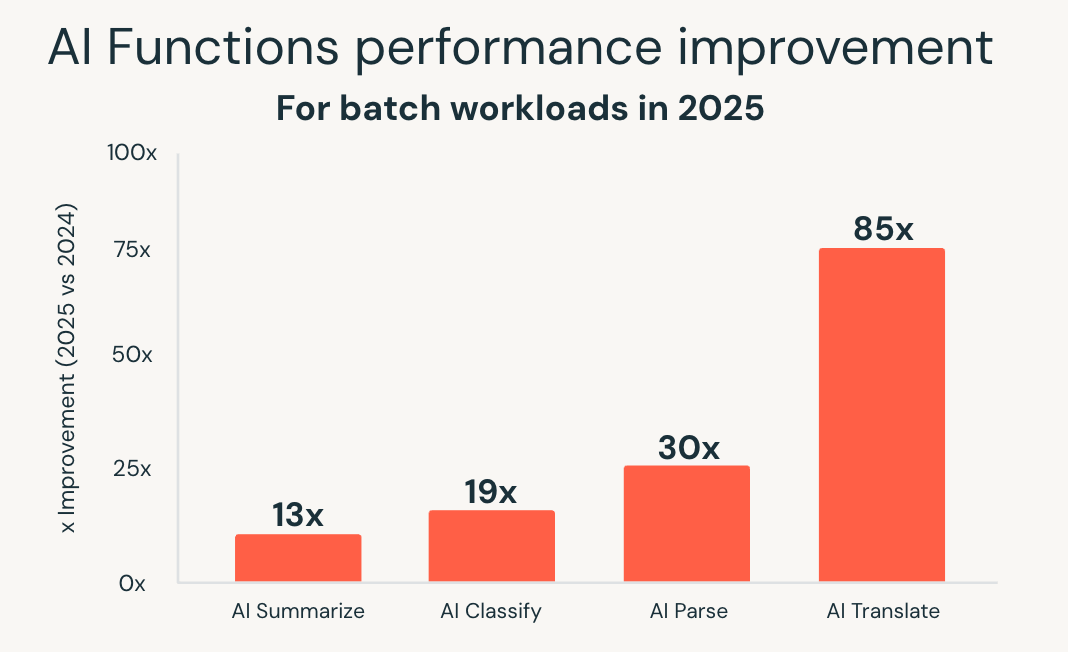
Diese Verbesserungen ermöglichen eine intelligente Dokumentenverarbeitung, die Gewinnung von Erkenntnissen aus unstrukturierten Daten und Predictive Analytics über vertraute SQL-Schnittstellen. KI-Workloads skalieren zusammen mit Analyse-Workloads, ohne dass separate Systeme oder benutzerdefinierte Pipelines erforderlich sind.
Mit AI Functions erweitert Databricks SQL seine Funktionalität über Analysen hinaus auf KI-gestützte Workloads, während die Einfachheit und die Leistungserwartungen des warehouse erhalten bleiben.
Erste Schritte
All diese Verbesserungen sind bereits in Databricks SQL Serverless verfügbar, ohne dass etwas aktiviert oder konfiguriert werden muss.
Wenn Sie DBSQL Serverless noch nicht ausprobiert haben, erstellen Sie ein serverloses Warehouse und starten Sie mit dem Abfragen. Bestehende Workloads profitieren sofort, da Performance- und Kostenverbesserungen automatisch angewendet werden, während sich die Plattform weiterentwickelt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.