Fortschritt im Lakehouse mit Apache Iceberg v3 auf Databricks
Databricks unterstützt Apache Iceberg v3 und bietet Kunden eine einheitliche, leistungsstarke und interoperable Datenschicht
von Ryan Blue, Daniel Weeks, Jason Reid, Fred Liu und Aniruth Narayanan
• Databricks unterstützt Apache Iceberg v3, sodass Kunden interoperable, verwaltete Workloads auf einer einzigen Datenkopie ausführen können
• Mit Iceberg v3 sind Deletion Vectors, Row-Level Lineage und der Variant-Datentyp jetzt für alle verwalteten Tabellen verfügbar
• Mit diesen Funktionen bringt Databricks die Data Intelligence Platform für beste Leistung auf alle Formate
Databricks unterstützt Apache Iceberg v3 auf der Data Intelligence Platform und bietet Kunden eine einheitliche und offene Datenschicht mit erstklassiger Leistung, Interoperabilität und Governance.
Mit dieser Version können Databricks-Kunden, die Iceberg-Workloads ausführen, nun die Vorteile von v3-Funktionen nutzen, einschließlich Deletion Vectors, Row-Level Lineage und dem Variant-Datentyp. Diese Funktionen ermöglichen es Teams, moderne Workloads effizient und konsistent über Plattformen hinweg auszuführen. Diese Funktionen funktionieren auch nahtlos über Delta- und Iceberg-Tabellen hinweg und ermöglichen Interoperabilität ohne Daten-Rewriting.

Diese Version stärkt das Engagement von Databricks für offene Standards und hilft Kunden, auf der Lakehouse-Grundlage von Delta Lake, Apache Iceberg, Apache Parquet und Apache Spark aufzubauen, alles mit voller Governance und Flexibilität.
In diesem Blog werden wir untersuchen:
- Eine einheitliche Datenschicht mit Iceberg v3
- Effiziente Iceberg v3-Workloads auf Databricks
- Fortschritte bei offenen Tabellenformaten
Eine einheitliche Datenschicht mit Iceberg v3
Delta Lake und Apache Iceberg sind zur Grundlage des modernen Lakehouse geworden, beide mit starken Fähigkeiten für Zuverlässigkeit, Governance und skalierbares Datenmanagement. Sie verwenden beide Metadaten-Dateien, um Parquet-Datendateien und Row-Level-Löschungen zu verfolgen. Kleinere Unterschiede zwischen den Formaten in diesen Daten- und Löschdateien zwangen Organisationen jedoch oft, ein Format und seine Funktionen zu wählen, meist basierend darauf, welche Datenplattformen sie verwendeten. Diese Wahl war oft unumkehrbar, da das Umschreiben von Petabytes an Daten unpraktisch ist.
Iceberg v3 schließt diese Lücke. Es führt Funktionen ein, die eng mit Delta und dem breiteren offenen Ökosystem wie Parquet und Spark übereinstimmen, sodass Teams eine einzige Datenkopie mit konsistentem Verhalten und Leistung über Formate hinweg verwenden können.
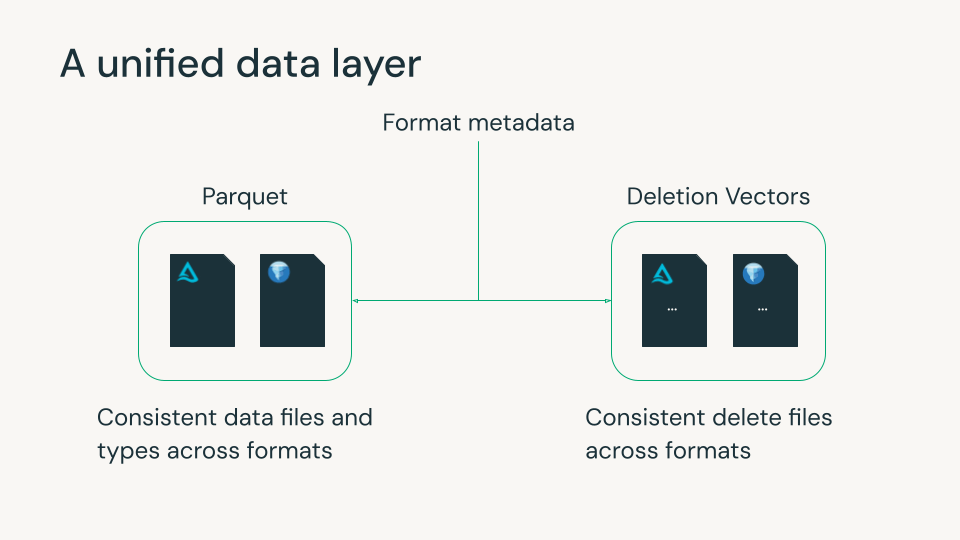
Databricks glaubt seit langem, dass die Zukunft des Lakehouse Optionalität ohne Fragmentierung ist. Unsere Beiträge zu Iceberg v3 spiegeln dieses Engagement wider: Wir helfen, Kern-Tabellenverhalten zu vereinheitlichen, damit Kunden die Engines und Tools ihrer Wahl verwenden können, während alles konsistent mit Unity Catalog verwaltet wird.
Effiziente Iceberg v3-Workloads auf Databricks
Mit Iceberg v3 bringt Databricks Funktionen der Data Intelligence Platform auf alle von Unity Catalog verwalteten Tabellen.
Deletion Vectors für schnellere Updates
Deletion Vectors ermöglichen das Löschen oder Aktualisieren von Zeilen, ohne Parquet-Dateien neu schreiben zu müssen. Stattdessen werden Löschungen als separate Dateien gespeichert und beim Lesen zusammengeführt. Die meisten Data Engineering-Workloads ändern nur wenige Zeilen auf einmal, was dies zu einer kritischen Funktion für effiziente Schreibvorgänge macht.

Sie können jetzt die erstklassige ETL-Preis-Leistungs-Verhältnis von Databricks nutzen, um Iceberg-Workloads mit Deletion Vectors auszuführen. Im Vergleich zu regulären MERGE-Anweisungen können Deletion Vectors Updates um bis zu das 10-fache beschleunigen. Iceberg-Engines können verwaltete Iceberg-Tabellen über die Iceberg REST Catalog APIs von Unity Catalog lesen und schreiben. Wie Geodis anmerkt:
„Jetzt, da Deletion Vectors zu Iceberg gekommen sind, können wir unseren Iceberg-Datenbestand in Unity Catalog zentralisieren, während wir die Engine unserer Wahl nutzen und erstklassige Leistung beibehalten.“ —Delio Amato, Chief Architect & Data Officer, Geodis
Row Lineage für Row-Level-Concurrency
Row Lineage gibt jeder Zeile eine eindeutige ID, wodurch Änderungen im Laufe der Zeit leicht verfolgt werden können. Row Lineage ist für alle Iceberg v3-Tabellen erforderlich.
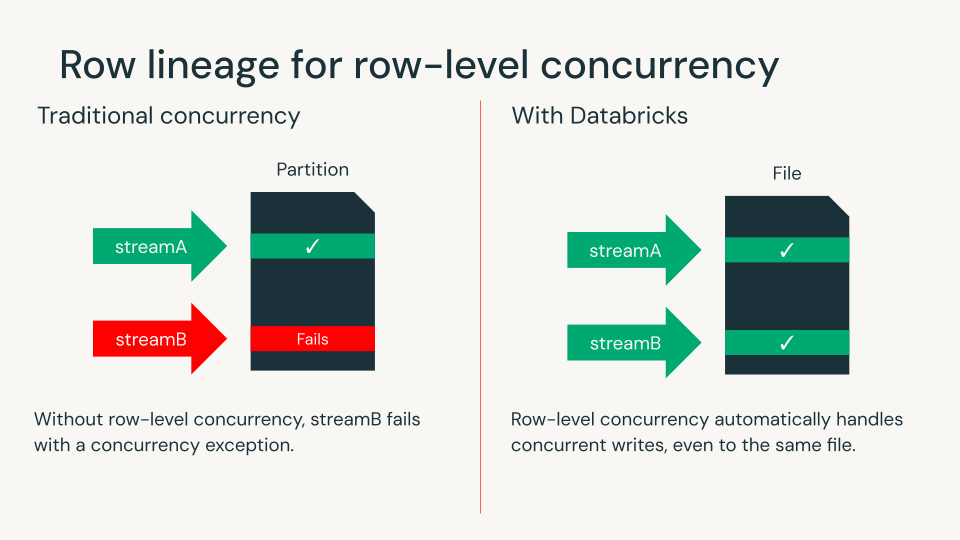
Mit Deletion Vectors und Row Lineage können Databricks-Kunden jetzt Row-Level Concurrency nutzen, um Schreibkonflikte auf Zeilenebene zu erkennen. Dies eliminiert die Notwendigkeit, komplexe Datenlayouts zu entwerfen oder Workloads zu koordinieren, um Concurrency sicherzustellen. Databricks bleibt die einzige Lakehouse-Engine, die diese Funktion für offene Tabellenformate bietet.
Variant-Datentyp für flexible Aufnahme
Moderne Daten passen selten sauber in Zeilen und Spalten. Protokolle, Ereignisse und Anwendungsdaten kommen oft im JSON-Format an. Der Variant-Datentyp speichert semi-strukturierte Daten direkt und bietet eine hervorragende Leistung, ohne dass komplexe Schemata oder fehleranfällige Pipelines erforderlich sind.

Mit dem Variant-Datentyp in Databricks können Sie Rohdaten direkt in Ihre Lakehouse-Tabellen laden, indem Sie Aufnahmefunktionen verwenden. Diese Funktionen unterstützen das Laden von JSON-, CSV- und XML-Daten. Variant unterstützt Shredding, das gängige Felder in separate Chunks extrahiert, um eine spaltenähnliche Leistung zu erzielen. Dies beschleunigt Abfragen für Low-Latency-BI-, Dashboard- und Alerting-Pipelines.
Variant funktioniert sowohl über Delta als auch über Iceberg. Teams, die verschiedene Engines verwenden, können dieselbe Tabelle abfragen, einschließlich der Variant-Spalten, ohne Datenredundanz:
„Vorbei sind die Zeiten einfacher Skalardaten, insbesondere für Anwendungsfälle, die Sicherheits- und Anwendungs-Logs erfordern. Unity Catalog und Iceberg v3 erschließen die Leistung semi-strukturierter Daten durch Variant. Dies ermöglicht Interoperabilität und kostengünstige Log-Sammlung im Petabyte-Maßstab.“ —Russell Leighton, Chief Architect, Panther
Fortschritte bei offenen Tabellenformaten
Iceberg v3 markiert einen wichtigen Schritt zur Vereinheitlichung offener Tabellenformate über die Datenschicht hinweg. Die nächste Grenze ist die Verbesserung der Art und Weise, wie Formate Metadaten im großen Maßstab verwalten und synchronisieren. Community-Bemühungen, wie der adaptive Metadatenbaum, der erstmals auf dem Iceberg Summit vorgestellt wurde, können den Metadaten-Overhead reduzieren und Tabellenoperationen im großen Maßstab beschleunigen.
Während sich diese Ideen weiterentwickeln, bringen sie die Delta- und Iceberg-Communities näher zusammen, mit gemeinsamen Zielen rund um schnellere Commits, effizientes Metadatenmanagement und skalierbare Multi-Tabellen-Operationen. Databricks trägt weiterhin zu dieser Entwicklung bei und ermöglicht es Kunden, die beste Leistung und Interoperabilität zu erzielen, ohne durch Unterschiede auf Format-Ebene eingeschränkt zu sein.
Probieren Sie Iceberg v3 noch heute mit Databricks aus
Diese Iceberg v3-Funktionen sind jetzt auf Databricks verfügbar und bieten Kunden die zukunftssicherste Implementierung des Standards, unterstützt durch die Governance von Unity Catalog. Mit Iceberg v3 können Databricks-Kunden die besten Funktionen über Delta- und Iceberg-Tabellen hinweg nutzen. Das Erstellen einer von Unity Catalog verwalteten Tabelle mit Iceberg v3 ist einfach:
Beginnen Sie mit Unity Catalog und Iceberg v3 und nehmen Sie an unseren bevorstehenden Open Lakehouse + AI-Veranstaltungen teil, um mehr über unsere Arbeit im gesamten offenen Ökosystem zu erfahren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.