Agentisches Data Engineering mit Genie Code und Lakeflow
Genie Code optimiert die Entwicklung, Orchestrierung und Bereitstellung von Datenpipelines
von Gal Oshri, Camiel Steenstra, Lennart Kats und Joanna Zouhour
- Genie Code ist ein autonomer KI-Partner, der speziell für Daten entwickelt wurde
- Data Engineers können Genie Code direkt in Lakeflow verwenden, vom Erstellen von Pipelines im Pipeline Editor bis zur Orchestrierung von Workflows in Lakeflow Jobs
- Genie Code unterstützt den gesamten Data-Engineering-Lebenszyklus – von der Entwicklung und Orchestrierung bis zur Überwachung und Fehlerbehebung – innerhalb einer einzigen Agenten-Erfahrung
Mit Genie Code können Data Engineers natürliche Sprache verwenden, um produktionsreife Datenpipelines zu generieren, sie mit Jobs zu orchestrieren und Fehler zu beheben. Aufgaben, die früher Wochen dauerten – Daten finden, Transformationen erstellen, Jobs zusammenfügen und Fehler beheben – können jetzt in Stunden erledigt werden, während die Einhaltung von Governance- und Betriebsstandards gewährleistet ist.
Im Folgenden zeigen wir, wie dies in der Praxis funktioniert: Daten entdecken, Pipelines erstellen, Jobs orchestrieren und Fehler beheben, alles in einem einzigen Gespräch.
Komplette, produktionsreife Pipelines und Jobs mit natürlicher Sprache erstellen und orchestrieren
Genie Code kann Sie jetzt in einem einzigen Thread von der Exploration zu geplanten Pipelines und Jobs führen und Ihnen dabei helfen, diese End-to-End zu erstellen und zu betreiben.
Es beschleunigt die Entwicklung von Lakeflow Spark Declarative Pipelines und vereinfacht die Orchestrierung und Ausführung von Pipelines und Notebooks über Lakeflow Jobs. Genie Code versteht Ihren Pipeline- und Job-Kontext und greift auf Code, Konfiguration und Ausführungsergebnisse zu.
Genie Code unterstützt Sie in wichtigen Phasen des Data-Engineering-Lebenszyklus:
- Suche über Daten-Assets, nicht nur Code: Genie Code verwendet Popularität, Lineage, Codebeispiele und Unity Catalog Metadaten, um die relevantesten Datensätze für Ihre Aufgabe zu identifizieren. Sie können Genie Code beispielsweise bitten, zu erklären, wie Tabellen zusammenhängen oder wie Daten durch eine Pipeline fließen. Bei SiriusXM verwenden Teams Genie Code, um Tabellenbeziehungen schneller zu verstehen.
- Pipelines erstellen und ändern: Beschreiben Sie zunächst die gewünschte Pipeline in einfacher Sprache, z. B. eine Betrugserkennungspipeline, die auf einer Medaillon-Architektur basiert. Genie Code generiert eine Spark Declarative Pipeline mit Bronze-, Silver- und Gold-Schichten, einschließlich Quellen, Transformationen, Datenqualitäts-Erwartungen und Ausgaben. Von dort aus können Sie Änderungen anfordern, die vorgeschlagenen Diffs überprüfen und die Pipeline ausführen und testen.
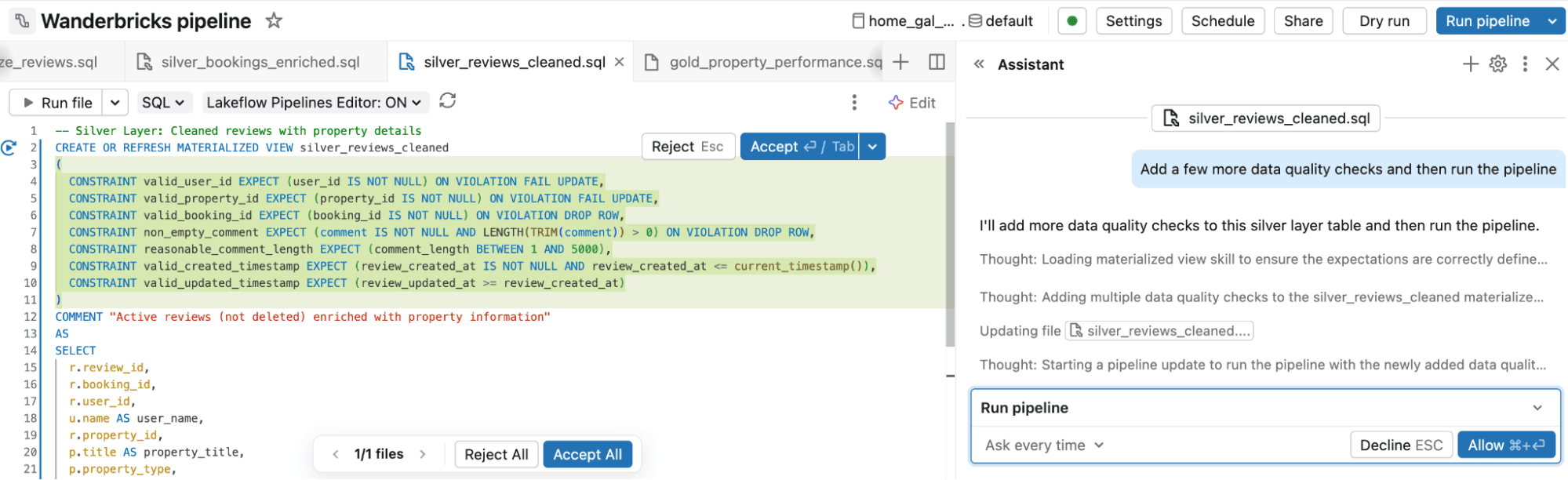
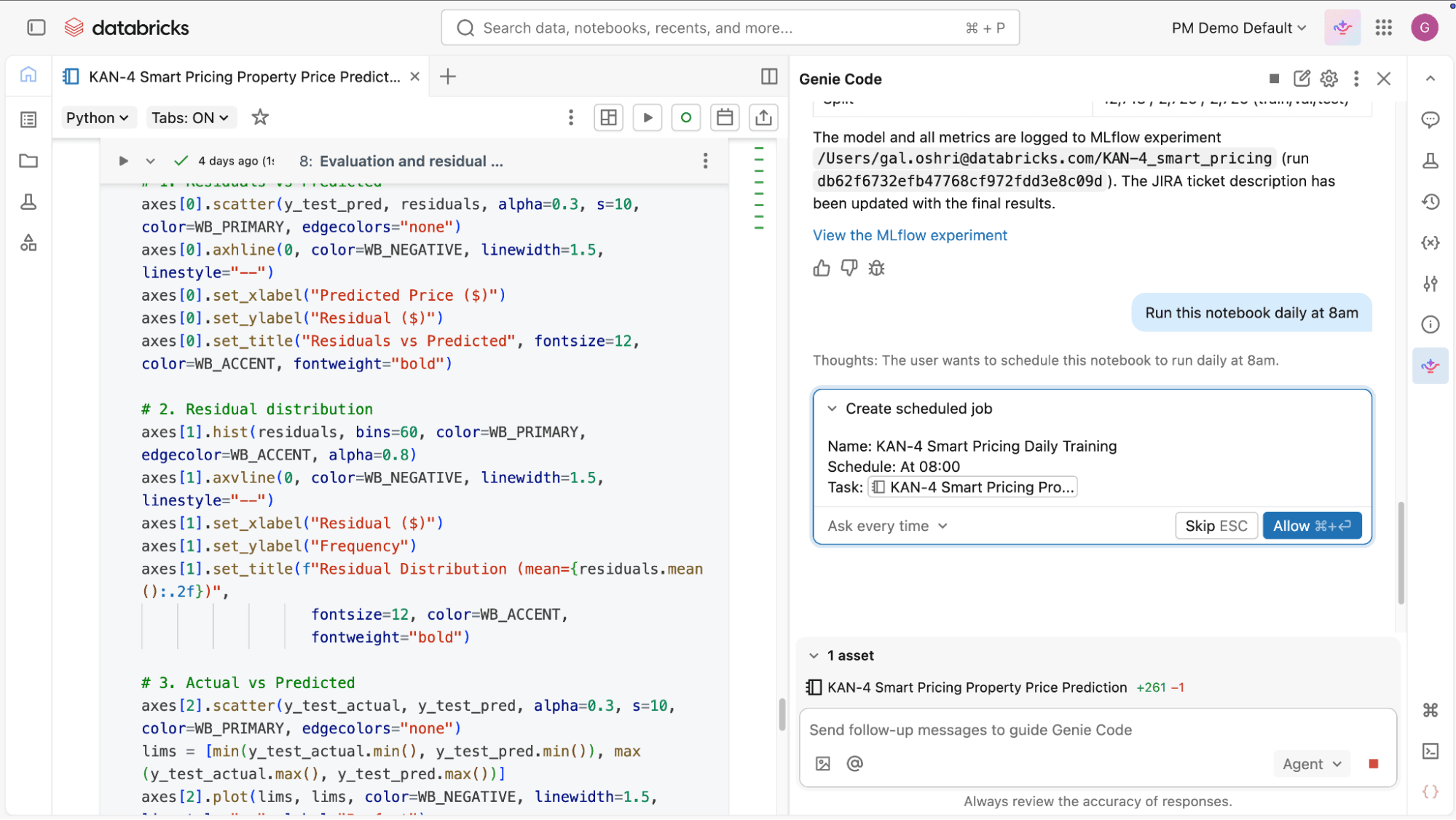
- Jobs definieren und orchestrieren: Es ist nicht mehr nötig, die Orchestrierungslogik manuell zu definieren und zu pflegen. Sie beschreiben den gewünschten Job, einschließlich Aufgaben, Abhängigkeiten und Zeitplan. Genie Code konfiguriert ihn für Sie und hilft dann, Orchestrierungsprobleme in natürlicher Sprache zu ändern, zu debuggen und zu beheben.
- Bestehende Workflows erweitern und weiterentwickeln: Wenn sich Anforderungen ändern, hilft Ihnen Genie Code, Pipelines und Jobs mit neuen Datensätzen und Transformationen zu aktualisieren. Es versteht die aktuelle Struktur und die Ergebnisse Ihrer Pipelines und kann diese erweitern, indem es AutoCDC-Flows für die Änderungsdatenerfassung schreibt, Auto Loader konfiguriert, Datenqualitäts-Erwartungen anwendet und der Medaillon-Architektur folgt.
- Best Practices mit Declarative Automation Bundles (DABs) anwenden: Genie Code kann direkt in Ihren bestehenden DABs-Projekten arbeiten: Ressourcen hinzufügen, Konfigurationen aktualisieren, Bundles validieren und auf Ihre Ziele bereitstellen. So können Sie Software-Engineering-Best Practices wie Quellcodeverwaltung, Tests und CI/CD für Ihre Datenprojekte übernehmen, ohne YAML manuell schreiben zu müssen.
- Schneller arbeiten ohne Qualitätsverlust: Diese Funktionen reduzieren den manuellen Aufwand und halten die Workflows gleichzeitig mit den Unternehmensanforderungen im Einklang. Pipelines werden weiterhin über Unity Catalog gesteuert und folgen etablierten Mustern für Leistung und Datenqualität, während Jobs eine konsistente Konfiguration für Planung, Wiederholungen und Abhängigkeiten erben. Data Engineers behalten die Kontrolle, verbringen aber weniger Zeit mit sich wiederholenden Aufgaben.
Pipelines und Jobs überwachen, diagnostizieren und debuggen
- Pipeline-Verhalten verstehen und verbessern: Genie Code kann Datensätze und Pipeline-Ausgaben überprüfen, um Ihnen zu helfen, eine Pipeline End-to-End zu verstehen. Es kann beispielsweise Transformationen zusammenfassen, verfolgen, wie Daten in nachgelagerte Tabellen fließen, und unerwartete Änderungen in Zeilenanzahlen oder Schemata hervorheben.
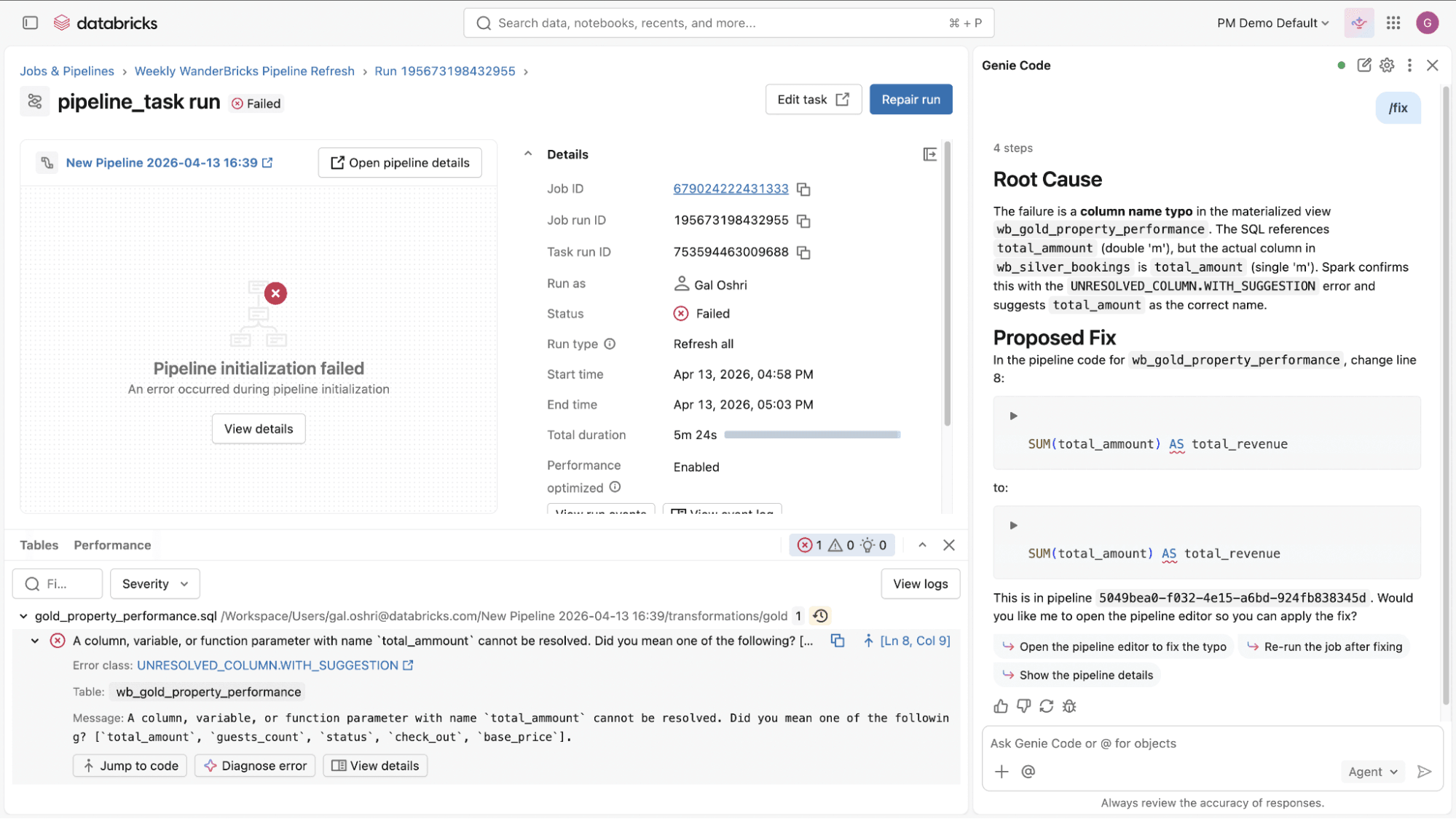
- Job- und Pipeline-Fehler debuggen und diagnostizieren: Wenn eine Pipeline oder ein Job fehlschlägt, hilft Ihnen Genie Code, das Problem zu lösen. Es analysiert Fehler, schlägt Aktualisierungen für die relevanten Dateien vor und zeigt Ihnen die Diffs, bevor Änderungen angewendet werden. Sie können jede Aktualisierung überprüfen und entscheiden, was weitergeht. Dies verwandelt lange, manuelle Debug-Zyklen in schnellere, geführte Iterationen.
- Genie Code erweitern und anpassen: Genie Code ist nicht auf integrierte Funktionen beschränkt. Teams können es mit benutzerdefinierten Anweisungen und Agenten-Skills erweitern und externe Systeme über MCP-Server integrieren, wodurch Genie Code mit domänenspezifischer Logik, internen Tools und benutzerdefinierten Workflows arbeiten kann. Dies stellt sicher, dass Genie Code sich an Ihre Umgebung und Ihr Domänenwissen anpasst.
Was kommt als Nächstes
Weitere Funktionen werden kommen, um Genie Code über Pipelines, Jobs und die gesamte Plattform hinweg zu erweitern. Eine spannende Funktion am Horizont sind KI-optimierte Workloads. In Zukunft können Sie Genie Code auch im Hintergrund laufen lassen, um Ihre Plattform effizient zu halten, sodass Sie repetitive und zeitaufwändige Aufgaben abgeben können. Dazu gehören die Reaktion auf Job-Fehler und die Verwaltung routinemäßiger Upgrades, aber auch die automatische Anpassung der Cluster-Nutzung.
Möchten Sie mehr über diese Updates und Best Practices erfahren? Melden Sie sich unbedingt für den Data+AI Summit an, wo wir Hunderte von Sessions zu Genie Code, Lakeflow und vielem mehr anbieten!
Probieren Sie die Data-Engineering-Funktionen von Genie Code aus
Öffnen Sie Genie Code im Agentenmodus und bitten Sie es, Ihnen beim Erstellen oder Aktualisieren Ihrer Pipelines und Jobs zu helfen. Weitere Details finden Sie in der Demo.
Lesen Sie die Dokumentation, um mehr zu erfahren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.