Ankündigung: Native Lakehouse Sync von Lakebase
Öffnen von Lakebase-Daten für Modelle, Analysen und andere Engines
von Pranav Aurora, Hristo Stoyanov und Cheng Chen
- Native Lakehouse Sync (Public Preview) repliziert Lakebase Postgres-Daten automatisch in Unity Catalog-verwaltete Tabellen, ohne Pipelines oder externe Rechenleistung.
- Traditionelle CDC-Stacks brechen unter agentengesteuerten Workloads zusammen. Da Lakebase und das Lakehouse denselben offenen Speicher nutzen, wird Sync zu einer nativen Datenbankeigenschaft ohne Leistungseinbußen für Postgres, ohne zusätzliche Kosten und mit automatischer Schema-Weitergabe.
- Live-ML-Funktionen, die auf dem aktuellen Anwendungszustand basieren, operative Daten als Bronze-Schicht einer Medaillon-Architektur mit vollständiger SCD-Typ-2-Historie und integrierte Audit-Erfassung für jede Änderung.
Heute freuen wir uns, die Public Preview von Native Lakehouse Sync anzukündigen, einer Kernfunktion von Lakebase Postgres, die Lakebase-Daten in Unity Catalog-verwaltete Tabellen repliziert, ohne Pipelines oder externe Rechenleistung. Native Lakehouse Sync ist in allen Lakebase-Regionen auf AWS und Azure verfügbar.
Warum wir es entwickelt haben
Anwendungen liefen früher auf einer einzigen operativen Datenbank. Als die Anwendungsfälle zunahmen, reichte eine Datenbank nicht mehr aus. Analysen, ML und Suche leben alle außerhalb der operativen Datenbank, was bedeutet, dass Daten verschoben werden müssen.
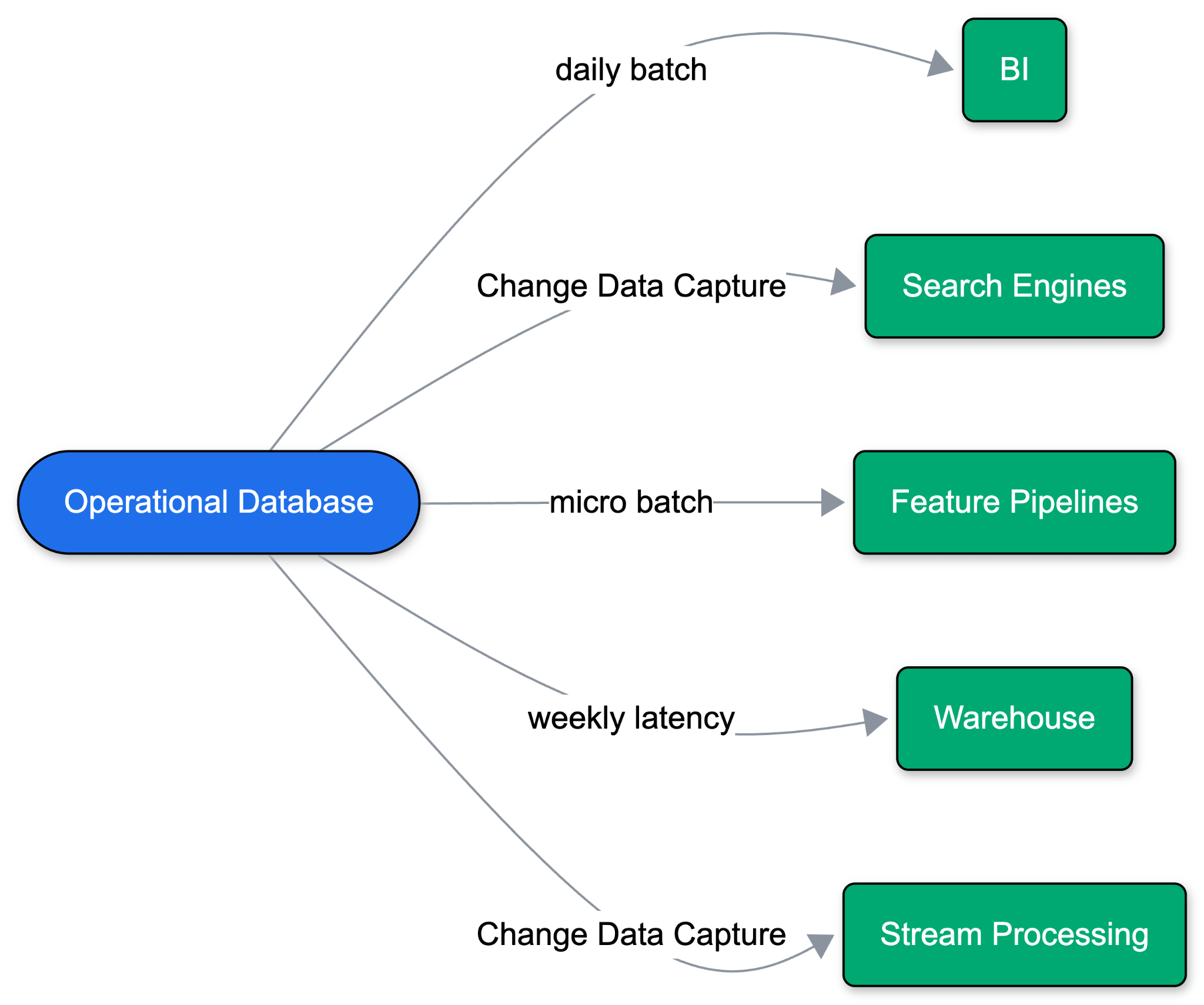
Historisch gesehen bedeutete dies tägliche Batch-Dumps in ein Warehouse, was sich schließlich zur Erfassung von Änderungsdaten (Change Data Capture, CDC) entwickelte. Hyperscaler verpackten dies als „verwaltete“ Synchronisierungen („Zero-ETL“), indem sie Datenpipelines neben der Datenbank bereitstellten. Diese verwalteten Synchronisierungen basieren jedoch auf veralteten Annahmen: Always-on-Workloads, stabile Schemata, vorhersehbare Abfragevolumen und ein einziges Ziel-Warehouse. Das Problem verschärft sich mit jedem neuen Datenspeicherort: Die operative Leistung verschlechtert sich, das Schema driftet und die Fehlerquellen vervielfachen sich im gesamten Stack.
Agenten-basiertes Development bricht dieses Modell vollständig auf. Agenten verzweigen Daten schnell, um sicher zu iterieren, skalieren zwischen Aufgaben auf Null und starten kurzlebige Umgebungen. Die Verwaltung einer benutzerdefinierten Pipeline für jeden Branch und jedes Ziel ist einfach nicht skalierbar.
Die Anbindung an ein Warehouse ist der falsche Ansatz. Nachgelagerte Verbraucher sind selten nur noch Dashboards; es sind eingebettete Modelle, LLMs, Vorhersagedienste und Feature-Pipelines. Offene Tabellenformate wie Delta Lake und Apache Iceberg™ bieten die ideale Grundlage: Daten einmal in kostengünstigem Objektspeicher speichern, um alle Workloads ohne Duplizierung zu unterstützen. Es ist ein bekanntes Problem: Sie benötigen ein Lakehouse und möchten aktuelle operative Daten darin haben.
Das Schreiben operativer Daten in ein Lakehouse schuf jedoch neue Herausforderungen. Teams waren gezwungen, Postgres-Replikations-Slots, Debezium-Konnektoren, Stream-Processing-Engines zum Schreiben in offene Formate und separate Rechenleistung zur Optimierung der Tabellen zu konfigurieren. Jeder Schritt fügt einen Fehlerpunkt hinzu.
Sync als Eigenschaft von Lakebase
Lakebase basiert auf einer grundlegend anderen Annahme: Eine operative Datenbank sollte auf demselben offenen, kostengünstigen Cloud-Speicher wie Ihr Lakehouse laufen. Da OLTP und OLAP diese einheitliche Speicherbasis gemeinsam nutzen, können wir die ETL-Pipeline vollständig eliminieren. Datenbewegung wird zu einer nativen Eigenschaft der Datenbank selbst.
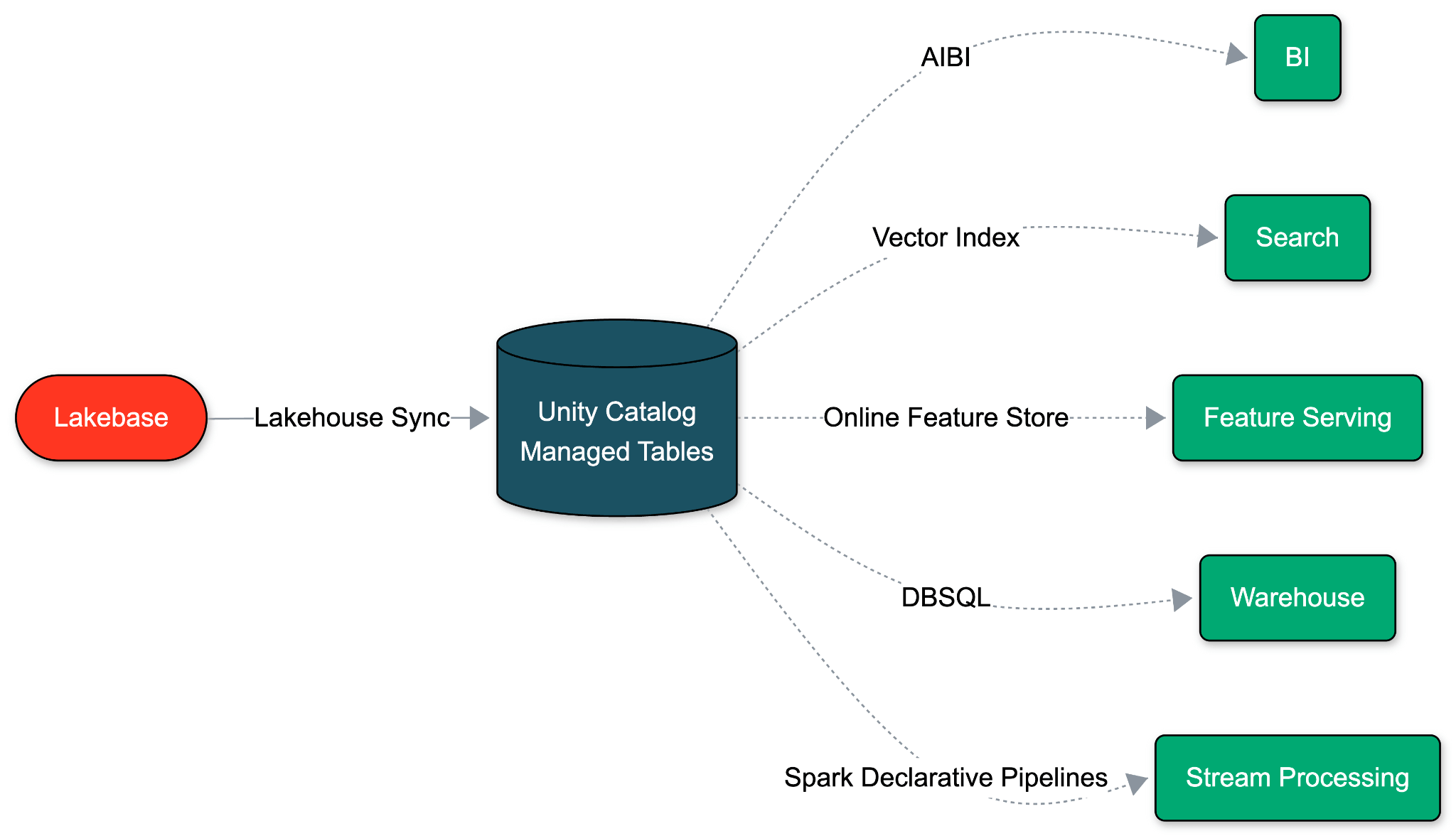
Mit Native Lakehouse Sync dekodiert Lakebase sein Write-Ahead-Log (WAL) und schreibt direkt in Unity Catalog Managed Tables. Ein einziger Schalter auf Schemaebene aktiviert es in weniger als einer Minute. Diese Synchronisierung hat keine Auswirkungen auf die Postgres-Leistung und keine zusätzlichen Kosten. Und da Databricks beide Enden kontrolliert, fließen Schemaänderungen automatisch, wodurch Drift und Verzögerung entfallen.
End-to-End Agenten-basiert
Agenten erstellen Apps auf Lakebase. Agenten wie Databricks Genie analysieren die Daten. Um diesen gesamten Lebenszyklus autonom zu gestalten, ist Native Lakehouse Sync als Kerneigenschaft von Lakebase konzipiert. Es erbt die genauen Verhaltensweisen, die Agenten benötigen, um nahtlos zu funktionieren:
- Skalierung auf Null: Sync pausiert, wenn die Datenbank auf Null skaliert, und wird beim Aufwachen von der letzten LSN fortgesetzt.
- Keine Verwaltung von Rechenleistung: Sync ist ein nativer Bestandteil von Lakebase. Überwachung und Beobachtbarkeit bleiben innerhalb Ihres Lakebase-Projekts.
- Automatische Schema-Weitergabe: Schemaänderungen fließen automatisch. Das Hinzufügen einer Spalte wird sofort weitergegeben. Das Löschen einer Spalte behält sie am Zielort. Agenten müssen die Synchronisierung nie neu erstellen.
Lakehouse-Grundlagen auf der Zielseite
Da das Ziel eine Unity Catalog-verwaltete Tabelle ist, ist jede Lakehouse-Funktion für synchronisierte Daten verfügbar, sobald sie landen.
- KI-native Analysen: Sofort verfügbar für Abfragen, Analysen und Pipeline-Generierung durch Agenten wie Databricks Genie und Genie Code.
- Universelle Lesbarkeit: Lesbar durch Databricks SQL, Apache Spark, Lakeflow Spark Declarative Pipelines, ML-Notebooks und jedes Tool, das Delta oder Iceberg spricht.
- Einheitliche Governance: Lineage, Zugriffsrichtlinien, Tags und Audits werden von Unity Catalog übernommen.
- Automatische Optimierung: Predictive Optimization und Liquid Clustering werden ohne Einrichtung angewendet.
- Standard-Versionierung: Jedes Einfügen, Aktualisieren und Löschen wird als SCD-Typ-2-Historie gespeichert. Audit-Protokolle, Rewinds und CDF-Semantik sind integriert.
Was Sie mit Native Lakehouse Sync erstellen können
Zusammen ermöglichen diese Quell- und Zielverhaltensweisen drei Muster, die zuvor einen benutzerdefinierten Change Data Capture (CDC)-Stack erforderten:
Agenten-Gedächtnis und Live-ML-Features. Anwendungs-Schreibvorgänge landen innerhalb einer Minute in Unity Catalog, sodass Modelle gegen den aktuellen Zustand der Anwendung neu trainiert und bewertet werden können, ohne eine separate Erfassungspipeline.
Operative Daten in der Medaillon-Architektur. Verwenden Sie Lakebase als Bronze-Tabellen in der Medaillon-Architektur. Hochfrequente Aktualisierungen erfolgen in Postgres, und die vollständige Änderungshistorie fließt automatisch als SCD Typ 2 in das Lakehouse.
Compliance und Audit. Jedes Einfügen, Aktualisieren und Löschen wird als Historienzeile in Unity Catalog erfasst. Keine anwendungsseitige Historienverfolgung, keine separate Audit-Pipeline.
Erste Schritte
Native Lakehouse Sync befindet sich in der Public Preview. Das Starten eines Lakebase ist sofort möglich. Aktivieren Sie Sync für ein Schema, und jede vorhandene und zukünftige Tabelle wird innerhalb einer Minute in Unity Catalog angezeigt
Lakebase basiert auf derselben offenen Datenbasis wie das Lakehouse. Native Lakehouse Sync macht diese Vision Wirklichkeit und ermöglicht den automatischen Fluss von Lakebase-Daten in offene Formate ohne separate Pipeline.
Der nächste Schritt: Dieselbe Offenheit vom Lakehouse auf Lakebase-Tabellen übertragen. Bleiben Sie dran.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.)
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.