Aufbau eines Data Mesh auf Basis des Databricks Lakehouse, Teil 2
von Bernhard Walter, Sharon Richardson, Guillermo Schiava D'Albano, Pawarit Laosunthara, Amr Ali und Fran Medina Castro
Im letzten Blogbeitrag "Databricks Lakehouse und Data Mesh" haben wir das Data Mesh basierend auf dem Databricks Lakehouse vorgestellt. Dieser Blogbeitrag untersucht, wie die Fähigkeiten des Databricks Lakehouse das Data Mesh aus architektonischer Sicht unterstützen.
Data Mesh ist ein architektonisches und organisatorisches Paradigma, keine Technologie oder Lösung, die man kauft. Um ein Data Mesh effektiv zu implementieren, benötigen Sie jedoch eine flexible Plattform, die die Zusammenarbeit zwischen Daten-Personas sicherstellt, Datenqualität liefert und Interoperabilität und Produktivität über alle Daten- und KI-Workloads hinweg erleichtert.
Werfen wir einen Blick darauf, wie die Funktionen der Databricks Lakehouse Platform diese Anforderungen erfüllen.
Der grundlegende Baustein eines Data Mesh ist die Datendomäne, die normalerweise aus den folgenden Komponenten besteht:
- Quelldaten (im Besitz der Domäne)
- Self-Service-Compute-Ressourcen und Orchestrierung (innerhalb von Databricks Workspaces)
- Domänenorientierte Datenprodukte, die anderen Teams und Domänen zur Verfügung gestellt werden
- Erkenntnisse, die für die Nutzung durch Geschäftsbenutzer bereit sind
- Einhaltung von föderalen Computational Governance-Richtlinien
Dies ist in der folgenden Abbildung dargestellt:
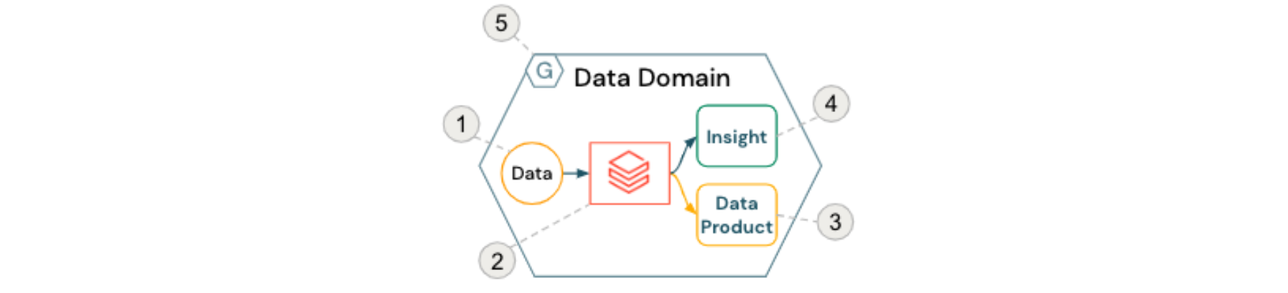
Um die domänenübergreifende Zusammenarbeit und Self-Service-Analysen zu erleichtern, werden häufig zentrale Dienste für Zugriffskontrollmechanismen und Datenkatalogisierung bereitgestellt. Zum Beispiel bietet Databricks Unity Catalog nicht nur informative Katalogisierungsfunktionen wie Datenentdeckung und Lineage, sondern auch die Durchsetzung von feingranularen Zugriffskontrollen und Auditing, die viele Organisationen heute wünschen.
Data Mesh kann in verschiedenen Topologien eingesetzt werden. Außerhalb moderner digital-nativer Unternehmen wird ein stark dezentralisiertes Data Mesh mit vollständig unabhängigen Domänen normalerweise nicht empfohlen, da dies zu Komplexität und Overhead in den Domänenteams führt, anstatt ihnen zu ermöglichen, sich auf Geschäftslogik und qualitativ hochwertige Daten zu konzentrieren. Zwei beliebte Beispiele, die in Unternehmen häufig anzutreffen sind, sind das Harmonisierte Data Mesh und das Hub & Spoke Data Mesh.
1) Ansatz für ein harmonisiertes Data Mesh
Ein harmonisiertes Data Mesh betont die Autonomie innerhalb der Domänen:
- Datendomänen erstellen und veröffentlichen domänenspezifische Datenprodukte
- Die Datenentdeckung wird automatisch durch Unity Catalog ermöglicht
- Datenprodukte werden auf Peer-to-Peer-Basis konsumiert
- Die Domäneninfrastruktur wird harmonisiert durch
- Plattform-Blueprints, die Sicherheit und Compliance gewährleisten
- Self-Service-Plattformdienste (Automatisierung der Domänenbereitstellung, Datenkatalogisierung, Metadatenveröffentlichung, Richtlinien für Daten- und Compute-Ressourcen)
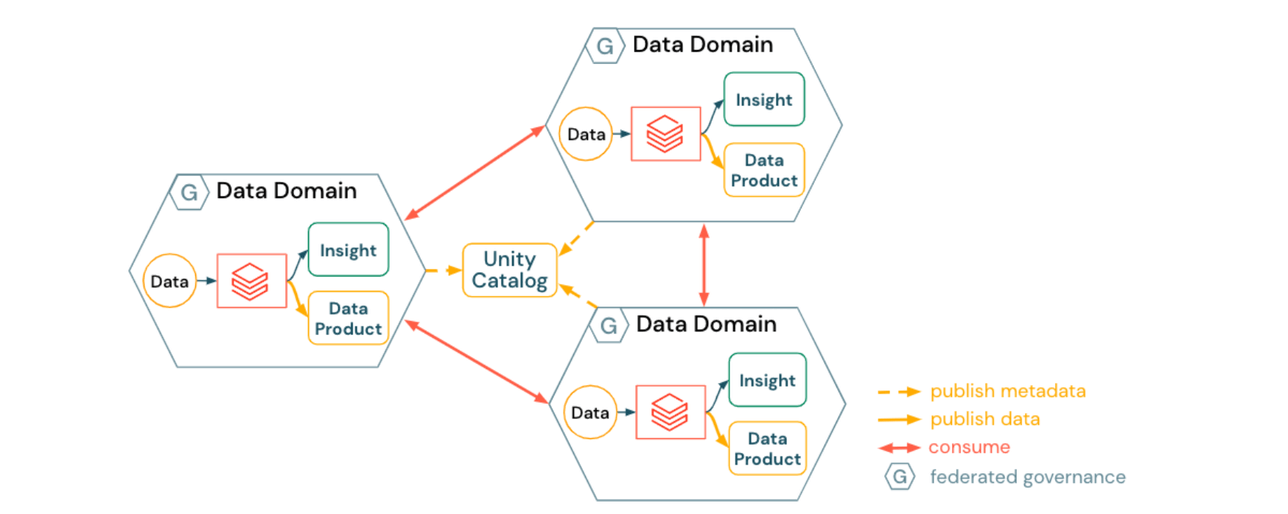
Die Auswirkungen eines harmonisierten Ansatzes können sein:
- Datendomänen müssen Standards und Best Practices für Interoperabilität und Infrastrukturmanagement einhalten
- Datendomänen investieren jeweils unabhängig mehr Zeit und Mühe in Themen wie Zugriffskontrollen, zugrunde liegende Speicher-Accounts oder sogar Infrastruktur (z. B. Event-Broker für Streaming-Datenprodukte)
Dieser Ansatz kann in globalen Organisationen herausfordernd sein, in denen verschiedene Teams unterschiedliche Kenntnisse und Fähigkeiten haben und es schwierig finden, mit den neuesten Praktiken und Richtlinien auf dem Laufenden zu bleiben.
2) Ansatz für ein Hub & Spoke Data Mesh
Ein Hub & Spoke Data Mesh beinhaltet einen zentralen Ort für die Verwaltung gemeinsam nutzbarer Datenbestände und von Daten, die logisch nicht in eine einzelne Domäne fallen:
- Datendomänen (Spokes) erstellen domänenspezifische Datenprodukte
- Datenprodukte werden im Data Hub veröffentlicht, der die Mehrheit der in Unity Catalog registrierten Assets besitzt und verwaltet
- Der Data Hub bietet generische Plattformdienste für Datendomänen wie:
- Self-Service-Datenveröffentlichung an verwalteten Speicherorten
- Datenkatalogisierung, Lineage, Audit und Zugriffskontrolle �über Unity Catalog
- Datenmanagementdienste wie Time Travel und DSGVO-Prozesse domänenübergreifend (z. B. Anfragen zum Recht auf Vergessenwerden)
- Der Data Hub kann auch als Datendomäne fungieren. Zum Beispiel Pipelines oder Tools für generische oder extern erworbene Datensätze wie Wetter-, Marktforschungs- oder Standard-Makrodaten.
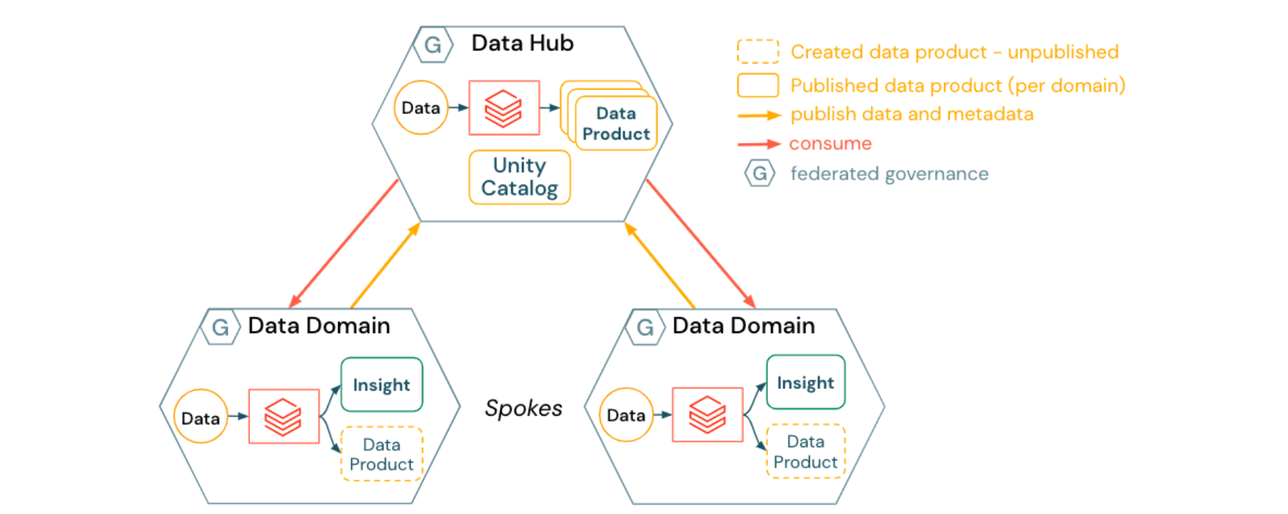
Die Auswirkungen eines Hub and Spoke Data Mesh sind:
- Datendomänen können von zentral entwickelten und bereitgestellten Datendiensten profitieren, wodurch sie sich stärker auf Geschäfts- und Datentransformationslogik konzentrieren können
- Infrastrukturautomatisierung und Self-Service-Compute können verhindern, dass das Data Hub-Team zu einem Engpass für die Veröffentlichung von Datenprodukten wird
Bei beiden Ansätzen können Domänen auch gemeinsame und wiederholbare Anforderungen haben, wie zum Beispiel:
- Datenaufnahme-Tools und Konnektoren
- MLOps-Frameworks, Vorlagen oder Best Practices
- Pipelines für CI/CD, Datenqualität und Überwachung
Ein zentraler Pool von Fähigkeiten und Fachwissen, wie ein Center of Excellence, kann sowohl für wiederholbare Aktivitäten, die domänenübergreifend üblich sind, als auch für seltene Aktivitäten, die Nischenkenntnisse erfordern, die möglicherweise nicht in jeder Domäne verfügbar sind, von Vorteil sein.
Es ist auch durchaus möglich, einige Variationen zwischen einem vollständig harmonisierten Data Mesh und einem Hub-and-Spoke-Modell zu haben. Zum Beispiel ein minimales globales Daten-Hub, um nur Datenbestände zu hosten, die logisch nicht in eine einzelne Domäne fallen, und um extern erworbene Daten zu verwalten, die domänenübergreifend verwendet werden. Unity Catalog spielt die zentrale Rolle bei der Bereitstellung der authentifizierten Datenentdeckung, wo immer Daten innerhalb einer Databricks-Bereitstellung verwaltet werden.
Skalierung und Weiterentwicklung des Data Mesh
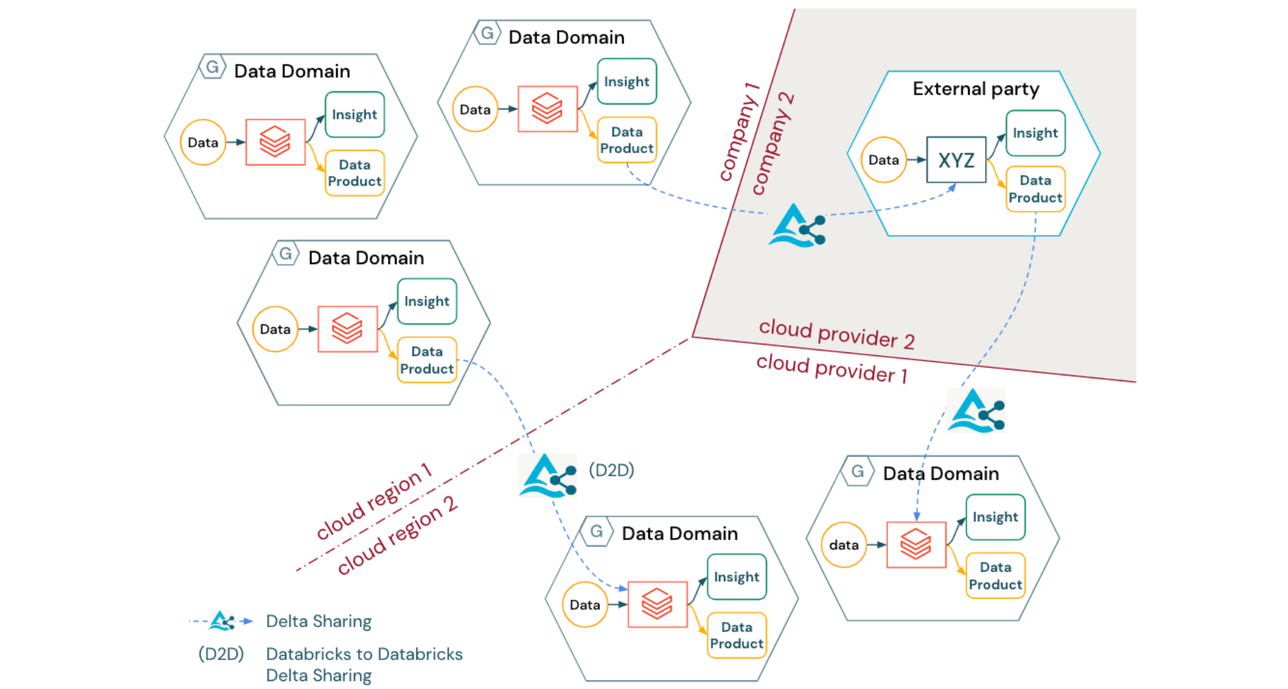
Unabhängig von der Art der bereitgestellten logischen Data Mesh-Architektur stehen viele Organisationen vor der Herausforderung, ein Betriebsmodell zu schaffen, das Cloud-Regionen, Cloud-Anbieter und sogar Rechtseinheiten überspannt. Darüber hinaus bleibt, während sich Organisationen weiterentwickeln in Richtung Produktivitätssteigerung (und potenziell sogar Monetarisierung) von Datenbeständen, eine unternehmensweite, interoperable Datenfreigabe entscheidend für die Zusammenarbeit nicht nur zwischen internen Domänen, sondern auch zwischen Unternehmen.
Delta Sharing bietet eine Lösung für dieses Problem mit den folgenden Vorteilen:
- Delta Sharing ist ein offenes Protokoll zum sicheren Teilen von Datenprodukten zwischen Domänen über organisatorische, regionale und technische Grenzen hinweg
- Das Delta Sharing-Protokoll ist herstellerunabhängig (einschließlich eines breiten Ökosystems von Clients) und bietet eine Brücke zwischen verschiedenen Domänen oder sogar verschiedenen Unternehmen, ohne dass diese denselben Technologie-Stack oder Cloud-Anbieter verwenden müssen
Abschließende Bemerkungen
Data Mesh und Lakehouse entstanden beide aufgrund gemeinsamer Schmerzpunkte und Mängel von Enterprise Data Warehouses und traditionellen Data Lakes[1][2]. Data Mesh artikuliert umfassend die Geschäfts vision und die Bedürfnisse zur Verbesserung der Produktivität und des Werts von Daten, während das Databricks Lakehouse eine offene und skalierbare Grundlage bietet, um diese Bedürfnisse mit maximaler Interoperabilität, Kosteneffizienz und Einfachheit zu erfüllen.
In diesem Artikel haben wir zwei Beispiel-Fähigkeiten der Databricks Lakehouse-Plattform hervorgehoben, die die Zusammenarbeit und Produktivität verbessern und gleichzeitig die föderierte Governance unterstützen, nämlich:
- Unity Catalog als Wegbereiter für die unabhängige Datenveröffentlichung, zentrale Datenermittlung und föderierte rechnerische Governance im Data Mesh
- Delta Sharing für große, global verteilte Organisationen mit Bereitstellungen über Clouds und Regionen hinweg. Delta Sharing teilt effizient und sicher frische, aktuelle Daten zwischen Domänen in unterschiedlichen organisatorischen Grenzen ohne Duplizierung
Es gibt jedoch eine Fülle weiterer Databricks-Funktionen, die als großartige Wegbereiter auf dem Weg zum Data Mesh für verschiedene Personas dienen. Zum Beispiel:
- Workflows und Delta Live Tables für hochwertige Self-Service-Datenpipelines, die sowohl Batch- als auch Streaming-Workloads unterstützen
- Databricks SQL, das performante BI- und SQL-Abfragen direkt auf dem Lake ermöglicht und somit den Bedarf für Domänenteams reduziert, mehrere Kopien/Datenspeicher für ihre Datenprodukte zu pflegen
- Databricks Feature Store, der die gemeinsame Nutzung und Wiederverwendung zwischen Data Science- und Machine Learning-Teams fördert
Erfahren Sie mehr über Lakehouse für Data Mesh:
- Matei Zaharia: Data Mesh und Lakehouse
- Zalando & Thoughtworks: Data Lakehouse und Data Mesh – Zwei Seiten derselben Medaille
- Databricks: Meshing About with Databricks
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.