Erstellung eines Wissensassistenten für Code
Bewertung von Chunking-Strategien mit MLflow
von Daniel Liden
- RAG über Code hat einzigartige Chunking-Herausforderungen: Das Aufteilen von Funktionen mitten im Körper oder das Verwerfen des strukturellen Kontexts verschlechtert die Abfrage, selbst wenn Sie die richtige Datei finden.
- Wir haben das GenAI-Evaluierungsframework von MLflow mit integrierten und benutzerdefinierten LLM-Richtern verwendet, um drei Chunking-Strategien, die mit dem Databricks Knowledge Assistant verwendet werden, systematisch zu vergleichen.
- Der Evaluierungsprozess selbst war die wichtigste Lektion: Strukturierte Bewertungsdatensätze, nachvollziehbare Ergebnisse und benutzerdefinierte LLM-Richter, die auf das abgestimmt sind, was Ihnen wirklich wichtig ist, machen die RAG-Iteration praktikabel.
Wenn Entwickler einem neuen Projekt beitreten oder an einer unbekannten Codebasis arbeiten müssen, helfen Wissensassistenten wie der Databricks Knowledge Assistant ihnen, sich durch die Beantwortung von Fragen in natürlicher Sprache zum Code schnell einzuarbeiten. Die Qualität der Antworten hängt jedoch stark davon ab, wie der Quellcode und der umgebende Kontext vorbereitet und hinzugefügt wurden. Ein Schlüsselfaktor ist das Chunking: wie Sie Quelldateien in Teile für die Indizierung und Abfrage aufteilen. Code macht dies schwierig. Wenn Sie eine Funktion mitten im Körper aufteilen oder ihren Klassenkontext entfernen, wird selbst ein fähiger Assistent Schwierigkeiten haben, Fragen dazu zu beantworten.
Wir haben drei Knowledge Assistants für unser Casper’s Kitchens Demo-GitHub-Repository entwickelt, die jeweils eine andere Chunking-Strategie verwenden, von einer einfachen festen Größe als Baseline bis hin zu einem strukturbewussten Ansatz, der Code in seine syntaktischen Komponenten zerlegt. Das Repository simuliert ein Ghost-Kitchen-Unternehmen auf Databricks und nutzt eine breite Palette von Funktionen, darunter Lakeflow-Pipelines, DSPy-Agenten und Databricks Asset Bundles (DABs), mit Dokumentation in Markdown-Dateien und Notebook-Zellen. Die dateiübergreifenden Abhängigkeiten, gemischten Dateiformate und domänenspezifischen Muster machen es zu einer Art Projekt, bei dem ein fähiger Wissensassistent eine enorme Hilfe wäre.
Dieser Beitrag erläutert, was die Arbeit mit Code von der Arbeit mit typischen Geschäftsunterlagen unterscheidet, wie wir jede Chunking-Strategie als Databricks Knowledge Assistant bereitgestellt haben und wie wir das Evaluierungsframework von MLflow verwendet haben, um sie zu vergleichen. Den gesamten Code finden Sie hier.
Wie Knowledge Assistants funktionieren (und warum Code anders ist)
Im Grunde verwenden Wissensassistenten verschiedene Formen der Retrieval-Augmented Generation (RAG). Sie rufen relevante Teile der Quelldaten ab, oft aus einem Vektorsuchindex, und übergeben sie als Kontext an ein großes Sprachmodell, um eine Antwort auf eine Benutzeranfrage zu generieren.
Databricks Knowledge Assistant baut auf dieser Grundlage mit hochentwickelten Abfragetechniken auf, einschließlich Instructed Retriever, der Dekomposition von Abfragen, kontextbezogener Neureihenfolge und Schlussfolgerungen über Metadaten von Dokumenten integriert. Diese Fähigkeiten tragen wesentlich zur Bewältigung der Komplexität realer Codebasen bei und funktionieren am besten, wenn die zugrunde liegenden Chunks aussagekräftige semantische Grenzen wahren.
Wissensassistenten werden am häufigsten über Sammlungen von Geschäftsunterlagen erstellt und ausgewertet, die tendenziell linear verlaufen, mit Absätzen und Abschnitten. Code hat verschachtelte Hierarchien: Dateien enthalten Klassen, Klassen enthalten Methoden, Methoden enthalten Logikblöcke. Die semantische Einheit im Code ist oft eine vollständige Funktion, kein Absatz.
Dies schafft spezifische Herausforderungen, darunter:
- Semantische Grenzen: Das Aufteilen einer Funktion mitten im Körper verliert den Kontext, der zum Verständnis ihrer Funktion erforderlich ist. Ein Chunk, der
deletion_order = ['experiments', 'jobs'...enthält, ist weniger nützlich, wenn er nicht zeigt, dass diese Variable innerhalb vonUCState.clear_all()liegt. - Dateiübergreifende Abhängigkeiten: Code verweist auf anderen Code. Das Verständnis einer Funktion erfordert oft Kontext aus ihrer Klasse, ihren Importen oder verwandten Funktionen.
- Gemischte Dateitypen: Unsere Codebasis enthält
.py-Dateien,.ipynb-Notebooks (JSON mit Code/Markdown-Zellen),.md-Dokumentationen und.yaml-Konfigurationen, die jeweils unterschiedliche Parsing-Ansätze erfordern.
Da Databricks Knowledge Assistant Ihnen die Verwendung Ihres eigenen Vektorindex ermöglicht, können Sie Chunks beliebig vorbereiten und Knowledge Assistant einfach auf das Ergebnis verweisen. Dies ermöglichte uns, verschiedene Ansätze zur Vorbereitung unserer Codebasis für RAG zu vergleichen und den besten auszuwählen.
Chunking-Strategien
Um zu sehen, wie sich Chunking-Strategien in der Praxis unterscheiden, betrachten wir, was passiert, wenn Sie fragen: „In welcher Reihenfolge erfolgt die Bereinigung von Ressourcen?“ Die Antwort befindet sich in einer Dienstklasse, die Experimente, Jobs und Pipelines verfolgt. Ihre Logik umfasst die Initialisierung, eine Liste der Bereinigungsreihenfolge und Bereinigungsmethoden. Hier erfahren Sie, wie jede Methode funktioniert und wie sie den abgerufenen Kontext über die Ressourcenbereinigungsklasse UCState beeinflusst.
Naive Baseline: Feste Zeichen-Chunks
Der einfachste Ansatz besteht darin, die Quelldateien in festen Zeichenintervallen mit Überlappung aufzuteilen und Code als einfachen Text zu behandeln. Dies ist nichts, was Sie heute für ein produktionsreifes RAG-System wählen würden. Es ignoriert Syntax und semantische Grenzen und scheitert daher genau in den Bereichen, die für Codeabfragen wichtig sind. Es ist jedoch auch extrem einfach zu implementieren, oft „gut genug“ für schnelle Experimente oder repos mit vielen Dokumenten, und als erster Schritt üblich, daher ist es eine nützliche Baseline.
Hier ist, was das naive Chunking für eine Suche nach deletion_order in unserer Codebasis ergibt:
Der Variablenname wurde in zwei Teile geteilt (eletion statt deletion) und der Chunk enthält nicht den Methodennamen. Wenn jemand nach „UCState deletion order“ sucht, wird dieser Chunk nicht gut übereinstimmen. Darüber hinaus wurde die Liste deletion_order in der Methode abgeschnitten.
Sprachbewusst: LangChain Heuristic Splitter
LangChains RecursiveCharacterTextSplitter.from_language() verwendet sprachspezifische Trennzeichen (wie \nclass und \ndef für Python), um bevorzugt an logischen Grenzen zu trennen. Es versucht, Funktionen intakt zu halten, erzwingt aber dennoch strenge Größenbeschränkungen. Konzeptionell verbessert dies das naive Chunking, indem es Trennungen an wahrscheinlichen semantischen Grenzen (wie def und class) anstelle von willkürlichen Zeichenzählungen priorisiert, sodass Chunks eher vollständige Logikeinheiten enthalten.
Hier ist, was dieser Ansatz für dieselbe Suche ergab:
Der Chunk beginnt an einer natürlicheren Grenze, ihm fehlt jedoch immer noch der Kontext, der zeigt, zu welcher Datei oder Funktion er gehört, und er bricht direkt nach dem Beginn einer for-Schleife ab.
AST-basiert: Tree-Sitter mit Metadaten-Headern
Die AST-basierte Aufteilung verwendet einen Parser wie Tree-sitter, um die tatsächliche Code-Struktur zu verstehen. Ein AST ist eine Baumdarstellung von Code, die seine syntaktische Struktur erfasst – wie der Code gemäß den Grammatikregeln einer Sprache organisiert ist. Anstatt an Zeichengrenzen zu trennen oder heuristische Muster zu verwenden, analysiert eine AST-basierte Aufteilungsstrategie den Code in einen Syntaxbaum und teilt ihn an semantischen Grenzen, wie Funktionen, Klassen oder Anweisungsblöcken. Sie kann auch Größenbeschränkungen überschreiten, wenn dies erforderlich ist, um eine vollständige Einheit zusammenzuhalten, anstatt sie mitten in einer Funktion zu teilen.
Wir haben die Python-Bibliothek ASTChunk verwendet, um die AST-basierte Aufteilung zu handhaben. Die Bibliothek enthält eine Option für die Chunk-Erweiterung, die dazu führt, dass jedem Chunk ein Metadaten-Header vorangestellt wird, der den Dateipfad und die Klassen-/Funktionshierarchie anzeigt. Dieser Kontext wird Teil des Embeddings und hilft dem Retrieval, Abfragen mit relevantem Code abzugleichen, auch wenn die Abfragebegriffe nicht im Chunk-Text vorkommen.
Hier ist der Chunk, den dieser Ansatz für unsere Abfrage erzeugt hat:
Der Header teilt uns genau mit, wo sich dieser Code befindet: utils/uc_state/state_manager.py → class UCState: → def clear_all(...). Wenn dieser Chunk eingebettet wird, hat er eine stärkere semantische Verbindung zu Abfragen nach „UCState“, „clear_all“ oder „deletion order“.
Zu diesem Zeitpunkt hatten wir einige Vorstellungen davon, welche Methoden in unserem Knowledge Assistant wahrscheinlich am besten funktionieren würden. Aber um sicher zu sein, mussten wir eine systematische Auswertung durchführen.
Evaluierungsaufbau mit MLflow
Das GenAI-Evaluierungsframework von MLflow bietet ein vollständiges Toolkit zum Vergleichen von LLMs, Agents und Retrieval-Systemen. Sie geben ihm einen Evaluationsdatensatz, eine Vorhersagefunktion und LLM-Richter, und es durchläuft jede Frage Ihre Pipeline und bewertet die Ergebnisse. Hier ist, wie wir es verwendet haben, um die drei Aufteilungsmethoden zu vergleichen.
Der Evaluationsdatensatz
Wir haben 46 Fragen zu einer Vielzahl von Kategorien erstellt, die von allgemeinen konzeptionellen Themen bis hin zu detaillierten Abfragen zum Code reichen.
| Kategorie | Anzahl | Beispiel |
|---|---|---|
| Identifizierung spezifischer Werte | 7 | „Was ist die genaue Löschreihenfolge in UCState.clear_all()?“ |
| Abrufen vollständiger Definitionen | 8 | „Listen Sie alle Felder und Validatoren im ComplaintResponse-Modell auf.“ |
| Verständnis von Systemflüssen | 6 | „Wie funktioniert die Beschwerdepipeline Ende-zu-Ende, von der Generierung bis zur Lakebase-Synchronisierung?“ |
| Vergleich von App-Implementierungen | 13 | „Wie unterscheidet sich parse_agent_response zwischen complaints-manager und refund-manager?“ |
| Vergleich von Frameworks & Mustern | 12 | „Welches ML-Framework verwendet jeder Agent? Wie unterscheiden sich ihre Fehlerbehandlungs- und Streaming-Muster?“ |
Wir haben den Datensatz bewusst auf Disambiguierungsfragen ausgerichtet, bei denen die Codebasis strukturell ähnlichen Code in verschiedenen Kontexten aufweist, wie z. B. zwei Apps mit überlappenden Funktionsnamen, parallele Datenbankschemata oder Konfigurationsdateien, die sich auf subtile Weise unterscheiden. Dies sind die Abfragen, die Schwächen bei der Aufteilung am deutlichsten aufzeigen. Wenn Ihren Chunks Metadaten darüber fehlen, wo sich der Code befindet, wird das Retrieval-System Schwierigkeiten haben, zwischen ähnlichen Klassen und Funktionen zu unterscheiden, die in verschiedenen Kontexten existieren.
Die LLM-Richter
Wir haben drei Haupt-LLM-Richter verwendet, die jeweils einen anderen Qualitätsaspekt erfassen:
RetrievalSufficiency(integriert): Enthalten die abgerufenen Chunks genügend Informationen, um die Frage zu beantworten? Dies ist die Schlüsselmetrik für den Vergleich von Aufteilungsstrategien, da sie die Retrieval-Qualität unabhängig von der Generierung misst.RetrievalGroundedness(integriert): Ist die Antwort im abgerufenen Kontext verankert, oder werden Informationen eingeführt, die nicht in den Chunks vorhanden sind?answer_correctness(benutzerdefiniert): Dieser benutzerdefinierte Scorer bewertet jede Antwort als korrekt, teilweise korrekt oder inkorrekt, was sie etwas nuancierter macht als einen strengen Ja/Nein-Korrektheitsrichter. Angesichts der Möglichkeit fragmentierter oder unvollständiger Kontexte möchten wir auf Antworten achten, denen Details fehlen oder die kleine Ungenauigkeiten aufweisen.
Ausführung der Evaluierung
Um den Vergleich fair zu halten, verwendeten alle Strategien die gleiche Ziel-Chunk-Größe (1.000 Zeichen), den gleichen Überlapp (200 Zeichen) und das gleiche Embedding-Modell (databricks-gte-large-en). In der Praxis unterscheiden sich die endgültigen Chunk-Größen immer noch (z. B. kann die AST-basierte Aufteilung erweitert werden, um eine vollständige semantische Einheit zu erhalten, während sehr kleine Dateien natürlich kleine Chunks erzeugen).
Für jede Aufteilungsstrategie schrieben wir die Chunks in eine Delta-Tabelle, erstellten einen Vektor-Suchindex mit verwalteten Embeddings (unter Verwendung des databricks-gte-large-en Embedding-Modells, wie vom Databricks Knowledge Assistant gefordert) und verbanden den Index mit einem Knowledge Assistant-Endpunkt. Die Dokumentation deckt die vollständige Einrichtung ab.
Wir evaluierten jede Aufteilungsstrategie, indem wir ihren Knowledge Assistant-Endpunkt direkt abfragten. Die to_predict_fn() von MLflow wickelt einen Serving-Endpunkt als Vorhersagefunktion ein, und da Knowledge Assistants vollständige MLflow-Spuren erstellen, einschließlich Retrieval-Spans, können die integrierten Richter sowohl die abgerufenen Chunks als auch die endgültige Antwort inspizieren.
Die LLM-Richter rufen einen LLM-Richter über Databricks Model Serving auf. Wir haben databricks-claude-opus-4-6 verwendet:
Sobald die Evaluationsläufe abgeschlossen sind, können Sie im Experiment-UI von MLflow die Ergebnisse aller drei Strategien nebeneinander vergleichen:
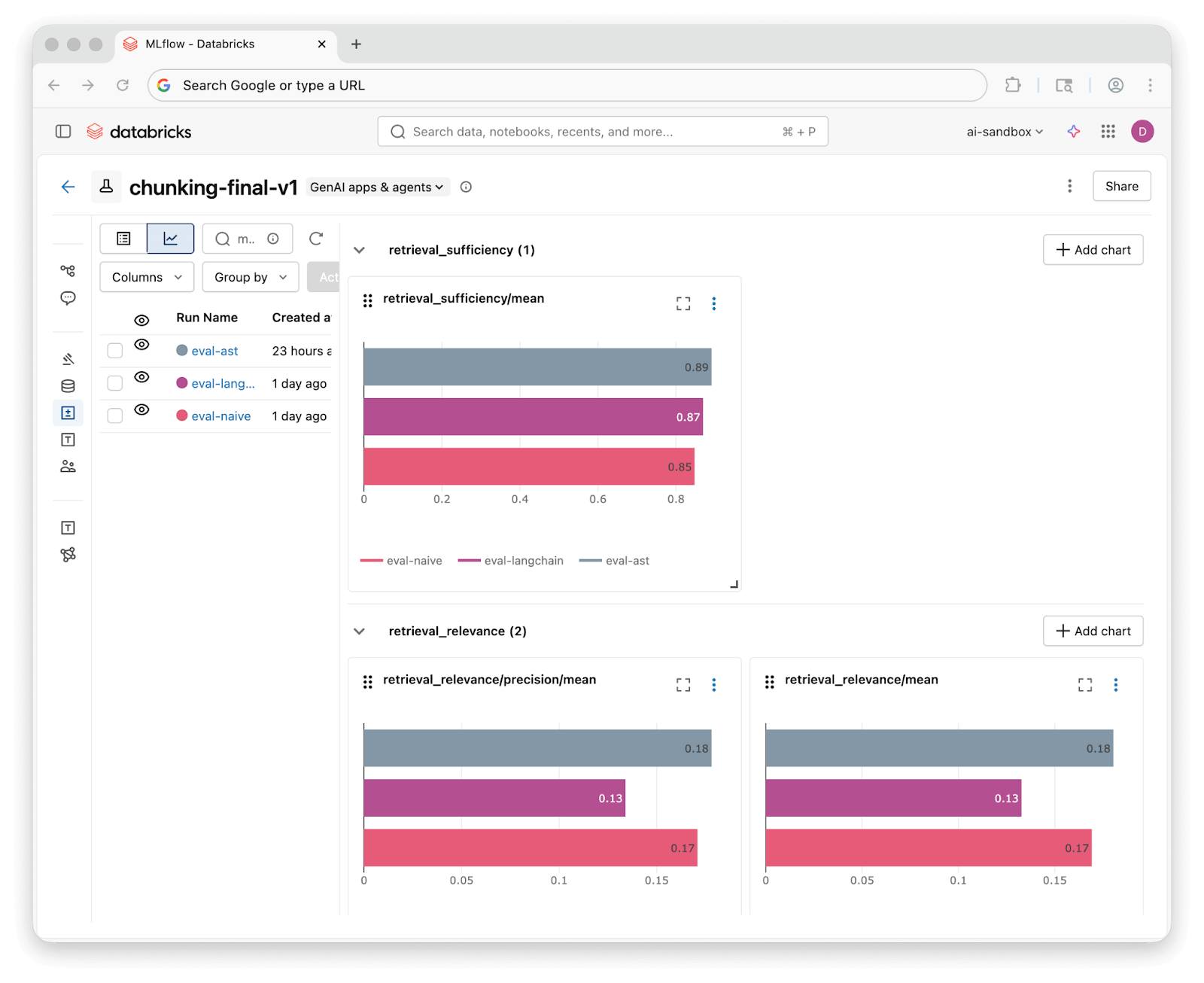
Ergebnisse und gewonnene Erkenntnisse
Wir haben alle 46 Fragen für jeden Knowledge Assistant ausgeführt und die Ergebnisse mit unseren drei Richtern bewertet. Hier ist, was wir herausgefunden haben:
| Richter | Naive | Sprachsensitiver Splitter | AST |
|---|---|---|---|
| Abrufeffizienz | 85% | 87% | 89% |
| Abruf-Fundiertheit | 76% | 72% | 76% |
| Antwortkorrektheit (benutzerdefiniert) | 59% vollständig korrekt (37% teilweise) | 61% vollständig korrekt (37% teilweise) | 70% vollständig korrekt (28% teilweise) |
Alle drei Strategien erreichen eine Abrufeffizienz von über 85 %, was bedeutet, dass die Retrieval-Techniken des Knowledge Assistant relevante Kontexte finden, unabhängig davon, wie der Code aufgeteilt wurde. Die Unterschiede auf Abrufebene sind gering.
Die Ergebnisse der benutzerdefinierten Korrektheit erzählen die interessantere Geschichte. Die AST-basierte Aufteilung liefert in 70 % der Fälle eine vollständig korrekte Antwort, verglichen mit 59 % bei Naive und 61 % bei Sprachsensitiv. Alle drei Strategien liefern in fast allen Fällen mindestens eine teilweise korrekte Antwort. Bessere Chunks helfen dem Knowledge Assistant, Fragen vollständiger zu beantworten.
Der Vorteil konzentriert sich auf bestimmte Fragetypen. Die AST-basierte Aufteilung war bei Disambiguierungsfragen, bei denen strukturell ähnlicher Code über Module hinweg existiert, aufgrund der vorangestellten Metadaten (Dateipfad, Klasse, Funktionsname), die den notwendigen Kontext liefern, hervorragend. Alle drei Strategien waren bei Wertabfragen und der vollständigen Abrufung von Definitionen vergleichbar.
MLflow Traces machen es einfach, einzelne Fragen zu untersuchen und genau zu sehen, welche Chunks abgerufen wurden und wo sich die Antworten unterschieden:
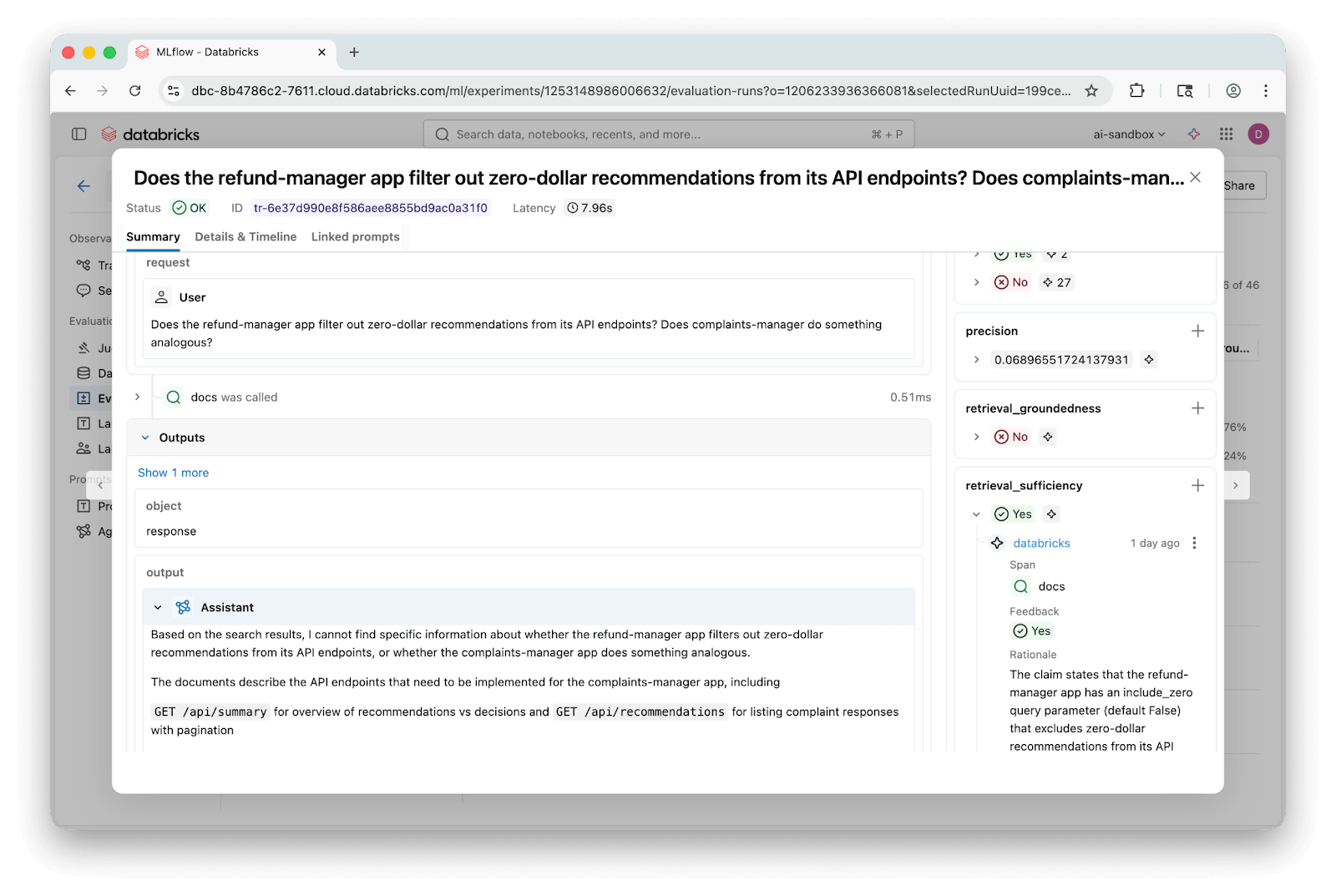
Diese Untersuchung ließ einige Fragen unbeantwortet: Waren die Verbesserungen, die wir bei der AST-basierten Aufteilung sahen, hauptsächlich eine Folge der größeren durchschnittlichen Chunk-Größen? Wie stark hingen die Ergebnisse von der Wahl des Modells ab, das die LLM-Richter antreibt? Haben unsere Evaluationsfragen wichtige Kategorien übersehen, die echte Benutzer stellen würden?
Gelernte Lektionen
Der Databricks Knowledge Assistant ist sofort einsatzbereit und sehr leistungsfähig. Die Abrufeffizienz war bei allen drei Strategien hoch, und fast jede Frage wurde mindestens teilweise korrekt beantwortet.
Die Datenvorbereitung ist immer noch wichtig. Die AST-basierte Aufteilung verbesserte die Fundiertheit und Korrektheit in dieser Auswertung, insbesondere bei Fragen, die die Unterscheidung ähnlichen Codes betrafen. Selbst geringfügige Verbesserungen bei der Abruf- und Antwortqualität summieren sich bei einem Team von Entwicklern, die Dutzende von Fragen pro Tag stellen.
Benutzerdefinierte LLM-Richter helfen, das zu messen, was uns wirklich wichtig ist. Die make_judge() API von MLflow erleichtert die Erstellung von anwendungsfallspezifischen LLM-Richtern. Unser benutzerdefinierter answer_correctness-Richter konnte eine differenziertere Sicht auf die Korrektheit geben als ein einfacher Pass/Fail-Korrektheitsrichter.
MLflow Traces vereinfachen die Evaluationsschleife. Sie können einzelne Fragen untersuchen, um genau zu sehen, welche Chunks abgerufen wurden und wo die Antwort falsch war. Da Traces persistent sind, können Sie mit verschiedenen Richtern neu bewerten, ohne den Endpunkt erneut abfragen zu müssen.
Referenzen
- Databricks Agent Bricks: Knowledge Assistant—Einrichtungsanleitung für die Erstellung eines Knowledge Assistant mit benutzerdefinierten Vektorsuchindizes.
- MLflow GenAI-Evaluierungsframework—Dokumentation für
mlflow.genai.evaluate(), integrierte LLM-Richter und die API für benutzerdefinierte Scorer. - cAST: Enhancing Code Retrieval-Augmented Generation with Structural Chunking via Abstract Syntax Tree—Das Paper, das unseren Ansatz für die AST-basierte Aufteilung motiviert hat, mit Benchmarks für mehrere Code-RAG-Aufgaben. Wir haben die Python-Bibliothek ASTChunk implementiert.
- LangChain
RecursiveCharacterTextSplitter—API-Referenz für den sprachsensitiven Text-Splitter, den wir in dem Vergleich verwendet haben.
Probieren Sie es selbst aus
Sie können diese Demo im Casper’s Kitchens Repo nachvollziehen. Egal, ob Sie Chunking-Strategien für Ihren eigenen Code auswerten oder andere RAG-Verbesserungen untersuchen, dieses Evaluationsframework bietet Ihnen eine reproduzierbare Möglichkeit, Ansätze zu vergleichen.
- Erstellen Sie einen Evaluationsdatensatz mit Fragen und erwarteten Antworten.
- Implementieren Sie Chunking-Strategien (oder verwenden Sie unsere als Ausgangspunkt).
- Richten Sie MLflow LLM-Richter ein – beginnen Sie mit den integrierten Optionen und fügen Sie benutzerdefinierte hinzu, wenn Sie Lücken finden.
- Führen Sie Auswertungen mit frischen Indizes für jede Strategie durch.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.