Instructed Retriever: Erschließung von Schlussfolgerungen auf Systemebene in Such-Agenten
Abrufsbasierte Agenten sind das Kernstück vieler geschäftskritischer Unternehmensanwendungen. Unternehmenskunden erwarten von ihnen, dass sie schlussfolgernde Tasks ausführen, die die Befolgung spezifischer Benutzeranweisungen und den effektiven Einsatz über heterogene Wissensquellen hinweg erfordern. Allerdings scheitert die traditionelle Retrieval Augmented Generation (RAG) häufig daran, feingranulare Benutzerabsichten und Spezifikationen von Wissensquellen in präzise Suchanfragen zu übersetzen. Die meisten bestehenden Lösungen ignorieren dieses Problem praktisch und setzen auf handelsübliche Suchwerkzeuge. Andere unterschätzen die Herausforderung drastisch und verlassen sich ausschließlich auf benutzerdefinierte Modelle für Einbettung und Neusortierung, die in ihrer Ausdruckskraft grundlegend begrenzt sind. In diesem Blog stellen wir den Instructed Retriever vor – eine neuartige Abrufarchitektur, die die Einschränkungen von RAG überwindet und die Suche für die Agenten-Ära neu gestaltet. Anschließend veranschaulichen wir, wie diese Architektur leistungsfähigere abrufsbasierte Agenten ermöglicht, einschließlich Systemen wie Agent Bricks: Knowledge Assistant, die über komplexe Unternehmensdaten schlussfolgern und Benutzeranweisungen strikt einhalten müssen.
Betrachten wir beispielsweise ein Beispiel aus Abbildung 1, in dem ein Nutzer nach der Akkulaufzeit eines fiktiven FooBrand-Produkts fragt. Darüber hinaus enthalten die Systemspezifikationen Anweisungen zur Aktualität, zu den zu berücksichtigenden Dokumenttypen und zur Antwortlänge. Um die Systemspezifikationen korrekt zu befolgen, muss die Nutzeranfrage zunächst in strukturierte Suchanfragen übersetzt werden, die zusätzlich zu den Keywords die entsprechenden Spaltenfilter enthalten. Anschließend muss eine prägnante, auf den Abfrageergebnissen basierende Antwort auf Grundlage der Nutzeranweisungen generiert werden. Ein solch komplexes und gezieltes Befolgen von Anweisungen ist mit einer einfachen Retrieval-Pipeline, die sich ausschließlich auf die Nutzeranfrage konzentriert, nicht zu erreichen.
![Abbildung 1. Beispiel für den instructed Retrieval-Workflow für die Abfrage [Wie hoch ist die erwartete Akkulaufzeit für FooBrand-Produkte?]. Benutzeranweisungen werden übersetzt in (a) zwei strukturierte Retrieval-Abfragen, die sowohl aktuelle Rezensionen als auch eine offizielle Produktbeschreibung abrufen, und (b) eine kurze Antwort, die auf den Suchergebnissen basiert.](https://www.databricks.com/sites/default/files/inline-images/image7_24.png)
Herkömmliche RAG-Pipelines beruhen auf einem einstufigen Abruf, der ausschließlich die Nutzerabfrage verwendet, und beziehen keine zusätzlichen Systemspezifikationen wie spezifische Anweisungen, Beispiele oder Schemata von Wissensquellen mit ein. Wie wir jedoch in Abbildung 1 zeigen, sind diese Spezifikationen für die erfolgreiche Befolgung von Anweisungen in agentenbasierten Suchsystemen entscheidend. Um diese Einschränkungen zu überwinden und Tasks wie die in Abbildung 1 beschriebene erfolgreich abzuschließen, ermöglicht unsere Instructed-Retriever-Architektur den Fluss von Systemspezifikationen in jede der Systemkomponenten.
Auch über RAG hinaus sind in fortschrittlicheren agentenbasierten Suchsystemen, die eine iterative Suchausführung ermöglichen, die Befolgung von Anweisungen und das Verständnis der zugrunde liegenden Schemata von Wissensquellen entscheidende Fähigkeiten, die nicht erschlossen werden können, indem RAG lediglich als Werkzeug für mehrere Schritte ausgeführt wird, wie Tabelle 1 veranschaulicht. Somit bietet die Architektur des Instructed Retriever eine hochleistungsfähige Alternative zu RAG, wenn eine niedrige Latenz und ein geringer Modell-Footprint erforderlich sind, und ermöglicht gleichzeitig effektivere Such-Agents für Szenarien wie tiefgehende Recherchen.
Retrieval Augmented Generation (RAG) | Instructed Retriever | Mehrstufiger Agent (RAG) | Mehrschrittiger Agent (Instructed Retriever) | |
Anzahl der Suchschritte | Einzeln | Einzeln | Mehrere | Mehrere |
Fähigkeit, Anweisungen zu befolgen | ✖️ | ✅ | ✖️ | ✅ |
Verständnis der Wissensquelle | ✖️ | ✅ | ✖️ | ✅ |
Niedrige Latenz | ✅ | ✅ | ✖️ | ✖️ |
Kleiner Modell-Footprint | ✅ | ✅ | ✖️ | ✖️ |
Schlussfolgern über Ausgaben | ✖️ | ✖️ | ✅ | ✅ |
Tabelle 1. Eine Zusammenfassung der Fähigkeiten von traditionellem RAG, Instructed Retriever und einem mehrstufigen Suchagenten, der mit einem der beiden Ansätze als Werkzeug implementiert ist
Um die Vorteile des Instructed Retrievers zu demonstrieren, zeigt Abbildung 2 seine Performance im Vergleich zu RAG-basierten Baselines auf einer Reihe von Datasets zum Question Answering im Unternehmensbereich1. Bei diesen komplexen Benchmarks steigert der Instructed Retriever die Performance um mehr als 70 % im Vergleich zum herkömmlichen RAG. Der Instructed Retriever übertrifft sogar einen RAG-basierten, mehrstufigen Agenten um 10 %. Die Einbindung als Tool in einen mehrstufigen Agenten bringt zusätzliche Vorteile und reduziert gleichzeitig die Anzahl der Ausführungsschritte im Vergleich zu RAG.
Im weiteren Verlauf des Blogposts besprechen wir das Design und die Implementierung dieser neuartigen Instructed-Retriever-Architektur. Wir zeigen, dass der Instructed Retriever in der Phase der Query-Generierung zu einer präzisen und robusten Befolgung von Anweisungen führt, was zu signifikanten Verbesserungen des Retrieval-Recalls führt. Darüber hinaus zeigen wir, dass diese Fähigkeiten zur Abfrageerstellung sogar in kleinen Modellen durch Offline-Reinforcement-Learning freigeschaltet werden können. Schließlich schlüsseln wir die End-to-End-Performance des Instructed Retrievers sowohl in einstufigen als auch in mehrstufigen agentenbasierten Setups weiter auf. Wir zeigen, dass er im Vergleich zu herkömmlichen RAG-Architekturen konsistent signifikante Verbesserungen der Antwortqualität ermöglicht.
Instructed Retriever-Architektur
Um die Herausforderungen des Schlussfolgerns auf Systemebene in agentenbasierten Abrufsystemen zu bewältigen, schlagen wir eine neuartige Architektur namens Instructed Retriever vor, die in Abbildung 3 dargestellt ist. Der Instructed Retriever kann entweder in einem statischen Workflow aufgerufen oder einem Agenten als Tool zur Verfügung gestellt werden. Die wichtigste Neuerung ist, dass diese neue Architektur eine optimierte Möglichkeit bietet, nicht nur die unmittelbare Abfrage des Nutzers zu bearbeiten, sondern auch die gesamten Systemspezifikationen an die Komponenten des Abruf- und Generierungssystems weiterzugeben. Dies ist eine grundlegende Abkehr von herkömmlichen RAG-Pipelines, bei denen Systemspezifikationen (bestenfalls) die ursprüngliche Abfrage beeinflussen, dann aber verloren gehen, wodurch der Retriever und der Antwortgenerator gezwungen sind, ohne den entscheidenden Kontext dieser Spezifikationen zu arbeiten.
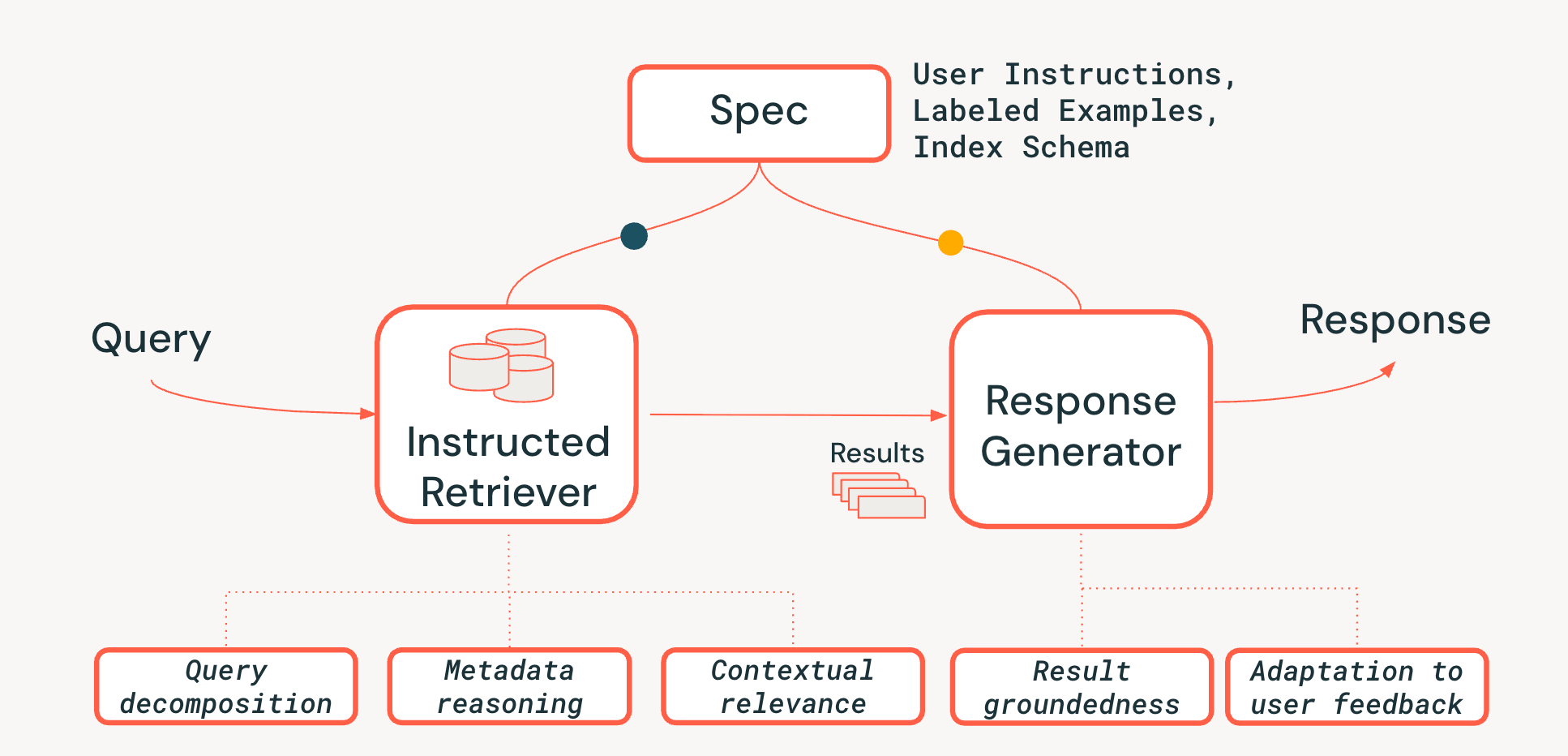
Systemspezifikationen sind somit eine Reihe von Leitprinzipien und Anweisungen, die der Agent befolgen muss, um die Nutzeranfrage zuverlässig zu erfüllen. Dazu kann Folgendes gehören:
- Benutzeranweisungen: Allgemeine Präferenzen oder Einschränkungen, wie "Fokus auf Rezensionen der letzten Jahre" oder "Keine FooBrand-Produkte in den Ergebnissen anzeigen".
- Gelabelte Beispiele: Konkrete Beispiele für relevante/nicht relevante <query, document> -Paare, die dabei helfen zu definieren, wie ein hochwertiger, anweisungskonformer Abruf für eine bestimmte Task aussieht.
- Indexbeschreibungen: Ein Schema, das dem Agenten mitteilt, welche Metadaten zum Abrufen tatsächlich verfügbar sind (z. B. product_brand, doc_timestamp, im Beispiel in Abbildung 1).2
Um die Persistenz von Spezifikationen in der gesamten Pipeline zu ermöglichen, fügen wir dem Retrieval-Prozess drei entscheidende Fähigkeiten hinzu:
- Abfragedekomposition: Die Fähigkeit, eine komplexe, mehrteilige Abfrage („Finde mir ein FooBrand-Produkt, aber nur aus dem letzten Jahr und kein ‚Lite‘-Modell“) in einen vollständigen Suchplan zu zerlegen, der mehrere Schlagwort-Suchen und Filteranweisungen enthält.
- Kontextuelle Relevanz: Über die reine Textähnlichkeit hinaus zu einem echten Verständnis der Relevanz im Kontext von Abfrage- und Systemanweisungen. Das bedeutet, dass der Re-Ranker beispielsweise die Anweisungen verwenden kann, um Dokumente zu priorisieren, die der Absicht des Benutzers entsprechen (z. B. "Aktualität"), selbst wenn die Schlagwörter eine schwächere Übereinstimmung aufweisen.
- Metadaten-Reasoning: Eines der wichtigsten Unterscheidungsmerkmale unserer Instructed Retriever-Architektur ist die Fähigkeit, Anweisungen in natürlicher Sprache ("vom letzten Jahr") in präzise, ausführbare Suchfilter ("doc_timestamp > TO_TIMESTAMP('2024-11-01')") zu übersetzen.
Wir stellen außerdem sicher, dass die Phase der Antwortgenerierung mit den abgerufenen Ergebnissen, den Systemspezifikationen und dem bisherigen Nutzerverlauf oder Feedback übereinstimmt (wie in diesem Blog ausführlicher beschrieben).
Die Einhaltung von Anweisungen bei Suchagenten ist eine Herausforderung, da der Informationsbedarf der Nutzer komplex, vage oder sogar widersprüchlich sein kann und sich oft über viele Runden von Feedback in natürlicher Sprache ansammeln. Der Retriever muss außerdem schemabewusst sein – also in der Lage sein, die Sprache des Nutzers in strukturierte Filter, Felder und Metadaten zu übersetzen, die tatsächlich im Index vorhanden sind. Schließlich müssen die Komponenten nahtlos zusammenarbeiten, um diese komplexen, manchmal vielschichtigen Einschränkungen zu erfüllen, ohne eine davon zu übersehen oder falsch zu interpretieren. Eine solche Koordination erfordert ein ganzheitliches logisches Denken auf Systemebene. Wie unsere Experimente in den nächsten beiden Abschnitten zeigen, stellt die Instructed Retriever-Architektur einen wichtigen Fortschritt dar, um diese Fähigkeit in Suchworkflows und bei Agenten zu ermöglichen.
Evaluierung der Anweisungsbefolgung bei der Abfrage-Generierung
Die meisten bestehenden Retrieval-Benchmarks berücksichtigen nicht, wie Modelle Spezifikationen in natürlicher Sprache interpretieren und ausführen, insbesondere solche, die strukturierte Einschränkungen auf der Grundlage des Indexschemas beinhalten. Um die Fähigkeiten unserer Instructed Retriever-Architektur zu bewerten, haben wir daher das StaRK -Dataset (Semi-Structured Retrieval Benchmark) erweitert und einen neuen Retrieval-Benchmark für die Befolgung von Anweisungen, StaRK-Instruct, entwickelt, wobei wir dessen E-Commerce -Untergruppe, STaRK-Amazon, verwenden.
Für unser Dataset konzentrieren wir uns auf drei gängige Arten von Nutzeranweisungen, die vom Modell verlangen, über die reine Textähnlichkeit hinaus zu schlussfolgern:
- Einschlussanweisungen – Auswählen von Dokumenten, die ein bestimmtes Attribut enthalten müssen (z. B. „Finde eine Jacke von FooBrand, die für kaltes Wetter am besten bewertet ist“).
- Ausschlussanweisungen – Herausfiltern von Elementen, die nicht in den Ergebnissen erscheinen sollen (z. B. “empfiehl einen kraftstoffsparenden SUV, aber ich habe schlechte Erfahrungen mit FooBrand gemacht, also vermeide alles, was sie herstellen”).
- Recency-Boosting – Bevorzugung neuerer Elemente, wenn zeitbezogene Metadaten verfügbar sind (z. B. „Welche FooBrand-Laptops sind gut gealtert? Priorisieren Sie Bewertungen aus den letzten 2–3 Jahren – ältere Bewertungen sind aufgrund von Betriebssystemänderungen weniger relevant“).
Um StaRK-Instruct zu erstellen und dabei die vorhandenen Relevanzbeurteilungen von StaRK-Amazon wiederzuverwenden, folgten wir früheren Arbeiten zum Thema Instruction Following im Information Retrieval. Dabei haben wir die bestehenden Anfragen durch zusätzliche Einschränkungen, die die Relevanzdefinitionen eingrenzen, zu spezifischeren Anfragen synthetisiert. Die relevanten Dokumentensätze werden dann programmatisch gefiltert, um die Übereinstimmung mit den umgeschriebenen Anfragen sicherzustellen. Durch diesen Prozess synthetisierten wir 81 StaRK-Amazon-Anfragen (19,5 relevante Dokumente pro Anfrage) zu 198 Anfragen in StaRK-Instruct (11,7 relevante Dokumente pro Anfrage, über die drei Anweisungstypen hinweg).
Um die Query-Generierung-Fähigkeiten von Instructed Retriever mithilfe von StaRK-Instruct zu evaluieren, evaluieren wir die folgenden Methoden (in einem einstufigen Retrieval-Setup).
- Raw Query – Als Baseline verwenden wir die ursprüngliche Nutzer-Query für das Retrieval, ohne zusätzliche Phasen zur Generierung von Abfragen. Dies ähnelt einem herkömmlichen RAG-Ansatz.
- GPT5-nano, GPT5.2, Claude4.5-Sonnet – wir verwenden jedes der entsprechenden Modelle, um eine Retrieval-Query zu generieren, wobei wir sowohl die ursprünglichen Benutzerabfragen, Systemspezifikationen einschließlich Benutzeranweisungen als auch das Indexschema verwenden.
- InstructedRetriever-4B – Obwohl Spitzenmodelle wie GPT5.2 und Claude4.5-Sonnet hochwirksam sind, können sie für Tasks wie die Generierung von Queries und Filtern, insbesondere bei groß angelegten Implementierungen, zu teuer sein. Daher wenden wir den Mechanismus der Test-time Adaptive Optimization (TAO) an, der Test-time Compute und Offline Reinforcement Learning (RL) nutzt, um einem Modell beizubringen, eine Task anhand früherer Eingabebeispiele besser zu erledigen. Konkret verwenden wir die „synthetisierte“ Query-Teilmenge aus StaRK-Amazon und generieren zusätzliche, Anweisungen befolgende Queries mithilfe dieser synthetisierten Queries. Wir verwenden den Recall direkt als Belohnungssignal, um ein kleines Modell mit 4 Mrd. Parametern feinabzustimmen, indem wir Stichproben von Kandidaten-Tool-Aufrufen nehmen und diejenigen verstärken, die höhere Recall-Werte erzielen.
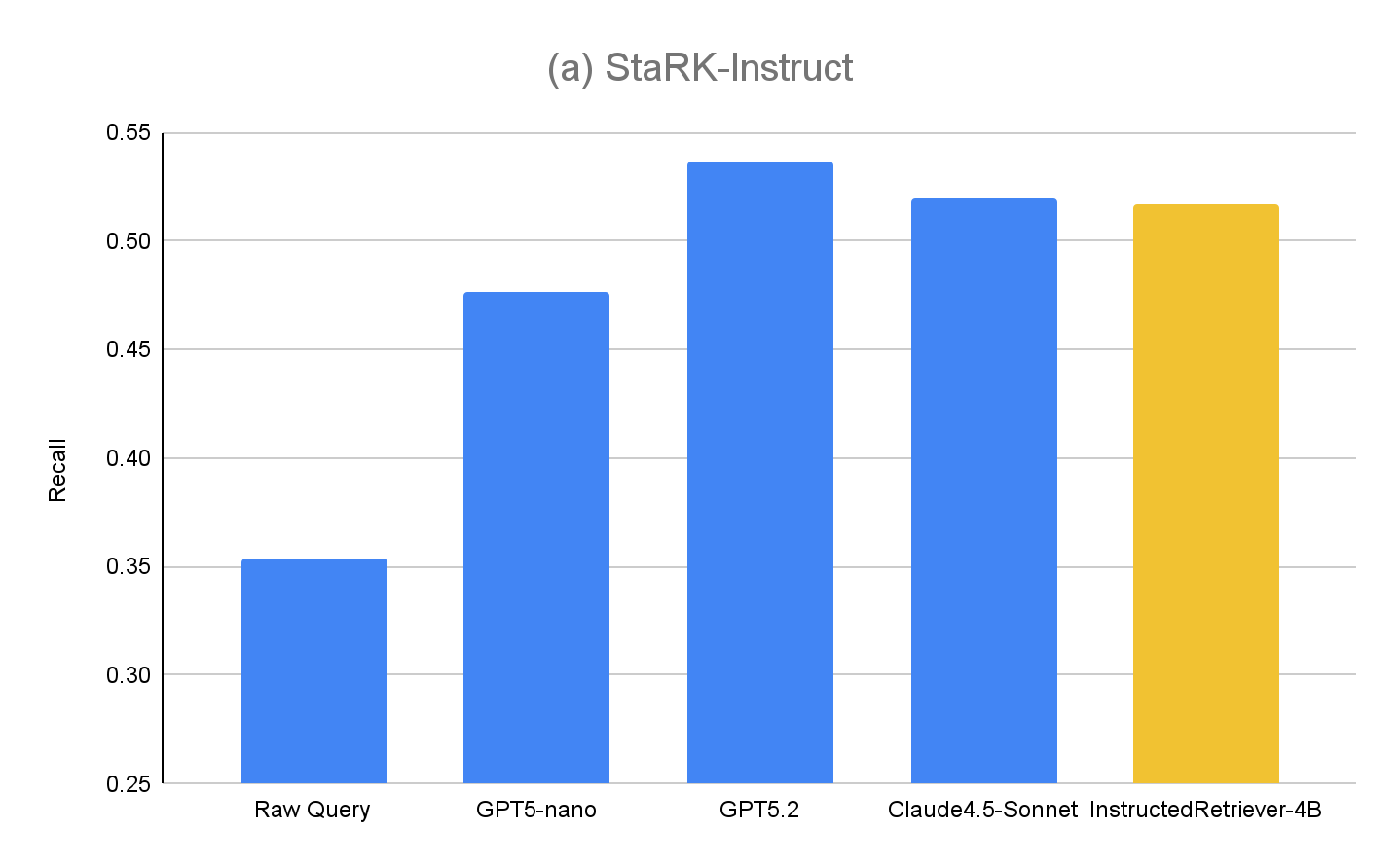
Die Ergebnisse für StaRK-Instruct sind in Abbildung 4(a) dargestellt. Die instruktionsbasierte Anfragegenerierung erzielt einen um 35–50 % höheren Recall im StaRK-Instruct-Benchmark im Vergleich zur Roh-Query -Baseline. Die Zuwächse sind über alle Modellgrößen hinweg konsistent, was bestätigt, dass effektives Parsen von Anweisungen und die Formulierung strukturierter Anfragen selbst bei knappen Rechenbudgets messbare Verbesserungen liefern können. Größere Modelle zeigen im Allgemeinen weitere Zuwächse, was auf die Skalierbarkeit des Ansatzes mit der Modellkapazität hindeutet. Unser feingetuntes InstructedRetriever-4B -Modell erreicht jedoch fast die Performance wesentlich größerer Frontier-Modelle und übertrifft das GPT5-nano -Modell. Das zeigt, dass Alignment die Effektivität des Instruction Following in agentenbasierten Retrieval-Systemen selbst bei kleineren Modellen erheblich steigern kann.
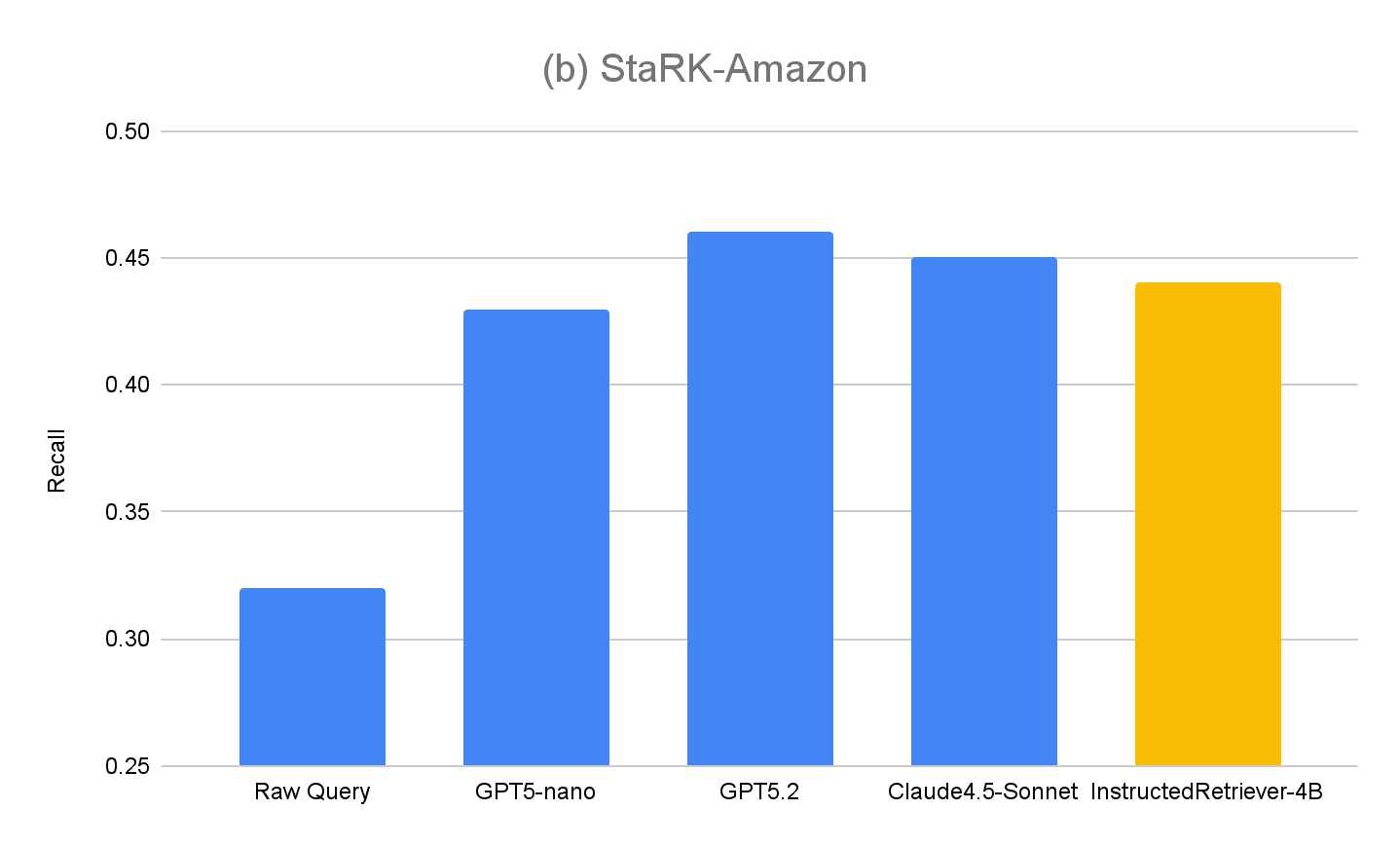
Um die Generalisierung unseres Ansatzes weiter zu bewerten, messen wir auch die Performance auf dem ursprünglichen Evaluierungssatz StaRK-Amazon, bei dem Queries keine expliziten metadatenbezogenen Anweisungen enthalten. Wie in Abbildung 4(b) gezeigt, übertreffen alle instruktionsbasierten Querygenerierungsmethoden den Recall von Raw Query auf StaRK-Amazon um rund 10 %, was bestätigt, dass die Befolgung von Anweisungen auch in uneingeschränkten Szenarien der Querygenerierung von Vorteil ist. Wir sehen auch keine Verschlechterung der Performance von InstructedRetriever-4B im Vergleich zu nicht feinabgestimmten Modellen, was bestätigt, dass die Spezialisierung auf die strukturierte Querygenerierung die allgemeinen Fähigkeiten zur Querygenerierung nicht beeinträchtigt.
Bereitstellung von Instructed Retriever in Agent Bricks
Im vorherigen Abschnitt haben wir die signifikanten Verbesserungen bei der Retrieval-Qualität demonstriert, die durch eine anweisungsfolgende Abfragegenerierung erzielt werden können. In diesem Abschnitt untersuchen wir die Nützlichkeit eines Instructed Retrievers als Teil eines produktionsreifen, agentenbasierten Retrieval-Systems genauer. Insbesondere wird der Instructed Retriever im Agent Bricks Knowledge Assistant angewendet, einem QA-Chatbot, mit dem Sie Fragen stellen und zuverlässige Antworten auf der Grundlage des bereitgestellten domänenspezifischen Wissens erhalten können.
Wir betrachten zwei DIY-RAG-Lösungen als Baselines:
- RAG Wir speisen die besten abgerufenen Ergebnisse unserer hochleistungsfähigen Vektorsuche zur Generierung in ein großes Spitzen-Sprachmodell ein.
- RAG + Rerank Wir lassen auf die Abrufphase eine Reranking-Phase folgen, die die Abrufgenauigkeit in früheren Tests nachweislich um durchschnittlich 15 Prozentpunkte steigerte. Die neu geordneten Ergebnisse werden zur Generierung an ein führendes Large Language Model übergeben.
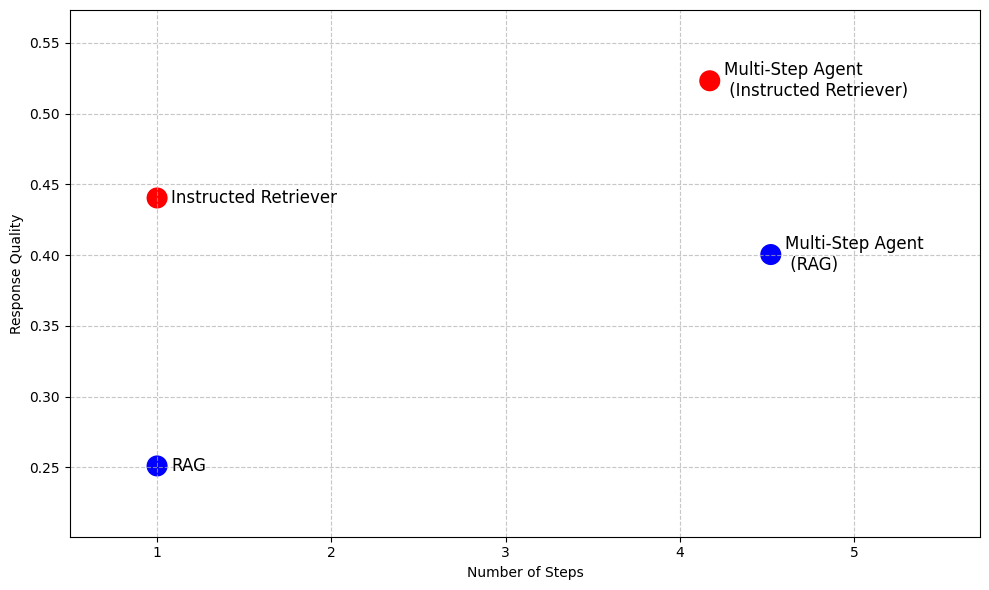
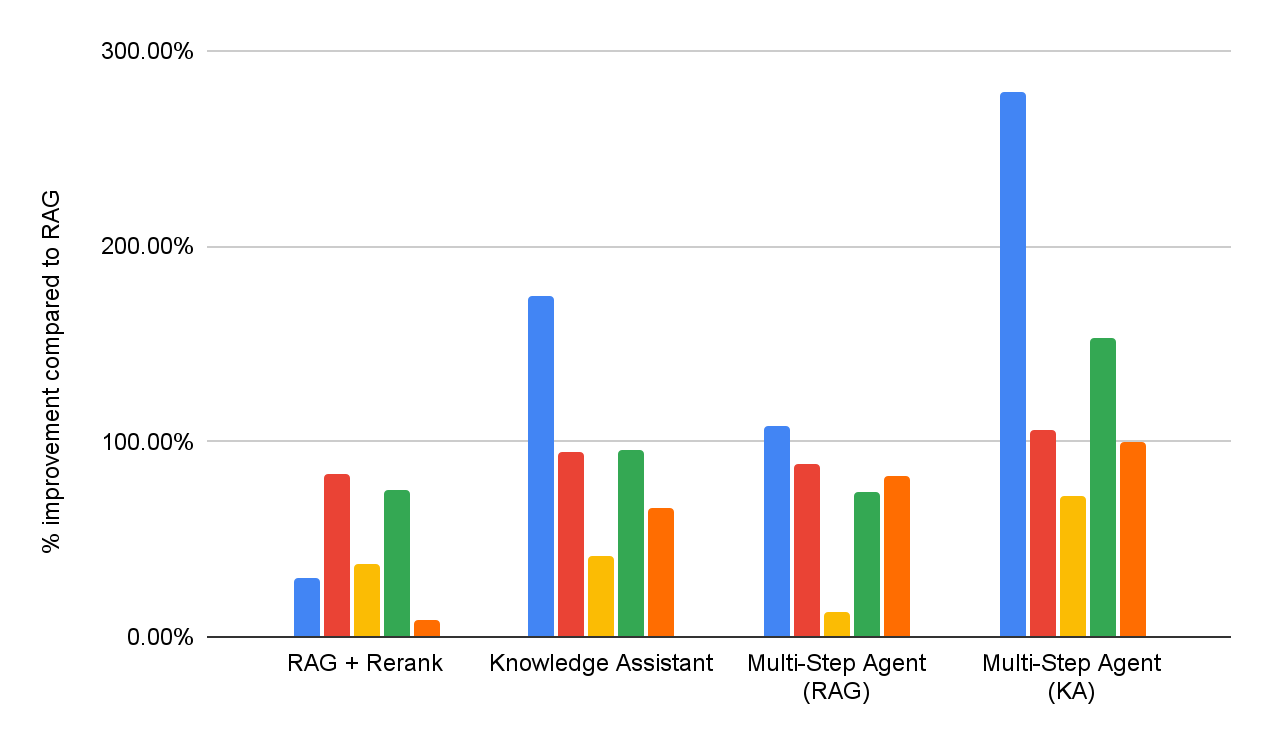
Um die Wirksamkeit sowohl der DIY-RAG-Lösungen als auch des Knowledge Assistant zu bewerten, führen wir eine Bewertung der Antwortqualität für dieselbe Benchmark-Suite für Question-Answering in Unternehmen durch, wie in Abbildung 1 dargestellt. Darüber hinaus implementieren wir zwei mehrstufige Agenten, die jeweils entweder auf RAG oder den Knowledge Assistant als Suchwerkzeug zugreifen können. Die detaillierte Performance für jedes Dataset ist in Abbildung 5 dargestellt (als prozentuale Verbesserung im Vergleich zur RAG -Baseline).
Insgesamt lässt sich feststellen, dass alle Systeme die einfache RAG-Baseline in allen Datensätzen durchgängig übertreffen, was deren Unfähigkeit widerspiegelt, mehrteilige Spezifikationen zu interpretieren und konsistent durchzusetzen. Das Hinzufügen einer Reranking-Phase verbessert die Ergebnisse und zeigt den Nutzen einer nachträglichen Relevanzmodellierung. Der Knowledge Assistant, der mit der Instructed-Retriever-Architektur implementiert wurde, bringt weitere Verbesserungen, was die Bedeutung unterstreicht, die Systemspezifikationen – Einschränkungen, Ausschlüsse, zeitliche Präferenzen und Metadatenfilter – in jeder Phase des Abrufs und der Generierung beizubehalten.
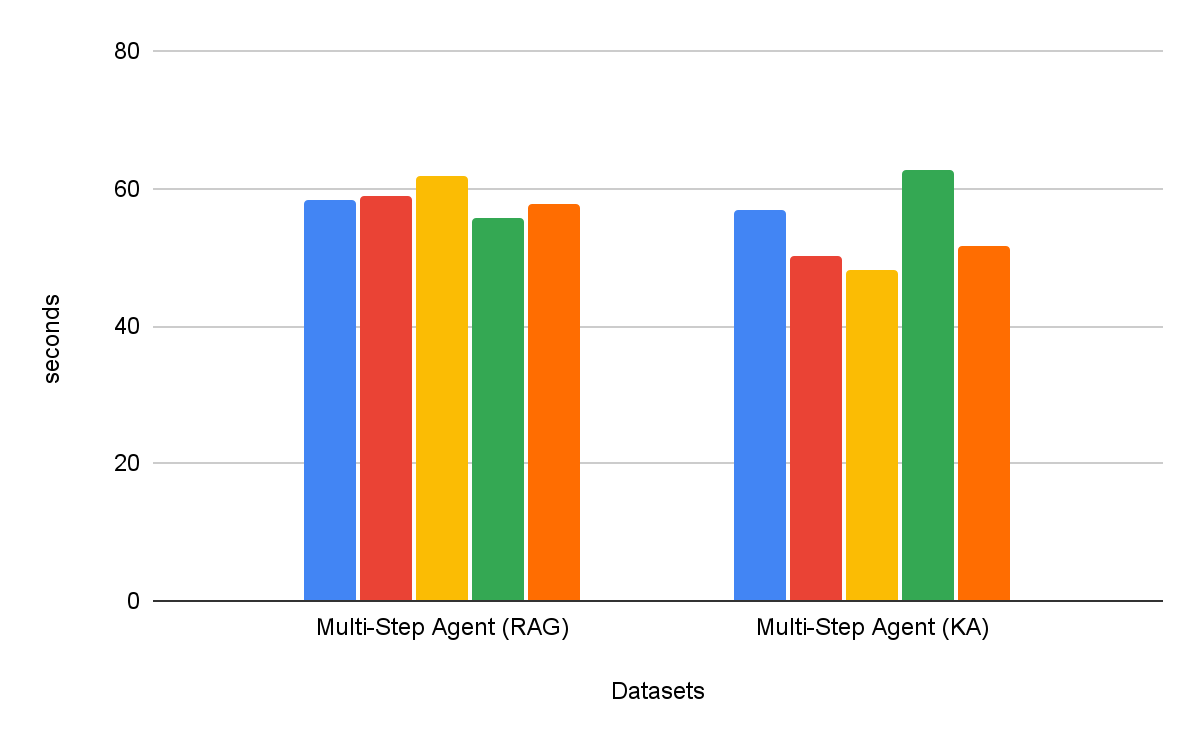
Mehrstufige Suchagenten sind durchweg effektiver als einstufige Retrieval-Workflows. Darüber hinaus ist die Wahl des Tools entscheidend: Knowledge Assistant als Tool übertrifft RAG als Tool um über 30 %, mit einer konsistenten Verbesserung über alle Datensätze hinweg. Interessanterweise verbessert es nicht nur die Qualität, sondern verkürzt in den meisten Datensätzen auch die Zeit bis zum Abschluss der Task, mit einer durchschnittlichen Reduzierung von 8 % (Abbildung 6).
Fazit
Die Erstellung zuverlässiger Unternehmens-Agenten erfordert eine umfassende Befolgung von Anweisungen und logisches Denken auf Systemebene beim Abrufen von Daten aus heterogenen Wissensquellen. Zu diesem Zweck stellen wir in diesem Blog die Instructed-Retriever -Architektur vor, mit der Kerninnovation, vollständige Systemspezifikationen – von Anweisungen über Beispiele bis hin zum Indexschema – durch jede Stufe der Such-Pipeline weiterzugeben.
Wir haben auch einen neuen StaRK-Instruct -Dataset vorgestellt, der die Fähigkeit eines Abrufagenten bewertet, mit realen Anweisungen wie Einschluss, Ausschluss und Aktualität umzugehen. Auf diesem Benchmark erzielte die Instructed-Retriever-Architektur eine erhebliche Steigerung des Abruf-Recalls von 35–50 %, was den Nutzen eines systemweiten Bewusstseins für Anweisungen bei der Abfrage-Generierung empirisch belegt. Wir zeigen auch, dass ein kleines, effizientes Modell optimiert werden kann, um die Performance größerer proprietärer Modelle bei der Befolgung von Anweisungen zu erreichen. Dies macht den Instructed Retriever zu einer kostengünstigen Agenten-Architektur, die für reale Unternehmensimplementierungen geeignet ist.
Bei der Integration in einen Agent Bricks Knowledge Assistant führt die Instructed Retriever-Architektur direkt zu qualitativ hochwertigeren und genaueren Antworten für den Endbenutzer. In unserer umfassenden Benchmark-Suite mit hohem Schwierigkeitsgrad liefert sie Zuwächse von über 70 % im Vergleich zu einer einfachen RAG-Lösung und eine Qualitätssteigerung von über 15 % im Vergleich zu anspruchsvolleren DIY-Lösungen, die Reranking beinhalten. Darüber hinaus kann Instructed Retriever, wenn es als Tool für einen mehrstufigen Such-Agenten integriert wird, nicht nur die Performance um über 30 % steigern, sondern auch die Zeit bis zum Abschluss der Task um 8 % verkürzen, verglichen mit RAG als Tool.
Instructed Retriever ist zusammen mit vielen zuvor veröffentlichten Innovationen wie Prompt-Optimierung, ALHF, TAO und RLVR jetzt im Agent Bricks-Produkt verfügbar. Das Kernprinzip von Agent Bricks besteht darin, Unternehmen bei der Entwicklung von Agenten zu unterstützen, die präzise Schlussfolgerungen auf Basis ihrer proprietären Daten ziehen, kontinuierlich aus Feedback lernen und bei domänenspezifischen Tasks eine Qualität und Kosteneffizienz auf dem neuesten Stand der Technik erzielen. Wir ermutigen unsere Kunden, den Knowledge Assistant und andere Agent Bricks-Produkte auszuprobieren, um steuerbare und effektive Agenten für ihre eigenen Unternehmensanwendungsfälle zu erstellen.
Autoren: Cindy Wang, Andrew Drozdov, Michael Bendersky, Wen Sun, Owen Oertell, Jonathan Chang, Jonathan Frankle, Xing Chen, Matei Zaharia, Elise Gonzales, Xiangrui Meng
1 Unsere Suite enthält eine Mischung aus fünf proprietären und akademischen Benchmarks, die die folgenden Fähigkeiten testen: Befolgung von Anweisungen, domänenspezifische Suche, Erstellung von Berichten, Erstellung von Listen und Suche in PDFs mit komplexen Layouts. Jedem Benchmark ist ein benutzerdefinierter Qualitätsprüfer zugeordnet, der auf dem Antworttyp basiert.
2 Indexbeschreibungen können in die benutzerdefinierte Anweisung aufgenommen oder automatisch durch Methoden zur Schemaverknüpfung konstruiert werden, die häufig in Systemen für Text-zu-SQL eingesetzt werden, z. B. zum Wertabruf.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.