Aufbau einer Anwendung in nahezu Echtzeit mit Zerobus Ingest und Lakebase
Erfahren Sie, wie Sie die Datenaufnahme für Anwendungsfälle in den Bereichen IoT, Clickstream und Telemetrie auf Databricks vereinfachen können.
von Grant Doyle und Benjamin Nwokeleme
- Erfahren Sie, wie Zerobus Ingest Multi-Hop-Architekturen für IoT-, Clickstream- und Telemetrie-Anwendungsfälle eliminiert
- Erfahren Sie, wie Lakebase komplexe, benutzerdefinierte ETL-Pipelines eliminiert und Transaktionsdaten für operative Anwendungsfälle integriert
- Erstellen Sie ein Nahezu-Echtzeit-Dashboard mit Zerobus Ingest, Lakebase und Databricks Apps
Ereignisdaten aus IoT, Clickstreams und Anwendungs-Telemetrie ermöglichen in Kombination mit der Databricks Data Intelligence Platform entscheidende Echtzeitanalysen und KI. Traditionell erforderte die Aufnahme dieser Daten mehrere Daten-Hops (Message-Bus, Spark-Jobs) zwischen der Datenquelle und dem Lakehouse. Dies führt zu zusätzlichem Betriebsaufwand und Datenverdopplung, erfordert spezielles Fachwissen und ist im Allgemeinen ineffizient, wenn das Lakehouse das einzige Ziel für diese Daten ist.
Sobald diese Daten im Lakehouse landen, werden sie für nachgelagerte analytische Anwendungsfälle transformiert und aufbereitet. Teams müssen diese analytischen Daten jedoch häufig für operative Anwendungsfälle bereitstellen, und die Erstellung dieser benutzerdefinierten Anwendungen kann ein aufwändiger Prozess sein. Sie müssen wesentliche Infrastrukturkomponenten wie eine dedizierte OLTP-Datenbankinstanz (mit Netzwerk, Monitoring, Backups und mehr) bereitstellen und warten. Zusätzlich müssen sie den Reverse-ETL -Prozess für die analytischen Daten in die Datenbank verwalten, um sie in der Echtzeitanwendung wieder verfügbar zu machen. Dies würde erfordern, dass das Team zusätzliche Pipelines erstellt, um Daten aus dem Lakehouse in die externe operative Datenbank zu verschieben. Diese Pipelines erweitern die Infrastruktur, die Entwickler einrichten und warten müssen, was ihre Aufmerksamkeit vom Hauptziel ablenkt: der Entwicklung der Anwendungen für ihr Unternehmen.
Wie vereinfacht Databricks also sowohl die Aufnahme von Daten in das Lakehouse als auch die Bereitstellung von Gold-Daten zur Unterstützung operativer Workloads?
Hier kommen Zerobus Ingest und Lakebase ins Spiel.
Über Zerobus Ingest
Zerobus Ingest, Teil von Lakeflow Connect, ist eine Reihe von APIs, die eine optimierte Möglichkeit bieten, Ereignisdaten direkt in das Lakehouse zu übertragen. Durch die vollständige Eliminierung der Single-Sink-Message-Bus-Schicht reduziert Zerobus Ingest die Infrastruktur, vereinfacht den Betrieb und ermöglicht die Dateningestion in nahezu Echtzeit im großen Scale. Dadurch macht es Zerobus Ingest einfacher als je zuvor, den Wert Ihrer Daten zu erschließen.
Die datenerzeugende Anwendung muss eine Zieltabelle angeben, in die Daten geschrieben werden sollen, sicherstellen, dass die Nachrichten korrekt dem Schema der Tabelle zugeordnet werden, und dann einen Stream initiieren, um Daten an Databricks zu senden. Auf der Databricks-Seite validiert die API die Schemata der Nachricht und der Tabelle, schreibt die Daten in die Zieltabelle und sendet eine Bestätigung an den Client, dass die Daten gespeichert wurden.
Wichtige Vorteile von Zerobus Ingest:
- Optimierte Architektur: Beseitigt die Notwendigkeit für komplexe Workflows und Datenduplizierung.
- Scale Performance: unterstützt die Ingestion in Nahezu-Echtzeit (bis zu 5 Sekunden) und ermöglicht Tausenden von Clients, in dieselbe Tabelle zu schreiben (bis zu 100 MB/s Durchsatz pro Client).
- Integration mit der Data Intelligence Platform: beschleunigt die Time-to-Value, indem es Teams ermöglicht, Analyse- und KI-Tools wie MLflow zur Betrugserkennung direkt auf ihre Daten anzuwenden.
Zerobus-Aufnahmefähigkeit | Spezifikationen |
Erfassungslatenz | Nahezu in Echtzeit (≤5 Sekunden) |
Maximaler Durchsatz pro Client | Bis zu 100 MB/s |
Gleichzeitige Clients | Tausende pro Tabelle |
Kontinuierliche Synchronisierungsverzögerung (Delta → Lakebase) | 10–15 Sekunden |
Echtzeit-Latenz des foreach-Writers | 200–300 Millisekunden |
Über Lakebase
Lakebase ist eine vollständig verwaltete, serverlose und skalierbare Postgres-Datenbank, die in die Databricks-Plattform integriert ist. Sie wurde für operative und transaktionale Workloads mit geringer Latenz entwickelt, die direkt auf denselben Daten ausgeführt werden, auf denen auch Analyse- und KI-Anwendungsfälle basieren.
Die vollständige Trennung von Compute und Speicher ermöglicht eine schnelle Bereitstellung und elastisches Autoscaling. Die Integration von Lakebase in die Databricks-Plattform ist ein wesentliches Unterscheidungsmerkmal gegenüber herkömmlichen Datenbanken, da Lakebase Lakehouse-Daten sowohl für Echtzeitanwendungen als auch für KI direkt verfügbar macht, ohne dass komplexe, benutzerdefinierte Datenpipelines erforderlich sind. Es ist darauf ausgelegt, die Anforderungen an die Datenbankerstellung, Abfragelatenz und Gleichzeitigkeit zu erfüllen, um Unternehmensanwendungen und agentenbasierte Workloads zu unterstützen. Schließlich ermöglicht es Entwicklern, Datenbanken wie Code einfach zu versionieren und zu verzweigen.
Wesentliche Vorteile von Lakebase:
- Automatische Datensynchronisation: Ermöglicht die einfache Synchronisierung von Daten aus dem Lakehouse (analytische Schicht) mit Lakebase als Snapshot, geplant oder kontinuierlich, ohne dass komplexe externe Pipelines erforderlich sind.
- Integration mit der Databricks-Plattform: Lakebase lässt sich mit Unity Catalog, Lakeflow Connect, Spark Declarative Pipelines, Databricks Apps und mehr integrieren.
- Integrierte Berechtigungen und Governance: Konsistente Rollen- und Berechtigungsverwaltung für operative und analytische Daten. Native Postgres-Berechtigungen können weiterhin über das Postgres-Protokoll beibehalten werden.
Zusammen ermöglichen diese Tools den Kunden, Daten aus verschiedenen Systemen direkt in Delta-Tabellen zu erfassen und Reverse-ETL-Anwendungsfälle im großen Umfang mit Scale zu implementieren. Als Nächstes werden wir untersuchen, wie diese Technologien verwendet werden können, um eine Anwendung in nahezu Echtzeit zu implementieren!
So erstellen Sie eine Anwendung in Nahezu-Echtzeit
Als praktisches Beispiel helfen wir dem Essenslieferdienst „Data Diners“, sein Führungspersonal mit einer Anwendung auszustatten, mit der Fahreraktivitäten und Lieferungen in Echtzeit überwacht werden können. Derzeit fehlt ihnen diese Transparenz, was ihre Fähigkeit einschränkt, Probleme zu beheben, die während der Lieferungen auftreten.
Warum ist eine Echtzeitanwendung wertvoll?
- Betriebsübersicht: Das Management kann sofort sehen, wo sich jeder Fahrer befindet und wie ihre aktuellen Lieferungen vorankommen. Das bedeutet weniger blinde Flecken bei verspäteten Bestellungen oder wenn ein Fahrer Hilfe benötigt.
- Problembehebung: Live-Standort- und Statusdaten ermöglichen es Disponenten, Fahrer umzuleiten, Prioritäten anzupassen oder Kunden bei Verzögerungen proaktiv zu kontaktieren, wodurch fehlgeschlagene oder verspätete Lieferungen reduziert werden.
Sehen wir uns an, wie Sie dies mit Zerobus Ingest, Lakebase und Databricks Apps auf der Data Intelligence Platform erstellen!
Überblick über die Anwendungsarchitektur
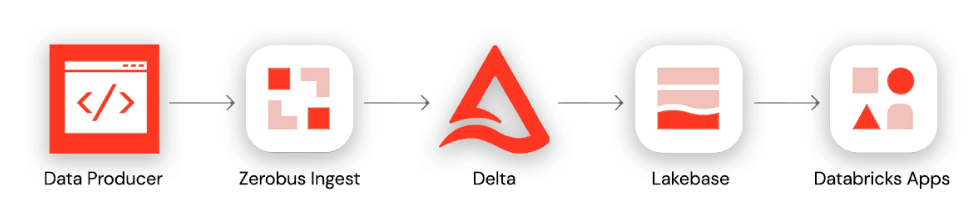
Diese End-to-End-Architektur folgt vier Phasen: (1) Ein Datenerzeuger verwendet das Zerobus SDK, um Ereignisse direkt in eine Delta-Tabelle im Databricks Unity Catalog zu schreiben. (2) Eine kontinuierliche Synchronisierungspipeline überträgt aktualisierte Datensätze aus der Delta-Tabelle an eine Lakebase-Postgres-Instanz. (3) Ein FastAPI-Backend verbindet sich über WebSockets mit Lakebase, um Echtzeit-Updates zu streamen. (4) Eine auf Databricks Apps basierende Front-End-Anwendung visualisiert die Live-Daten für Endbenutzer.
Beginnend mit unserem Datenproduzenten wird die Data-Diner-App auf dem Telefon des Fahrers GPS-Telemetriedaten über den Standort des Fahrers (Breiten- und Längengradkoordinaten) auf dem Weg zur Auslieferung von Bestellungen ausgeben. Diese Daten werden an ein API-Gateway gesendet, das die Daten letztendlich an den nächsten Dienst in der Ingestionsarchitektur sendet.
Mit dem Zerobus SDK können wir schnell einen Client schreiben, um Ereignisse vom API-Gateway an unsere Zieltabelle weiterzuleiten. Da die Zieltabelle nahezu in Echtzeit aktualisiert wird, können wir dann eine kontinuierliche Synchronisierungspipeline erstellen, um unsere Lakebase-Tabellen zu aktualisieren. Schließlich können wir durch die Nutzung von Databricks Apps ein FastAPI-Backend bereitstellen, das WebSockets verwendet, um Echtzeit-Updates aus Postgres zu streamen, zusammen mit einer Frontend-Anwendung, um den Live-Datenfluss zu visualisieren.
Vor der Einführung des Zerobus SDK hätte die Streaming-Architektur mehrere Hops umfasst, bevor die Daten in der Zieltabelle landeten. Unser API-Gateway hätte die Daten in einen Staging-Bereich wie Kafka auslagern müssen, und wir hätten Spark Structured Streaming benötigt, um die Transaktionen in die Zieltabelle zu schreiben. All dies führt zu unnötiger Komplexität, insbesondere da das alleinige Ziel das Lakehouse ist. Die obige Architektur zeigt stattdessen, wie die Databricks Data Intelligence Platform die durchgängige Entwicklung von Unternehmensanwendungen vereinfacht – von der Datenaufnahme über Echtzeitanalysen bis hin zur Implementierung interaktiver Anwendungen.
Erste Schritte
Voraussetzungen: Was Sie benötigen
- Lakebase: Allgemein verfügbar auf AWS und Azure.
- Zerobus Ingest: Allgemein verfügbar auf AWS und Azure
- Databricks Apps: Überprüfen Sie, ob Sie über die Berechtigungen zum Erstellen von Databricks Apps verfügen.
Schritt 1: Erstellen Sie eine Zieltabelle im Databricks Unity Catalog
Die von den Client-Anwendungen erzeugten Ereignisdaten werden in einer Delta-Tabelle gespeichert. Verwenden Sie den nachstehenden Code, um diese Zieltabelle in Ihrem gewünschten Katalog und Schema zu erstellen.
Schritt 2: Mit OAUTH authentifizieren
Schritt 3: Erstellen Sie den Zerobus-Client, und nehmen Sie Daten in die Zieltabelle auf.
Der nachstehende Code pusht die Telemetrieereignisdaten über die Zerobus API in Databricks.
Einschränkung und Umgehungslösung für Change Data Feed (CDF)
Derzeit unterstützt Zerobus Ingest CDF nicht. CDF ermöglicht es Databricks, Änderungsereignisse für neue Daten aufzuzeichnen, die in eine Delta-Tabelle geschrieben werden. Diese Änderungsereignisse können Einfügungen, Löschungen oder Aktualisierungen sein. Diese Änderungsereignisse können dann verwendet werden, um die synchronisierten Tabellen in Lakebase zu aktualisieren. Um Daten mit Lakebase zu synchronisieren und mit unserem Projekt fortzufahren, schreiben wir die Daten aus der Zieltabelle in eine neue Tabelle und aktivieren CDF für diese Tabelle.
Schritt 4: Bereitstellung von Lakebase und Synchronisierung der Daten mit der Datenbankinstanz
Um die App zu betreiben, synchronisieren wir Daten aus dieser neuen, CDF-fähigen Tabelle in eine Lakebase-Instanz. Wir werden diese Tabelle kontinuierlich synchronisieren, um unser Nahezu-Echtzeit-Dashboard zu unterstützen.
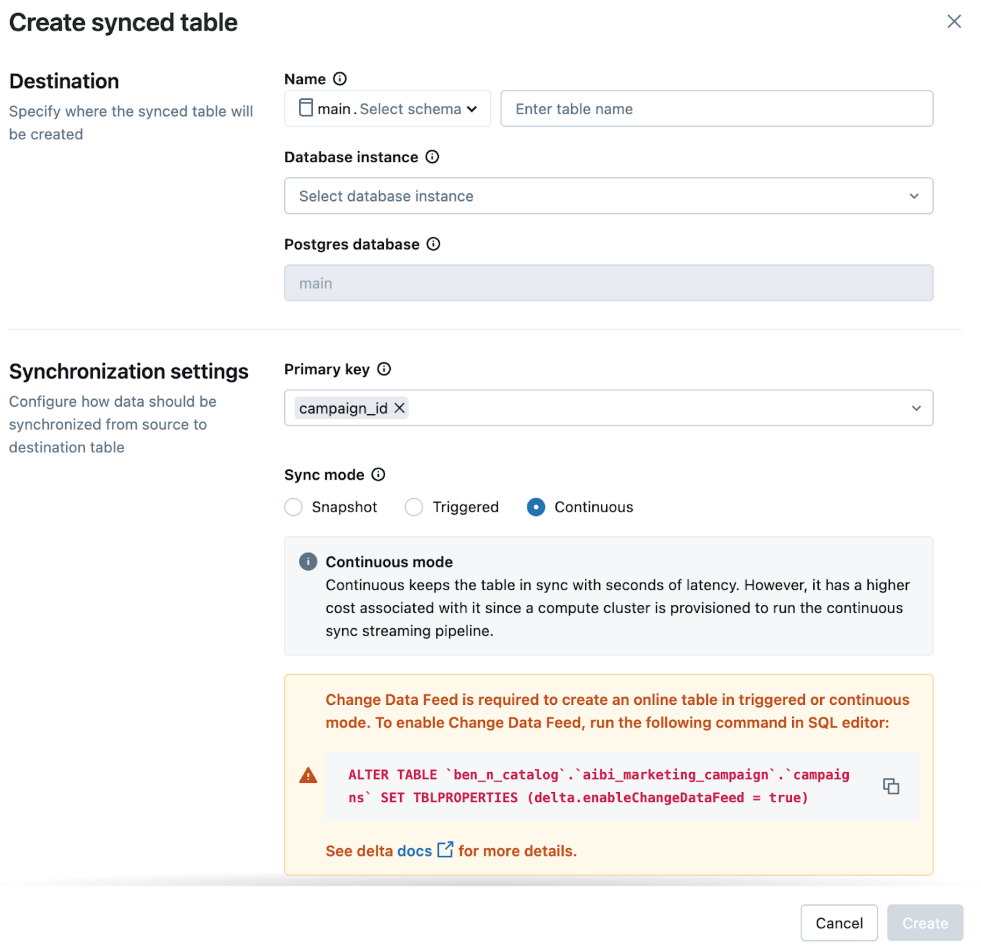
In der Benutzeroberfläche wählen wir aus:
- Synchronisierungsmodus: Kontinuierlich für Updates mit geringer Latenz
- Primärschlüssel: table_primary_key
Dadurch wird sichergestellt, dass die App die neuesten Daten mit minimaler Verzögerung widerspiegelt.
Hinweis: Sie können die Synchronisierungs-Pipeline auch programmgesteuert mit dem Databricks SDK erstellen.
Echtzeitmodus über foreach-Writer
Kontinuierliche Synchronisierungen von Delta zu Lakebase haben eine Verzögerung von 10 bis 15 Sekunden. Wenn Sie also eine geringere Latenz benötigen, sollten Sie den Echtzeitmodus über ForeachWriter verwenden, um Daten direkt aus einem DataFrame mit einer Lakebase-Tabelle zu synchronisieren. Dadurch werden die Daten innerhalb von Millisekunden synchronisiert.
Siehe den Lakebase ForeachWriter-Code auf Github.
Schritt 5: Erstellen Sie die App mit FastAPI oder einem anderen Framework Ihrer Wahl.
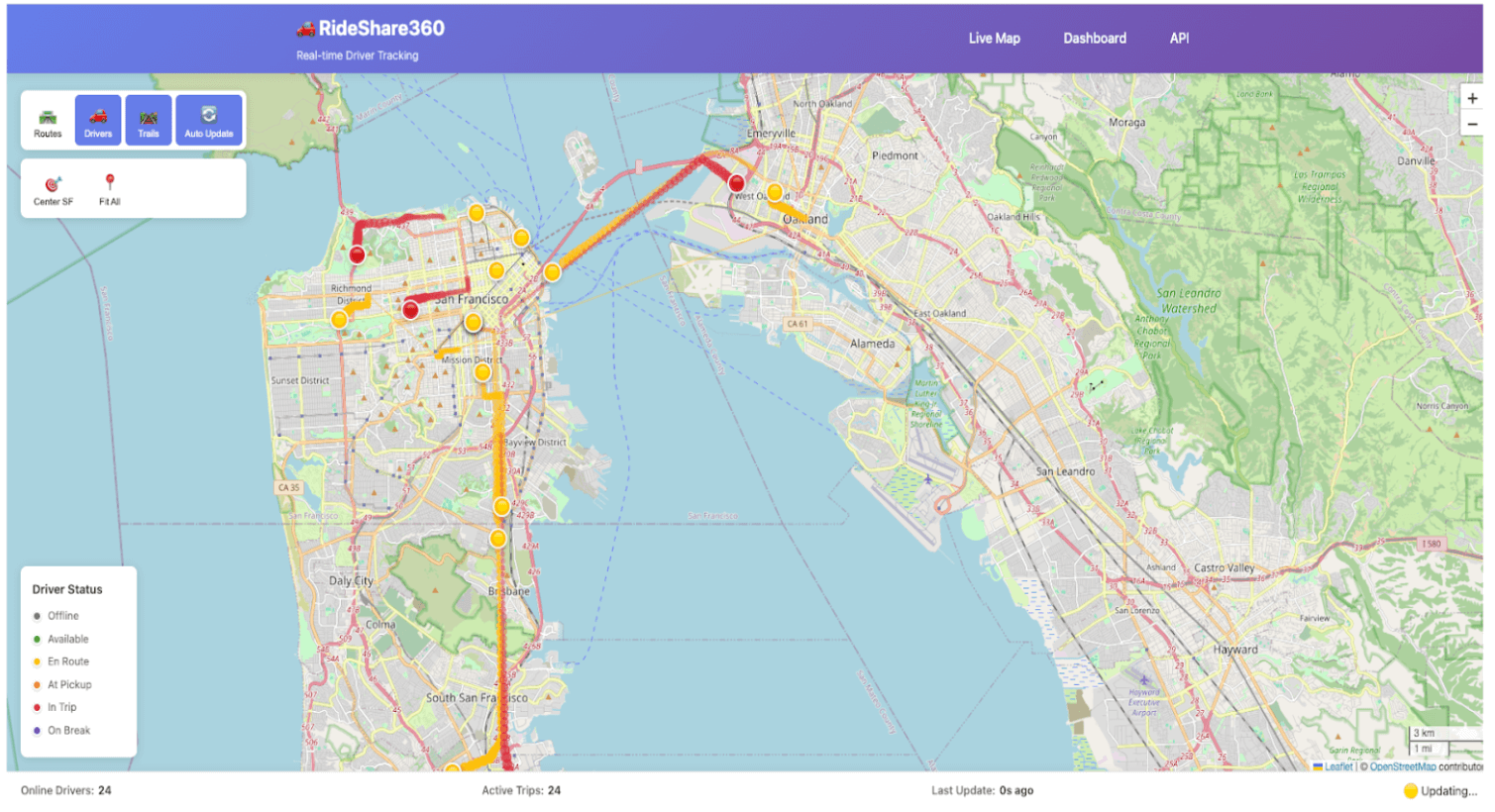
Da Ihre Daten mit Lakebase synchronisiert sind, können Sie nun Ihren Code bereitstellen, um Ihre App zu erstellen. In diesem Beispiel ruft die App Ereignisdaten von Lakebase ab und verwendet sie, um eine Nahezu-Echtzeit-Anwendung zu aktualisieren, mit der die Aktivität eines Fahrers auf dem Weg zur Auslieferung von Essen verfolgt werden kann. Lesen Sie die Dokumentation „Erste Schritte mit Databricks-Apps“, um mehr über das Erstellen von Apps auf Databricks zu erfahren.
Weitere Ressourcen
Entdecken Sie weitere Tutorials, Demos und Lösungsbeschleuniger, um Ihre eigenen Anwendungen für Ihre spezifischen Anforderungen zu erstellen.
- Erstellen einer End-to-End-Anwendung: Ein Echtzeit-Segelsimulator verfolgt eine Flotte von Segelbooten mithilfe des Python SDK und der REST API, zusammen mit Databricks Apps und Databricks Asset Bundles. Blog lesen
- Lösung für digitale Zwillinge erstellen: Erfahren Sie, wie Sie mit Databricks Apps und Lakebase die betriebliche Effizienz maximieren und Echtzeit-Einblicke sowie die prädiktive Wartung beschleunigen. Blog lesen
Erfahren Sie mehr über Zerobus Ingest, Lakebase und Databricks Apps in der technischen Dokumentation. Sie können sich auch das Databricks Apps Cookbook und die Cookbook Resource Collection ansehen.
Fazit
IoT-, Clickstream-, Telemetrie- und ähnliche Anwendungen generieren täglich Milliarden von Datenpunkten, die zum Betreiben kritischer Echtzeitanwendungen in verschiedenen Branchen verwendet werden. Daher ist die Vereinfachung der Ingestion aus diesen Systemen von größter Bedeutung. Zerobus Ingest bietet eine optimierte Möglichkeit, Ereignisdaten direkt aus diesen Systemen in das Lakehouse zu verschieben und gleichzeitig eine hohe Performance zu gewährleisten. Es lässt sich gut mit Lakebase kombinieren, um die durchgängige Entwicklung von Unternehmensanwendungen zu vereinfachen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.