Klinische operative Intelligenz gehört auf das Lakehouse
Wie Databricks Apps, Lakebase und AI/BI Genie den Integrationsstack zwischen klinischen Daten und Entscheidungsunterstützungsanwendungen eliminieren – und warum diese Architekturänderung das ist, was klinische Operationen bisher vermisst haben.
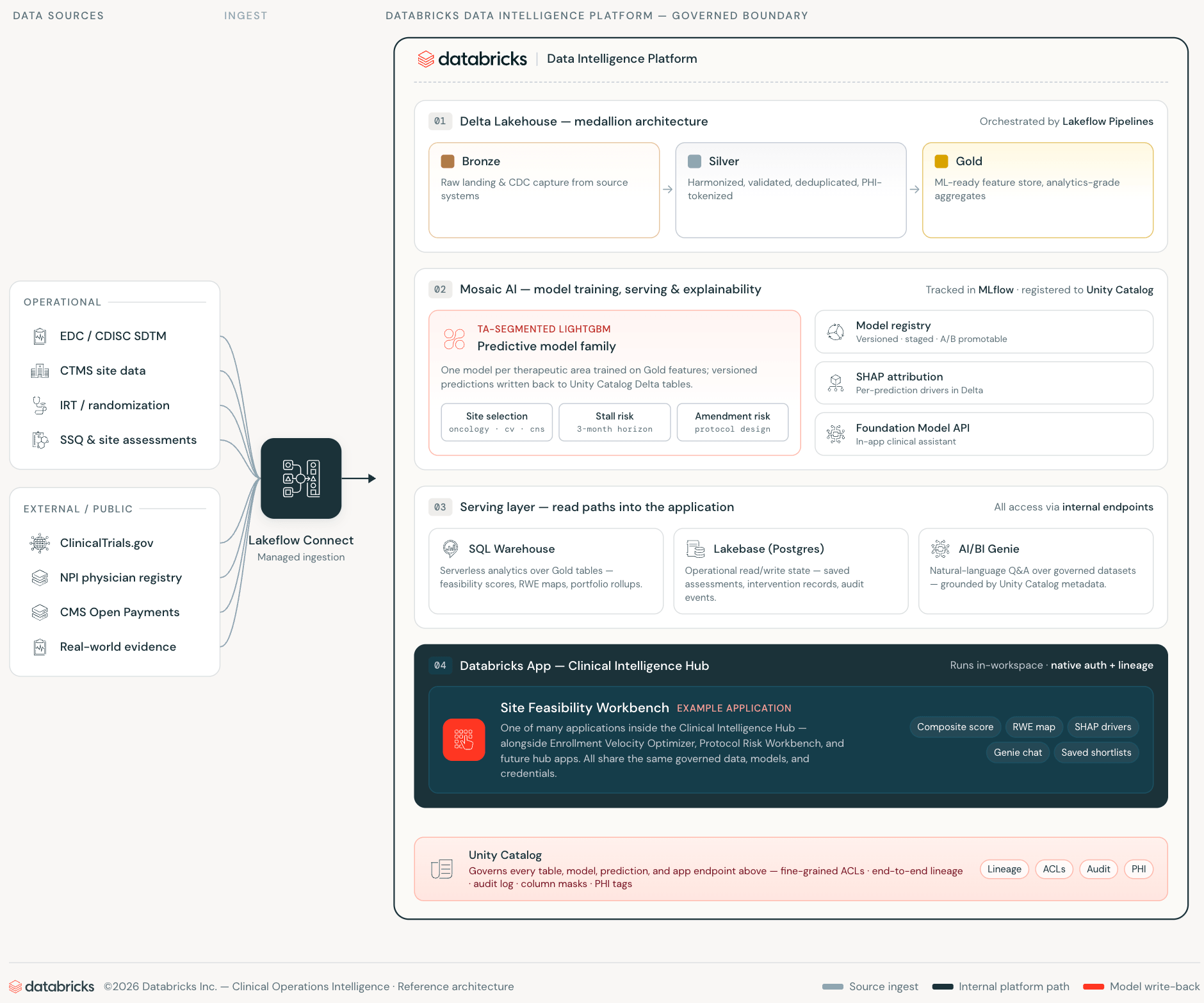
- Was es ist: Die Site Feasibility Workbench ist eine Open-Source Databricks App, die die Auswahl von klinischen Studienstandorten vollständig innerhalb des Databricks-Arbeitsbereichs durchführt – sie kombiniert ML-gestützte Standortbewertung, Lakebase für den operativen Zustand und AI/BI Genie für den natürlichsprachlichen Datenzugriff, ohne externe API-Aufrufe oder Synchronisationspipelines.
- Die Herausforderung, die sie löst: 37 % der Prüferstandorte verfehlen die Einschreibungsziele, und die Ursache liegt in der Architektur – klinische Operationsdaten und die Anwendungen, die sie verwenden, leben in getrennten Systemen, was Entscheidungen in Tabellenkalkulationen erzwingt und Integrationsaufwand, Anmeldeinformationen-Wildwuchs und Synchronisationsverzögerungen verursacht, die das Vertrauen in die Daten untergraben.
- Ergebnisse und Errungenschaften: TA-segmentierte LightGBM-Modelle, die auf Ihrer eigenen CTMS-, EDC- und IRT-Historie trainiert wurden – nicht auf Branchendurchschnitten – liefern Bewertungen, die mit wachsendem Portfolio besser werden, mit SHAP-gesteuerten Erklärungen, die als verwaltete, versionierte Delta-Tabellen gespeichert werden. Jede Vorhersage trägt eine SHAP-gesteuerte Attribution, die als verwaltete Delta-Tabelle gespeichert ist, wodurch die Modellbegründung genauso prüfbar und versioniert ist wie die Bewertung selbst.
Das Problem mit klinischen Daten ist kein Speicherproblem. Die meisten Organisationen verfügen bereits über ein Data Warehouse, ein CTMS, ein EDC und irgendwo nachgelagert eine BI-Schicht. Das Problem ist, dass keines dieser Systeme auf eine Weise miteinander kommuniziert, die die tatsächlichen Entscheidungen unterstützt, die klinische Teams treffen müssen – und so werden die Entscheidungen stattdessen in Tabellenkalkulationen getroffen.
Heute veröffentlichen wir die Site Feasibility Workbench als vollständig Open-Source Databricks App – um zu zeigen, wie klinische Operationsintelligenz aussieht, wenn die Anwendung, die Modelle und die Daten auf derselben Plattform leben. Das Tufts Center for the Study of Drug Development hat dokumentiert, dass 37 % der aktivierten Prüfzentren weniger Patienten als ihre Ziele einschrieben und weitere 11 % überhaupt keine Patienten einschrieben – mit der kombinierten Auswirkung, dass 53 % der Studien ihre geplanten Rekrutierungszeitpläne überschritten, wobei jede sechste Studie mehr als doppelt so lange dauerte als geplant (Lamberti et al.; nachfolgende CSDD-Auswirkungsberichte verfolgen weiterhin Unterperformance auf ähnlichen Niveaus). Bis zu 500.000 US-Dollar pro Tag an nicht realisierten Arzneimittelverkäufen und 40.000 US-Dollar pro Tag an direkten Studienkosten ist die chronische Unterperformance von Zentren einer der folgenreichsten Kostentreiber in der Arzneimittelentwicklung. Diese kombinierte Unterperformance-Rate ist seit mindestens zwei Jahrzehnten im Wesentlichen unverändert geblieben. Die Werkzeuge sind nicht das Problem. Die Architektur ist es.
Klinische Operationsteams benötigen keine weiteren Dashboards, die mit bestehenden Systemen verbunden sind. Sie benötigen ihre Entscheidungsunterstützungsanwendungen dort, wo ihre Daten und Modelle leben – damit die Feedbackschleife zwischen einer Vorhersage und dem operativen Ergebnis, das sie validiert, tatsächlich geschlossen wird.
Das Architektur-Argument
Der konventionelle Ansatz zur klinischen Entscheidungsunterstützung sieht so aus: Analytische Daten leben in einem Data Warehouse oder Lakehouse. Eine separate Anwendungsdatenbank speichert den operativen Zustand. Eine Pipeline hält sie lose synchronisiert. Eine Webanwendung sitzt vor beiden und fügt semantische Harmonisierung in der Silver-Schicht hinzu. Jede Schicht führt Integrationsaufwand, Angriffsfläche für Anmeldeinformationen und eine Synchronisierungsverzögerung ein, die das Vertrauen in die von der Anwendung angezeigten Daten untergräbt.
Databricks Apps, Lakebase und AI/BI Genie eliminieren jede dieser Schichten – nicht, indem sie sie abstrahieren, sondern indem sie sie überflüssig machen.
Databricks Apps führen die Webanwendung innerhalb des Workspaces aus. Die App authentifiziert sich als erstklassiges Workspace-Dienstprinzip, fragt Unity Catalog über die SQL Statement API ab und ruft AI/BI Genie über die Workspace REST API auf – alles über interne Verbindungen. Klinische Operationsdaten überschreiten niemals eine Workspace-Grenze. Die App erbt Unity Catalog-Zugriffskontrollen ohne zusätzliche Konfiguration.
Lakebase ist die operative Datenbank-Schicht – verwaltetes PostgreSQL, das bei Inaktivität auf Null skaliert, vollständig innerhalb des Workspace-Identitätssystems bereitgestellt und mit Anmeldeinformationen versehen wird. Wo eine traditionelle Anwendung eine separat verwaltete RDS-Instanz mit eigenem Schema-Drift, Synchronisierungsjobs und Anmeldeinformationsrotation erfordern würde, befindet sich Lakebase auf derselben Plattform, auf der die Daten und Modelle leben.
AI/BI Genie schließt die letzte Lücke: natürlicher Sprachzugriff auf verwaltete Daten, direkt in den Anwendungs-Workflow eingebettet. Studienmanager stellen Fragen in einfacher Sprache an dieselben Unity Catalog-Tabellen, auf denen die ML-Modelle trainiert wurden, wobei dieselben Zugriffskontrollen angewendet werden.
Das Ergebnis ist eine klinische Operationsanwendung, die keine externen API-Aufrufe tätigt, keine separate operative Datenbankinfrastruktur unterhält und keine Synchronisierungs-Pipeline zwischen der analytischen und der operativen Schicht benötigt.
Das Auditierbarkeits-Argument
Der Standardansatz der Branche für die Machbarkeit von Studienzentren stützt sich auf kommerzielle Scoring-Produkte von Anbietern oder auf Analyseplattformen von CROs. Diese Werkzeuge basieren auf aggregierten Branchen-Daten – nützlich als Basis, aber blind für die Besonderheiten Ihres Portfolios. Ein Sponsor mit einem Jahrzehnt CTMS-, EDC- und IRT-Historie trägt signifikante Signale darüber, wie seine Zentren bei seinen Protokollen abschneiden.
Wenn der ML-Stack auf Databricks läuft, wird dieses institutionelle Wissen zu Trainingsdaten. Die Modelle in dieser Workbench werden auf Ihren historischen Rekrutierungsraten, Ihrer Historie der Zentrumsqualifizierung, Ihren Mustern von Screen-Failures und Ihrer Protokollausführungsbilanz trainiert – nicht auf Branchendurchschnitten. CMS Open Payments fügt eine öffentliche Signal-Schicht hinzu, die, wenn sie richtig eingesetzt wird, mit Forschungsengagement und Infrastruktur korreliert und frei verfügbar ist. Mit wachsendem Studienportfolio verbessern sich die Modelle auf derselben Infrastruktur. Das ist der Zinseszinseffekt, den eine Single-Platform-Architektur ermöglicht und den ein lizenziertes Scoring-Produkt nicht bieten kann: Jede neue Studie verbessert die Vorhersage, und jede neue Zentrumsbeziehung spiegelt sich im nächsten Trainingslauf wider. MLflow verfolgt jeden Modell-Trainingslauf, Parameter, Metriken und Artefakte – was den Vergleich zwischen Modellversionen, die Reproduzierbarkeit auf Abruf und eine vollständige Audit-Spur von rohen CTMS- und EDC-Datensätzen bis zur bereitgestellten Vorhersage ermöglicht.
Die regulatorische Dimension spielt hier ebenfalls eine Rolle. 21 CFR Part 11, ICH E6(R3) und die Leitlinien der FDA für gute maschinelle Lernpraktiken (GMLP), zusammen mit der zunehmenden Betonung der FDA auf Transparenz bei algorithmischer Entscheidungsunterstützung, machen Modell-Erklärbarkeit und Daten-Governance zu wesentlichen Überlegungen, nicht zu optionalen Funktionen. Da jede Vorhersage eine SHAP-Attribution trägt, die als verwaltete Unity Catalog Delta-Tabelle gespeichert ist – versioniert in MLflow, mit Lineage über Unity Catalog, abfragbar – ist die Begründung für eine Zentrums-Auswahl so auditierbar wie der Score selbst. Ein klinisches Angelegenheiten-Team kann eine Frage eines Datenüberwachungsausschusses mit einer SQL-Abfrage beantworten, nicht mit einem Black-Box-Anbieterbericht.
Was wir gebaut haben
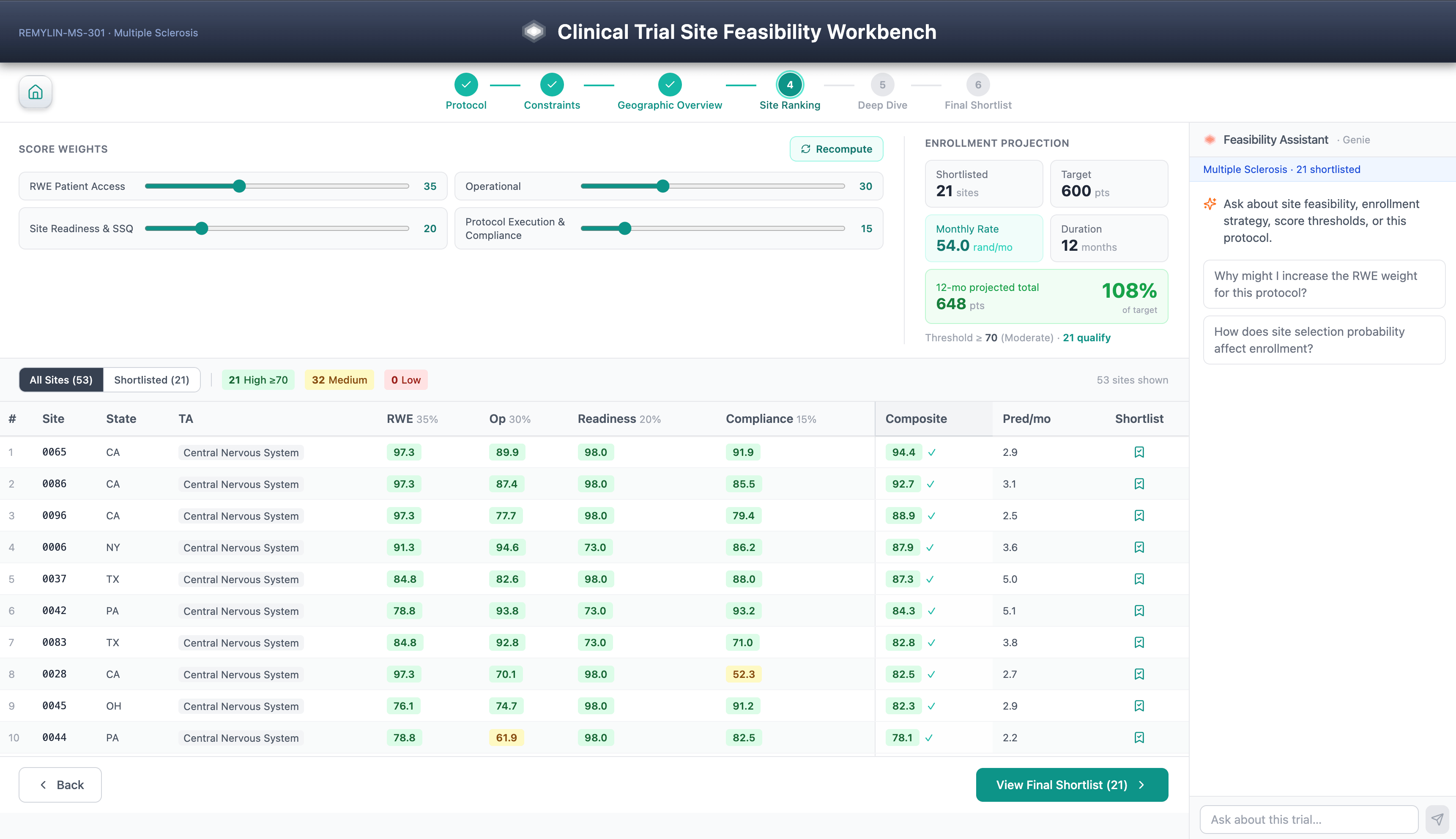
Die Site Feasibility Workbench ist ein sechsstufiger geführter Workflow für die Auswahl von klinischen Studienzentren: Protokollauswahl, Score-Beschränkungen, geografischer Überblick, Zentrums-Ranking, SHAP-gesteuerte Zentrums-Tiefenanalyse und endgültige Shortlist. Diversitätsaspekte sind eine erstklassige Scoring-Dimension, die mit den Erwartungen des FDA Diversity Action Plan gemäß FDORA 2022 übereinstimmen.
Zusammengesetzte Machbarkeits-Scores kombinieren Real-World Evidence, Patientenzugangsdaten, historische Zentrumsleistung, Historie der Zentrumsqualifizierung, Open Payments KOL-Signal und Protokollausführungsfaktoren – alles angetrieben von TA-segmentierten LightGBM-Modellen, die auf der eigenen CTMS-, EDC- und IRT-Historie der Organisation trainiert wurden.
Der hervorzuhebende Teil sind nicht die Workflow-Schritte oder die Modell-Features. Patientendaten erben Unity Catalog-Zugriffskontrollen & PHI-Handling folgt der vom Sponsor konfigurierten HIPAA Safe Harbor / Expert Determination-Haltung auf Katalog- oder Schema-Ebene.
Es ist das, was die Architektur ermöglicht: Jede Vorhersage trägt eine SHAP-Erklärung, die als verwaltete Delta-Tabelle neben der Vorhersage selbst gespeichert ist, wodurch die Modellbegründung so auditierbar und versioniert ist wie der Score, den sie erklärt. Da jede Vorhersage in verwaltete SHAP-Attributionen zerlegt wird, können Sponsoren Empfehlungen zur systematischen Unterbewertung von Gemeindezentren, Einrichtungen, die hauptsächlich Minderheiten betreuen, oder Erstprüfern überprüfen – und so die Erklärbarkeit in eine Fairness-Kontrolle verwandeln.
Gespeicherte Shortlists werden in Lakebase für die Teamfreigabe persistent gemacht. Der AI/BI Genie-Assistent beantwortet domänenübergreifende Fragen in natürlicher Sprache zu denselben Unity Catalog-Tabellen. Nichts davon erfordert eine Infrastruktur außerhalb des Workspaces.
Dies ist eine Entscheidungsunterstützungsschicht, kein System der Aufzeichnung. CTMS/EDC/IRT bleiben maßgeblich. Die Workbench liefert Vorhersagen, deren Lineage in Unity Catalog und MLflow verwaltet wird.
Die vollständige Anwendung – FastAPI-Backend, React-Frontend, Seed-Notebooks und Deploy-Skripte – wird als Open-Source-Repository veröffentlicht. Die Bereitstellung in einem bestehenden Databricks-Workspace mit Unity Catalog dauert etwa 30 Minuten technischer Bereitstellungszeit, vor der sponsorspezifischen Sicherheitsüberprüfung und Validierung.
Ein Modul einer größeren Plattform
Die Site Feasibility Workbench ist die erste öffentliche Version einer breiteren Architektur – dem Databricks Clinical Operations Intelligence Hub –, die den gesamten Studienlebenszyklus abdeckt:
- Standort-Machbarkeit und -Auswahl – was dieses Repository abdeckt
- Patienten-Kohorten und -Rekrutierung – protokollkonforme Kohortenbildung aus EHR und realen Daten im Lakehouse-Maßstab
- Enrollment Velocity Optimizer – ML-Stall-Vorhersage pro Standort und Monat mit einem Vorhersagehorizont von 1–3 Monaten
- Risikobasiertes Monitoring und Compliance – kontinuierliche Überwachung von Rekrutierungsanomalien, Datenverzögerungen und Protokollabweichungen
Alle vier werden als Databricks Apps bereitgestellt. Alle vier fragen Unity Catalog direkt ab. Keine externen API-Aufrufe. Wenn klinische Anwendungen dort leben, wo Ihre Daten und Modelle leben, schließt sich der Regelkreis. Standortauswahlmodelle lernen aus Rekrutierungsergebnissen. Risikobewertungen werden aktualisiert, wenn sich die Änderungshistorie erweitert. Jede KI-gesteuerte Empfehlung hat eine Herkunftsspur zurück zu den CTMS-, EDC- und IRT-Datensätzen, die sie erzeugt haben.
Los geht's
Klonen Sie das öffentliche Repository. Stellen Sie es bereit. Sagen Sie uns, was Sie ändern.
Für den vollständigen Clinical Operations Intelligence Hub – sehen Sie sich die BrickTalk-Aufzeichnung an: Scaling BioPharma Intelligence + Databricks Agentic Clinical Ops.
Lakebase und Databricks Apps in der Produktion decken die Plattform-Primitive im Detail ab.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.