Best Practices für Data Modeling & Implementierung auf einem modernen Lakehouse
von Leo Mao, Abhishek Dey, Justin Breese und Soham Bhatt
Viele unserer Kunden migrieren ihre alten Data Warehouses zur Databricks Lakehouse, da sie dadurch nicht nur ihr Data Warehouse modernisieren können, sondern auch sofortigen Zugriff auf eine ausgereifte Streaming- und Advanced Analytics-Plattform erhalten. Lakehouse kann alles, da es eine einzige Plattform für all Ihre Streaming-, ETL-, BI- und KI-Anforderungen ist – und es hilft Ihren Geschäfts- und Datenteams, auf einer Plattform zusammenzuarbeiten.
Bei der Unterstützung unserer Kunden stellen wir fest, dass viele nach Best Practices für die richtige Datenmodellierung und die Implementierung physischer Datenmodelle in Databricks suchen.
In diesem Artikel möchten wir uns eingehend mit der Best Practice der dimensionalen Modellierung auf der Databricks Lakehouse Platform befassen und ein Live-Beispiel für die Implementierung eines physischen Datenmodells unter Verwendung unserer Best Practices für die Tabellenerstellung und DDL bereitstellen.
Hier sind die übergeordneten Themen, die wir in diesem Blog behandeln werden:
- Die Bedeutung der Datenmodellierung
- Gängige Datenmodellierungstechniken
- DDL-Implementierung der Data Warehouse-Modellierung
- Best Practices & Empfehlungen für die Datenmodellierung auf der Databricks Lakehouse
Die Bedeutung der Datenmodellierung für Data Warehouses
Datenmodelle stehen im Mittelpunkt des Aufbaus eines Data Warehouse. Typischerweise beginnt der Prozess mit der Verteidigung des semantischen Geschäftsmodellinformationsmodells, dann eines logischen Datenmodells und schließlich eines physischen Datenmodells (PDM). Alles beginnt mit einer ordnungsgemäßen Systemanalyse- und Designphase, in der zuerst ein Geschäftsmodellinformationsmodell und Prozessflüsse erstellt werden und wichtige Geschäftseinheiten, Attribute und ihre Interaktionen gemäß den Geschäftsprozessen innerhalb der Organisation erfasst werden. Anschließend wird das logische Datenmodell erstellt, das darstellt, wie die Entitäten miteinander in Beziehung stehen, und dies ist ein technologieunabhängiges Modell. Schließlich wird ein PDM basierend auf der zugrunde liegenden Technologieplattform erstellt, um sicherzustellen, dass Lese- und Schreibvorgänge effizient durchgeführt werden können. Wie wir alle wissen, sind für Data Warehousing analytikfreundliche Modellierungsstile wie das Sternschema und Data Vault sehr beliebt.
Best Practices für die Erstellung eines physischen Datenmodells in Databricks
Basierend auf dem definierten Geschäftsproblem ist das Ziel des Datenmodelldesigns, die Daten auf einfache Weise für Wiederverwendbarkeit, Flexibilität und Skalierbarkeit darzustellen. Hier ist ein typisches Sternschema-Datenmodell, das eine Sales-Fakten-Tabelle zeigt, die jede Transaktion und verschiedene Dimensionstabellen wie Kunden, Produkte, Geschäfte, Datum usw. enthält, nach denen Sie die Daten aufschlüsseln können. Die Dimensionen können mit der Fakten-Tabelle verknüpft werden, um spezifische Geschäftsfragen zu beantworten, wie z. B. welche Produkte in einem bestimmten Monat am beliebtesten sind oder welche Geschäfte im Quartal am besten abschneiden. Sehen wir uns an, wie Sie dies in Databricks implementieren können.
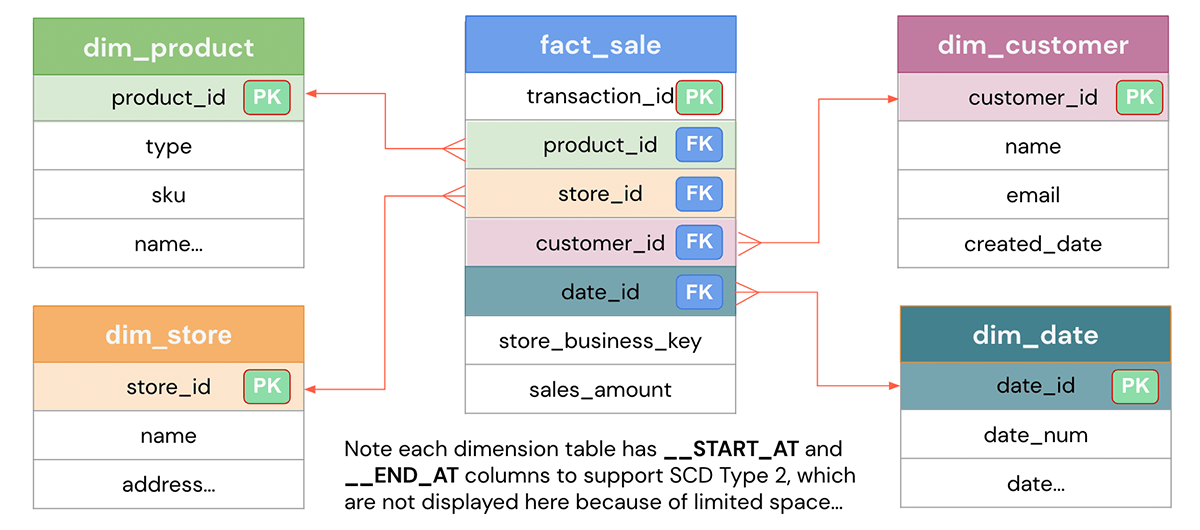
DDL-Implementierung der Data Warehouse-Modellierung auf Databricks
In den folgenden Abschnitten werden wir das Folgende anhand unserer Beispiele demonstrieren.
- Erstellung eines 3-stufigen Katalogs, einer Datenbank und einer Tabelle
- Definitionen von Primärschlüssel und Fremdschlüssel
- Identitätsspalten für Surrogatschlüssel
- Spaltenbeschränkungen für Datenqualität
- Index, Optimierung und Analyse
- Fortgeschrittene Techniken
1. Unity Catalog - 3-stufigen Namespace
Unity Catalog ist eine Databricks Governance-Schicht, die es Databricks-Administratoren und Datenverwaltern ermöglicht, Benutzer und deren Zugriff auf Daten zentral über alle Arbeitsbereiche in einem Databricks-Konto mit einem einzigen Metastore zu verwalten. Benutzer in verschiedenen Arbeitsbereichen können den Zugriff auf dieselben Daten teilen, abhängig von den zentral in Unity Catalog gewährten Berechtigungen. Unity Catalog hat einen 3-stufigen Namespace (catalog.schema(database).table), der Ihre Daten organisiert. Erfahren Sie hier mehr über Unity Catalog.
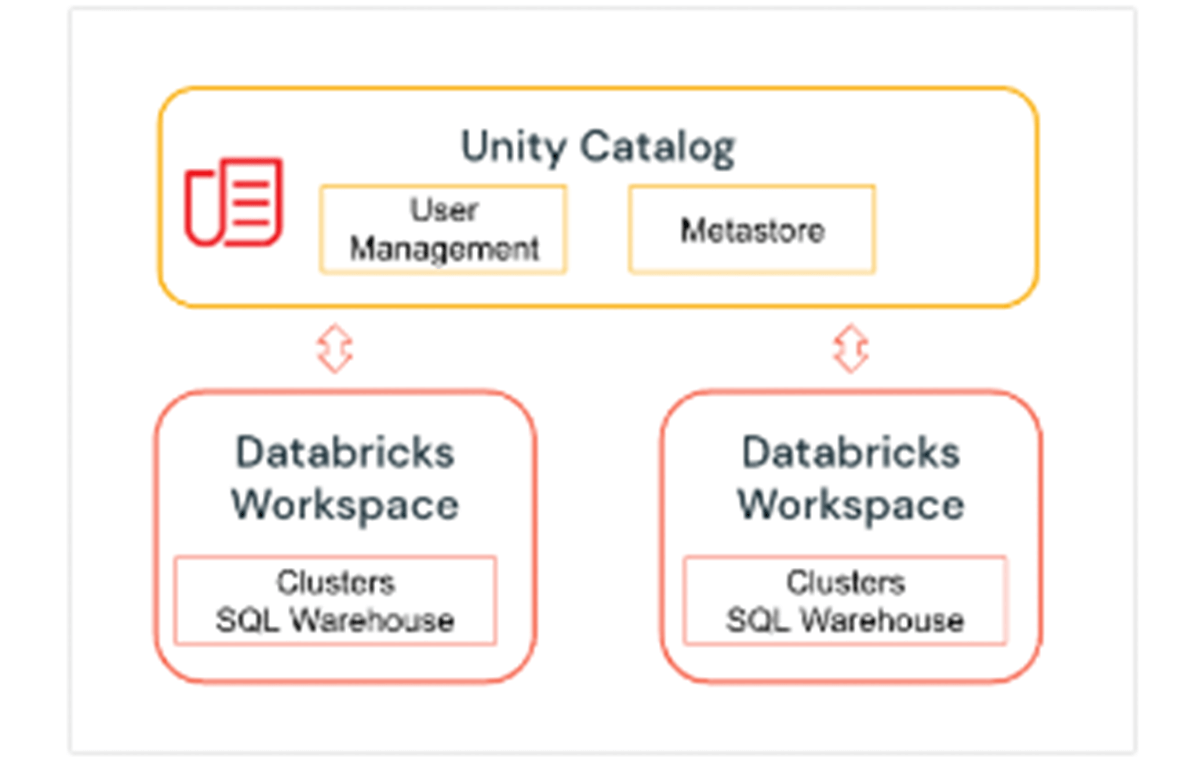
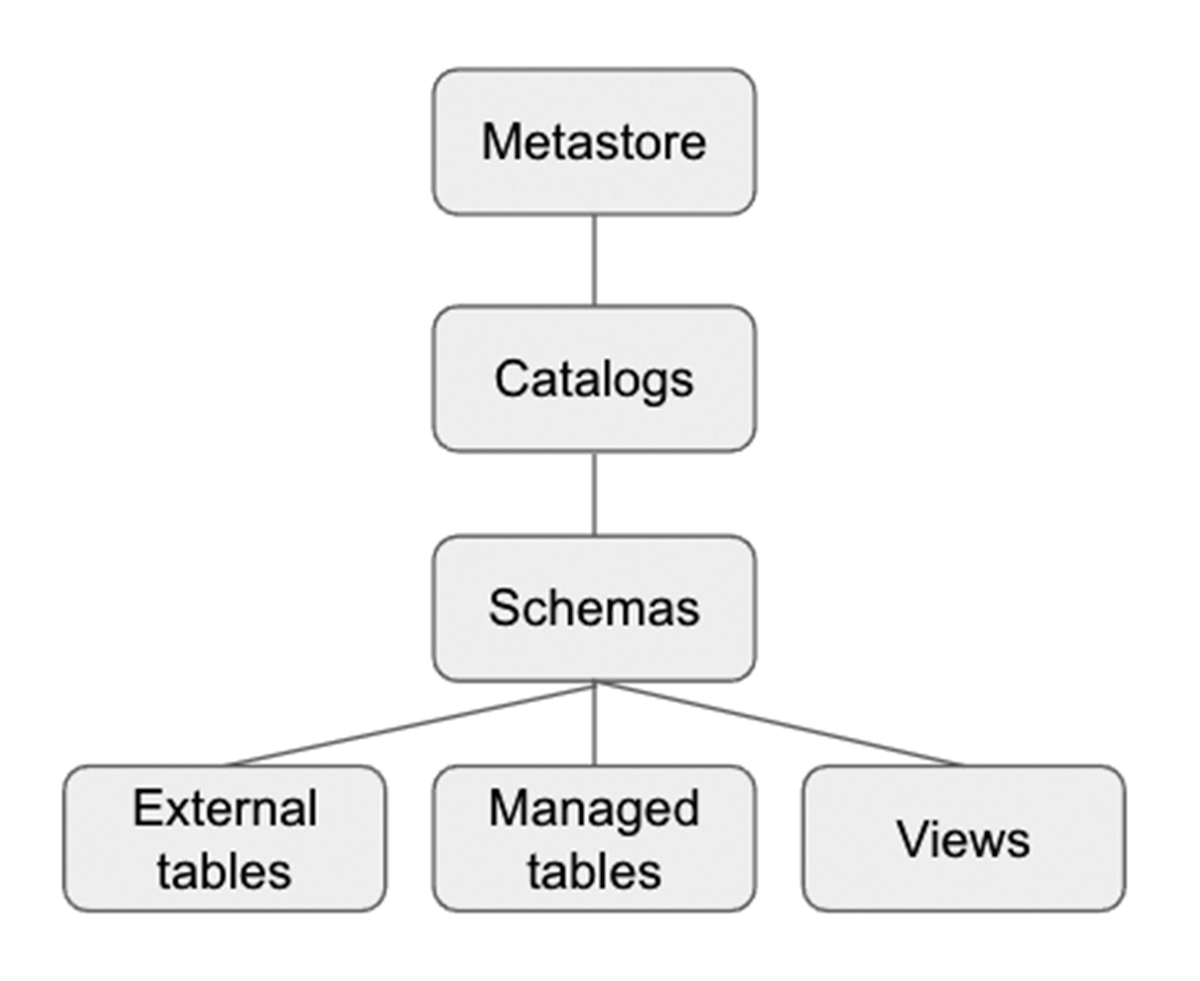
Hier ist, wie der Katalog und das Schema eingerichtet werden, bevor wir Tabellen innerhalb der Datenbank erstellen. Für unser Beispiel erstellen wir einen Katalog US_Stores und ein Schema (Datenbank) Sales_DW wie unten gezeigt und verwenden diese für den späteren Teil des Abschnitts.
Einrichtung des Katalogs und der Datenbank
Hier ist ein Beispiel für die Abfrage der Tabelle fact_sales mit einem 3-stufigen Namespace.
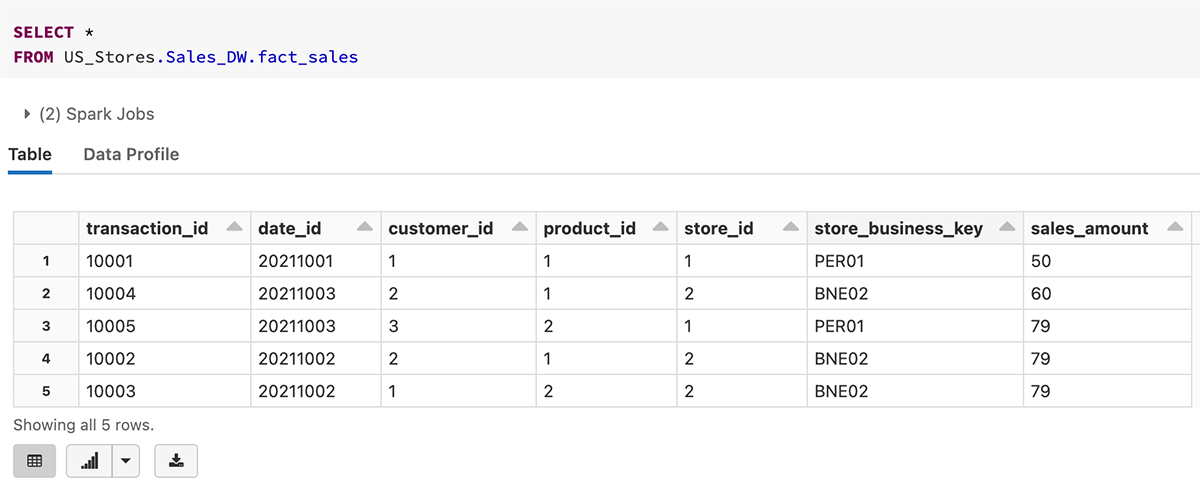
2. Definitionen von Primärschlüssel und Fremdschlüssel
Primär- und Fremdschlüsseldefinitionen sind bei der Erstellung eines Datenmodells sehr wichtig. Die Möglichkeit, PK/FK-Definitionen zu unterstützen, macht die Definition des Datenmodells in Databricks sehr einfach. Es hilft Analysten auch, die Join-Beziehungen im Databricks SQL Warehouse schnell zu erkennen, damit sie effektiv Abfragen schreiben können. Wie die meisten anderen Massively Parallel Processing (MPP), EDW und Cloud Data Warehouses sind die PK/FK-Beschränkungen nur informativ. Databricks unterstützt keine Erzwingung der PK/FK-Beziehung, bietet aber die Möglichkeit, sie zu definieren, um die Gestaltung des semantischen Datenmodells zu erleichtern.
Hier ist ein Beispiel für die Erstellung der Tabelle dim_store mit store_id als Identitätsspalte, die gleichzeitig als Primärschlüssel definiert ist.
DDL-Implementierung für die Erstellung der Store-Dimension mit Primärschlüsseldefinitionen
Nachdem die Tabelle erstellt wurde, können wir sehen, dass der Primärschlüssel (store_id) als Beschränkung in der Tabellendefinition unten erstellt wurde.
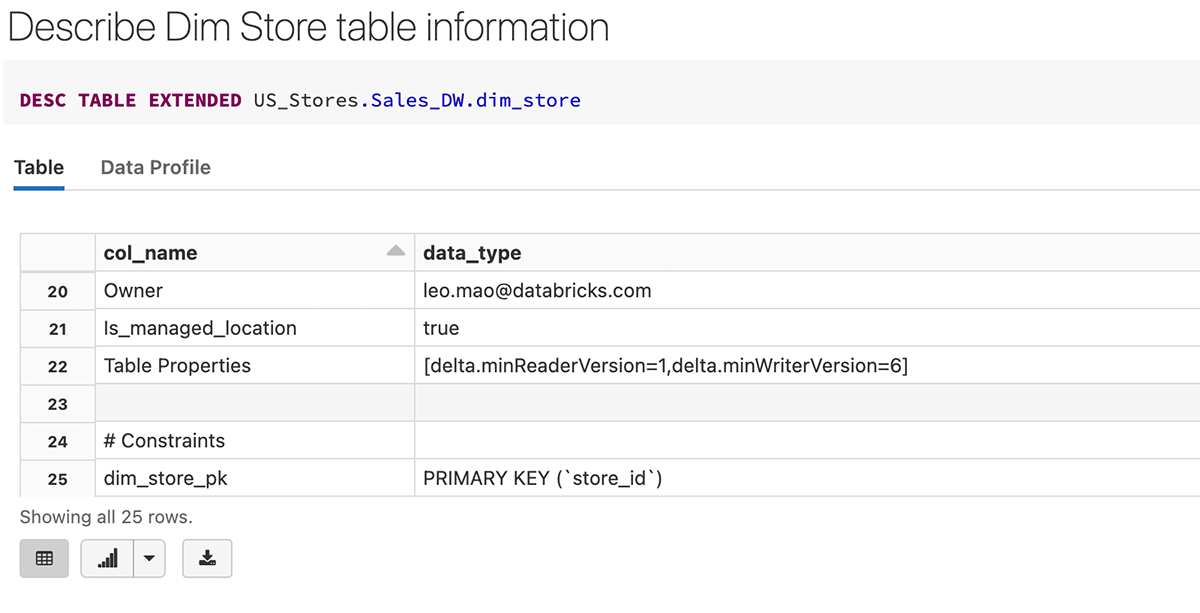
Hier ist ein Beispiel für die Erstellung der Tabelle fact_sales mit transaction_id als Primärschlüssel sowie Fremdschlüsseln, die auf die Dimensionstabellen verweisen.
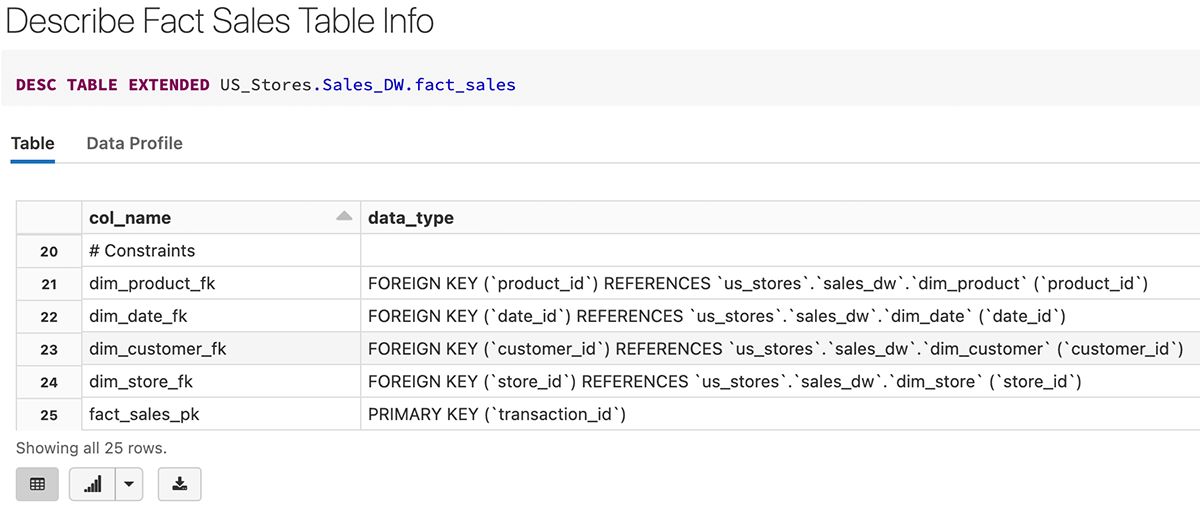
DDL-Implementierung für die Erstellung von Sales-Fakten mit Fremdschlüsseldefinitionen
Nachdem die Fakten-Tabelle erstellt wurde, konnten wir sehen, dass der Primärschlüssel (transaction_id) und die Fremdschlüssel als Beschränkungen in der unten stehenden Tabellendefinition erstellt wurden.
3. Identitätsspalten für Surrogatschlüssel
Eine Identitätsspalte ist eine Spalte in einer Datenbank, die automatisch eine eindeutige ID-Nummer für jede neue Datenzeile generiert. Diese werden häufig zur Erstellung von Surrogatschlüsseln in Data Warehouses verwendet. Surrogatschlüssel sind systemgenerierte, bedeutungslose Schlüssel, sodass wir uns nicht auf verschiedene natürliche Primärschlüssel und Verkettungen mehrerer Felder verlassen müssen, um die Eindeutigkeit der Zeile zu identifizieren. Typischerweise werden diese Surrogatschlüssel als Primär- und Fremdschlüssel in Data Warehouses verwendet. Details zu Identitätsspalten werden in diesem Blog diskutiert. Nachfolgend finden Sie ein Beispiel für die Erstellung einer Identitätsspalte customer_id mit automatisch zugewiesenen Werten, beginnend mit 1 und inkrementiert um 1.
DDL-Implementierung für die Erstellung einer Kundendimension mit einer Identitätsspalte
4. Spaltenbeschränkungen für Datenqualität
Zusätzlich zu Informationsbeschränkungen für Primär- und Fremdschlüssel unterstützt Databricks auch datenqualitätsprüfende Spaltenbeschränkungen, die durchgesetzt werden, um die Qualität und Integrität von Daten sicherzustellen, die einer Tabelle hinzugefügt werden. Die Beschränkungen werden automatisch überprüft. Gute Beispiele hierfür sind NOT NULL-Beschränkungen und Spaltenwertbeschränkungen. Im Gegensatz zu anderen Cloud Data Warehouses ging Databricks weiter und bietet Spaltenwertprüfungsbeschränkungen, die sehr nützlich sind, um die Datenqualität einer bestimmten Spalte sicherzustellen. Wie wir unten sehen können, prüft die valid_sales_amount-Prüfbeschränkung, ob alle vorhandenen Zeilen die Beschränkung erfüllen (d. h. sales amount > 0), bevor sie der Tabelle hinzugefügt werden. Weitere Informationen finden Sie hier.
Hier sind Beispiele für das Hinzufügen von Beschränkungen für dim_store bzw. fact_sales, um sicherzustellen, dass store_id und sales_amount gültige Werte haben.
Hinzufügen von Spaltenbeschränkungen zu vorhandenen Tabellen zur Gewährleistung der Datenqualität
5. Index, Optimize und Analyze
Traditionelle Datenbanken verfügen über B-Tree- und Bitmap-Indizes. Databricks verfügt über eine viel fortschrittlichere Indexierungsform – die multidimensionale Z-Order-Clustering-Indexierung, und wir unterstützen auch Bloom-Filter-Indexierung. Zunächst verwendet das Delta-Dateiformat das Parquet-Dateiformat, ein spaltenorientiertes komprimiertes Dateiformat, das bereits sehr effizient bei der Spaltenbeschneidung ist. Darüber hinaus bietet die Verwendung von Z-Order-Indizes die Möglichkeit, Petabyte-große Daten in Sekunden zu durchsuchen. Sowohl Z-Order als auch Bloom-Filter-Indexierung reduzieren die Datenmenge, die gescannt werden muss, um hochselektive Abfragen gegen große Delta-Tabellen zu beantworten, dramatisch. Dies führt typischerweise zu einer Verbesserung der Laufzeit um Größenordnungen und Kosteneinsparungen. Verwenden Sie Z-Order für Ihre Primärschlüssel und Fremdschlüssel, die für die häufigsten Joins verwendet werden. Und verwenden Sie bei Bedarf zusätzliche Bloom-Filter-Indexierung.
Optimieren Sie fact_sales nach customer_id und product_id für bessere Abfrage- und Join-Leistung
Erstellen Sie einen Bloomfilter-Index, um das Überspringen von Daten für eine bestimmte Spalte zu ermöglichen
Und wie bei jedem anderen Data Warehouse können Sie ANALYZE TABLE verwenden, um Statistiken zu aktualisieren und sicherzustellen, dass der Query-Optimierer die besten Statistiken für die Erstellung des besten Abfrageplans hat.
Sammeln Sie Statistiken für alle Spalten für einen besseren Abfrageausführungsplan
6. Fortgeschrittene Techniken
Während Databricks fortgeschrittene Techniken wie Tabellenpartitionierung unterstützt, sollten Sie diese Funktionen sparsam einsetzen, nur wenn Sie viele Terabytes an komprimierten Daten haben – denn meistens geben Ihnen unsere OPTIMIZE- und Z-ORDER-Indizes die beste Datei- und Datenbereinigung, was die Partitionierung einer Tabelle nach Datum oder Monat fast zu einer schlechten Praxis macht. Es ist jedoch eine gute Praxis sicherzustellen, dass Ihre Tabellen-DDLs für automatische Optimierung und automatische Kompaktierung eingerichtet sind. Diese stellen sicher, dass Ihre häufig geschriebenen Daten in kleinen Dateien in größere spaltenorientierte komprimierte Formate von Delta komprimiert werden.
Möchten Sie ein visuelles Datenmodellierungstool nutzen? Unser Partner erwin Data Modeler von Quest kann verwendet werden, um Sternschemata, Data Vaults und beliebige Branchen-Datenmodelle in Databricks mit nur wenigen Klicks zu reverse-engineeren, zu erstellen und zu implementieren.
Databricks Notebook Beispiel
Mit der Databricks-Plattform kann man problemlos verschiedene Datenmodelle mit Leichtigkeit entwerfen und implementieren. Um alle oben genannten Beispiele in einem vollständigen Workflow zu sehen, schauen Sie sich bitte dieses Beispiel an.
Schauen Sie sich auch unseren verwandten Blogbeitrag an – Fünf einfache Schritte zur Implementierung eines Sternschemas in Databricks mit Delta Lake.
Beginnen Sie mit dem Aufbau Ihrer dimensionalen Modelle im Lakehouse
Testen Sie Databricks 14 Tage kostenlos.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.