Datenqualitäts-Monitoring im großen Scale mit agentenbasierter KI
Basiert auf Unity Catalog, um Probleme frühzeitig zu erkennen und schnell zu beheben
von Jacqueline Li, Danny Chiao und Saravanan Balasubramanian
• Manuelle, regelbasierte Datenqualität skaliert nicht mit dem Wachstum von Datenbeständen für Analysen und KI.
• Die agentenbasierte Datenqualitäts-Monitoring lernt erwartete Datenmuster und erkennt Probleme in kritischen Datasets.
• Plattformnative Signale wie die Datenherkunft (Lineage) im Unity Catalog helfen Teams, Probleme auf Enterprise Scale schneller zu lösen.
Die Herausforderung der Datenqualität bei Scale
Da Unternehmen immer mehr Daten- und KI-Produkte entwickeln, wird die Aufrechterhaltung der Datenqualität schwieriger. Daten sind die Grundlage für alles – von Dashboards für Führungskräfte bis hin zu unternehmensweiten Q&A-Bots. Eine veraltete Tabelle führt zu veralteten oder sogar falschen Antworten, was sich direkt auf die Geschäftsergebnisse auswirkt.
Die meisten Ansätze zur Datenqualität lassen sich nicht auf diese Realität skalieren. Datenteams verlassen sich auf manuell definierte Regeln, die auf eine kleine Anzahl von Tabellen angewendet werden. Mit dem Wachstum der Datenbestände entstehen blinde Flecken und die Sichtbarkeit des Gesamtzustands wird eingeschränkt.
Teams fügen kontinuierlich neue Tabellen hinzu, von denen jede ihre eigenen Datenmuster aufweist. Die Durchführung benutzerdefinierter Prüfungen für jedes Dataset ist nicht nachhaltig. In der Praxis wird nur eine Handvoll kritischer Tabellen überwacht, während der Großteil des Bestands ungeprüft bleibt.
Das Ergebnis ist, dass Unternehmen mehr Daten als je zuvor haben, aber weniger Vertrauen, diese zu nutzen.
Einführung der agentengesteuerten Datenqualitäts-Monitoring
Databricks gibt heute die Public Preview der Datenqualitätsüberwachung auf AWS, Azure Databricks und GCP bekannt.
Das Data Quality Monitoring ersetzt fragmentierte, manuelle Prüfungen durch einen agentenbasierten Ansatz, der auf Scale ausgelegt ist. Anstatt statischer Schwellenwerte lernen KI-Agenten normale Datenmuster, passen sich an Veränderungen an und überwachen den Datenbestand kontinuierlich.
Die tiefe Integration in die Databricks-Plattform ermöglicht mehr als nur die Erkennung.
- Die Ursache wird direkt in vorgelagerten Lakeflow-Jobs und -Pipelines angezeigt. Teams können von der Datenqualitäts-Monitoring direkt zum betroffenen Job springen und die integrierten Observability-Funktionen von Lakeflow nutzen, um einen tieferen Einblick in Fehler zu erhalten und Probleme schneller zu beheben.
- Probleme werden priorisiert, indem die Herkunft aus dem Unity Catalog und zertifizierte Tags verwendet werden. So wird sichergestellt, dass Datasets mit hoher Auswirkung zuerst behandelt werden.
Mit plattformnativem Monitoring erkennen Teams Probleme früher, konzentrieren sich auf das Wesentliche und beheben Probleme schneller im Enterprise Scale.
„Unser Ziel war es schon immer, dass unsere Daten uns mitteilen, wenn es ein Problem gibt. Databricks' Data Quality Monitoring schafft dies endlich durch seinen KI-gesteuerten Ansatz. Es ist nahtlos in die UI integriert und führt ein hands-off, konfigurationsfreies Monitoring aller unserer Tabellen durch, was bei anderen Produkten immer ein limitierender Faktor war. Anstatt dass Benutzer Probleme melden, weisen unsere Daten zuerst darauf hin, was die Qualität, das Vertrauen und die Integrität unserer Plattform verbessert.“ – Jake Roussis, leitender Data Engineer bei Alinta Energy
So funktioniert das Datenqualitätsmonitoring
Das Data Quality Monitoring liefert durch zwei komplementäre Methoden umsetzbare Erkenntnisse.
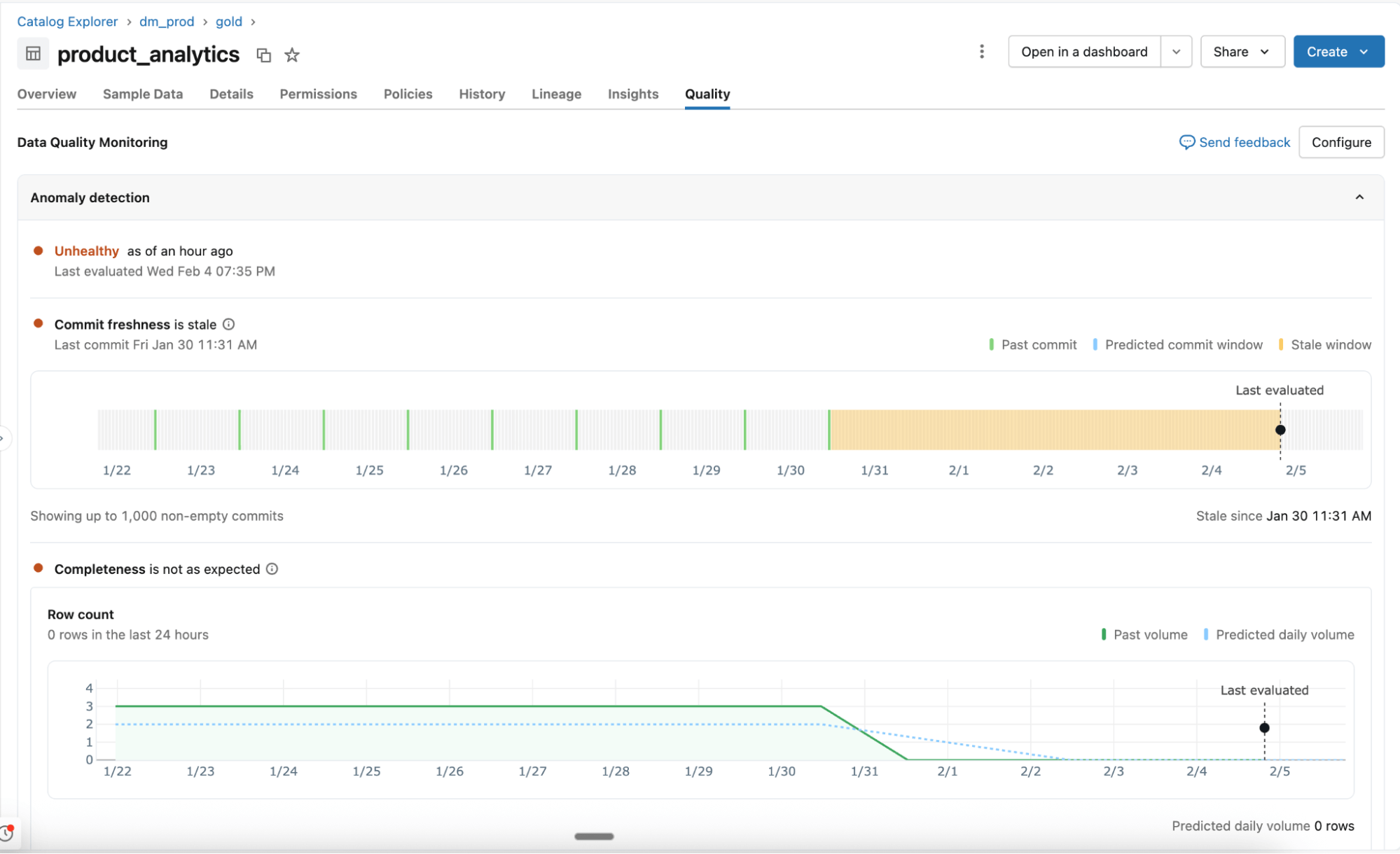
Erkennung von Anomalien
Die auf Schemaebene aktivierte Anomalieerkennung überwacht alle kritischen Tabellen ohne manuelle Konfiguration. KI-Agenten lernen historische Muster und saisonales Verhalten, um unerwartete Änderungen zu erkennen.
- Erlernte Verhaltensmuster statt statischer Regeln: Agenten passen sich an normale Schwankungen an und überwachen wichtige Qualitätssignale wie Aktualität und Vollständigkeit. Die Unterstützung für zusätzliche Prüfungen, einschließlich prozentualer Nullwerte, Eindeutigkeit und Gültigkeit, folgt in Kürze.
- Intelligentes Scannen für Scale: Alle Tabellen in einem Schema werden einmal gescannt und dann je nach Wichtigkeit der Tabelle und Aktualisierungshäufigkeit erneut überprüft. Anhand der Datenherkunft (Lineage) im Unity Catalog und der Zertifizierung wird bestimmt, welche Tabellen am wichtigsten sind. Häufig genutzte Tabellen werden öfter gescannt, während statische oder veraltete Tabellen automatisch übersprungen werden.
- Systemtabellen für Transparenz und Berichterstellung: Der Tabellenzustand, erlernte Schwellenwerte und beobachtete Muster werden in Systemtabellen aufgezeichnet. Teams verwenden diese Daten für Warnungen, Berichterstellung und tiefere Analysen.
Daten-Profiling
Die auf Tabellenebene aktivierte Data-Profiing erfasst zusammenfassende Statistiken und verfolgt deren Änderungen im Laufe der Zeit. Diese Metriken liefern historischen Kontext und werden der Anomalieerkennung zur Verfügung gestellt, damit Sie Probleme leicht erkennen können.
„Bei OnePay ist es unsere Mission, Menschen zu finanziellem Fortschritt zu verhelfen, indem wir sie befähigen, ihr Geld zu sparen, auszugeben, zu leihen und zu vermehren. Qualitativ hochwertige Daten in all unseren Datasets sind für die Erfüllung dieser Mission von entscheidender Bedeutung. Mit der Datenqualitäts-Monitoring können wir Probleme frühzeitig erkennen und schnell handeln. Wir können die Genauigkeit unserer Analysen, Berichte und der Entwicklung robuster ML-Modelle sicherstellen, was alles dazu beiträgt, unsere Kunden besser zu bedienen.“ —Nameet Pai, Head of Platform & Data Engineering bei OnePay
Gewährleisten Sie die Qualität eines ständig wachsenden Datenbestands
Mit einem automatisierten Qualitäts-Monitoring können Datenplattformteams den Gesamtzustand ihrer Daten im Auge behalten und die rechtzeitige Behebung von Problemen sicherstellen.
Agentenbasierte Überwachung mit einem Klick: Überwachen Sie ganze Schemas ohne manuelle Regelerstellung und Threshold-Konfiguration. Die Datenqualitätsüberwachung lernt historische Muster und saisonale Verhaltensweisen (z. B. Volumenrückgänge am Wochenende, Steuersaison usw.), um Anomalien in all Ihren Tabellen intelligent zu erkennen.
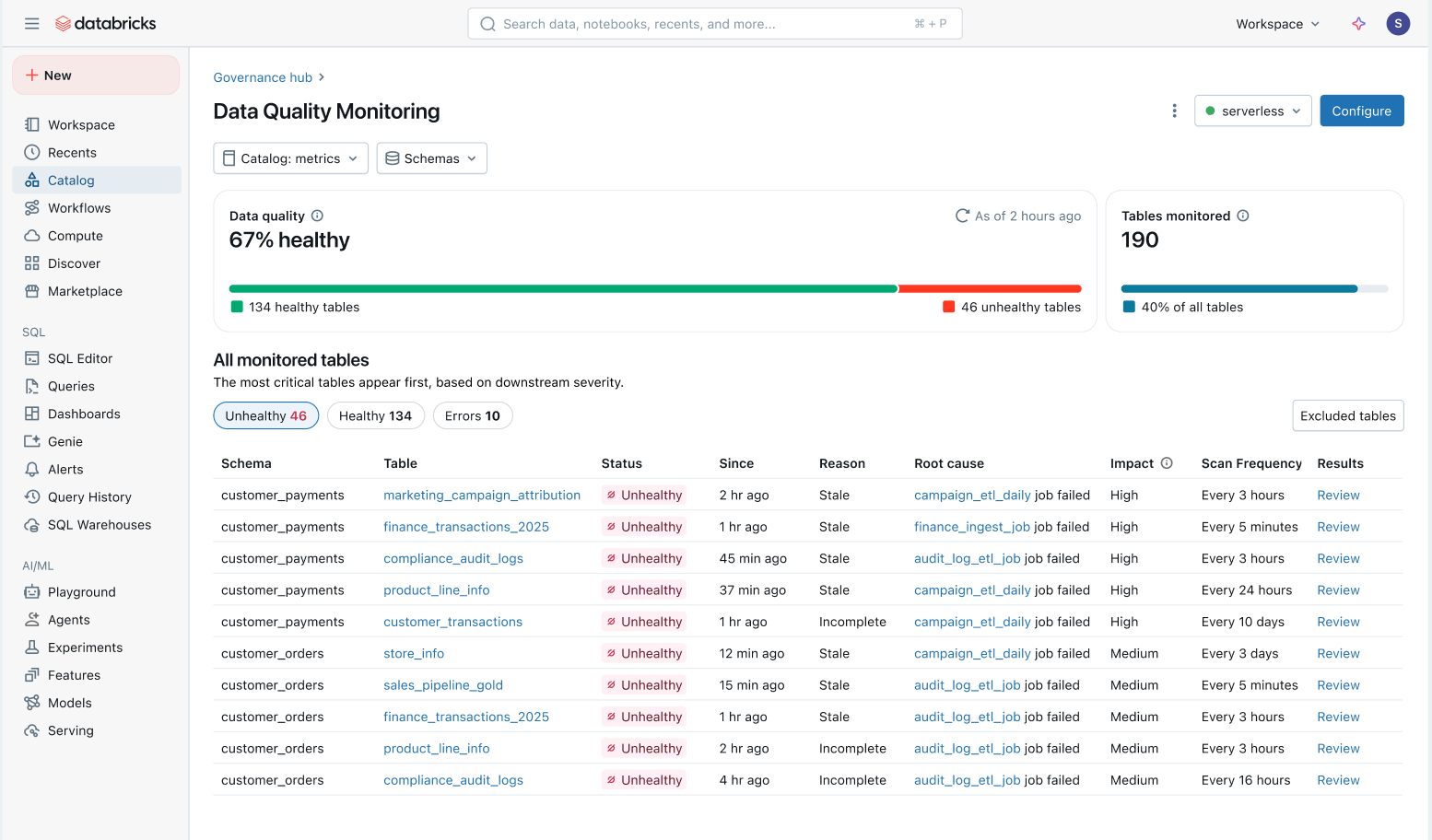
Ganzheitliche Übersicht über die Datengesundheit: Verfolgen Sie einfach den Zustand aller Tabellen in einer konsolidierten Ansicht und stellen Sie sicher, dass Probleme behoben werden.
- Nach nachgelagerten Auswirkungen priorisierte Probleme: Alle Tabellen werden basierend auf ihrer nachgelagerten Lineage und ihrem Abfragevolumen priorisiert. Qualitätsprobleme bei Ihren wichtigsten Tabellen werden zuerst gekennzeichnet.[[ ## completed ## ]]
- Schnellere Problemlösung: In Unity Catalog verfolgt das Datenqualitäts-Monitoring Probleme direkt zu vorgeschalteten Lakeflow Jobs und Spark Declarative Pipelines. Teams können aus dem Katalog direkt zum betroffenen Job springen, um spezifische Fehler, Code-Änderungen und andere Ursachen zu untersuchen.
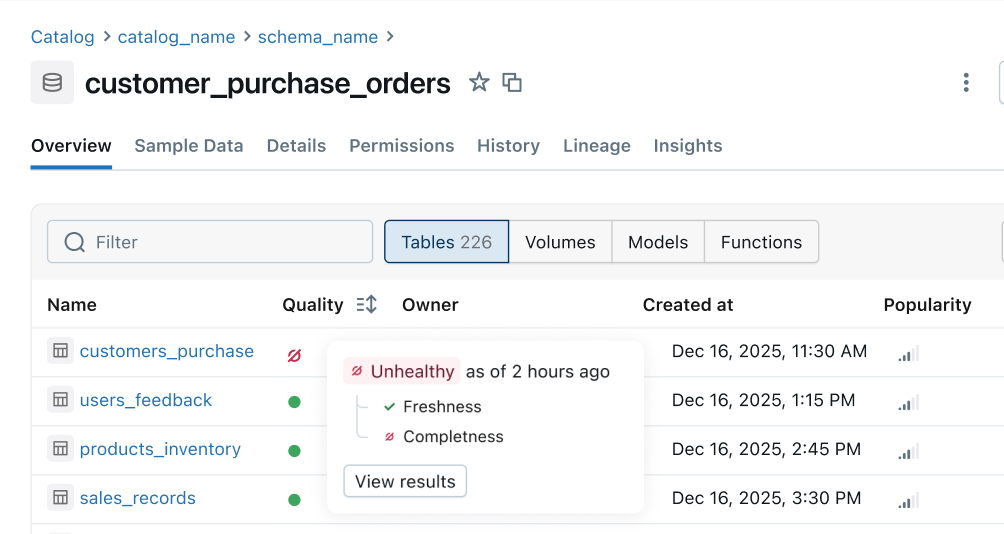
Zustandsindikator: Einheitliche Qualitätssignale werden von vorgelagerten Pipelines an nachgelagerte Geschäftsoberflächen weitergegeben. Data-Engineering-Teams werden zuerst über Probleme benachrichtigt und Nutzer können sofort erkennen, ob die Daten sicher verwendet werden können.
Wie geht es weiter?
Das steht in den kommenden Monaten auf unserer Roadmap:
- Mehr Qualitätsregeln: Unterstützung für weitere Prüfungen wie prozentualer Null-Anteil, Eindeutigkeit und Gültigkeit.
- Automatisierte Alerts und Ursachenanalyse: Erhalten Sie automatisch Alerts und beheben Sie Probleme schnell mit intelligenten Hinweisen auf die Ursache, die direkt in Ihre Jobs und Pipelines integriert sind.
- Plattformweiter Zustandsindikator: Sehen Sie einheitliche Zustandssignale in Unity Catalog, Lakeflow Observability, Lineage, Notebooks, Genie usw.
- Fehlerhafte Daten filtern und isolieren: Fehlerhafte Daten proaktiv identifizieren und verhindern, dass sie die Nutzer erreichen.
Erste Schritte: Public Preview
Erleben Sie intelligentes Monitoring im Scale und erstellen Sie eine vertrauenswürdige Self-Serve-Datenplattform. Testen Sie die Public Preview noch heute:
- Datenqualitäts-Monitoring aktivieren auf der Registerkarte „Schemadetails“ in Unity Catalog
- Verschaffen Sie sich einen ganzheitlichen Überblick über alle überwachten Tabellen direkt im Produkt.
- Konfigurieren Sie Alerts mit diesem template
(Dieser Blogbeitrag wurde mit KI-gest�ützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.