Serverless JARs entwickeln und bereitstellen
von Achille Negrier, Edward Feng, Giorgi Kikolashvili und Shiyu Wang
- Führen Sie Serverless JARs in Scala oder Java mit sofortigen Startzeiten und ohne Clusterverwaltung aus.
- Entwickeln Sie in Ihrer bevorzugten IDE mit Databricks Connect und testen Sie gegen reale Daten und produktionsähnliche Umgebungen.
- Bezahlen Sie nur für die geleistete Arbeit mit elastischer, nutzungsbasierter Abrechnung, nicht für Leerlaufzeiten oder die Beschaffung von Instanzen.
Serverless JARs und Databricks Connect für Scala
Serverless JARs ermöglichen Teams das Erstellen und Ausführen von Scala- und Java-Spark-Jobs auf vollständig verwalteten Serverless-Compute-Ressourcen. Teams können weiterhin produktionsreife Spark-Pipelines in den Sprachen erstellen, denen sie vertrauen, mit automatischen Upgrades und ohne den Betriebsaufwand für die Verwaltung von Clustern:
- Schneller Start: Mit Serverless starten Scala- und Java-Jobs in Sekunden statt Minuten. Ingenieure können Code sofort ausführen und iterieren, ohne auf das Hochfahren von Clustern warten zu müssen.
- Versionslose Upgrades: Serverless läuft kontinuierlich auf der neuesten unterstützten Spark-Laufzeitumgebung, sodass Sie niemals Databricks Runtime-Upgrades planen oder verwalten müssen.
- Keine zu verwaltende Infrastruktur: Kein Cluster-Provisioning, keine Kapazitätsplanung und keine Laufzeitverwaltung. Databricks kümmert sich automatisch um Infrastruktur, Skalierung und Leistungsoptimierung, sodass sich Entwickler auf das Schreiben von Code konzentrieren können.
- Nur für das bezahlen, was Sie nutzen: Anstatt für Always-On-Cluster oder ungenutzte Kapazitäten zu bezahlen, werden Teams nur für die tatsächlich genutzte Rechenleistung abgerechnet.
Wie funktionieren Serverless JARs?
Sie können JARs mit Lakeflow Jobs auf Serverless Compute ausführen. Serverless JARs basieren auf Spark 4 (Scala 2.13) und Spark Connect und verwenden dieselbe Architektur wie Python. Die Entkopplung von Benutzercode von der Engine ermöglicht versionslose Upgrades, beseitigt Abhängigkeitskonflikte und ermöglicht native, feingranulare Zugriffssteuerungen mit Lakeguard.
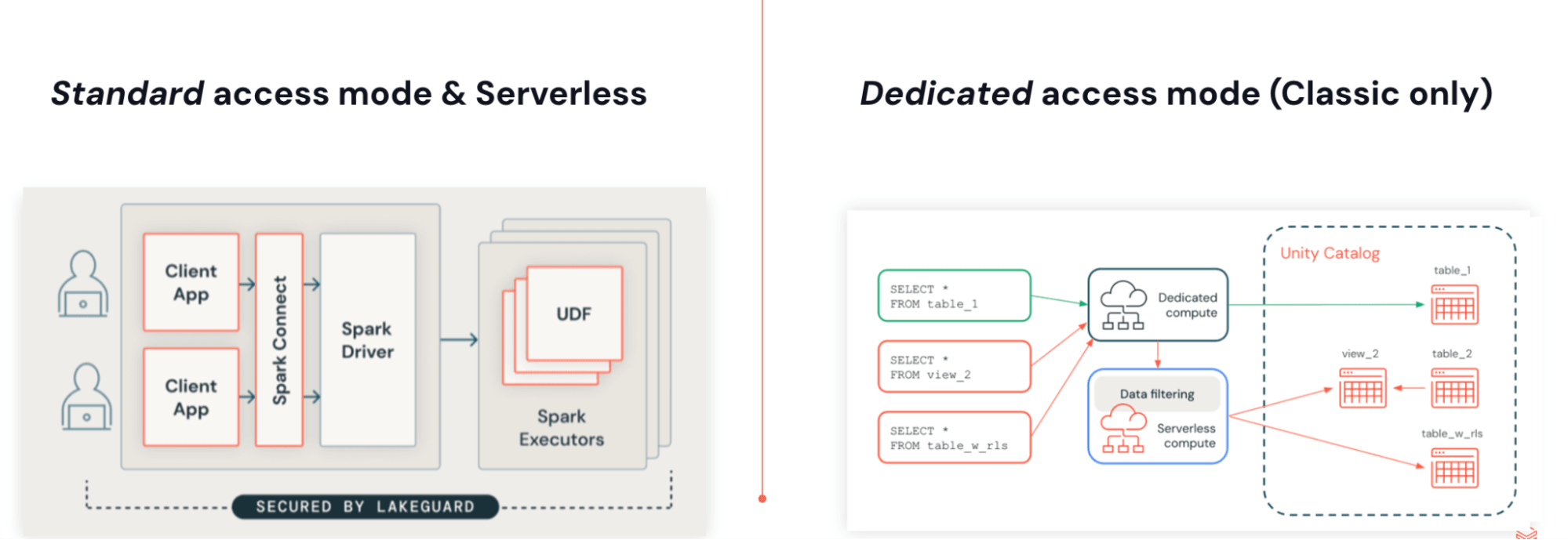
Diese Architektur hat einige wichtige Vorteile:
- Versionslose Ausführung: Anwendungen sind nicht mehr an eine bestimmte Databricks Runtime-Version gebunden. Serverless läuft immer auf der neuesten unterstützten Laufzeitumgebung, sodass Sie keine Databricks Runtime-Upgrades planen, terminieren oder verwalten müssen.
- Native feingranulare Zugriffssteuerungen mit Lakeguard: Da die gesamte Ausführung auf dem Server stattfindet, kann Databricks Zeilenfilter und attributbasierte Zugriffssteuerungen (ABAC) kostengünstig erzwingen.
- Schlanke und unabhängige Abhängigkeiten: Die Serverless-Umgebung läuft isoliert von Spark und kann daher eine unabhängige und reduzierte Menge an Abhängigkeiten bereitstellen, was auch Abhängigkeitskonflikte beseitigt.
Entwicklung mit Databricks Connect und Databricks Asset Bundles
Mit Databricks Connect können Sie Code interaktiv in Ihrer bevorzugten IDE, wie z. B. IntelliJ oder Cursor, schreiben und debuggen und dabei Serverless-Compute mit nahezu sofortigen Startzeiten nutzen.
Dies beschleunigt und zuverlässiger macht Entwicklungszyklen, da Sie gegen reale Daten und Umgebungen testen können, ohne Ihre IDEs verlassen zu müssen. Sobald Sie mit der Entwicklung fertig sind, können Sie Ihren Job mit Databricks Asset Bundles produktiv setzen.
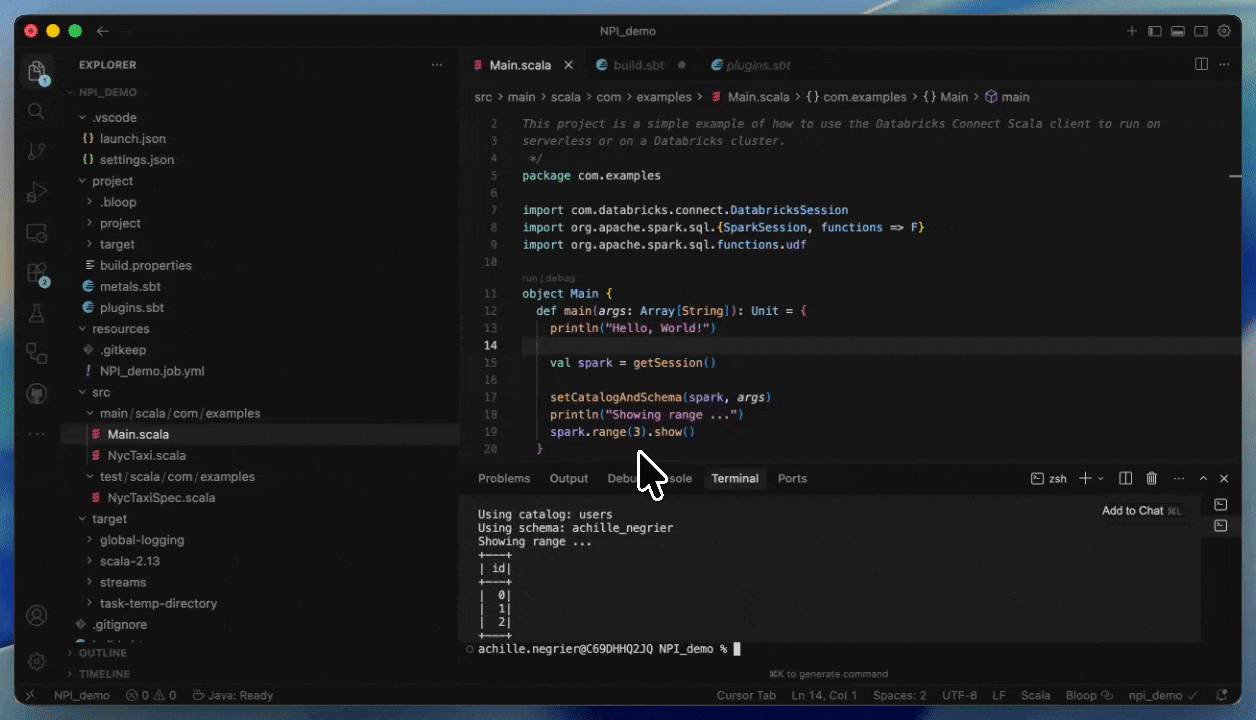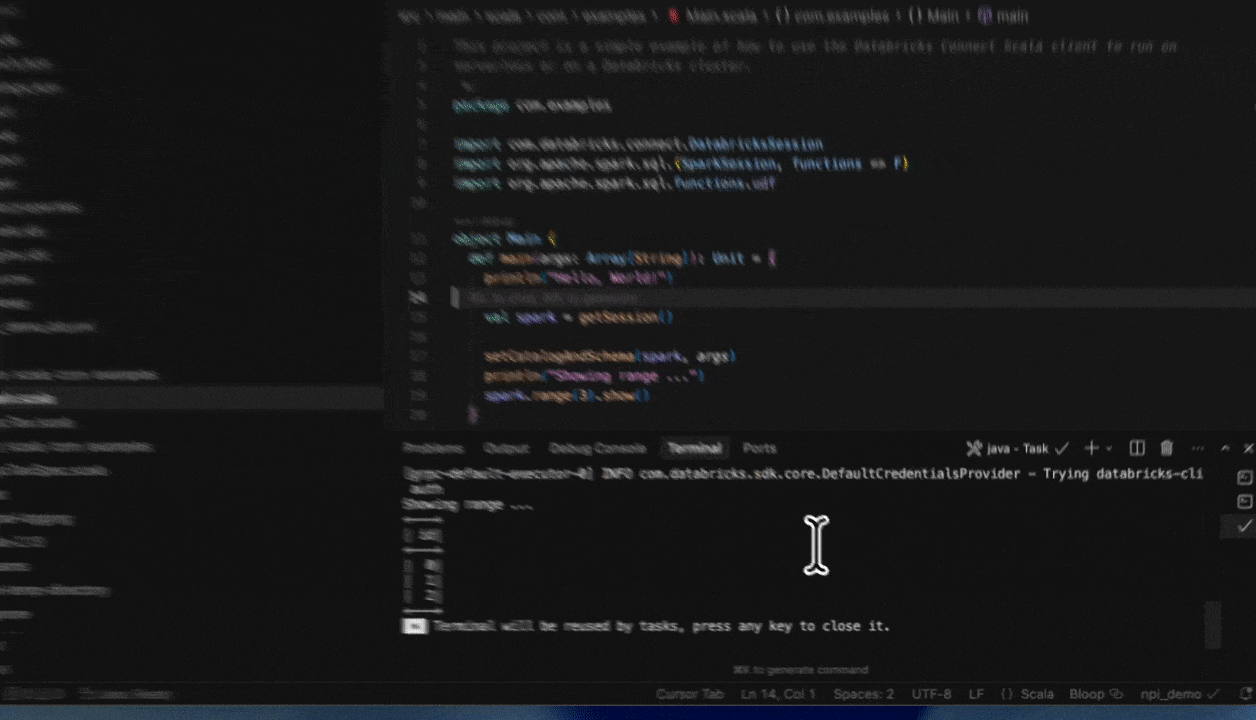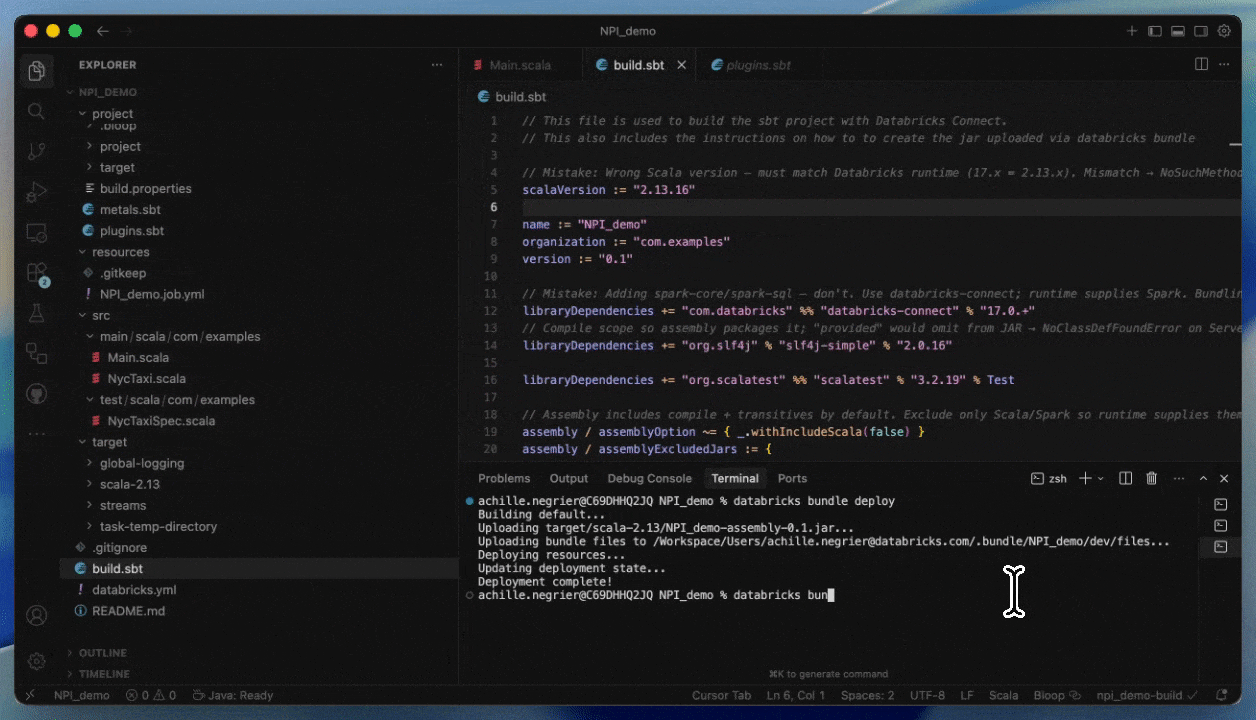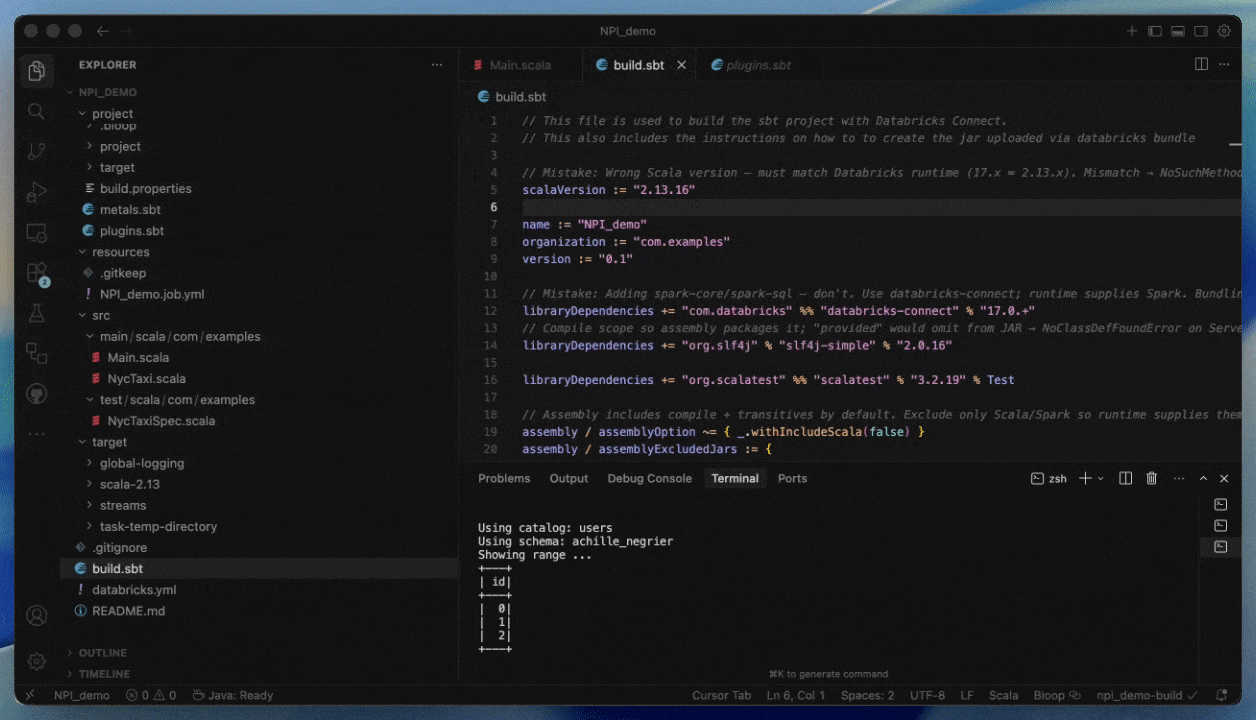
Bereitstellung auf Serverless durch Angabe eines JAR
Schritt 1: Kompilieren Sie Ihr JAR für Serverless
- Kompilieren Sie mit Spark 4 (Scala 2.13) und Spark Connect
- Bündeln Sie alle Nicht-Spark-Abhängigkeiten explizit oder stellen Sie sie als zusätzliche JARs bereit
Schritt 2: Erstellen Sie einen Serverless-Job
- Laden Sie Ihr JAR in ein Unity Catalog-Volume oder in einen UC-Arbeitsbereichsordner hoch.
- Erstellen Sie einen neuen Job mit einer JAR-Aufgabe und wählen Sie Serverless als Compute aus.
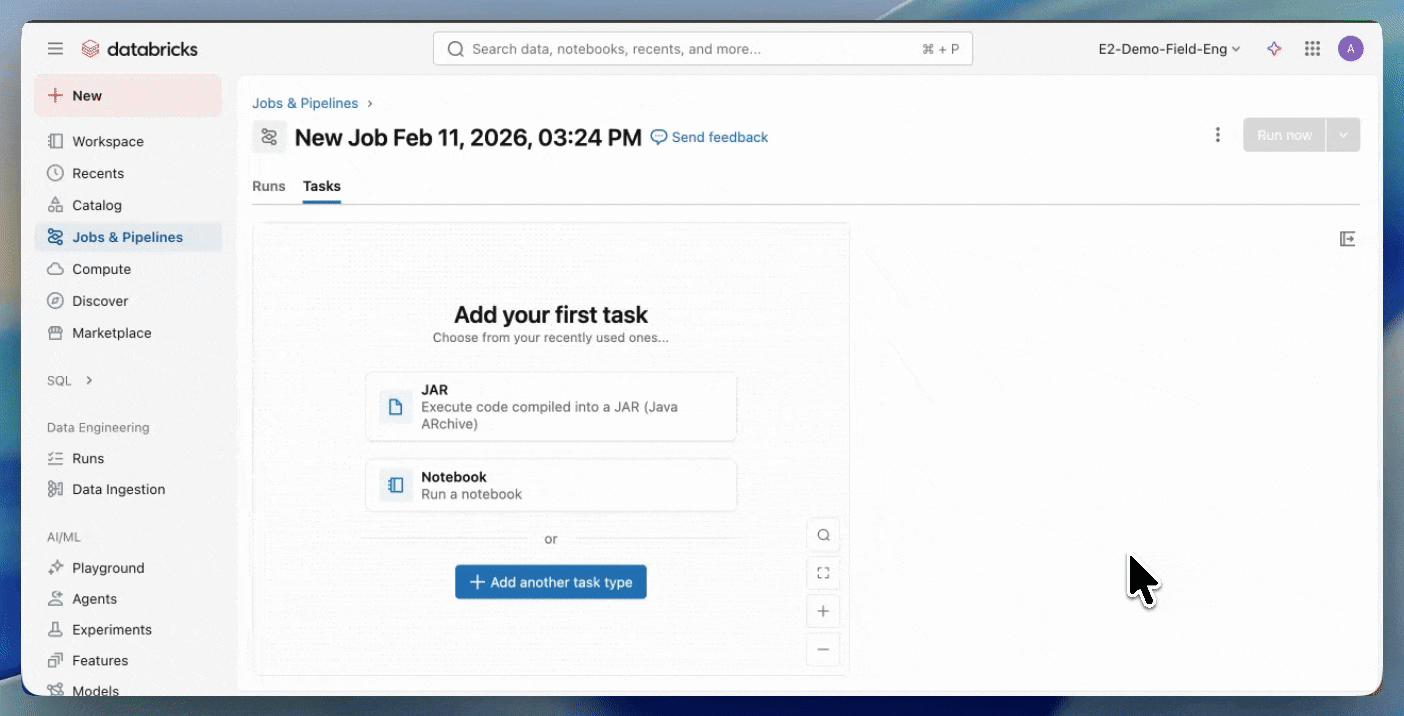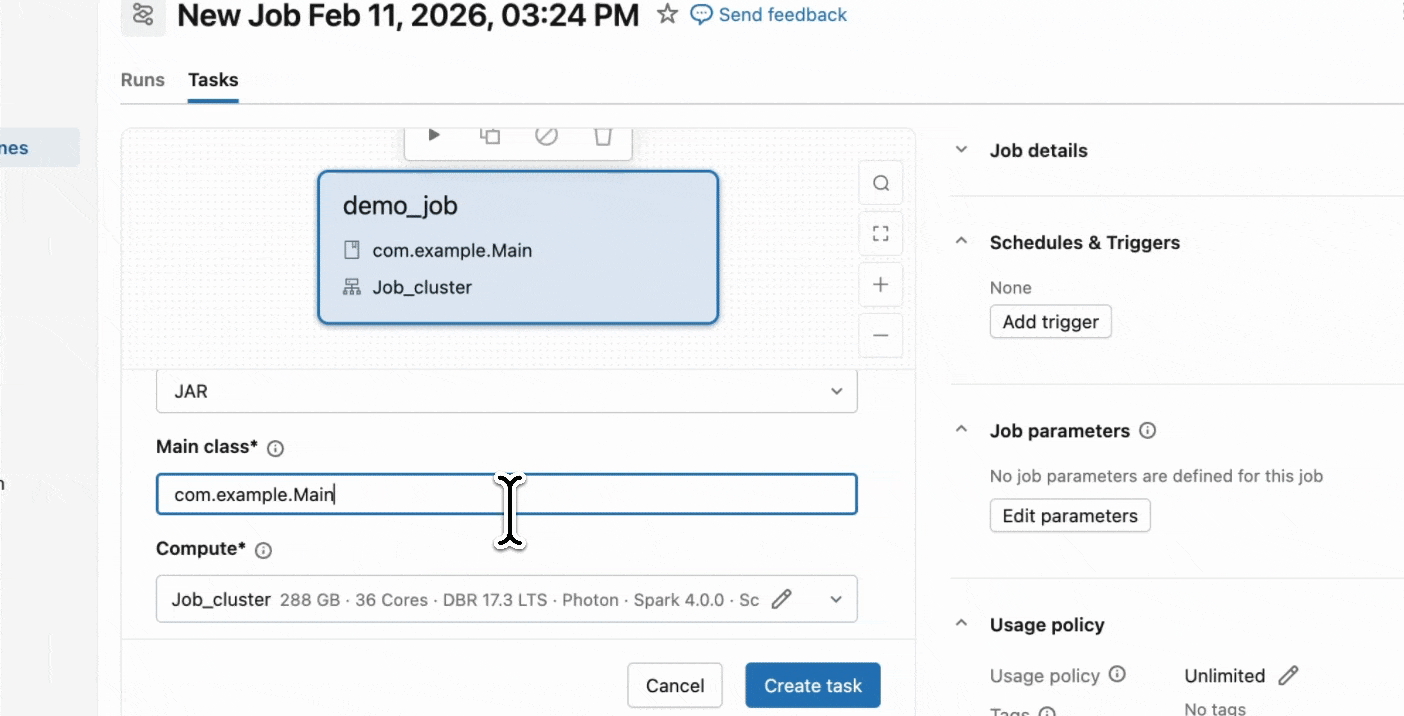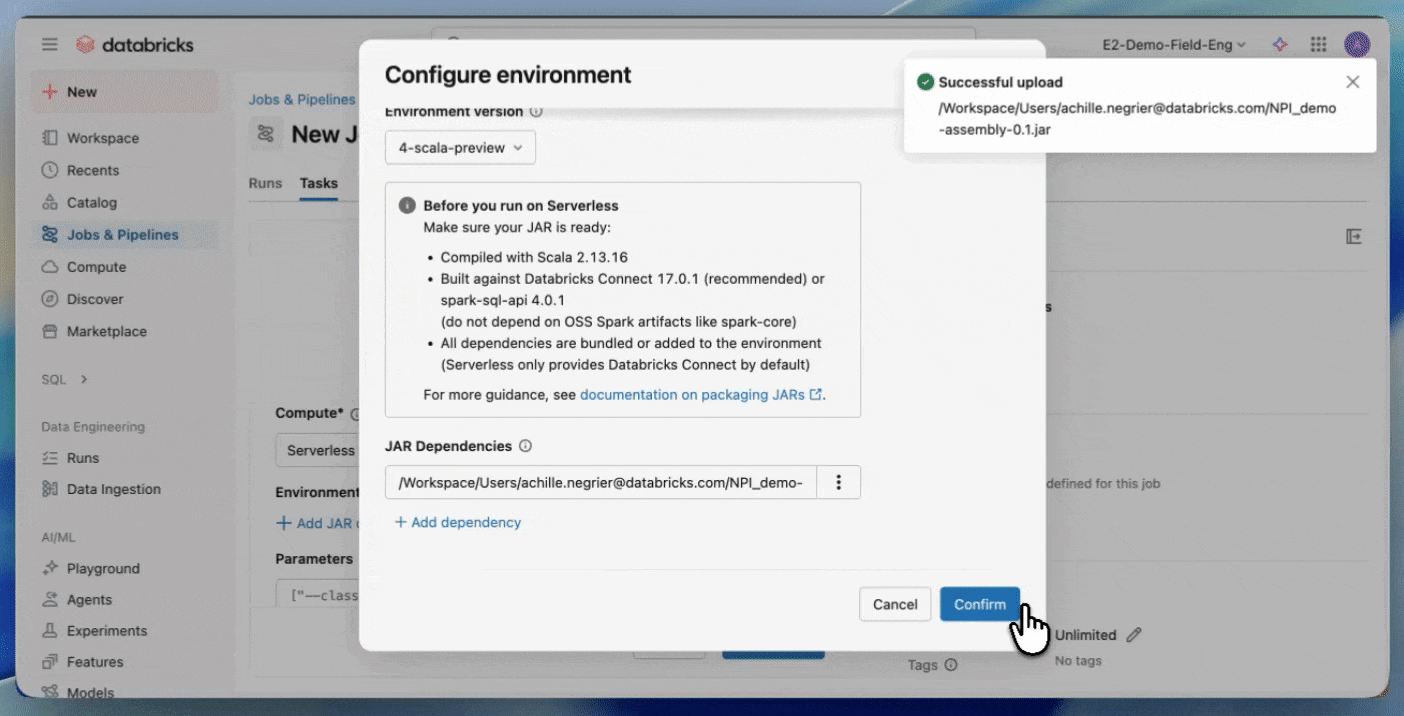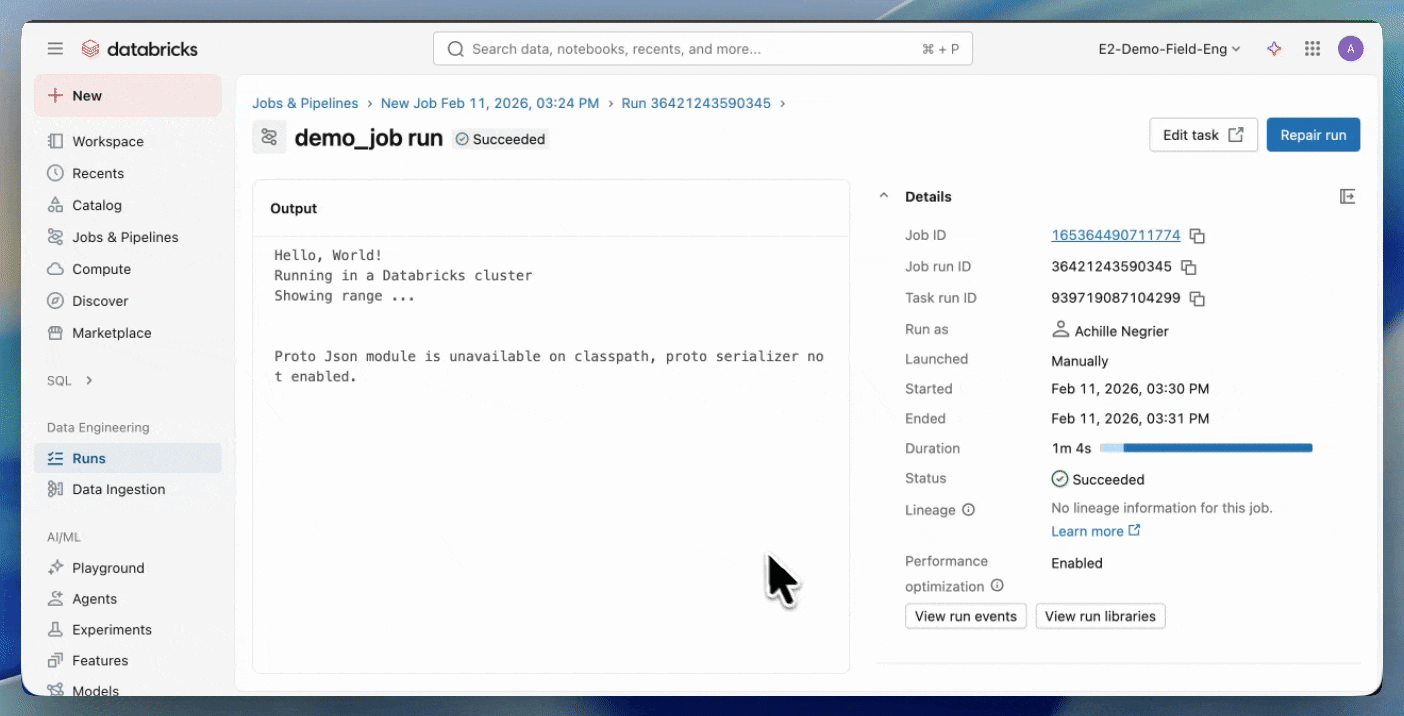
Erste Schritte mit Serverless JARs.
Um schnell loszulegen, folgen Sie dem Tutorial zur Entwicklung und Bereitstellung von Scala-Jobs mit der Databricks Asset Bundle-Vorlage. Für ein Tutorial zur manuellen Kompilierung eines JAR siehe Ausführen von Scala-Code auf Serverless Compute.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.